redis中的不同线程
redis单线程是指什么?
redis的所有命令处理都在同一个线程中完成
redis为什么采用单线程?
redis中存在多种数据结构存储value,如果采用多线程,加锁会很复杂、加锁力度不阿红控制,同时,采用多线程涉及频繁的cpu上下文切换,抵消多线程的优势。

redis 存储结构
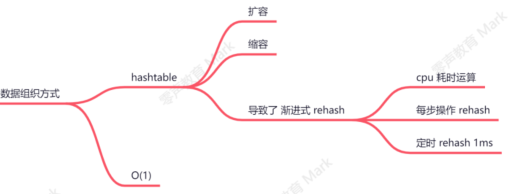
redis采用hashtable组织其存储的kv数据
hashtable字典实现
redis 中 hashtable 组织是通过字典来实现的;hash 结构当节点超过 512 个或者单个字符串长度大于 64 时,hash 结构采用字典实现
数据结构
cpp
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictht {
dictEntry **table;
unsigned long size;// 数组长度
unsigned long sizemask; //size-1
unsigned long used;//当前数组当中包含的元素
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error)
用于安全遍历*/
} dict;冲突
抽屉原理 :n+1个苹果放在 n 个抽屉中,苹果最多的那个抽屉至少有 2 个苹果;64位整数远大 于数组的长度,比如数组长度为 4,那么 1、5、9、1+4n 都是映射到1号位数组;所以大概 率会发生冲突
抽屉就是hashtable,苹果就是对应k-v对。
负载因子
负载因子 = used / size ;
used 是数组存储元素的个数,size是hashtable大小
负载因子越小,冲突越小;负载因子越大,冲突越大;
redis 的负载因子是 1;
扩容
如果负载因子 > 1,为了避免频繁的hash冲突,则会发生扩容,即申请一个新的的数组;扩容的规则是翻倍;
如果正在 fork(在 rdb、aof 复写以及 rdb-aof 混用情况下)时,会阻止扩容;但是此时若负载 因子 > 5,索引效率大大降低, 则马上扩容;这里涉及到写时复制原理
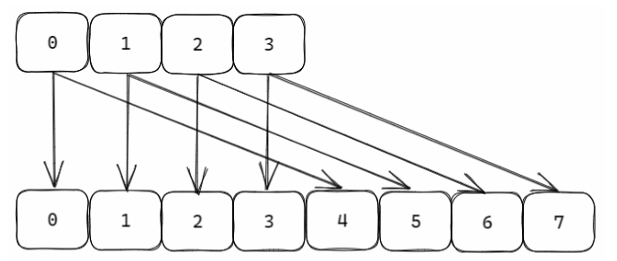
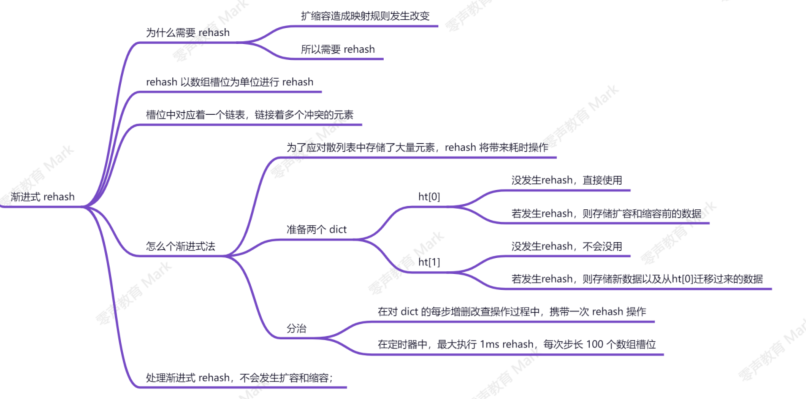
扩容后的渐进式rehash
rehash的原因
扩容后,hashtable的size发生改变,基于原来size的映射规则不在适用
rehash步骤
将 ht0 中的元素重新经过 hash 函数生成 64 位整数,再对 射到 ht 1 ;
渐进式rehash的原因
当 hashtable 中的元素过多的时候,不能一次性 rehash 到 ht1 ;这样会长期占用 redis,其他 命令得不到响应;所以需要使用渐进式 rehash;
渐进式规则
-
分治的思想,将 rehash 分到之后的每步增删改查的操作当中;
-
在定时器中,最大执行一毫秒 rehash ;每次步长 100 个数组槽位;
处于渐进式 rehash 阶段时,不会会发生扩容缩容
缩容
如果负载因子 < 0.1 ,则会发生缩容;缩容的规则是恰好 包含 used 的 ;
恰好 的理解:假如此时数组存储元素个数为 9,恰好包含该元素的就是 ,也就是 16;
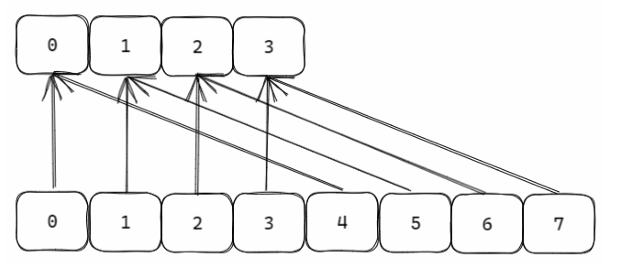
redis-value存储转换
跳表
理想跳表到概率跳表

redis跳表

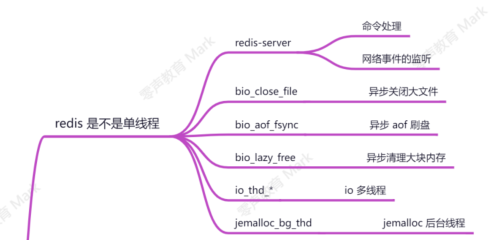
redis IO多线程处理
为什么要采用IO多线程?
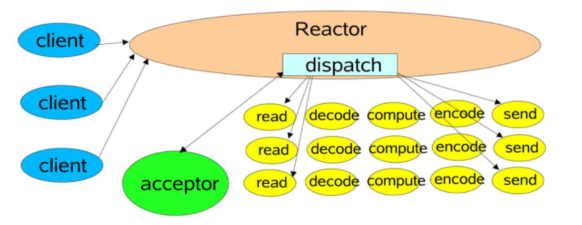
多个连接同时发送数据到redis时,会导致IO密集操作(read和send)和cpu密集型操作(decode和encode),如果采用单线程处理,就只能串行的处理每个连接的数据,但是read、decode、encode和send是可以并行执行的。
处理流程
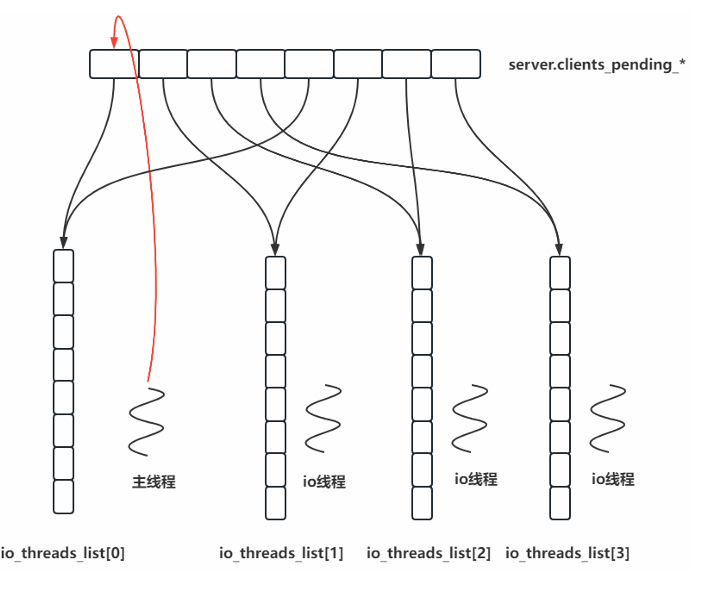
1.主线程将IO密集型任务和cpu密集型任务放入全局队列中,并分配给每个IO线程并行执行。
2.所有的命令处理由一个线程单独执行
3.结果处理再交由每个IO线程执行。
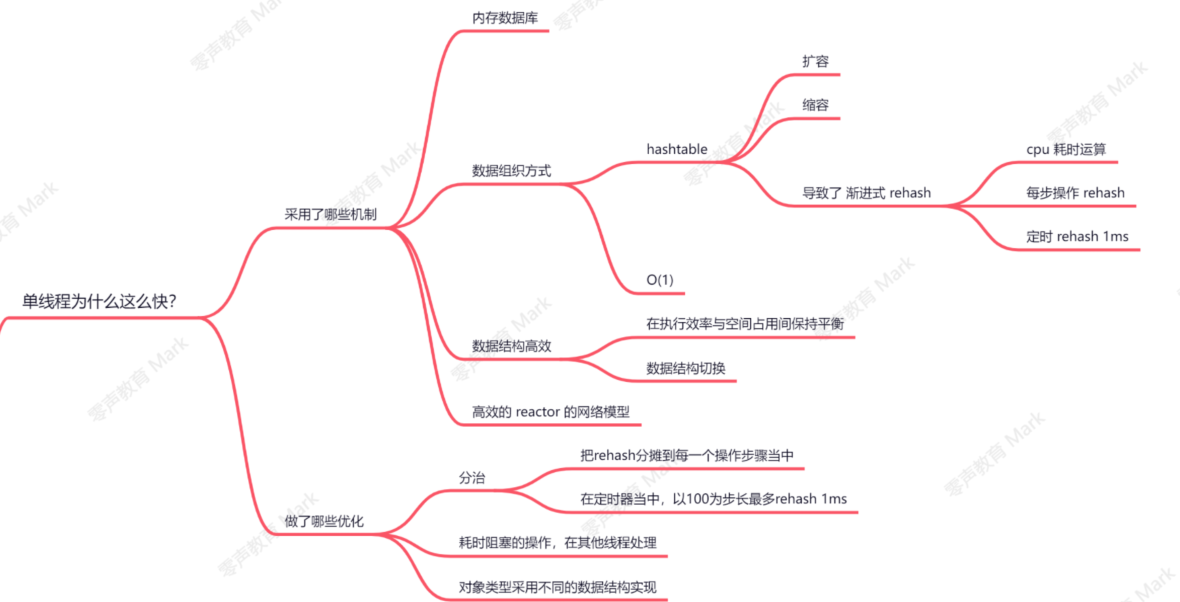
redis的单线程为什么高效?
1.采用hashtable,使其增删改查操作时间复杂度为O(1),同时采用渐进式rehash,避免长时间对redis的占用。
2.对不同value采用高效的数据结构,同时基于节点数量会对数据结构进行切换。
3.采用高效的reactor网络模型,基于IO多路复用,实现对网络多客户端连接的快速响应。
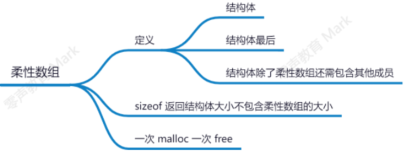
柔性数组