🌟 Hello,我是蒋星熠Jaxonic!
🌈 在浩瀚无垠的技术宇宙中,我是一名执着的星际旅人,用代码绘制探索的轨迹。
🚀 每一个算法都是我点燃的推进器,每一行代码都是我航行的星图。
🔭 每一次性能优化都是我的天文望远镜,每一次架构设计都是我的引力弹弓。
🎻 在数字世界的协奏曲中,我既是作曲家也是首席乐手。让我们携手,在二进制星河中谱写属于极客的壮丽诗篇!
一、简介
推特作为全球最大的实时信息平台之一,蕴含着海量的价值数据。在过去几年中,我设计并实现了多个推特数据爬取与分析系统,推特提供了多种API接口,用于开发者获取平台数据。了解这些API的特点和限制,是进行有效数据爬取的第一步。但是推特的反爬机制特别强,需要进行特殊的处理才可以。
二、结果展示
先开门见山了:
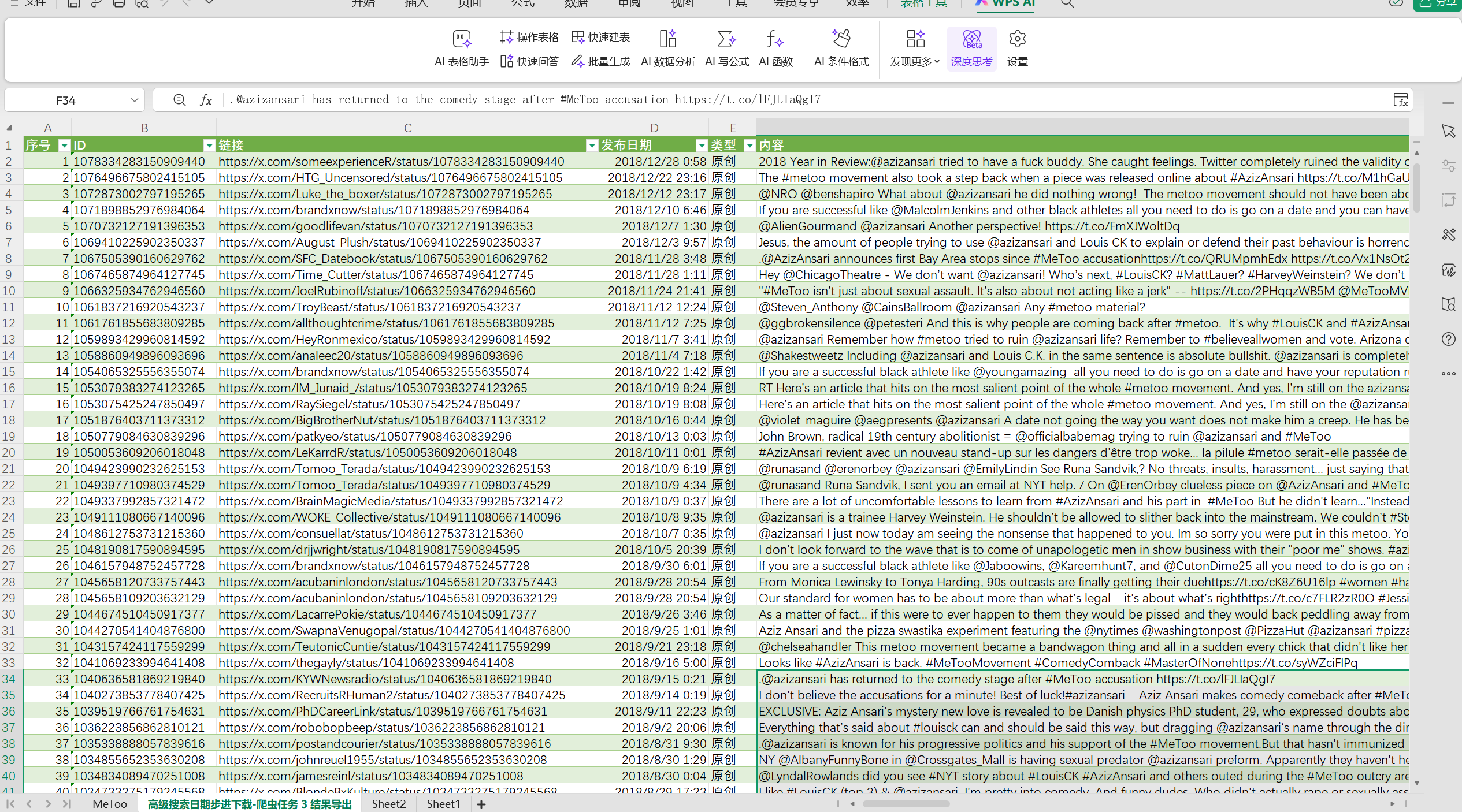
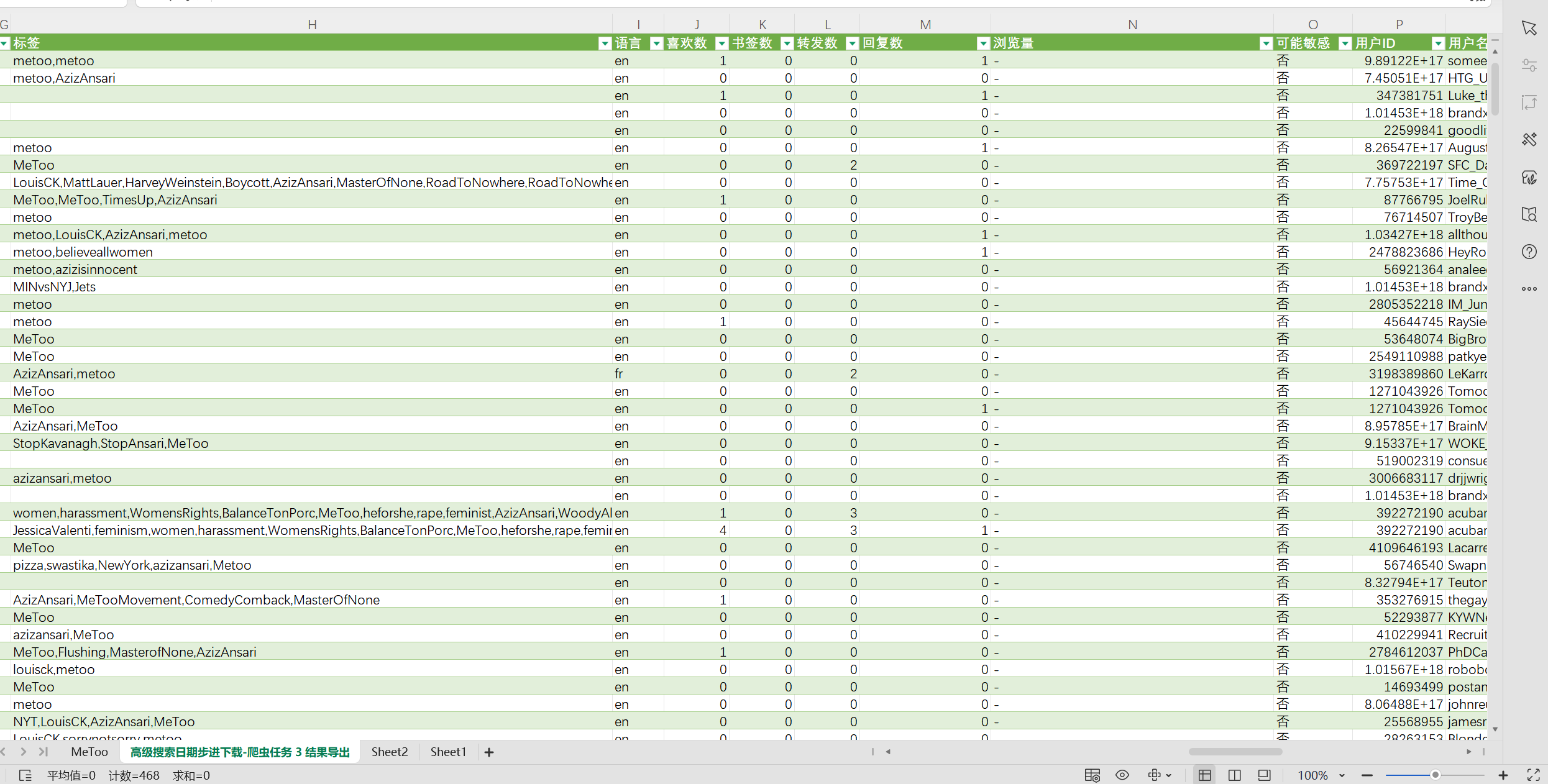
这是爬取到的数据,包含了很多内容,像推文内容,发布时间,点赞数,转推数,评论数,用户名,用户简介,用户ip,用户贴子数,关注量等等
三、代码部分:
引入需要的包:
python
import json
import os
import time
import requests
import pandas as pd
import datetime
import uuid
import base64
import random
from urllib.parse import quote定义爬虫类和headers等信息:
python
# 禁用警告
requests.packages.urllib3.disable_warnings()
class TwitterKeywordSearch:
def __init__(self, saveFileName, cookie_str):
self.saveFileName = saveFileName
self.cookie_str = cookie_str
self.operation_hash = "NiZ1seU-Qm1TUiThEaWXKA" # 固定 hash
self.bearer_token = "Bearer AAAAAAAAAAAAAAAAAAAAANRILgAAAAAAnNwIzUejRCOuH5E6I8xnZz4puTs%3D1Zv7ttfk8LF81IUq16cHjhLTvJu4FA33AGWWjCpTnA"
# 从 Cookie 字符串解析
self.cookies = {}
for item in cookie_str.split("; "):
if "=" in item:
k, v = item.split("=", 1)
self.cookies[k.strip()] = v.strip()
# 提取 ct0 用于 x-csrf-token
self.ct0 = self.cookies.get('ct0', '')
# 基础 headers(完全复刻浏览器)
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0',
'Authorization': self.bearer_token,
'x-twitter-client-language': 'en',
'x-twitter-active-user': 'yes',
'x-twitter-auth-type': 'OAuth2Session',
'x-csrf-token': self.ct0,
'Accept': '*/*',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'cors',
'Referer': 'https://x.com/search',
'Accept-Encoding': 'gzip, deflate, br, zstd',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6,zh-TW;q=0.5',
'Priority': 'u=1, i',
'sec-ch-ua': '"Not;A=Brand";v="99", "Microsoft Edge";v="139", "Chromium";v="139"',
'sec-ch-ua-arch': '"x86"',
'sec-ch-ua-bitness': '"64"',
'sec-ch-ua-full-version': '"139.0.3405.86"',
'sec-ch-ua-full-version-list': '"Not;A=Brand";v="99.0.0.0", "Microsoft Edge";v="139.0.3405.86", "Chromium";v="139.0.7258.67"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-ch-ua-platform-version': '"19.0.0"',
'Content-Type': 'application/json',
'x-client-transaction-id': self.generate_transaction_id(), # 动态生成
}
self.resultList = []定义各种爬取函数:
python
def generate_transaction_id(self):
"""生成 x-client-transaction-id"""
timestamp = str(int(time.time() * 1000))
rand_str = str(uuid.uuid4())
raw = f"{timestamp}:{rand_str}"
return base64.b64encode(raw.encode()).decode()
def get_params(self, raw_query, cursor=None):
"""构造 variables 和 features(完全复刻浏览器)"""
variables = {
"rawQuery": raw_query,
"count": 20,
"querySource": "recent_search_click",
"product": "Latest",
"withGrokTranslatedBio": False
}
if cursor:
variables["cursor"] = cursor
features = {
"rweb_video_screen_enabled": False,
"payments_enabled": False,
"rweb_xchat_enabled": False,
"profile_label_improvements_pcf_label_in_post_enabled": True,
"rweb_tipjar_consumption_enabled": True,
"verified_phone_label_enabled": False,
"creator_subscriptions_tweet_preview_api_enabled": True,
"responsive_web_graphql_timeline_navigation_enabled": True,
"responsive_web_graphql_skip_user_profile_image_extensions_enabled": False,
"premium_content_api_read_enabled": False,
"communities_web_enable_tweet_community_results_fetch": True,
"c9s_tweet_anatomy_moderator_badge_enabled": True,
"responsive_web_grok_analyze_button_fetch_trends_enabled": False,
"responsive_web_grok_analyze_post_followups_enabled": True,
"responsive_web_jetfuel_frame": True,
"responsive_web_grok_share_attachment_enabled": True,
"articles_preview_enabled": True,
"responsive_web_edit_tweet_api_enabled": True,
"graphql_is_translatable_rweb_tweet_is_translatable_enabled": True,
"view_counts_everywhere_api_enabled": True,
"longform_notetweets_consumption_enabled": True,
"responsive_web_twitter_article_tweet_consumption_enabled": True,
"tweet_awards_web_tipping_enabled": False,
"responsive_web_grok_show_grok_translated_post": False,
"responsive_web_grok_analysis_button_from_backend": True,
"creator_subscriptions_quote_tweet_preview_enabled": False,
"freedom_of_speech_not_reach_fetch_enabled": True,
"standardized_nudges_misinfo": True,
"tweet_with_visibility_results_prefer_gql_limited_actions_policy_enabled": True,
"longform_notetweets_rich_text_read_enabled": True,
"longform_notetweets_inline_media_enabled": True,
"responsive_web_grok_image_annotation_enabled": True,
"responsive_web_grok_imagine_annotation_enabled": True,
"responsive_web_grok_community_note_auto_translation_is_enabled": False,
"responsive_web_enhance_cards_enabled": False
}
return {
"variables": json.dumps(variables, separators=(',', ':')),
"features": json.dumps(features, separators=(',', ':'))
}
def get(self, raw_query, cursor=None):
"""发送请求"""
url = f"https://x.com/i/api/graphql/{self.operation_hash}/SearchTimeline"
params = self.get_params(raw_query, cursor)
# 每次请求更新 transaction-id
self.headers['x-client-transaction-id'] = self.generate_transaction_id()
# 动态更新 Referer
self.headers['Referer'] = f"https://x.com/search?q={quote(raw_query)}&src=recent_search_click&f=live"
try:
response = requests.get(
url,
headers=self.headers,
cookies=self.cookies,
params=params,
timeout=(10, 20),
verify=False
)
if response.status_code == 429:
reset_time = int(response.headers.get('x-rate-limit-reset', time.time() + 900))
wait_time = max(reset_time - int(time.time()), 60)
print(f"【限流】等待 {wait_time} 秒...")
time.sleep(wait_time)
return None
if response.status_code == 200:
try:
return response.json()
except json.JSONDecodeError:
print("❌ 响应不是 JSON 格式")
print("响应内容:", response.text[:300])
return None
else:
print(f"请求失败: {response.status_code}, 响应: {response.text[:200]}")
return None
except Exception as e:
print(f"请求异常: {e}")
time.sleep(5)
return None
def get_cursor(self, response_json):
"""从响应中提取 next_cursor"""
try:
entries = response_json['data']['search_by_raw_query']['search_timeline']['timeline']['instructions']
next_cursor = None
for entry in entries:
if entry['type'] == 'TimelineAddEntries':
for item in entry['entries']:
if 'cursor-bottom' in item['entryId']:
content = item['content']
if content.get('cursorType') == 'Bottom':
next_cursor = content['value']
break
elif entry['type'] == 'TimelineReplaceEntry':
if 'cursor-bottom' in entry['entry']['entryId']:
next_cursor = entry['entry']['content']['value']
break
return next_cursor
except Exception as e:
print(f"提取 cursor 失败: {e}")
return None
def parse_data(self, response_json):
"""解析推文数据"""
def trans_time(created_at):
dt = datetime.datetime.strptime(created_at, '%a %b %d %H:%M:%S +0000 %Y')
return dt.strftime('%Y-%m-%d %H:%M:%S')
items = []
try:
entries = response_json['data']['search_by_raw_query']['search_timeline']['timeline']['instructions']
for entry in entries:
if entry['type'] == 'TimelineAddEntries':
for item in entry['entries']:
entry_id = item['entryId']
if 'tweet-' in entry_id or 'profile-conversation' in entry_id:
content = item['content']['itemContent']
if 'tweet_results' in content:
tweet = content['tweet_results']['result']
legacy = tweet.get('legacy') or tweet.get('tweet', {}).get('legacy')
core = tweet.get('core') or tweet.get('tweet', {}).get('core')
if not legacy or not core:
continue
user = core['user_results']['result']['legacy']
full_text = legacy.get('full_text', '')
if 'note_tweet' in tweet:
full_text = tweet['note_tweet']['result']['text']
items.append({
"内容": full_text,
"时间": trans_time(legacy['created_at']),
"点赞": legacy.get('favorite_count', 0),
"评论": legacy.get('reply_count', 0),
"转发": legacy.get('retweet_count', 0) + legacy.get('quote_count', 0),
"简介": user.get('description', ''),
"粉丝量": user.get('followers_count', 0),
"关注量": user.get('friends_count', 0)
})
except Exception as e:
print(f"解析失败: {e}")
if items:
self.save_data(items)
print(f"✅ 保存 {len(items)} 条推文")
return items
def save_data(self, data_list):
"""追加保存到 CSV"""
df = pd.DataFrame(data_list)
file_path = f'./{self.saveFileName}.csv'
header = not os.path.exists(file_path)
df.to_csv(file_path, index=False, mode='a', encoding='utf_8_sig', header=header)
def run(self, raw_query):
"""主爬取逻辑"""
cursor = None
page = 1
while True:
print(f"📌 第 {page} 页...")
response = self.get(raw_query, cursor)
if not response:
print("❌ 请求失败或被限流")
break
new_tweets = self.parse_data(response)
if not new_tweets:
print("📭 无新数据,可能已到底")
break
next_cursor = self.get_cursor(response)
if not next_cursor or next_cursor == cursor:
print("🔚 已到最后一页")
break
cursor = next_cursor
page += 1
time.sleep(random.uniform(3, 7)) # 随机延时
def main(self, keywords_list):
"""批量执行"""
for keyword in keywords_list:
print(f"\n🔍 开始搜索: {keyword}")
self.run(keyword)用户配置,这里有像token,ct0,cookie等信息,需要自己配置,至于获取的方法见下文:
python
# ========================
# ✅ 用户配置区(请替换)
# ========================
if __name__ == '__main__':
# 🔐 从浏览器复制的完整 Cookie(请确保有效)
COOKIE_STR = "__cuid=0c6eafb48bca44bfa53c96ecfc34766e; g_state={\"i_l\":0}; kdt=DjYN3dU6uqZUFbK0Z2yCGIMfxs3tBeg26PMxUJ4a; att=1-yhCypM1zy0pRa4hZkYP5WuKabl5TxYyRiLioSlOW; lang=en; dnt=1; guest_id=v1%3A175516465513586295; guest_id_marketing=v1%3A175516465513586295; guest_id_ads=v1%3A175516465513586295; personalization_id=\"v1_i54Wl/43qBb3wyWw5rTpnw==\"; gt=1955928444279382425; _twitter_sess=BAh7CSIKZmxhc2hJQzonQWN0aW9uQ29udHJvbGxlcjo6Rmxhc2g6OkZsYXNo%250ASGFzaHsABjoKQHVzZWR7ADoPY3JlYXRlZF9hdGwrCLNX96eYAToMY3NyZl9p%250AZCIlYTk5MTdiYmU5N2MwYWNlMDcyNDNlYmU3NGE5YzNmYTg6B2lkIiU2ZDhk%250AZGQwZmVkYjgxOWM4N2JlOTI2MzZlNjQyMDIyMg%253D%253D--32e8b8bbc3092f636d7dfdf0870d7bc3cc9c1143; auth_token=a512f85cc3d5473e0efe957edd507ef70a795325; ct0=646e440727f56a3ae48ff5c117073ff5b225a9e04a13bee1ffc4765ced1e8024ff957ed7bae4dc1098a8e9216176f2ee03d631a6a7b6ad12f518baf47f966114005d09981cb8382103691b32255af6c6; twid=u%3D1955928620771520512; ph_phc_TXdpocbGVeZVm5VJmAsHTMrCofBQu3e0kN8HGMNGTVW_posthog=%7B%22distinct_id%22%3A%220198a7ff-c624-71c1-bbfd-28d98ef752a9%22%2C%22%24sesid%22%3A%5B1755165267989%2C%220198a7ff-c623-7586-8e40-0293329c615b%22%2C1755165214243%5D%7D; cf_clearance=Hg4mn9dhWvdVIcA5VcFR1Fw8TjX4aqyESpH1HYyBzE0-1755165970-1.2.1.1-Ese9AP5TQuv.LAU6Ah_iLxp0axDGXgahTEGQI_XJ6U_ezjTFFLzo9zg1WiRbX_6yrBwRFGRpp6MFt21Ruqza0LfY_qow25dGGt5Q7Yk.mEIH13Ao5vCkYx6vUBEh0hTDw9KWlZu_158u.L0qr9YSMactfbbobwbxV1wYuTPEIdxdVN6yxxgR17Fo.7ofspnvwFv_OuM8AEgkUc8IAmbQuUINolhFHTXctXrAPJqKrDw"
# 🔍 搜索关键词(注意:中文逗号 %EF%BC%8C 已保留)
KEYWORDS = ["MeToo,AzizAnsari"] # 可添加更多,如 ["covid", "ai"]
# 💾 保存文件名
SAVE_FILE = "twitter_mee_too_aziz"
# ✅ 创建爬虫并运行
crawler = TwitterKeywordSearch(saveFileName=SAVE_FILE, cookie_str=COOKIE_STR)
crawler.main(KEYWORDS)四、获取自己推特Cookie,token,URL等信息的方法:
连接魔法后按F12跳转到开发者工具,然后点击网络,因为很多网页请求信息都存在searchtimeline里:
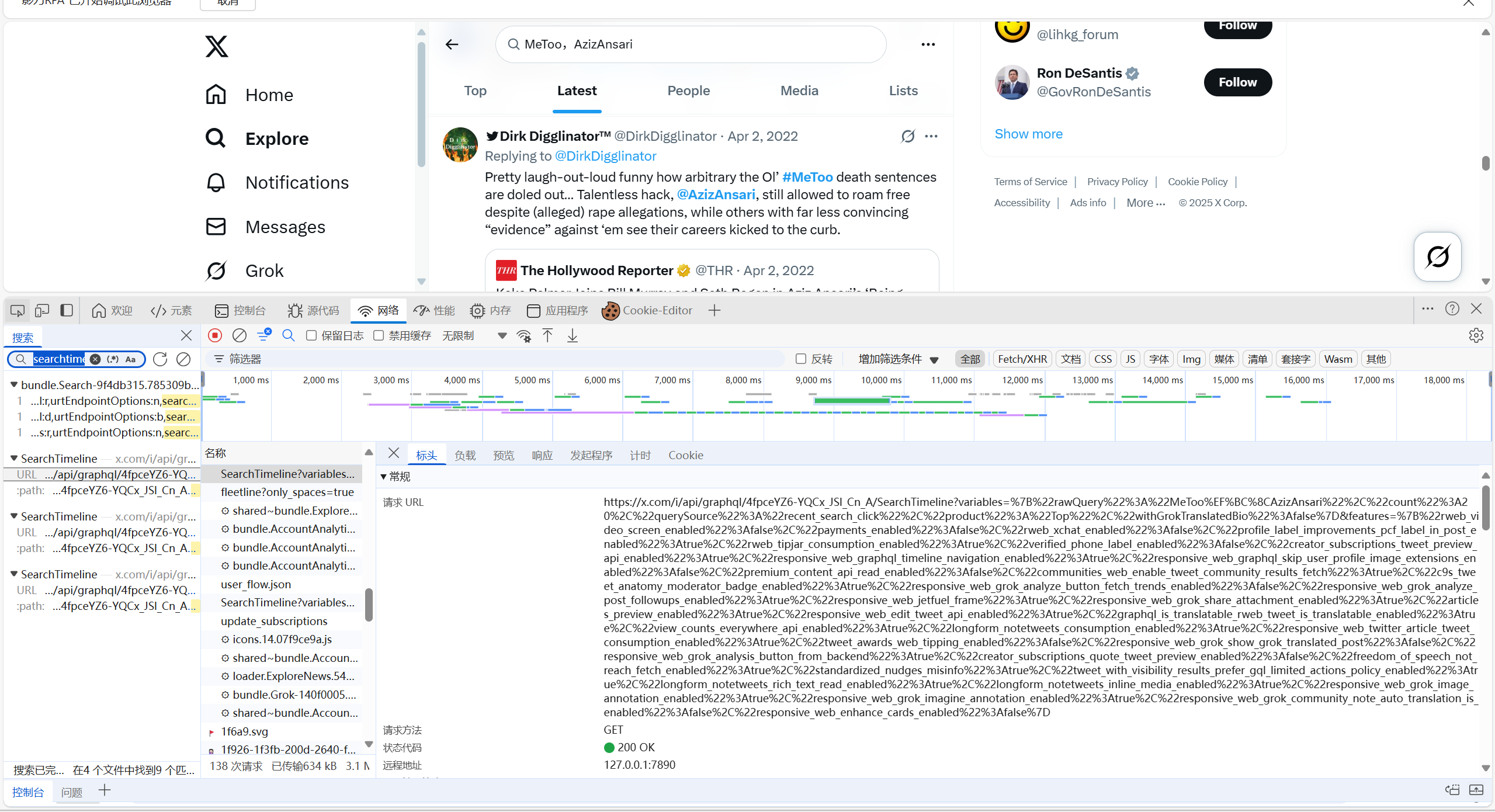

自己去找到相关信息改代码,也可以下载浏览器插件:
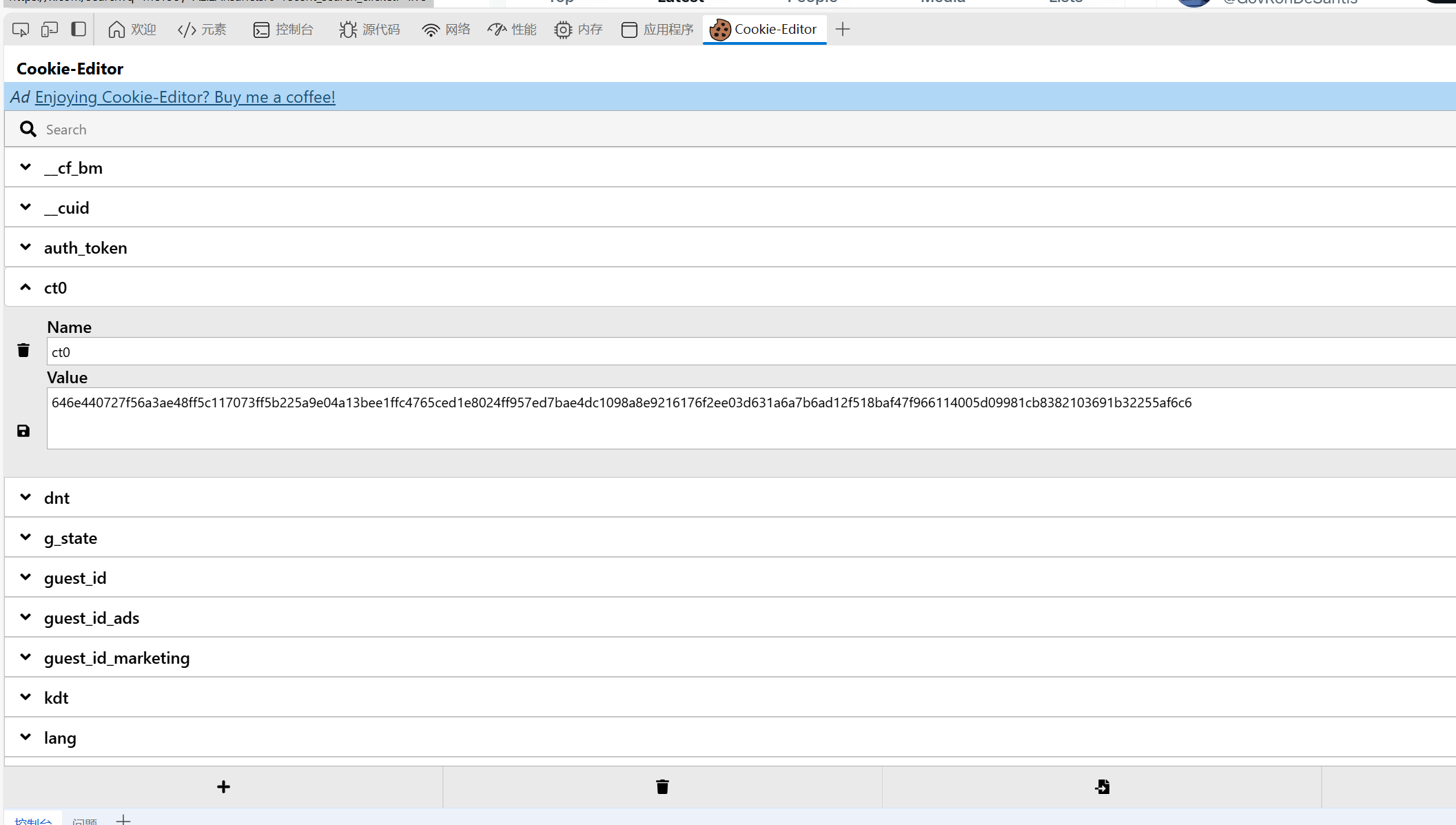
由于推特是有反爬机制的,searchtimeline会实时更新,每次往下翻页会出现新的searchtimeline,像这样: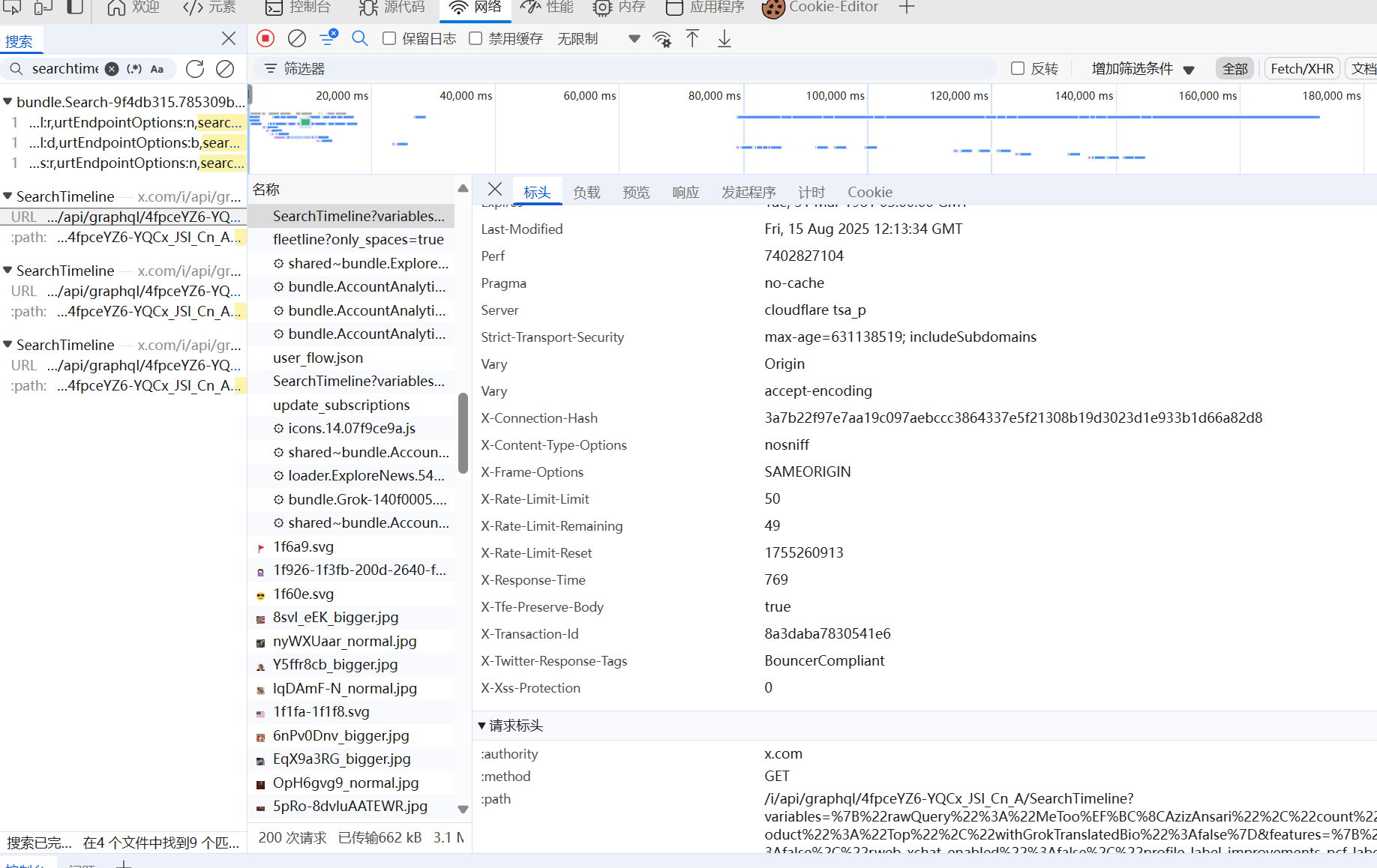
所以我在代码里设置了更新读入的机制,还有推迟爬取防止被限流检测到不是真人
五、完整代码:
python
import json
import os
import time
import requests
import pandas as pd
import datetime
import uuid
import base64
import random
from urllib.parse import quote
# 禁用警告
requests.packages.urllib3.disable_warnings()
class TwitterKeywordSearch:
def __init__(self, saveFileName, cookie_str):
self.saveFileName = saveFileName
self.cookie_str = cookie_str
self.operation_hash = "NiZ1seU-Qm1TUiThEaWXKA" # 固定 hash
self.bearer_token = "Bearer AAAAAAAAAAAAAAAAAAAAANRILgAAAAAAnNwIzUejRCOuH5E6I8xnZz4puTs%3D1Zv7ttfk8LF81IUq16cHjhLTvJu4FA33AGWWjCpTnA"
# 从 Cookie 字符串解析
self.cookies = {}
for item in cookie_str.split("; "):
if "=" in item:
k, v = item.split("=", 1)
self.cookies[k.strip()] = v.strip()
# 提取 ct0 用于 x-csrf-token
self.ct0 = self.cookies.get('ct0', '')
# 基础 headers(完全复刻浏览器)
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0',
'Authorization': self.bearer_token,
'x-twitter-client-language': 'en',
'x-twitter-active-user': 'yes',
'x-twitter-auth-type': 'OAuth2Session',
'x-csrf-token': self.ct0,
'Accept': '*/*',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'cors',
'Referer': 'https://x.com/search',
'Accept-Encoding': 'gzip, deflate, br, zstd',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6,zh-TW;q=0.5',
'Priority': 'u=1, i',
'sec-ch-ua': '"Not;A=Brand";v="99", "Microsoft Edge";v="139", "Chromium";v="139"',
'sec-ch-ua-arch': '"x86"',
'sec-ch-ua-bitness': '"64"',
'sec-ch-ua-full-version': '"139.0.3405.86"',
'sec-ch-ua-full-version-list': '"Not;A=Brand";v="99.0.0.0", "Microsoft Edge";v="139.0.3405.86", "Chromium";v="139.0.7258.67"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-ch-ua-platform-version': '"19.0.0"',
'Content-Type': 'application/json',
'x-client-transaction-id': self.generate_transaction_id(), # 动态生成
}
self.resultList = []
def generate_transaction_id(self):
"""生成 x-client-transaction-id"""
timestamp = str(int(time.time() * 1000))
rand_str = str(uuid.uuid4())
raw = f"{timestamp}:{rand_str}"
return base64.b64encode(raw.encode()).decode()
def get_params(self, raw_query, cursor=None):
"""构造 variables 和 features(完全复刻浏览器)"""
variables = {
"rawQuery": raw_query,
"count": 20,
"querySource": "recent_search_click",
"product": "Latest",
"withGrokTranslatedBio": False
}
if cursor:
variables["cursor"] = cursor
features = {
"rweb_video_screen_enabled": False,
"payments_enabled": False,
"rweb_xchat_enabled": False,
"profile_label_improvements_pcf_label_in_post_enabled": True,
"rweb_tipjar_consumption_enabled": True,
"verified_phone_label_enabled": False,
"creator_subscriptions_tweet_preview_api_enabled": True,
"responsive_web_graphql_timeline_navigation_enabled": True,
"responsive_web_graphql_skip_user_profile_image_extensions_enabled": False,
"premium_content_api_read_enabled": False,
"communities_web_enable_tweet_community_results_fetch": True,
"c9s_tweet_anatomy_moderator_badge_enabled": True,
"responsive_web_grok_analyze_button_fetch_trends_enabled": False,
"responsive_web_grok_analyze_post_followups_enabled": True,
"responsive_web_jetfuel_frame": True,
"responsive_web_grok_share_attachment_enabled": True,
"articles_preview_enabled": True,
"responsive_web_edit_tweet_api_enabled": True,
"graphql_is_translatable_rweb_tweet_is_translatable_enabled": True,
"view_counts_everywhere_api_enabled": True,
"longform_notetweets_consumption_enabled": True,
"responsive_web_twitter_article_tweet_consumption_enabled": True,
"tweet_awards_web_tipping_enabled": False,
"responsive_web_grok_show_grok_translated_post": False,
"responsive_web_grok_analysis_button_from_backend": True,
"creator_subscriptions_quote_tweet_preview_enabled": False,
"freedom_of_speech_not_reach_fetch_enabled": True,
"standardized_nudges_misinfo": True,
"tweet_with_visibility_results_prefer_gql_limited_actions_policy_enabled": True,
"longform_notetweets_rich_text_read_enabled": True,
"longform_notetweets_inline_media_enabled": True,
"responsive_web_grok_image_annotation_enabled": True,
"responsive_web_grok_imagine_annotation_enabled": True,
"responsive_web_grok_community_note_auto_translation_is_enabled": False,
"responsive_web_enhance_cards_enabled": False
}
return {
"variables": json.dumps(variables, separators=(',', ':')),
"features": json.dumps(features, separators=(',', ':'))
}
def get(self, raw_query, cursor=None):
"""发送请求"""
url = f"https://x.com/i/api/graphql/{self.operation_hash}/SearchTimeline"
params = self.get_params(raw_query, cursor)
# 每次请求更新 transaction-id
self.headers['x-client-transaction-id'] = self.generate_transaction_id()
# 动态更新 Referer
self.headers['Referer'] = f"https://x.com/search?q={quote(raw_query)}&src=recent_search_click&f=live"
try:
response = requests.get(
url,
headers=self.headers,
cookies=self.cookies,
params=params,
timeout=(10, 20),
verify=False
)
if response.status_code == 429:
reset_time = int(response.headers.get('x-rate-limit-reset', time.time() + 900))
wait_time = max(reset_time - int(time.time()), 60)
print(f"【限流】等待 {wait_time} 秒...")
time.sleep(wait_time)
return None
if response.status_code == 200:
try:
return response.json()
except json.JSONDecodeError:
print("❌ 响应不是 JSON 格式")
print("响应内容:", response.text[:300])
return None
else:
print(f"请求失败: {response.status_code}, 响应: {response.text[:200]}")
return None
except Exception as e:
print(f"请求异常: {e}")
time.sleep(5)
return None
def get_cursor(self, response_json):
"""从响应中提取 next_cursor"""
try:
entries = response_json['data']['search_by_raw_query']['search_timeline']['timeline']['instructions']
next_cursor = None
for entry in entries:
if entry['type'] == 'TimelineAddEntries':
for item in entry['entries']:
if 'cursor-bottom' in item['entryId']:
content = item['content']
if content.get('cursorType') == 'Bottom':
next_cursor = content['value']
break
elif entry['type'] == 'TimelineReplaceEntry':
if 'cursor-bottom' in entry['entry']['entryId']:
next_cursor = entry['entry']['content']['value']
break
return next_cursor
except Exception as e:
print(f"提取 cursor 失败: {e}")
return None
def parse_data(self, response_json):
"""解析推文数据"""
def trans_time(created_at):
dt = datetime.datetime.strptime(created_at, '%a %b %d %H:%M:%S +0000 %Y')
return dt.strftime('%Y-%m-%d %H:%M:%S')
items = []
try:
entries = response_json['data']['search_by_raw_query']['search_timeline']['timeline']['instructions']
for entry in entries:
if entry['type'] == 'TimelineAddEntries':
for item in entry['entries']:
entry_id = item['entryId']
if 'tweet-' in entry_id or 'profile-conversation' in entry_id:
content = item['content']['itemContent']
if 'tweet_results' in content:
tweet = content['tweet_results']['result']
legacy = tweet.get('legacy') or tweet.get('tweet', {}).get('legacy')
core = tweet.get('core') or tweet.get('tweet', {}).get('core')
if not legacy or not core:
continue
user = core['user_results']['result']['legacy']
full_text = legacy.get('full_text', '')
if 'note_tweet' in tweet:
full_text = tweet['note_tweet']['result']['text']
items.append({
"内容": full_text,
"时间": trans_time(legacy['created_at']),
"点赞": legacy.get('favorite_count', 0),
"评论": legacy.get('reply_count', 0),
"转发": legacy.get('retweet_count', 0) + legacy.get('quote_count', 0),
"简介": user.get('description', ''),
"粉丝量": user.get('followers_count', 0),
"关注量": user.get('friends_count', 0)
})
except Exception as e:
print(f"解析失败: {e}")
if items:
self.save_data(items)
print(f"✅ 保存 {len(items)} 条推文")
return items
def save_data(self, data_list):
"""追加保存到 CSV"""
df = pd.DataFrame(data_list)
file_path = f'./{self.saveFileName}.csv'
header = not os.path.exists(file_path)
df.to_csv(file_path, index=False, mode='a', encoding='utf_8_sig', header=header)
def run(self, raw_query):
"""主爬取逻辑"""
cursor = None
page = 1
while True:
print(f"📌 第 {page} 页...")
response = self.get(raw_query, cursor)
if not response:
print("❌ 请求失败或被限流")
break
new_tweets = self.parse_data(response)
if not new_tweets:
print("📭 无新数据,可能已到底")
break
next_cursor = self.get_cursor(response)
if not next_cursor or next_cursor == cursor:
print("🔚 已到最后一页")
break
cursor = next_cursor
page += 1
time.sleep(random.uniform(3, 7)) # 随机延时
def main(self, keywords_list):
"""批量执行"""
for keyword in keywords_list:
print(f"\n🔍 开始搜索: {keyword}")
self.run(keyword)
# ========================
# ✅ 用户配置区(请替换)
# ========================
if __name__ == '__main__':
# 🔐 从浏览器复制的完整 Cookie(请确保有效)
COOKIE_STR = "__cuid=0c6eafb48bca44bfa53c96ecfc34766e; g_state={\"i_l\":0}; kdt=DjYN3dU6uqZUFbK0Z2yCGIMfxs3tBeg26PMxUJ4a; att=1-yhCypM1zy0pRa4hZkYP5WuKabl5TxYyRiLioSlOW; lang=en; dnt=1; guest_id=v1%3A175516465513586295; guest_id_marketing=v1%3A175516465513586295; guest_id_ads=v1%3A175516465513586295; personalization_id=\"v1_i54Wl/43qBb3wyWw5rTpnw==\"; gt=1955928444279382425; _twitter_sess=BAh7CSIKZmxhc2hJQzonQWN0aW9uQ29udHJvbGxlcjo6Rmxhc2g6OkZsYXNo%250ASGFzaHsABjoKQHVzZWR7ADoPY3JlYXRlZF9hdGwrCLNX96eYAToMY3NyZl9p%250AZCIlYTk5MTdiYmU5N2MwYWNlMDcyNDNlYmU3NGE5YzNmYTg6B2lkIiU2ZDhk%250AZGQwZmVkYjgxOWM4N2JlOTI2MzZlNjQyMDIyMg%253D%253D--32e8b8bbc3092f636d7dfdf0870d7bc3cc9c1143; auth_token=a512f85cc3d5473e0efe957edd507ef70a795325; ct0=646e440727f56a3ae48ff5c117073ff5b225a9e04a13bee1ffc4765ced1e8024ff957ed7bae4dc1098a8e9216176f2ee03d631a6a7b6ad12f518baf47f966114005d09981cb8382103691b32255af6c6; twid=u%3D1955928620771520512; ph_phc_TXdpocbGVeZVm5VJmAsHTMrCofBQu3e0kN8HGMNGTVW_posthog=%7B%22distinct_id%22%3A%220198a7ff-c624-71c1-bbfd-28d98ef752a9%22%2C%22%24sesid%22%3A%5B1755165267989%2C%220198a7ff-c623-7586-8e40-0293329c615b%22%2C1755165214243%5D%7D; cf_clearance=Hg4mn9dhWvdVIcA5VcFR1Fw8TjX4aqyESpH1HYyBzE0-1755165970-1.2.1.1-Ese9AP5TQuv.LAU6Ah_iLxp0axDGXgahTEGQI_XJ6U_ezjTFFLzo9zg1WiRbX_6yrBwRFGRpp6MFt21Ruqza0LfY_qow25dGGt5Q7Yk.mEIH13Ao5vCkYx6vUBEh0hTDw9KWlZu_158u.L0qr9YSMactfbbobwbxV1wYuTPEIdxdVN6yxxgR17Fo.7ofspnvwFv_OuM8AEgkUc8IAmbQuUINolhFHTXctXrAPJqKrDw"
# 🔍 搜索关键词(注意:中文逗号 %EF%BC%8C 已保留)
KEYWORDS = ["MeToo,AzizAnsari"] # 可添加更多,如 ["covid", "ai"]
# 💾 保存文件名
SAVE_FILE = "twitter_mee_too_aziz"
# ✅ 创建爬虫并运行
crawler = TwitterKeywordSearch(saveFileName=SAVE_FILE, cookie_str=COOKIE_STR)
crawler.main(KEYWORDS)■ 我是蒋星熠Jaxonic!如果这篇文章在你的技术成长路上留下了印记
■ 👁 【关注】与我一起探索技术的无限可能,见证每一次突破
■ 👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
■ 🔖 【收藏】将精华内容珍藏,随时回顾技术要点
■ 💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
■ 🗳 【投票】用你的选择为技术社区贡献一份力量
■ 技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!