
Amundsen 是一个数据发现和元数据引擎,旨在提高数据分析师、数据科学家和工程师与数据交互时的生产力。目前,它通过索引数据资源(表格、仪表板、数据流等)并基于使用模式(例如,查询频率高的表格会优先于查询频率低的表格)提供页面排名式的搜索功能来实现这一目标。您可以将其视为数据版的 Google 搜索。该项目以挪威探险家罗尔德·阿蒙森 (Roald Amundsen) 的名字命名,他是第一个发现南极的人。
1.1 Amundsen简介
1.1.1 核心定位:开源数据发现平台
- 官方定义 : "Amundsen is a metadata driven application for improving the productivity of data analysts, data scientists and engineers when interacting with data."
(来源:Amundsen GitHub)
- 关键解析 :
- 元数据驱动:以元数据(数据描述、血缘、使用记录等)为核心构建功能。
- 提升数据生产力:解决数据从业者(分析师/科学家/工程师)的"数据发现难"问题。
- 关键解析 :
- 产品本质 :
- 非数据存储或处理引擎,而是 数据目录(Data Catalog) ------ 用于集中管理、索引和探索数据资产。
1.1.2 核心价值:数据民主化与协作
- 元数据管理 :
- 统一视图:聚合分散的元数据(表结构、血缘、所有权),形成可搜索的目录。
- 减少重复工作:避免用户手动维护电子表格或离线文档。
- 数据民主化 :
- 降低数据发现门槛:通过关键词搜索、过滤、排名和个性化推荐,让非技术用户快速定位数据。
- 协作闭环:支持用户添加描述、标签、所有权声明、常见查询片段(如GitHub的协作模式)。
1.1.3 起源与设计原则
- 诞生背景 (源自Lyft工程博客):
- Lyft为解决内部数据资产混乱问题于2019年开源,目前由 LF AI & Data Foundation 托管,仍保持 非商业化产品 治理模式。
- 设计原则 (官方架构文档):
- 简单优先:UI轻量易用(类Google搜索界面)。
- 可扩展性:微服务架构,支持通过 Databuilder 框架自定义元数据采集任务,支持 Elasticsearch/OpenSearch、PostgreSQL/MySQL、AWS Neptune、Neo4j 作为后端存储。
- 社区驱动:由用户贡献迭代,核心维护者来自 Airbnb、Apple、Dremio、Stripe 等组织。
1.1.4 与其他工具对比
| 工具 | 核心差异点 |
|---|---|
| Atlas | 与 Hadoop 生态深度耦合,偏重安全与治理;Amundsen 轻量且 UI 友好。 |
| DataHub | 原生支持流式元数据(Kafka)、GraphQL API;Amundsen 更早专注"搜索体验优化"。 |
| OpenMetadata | 同属 Apache 开源目录,侧重元数据事件流与治理工作流;Amundsen 专注于搜索与协作体验。 |
1.2 学习目标与范围
1.2.1 适用人群与学习路径
目标读者
- 数据从业者(分析师/工程师/科学家)
- 希望零成本快速体验开源数据目录的初学者
- 需理解元数据管理核心概念的技术爱好者
学习路径设计
本地环境搭建 核心概念解析 基础功能实操 自定义数据源实践 端到端应用
- 渐进式实践:从 Docker Compose 环境启动 → 元数据注入 → 搜索/浏览 → 血缘协作
- 最小化技术栈:仅需基础 Python/Docker Desktop/Docker Compose 知识
1.2.2 您将掌握的技能
| 能力维度 | 具体成果 |
|---|---|
| 环境管理 | 在个人电脑运行 Amundsen 全套服务(Frontend+Metadata+Search+Neo4j) |
| 概念理解 | 解析元数据模型/搜索排名原理/血缘协作逻辑 |
| 核心操作 | 完成数据摄取 → 关键词搜索 → 表详情解读 → 书签添加的全流程 |
| 扩展实践 | 将本地 SQLite 数据库注入为可发现的数据资产 |
1.2.3 内容边界说明
为保障学习效率,本指南:
- ✅ 专注:个人本地环境(非生产部署)
- ✅ 简化 :使用官方默认配置
docker-amundsen.yml(非企业级优化) - ✅ 开放 :所有代码/配置源自 Amundsen GitHub
- ❌ 不包含:云服务集成、大规模集群运维、商业定制化案例
1.3 官方资源概览
1.3.1 核心学习资源
GitHub 主仓库
- 地址:https://github.com/amundsen-io/amundsen
- 内容:
- 源代码(Frontend / Metadata / Search / Databuilder)
- Docker 配置(docker-compose.yml)
官方文档站点
- 地址:https://www.amundsen.io/amundsen/
- 关键文档:
- 安装指南(Installation)
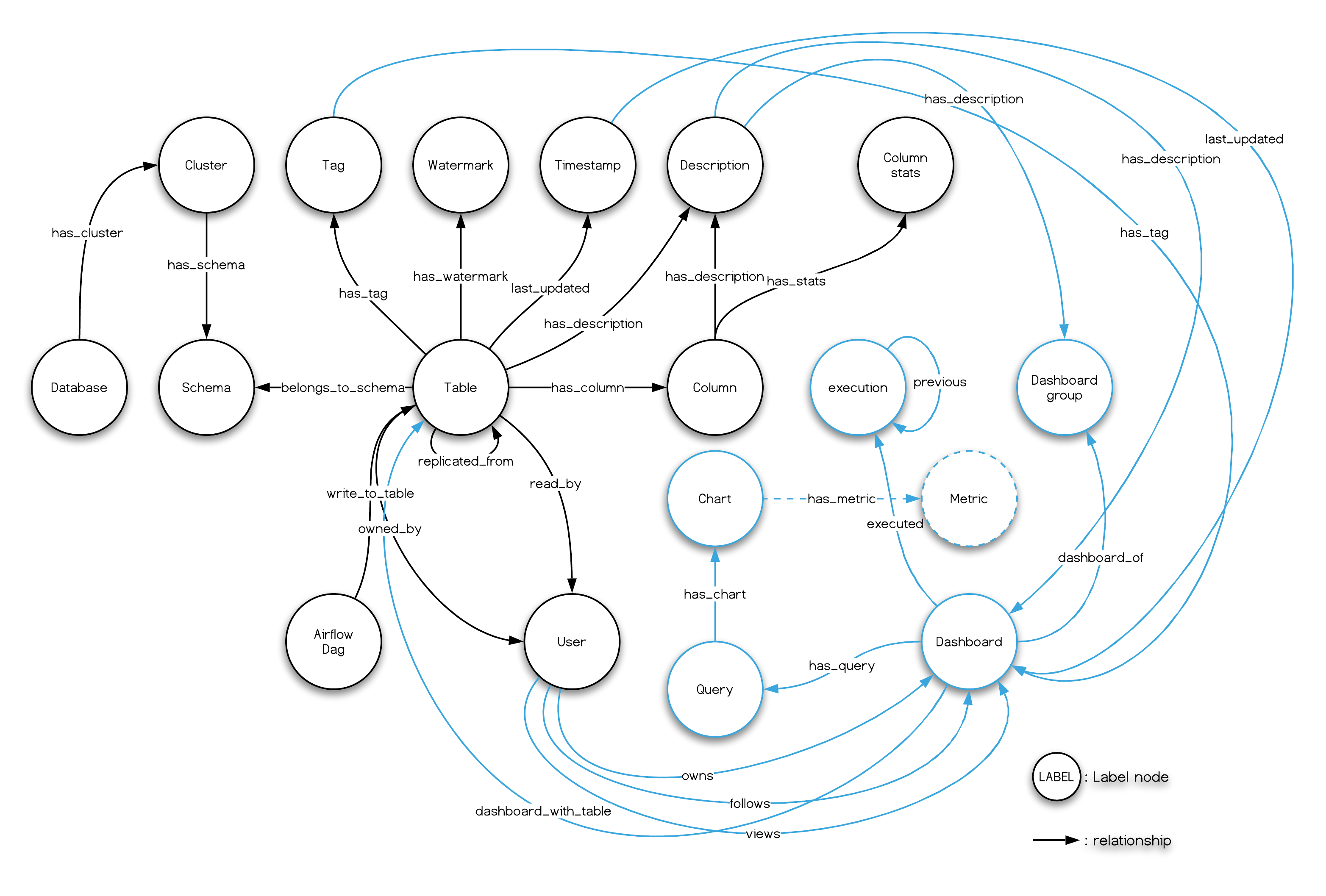
- 架构说明(Architecture)
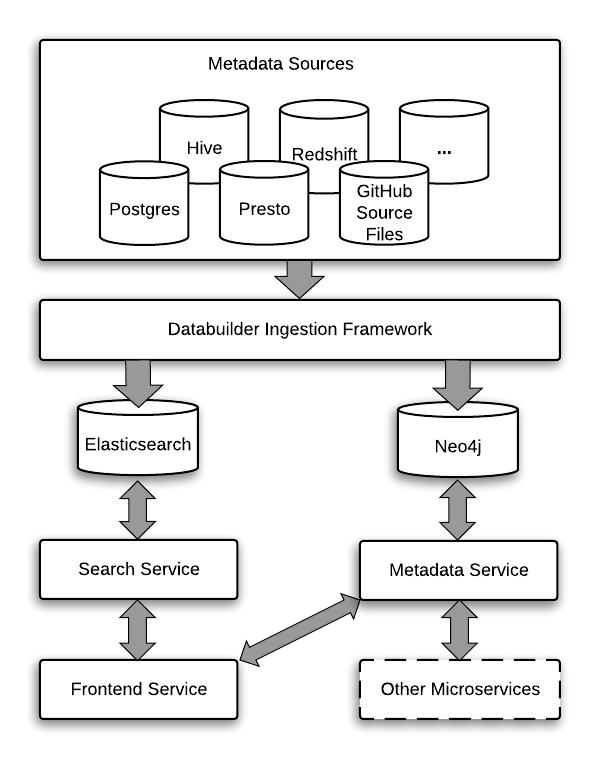
- Databuilder 用法(Data Ingestion)
- 安装指南(Installation)
社区支持渠道
- Slack 工作组:amundsen-workspace
- 问题讨论区:GitHub Issues
1.3.2 学习前提知识
基础工具能力
- Docker 与 Docker Compose:
- 容器创建/启停命令(
docker run,docker-compose up,docker-compose down) - 日志查看(
docker logs)
- 容器创建/启停命令(
- Python 基础:
- 理解 Python 脚本结构(如 Databuilder 示例)
- 包安装(
pip install)
核心概念认知
- 元数据基础:表(Table)、列(Column)、血缘(Lineage)定义
- 搜索引擎基础:Elasticsearch 索引概念(非运维级)
A. 术语表
元数据 (Metadata)
定义 :描述数据的数据(data about data)
Amundsen上下文:
- 表结构(名称/列/类型/列描述)
- 数据血缘关系
- 表使用统计信息(查询次数/活跃用户)
- 数据质量评分(SLA、Freshness、Completeness)
"Metadata is information about the data assets"
------ Amundsen Architecture Doc
元数据摄取 (Metadata Ingestion)
定义 :从数据源提取元数据并加载到目录系统的过程
技术流程:
提取 转换 加载 索引 数据源 Databuilder 清洗/增强 Neo4j Elasticsearch
实现方式:
- 批处理作业(Airflow DAG 定时执行)
- 流式摄取(Kafka Connect / Flink CDC)
- 支持 CSV / SQL / RDBMS / Hive / Glue / dbt / Iceberg 等源
血缘追踪 (Lineage Tracking)
定义 :记录数据从源头到终端的完整流动路径
Amundsen实现:
shell
# Neo4j 血缘关系模型
(:Table)-[:UPSTREAM]->(:Table)
(:Table)-[:COLUMN_UPSTREAM]->(:Column)
(:Dashboard)-[:DASHBOARD_UPSTREAM]->(:Table)核心价值:
- 影响分析(上游变更影响范围)
- 故障溯源(数据异常定位)
- 合规审计(数据来源证明)
- 成本归因(下游资源消耗追踪)
数据目录 (Data Catalog)
定义 :集中化管理企业数据资产的元数据存储库
核心能力:
- 数据发现(全文搜索 / 过滤器 / 推荐)
- 元数据管理(描述 / 标签 / 所有权 / 生命周期)
- 协作功能(书签 / 评论 / 通知 / 审批)
- 权限控制(表级 / 列级 / 行级)
"A metadata driven data discovery and catalog platform"
------ Amundsen Homepage
数据民主化 (Data Democratization)
定义 :使非技术人员能够自主发现和使用数据
实现机制:
- 类 Google 搜索界面(智能提示 / 分面搜索)
- 业务友好的元数据描述(术语表集成)
- 可视化血缘关系图(列级血缘 / 分区血缘)
- 数据预览(采样 / 统计摘要)
- 自然语言查询(与 LLM 集成)
效果衡量:
- 数据团队查询需求下降
- 业务用户自助分析比例上升
- 数据资产利用率提升
BM25 排序 (BM25 Ranking)
定义 :基于 BM25 概率模型的搜索结果评分算法
公式:
score ( D , Q ) = ∑ i = 1 n IDF ( q i ) ⋅ f ( q i , D ) ( k 1 + 1 ) f ( q i , D ) + k 1 ( 1 − b + b ⋅ ∣ D ∣ avgdl ) \text{score}(D,Q)=\sum_{i=1}^{n}\text{IDF}(q_i)\cdot\frac{f(q_i,D)\,(k_1+1)}{f(q_i,D)+k_1\left(1-b+b\cdot\dfrac{|D|}{\text{avgdl}}\right)} score(D,Q)=i=1∑nIDF(qi)⋅f(qi,D)+k1(1−b+b⋅avgdl∣D∣)f(qi,D)(k1+1)
其中
- IDF ( q i ) = ln ( N − n ( q i ) + 0.5 n ( q i ) + 0.5 ) \text{IDF}(q_i)=\ln\!\left(\dfrac{N-n(q_i)+0.5}{n(q_i)+0.5}\right) IDF(qi)=ln(n(qi)+0.5N−n(qi)+0.5)
- f ( q i , D ) f(q_i,D) f(qi,D):词项 q i q_i qi 在文档 D D D 中的词频
- ∣ D ∣ |D| ∣D∣:文档 D D D 的长度(词项总数)
- avgdl \text{avgdl} avgdl:整个索引的平均文档长度
- k 1 = 1.2 k_1=1.2 k1=1.2、 b = 0.75 b=0.75 b=0.75 为 Elasticsearch/OpenSearch 的默认值 。
Amundsen应用:
- 检索引擎:Elasticsearch / OpenSearch 默认 BM25
- 字段权重:表名(10×) > 描述(5×) > 列名(1×)
- 业务因子:黄金表 +15% 权重、最近更新 +10% 权重
可扩展架构 (Extensible Architecture)
定义 :通过插件化设计支持功能扩展
Amundsen实现点:
python
# 自定义提取器示例
from amundsen_common.models.table import TableMetadata
from databuilder.extractor.base_extractor import Extractor
class CustomExtractor(Extractor):
def extract(self) -> TableMetadata:
# 实现特定逻辑
return table_metadata扩展方向:
- 新数据源支持(Flink / Trino / Snowflake)
- 存储后端替换(PostgreSQL / Amazon Neptune)
- 分析引擎集成(Superset / Mode / Tableau)
- 身份认证插件(Okta / Auth0 / Azure AD)
元数据模型 (Metadata Model)
定义 :描述元数据实体及关系的抽象结构
Amundsen核心实体:
Table Column User Tag Badge Watermark Dashboard DashboardChart contains owns upstream tagged_by has_badge has_watermark contains references
设计原则:
- 全局唯一键标识资源(格式:database://cluster.schema/table)
- 轻量化关系(无属性边,属性存节点)
- Schema Registry 保证向后兼容
协作式元数据 (Collaborative Metadata)
定义 :通过用户协作生成的元数据
典型形式:
- 表/列描述(Markdown 支持 / 富文本)
- 数据质量标记(SLA、异常、弃用)
- 使用建议注释(查询示例 / 最佳实践)
- 业务术语(与 DataHub Business Glossary 对齐)
Amundsen实现:
- 类 Wiki 的编辑系统(版本历史 / 差异对比)
- 变更通知(Slack / Teams / Email)
- 审批工作流(Owner 审核 / Steward 审批)
风险提示与免责声明
本文内容基于公开信息研究整理,不构成任何形式的投资建议。历史表现不应作为未来收益保证,市场存在不可预见的波动风险。投资者需结合自身财务状况及风险承受能力独立决策,并自行承担交易结果。作者及发布方不对任何依据本文操作导致的损失承担法律责任。市场有风险,投资须谨慎。