做股票量化建模的朋友对 Qlib 应该都不陌生。作为微软开源的一款量化研究框架,Qlib 可以说是把"数据驱动建模"这件事做到极致了,尤其在以下几个方面非常出色:
- 提供了一整套 Alpha、模型、回测、评估流水线
- 原生支持机器学习模型(LightGBM、XGBoost、RNN、Transformer)
- 可与自定义数据源对接,构建灵活的预测平台
- 数据、特征、训练、预测、回测一站式搞定
但是,Qlib 自带的数据并不适合实盘研究
Qlib 虽然开箱即用,但它自带的数据是"为了教学、方便演示"准备的,主要问题有以下几点:
- 滞后严重:官方数据只更新到几年前,适合教学,但不适合做近期实盘策略研究
- 字段有限:只有基础的 OHLCV 数据,连 amount、换手率都没有
- 非主流行情源:不是直接来自交易所或主流券商,可能存在偏差
如果你真的想基于 A 股市场做实盘预测或策略训练,肯定得换自己的数据源。
替代方案:用 MiniQMT 下载行情数据,再导入 Qlib!
很多做量化的朋友已经用上了 MiniQMT ------ 它是一个轻量、高性能、接口友好的行情采集工具,可以从 QMT 接口抓取真实市场的 行情数据,并支持导出为 CSV 文件,非常适合我们拿来喂给 Qlib!
那么问题来了:
MiniQMT 拉下来的 CSV,怎么导入 Qlib 呢?
别急,我下面手把手教你做一遍,并附上完整示例代码
整体思路
把 MiniQMT 导出的行情数据(CSV),标准化格式 → 转换为 Qlib 的内部格式(bin) → 加载进 Qlib,就可以直接用来训练模型、跑回测啦!
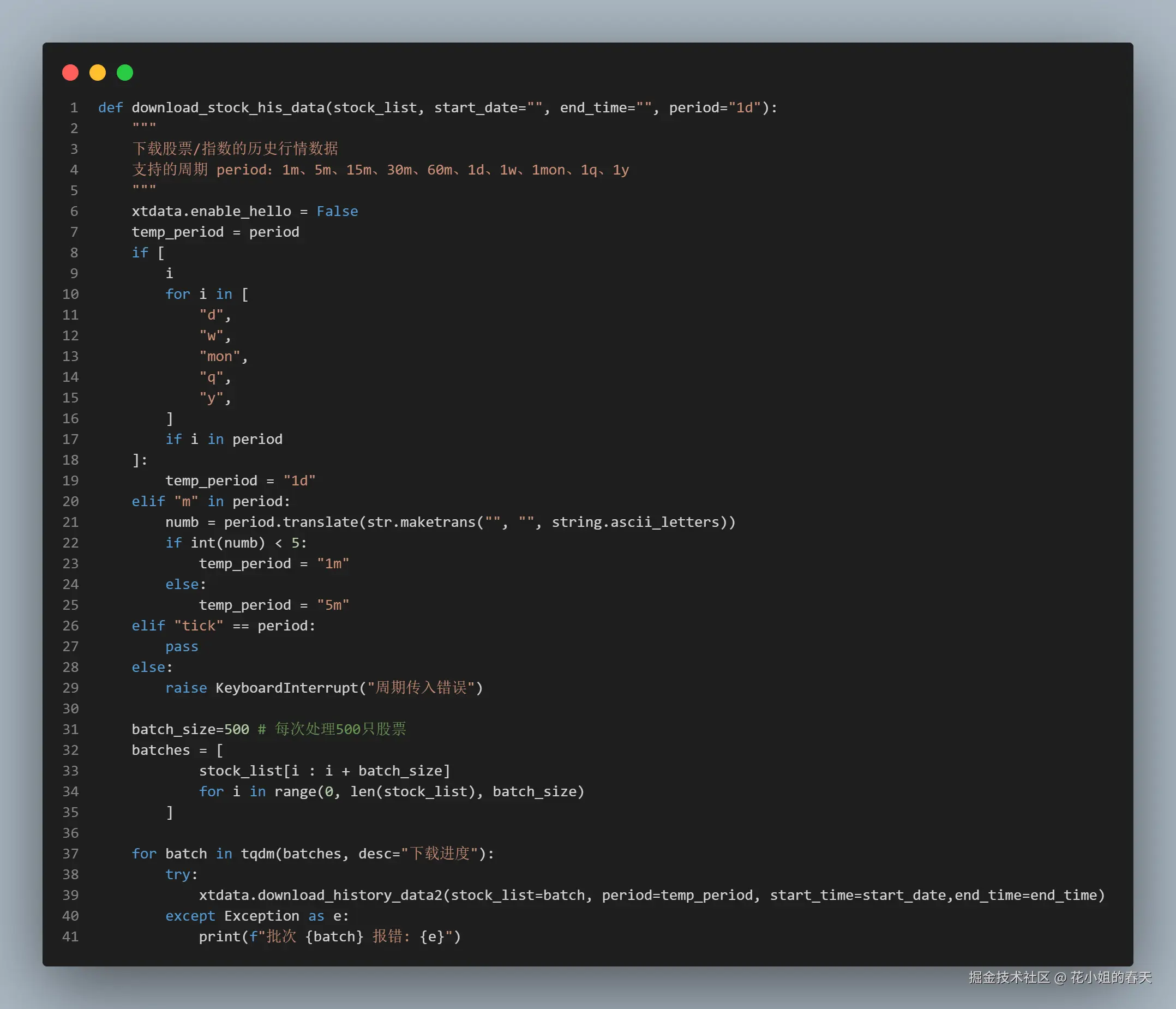
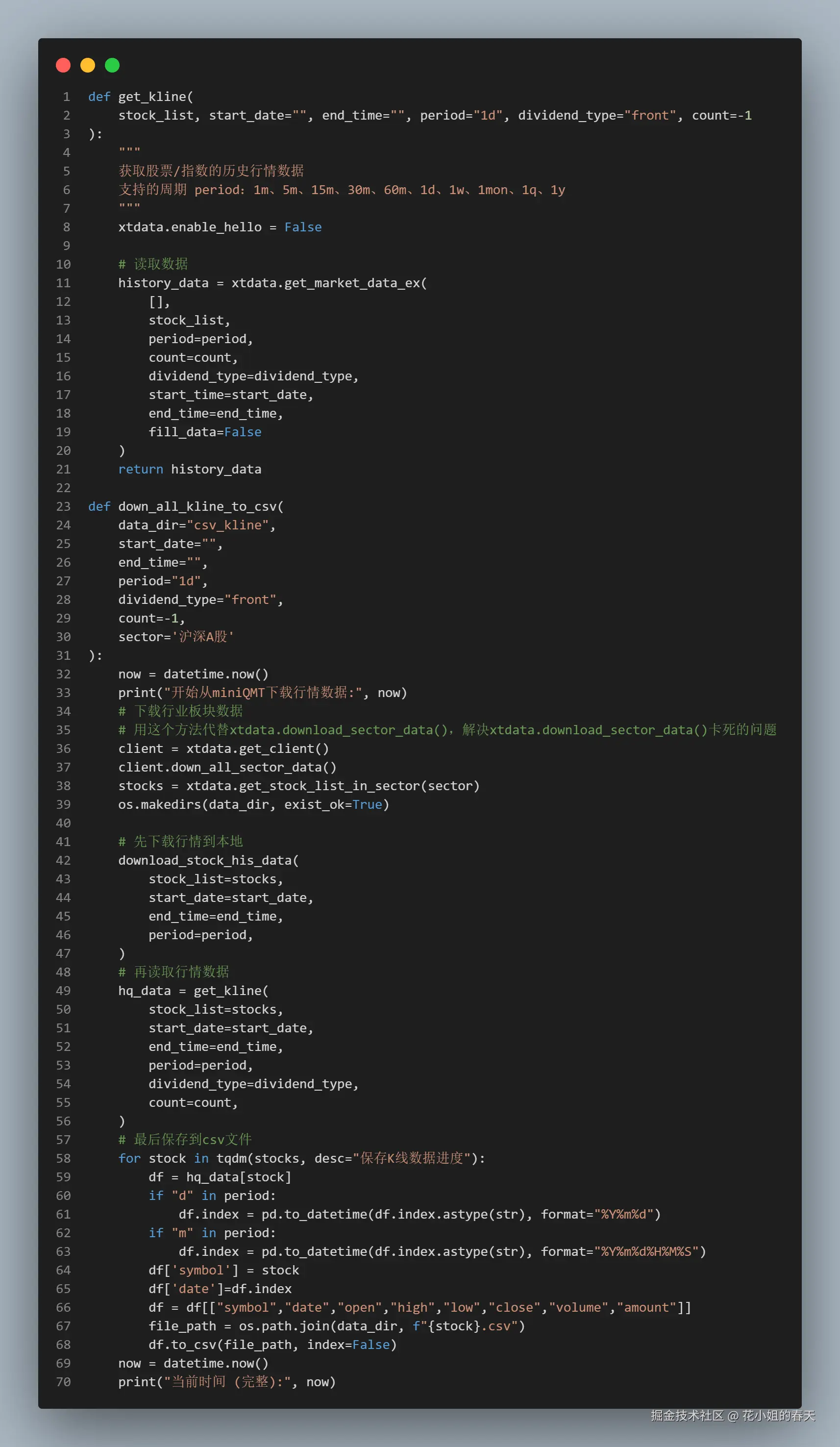
Step 1:数据下载
要通过miniQMT获取行情数据首先需要下载,这里我直接写成了一个方法,传入股票列表,开始时间、结束时间和周期即可,如果要下载全部周期的分钟和日线行情,只需要下载1d、1m、5m周期的行情以后,就可以在后面获取1m、5m、15m、30m、60m、1d、1w、1mon、1q、1y的行情了
Step 2:行情获取
数据下载以后,我们就可以把行情导出csv文件了,这里同样我写了对应的方法 get_kline 用于获取股票的行情 down_all_kline_to_csv用于把行情转换成csv格式 最后直接调用
python
down_all_kline_to_csv(sector='沪深300',
start_date="20190101",
end_time="",
period="1d",
data_dir="csv_kline")就可以把行情下载到项目根目录下的csv_kline文件夹里了
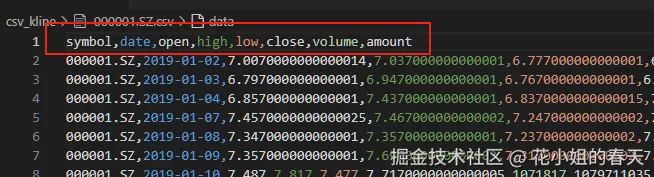
在存储csv文件的时候需要注意下,文件名一定要改成股票代码 ,同时csv里面也要有一列用来存股票代码,我这里用的是symbol 列,同时也需要有一列来记录行情对应的日期,我这里是date
这是对应的方法源码:
Step 3:编写转换脚本,导入 Qlib 数据目录
这是官方给出的教程:
https://qlib.readthedocs.io/en/latest/component/data.html#converting-csv-format-into-qlib-format
里面提出可以使用以下脚本来实现csv数据导入Qlib
python
python scripts/dump_bin.py dump_all --csv_path ~/.qlib/csv_data/my_data --qlib_dir ~/.qlib/qlib_data/my_data --include_fields open,close,high,low,volume,factor按照官方的Qlib安装教程,大家估计用的都是
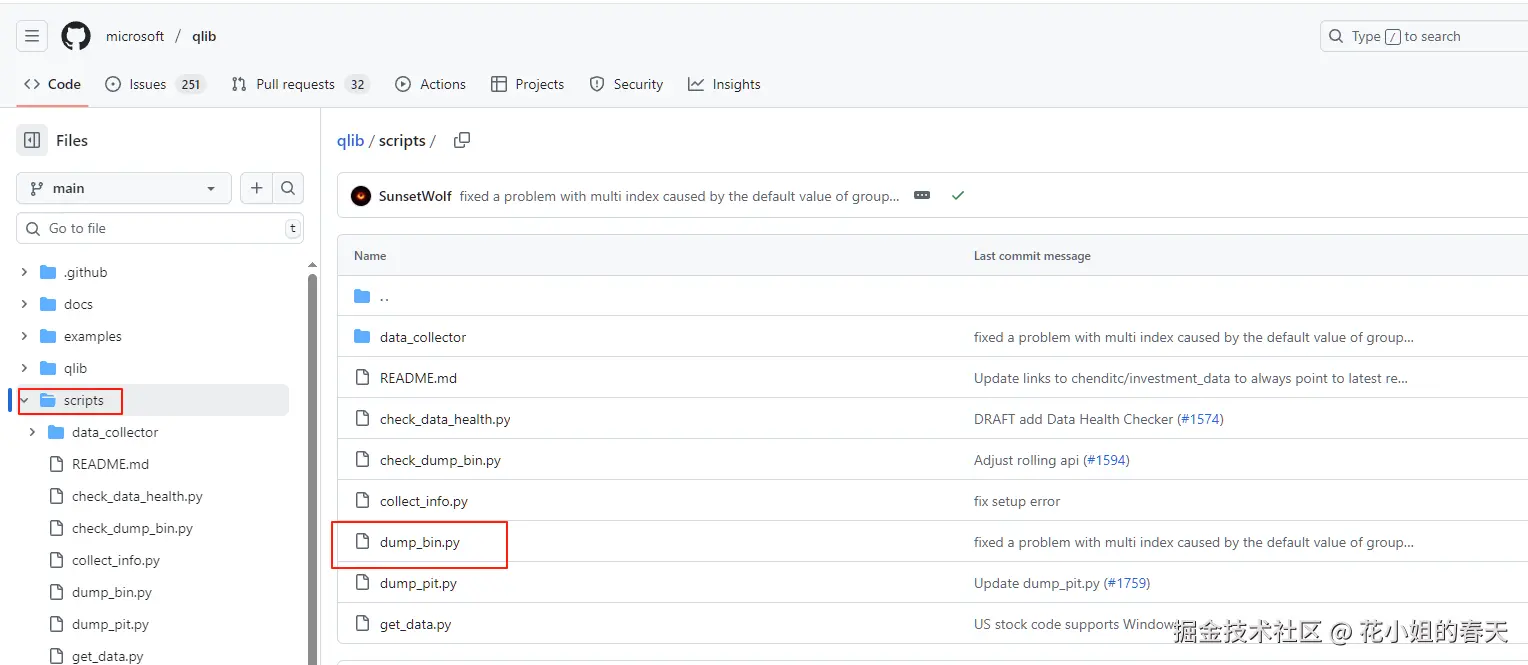
pip install pyqlib在执行python scripts/dump_bin.py dump_all......就会比较懵,这dump_bin.py哪来的呀!

我们打开Qlib的git地址,就会发现原理他在这里
然后我把dump_bin,py复制到了我的项目根目录
然后写下如下代码就可以轻松把数据导入到Qlib了
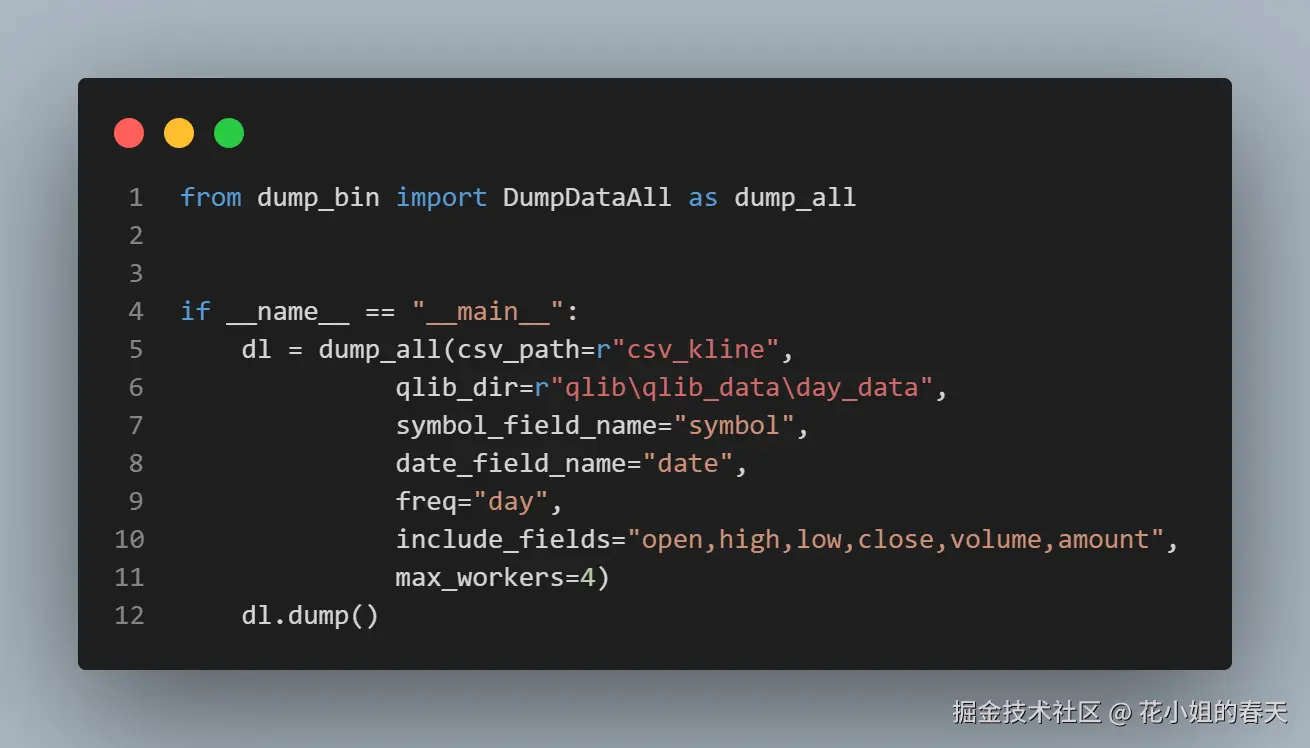
这里的csv_path就是csv行情文件的存放目录
- qlib_dir是qlib数据保存的目录
symbol_field_name表示你股票代码存放的列名date_field_name表示日期列对应的列名freq是行情周期include_fields表示你的数据要包括哪些列max_workers表示要用几个线程来执行
到此数据就从csv格式转换成Qlib需要的格式了
最后分享一个简单的demo

模型训练好以后,就会在根目录生成一个mlruns的目录,里面有对应的模型可以使用。