- 2024.8
- tsinghua
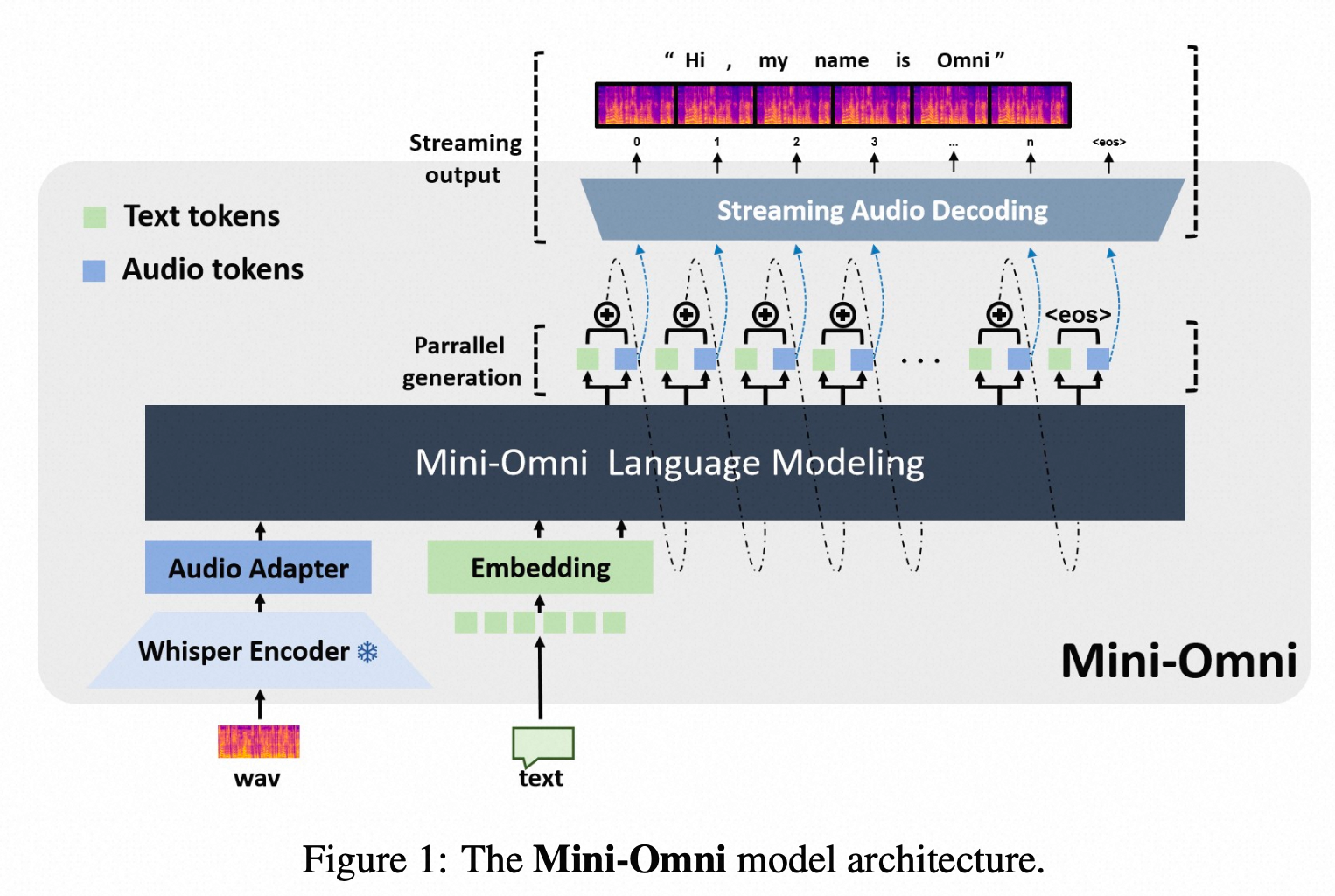
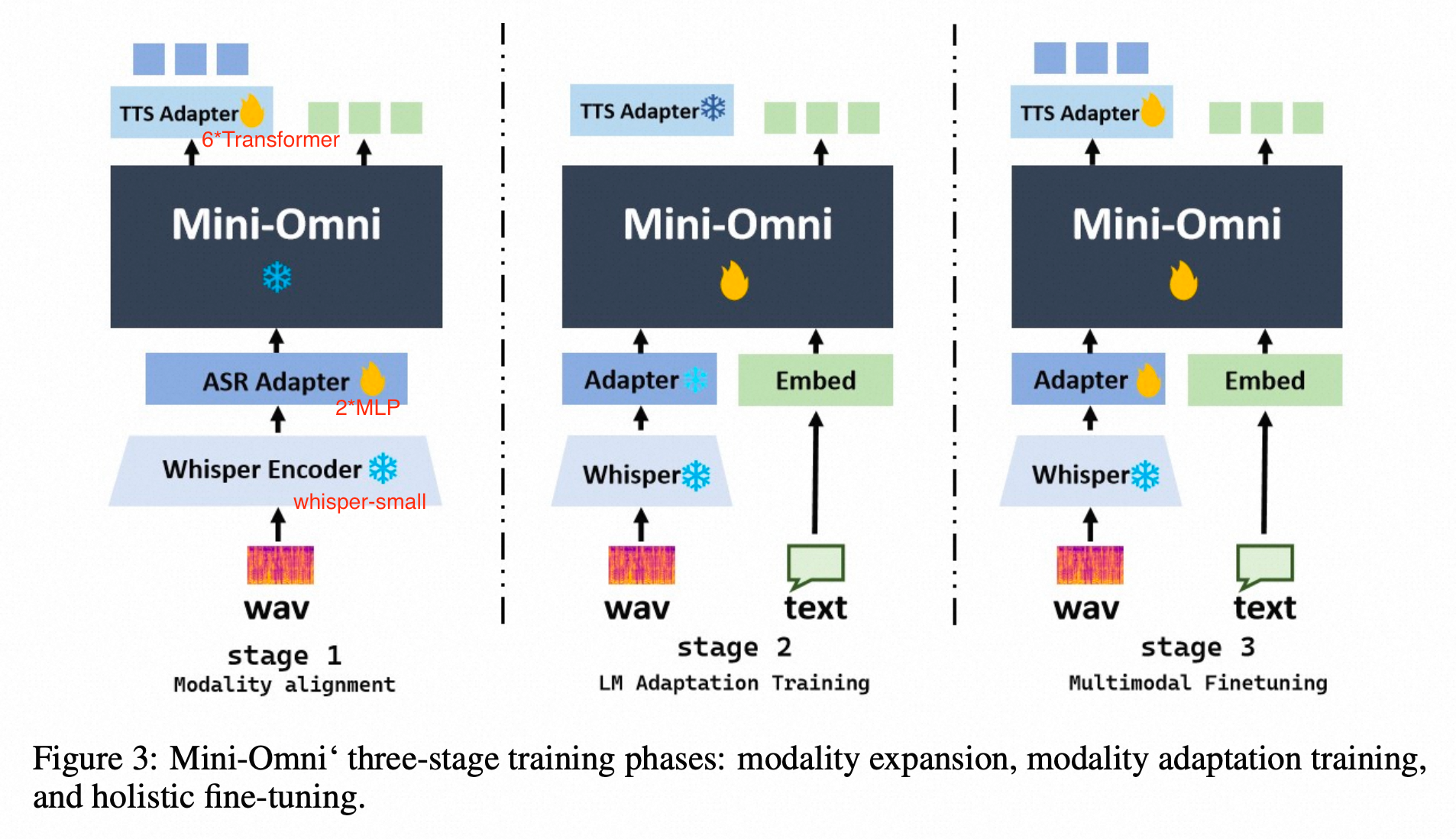
method
-
whisper encoder: whisper small
-
LLM
- Qwen0.5b init
- 预测方式:text + 7*audio token, parallel generation的方式预测,delay-step=1----先预测文本token,再预测SNAC 第一级码本,然后序列化的逐渐预测后续码本,也遵循了coarse-to-fine的预测;
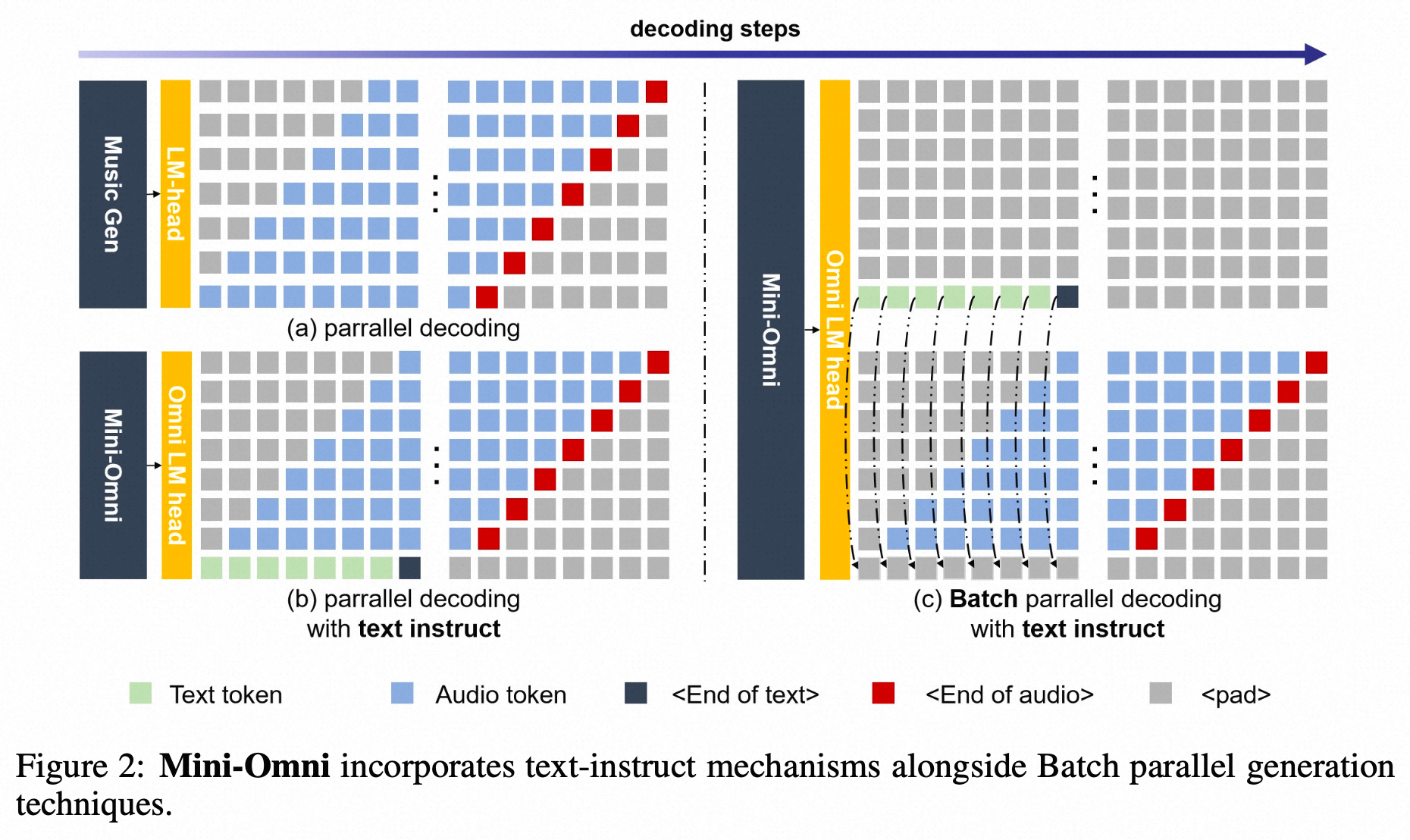
-
audio token:SNAC的码本,7级
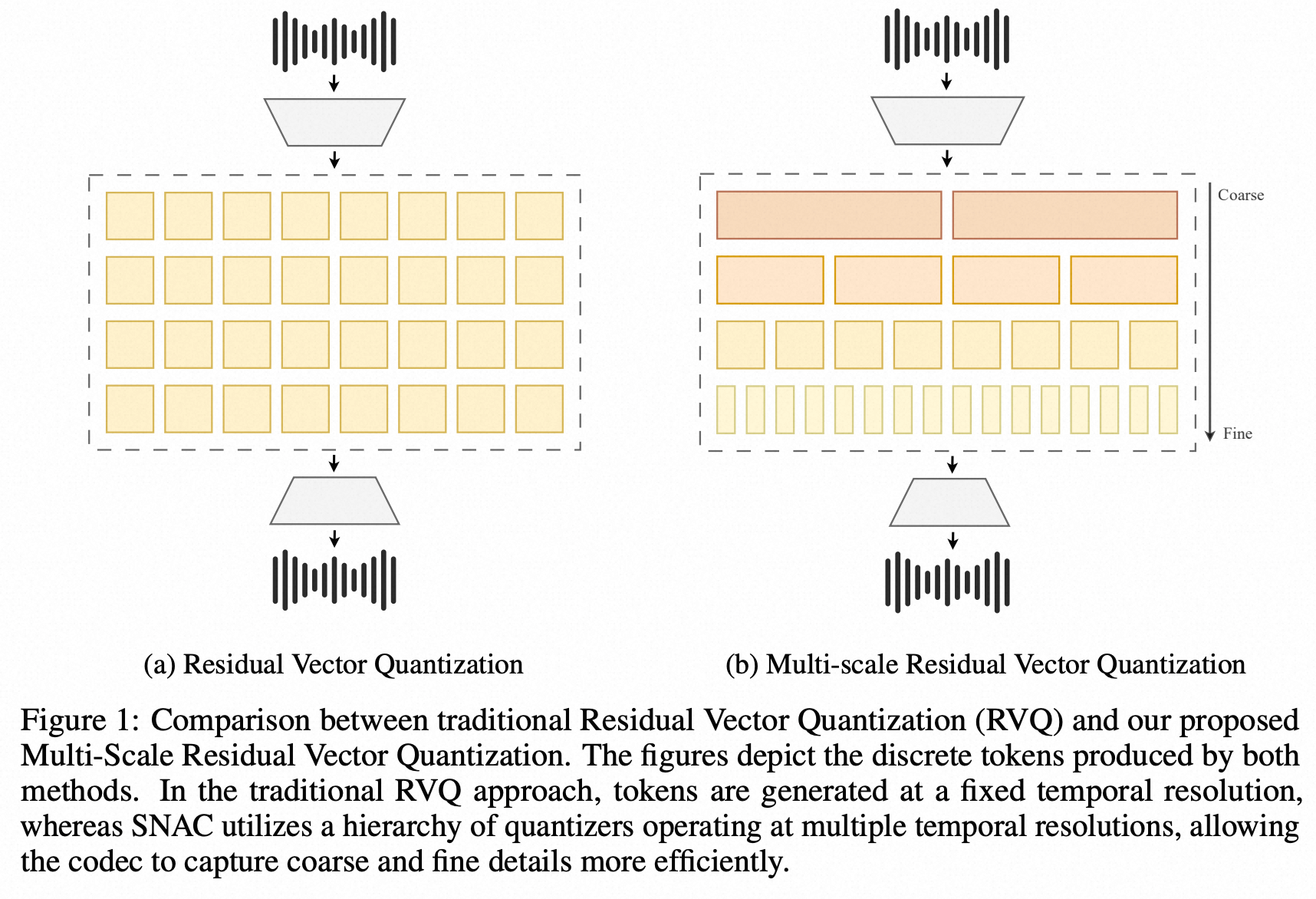
-
SNAC 的不同级别,码本的预测粒度不同;
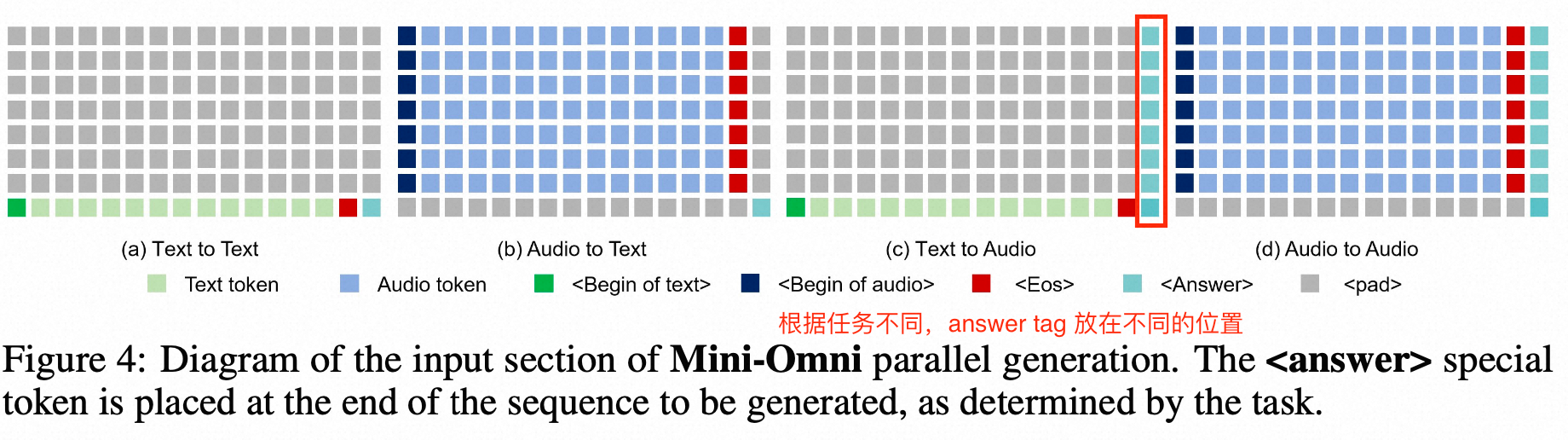
data
VoiceAssistant-400K 的数据集