简介
Elasticsearch 是一个开源的分布式搜索和分析引擎,基于 Apache Lucene 构建,能够高效地处理大规模数据的近实时搜索、分析和可视化。以下是其主要应用场景。
全文搜索(Full-Text Search)
搜索是Elasticsearch强项,支持多种语言的分词,包含中英文、数字和特殊符号。主要应用在电商平台商品搜索、企业知识库、垂直领域搜索引擎。
大数据实时分析
Elasticsearch 在大数据处理方面具有强大的能力,,本身提供了丰富的数据处理和分析功能,比如聚合、转换、上卷等,能够对数据进行分组、统计和分析。
日志管理与分析(Log Analytics)
日志和事件数据分析组织使用 Elasticsearch 来聚合、监控和分析来自各种来源的日志和事件数据。它是 ELK 堆栈(Elasticsearch、Logstash、Kibana)的关键组件,用于管理系统和应用程序日志以识别问题和监控系统运行状况。
数据库查询加速
随着数据库数据增长,数据库的查询性能急剧下降。尤其是多条件查询的时候,此时就需要借助 ElasticSearch 强大的海量数据查询、复杂条件组合查询。过程分为三步,一:数据库写入数据库时,同步数据到Elasticsearch;2.在Elasticsearch执行条件查询;3.回到数据库补充数据明细。
当然,es还有很有其他的功能,比如向量数据库、地理空间引擎。Elasticsearch 的核心价值在于 快速搜索 和 实时分析,特别适合日志、文本、指标、地理空间等数据的处理。结合 Kibana 可实现强大的可视化,而完整的 ELK 生态能覆盖从数据采集到展示的全流程。
核心逻辑概念
文档(Document)
定义:
- • Elasticsearch中的最小数据单元,采用JSON格式表示
- • 相当于关系型数据库中的一行记录
关键特性:
- • 每个文档必须有唯一ID(
_id字段) - • 包含原始JSON数据(存储在
_source字段中) - • 文档是不可变的,"更新"操作实际上是替换整个文档
- • 文档会被自动索引,使其可被搜索
示例:
json
{
"_id": "101",
"title": "Elasticsearch权威指南",
"author": "张三",
"publish_date": "2023-05-20",
"rating": 4.5,
"tags": ["搜索", "数据库", "NoSQL"]
}类型(Type) (7.x版本后已弃用)
历史定义:
- • 在6.x及更早版本中,类型用于区分同一索引中的不同文档结构
- • 类似于关系型数据库中"表"的概念
版本演进:
- • 5.x及之前:一个索引可包含多个类型
- • 6.x:开始限制一个索引只能有一个类型
- • 7.x:完全移除类型概念,统一使用
_doc作为固定类型名 - • 8.x:彻底删除类型相关API
当前状态:
- • 现在所有文档都使用伪类型
_doc - • 不同结构的文档应放入不同索引
索引(Index)
定义:
- • 文档的集合,类似于关系型数据库中的"数据库"概念
- • Elasticsearch中数据组织和管理的基本单位
核心特性:
- • 包含具有相似特征的文档集合
- • 每个索引有自己的映射定义和设置
- • 名称必须小写
- • 支持分布式存储(通过分片机制)
重要组件:
- • 分片(Shards) :索引的水平分割单元,支持分布式存储和并行处理
- • 副本(Replicas) :分片的完整拷贝,提供高可用性和读取吞吐量
映射(Mapping)
定义:
- • 定义文档及其包含字段的存储和索引方式
- • 相当于关系型数据库的"表结构"或"模式(Schema)"
核心功能:
- • 定义每个字段的数据类型(text/keyword/date等)
- • 控制字段是否被索引及如何被索引
- • 指定文本分析器(analyzer)和搜索行为
- • 设置字段的格式化规则(如日期格式)
映射类型:
- • 动态映射:自动检测和添加字段
- • 显式映射:手动预定义字段结构
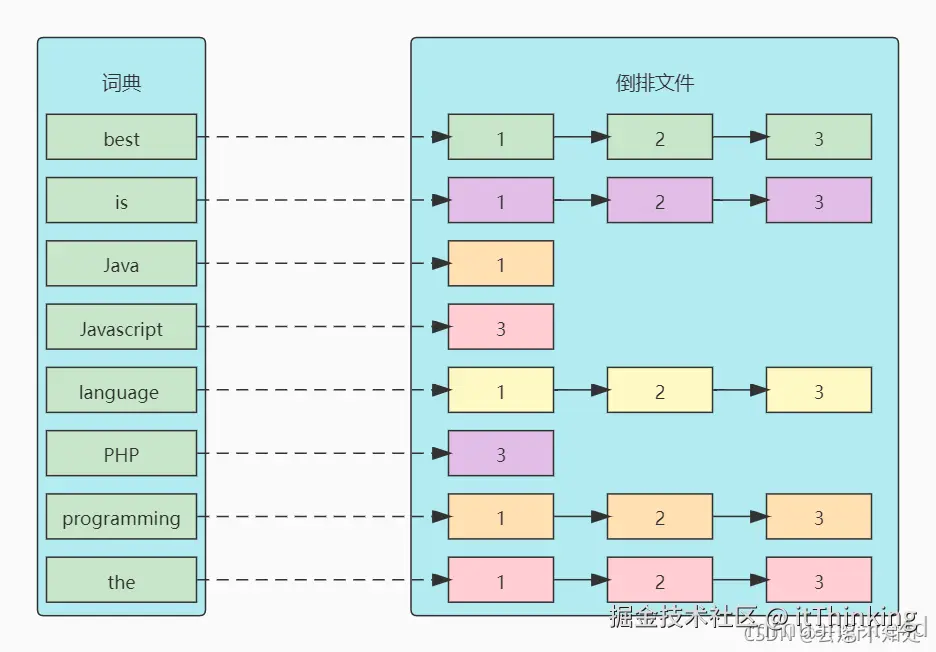
倒排索引(Inverted Index)
ElasticSearch这么快的核心是它独特的数据结构:倒排索引。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。
csharp
Doc 1:Java is the best programming language
Doc 2:PHP is the best programming language
Doc 3:Javascript is the best programming language为了创建索引,ES引擎通过分词器将每个文档的内容拆成单独的词(称之为词条,或term),再将这些词条创建成不含重复词条的排序列表,然后列出每个词条出现在哪个文档,结果如下:
Elasticsearch与关系数据库概念对比
| Elasticsearch | MySQL | 说明 |
|---|---|---|
| 索引(Index) | Database | 索引(index),就是文档的集合,类似数据库 |
| 类型(Type) | Table | 已废弃 |
| 文档(Docment) | Row | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| 字段(Field) | Column | 字段(Field),就是JSON文档中的字段,类似数据库中的列(CoLumn) |
| 映射(Mapping) | Schema | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| DSL | SQL | DSL是elasticseasrch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
Elasticsearch集群架构
Elasticsearch 集群 是由一个或多个节点(Node)组成的逻辑单元,共同存储数据并提供搜索和分析能力。每个集群有一个 唯一名称(cluster.name) ,默认是Elasticsearch,节点必须配置相同的 cluster.name 才能加入同一个集群。
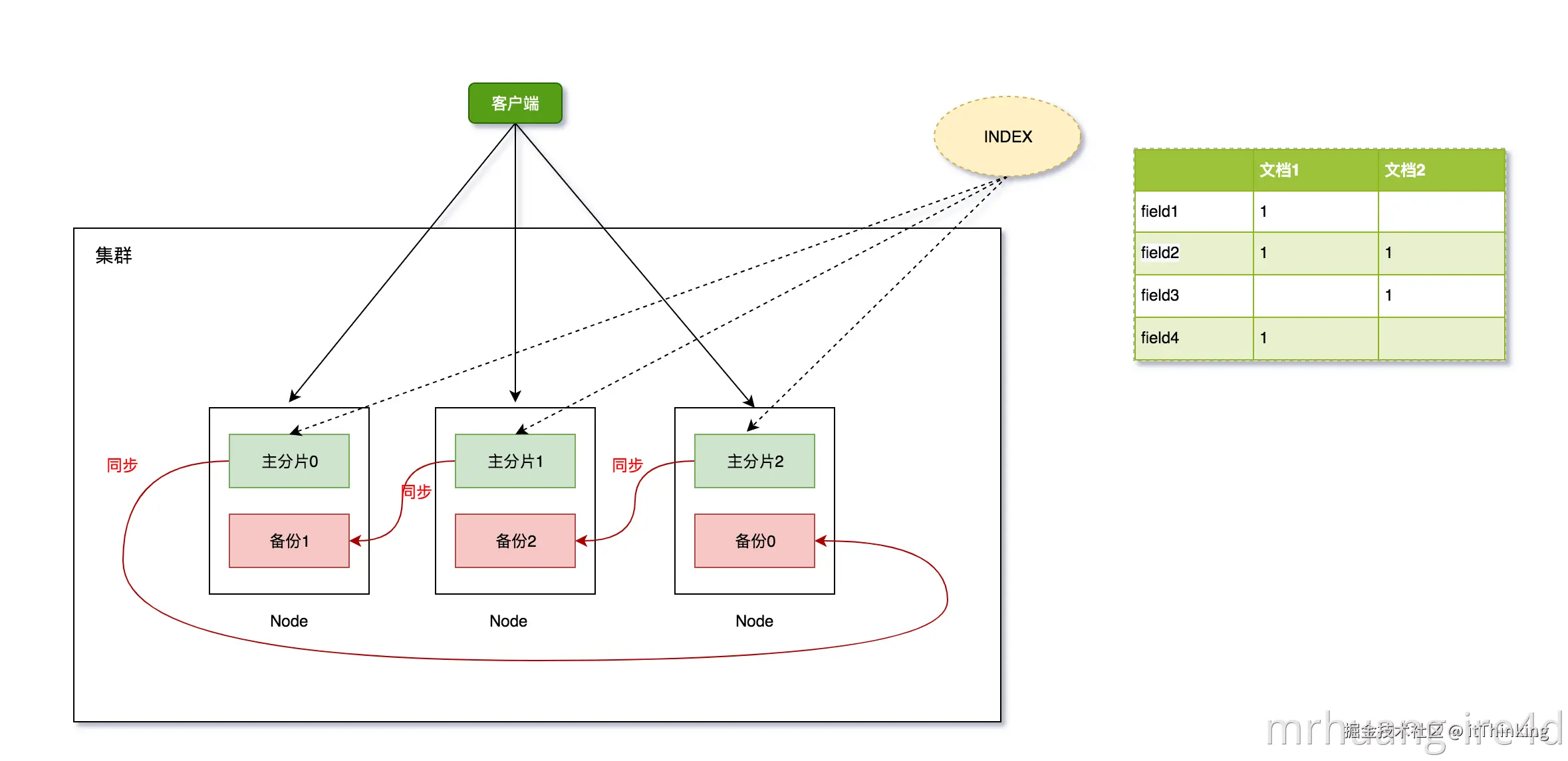
节点(Node)
一个节点就是 一个运行中的 Elasticsearch 实例 。你可以把它想象成一台服务器(物理机或虚拟机)上运行的一个 Elasticsearch 进程。节点通过node.name来设置节点名称,默认在启动时自动分配一个随机通用唯一标志符作为名称。一个Elasticsearch 集群通常含有多个节点, 以确保集群的高可用性、数据存储、查询处理和负载均衡。
每种节点在集群中扮演不同的角色,如主节点(master node)、数据节点(data node)、协调节点(coordinating node)和ingest节点(ingest node)。
Master Node:
- • 负责集群范围内的管理任务,如创建或删除索引、跟踪节点的加入或离开、以及分片分配。
- • 建议设置为奇数个节点(3个或5个),以确保在网络分区时能够达成共识。
Data Node:
- • 负责存储数据和执行数据相关的操作,如CRUD操作、搜索和聚合。
- • 根据数据量和查询需求,合理配置CPU、内存和磁盘。
Coordinating Node:
- • 作为负载均衡器,将请求分发到合适的数据节点,并聚合结果返回给客户端。
- • 默认情况下,所有节点都可以充当协调节点,但在大规模集群中,可以专门配置此角色以提高性能。
Ingest Node:
- • 负责预处理文档数据(例如,通过管道进行数据转换和丰富)。
- • 可根据数据摄入需求进行水平扩展。
节点的角色可以通过在 elasticsearch.yml 配置文件中的属性来设置(例如:node.roles: [ data, master ])。
分片
单台机器(节点)无法存储大量的索引数据, 通过分片,将索引数据分散到不同的机器上,实现水平扩展,提高系统的性能和吞吐量。分片可分为主分片和副本分片。
Primary Shard(主分片) :负责写入,数量固定(创建索引时指定)。
Replica Shard(副本分片) :主分片的拷贝,提供高可用和读取扩展。
分片具有以下特性:
- • 建立索引时, 系统会先将索引存储在主分片中, 然后再将主分片中的索引复制到不同的副本中.
- • 主分片和副本分片不会分配在同一个节点(避免单点故障)。
- • 高查询效率和查询时的吞吐量: 搜索可以在所有的副本上并行执行, 提高了服务的并发量.
- • 主分片在建立索引时设置, 后期不能修改,想要修改需要重新建立索引,副本分片可以动态调整。
副本(Replica)
ES支持为每个Shard创建多个副本, 相当于索引数据的冗余备份。副本是 Elasticsearch 实现高可用性 和高性能读取的基石。
- • 高可用性: 通过冗余存储(副本是主分片的完整拷贝)和自动故障转移(副本提升为主分片),确保节点故障时数据不丢失、服务不中断。
- • 高性能读取: 通过允许搜索请求在所有可用副本(及主分片)上并行执行,显著提升查询吞吐量和并发能力,实现读操作的横向扩展。
- • 写入代价: 增加副本会带来额外的存储开销、网络流量和潜在的写入延迟/吞吐量下降。设置副本数 (
number_of_replicas) 时需要仔细权衡可用性、读取性能需求与硬件资源成本。生产环境强烈建议至少保留 1 个副本。
数据写入流程
-
- 客户端发送请求
→ 向任一 ES 节点(协调节点)发送写请求(如PUT /index/_doc/1)。
- 客户端发送请求
-
- 路由到主分片
→ 协调节点根据文档 ID 计算目标主分片:shard = hash(id) % 主分片数。
→ 找到该主分片所在节点,转发请求。
- 路由到主分片
-
- 主分片写入与转发
→ 主分片节点 做两件事:
a. 本地写入 :将文档存入内存缓冲区,并立即写入磁盘 Translog (保证不丢数据)。
b. 并行转发 :将写请求同时发给所有副本分片节点。
- 主分片写入与转发
-
- 副本分片写入
→ 每个副本分片节点 收到请求后:
a. 本地写入 :同样存入内存缓冲区 + 写入磁盘 Translog 。
b. 回复确认:成功后通知主分片节点。
- 副本分片写入
-
- 主分片确认响应
→ 主分片节点等待足够数量 的分片(含自身和副本)写入成功(由wait_for_active_shards控制)。
→ 回复协调节点 "成功"。
- 主分片确认响应
-
- 协调节点响应客户端
→ 协调节点将 "成功" 返回给客户端。
- 协调节点响应客户端
数据读取流程
-
- 客户端发送请求
→ 向任一 ES 节点(协调节点)发送搜索请求(如GET /index/_search?q=keyword)。
- 客户端发送请求
-
- 分发查询(Scatter 阶段)
→ 协调节点确定索引涉及的所有分片(主分片 + 副本分片)。
→ 并行发送查询请求 到所有相关分片(优先选择负载低的副本)。
- 分发查询(Scatter 阶段)
-
- 分片本地执行搜索
→ 每个分片(主或副本)节点:
a. 在 本地 Lucene 索引 中执行搜索。
b. 返回 匹配文档的元数据 (_id、_score、排序值等)给协调节点。
- 分片本地执行搜索
-
- 聚合与排序(Gather 阶段)
→ 协调节点:
a. 合并 所有分片返回的结果(按相关性分数或指定排序)。
b. 生成全局排序后的 Top N 结果列表(如前100条)。
- 聚合与排序(Gather 阶段)
-
- 获取文档详情(Fetch 阶段 - 可选)
→ 若需返回文档完整内容(如_source字段):
a. 协调节点向 持有这些文档的分片 (主或副本)发送GET请求。
b. 分片返回完整文档内容。
- 获取文档详情(Fetch 阶段 - 可选)
-
- 响应客户端
→ 协调节点将 最终结果(元数据 + 完整文档)返回给客户端。
- 响应客户端
故障转移
当节点故障(宕机、网络中断)时,ES能够自动恢复集群健康状态,确保:
-
- 数据不丢失(有副本的前提下)
-
- 服务持续可用(读写操作不受影响)
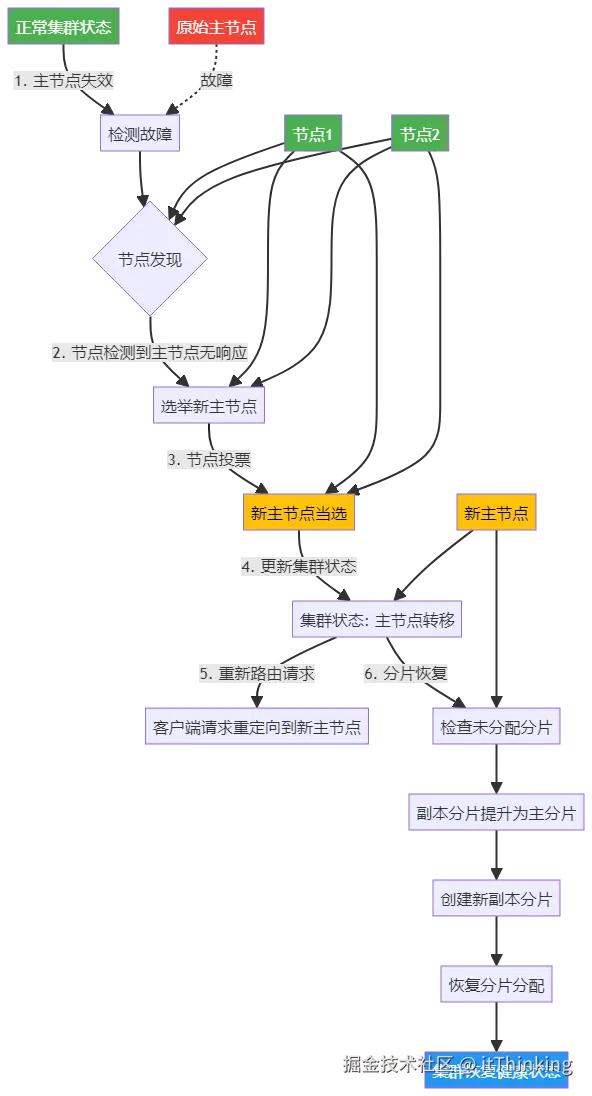
ES故障转移恢复包含故障检测、新主节点选举、数据节点故障转移三个流程。
故障检测
-
- 节点间心跳检测
→ 默认每1s发送一次 Ping 请求(通过discovery.zen.fd.ping_interval配置)。
→ 若连续超时(默认30s未响应),主节点将该节点标记为 故障节点。
- 节点间心跳检测
新主节点选举(控制面恢复)
-
- 主节点失联
→ 其他候选主节点(node.roles: [master])检测到主节点心跳丢失。
- 主节点失联
-
- 重新选举
→ 剩余候选主节点通过 选举算法 (类 Paxos)投票选出新主节点(通常在1-2s内完成)。
- 重新选举
-
- 新主节点生效
→ 更新集群状态(Cluster State),广播给所有节点。
- 新主节点生效
注意 :选举期间集群短暂不可用(写入/删索引等管理操作阻塞),但数据读写仍可通过协调节点处理。
数据节点故障转移(数据面恢复)
当数据节点(node.roles: [data])故障时:
场景 1:主分片所在节点故障
-
- 新主节点检测分片状态
→ 发现主分片(如P0)不可用。
- 新主节点检测分片状态
-
- 副本分片提升为主分片
→ 从原主分片的 健康副本分片 (如R0)中选择一个,提升为 新主分片。
- 副本分片提升为主分片
-
- 恢复索引写入能力
→ 新主分片可立即接收写入请求(原故障节点数据需后续恢复)。
- 恢复索引写入能力
场景 2:副本分片所在节点故障
-
- 新主节点标记副本不可用
→ 如副本分片R0状态变为UNASSIGNED。
- 新主节点标记副本不可用
-
- 自动分配新副本
→ 将副本数据从主分片(P0)复制到其他健康节点 ,创建新副本分片(如R0-new)。
- 自动分配新副本
场景 3:新节点加入集群
-
- 自动负载均衡
→ 新数据节点加入后,主节点自动将未分配的分片(主/副本)迁移到该节点。
- 自动负载均衡
-
- 数据同步
→ 新节点从现有分片拉取数据,完成副本重建。
- 数据同步
总结
Elasticsearch是一个开源的全文搜索引擎,适用于实时数据搜索、分析和可视化。它具有分布式、RESTful风格的接口,设计用于弹性、高可用性和高性能。本文是Elasticsearch的入门篇章。从典型应用场景、核心概念以及架构设计讲述了Elasticsearch。
参考:
www.cnblogs.com/Qiullen/art...
cloud.tencent.com/developer/a...