近年来,大模型(LLMs)的热潮推动了自然语言处理(NLP)任务的广泛进展,NL2SQL(自然语言转SQL)作为热门任务之一也不例外。 从下图可以看出,不同的benchmark以及测试方法在T5模型之后,出现了极速增长。
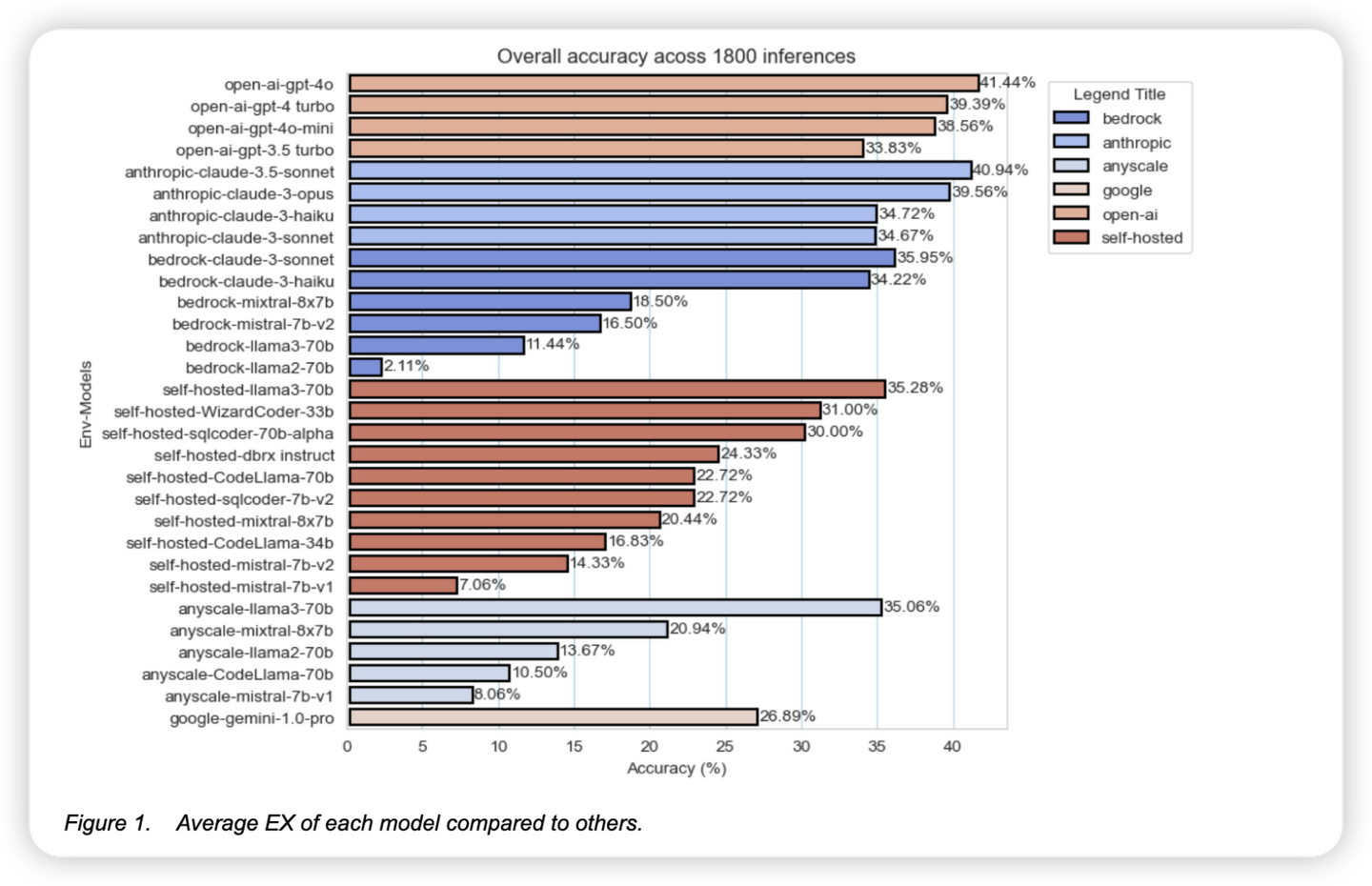
并且一些SOTA 模型在nl2sql任务的表现上和以往相比,有了极大的提升:
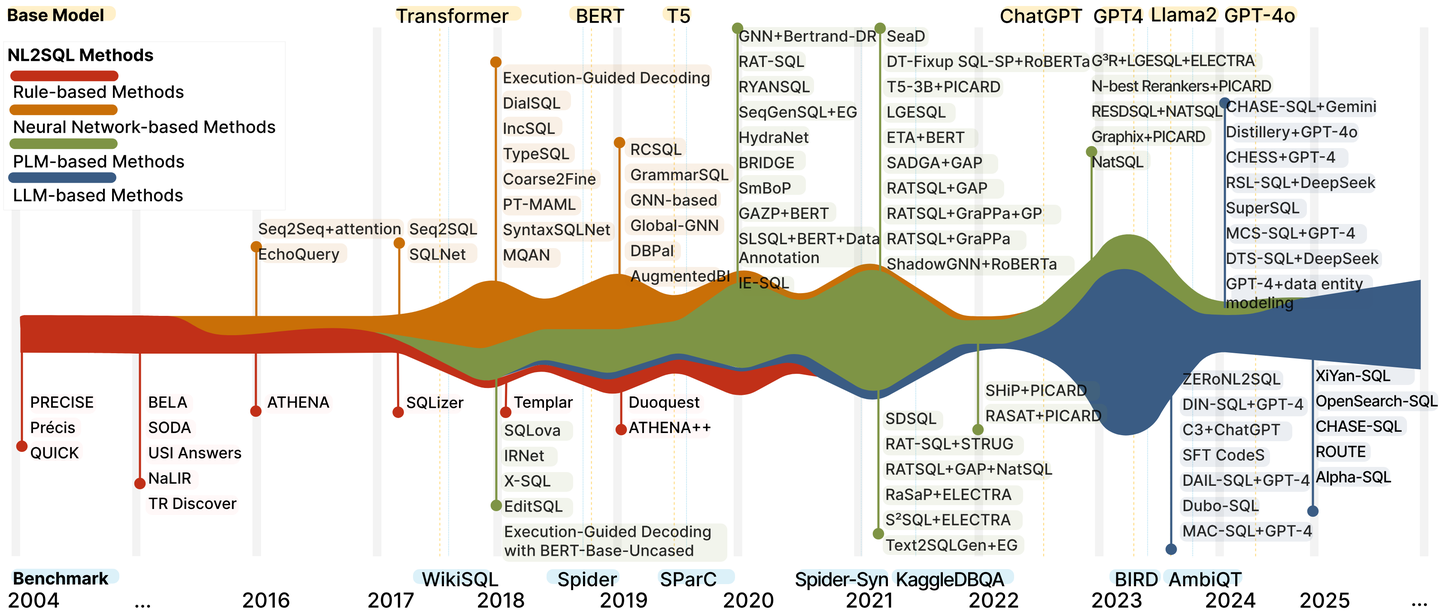
但是普遍的这些模型的参数量都在100B以上,而NL2SQL作为一个相对niche的场景,并且和业务场景结合密切的情况下,是否可以在一些小参数量的模型上也获得比较好的表现呢?
NL2SQL的核心是什么?
我们认为,NL2SQL的核心能力并不在于"语言建模"本身,而是在两个方面:
-
理解用户意图与问题背景(场景理解)
-
根据数据库结构正确地生成SQL(逻辑推理+语法生成)
这两个任务的挑战,不在于模型是否足够"大",而在于:
-
自然语言表达是否模糊(例如"订单总量是多少"可能有多种理解)
-
数据库结构是否复杂、是否包含大量无关表/列
-
字段命名是否清晰,是否有中文注释、是否包含样例数据
这些问题,很多时候靠"更大的模型"并不能直接解决。
先说结论, 来自工程实践中的关键启发:
模型并不是越大越好,Qwen Coder 3B/7B已足够胜任任务
我们尝试了多个模型:
-
Qwen 1.7B:参数过小小导致代码生成能力弱
-
Qwen2.5 Coder 3B & 7B:专为代码/SQL任务设计,结果优秀,微调后准确率达到 0.81 Execution Accuracy
这个结果已经超过了同等结构的SOTA方法(如RoBERTa + T5-3B组合),而且显著减少了部署成本。
✅ 结论:使用精调后的中型模型(3B-7B)已能解决大部分真实SQL生成任务。
Schema Linking 比模型大小更关键
很多真实数据库(如金盘数据库)存在如下问题:
-
字段名不可读(如 VBELN, ZZHYYH)
-
字段之间没有明确注释
-
多张表字段重复,关联复杂
这时候,如果不先过滤schema,大模型也会"幻觉"严重,因为注意力被不相关字段稀释。
我们尝试了:
-
简单DIN-SQL式的Schema Linking 1(https://arxiv.org/abs/2304.11015)
-
强化版RESDSQL交叉编码器 + 列增强层 2(https://arxiv.org/abs/2302.05965)
效果立竿见影,准确率从 0.44 → 0.81,说明大模型"理解错误"更多是输入结构的问题。
✅ 结论:场景理解靠结构优化(如schema linking),而不是盲目加参数。
训练样本设计、注释、示例数据远比模型大小重要
在对金盘等工业数据库做训练时,我们发现:
-
表/列名没信息,靠注释
-
不提供字段值样例,模型不知字段用途
-
用户问题表达差异大,golden SQL却一样
我们通过:
-
引入字段注释
-
注入字段样例
-
打乱schema顺序增强泛化
-
构造不同表达相同SQL的样本
在没有换更大模型的前提下,准确率显著提升。
✅ 结论:训练数据质量和构造方式决定了最终效果。
"大模型 + 幻觉 + JOIN滥用"反而是风险
在没有schema linking的情况下,大模型非常容易:
-
随意JOIN多张表
-
忽略限制条件(distinct、只返回某一列)
-
理解模糊表达错误,生成语义不符的SQL
反而小一点、结构清晰的模型,表现更稳定可靠。
回到问题:搭建NL2SQL系统需要大模型吗?
结论是:
❌ 不需要SOTA级别的大模型(70B+)才能做好NL2SQL。 ✅ 需要的是:
-
良好的schema linking策略
-
高质量的训练样本
-
合理的prompt设计与数据增强
-
中等规模、代码能力强的模型(如Qwen2.5 Coder 3B/7B)
展望
未来的NL2SQL系统,更像是一个结构化的"智能Agent":
-
能理解用户问题意图
-
能快速筛选schema
-
能学习约束和偏好
-
能精准生成SQL并自我验证
而不是一个越大越好的"语言模型"。如果你也在搭建自己的NL2SQL系统,不妨先别上来就调用GPT-4或GPT-4o,先试试把schema理清楚,再加点样例数据,然后用一个3B模型看看效果------说不定,已经足够用了。