1 简介
1.1 发展历程
1. 起步阶段(1990 年代):从图形加速到 GPU 雏形
1993年:NVIDIA 成立,初期专注于图形芯片设计。
1997年:发布 RIVA 128,首款支持 DirectX 5 和 OpenGL 1.1 的显卡,采用 128-bit 架构,奠定早期 3D 加速基础。
1999年:推出 GeForce 256,首次提出"GPU"概念,集成硬件变换与光照(T&L)引擎,不再依赖 CPU 处理图形数据,性能较前代提升 10 倍。
2. 架构迭代与市场扩张(2000 年代):从 GeForce 到 CUDA
2001年:GeForce3 引入可编程着色器(Vertex Shader 和 Pixel Shader),支持 DirectX 8,开启 "可编程图形" 时代。
2004年:GeForce 6800 Ultra(NV40架构)支持 DirectX 9,引入 SM(Streaming Multiprocessor)雏形,为后续并行计算奠定硬件基础。
2006年:GeForce 8800 GTX(G80架构)发布,首次采用统一渲染架构,支持 DirectX 10;同年推出 CUDA 平台,使GPU具备通用计算能力。
2008年:GeForce GTX 280(GT200架构)强化多GPU协同(SLI 技术),CUDA 核心数量提升至 240 个,通用计算性能显著增强。
3. 通用计算崛起(2010 年代):从游戏到 AI
2010年:GeForce GTX 480(Fermi架构)首次支持 ECC 内存,引入 L2 缓存和双通道 GDDR5 显存,CUDA 核心数量达 480 个,首次被广泛用于 AI 研究。
2012年:GeForce GTX 680(Kepler架构)能效比大幅提升,采用"开普勒"SM 设计,支持动态超频(GPU Boost),推动 GPU 在深度学习领域的应用。
2016年:GeForce GTX 1080 Ti(Pascal架构)采用16nm工艺,显存带宽提升至 484GB/s,CUDA 核心数量达 3584个,成为当时 AI 研究的"主力卡"。
2018年:GeForce RTX 2080 Ti(Turing架构)首次引入RT Core(光线追踪核心)和Tensor Core(张量核心),支持实时光线追踪和 AI 超采样(DLSS),开启"实时光追 + AI 加速"新纪元。
4. 全能计算时代(2020 年代至今):Ada Lovelace 与 Blackwell
2020年:GeForce RTX 3090(Ampere架构)升级 Tensor Core 和 RT Core,支持 FP16 混合精度计算,显存容量达 24GB GDDR6X,兼顾 8K 游戏与 AI 训练。
2022年:GeForce RTX 4090(Ada Lovelace架构)采用 4nm 工艺,引入 Shader Execution Reordering(SER) 和第二代 RT Core,DLSS 3 技术支持 AI 生成帧,光线追踪性能较上一代提升2倍,该架构面向消费级显卡领域。同时发布Hopper 架构,面向数据中心 / AI 领域。
2024年:GeForce RTX 5090(Blackwell架构)发布,集成更多CUDA Core 和Tensor Core,支持 FP4 超算精度,进一步模糊游戏GPU与数据中心GPU的界限,成为AI创作、实时渲染和科学计算的全能平台。
2025年:对应R100 以及 GeForce RTX 60 系列(Rubin架构),R100是基于Rubin 架构的首款产品,预计将于2025年第四季度进入量产。它将采用台积电3nm工艺,配备HBM4内存,使用台积电的CoWoS-L封装技术。此外,基于 Rubin 架构的消费级显卡 GeForce RTX 60 系列也在规划中,包括 RTX 6090、RTX 6080 和 RTX 6070 Ti 等,这些显卡预计会在 2026 年至 2027 年期间推出。
自2006年起,英伟达每次架构发布都是以一位知名科学家的名字命名,用于向他们表示致敬,主要历史如下:

1.2 关键概念
1 驱动及toolkit
首先理解下这两个概念:驱动关系到程序运行,也就是说程序要在平台(Windows/Linux)上运行,必须要有NVIDIA显卡及对应驱动,两者缺一不可;而toolkit关系到程序编译,平台上即便不存在显卡及驱动,只要它安装了toolkit即可编译相应的GPU程序,编译出的程序即可拷贝到存在GPU显卡及相关驱动的平台去运行,所以说这两个概念是相对独立的。在Ubuntu 22.04下推荐驱动和CUDA Toolkit分开装,驱动用apt管理,CUDA runfile只安装toolkit,如使用下面命令只安装toolkit,而不安装runfile里面的驱动:
sudo sh cuda_12.4.1_linux.run --silent --toolkit --toolkitpath=/usr/local/cuda-12.4当然也可以通过sudo sh cuda_12.4.1_linux.run进入交互菜单,在进行安装时把Driver前面的勾去掉,只选Toolkit、Samples等需要的部分。
另外在进行驱动安装前要确定下相关版本及兼容性,下面是chatgpt给出的GTX 1060+Ubuntu 22.04的兼容性参考表:
 在Ubuntu 22.04上推荐使用nvidia-driver-550配合12.4/12.6,来做为基于GTX 1060显卡程序运行及开发环境。
在Ubuntu 22.04上推荐使用nvidia-driver-550配合12.4/12.6,来做为基于GTX 1060显卡程序运行及开发环境。
2 硬件角度关键概念
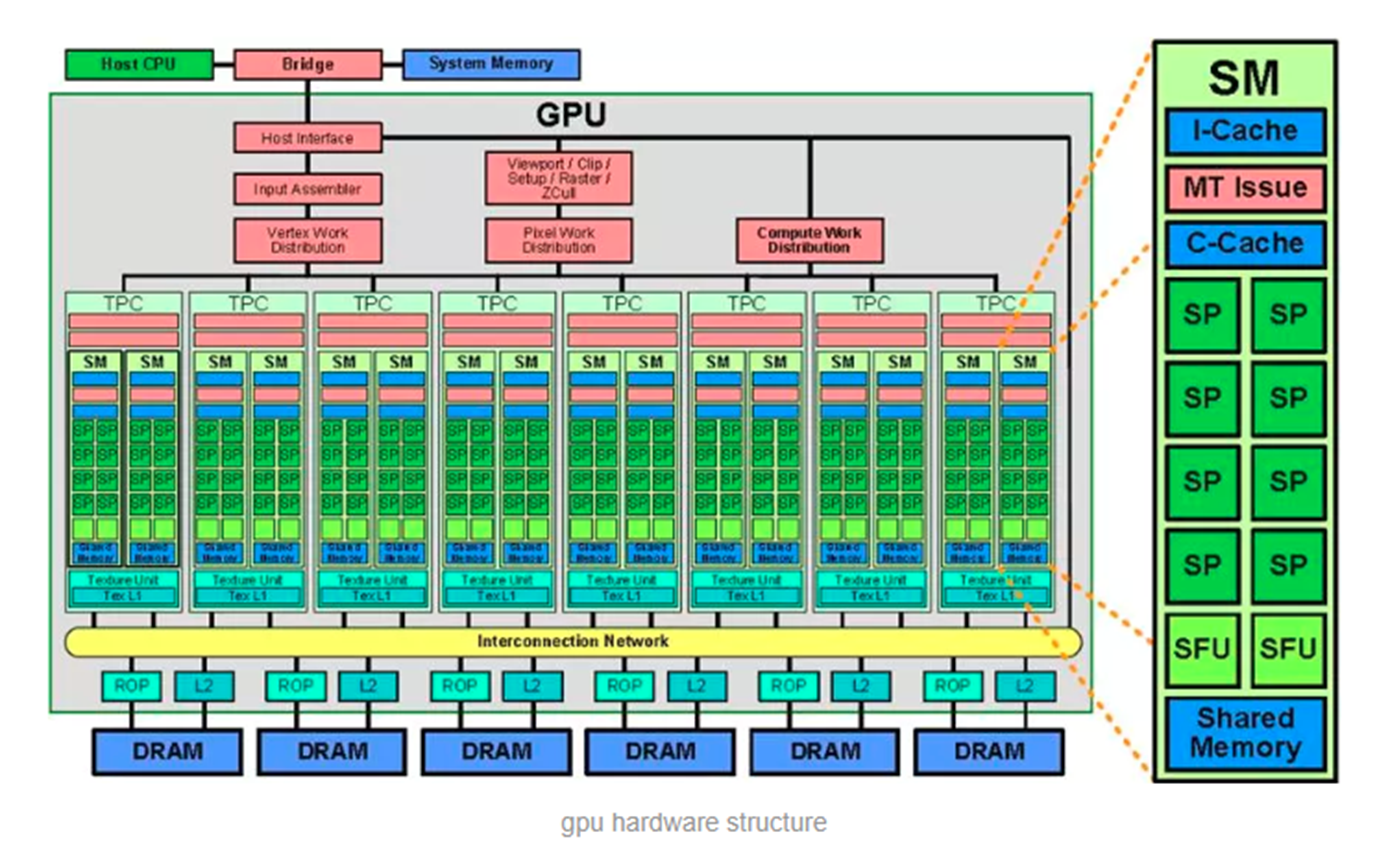
(1)SP(streaming processor):最基本的处理单元,也称CUDA core,最后具体的指令和任务都是在SP上处理的,GPU进行并行计算,就是很多SP同时做处理。
(2)SM(streaming multiprocessor):多个SP加上一些其他资源,如:warp scheduler,register,shared memory等组成一个SM,也叫GPU大核。由于register和shared memory资源的稀缺性,会限制active warps的个数,即限制了GPU的并行能力。
(3)Warp:一个SP可以执行一个thread,但是实际上并不是所有的thread能够在同一时刻执行。Nvidia把32个threads组成一个warp,warp是调度和运行的基本单元。一次调度时,warp的32个线程会被同时分配到32个SP一次执行完成。所以,如果SM有64个SP,就可以同时执行2个warp(64/32=2),如果SM有128个SP,就可在一个周期里同时执行4个warp。
3 软件角度关键概念
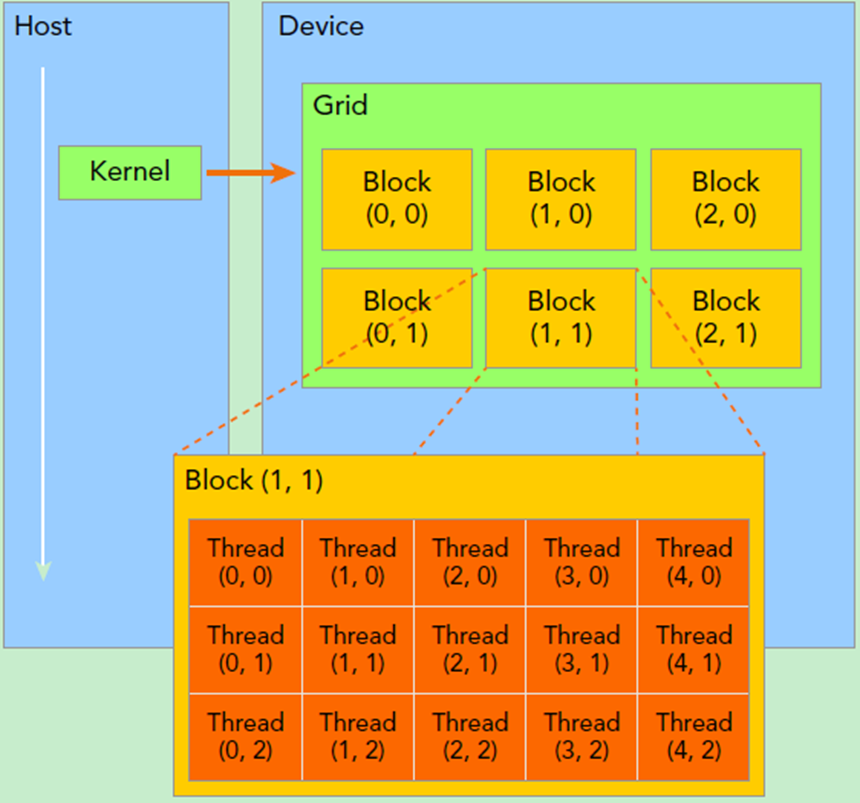
(1)Kernel:在GPU上调用的函数称为CUDA核函数(Kernel function),核函数会被GPU上的多个线程执行,其调用格式如下:
kernel_name<<<grid, block>>>(argument list);(2)Grid:由一个单独的kernel启动的所有线程组成一个grid,grid中所有线程共享global memory。Grid由很多Block组成,可以是一维、二维或三维。
(3)Block:block由许多线程组成,同样可以有一维、二维或者三维,block内部的多个线程可以同步(synchronize),可访问共享内存(share memory)。
(4)dim3:CUDA提供的一个内置类型,本质上是一个三维向量,用于指定网格和块的维度和大小。
struct dim3 {
unsigned int x, y, z;
};如dim3(16),则x为16,y和z取默认值为 1,dim3(16, 8),则x为16,y为8,z取默认值为 1。
4 关键内置变量
blockIdx:块儿索引,blockIdx.x表示block在grid中的x坐标。
threadIdx:线程索引,threadIdx.x表示thread在block中的x坐标。
gridDim: 每个grid在三个维度上的块数,gridDim.x表示x维度上block的数量,如上图中gridDim.x为3。
blockDim:每个block在三个维度上的线程数,blockDim.x表示x维度上thread的数量,如上图中blockDim.x为5。
例如,如下调用中grid为一维,有4个block,block也为一维,每个block有8个线程,所以调用会启动4*8=32个线程。
kernel_name<<<4, 8>>>(argumentt list);相应index取值由下图示意:

5 GPU核心
1 Texture Core(纹理核心)
专门负责纹理采样、过滤和坐标转换等图形渲染任务,广泛用于游戏、影视渲染中对纹理(如皮肤、布料、环境贴图)的处理。
2 CUDA Core(CUDA 核心)
执行传统的浮点运算(如 FP32、FP64)和整数运算,支持 CUDA 编程模型,负责处理通用并行计算任务(如科学计算、图像处理、物理模拟等),是NVIDIA GPU的基础计算核心。
3 Tensor Core(张量核心)
高效执行 FP16/FP32/INT8 等精度的矩阵乘法与累加(GEMM)操作,公式为 D = A × B + C(其中 A、B、C、D 为矩阵)。
4 RT Core(光线追踪核心)
加速光线与物体相交检测(Ray Tracing Intersection)计算,以及辐射度估计等光线追踪核心算法。
5 其他核心
DPU(数据处理单元)、Security Core(安全核心)、Infinity互联核心
现代 NVIDIA GPU(如 Ampere、Hopper、Blackwell 架构)通常同时集成这三种核心,分别负责通用计算、AI 加速和图形渲染,形成"三位一体"的计算能力。
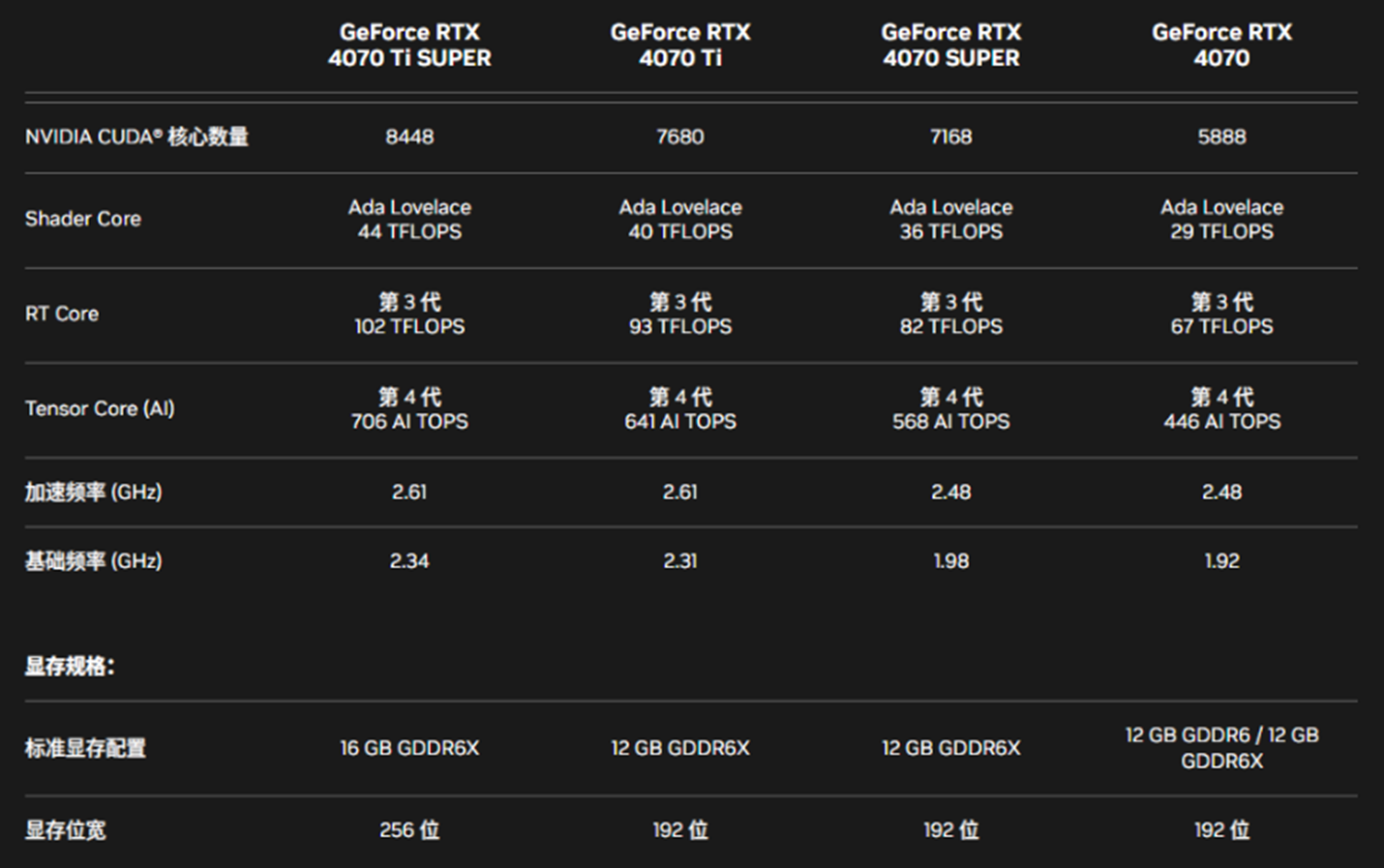
以下是RTX 4070系列显卡相关核心及其他关键参数信息:
1.3 示例程序
接下来先给出示例程序hello.cu源码:
1 #include<stdio.h>
2 #include <cuda.h>
3 #include <cuda_profiler_api.h>
4
5 //定义gpu 核函数
6 __global__ void helloFromGPU()
7 {
8 int blockIndex = (blockIdx.z * gridDim.y + blockIdx.y) * gridDim.x + blockIdx.x;
9 int globalThreadIndex = blockIndex * blockDim.x * blockDim.y * blockDim.z +
10 (threadIdx.z * blockDim.y + threadIdx.y) * blockDim.x + threadIdx.x;
11 printf("Hello World from block(%d %d %d) thread(%d %d %d) %d!\n", blockIdx.x, blockIdx.y, blockIdx.z,
12 threadIdx.x, threadIdx.y, threadIdx.z, globalThreadIndex);
13 }
14 int main()
15 {
16 //hello from cpu
17 printf("Hello World CPU!\n");
18 dim3 number_of_blocks(2, 3, 1);
19 dim3 threads_per_block(4, 8, 1);
20 //调用核函数
21 helloFromGPU<<<number_of_blocks, threads_per_block>>>();
22 cudaDeviceReset();
23 return 0;
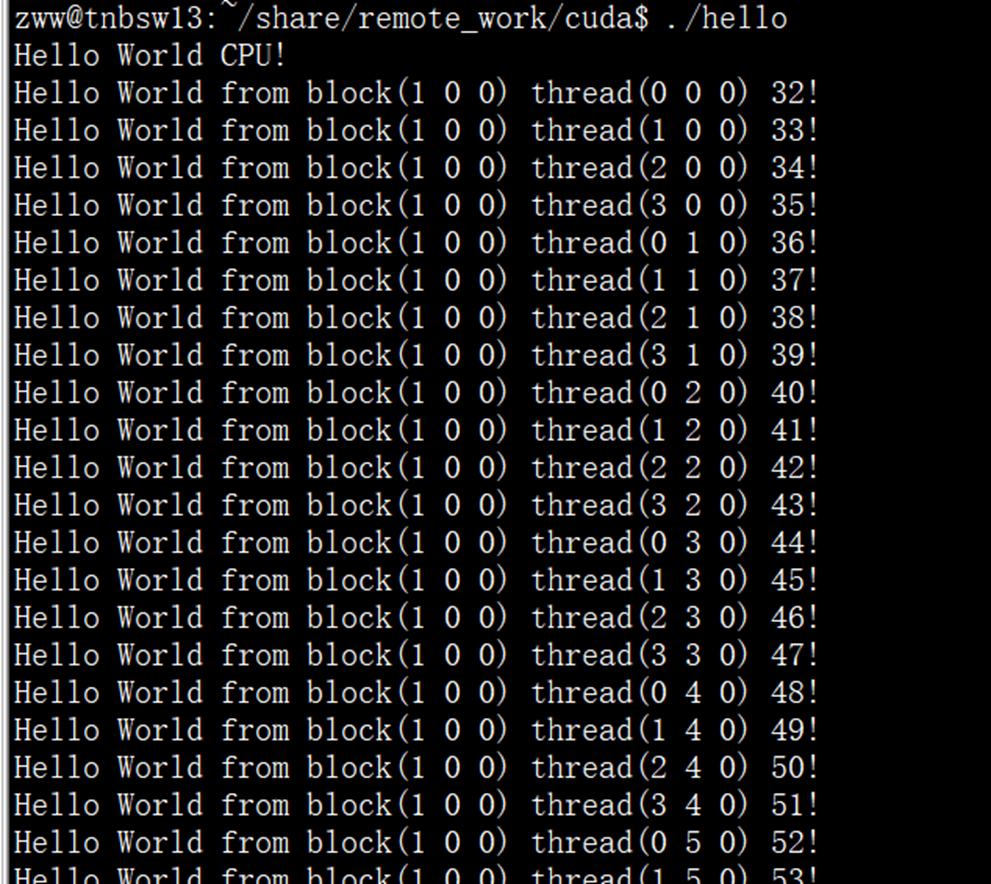
24 }运行nvcc --o hello hello.cu编译,然后执行该程序。运行结果中,第一个GPU thread输出是blockIdx(1,0,0), threadIdx(0,0,0), 即第1个block(下标从0开始)中第0个线程,所以其全局index为32。
2 程序调试
2.1 调试工具
CUDA程序主要调试工具如下所示:
| 工具 | 主要用途 | 适用平台 | 特点 |
|---|---|---|---|
| Nsight Systems | 系统级性能分析(时间线、API 调用、CPU/GPU 协作) | Win / Linux | 类似 "性能总览 + 火焰图" |
| Nsight Compute | 内核级性能分析(Warp、SM、Memory、Occupancy) | Win / Linux | 适合优化 CUDA kernel |
| Nsight Graphics | 图形 API 调试(OpenGL, Vulkan, DirectX) | Win / Linux | 适合游戏渲染调试 |
| cuda-gdb | 命令行级 GPU 代码调试 | Linux | 类似 GDB,用于内核断点调试 |
| cuda-memcheck(Compute Sanitizer) | 内存错误检查 | Win / Linux | 检查越界、未初始化、数据竞争 |
| Visual Studio Nsight Integration | 集成式调试 | Windows | 在 VS 里直接调试 CUDA 代码 |
从表中描述可有如下概括:
-
性能总览(CPU/GPU协作分析) → Nsight Systems
-
单个内核性能优化 → Nsight Compute
-
找 bug(内存错误) → cuda-memcheck
-
断点调试 GPU 代码
-
Windows → Nsight Visual Studio Edition
-
Linux → cuda-gdb
-
2.2 Nsight Systems(系统级分析)
用途:
-
查看 CPU 和 GPU 的交互,找出性能瓶颈(比如 GPU 等待 CPU 数据)。
-
分析多个内核之间的执行顺序。
-
检测数据传输和计算是否重叠。
安装:
-
Windows 下随 CUDA Toolkit 自带。
-
可在
C:\Program Files\NVIDIA Corporation\Nsight Systems找到nsys-ui.exe。
使用步骤:
-
启动 Nsight Systems UI
-
选择 Profile → Local → 勾选
CUDA API、CUDA Kernel -
运行你的 CUDA 程序
-
查看时间线,分析 GPU 运行效率
命令行示例:
nsys profile --trace=cuda,nvtx,osrt -o profile_report ./my_cuda_program生成.qdrep文件后,可用Nsight Systems打开。可以看出在Nsight System工具中给出kernel函数helloFromGPU的调用信息:
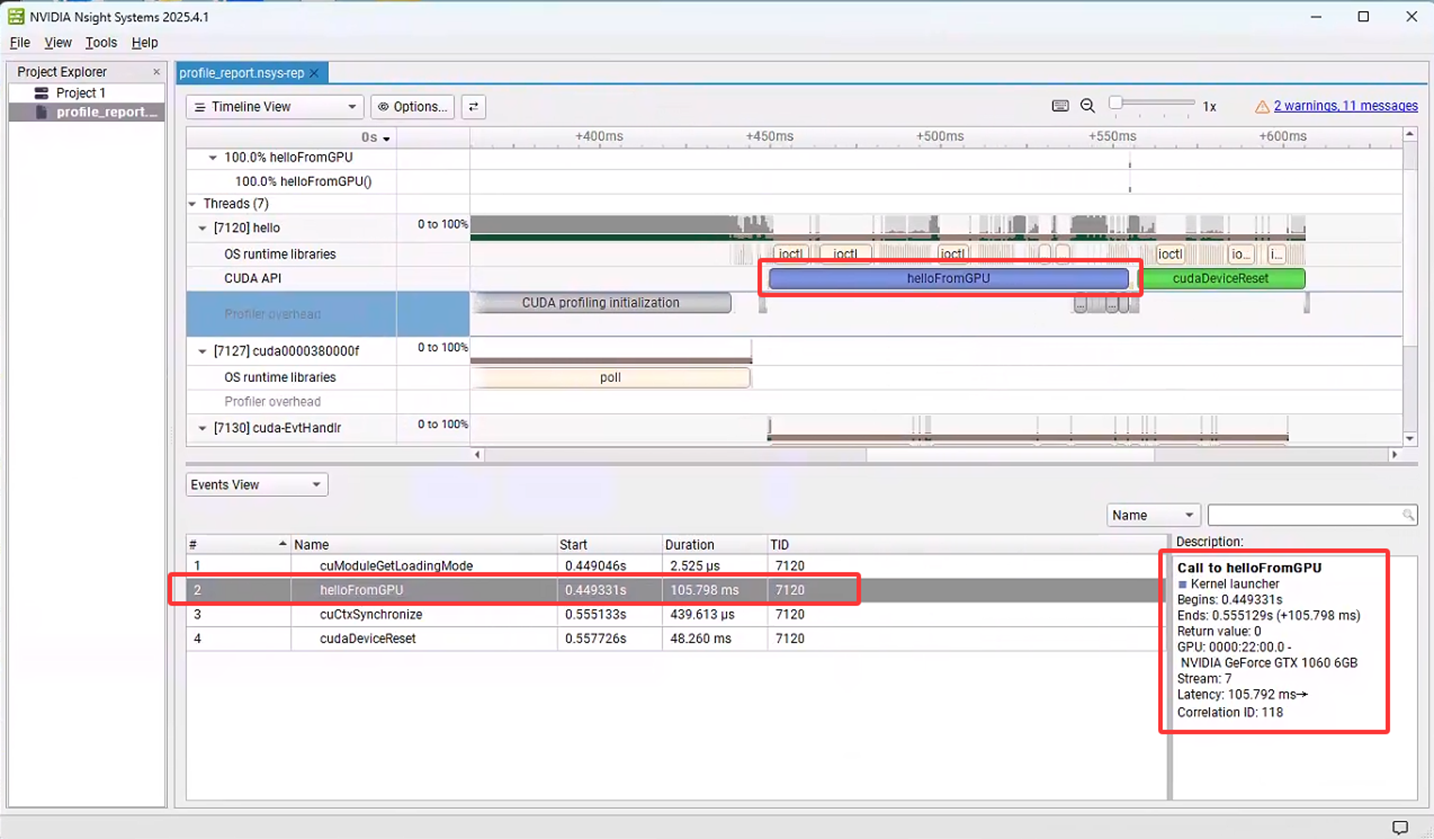
2.3 Nsight Compute(内核级分析)
用途:
-
分析单个 CUDA kernel 的性能。
-
查看 Warp 占用率 、SM 利用率 、内存带宽。
-
适合优化内核中的内存访问、分支效率。
安装:
-
Windows 下随 CUDA Toolkit 安装。
-
路径一般在
C:\Program Files\NVIDIA Corporation\Nsight Compute\ncu-ui.exe
使用步骤:
-
启动 Nsight Compute
-
在 "Launch" 里选择你的可执行程序
-
选择要分析的 kernel
-
查看报告(包括 Memory Throughput、Occupancy)
命令行示例:
ncu --set full ./helloLinux下运行解析结果如下:
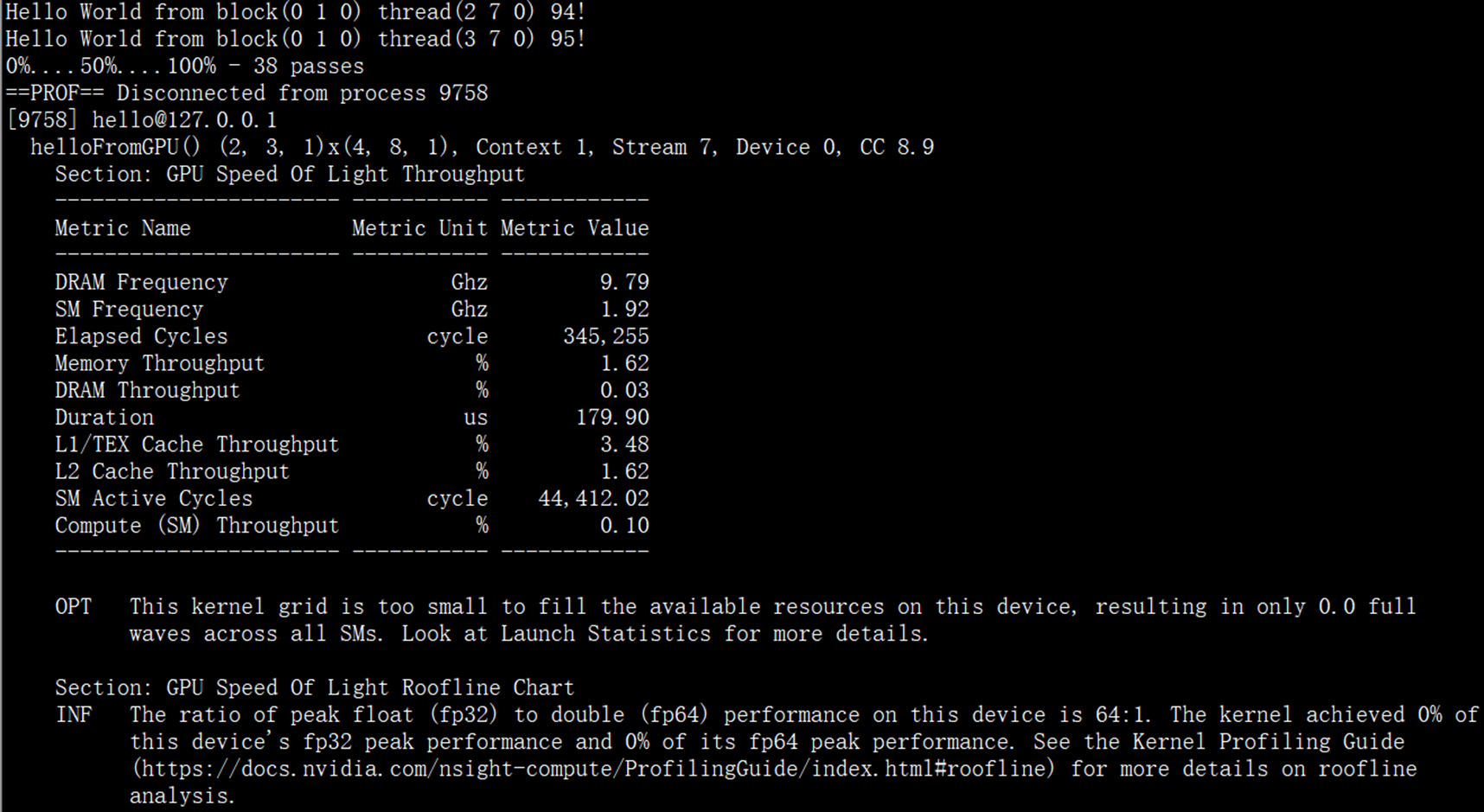
接下来,在windows下使用图形界面Nsight Compute进行分析,运行程序前对程序进行少许改动,再增加一个用于矩阵乘法运算的kernel调用,源码如下:


#include<stdio.h>
#include <cuda.h>
#include <cuda_profiler_api.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
using namespace std;
const int Row = 512; // 行数
const int Col = 512; // 列数
__global__
void matrix_mul_gpu(int* M, int* N, int* P, int width) // width代表列数
{
int i = threadIdx.x + blockDim.x * blockIdx.x; // 第i列的线程
int j = threadIdx.y + blockDim.y * blockIdx.y; // 第j行的线程
int sum = 0;
for (int k = 0; k < width; k++)
{
int a = M[j * width + k]; // 第j行的某一个值
int b = N[k * width + i]; // 第i列的某一个值
sum += a * b;
}
P[j * width + i] = sum;
}
void matrix_mul_cpu(int* M, int* N, int* P, int width)
{
for (int i = 0; i < width; i++)
for (int j = 0; j < width; j++)
{
int sum = 0;
for (int k = 0; k < width; k++)
{
int a = M[i * width + k];
int b = N[k * width + j];
sum += a * b;
}
P[i * width + j] = sum;
}
}
//定义gpu 核函数
__global__ void helloFromGPU()
{
int blockIndex = (blockIdx.z * gridDim.y + blockIdx.y) * gridDim.x + blockIdx.x;
int globalThreadIndex = blockIndex * blockDim.x * blockDim.y * blockDim.z +
(threadIdx.z * blockDim.y + threadIdx.y) * blockDim.x + threadIdx.x;
printf("Hello World from block(%d %d %d) thread(%d %d %d) %d!\n", blockIdx.x, blockIdx.y, blockIdx.z,
threadIdx.x, threadIdx.y, threadIdx.z, globalThreadIndex);
}
int main()
{
//hello from cpu
printf("Hello World CPU!\n");
dim3 number_of_blocks(2, 3, 1);
dim3 threads_per_block(4, 8, 1);
//调用核函数
helloFromGPU <<< number_of_blocks, threads_per_block >>> ();
cudaDeviceReset();
clock_t GPUstart, GPUend;
int* A = (int*)malloc(sizeof(int) * Row * Col);
int* B = (int*)malloc(sizeof(int) * Row * Col);
int* C = (int*)malloc(sizeof(int) * Row * Col);
//malloc device memory
int* d_dataA, * d_dataB, * d_dataC;
cudaMalloc((void**)&d_dataA, sizeof(int) * Row * Col);
cudaMalloc((void**)&d_dataB, sizeof(int) * Row * Col);
cudaMalloc((void**)&d_dataC, sizeof(int) * Row * Col);
//set value
for (int i = 0; i < Row * Col; i++) {
A[i] = 90;
B[i] = 10;
}
GPUstart = clock();
cudaMemcpy(d_dataA, A, sizeof(int) * Row * Col, cudaMemcpyHostToDevice);
cudaMemcpy(d_dataB, B, sizeof(int) * Row * Col, cudaMemcpyHostToDevice);
dim3 threadPerBlock(16, 16);
// (Col + threadPerBlock.x - 1)/threadPerBlock.x=Col/threadPerBlock.x+1,即多拿一个block来装不能整除的部分
dim3 blockNumber((Col + threadPerBlock.x - 1) / threadPerBlock.x, (Row + threadPerBlock.y - 1) / threadPerBlock.y);
printf("Block(%d,%d) Grid(%d,%d).\n", threadPerBlock.x, threadPerBlock.y, blockNumber.x, blockNumber.y);
// 每一个线程进行某行乘某列的计算,得到结果中的一个元素。也就是d_dataC中的每一个计算结果都和GPU中线程的布局<blockNumber, threadPerBlock >一致
matrix_mul_gpu << <blockNumber, threadPerBlock >> > (d_dataA, d_dataB, d_dataC, Col);
//拷贝计算数据-一级数据指针
cudaMemcpy(C, d_dataC, sizeof(int) * Row * Col, cudaMemcpyDeviceToHost);
//释放内存
free(A);
free(B);
free(C);
cudaFree(d_dataA);
cudaFree(d_dataB);
cudaFree(d_dataC);
GPUend = clock();
int GPUtime = GPUend - GPUstart;
printf("GPU运行时间:%d\n", GPUtime);
// CPU计算
clock_t CPUstart, CPUend;
int* A2 = (int*)malloc(sizeof(int) * Row * Col);
int* B2 = (int*)malloc(sizeof(int) * Row * Col);
int* C2 = (int*)malloc(sizeof(int) * Row * Col);
//set value
for (int i = 0; i < Row * Col; i++) {
A2[i] = 90;
B2[i] = 10;
}
CPUstart = clock();
matrix_mul_cpu(A2, B2, C2, Col);
CPUend = clock();
int CPUtime = CPUend - CPUstart;
printf("CPU运行时间:%d\n", CPUtime);
printf("加速比为:%lf\n", double(CPUtime) / GPUtime);
return 0;
}View Code
创建Nsight Compute工程,并指定可执行文件,以及分析结果文件:
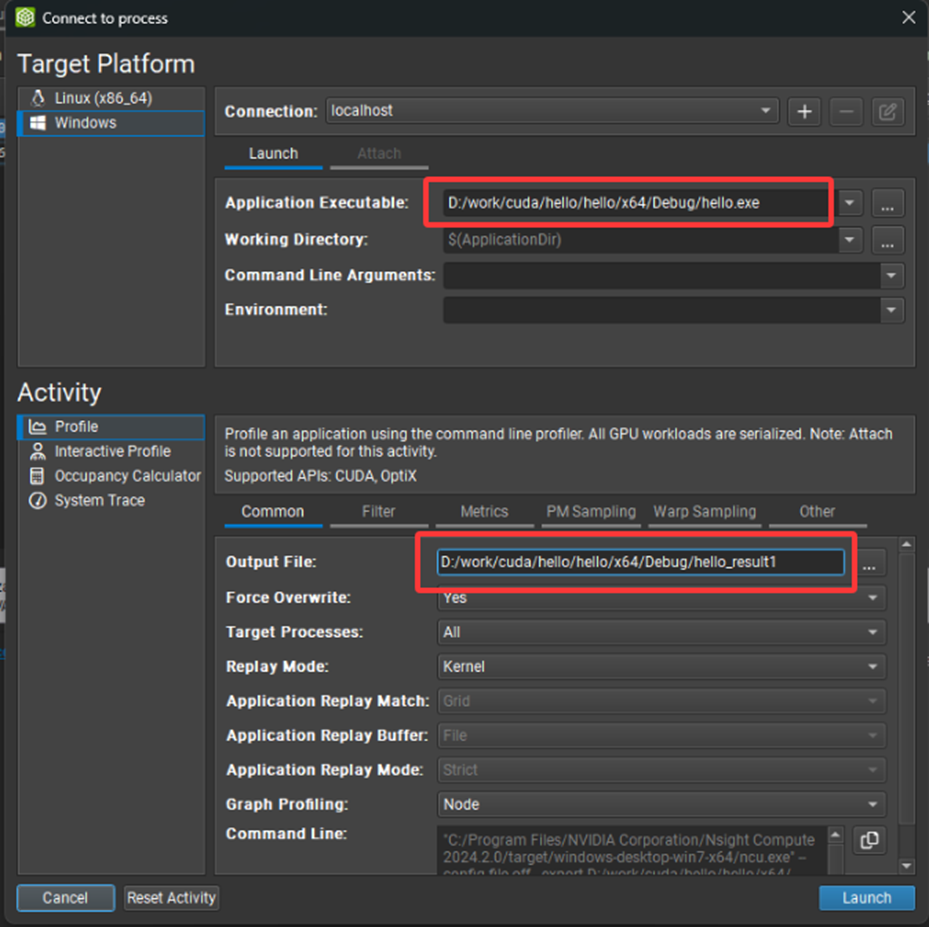
之后直接"Launch"程序,由于程序比较简单稍后工具便给出结果,在Summary页中给出了两个核函数的名称、运行时间、Grid Size及Block Size等主要信息:

在Details页给出了更为详细的信息不再显示,在Source页给出了源码与动态运行对应关系:
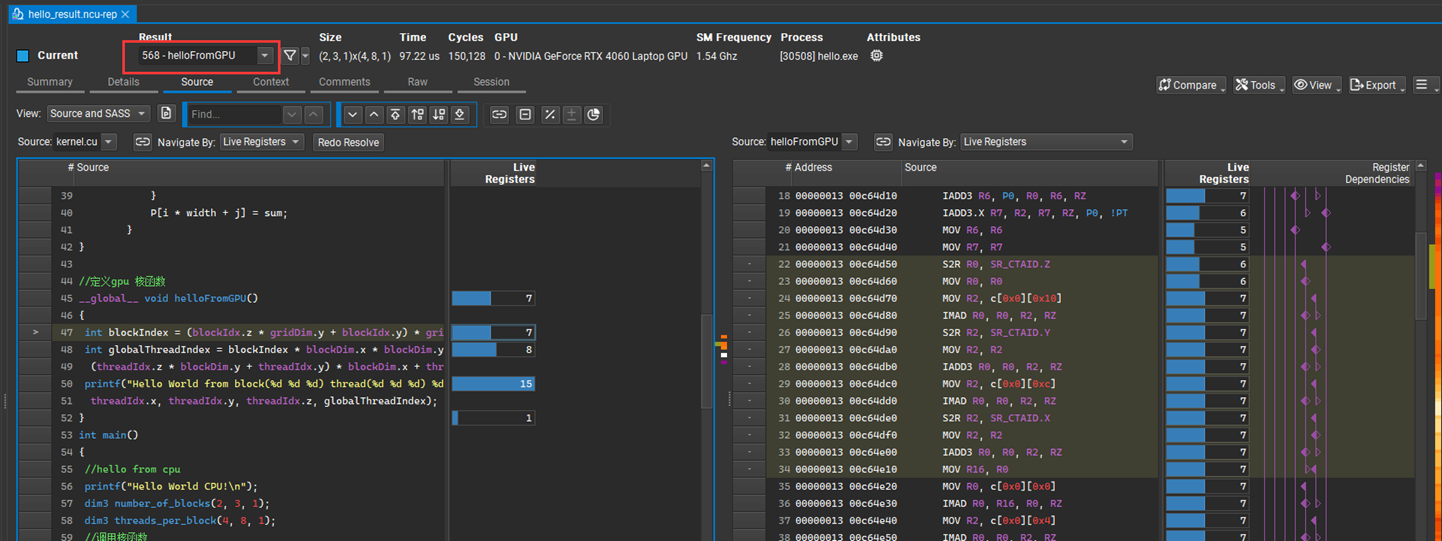
可以通过选择查看两个kernel函数各自的解析。
2.4 cuda-gdb(命令行断点调试)
用途:
-
设置断点到 CUDA kernel。
-
查看 GPU 线程变量值。
-
单步调试 GPU 代码。
限制:
-
仅 Linux 下可用(Windows 用 Nsight 代替)。
-
GPU 调试需要 调试模式编译:
nvcc -G -g hello.cu -o hellod示例(该示例调试调用的是未增加矩阵运算的原始代码):
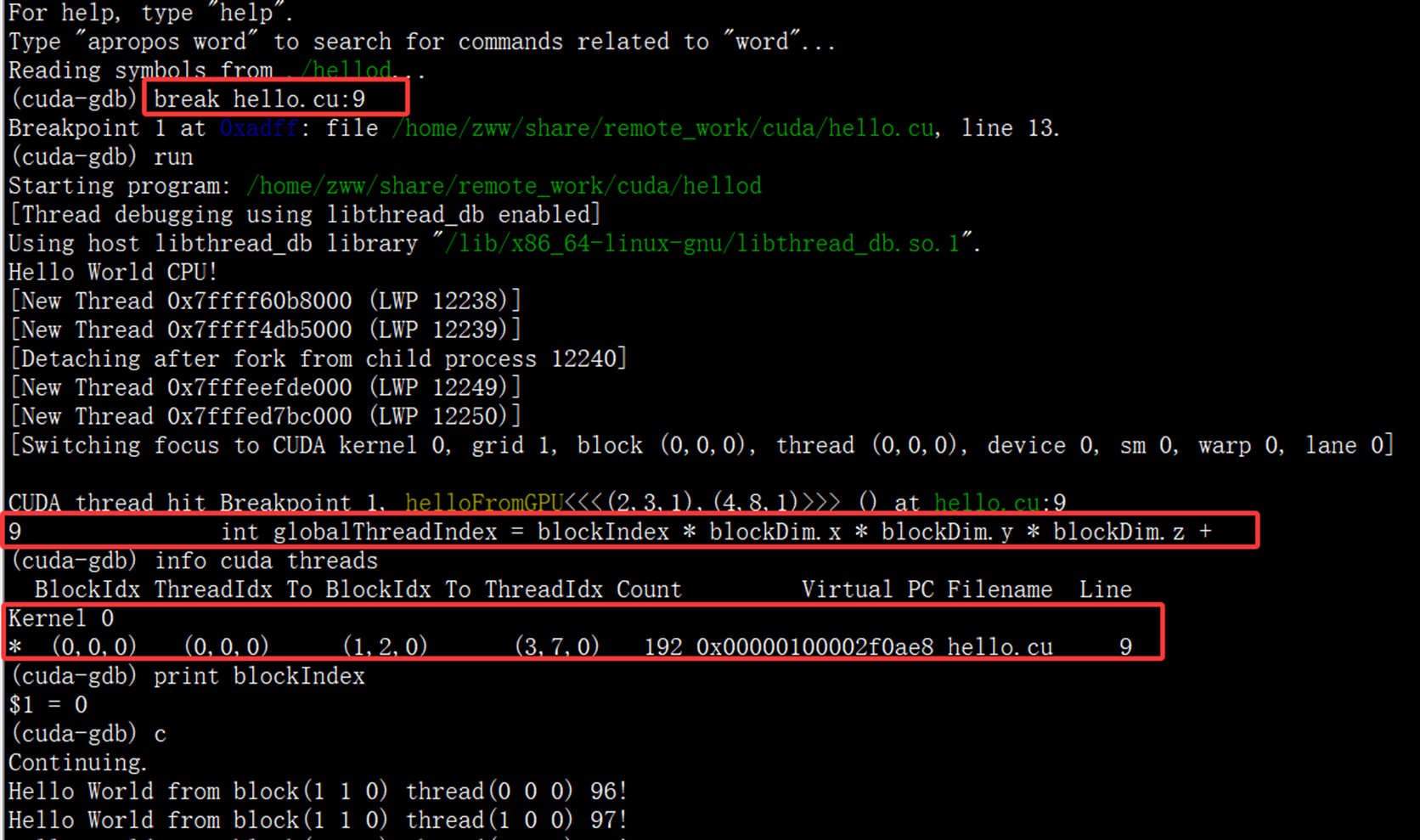
cuda-gdb ./hellod
(cuda-gdb) break hello.cu:9
(cuda-gdb) run
(cuda-gdb) info cuda threads
(cuda-gdb) print blockIndex下图给出了调试过程主要内容:
2.5 Visual Studio Nsight集成
用途:
-
Windows 下在 VS 里直接打断点调试 GPU 代码。
-
支持查看 GPU 线程局部变量、寄存器值。
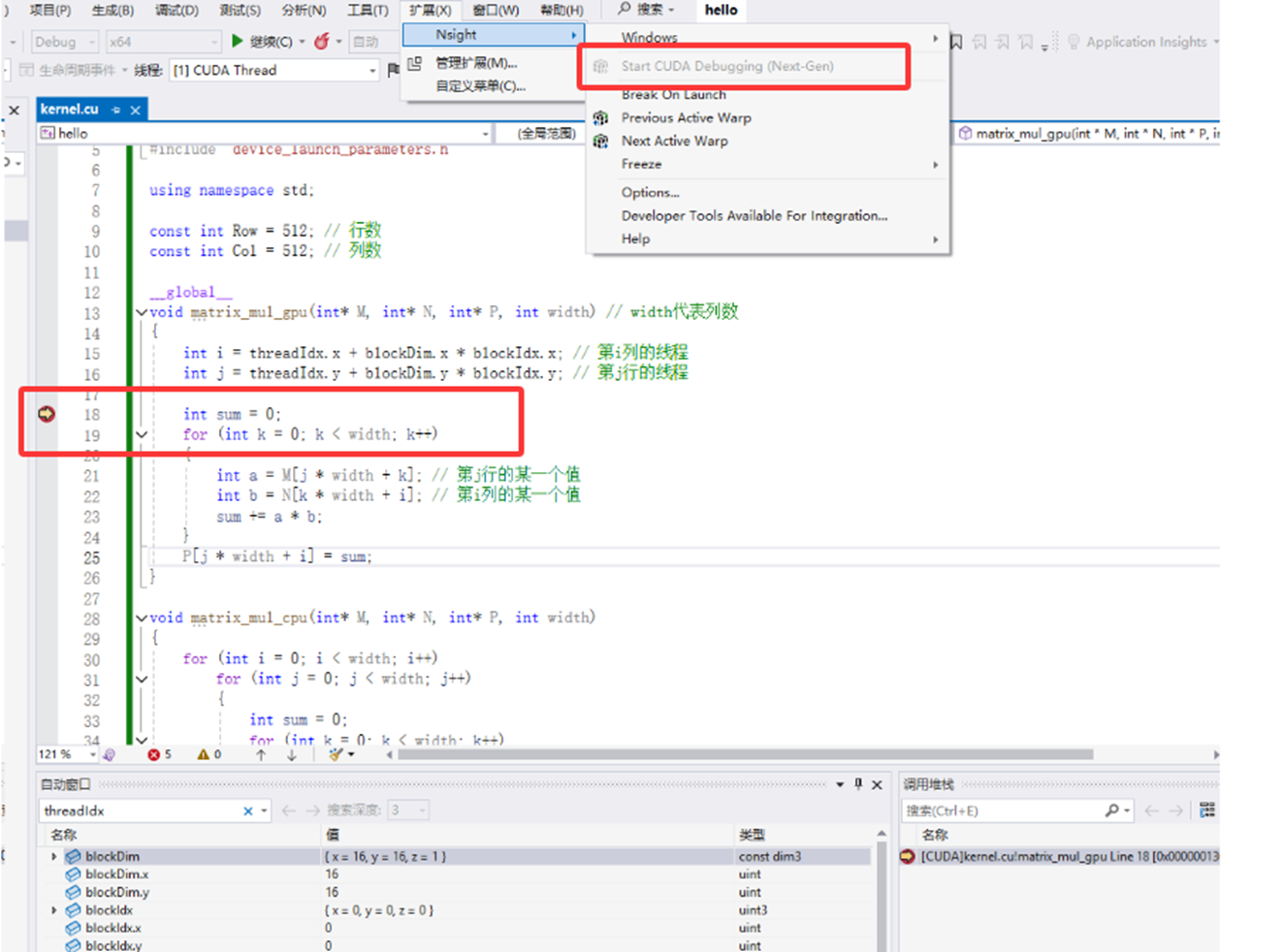
步骤:
-
安装 Nsight Visual Studio Edition(随 CUDA Toolkit 提供)。
-
在 VS 菜单"扩展"里选择Nsight → Start CUDA Debugging
-
在 CUDA 代码中打断点(__global__内也可以)
-
运行并调试
下图直接运行到了第2个核函数中的断点处,此时可方便查看相关局部变量的值:
2.6 cuda-memcheck(compute-sanitizer)
用途:
-
检查 GPU 内存错误(越界、未初始化)。
-
检测数据竞争(race condition)。
命令示例:
cuda-memcheck ./hello从CUDA 11.2版本开始,cuda-memcheck已被compute-sanitizer替代,这是NVIDIA官方推荐的新一代CUDA内存和线程错误检测工具。因此,在较新的 CUDA 工具包中,默认不再包含cuda-memcheck,而是以compute-sanitizer提供更强大的功能。compute-sanitizer完全兼容cuda-memcheck的功能,且支持更多新特性。使用方法与 cuda-memcheck 类似:
compute-sanitizer --tool memcheck ./hello
compute-sanitizer --tool racecheck ./hello由于程序比较简单没有内存及其他问题,运行后结果如下:

参考
https://www.cnblogs.com/upyun/p/17824106.html