在人工智能的竞技场上,模型的更新迭代早已不是新闻,但总有一些作品的诞生,不只是简单的数字增长,而是足以撼动整个领域根基的范式革命。今天,Meta扔下的这颗重磅炸弹------DINOv3,就是这样的存在。它不是又一个视觉模型,它更像是一个宣言:计算机视觉的玩法,从现在开始,彻底变了。
一位"自学成才"的艺术家
想象一下,一个艺术家在没有老师指导、没有看过任何标签的情况下,仅仅通过阅遍世间17亿幅画作,就自行领悟了光影、结构、情感和万物的本质。DINOv3就是这样一位"自学成才"的艺术家。
它摒弃了依赖海量人工标注的传统路径,一头扎进了自监督学习的汪洋大海。这片数据的海洋有多广阔?答案是17亿张图像,是其前辈DINOv2的12倍。而驱动这一切的,是一个拥有70亿参数的庞大"大脑",规模同样是前代的7倍。
这种蛮力式的学习方式,过去常常伴随着一个致命缺陷:模型学得越多,看得越细,特征反而变得模糊、退化,就像一位画家画得太久,反而失去了对整体的把握。而DINOv3的第一个神来之笔,就是名为"Gram锚定"的技术。它像一个记忆锚点,不断提醒模型"勿忘初心",确保在高分辨率的精雕细琢中,依然能保持对核心语义的清晰认知。
从"能看懂"到"能看透"
如果说过去的视觉模型是在"看懂"图片,那么DINOv3则是在"看透"世界。
它能自适应地处理从手机照片到卫星遥感图等各种尺寸的输入,最高可达惊人的4096x4096分辨率,而且在高分辨率下,其理解力丝毫不会打折。这种能力带来的结果是颠覆性的。
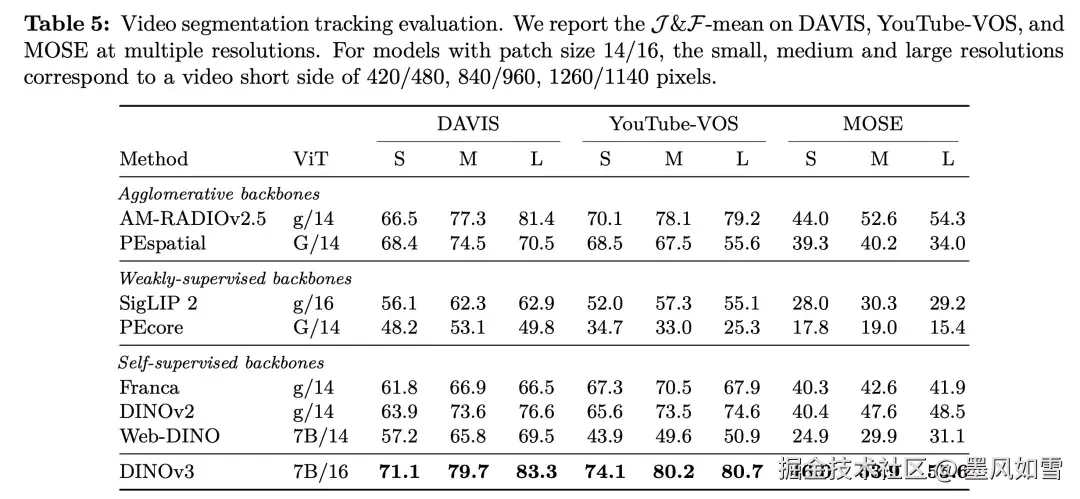
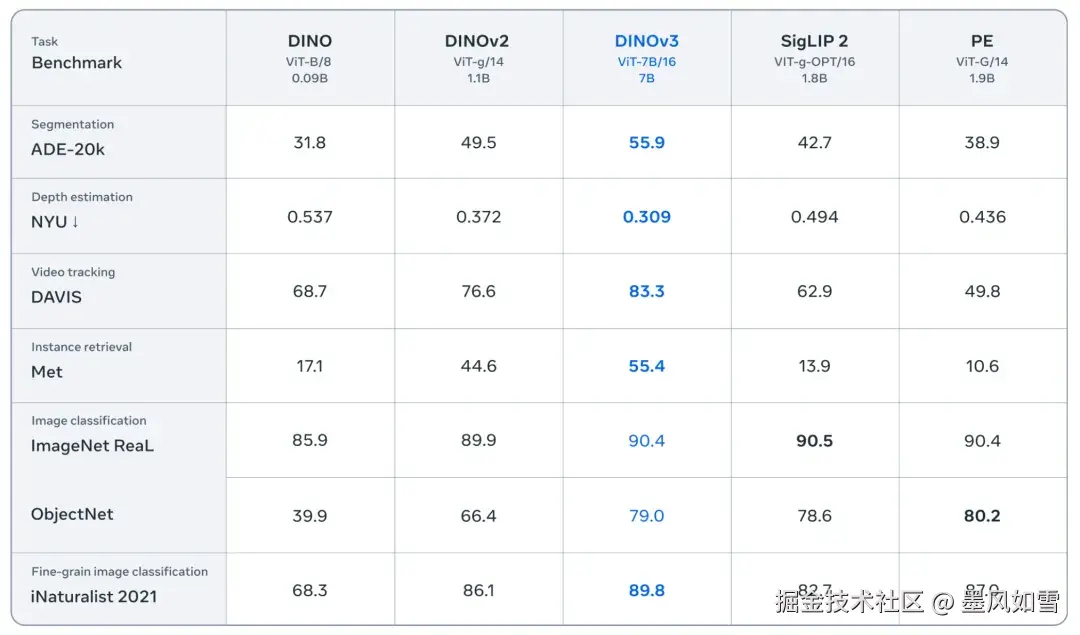
在语义分割任务中,它如同拥有了像素级的手术刀,在ADE20k和Cityscapes这些公认的"地狱难度"数据集上,将分割精度(mIoU)推向了55.9和81.1的新高峰,把一众前辈和对手远远甩在身后。在深度估计上,它对三维空间的感知力也变得异常敏锐,误差大幅降低,其表现甚至开始逼近那些专为此项任务设计的模型。
最令人惊叹的是,这一切成就,都是在"冻结主干"的前提下实现的。这意味着你不需要对这个70亿参数的庞然大物进行复杂的微调。只需把它当作一个通用的"视觉大脑",接上一个轻量级的适配器,它就能在你的特定任务上火力全开。这是一种前所未有的即插即用体验,一个模型,通吃六十多个视觉战场。
远征火星,俯瞰雨林
理论的强大终究要用现实来检验,而DINOv3的履历已经写上了星辰大海。
在美国宇航局(NASA)的火星探测计划中,它的技术血脉正帮助探测器更智能地理解那颗红色星球的陌生环境。在地球上,世界资源研究所(WRI)用它来分析卫星影像,监测肯尼亚的森林。过去,测量树冠高度的误差是4.1米,而DINOv3直接将其锐减至1.2米。这不仅是数字的提升,更意味着气候金融、环境保护的决策将变得空前精准和高效。
从自动驾驶的实时感知,到医疗影像的病灶识别,再到游戏开发中对复杂画面的解析,DINOv3正在证明,一个足够强大的视觉基础模型,可以成为驱动各行各业创新的通用引擎。
一个开放的巨人
Meta这次没有将这头巨兽圈养在自家的花园里。从70亿参数的完整模型,到为资源受限场景蒸馏出的轻量版本,再到所有的训练代码和评估工具,DINOv3以一个极其开放的姿态,向所有开发者张开了双臂。
它不仅仅是一个模型,更是一个生态的起点。它告诉我们,视觉AI的未来,不再是为每个任务去打造一把特制的锤子,而是拥有一个能够理解和重构视觉世界的"普罗米修斯",而现在,Meta已经将火种交到了我们手中。
DINOv3的出现,或许正是计算机视觉领域从"炼丹时代"迈向"工业时代"的真正拐点。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站