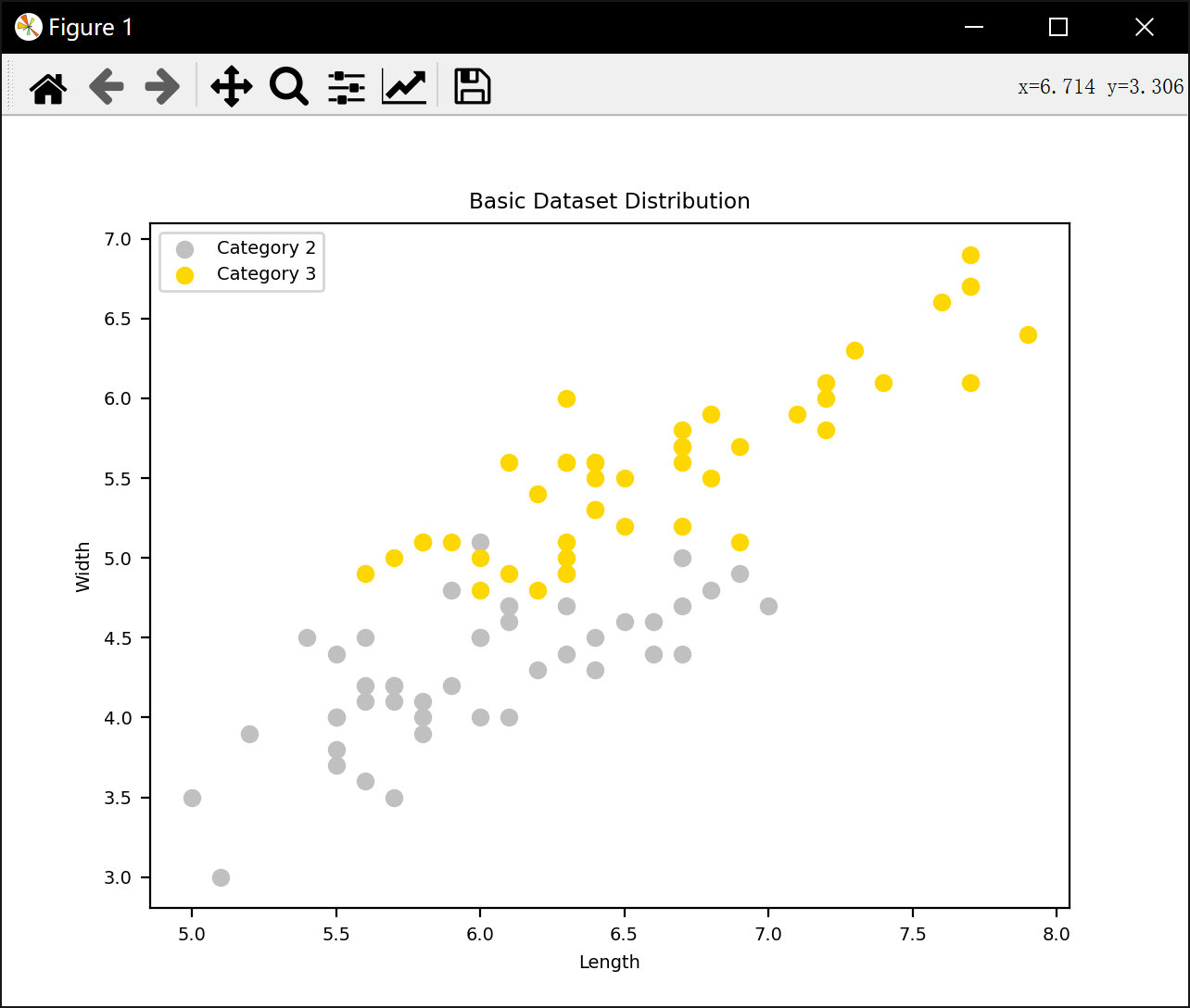
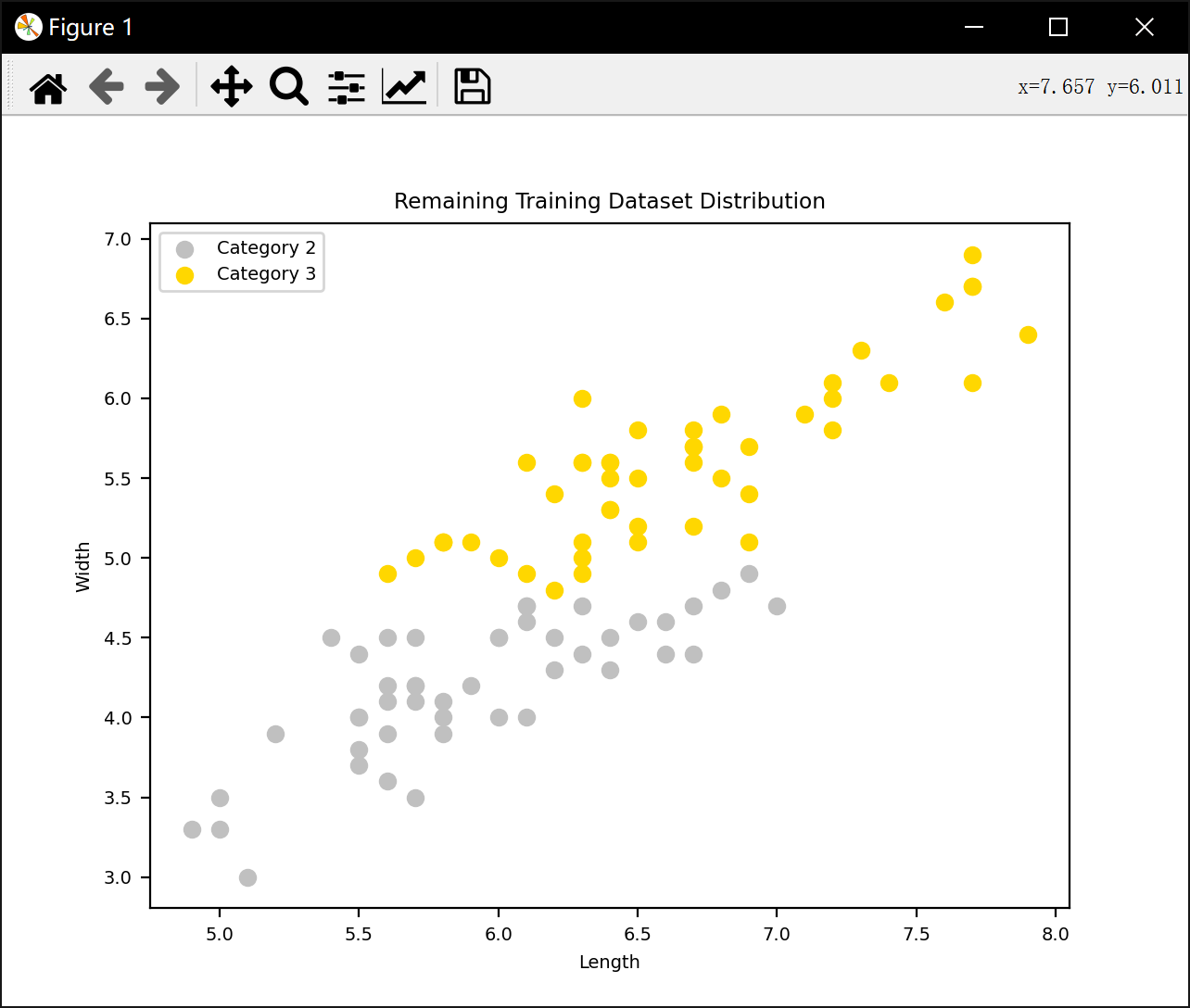
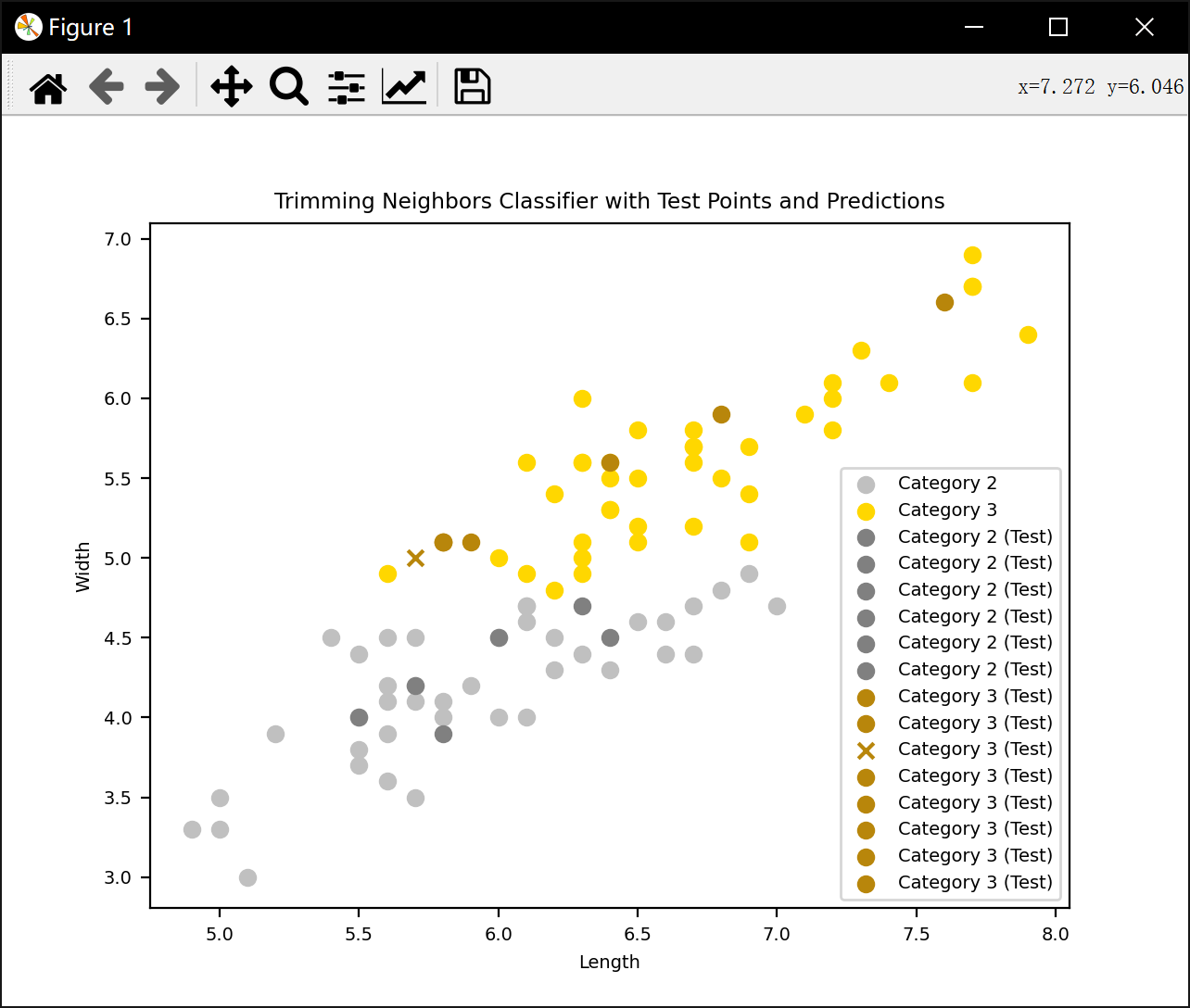
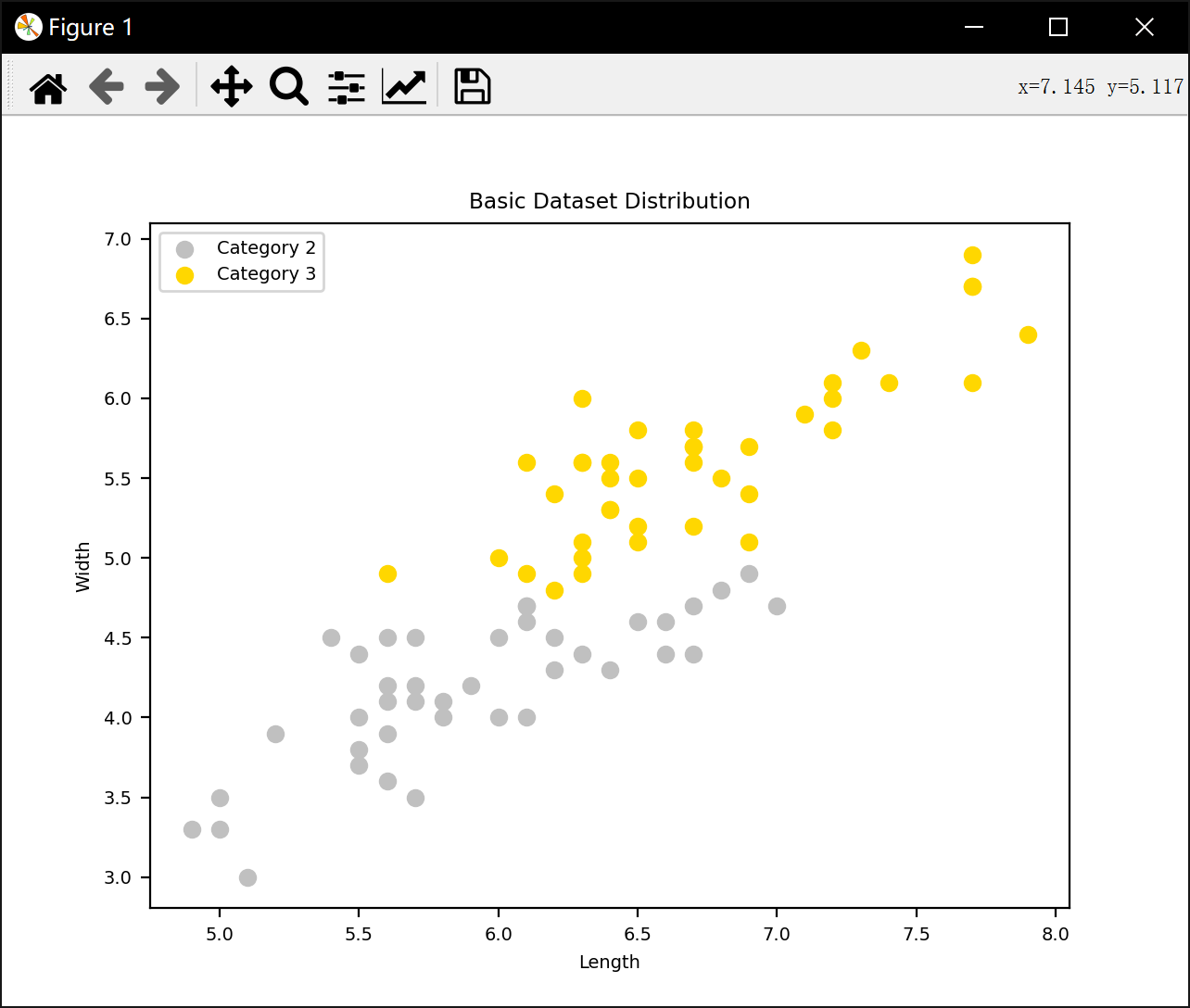
基于四种不同的近邻判别方法对数据进行划分和分类
-
最近邻:每个测试样本的类别由其最近的一个训练样本决定。
-
K近邻(KNN):根据测试样本的9个最近邻的多数投票决定类别。相比NN更鲁棒,但对K值敏感。
-
剪辑近邻 :训练中 迭代删除被KNN误分类的训练样本(剪辑噪声点)。测试中用剪辑后的训练集进行KNN分类。提升分类边界清晰度,减少过拟合。
-
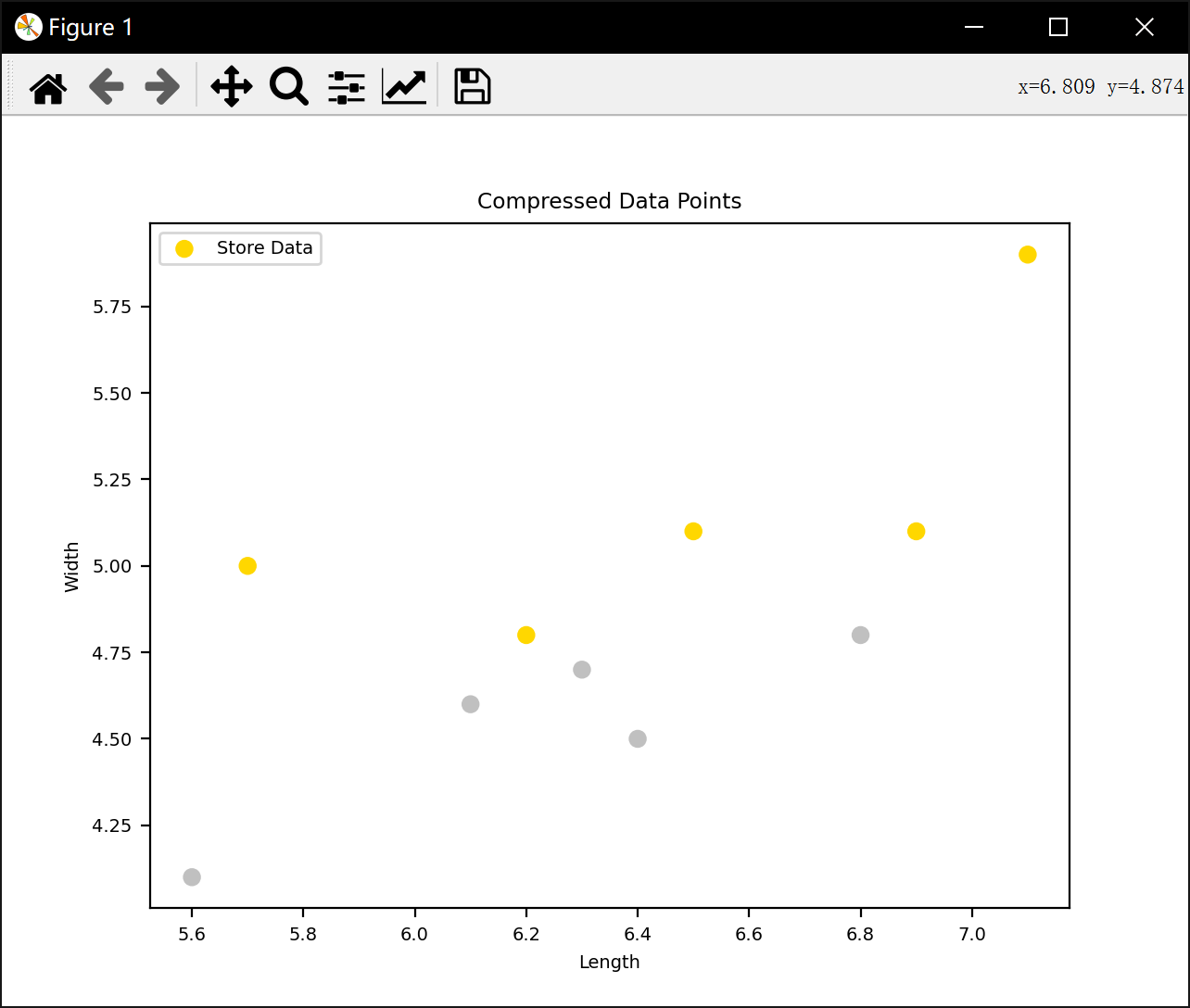
压缩近邻 :训练中 通过迭代将样本从
Bag移到Store,仅保留对分类关键的样本。测试中 用Store中的样本进行最近邻分类。显著减少存储样本量,提升效率。
程序代码:
python
import math
import random
import matplotlib
import numpy as np
from matplotlib import pyplot as plt
from sklearn import svm
data_dict = {}
train_data = {}
test_data = {}
matplotlib.rcParams.update({'font.size': 7})
with open('Iris数据txt版.txt', 'r') as file:
for line in file:
line = line.strip()
data = line.split('\t')
if len(data) >= 3:
try:
category = data[0]
attribute1 = eval(data[1])
attribute2 = eval(data[3])
if category in ['2', '3']:
if category not in data_dict:
data_dict[category] = {'Length': [], 'Width': []}
data_dict[category]['Length'].append(attribute1)
data_dict[category]['Width'].append(attribute2)
except ValueError:
print(f"Invalid data in line: {line}")
continue
for category, attributes in data_dict.items():
print(f'种类: {category}')
print(len(attributes["Length"]))
print(len(attributes["Width"]))
print(f'属性1: {attributes["Length"]}')
print(f'属性2: {attributes["Width"]}')
for category, attributes in data_dict.items():
lengths = attributes['Length']
widths = attributes['Width']
train_indices = random.sample(range(len(lengths)), 45)
test_indices = [i for i in range(len(lengths)) if i not in train_indices]
train_data[category] = {
'Length': [lengths[i] for i in train_indices],
'Width': [widths[i] for i in train_indices]
}
test_data[category] = {
'Length': [lengths[i] for i in test_indices],
'Width': [widths[i] for i in test_indices]
}
print(len(train_data['2']['Length']))
print(train_data['2'])
print(len(test_data['2']['Length']))
print(test_data['2'])
print(len(train_data['3']['Length']))
print(train_data['3'])
print(len(test_data['3']['Length']))
print(test_data['3'])
'''
#plt.scatter(train_data['1']['Length'], train_data['1']['Width'], color='paleturquoise', label='Category 1')
plt.scatter(train_data['2']['Length'], train_data['2']['Width'], color='silver', label='Category 2')
plt.scatter(train_data['3']['Length'], train_data['3']['Width'], color='gold', label='Category 3')
plt.xlabel('Length')
plt.ylabel('Width')
plt.legend()
plt.title('Basic Dataset Distribution')
plt.show()
#最近邻法
all_count = 0
right_count = 0
plt.scatter(train_data['2']['Length'], train_data['2']['Width'], color='silver', label='Category 2')
plt.scatter(train_data['3']['Length'], train_data['3']['Width'], color='gold', label='Category 3')
for category, attributes in test_data.items():
for i in range(len(attributes['Length'])):
test_point = (attributes['Length'][i], attributes['Width'][i])
min_distance = math.inf
n_category = None
for train_category, train_attributes in train_data.items():
for j in range(len(train_attributes['Length'])):
train_point = (train_attributes['Length'][j], train_attributes['Width'][j])
distance = np.sqrt((train_point[0] - test_point[0]) ** 2 + (train_point[1] - test_point[1]) ** 2)
if distance < min_distance:
min_distance = distance
n_category = train_category
all_count += 1
if n_category != category:
marker = 'x'
else:
marker = 'o'
right_count += 1
if category == '2':
color = 'gray'
else:
color = 'darkgoldenrod'
plt.scatter(test_point[0], test_point[1], color=color, marker=marker, label=f'Category {category} (Test)')
print("最近邻法准确率:",right_count/all_count)
plt.xlabel('Length')
plt.ylabel('Width')
plt.legend()
plt.title('Nearest Neighbor Classifier with Test Points and Predictions')
plt.show()
#k近邻法
kn = 9
all_count = 0
right_count = 0
plt.scatter(train_data['2']['Length'], train_data['2']['Width'], color='silver', label='Category 2')
plt.scatter(train_data['3']['Length'], train_data['3']['Width'], color='gold', label='Category 3')
for category, attributes in test_data.items():
for i in range(len(attributes['Length'])):
test_point = (attributes['Length'][i], attributes['Width'][i])
test_label = [0,0]
n_category = None
distances = []
for train_category, train_attributes in train_data.items():
for j in range(len(train_attributes['Length'])):
train_point = (train_attributes['Length'][j], train_attributes['Width'][j])
distances.append(np.sqrt((np.array(train_attributes['Length'][j]) - attributes['Length'][i]) ** 2 + (np.array(train_attributes['Width'][j]) - attributes['Width'][i]) ** 2))
nearest_indices = np.argsort(distances)[:kn]
print(nearest_indices)
nearest_categories = [list(train_data.keys())[index // len(train_data['2']['Length'])] for index in nearest_indices]
print(nearest_categories)
for k in nearest_categories:
if k == '2':
test_label[0] += 1
elif k == '3':
test_label[1] += 1
if test_label[0] > test_label[1]:
n_category = '2'
else:
n_category = '3'
all_count += 1
if n_category != category:
marker = 'x'
else:
marker = 'o'
right_count += 1
if category == '2':
color = 'gray'
else:
color = 'darkgoldenrod'
plt.scatter(test_point[0], test_point[1], color=color, marker=marker, label=f'Category {category} (Test)')
print("K邻法准确率:", right_count / all_count)
plt.xlabel('Length')
plt.ylabel('Width')
plt.legend()
plt.title('K-Neighbors Classifier with Test Points and Predictions')
plt.show()
'''
#剪辑近邻法
kn = 9
max_iterations = 1500
correct_iterations = 1000
iteration_sum = 0
pop_sum = 0
train_data_copy = {key: {'Length': value['Length'][:], 'Width': value['Width'][:]} for key, value in data_dict.items()}
print(train_data_copy)
iterations_without_error = 0
while iterations_without_error < correct_iterations and iteration_sum < max_iterations:
selected_category = random.choice(list(train_data_copy.keys()))
selected_attributes = train_data_copy[selected_category]
selected_index = random.randint(0, len(selected_attributes['Length']) - 1)
test_point = (selected_attributes['Length'][selected_index], selected_attributes['Width'][selected_index])
test_label = [0, 0]
n_category = None
distances = []
for train_category, train_attributes in train_data_copy.items():
for j in range(len(train_attributes['Length'])):
distance = np.sqrt((np.array(train_attributes['Length'][j]) - test_point[0]) ** 2 +
(np.array(train_attributes['Width'][j]) - test_point[1]) ** 2)
distances.append(distance)
nearest_indices = np.argsort(distances)[:kn]
nearest_categories = [list(data_dict.keys())[index // len(data_dict['2']['Length'])] for index in nearest_indices]
for k in nearest_categories:
if k == '2':
test_label[0] += 1
elif k == '3':
test_label[1] += 1
if test_label[0] > test_label[1]:
n_category = '2'
else:
n_category = '3'
if n_category != selected_category:
train_data_copy[selected_category]['Length'].pop(selected_index)
train_data_copy[selected_category]['Width'].pop(selected_index)
pop_sum += 1
iterations_without_error = 0
else:
iterations_without_error += 1
iteration_sum += 1
print("删除数据点数量:", pop_sum)
print("迭代次数:", iteration_sum)
#print(train_data_copy)
plt.scatter(train_data['2']['Length'], train_data['2']['Width'], color='silver', label='Category 2')
plt.scatter(train_data['3']['Length'], train_data['3']['Width'], color='gold', label='Category 3')
plt.xlabel('Length')
plt.ylabel('Width')
plt.legend()
plt.title('Basic Dataset Distribution')
plt.show()
for category, attributes in train_data_copy.items():
if category == '2':
color = 'silver'
label = 'Category 2'
elif category == '3':
color = 'gold'
label = 'Category 3'
plt.scatter(attributes['Length'], attributes['Width'], color=color, label=label)
plt.xlabel('Length')
plt.ylabel('Width')
plt.legend()
plt.title('Remaining Training Dataset Distribution')
plt.show()
test_data_copy = {}
rest_data = {}
for category, attributes in train_data_copy.items():
lengthsx = attributes['Length']
widthsx = attributes['Width']
rest_indices = random.sample(range(len(lengthsx)), 40)
test_indices_copy = [i for i in range(len(lengthsx)) if i not in rest_indices]
test_data_copy[category] = {
'Length': [lengthsx[i] for i in test_indices_copy],
'Width': [widthsx[i] for i in test_indices_copy]
}
rest_data[category] = {
'Length': [lengthsx[i] for i in rest_indices],
'Width': [widthsx[i] for i in rest_indices]
}
#print(test_data_copy['2'])
#print(test_data_copy['3'])
#print(rest_data['2'])
#print(rest_data['3'])
kn = 9
all_count = 0
right_count = 0
plt.scatter(rest_data['2']['Length'], rest_data['2']['Width'], color='silver', label='Category 2')
plt.scatter(rest_data['3']['Length'], rest_data['3']['Width'], color='gold', label='Category 3')
for category, attributes in test_data_copy.items():
for i in range(len(attributes['Length'])):
test_point = (attributes['Length'][i], attributes['Width'][i])
test_label = [0,0]
n_category = None
distances = []
for train_category, rest_attributes in rest_data.items():
for j in range(len(rest_attributes['Length'])):
train_point = (rest_attributes['Length'][j], rest_attributes['Width'][j])
distances.append(np.sqrt((np.array(rest_attributes['Length'][j]) - attributes['Length'][i]) ** 2 + (np.array(rest_attributes['Width'][j]) - attributes['Width'][i]) ** 2))
nearest_ind = np.argsort(distances)[:kn]
nearest_categories = [list(rest_data.keys())[index // len(rest_data['2']['Length'])] for index in nearest_ind]
for k in nearest_categories:
if k == '2':
test_label[0] += 1
elif k == '3':
test_label[1] += 1
if test_label[0] > test_label[1]:
n_category = '2'
else:
n_category = '3'
all_count += 1
if n_category != category:
marker = 'x'
else:
marker = 'o'
right_count += 1
if category == '2':
color = 'gray'
else:
color = 'darkgoldenrod'
plt.scatter(test_point[0], test_point[1], color=color, marker=marker, label=f'Category {category} (Test)')
print("剪辑近邻法准确率:", right_count / all_count)
plt.xlabel('Length')
plt.ylabel('Width')
plt.legend()
plt.title('Trimming Neighbors Classifier with Test Points and Predictions')
plt.show()
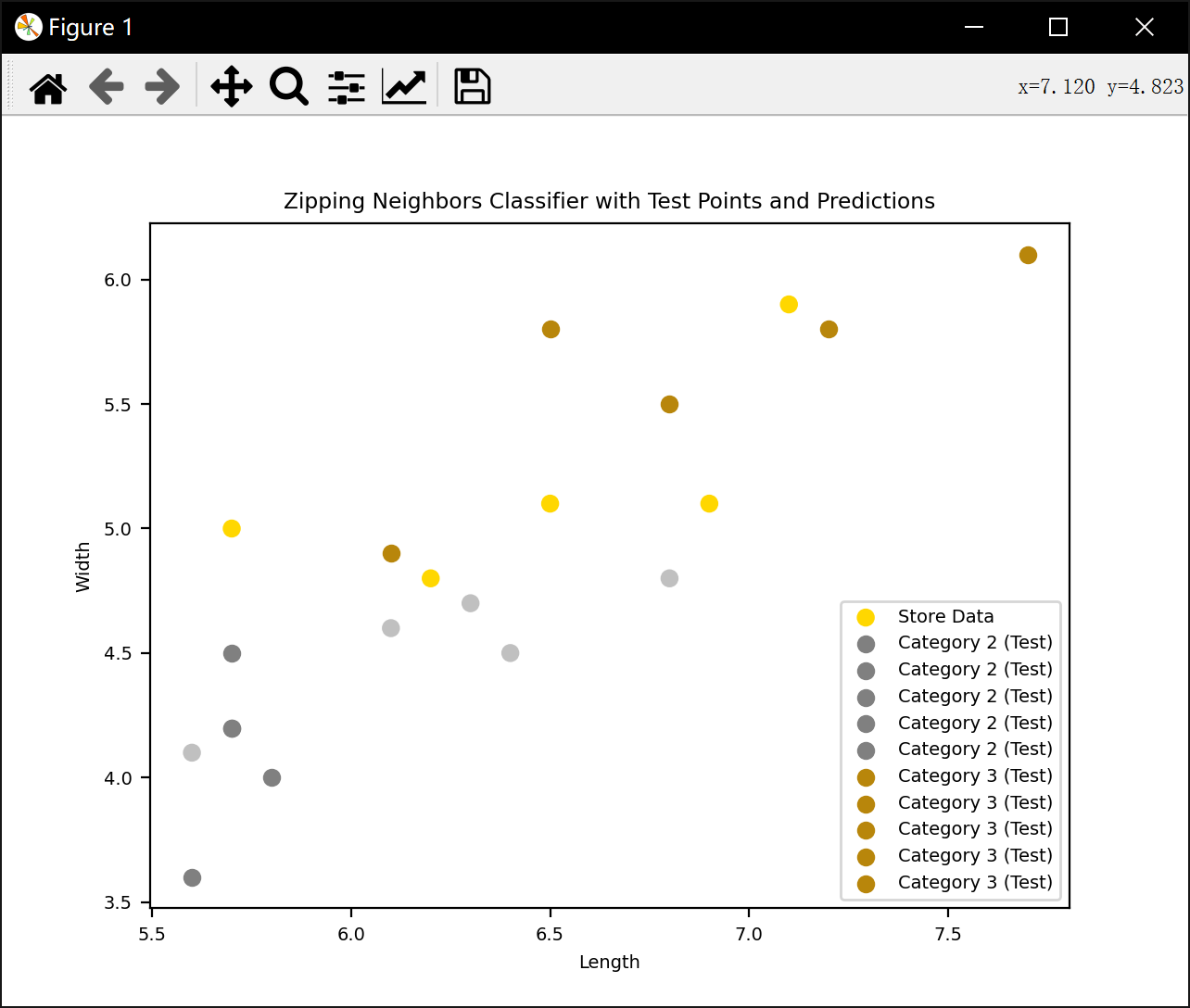
#压缩近邻法
Store = []
Bag = []
# 将所有样本放入Garbbag
for category, attributes in train_data_copy.items():
lengths = attributes['Length']
widths = attributes['Width']
for i in range(len(lengths)):
Bag.append((lengths[i], widths[i], category))
random.shuffle(Bag)
#print(Bag)
#print(len(Bag))
x = random.choice(Bag)
Bag.remove(x)
Store.append(x)
max_iterations = 10000
correct_iterations = 1000
correct_sum = 0
iteration_sum = 0
while correct_sum < correct_iterations and iteration_sum < max_iterations:
# 从Garbbag中随机选择一个样本
x = random.choice(Bag)
Bag.remove(x)
lengthx, widthx, catx = x
min_distance = math.inf
n_category = None
for i in Store:
lengthy, widthy, caty = i
distance = np.sqrt((lengthx - lengthy)**2 + (widthx - widthy)**2)
if distance < min_distance:
min_distance = distance
n_category = caty
if catx != n_category:
Store.append(x)
correct_sum = 0
else:
Bag.append(x)
correct_sum += 1
iteration_sum += 1
print("Store数据点数量:",len(Store))
print("迭代次数:",iteration_sum)
plt.scatter(rest_data['2']['Length'], rest_data['2']['Width'], color='silver', label='Category 2')
plt.scatter(rest_data['3']['Length'], rest_data['3']['Width'], color='gold', label='Category 3')
plt.xlabel('Length')
plt.ylabel('Width')
plt.legend()
plt.title('Basic Dataset Distribution')
plt.show()
lengths = [sample[0] for sample in Store]
widths = [sample[1] for sample in Store]
categories = [sample[2] for sample in Store]
colors = ['silver' if category == '2' else 'gold' for category in categories]
plt.scatter(lengths, widths, c=colors, label='Store Data')
plt.xlabel('Length')
plt.ylabel('Width')
plt.legend()
plt.title('Compressed Data Points')
plt.show()
test_data_copy = {}
for category, attributes in train_data_copy.items():
lengthsx = attributes['Length']
widthsx = attributes['Width']
test_indices = random.sample(range(len(lengthsx)), 5)
test_data_copy[category] = {
'Length': [lengthsx[i] for i in test_indices],
'Width': [widthsx[i] for i in test_indices]
}
plt.scatter(lengths, widths, c=colors, label='Store Data')
for category, attributes in test_data_copy.items():
for i in range(len(attributes['Length'])):
test_point = (attributes['Length'][i], attributes['Width'][i])
test_label = [0,0]
n_category = None
min_distance = math.inf
for lengthz, widthz, catz in Store:
distance = np.sqrt((lengthz - attributes['Length'][i]) ** 2 + (widthz - attributes['Width'][i]) ** 2)
if distance < min_distance:
min_distance = distance
n_category = catz
all_count += 1
if n_category != category:
marker = 'x'
else:
marker = 'o'
right_count += 1
if category == '2':
color = 'gray'
else:
color = 'darkgoldenrod'
plt.scatter(test_point[0], test_point[1], color=color, marker=marker, label=f'Category {category} (Test)')
print("压缩近邻法准确率:", right_count / all_count)
plt.xlabel('Length')
plt.ylabel('Width')
plt.legend()
plt.title('Zipping Neighbors Classifier with Test Points and Predictions')
plt.show()运行结果:
种类: 2
50
50
属性1: 7.0, 6.4, 6.9, 5.5, 6.5, 5.7, 6.3, 4.9, 6.6, 5.2, 5.0, 5.9, 6.0, 6.1, 5.6, 6.7, 5.6, 5.8, 6.2, 5.6, 5.9, 6.1, 6.3, 6.1, 6.4, 6.6, 6.8, 6.7, 6.0, 5.7, 5.5, 5.5, 5.8, 6.0, 5.4, 6.0, 6.7, 6.3, 5.6, 5.5, 5.5, 6.1, 5.8, 5.0, 5.6, 5.7, 5.7, 6.2, 5.1, 5.7
属性2: 4.7, 4.5, 4.9, 4.0, 4.6, 4.5, 4.7, 3.3, 4.6, 3.9, 3.5, 4.2, 4.0, 4.7, 3.6, 4.4, 4.5, 4.1, 4.5, 3.9, 4.8, 4.0, 4.9, 4.7, 4.3, 4.4, 4.8, 5.0, 4.5, 3.5, 3.8, 3.7, 3.9, 5.1, 4.5, 4.5, 4.7, 4.4, 4.1, 4.0, 4.4, 4.6, 4.0, 3.3, 4.2, 4.2, 4.2, 4.3, 3.0, 4.1
种类: 3
50
50
属性1: 6.3, 5.8, 7.1, 6.3, 6.5, 7.6, 4.9, 7.3, 6.7, 7.2, 6.5, 6.4, 6.8, 5.7, 5.8, 6.4, 6.5, 7.7, 7.7, 6.0, 6.9, 5.6, 7.7, 6.3, 6.7, 7.2, 6.2, 6.1, 6.4, 7.2, 7.4, 7.9, 6.4, 6.3, 6.1, 7.7, 6.3, 6.4, 6.0, 6.9, 6.7, 6.9, 5.8, 6.8, 6.7, 6.7, 6.3, 6.5, 6.2, 5.9
属性2: 6.0, 5.1, 5.9, 5.6, 5.8, 6.6, 4.5, 6.3, 5.8, 6.1, 5.1, 5.3, 5.5, 5.0, 5.1, 5.3, 5.5, 6.7, 6.9, 5.0, 5.7, 4.9, 6.7, 4.9, 5.7, 6.0, 4.8, 4.9, 5.6, 5.8, 6.1, 6.4, 5.6, 5.1, 5.6, 6.1, 5.6, 5.5, 4.8, 5.4, 5.6, 5.1, 5.1, 5.9, 5.7, 5.2, 5, 5.2, 5.4, 5.1
45
{'Length': 6.1, 6.0, 5.5, 7.0, 5.7, 6.1, 5.8, 6.4, 5.7, 5.8, 6.3, 5.5, 5.5, 6.6, 6.3, 6.7, 5.6, 6.9, 6.6, 6.1, 6.0, 5.4, 5.6, 5.1, 5.9, 5.7, 6.8, 5.9, 6.7, 6.1, 5.7, 6.4, 6.5, 6.0, 5.6, 5.0, 5.2, 5.5, 6.7, 5.5, 6.2, 5.8, 5.6, 6.3, 6.0, 'Width': 4.6, 4.0, 3.8, 4.7, 3.5, 4.7, 3.9, 4.5, 4.2, 4.1, 4.4, 4.0, 4.0, 4.4, 4.9, 4.7, 4.2, 4.9, 4.6, 4.7, 4.5, 4.5, 3.6, 3.0, 4.8, 4.1, 4.8, 4.2, 5.0, 4.0, 4.2, 4.3, 4.6, 4.5, 4.1, 3.5, 3.9, 4.4, 4.4, 3.7, 4.3, 4.0, 4.5, 4.7, 5.1}
5
{'Length': 5.7, 4.9, 6.2, 5.6, 5.0, 'Width': 4.5, 3.3, 4.5, 3.9, 3.3}
45
{'Length': 7.4, 6.4, 6.1, 5.8, 6.0, 6.5, 7.7, 7.6, 7.1, 6.9, 5.7, 6.3, 6.4, 7.3, 7.2, 7.2, 5.6, 6.7, 6.9, 7.7, 6.3, 6.0, 6.2, 6.1, 6.8, 6.3, 6.2, 6.8, 6.4, 6.7, 6.7, 6.4, 6.4, 7.2, 7.7, 7.7, 6.3, 6.5, 6.7, 5.8, 5.9, 6.7, 6.3, 6.3, 7.9, 'Width': 6.1, 5.3, 5.6, 5.1, 5.0, 5.5, 6.7, 6.6, 5.9, 5.1, 5.0, 4.9, 5.6, 6.3, 6.1, 5.8, 4.9, 5.2, 5.7, 6.7, 5.6, 4.8, 4.8, 4.9, 5.5, 5.6, 5.4, 5.9, 5.6, 5.8, 5.7, 5.3, 5.5, 6.0, 6.9, 6.1, 5, 5.2, 5.6, 5.1, 5.1, 5.7, 6.0, 5.1, 6.4}
5
{'Length': 5.8, 6.5, 4.9, 6.5, 6.9, 'Width': 5.1, 5.8, 4.5, 5.1, 5.4}
{'2': {'Length': 7.0, 6.4, 6.9, 5.5, 6.5, 5.7, 6.3, 4.9, 6.6, 5.2, 5.0, 5.9, 6.0, 6.1, 5.6, 6.7, 5.6, 5.8, 6.2, 5.6, 5.9, 6.1, 6.3, 6.1, 6.4, 6.6, 6.8, 6.7, 6.0, 5.7, 5.5, 5.5, 5.8, 6.0, 5.4, 6.0, 6.7, 6.3, 5.6, 5.5, 5.5, 6.1, 5.8, 5.0, 5.6, 5.7, 5.7, 6.2, 5.1, 5.7, 'Width': 4.7, 4.5, 4.9, 4.0, 4.6, 4.5, 4.7, 3.3, 4.6, 3.9, 3.5, 4.2, 4.0, 4.7, 3.6, 4.4, 4.5, 4.1, 4.5, 3.9, 4.8, 4.0, 4.9, 4.7, 4.3, 4.4, 4.8, 5.0, 4.5, 3.5, 3.8, 3.7, 3.9, 5.1, 4.5, 4.5, 4.7, 4.4, 4.1, 4.0, 4.4, 4.6, 4.0, 3.3, 4.2, 4.2, 4.2, 4.3, 3.0, 4.1}, '3': {'Length': 6.3, 5.8, 7.1, 6.3, 6.5, 7.6, 4.9, 7.3, 6.7, 7.2, 6.5, 6.4, 6.8, 5.7, 5.8, 6.4, 6.5, 7.7, 7.7, 6.0, 6.9, 5.6, 7.7, 6.3, 6.7, 7.2, 6.2, 6.1, 6.4, 7.2, 7.4, 7.9, 6.4, 6.3, 6.1, 7.7, 6.3, 6.4, 6.0, 6.9, 6.7, 6.9, 5.8, 6.8, 6.7, 6.7, 6.3, 6.5, 6.2, 5.9, 'Width': 6.0, 5.1, 5.9, 5.6, 5.8, 6.6, 4.5, 6.3, 5.8, 6.1, 5.1, 5.3, 5.5, 5.0, 5.1, 5.3, 5.5, 6.7, 6.9, 5.0, 5.7, 4.9, 6.7, 4.9, 5.7, 6.0, 4.8, 4.9, 5.6, 5.8, 6.1, 6.4, 5.6, 5.1, 5.6, 6.1, 5.6, 5.5, 4.8, 5.4, 5.6, 5.1, 5.1, 5.9, 5.7, 5.2, 5, 5.2, 5.4, 5.1}}
删除数据点数量: 6
迭代次数: 1203
剪辑近邻法准确率: 0.9285714285714286
Store数据点数量: 10
迭代次数: 1336
压缩近邻法准确率: 0.9583333333333334
进程已结束,退出代码0