🎯表格总结
把定义、核心特征、常见算法和典型应用场景都放进来,一眼就能看懂它们的区别与联系------
| 类别 | 定义 | 核心特征 | 常见算法 | 典型应用场景 |
|---|---|---|---|---|
| 监督学习 (Supervised Learning) | 在带有已知标签(目标值)的数据上训练模型,让模型学会预测输出 | - 有"老师"指导 - 输入与输出一一对应 - 目标是最小化预测误差 | - 线性回归(Linear Regression) - 逻辑回归(Logistic Regression) - 支持向量机(SVM) - 决策树(Decision Tree) - 随机森林(Random Forest) - XGBoost / LightGBM - 神经网络(Neural Network) | - 房价预测 - 垃圾邮件分类 - 图像识别(猫/狗分类) - 销量预测 |
| 非监督学习 (Unsupervised Learning) | 在无标签数据中寻找模式或结构 | - 无"老师"指导 - 只输入数据,不知道正确答案 - 目标是发现数据的潜在结构 | - 聚类(K-Means、层次聚类) - 主成分分析(PCA) - 关联规则(Apriori) - 高斯混合模型(GMM) - 自编码器(Autoencoder) | - 客户分群 - 购物篮分析(关联商品) - 降维与可视化 - 异常检测 |
💡 记忆小窍门
-
监督学习 :有"标准答案",目标是预测
-
非监督学习 :没"标准答案",目标是发现结构
-
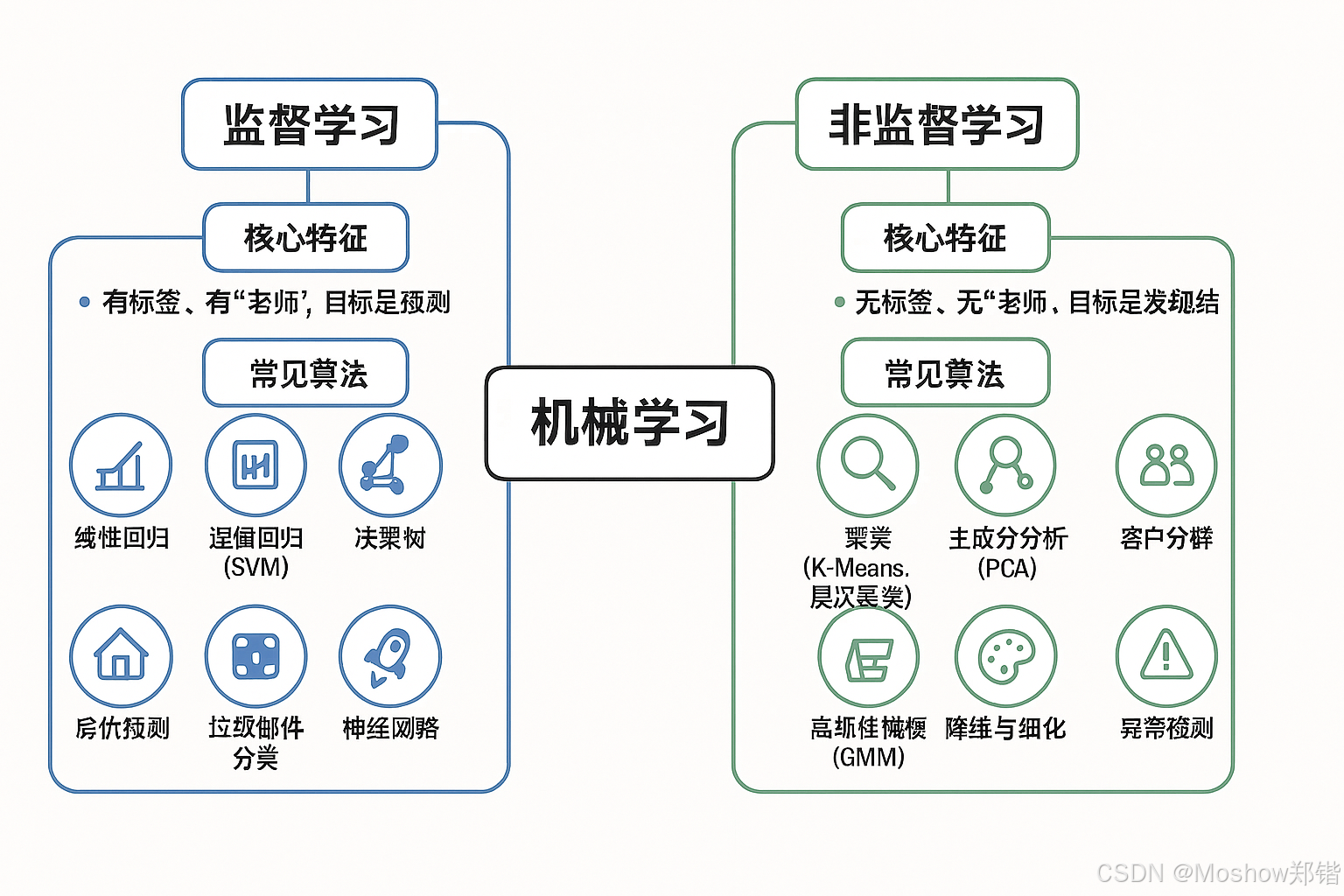
📌思维导图
bash
🎯 机器学习
│
├── 🔵 监督学习 (Supervised Learning)
│ │
│ ├── 🎯 核心特征 → 有标签、有"老师"、目标是预测
│ │
│ ├── 🧩 常见算法
│ │ ├─ 📈 线性回归(Linear Regression)
│ │ ├─ 📊 逻辑回归(Logistic Regression)
│ │ ├─ 📏 支持向量机(SVM)
│ │ ├─ 🌳 决策树(Decision Tree)
│ │ ├─ 🌲 随机森林(Random Forest)
│ │ ├─ 🚀 XGBoost / LightGBM
│ │ └─ 🧠 神经网络(Neural Network)
│ │
│ └── 📌 典型应用
│ ├─ 房价预测 🏠
│ ├─ 垃圾邮件分类 📧
│ ├─ 图像识别 📷
│ └─ 销量预测 📦
│
└── 🟢 非监督学习 (Unsupervised Learning)
│
├── 🎯 核心特征 → 无标签、无"老师"、目标是发现结构
│
├── 🧩 常见算法
│ ├─ 🔍 聚类(K-Means、层次聚类)
│ ├─ 🔎 主成分分析(PCA)
│ ├─ 🛒 关联规则(Apriori)
│ ├─ 📈 高斯混合模型(GMM)
│ └─ 🌀 自编码器(Autoencoder)
│
└── 📌 典型应用
├─ 客户分群 👥
├─ 购物篮分析 🛍
├─ 降维与可视化 🎨
└─ 异常检测 🚨