双向链表
链表的作用就是按照访问的时间顺序,无论单链表或双链表都如此。我们在单链表的例子看到,维护单链表通常离不开从头部节点开始遍历的操作,尽管有许多巧妙的优化办法,但是只要从链表中查找某个元素(随机访问),必然还是离不开遍历操作。有鉴于此,我们希望可以常数时间内(O(1))随机访问元素,这样就很容易想到 HashMap 了,没错,就是要让 HashMap 加入进来使用。另外,有人问,直接用 HashMap 不行么?HashMap 本身无顺序,而且要定位某个元素,还是要遍历这个 Map。
至于双向链表(Double Linked List),插入、删除更简单,关键双向链表的操作基本都是 O(1) ,更快了,这里我们就毫不客气地使用了。另外,有人问,单纯用双链表不行么?也可以但改进的意义不大,查找元素还是得遍历。 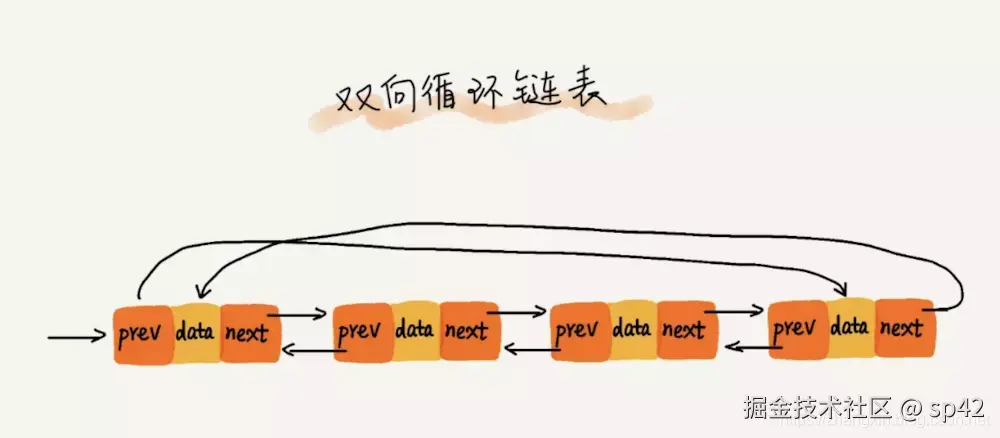 关于各个选型的时间复杂度比较
关于各个选型的时间复杂度比较
- 单链表:O(n)
- 单链表 + HashMap:O(n) 意义不大
- 双向链表:部分 O(1),查找元素还是得遍历 O(n)
- 双向链表+ HashMap:O(1)
- HashMap:访问 O(1),但遍历 O(n)
- 队列:队列只能做到先进先出,但是重复用到中间的数据时无法把中间的数据移动到顶端
下一步的优化方法便是采用双向链表+ HashMap。
java
public class LRUCache<K, V> {
static class Node<K, V> {
K key;
V value;
Node<K, V> pre;
Node<K, V> next;
public Node(K key, V value) {
this.key = key;
this.value = value;
}
}
private HashMap<K, Node<K, V>> map;
private int capicity, count;
private Node<K, V> head, tail;
/**
*
* @param capacity 缓存容量
*/
public LRUCache(int capacity) {
this.capicity = capacity;
map = new HashMap<>();
head = new Node<>(null, null);
tail = new Node<>(null, null);
head.next = tail;
head.pre = null;
tail.pre = head;
tail.next = null;
count = 0;
}
/**
* 加到头部
*
* @param node
*/
public void addToHead(Node<K, V> node) {
node.next = head.next;
node.next.pre = node;
node.pre = head;
head.next = node;
}
/**
* 删除节点
*
* @param node
*/
public void deleteNode(Node<K, V> node) {
node.pre.next = node.next;
node.next.pre = node.pre;
}
public V get(int key) {
if (map.get(key) != null) {
Node<K, V> node = map.get(key);
V result = node.value;
deleteNode(node);
addToHead(node);
return result;
}
return null; // 找不到
}
public void set(K key, V value) {
System.out.println("Going to set the (key, value) : (" + key + ", " + value + ")");
if (map.get(key) != null) { // 已存在
Node<K, V> node = map.get(key);
node.value = value;
deleteNode(node);
addToHead(node);
} else {// 插入新的
Node<K, V> node = new Node<>(key, value);
map.put(key, node);
if (count < capicity) {
count++;
addToHead(node);
} else { // 满了
map.remove(tail.pre.key);
deleteNode(tail.pre);
addToHead(node);
}
}
}
}掌握了前面的这些基础,再回头来看看双向链表(Double Linked List),感觉轻松简单多了。
浓缩版
就是 LinkedHashMap 啦,网上一堆介绍,笔者就不重复了。
java
import java.util.LinkedHashMap;
import java.util.Map;
/**
* Created by liuzhao on 14-5-15.
*/
public class LRUCache2<K, V> extends LinkedHashMap<K, V> {
private final int MAX_CACHE_SIZE;
public LRUCache2(int cacheSize) {
super((int) Math.ceil(cacheSize / 0.75) + 1, 0.75f, true);
MAX_CACHE_SIZE = cacheSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > MAX_CACHE_SIZE;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
for (Map.Entry<K, V> entry : entrySet()) {
sb.append(String.format("%s:%s ", entry.getKey(), entry.getValue()));
}
return sb.toString();
}
}带锁的线程安全的 LRULinkedHashMap 简单实现 blog.csdn.net/a921122/art...
参考文献
www.cnblogs.com/dolphin0520... my.oschina.net/zjllovecode... www.jianshu.com/p/b1ab4a170... www.sohu.com/a/298778364... www.geeksforgeeks.org/design-a-da... blog.csdn.net/qq_34417408... 分离链表结构和 lru