复盘不是重述过去,而是设计未来;每一次总结,都是进步的加速器。
📌 提示: 复盘的目的是什么
1. 事故概要
| 发生时间 | 2025-xx-xx 17:09:39 ~ 2025-xx-xx 17:23:54 (14min15s) |
|---|---|
| 影响系统 | xxx |
| 影响范围 | xxx |
| 责任人 | xxx |
| 严重性等级 | Px |
| 报告日期 | xxx |
2. 摘要
本次事故由于 简要原因 导致 系统名称 出现服务中断,持续约14分钟,影响范围包括 关键业务。故障由 发现方式 触发告警,应急响应及时启动,于17:23恢复服务。根本原因为 一句话根因。已制定X项改进措施,涵盖流程规范、监控告警与应急预案等方面,预计在时间前完成闭环。
3. 事故分析
2.1. 时间线梳理
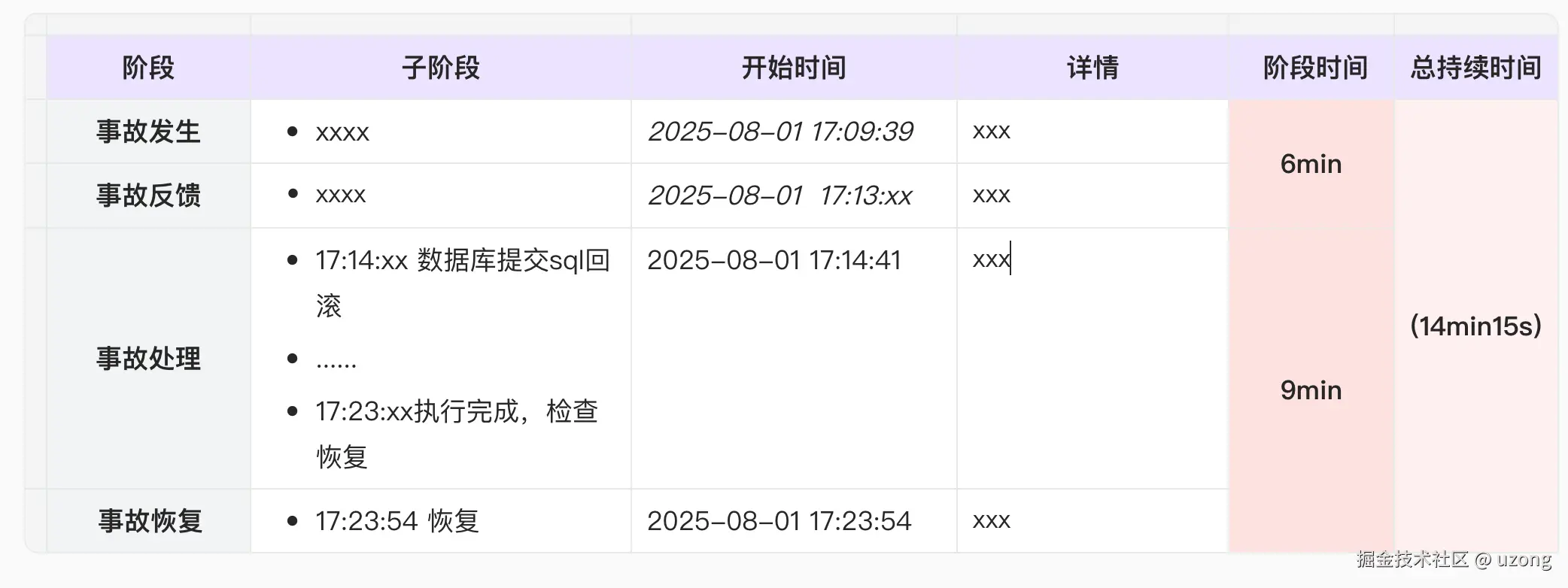
📌 提示: 反映整个故障的时间线,越详细越好,能够基于整个过程进行梳理,同时也能够更好的优化过程。
关键点: 时间精确到分钟,记录所有关键决策、操作、沟通和观察到的现象。
2.2. 事故响应过程
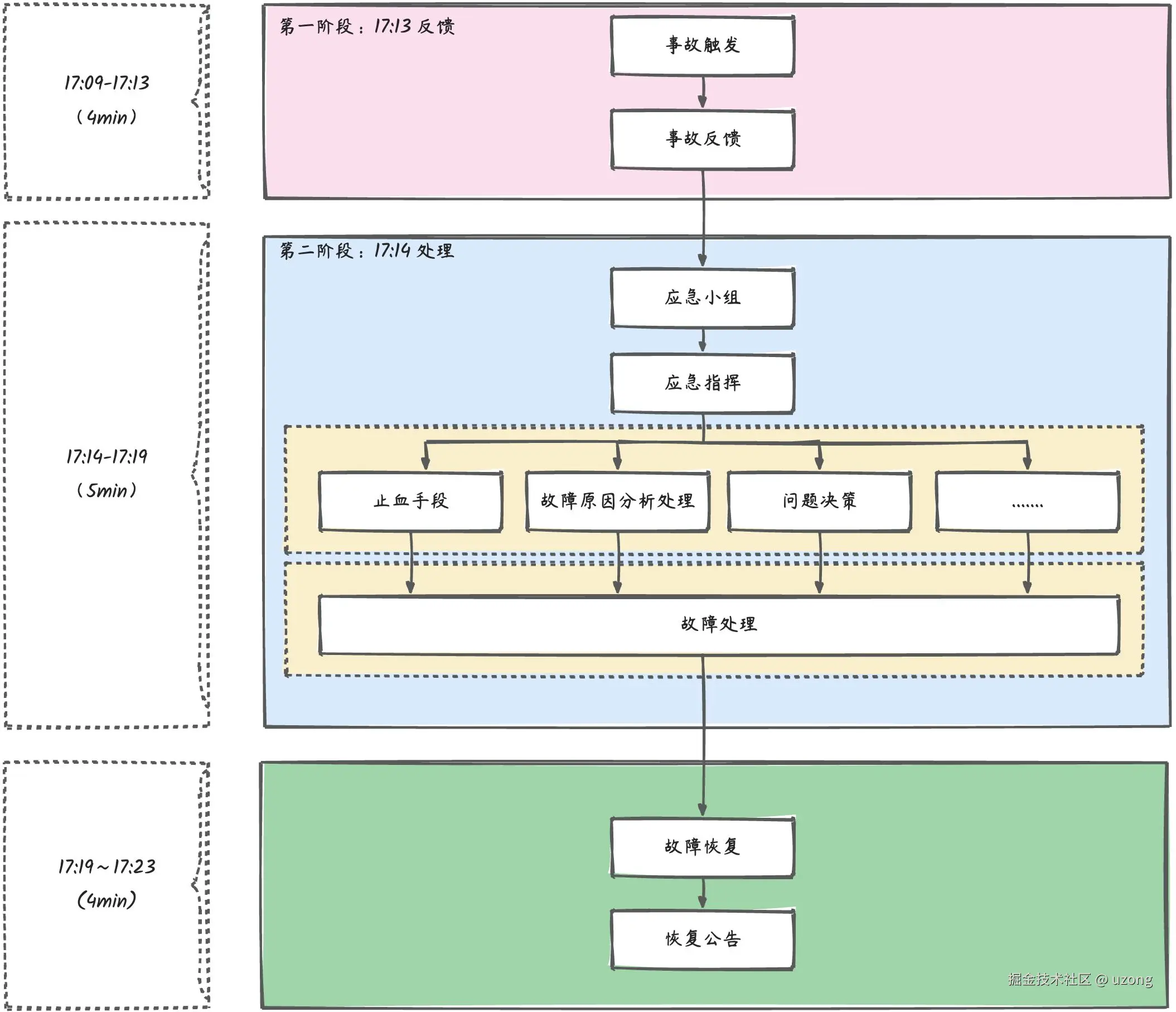
tips:响应过程,根据实际情况给出,针对大型故障会更加复杂。
故障是如何被发现的(监控告警 / 用户反馈 / 内部测试)
- 第一时间通知了哪些人, 通过什么方式(IM群、电话、邮件)
- 是否启动了应急响应机制
- 是否有应急指挥人
- 跨团队协作情况如何
- 是否存在沟通延迟
- 信息同步是否及时
- 对内对外通报机制是否有效
2.3. 事故根因分析
根因总结:"在未充分评估SQL性能的情况下,...... ,最终导致服务不可用"
tips 一句话概括
故障原因剖析(详细部分)
一般从流程、技术层面、人为因素、系统等多个层面考虑
- 直接原因:xxx
- 根本原因:xxx
- 潜在原因: xxx
| 层级 | 问题 | 回答 |
|---|---|---|
| Why 1 | 为什么服务不可用? | API响应超时,调用方堆积 |
| Why 2 | 为什么API超时? | 数据库连接池被打满 |
| Why 3 | 为什么连接池被打满? | 出现大量长事务 |
| Why 4 | 为什么有长事务? | 执行了无索引条件的DELETE语句 |
| ...... | ...... | ...... |
分析方法建议: 可使用 5 Whys (连续问5个"为什么") 或 鱼骨图 (Ishikawa Diagram) 等方法进行深入挖掘。
2.4. 行为规范分析
| 规范和流程 | 行为 | 是否规范 |
|---|---|---|
| SQL变更执行是否先线下再线上 | - xxx | 是 |
| SQL变更完是否验证 | - xxx | 是 |
| SQL 变更操作是否低峰时间段 | - xxx | 否 |
| SQL 清理逻辑不完备 | - xxx | 否 |
| ...... | ...... | ...... |
📌 提示: 从流程规范进行总结
4. 影响评估
4.1. 业务影响
| 项目 | 描述 |
|---|---|
| 影响用户数 | 约 52,000 人 |
| 订单失败数 | 峰值期间失败率 38% |
| 损失预估 | 直接营收影响约 ¥120,000(估算) |
| ..... | ...... |
4.2. 技术影响
| 影响项 | 具体描述 |
|---|---|
| - 数据异常率 | xxx |
| - xxx | xxx |
例如:统计数据异常
4.3. 客户影响
......
5. 经验教训
总结从本次故障中获得的关键认知。
从流程、技术、监控、应急等多个维度梳理
-
例如:压力测试是上线前不可或缺的环节。
-
例如:监控告警需要覆盖核心业务链路的关键指标。
-
例如:应急预案需要定期演练以确保有效性。
-
例如:变更管理流程必须严格执行。
- ......
6. 改进措施
针对根本原因和经验教训,制定具体的、可衡量的、可执行的改进措施,并明确负责人和完成时间
| 分类 | 项目 | 改进措施 | 负责人 | 预计完成时间 | 状态 |
|---|---|---|---|---|---|
| 流程规范 | xxx | - xxx | |||
| xxx | - xxx | ||||
| xxx | - xxx | ||||
| 技术层面 | xxx | - xxx | |||
| 故障响应 | xxx | - xxx | |||
| ...... | xxx | - xxx |
****📌 提示: 改进措施一定是有一定计划和措施的。而不是空谈感想
| ### 后续文档建设计划 | 目的 | 负责人 | 完成时间 |
|---|---|---|---|
| 回滚手册 | ...... | xxx | ...... |
| 核心服务恢复手册 | ...... | xxx | ...... |
| 故障排查手册 | ...... | xxx | ...... |
| 故障规范手册 | ...... | xxx | ...... |
| ...... | ...... | ...... | ...... |
7. 总结和反思
- 事故前(避免):核心服务,任何变更增加评审(sql、代码、配置等),可能会导致一些间接影响。
- 事故后(快速):有故障恢复的SOP,增加事故解决效率
总结和反思不是终点,而是对生产系统的敬畏。规范流程的同时也需要提升故障解决效率
8. 附件 (Appendices) (可选)
- 相关日志片段
- 监控图表截图
- 告警通知记录
- 沟通记录(邮件、IM截图等)
- 相关代码变更记录 (Commit ID)
- 详细技术分析报告
9. 开放建议与后续行动项
开放讨论与建议收集,并给出具体的一些后续 Action
| 类型 | 内容 | 提出人 | 负责人 | 状态 | 备注 |
|---|---|---|---|---|---|
| 建议 | 建立变更沙箱环境,模拟高风险操作 | 架构组 | xxx | 待评估 | ...... |
| 行动 | 组织一次故障演练(GameDay) | 运维组 | xxx | 进行中 | ...... |
| 建议 | 监控告警增加业务维度标签 | SRE | xxx | 已采纳 | ...... |
10. 复盘原则
- 复盘的目的是学习和改进,避免指责个人。
- 尽可能使用数据和事实来支撑分析和结论
- 故障解决后尽快启动复盘,趁记忆清晰
- 严格跟踪改进行动计划的执行,确保措施落地
- 无责复盘(blameless postmortem)、避免情绪化词汇,坚持"无责文化",聚焦系统而非个人