一、原子操作与锁
1.1、什么是原子操作?
在多线程环境下,确保对共享变量的操作在执行时不会被干扰,从而避免竞态条件,即在同一时刻只允许一个线程可以执行该操作。
1.2、原子性的底层实现
- 从存储体系结构来看
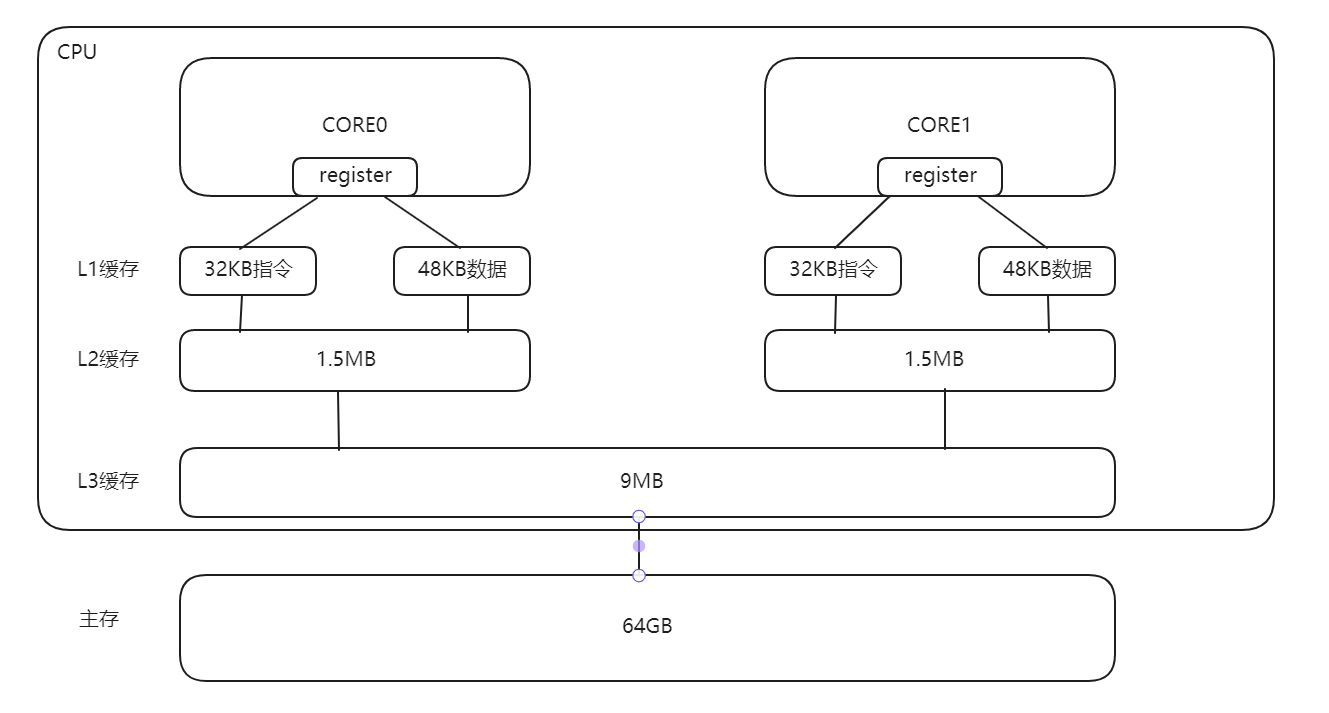
首先是寄存器,离CPU的位置最近,CPU可以直接访问寄存器,寄存器的速度最快。然后是高速缓存(L1、L2、L3),再到内存;速度是依次下降的
其中L1和L2缓存是每个核独占的,L3是多个核共享的。
之所以要设计这样的存储体系结构,主要是为了解决CPU和内存之间的速度不匹配问题。
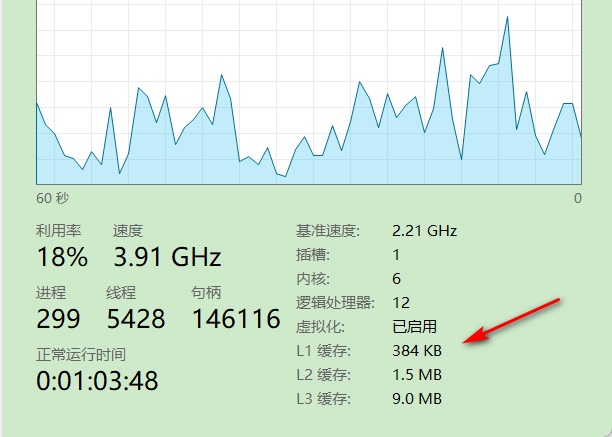
以自己电脑为例,可以清晰看到三级缓存的存在,以及它们各自的容量.
- 从CPU处理器来看
- 何为原子性?
原子性指的是一个操作是不可中断的,要么全部执行成功,要么就都不执行。(数据库事务也是如此,要么全部成功,要么就都不执行。) - 单处理器单核(单线程):
- 保证操作指令不被打断。
- 通过自旋锁
- 屏蔽中断
- 保证操作指令不被打断。
- 多处理器多核(多线程):
- 除了通过自旋锁和屏蔽中断保证原子性外,还可以通过避免其他核心操作相关的内存空间。
- 以往数据发生改变通过总线广播,那么可以通过锁总线的方式,避免其他核心访问内存空间。(低效)
- 只锁定相关内存空间,而不是整个总线。比如锁住变量
i,不影响变量j的操作
- 除了通过自旋锁和屏蔽中断保证原子性外,还可以通过避免其他核心操作相关的内存空间。
- CPU缓存的读写策略
- 读操作:
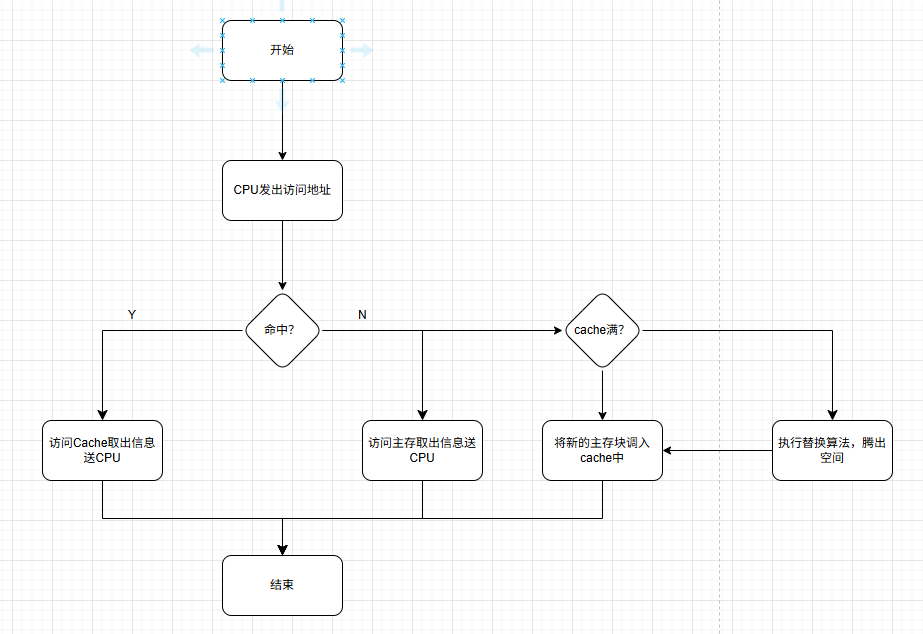
- CPU发出主存地址后,首先判断该地址是否在缓存中
- 如果在,则直接从缓存中读取数据
- 如果不在,一方面从主存中读取数据,另一方面将该地址所在的缓存行加载到CPU的缓存中
- 如果CPU缓存中没有空闲的缓存行,则会采用替换算法(如
FIFO,LRU,随机替换)将旧的缓存行替换掉,并将新读取的数据加载到新的缓存行中
-
写操作:
对于写操作就比较复杂,因为对Cahce块内写入的信息,必须与被映射的主存块内的信息完全一致。当程序运行过程中需对某个单元进行写操作时,会出现如何使Cache与主存内容保持一致 的问题。目前有以下几种方法:- 写直达法(Write-Through):
写操作时,既写入Cache,也写入主存。能保证主存和Cache的数据始终保持一致,但增加了访存次数。 - 写回法(Write-Back):
- 写操作时,只写入Cache,而不写入主存,当Cache中的数据被替换时,再将该数据写回主存。减少了访存次数,但增加了数据不一致的风险。
- 为了识别Cache中的数据是否与主存一致,Cache块中通常会有一个标志位(脏位),该位有两个状态:"清"(表示为被修改过,与主存一致)和"浊"(表示修改过,与主存不一致)
- 在Cache替换时,"清"的Cache不必写回主存
- 在写Cache时,要将标志位设置为"浊",替换时此Cache块必须写回主存,同时标志位置为"清"。
- 写直达法(Write-Through):
- 缓存一致性协议
- 为什么会出现缓存不一致问题?
- 现代CPU基本都是多核的
- 现代CPU基本都采用写回策略
- 解决方案--缓存一致性协议(MESI )
- MESI: 通过总线嗅探策略(将读写请求通过总线广播给所有核心,核心根据本地状态进行响应)实现事务串行化,通过状态机降低总线带宽压力。
- 状态:
- M(Modified):数据已经被修改 ,但未同步到内存中。如果其他核心要读数据,需要将数据从缓存同步到内存中,并将状态转为S(Shared)。
- E(Exclusive): 独占,某个数据只在某核心中,此时缓存和内存中的数据一致
- S(Shared): 共享,多个核心可以访问该数据,此时缓存和内存中的数据一致
- I(Invalidated): 无效,某数据在该核心中失效,不是最新数据。
- 事件:
- PrRd: 核心请求从缓存中读取数据
- PrWr: 核心请求向缓存中写入数据
- BusRd: 总线嗅探器收到来自其他核心的读出缓存请求
- BusRdX: 总线嗅探器收到另一核心写一个其不拥有的缓存块的请求
- BusUpgr: 总线嗅探器收到另一核心写一个其拥有的缓存块的请求
- Flush: 总线嗅探器收到另一核心把一个缓存块写回到主存的请求
- FlushOpt: 总线嗅探器收到一个缓存块被放置在总线,以提供给另一个核心的请求,类似Flush,但不写回主存,只作用与缓存
***小结:***原子性操作的底层实现 = 硬件自旋锁 + 屏蔽中断 + 锁总线锁住 ME状态; 锁总线锁住ME状态,是根据现代CPU的写回策略以及保持缓存一致性来决定的。
1.3、内存序
- 什么是内存序:
-
CPU和编译器,会对代码进行优化,比如指令重排。
c++// 原来代码执行顺序: int i = 1; int j = 1; i += 1; j += 2; // 经过优化后的执行顺序可能为: int i = 1; i += 1; int j = 1; j += 2; // 将相关的变量放在一起,减少缓存失效次数这样处理在单线程中没有问题,但是在多线程中就会出现问题。时序发生改变,导致结果不可预期。
所以内存序是为了指导CPU和编译器进行优化时,需要遵守的规则 以及操作某个核心中的数据时,是否需要同步至其他核心
-
- 内存序规定了什么:
- 规定了多个线程访问同一个内存地址的语义
- 某个线程对内存地址的更新何时能被其他线程看见
- 某个线程对内存地址访问附近可以做怎么样的优化
- 内存序具体规则:
-
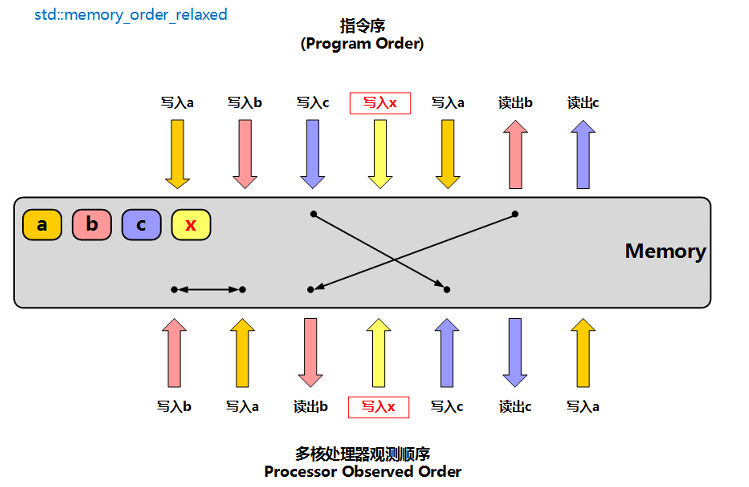
memory_order_relaxed:松散内存序,只用来保证对原子对象的操作具备原子性,不保证多线程的执行顺序(随便优化)
- 比如指令序:
写入a,写入b,写入c,写入x,写入a,读出b,读出c对写入x进行memory_order_relaxed - 可以得到:
写入b,写入a,读出b,写入x,写入c,读出c,写入a,只保证写入x的顺序,其他顺序可以任意调整
- 比如指令序:
-
memory_order_release: 释放操作,写操作,在写缓存的同时,会将数据同步到主存中,其他核心可以看见该核心对内存地址的更新
- 只允许该指令后的指令能被优化到该指令之前,不允许该指令之前的指令被优化到该指令之后
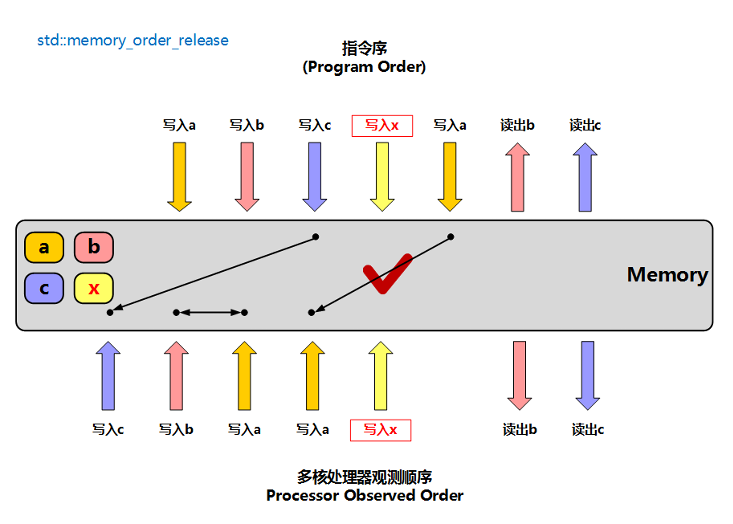
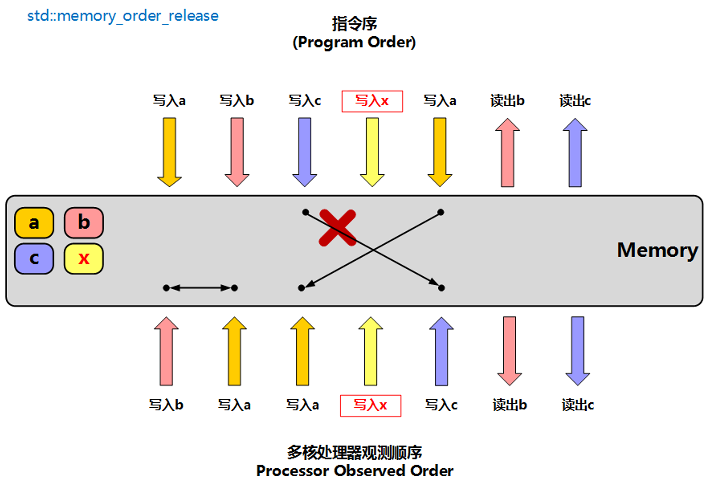
- 只允许该指令后的指令能被优化到该指令之前,不允许该指令之前的指令被优化到该指令之后
-
memory_order_acquire: 获取操作,读操作,为保证数据一致性,会读取主存的数据,然后同步至缓存当中,其他核心可以看见该核心对内存地址的更新
- 只允许该指令之前的指令能被优化到该指令之后,不允许该指令之后的指令被优化到该指令之前
- 和
memory_order_release配合使用,保证内存操作的顺序
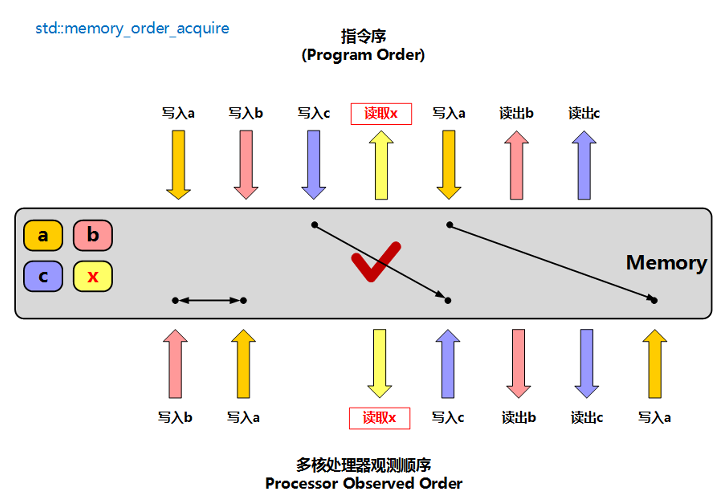
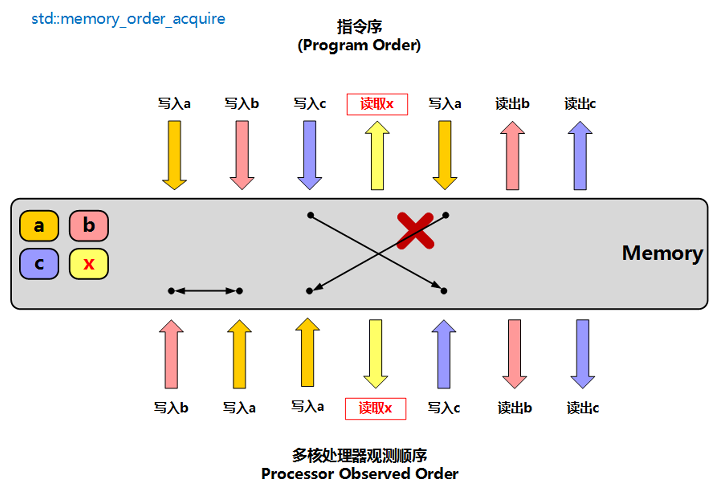
-
memory_order_consume: 不建议使用,在大多数平台上,只会影响编译器的优化
-
memory_order_acq_rel: 获取-释放操作 ,在
memory_order_acquire和memory_order_release的基础上,既保证该指令之前的指令不能被优化到该指令之后,又保证该指令之后的指令不能被优化到该指令之前,相当于存在内存屏障 -
memory_order_seq_cst: 顺序一致操作 ,对于读操作相当于
memory_order_acquire,对于写操作相当于memory_order_release,对于读写操作相当于memory_order_acq_rel,是所有原子操作的默认内存序 ,并且会对所有使用该模型的原子操作建立一个全局顺序,保证了多个原子变量的操作在所有线程里观察到的操作顺序相同,但也是最慢的。
-
二、原子操作实践
2.1、游戏在线人数统计
以游戏在线人数统计为背景 ,统计某个时间点在线人数。
- 不使用原子操作之前
cpp
#include <iostream>
#include <thread>
#include <vector>
// 全局变量 - 在线人数
int online_players = 0;
// 模拟玩家登录
void player_login() {
for (int i = 0; i < 10000; ++i) {
int current = online_players; // 1. 读取
current = current + 1; // 2. 修改
online_players = current; // 3. 写入
}
}
// 模拟玩家登出
void player_logout() {
for (int i = 0; i < 5000; ++i) {
int current = online_players;
current = current - 1;
online_players = current;
}
}
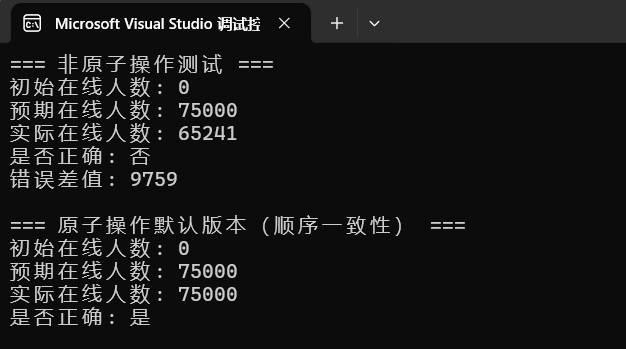
void test_non_atomic() {
std::cout << "=== 非原子操作测试 ===" << std::endl;
// 记录开始值
int start_value = online_players;
// 创建多个线程模拟玩家登录
std::vector<std::thread> login_threads;
for (int i = 0; i < 10; ++i) {
login_threads.emplace_back(player_login);
}
// 创建多个线程模拟玩家登出
std::vector<std::thread> logout_threads;
for (int i = 0; i < 5; ++i) {
logout_threads.emplace_back(player_logout);
}
// 等待所有线程完成
for (auto& t : login_threads) t.join();
for (auto& t : logout_threads) t.join();
// 计算预期结果
int expected = start_value + (10 * 10000) - (5 * 5000);
std::cout << "初始在线人数: " << start_value << std::endl;
std::cout << "预期在线人数: " << expected << std::endl;
std::cout << "实际在线人数: " << online_players << std::endl;
std::cout << "是否正确: " << (online_players == expected ? "是" : "否") << std::endl;
std::cout << "错误差值: " << (expected - online_players) << std::endl;
}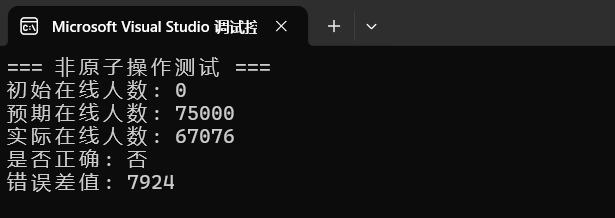
可以明显看到,实际统计的人数和预期的人数完全不一致,而且差距还挺大。
- 使用原子操作之后
cpp
std::atomic<int> atomic_online_players(0);
// 使用原子操作-默认(顺序一致性)
void player_login_atomic_seq_cst()
{
for (int i = 0; i < 10000; ++i) {
atomic_online_players.fetch_add(1, std::memory_order_seq_cst);
}
}
void player_logout_atomic_seq_cst() {
for (int i = 0; i < 5000; ++i) {
atomic_online_players.fetch_sub(1, std::memory_order_seq_cst);
}
}
void test_atomic_basic() {
std::cout << "\n=== 原子操作默认版本(顺序一致性) ===" << std::endl;
atomic_online_players = 0; // 重置计数器
int start_value = atomic_online_players.load();
// 创建线程
std::vector<std::thread> login_threads;
std::vector<std::thread> logout_threads;
for (int i = 0; i < 10; ++i) {
login_threads.emplace_back(player_login_atomic_seq_cst);
}
for (int i = 0; i < 5; ++i) {
logout_threads.emplace_back(player_logout_atomic_seq_cst);
}
for (auto& t : login_threads) t.join();
for (auto& t : logout_threads) t.join();
auto end = std::chrono::high_resolution_clock::now();
int expected = start_value + (10 * 10000) - (5 * 5000);
std::cout << "初始在线人数: " << start_value << std::endl;
std::cout << "预期在线人数: " << expected << std::endl;
std::cout << "实际在线人数: " << atomic_online_players.load() << std::endl;
std::cout << "是否正确: " << (atomic_online_players == expected ? "是" : "否") << std::endl;
}
2.2、原子操作-六种内存序对比
- 松散内存序(
memory_order_relaxed)
cpp
// 松散内存序 - 只保证原子性,不保证顺序
void player_login_atomic_relaxed()
{
for (int i = 0; i < 10000; ++i) {
atomic_online_players.fetch_add(1, std::memory_order_relaxed);
}
}
void player_logout_atomic_relaxed()
{
for (int i = 0; i < 5000; ++i) {
atomic_online_players.fetch_sub(1, std::memory_order_relaxed);
}
}
void test_relaxed()
{
std::cout << "\n=== memory_order_relaxed ===" << std::endl;
std::cout << "只保证原子性,不保证内存顺序" << std::endl;
atomic_online_players = 0; // 重置计数器
int start_value = atomic_online_players.load();
auto start = std::chrono::high_resolution_clock::now();
// 创建线程
std::vector<std::thread> login_threads;
std::vector<std::thread> logout_threads;
for (int i = 0; i < 10; ++i) {
login_threads.emplace_back(player_login_atomic_relaxed);
}
for (int i = 0; i < 5; ++i) {
logout_threads.emplace_back(player_logout_atomic_relaxed);
}
for (auto& t : login_threads) t.join();
for (auto& t : logout_threads) t.join();
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(end - start);
int expected = start_value + (10 * 10000) - (5 * 5000);
std::cout << "初始在线人数: " << start_value << std::endl;
std::cout << "预期在线人数: " << expected << std::endl;
std::cout << "实际在线人数: " << atomic_online_players.load() << std::endl;
std::cout << "是否正确: " << (atomic_online_players == expected ? "是" : "否") << std::endl;
std::cout << "执行时间: " << duration.count() << " 微秒" << std::endl;
}- 释放内存序(
release)
cpp
void player_login_atomic_release()
{
// 单独使用release内存序是错误操作
for (int i = 0; i < 10000; ++i) {
atomic_online_players.fetch_add(1, std::memory_order_release);
}
}
void player_logout_atomic_release()
{
for (int i = 0; i < 5000; ++i) {
atomic_online_players.fetch_sub(1, std::memory_order_release);
}
}
void test_release()
{
std::cout << "\n=== memory_order_release ===" << std::endl;
std::cout << "释放内存序\n";
atomic_online_players = 0; // 重置计数器
int start_value = atomic_online_players.load();
auto start = std::chrono::high_resolution_clock::now();
// 创建线程
std::vector<std::thread> login_threads;
std::vector<std::thread> logout_threads;
for (int i = 0; i < 10; ++i) {
login_threads.emplace_back(player_login_atomic_release);
}
for (int i = 0; i < 5; ++i) {
logout_threads.emplace_back(player_logout_atomic_release);
}
for (auto& t : login_threads) t.join();
for (auto& t : logout_threads) t.join();
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(end - start);
int expected = start_value + (10 * 10000) - (5 * 5000);
std::cout << "初始在线人数: " << start_value << std::endl;
std::cout << "预期在线人数: " << expected << std::endl;
std::cout << "实际在线人数: " << atomic_online_players.load() << std::endl;
std::cout << "是否正确: " << (atomic_online_players == expected ? "是" : "否") << std::endl;
std::cout << "执行时间: " << duration.count() << " 微秒" << std::endl;
}- 获取内存序(
acquire)
cpp
void player_login_atomic_acquire()
{
// 单独使用acquire内存序是错误操作
for (int i = 0; i < 10000; ++i) {
atomic_online_players.fetch_add(1, std::memory_order_acquire);
}
}
void player_logout_atomic_acquire()
{
for (int i = 0; i < 5000; ++i) {
atomic_online_players.fetch_sub(1, std::memory_order_acquire);
}
}
void test_acquire()
{
std::cout << "\n=== memory_order_acquire ===" << std::endl;
std::cout << "获取内存序\n";
atomic_online_players = 0; // 重置计数器
int start_value = atomic_online_players.load();
auto start = std::chrono::high_resolution_clock::now();
// 创建线程
std::vector<std::thread> login_threads;
std::vector<std::thread> logout_threads;
for (int i = 0; i < 10; ++i) {
login_threads.emplace_back(player_login_atomic_acquire);
}
for (int i = 0; i < 5; ++i) {
logout_threads.emplace_back(player_logout_atomic_acquire);
}
for (auto& t : login_threads) t.join();
for (auto& t : logout_threads) t.join();
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(end - start);
int expected = start_value + (10 * 10000) - (5 * 5000);
std::cout << "初始在线人数: " << start_value << std::endl;
std::cout << "预期在线人数: " << expected << std::endl;
std::cout << "实际在线人数: " << atomic_online_players.load() << std::endl;
std::cout << "是否正确: " << (atomic_online_players == expected ? "是" : "否") << std::endl;
std::cout << "执行时间: " << duration.count() << " 微秒" << std::endl;
}- 获取释放内存序(
acq_rel)
cpp
void player_login_atomic_acq_rel()
{
for (int i = 0; i < 10000; ++i) {
atomic_online_players.fetch_add(1, std::memory_order_acq_rel);
}
}
void player_logout_atomic_acq_rel()
{
for (int i = 0; i < 5000; ++i) {
atomic_online_players.fetch_sub(1, std::memory_order_acq_rel);
}
}
void test_acq_rel()
{
std::cout << "\n=== memory_order_acq_rel ===" << std::endl;
std::cout << "获取-释放内存序\n";
atomic_online_players = 0; // 重置计数器
int start_value = atomic_online_players.load();
auto start = std::chrono::high_resolution_clock::now();
// 创建线程
std::vector<std::thread> login_threads;
std::vector<std::thread> logout_threads;
for (int i = 0; i < 10; ++i) {
login_threads.emplace_back(player_login_atomic_acq_rel);
}
for (int i = 0; i < 5; ++i) {
logout_threads.emplace_back(player_logout_atomic_acq_rel);
}
for (auto& t : login_threads) t.join();
for (auto& t : logout_threads) t.join();
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(end - start);
int expected = start_value + (10 * 10000) - (5 * 5000);
std::cout << "初始在线人数: " << start_value << std::endl;
std::cout << "预期在线人数: " << expected << std::endl;
std::cout << "实际在线人数: " << atomic_online_players.load() << std::endl;
std::cout << "是否正确: " << (atomic_online_players == expected ? "是" : "否") << std::endl;
std::cout << "执行时间: " << duration.count() << " 微秒" << std::endl;
}- 消费内存序(
consume)
cpp
// 消费内存序-不推荐使用,现在大部分平台将其实现为acquire
void player_login_atomic_consume()
{
for (int i = 0; i < 10000; ++i) {
atomic_online_players.fetch_add(1, std::memory_order_consume);
}
}
void player_logout_atomic_consume()
{
for (int i = 0; i < 5000; ++i) {
atomic_online_players.fetch_sub(1, std::memory_order_consume);
}
}
void test_consume()
{
std::cout << "\n=== memory_order_consume ===" << std::endl;
std::cout << "消费内存序-不推荐使用,现在大部分平台将其实现为acquire\n";
atomic_online_players = 0; // 重置计数器
int start_value = atomic_online_players.load();
auto start = std::chrono::high_resolution_clock::now();
// 创建线程
std::vector<std::thread> login_threads;
std::vector<std::thread> logout_threads;
for (int i = 0; i < 10; ++i) {
login_threads.emplace_back(player_login_atomic_consume);
}
for (int i = 0; i < 5; ++i) {
logout_threads.emplace_back(player_logout_atomic_consume);
}
for (auto& t : login_threads) t.join();
for (auto& t : logout_threads) t.join();
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(end - start);
int expected = start_value + (10 * 10000) - (5 * 5000);
std::cout << "初始在线人数: " << start_value << std::endl;
std::cout << "预期在线人数: " << expected << std::endl;
std::cout << "实际在线人数: " << atomic_online_players.load() << std::endl;
std::cout << "是否正确: " << (atomic_online_players == expected ? "是" : "否") << std::endl;
std::cout << "执行时间: " << duration.count() << " 微秒" << std::endl;
}
int main()
{
//test_non_atomic();
test_atomic_basic();
test_relaxed();
test_release();
test_acquire();
test_acq_rel();
test_consume();
return 0;
}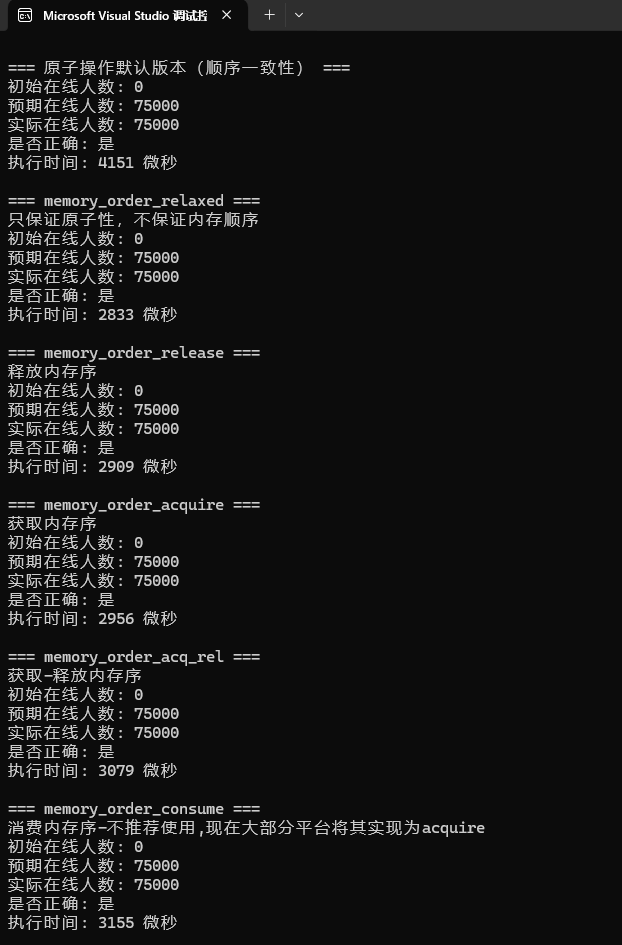
小结:
- 可以明显看到,
memory_order_relaxed的执行时间最短,因为它不保证任何内存序,只保证原子性;而memory_order_seq_cst最慢,因为它需要保证全局顺序一致性,建立单一全局操作顺序,需要最强的内存屏障。 - 不能单独使用``memory_order_acquire
或memory_order_release`,但为什么得到正确的结果?- 因为目前只涉及一个原子变量操作
- 无依赖关系,不需要同步其他非原子变量的状态