什么是LLM大语言模型
核心概念
定义:基于海量数据训练的深度学习模型,可处理文本/音频/视频等多模态输入并生成输出。
简单理解:大语言模型(LLM)就是个「吃书长大的话痨学霸」 🤓📚💬
它像一只 吞了全世界图书馆的电子鹦鹉 🦜,你问它啥,它都能从肚子里(其实是神经网络)掏出一串像模像样的回答,甚至能写诗、编代码、装莎士比亚...
但小心!它偶尔会一本正经地胡说八道 😅(比如告诉你"番茄是蓝色的" ------ 因为它只"读书"没亲手摸过番茄)。
核心特征:训练数据大和参数量大
- 训练数据规模巨大(TB级语料)
- 参数量级庞大(百亿至万亿级)
- 上下文窗口长(如GPT-3.5支持16K tokens)
基础单位(Token)
-
定义:文本处理的最小单元,是模型计算长度的基础
-
特性:
- 汉字处理:1个汉字 ≈ 1.5个token(可能是字/词/部分汉字)
- 长度计算:上下文长度基于token计数(如16K tokens ≠ 16K字符)
-
词表(Vocabulary) :
- 功能:存储所有token与ID的映射关系
- 语言差异:
- 英文词表:字母+标点符号(约数百token)
- 中文词表:汉字+词汇(数千至数万token)
以下是一个词汇表(vocab)的片段示例,展示了token到id的映射关系。包括特殊符号、字节token、英文token和中文token等
python
{
"vocab": {
# 特殊符号部分
"<unk>": 0, # 未知符号占位符
"<|startoftext|>": 1, # 文本起始标记
# 字节token(用于处理特殊字符)
"<0x00>": 305, # 十六进制00的字节表示
"<0x01>": 306, # 十六进制01的字节表示
# ...(其他字节token)
# 英文token(带_前缀表示单词开头)
"ct": 611, # 普通英文片段
"__re": 612, # 单词开头片段(如"re"开头)
# ...(其他英文token)
# 中文token
"安徽省": 28560, # 中国省份名称
"子和": 28561, # 中文词汇片段
# ...(其他中文token)
}
}工作原理
(1) 文本生成流程
graph LR
A[输入文本] --> B(Token化)
B --> C[向量编码]
C --> D[神经网络计算]
D --> E[概率预测]
E --> F[Token生成]
F --> G[输出文本]
graph LR
A[输入文本: "你是谁"] --> B[词表转换]
B --> C[Token ID序列: 154, 5412, 15]
C --> D[参数计算]
subgraph Transformer模型
D --> E[多层自注意力<br>前馈神经网络]
end
E --> F[输出概率分布:<br>0.015, 0.0025, 0.005,...]
F --> G[选择概率最大的Token]
G --> H[输出新Token]
H --> I[叠加到输入序列]
I --> D
H --> J[最终输出文本]
以下是大模型(如Transformer)工作原理的图示说明。图中展示了从输入到输出的自回归生成过程: 
(2) 预测机制
1.统计预测:基于历史数据计算下一个token的概率分布
何快速预测下一个 token 是什么呢?一种最简单的办法就是基于统计,通过大量数据的统计,找到下一个 token。
- 采集大量文本进行扫描计算,并记录所有片段的输入以及下 一个文本出现的次数,得到一张巨大的分布表。
- 将输入的文本对照分布表查询,找到所有 token 的出现次数 或概率,找到出现次数最大的 token 即为预测结果。
2.机器学习预测:
- 文本→向量转换
- 计算向量间概率/距离
- 选择最高概率token
graph LR
A[输入文本<br>"肚子饿了"] --> B[Token转换<br>"肚"→123<br>"子"→456<br>"饿"→789<br>"了"→101]
B --> C[模型计算概率分布]
C --> D["怎么办":31%]
C --> E["吃什么":24.3%]
C --> F["为什么":15%]
E --> G[选择Token 243<br>"吃什么"]
G --> H[新输入序列<br>123+456+789+101+243]
H --> I[最终输出<br>"肚子饿了吃什么"]

训练流程
- 1.训练过程包括初始化模型参数、输入训练数据、计算损失、更新参数、判断停止条件等步骤。
- 2.训练过程中使用梯度下降等方法更新模型参数,最终得到准确的模型参数。
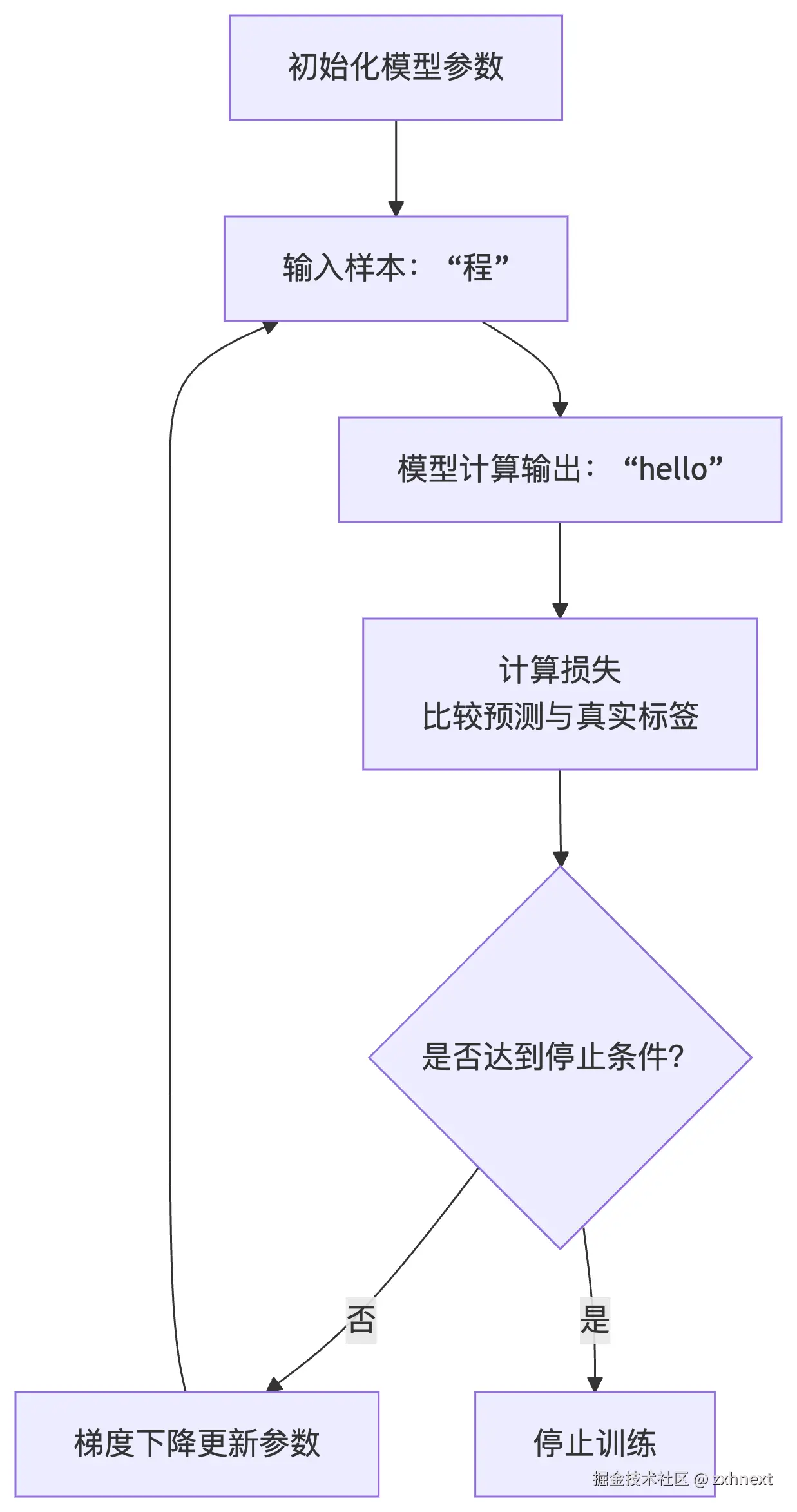
graph TD
A[初始化模型参数] --> B[输入样本: "程"]
B --> C[模型计算输出: "hello"]
C --> D[计算损失<br>比较预测与真实标签]
D --> E{是否达到停止条件?}
E -- 否 --> F[梯度下降更新参数]
F --> B
E -- 是 --> G[停止训练]
5. 核心局限性
| 限制类型 | 具体表现 |
|---|---|
| 实时性 | 无法获取互联网实时数据 |
| 数据依赖 | 仅能基于公开语料库回答 |
| 环境交互 | 默认无法主动访问外部系统 |
| 数学能力 | 复杂数学问题准确率低 |
| 可靠性风险 | 可能输出虚假/错误信息 |
| 长上下文处理 | 复杂上下文易出现逻辑断裂 |
| 交互适配 | 需集成到软件作为AI智能体 |
二、LLM应用开发关键概念
1. 核心术语
| 术语 | 定义 | 关键特征 |
|---|---|---|
| AIGC | AI生成内容 | 支持文字/图像/音频/视频生成,ChatGPT是其对话场景实现 |
| AGI | 人工通用智能 | 终极目标,具备类人的理解/学习/应用能力(非仅内容生成) |
| Agent | 智能代理 | 自主感知环境并执行任务的计算实体(如自动驾驶系统) |
| Prompt | 提示词 | 人机交互的核心媒介,引导模型生成响应 |
| LoRA | 插件式微调 | 低秩矩阵分解技术(W≈ABᵀ),显著降低微调成本 |
| 向量数据库 | 非结构化数据存储 | 支持图像/音频/文本的相似性检索(如人脸识别) |
| 数据蒸馏 | 数据浓缩技术 | 将大数据集提炼为小数据集,保持模型效果同时降低训练成本 |
2. 新一代交互模式
| 模式 | 特点 | 典型场景 |
|---|---|---|
| 嵌入模式 | AI作为工具,人类主导决策 | 内容创作(小说/3D设计) |
| 副驾驶模式 | 人机协同工作 | GitHub Copilot编程辅助 |
| 智能体模式 | AI自主完成任务 | AutoGPT自动目标拆解与执行 |