TF-IDF(Term Frequency-Inverse Document Frequency)是一种广泛应用于文本挖掘和信息检索领域的经典加权算法,主要用于评估一个词语在文档集合中的重要程度。其核心思想是:一个词语在文档中出现的频率越高,同时在所有文档中出现的频率越低,则该词语对该文档的区分能力越强。
TF-IDF 的计算公式
TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的文本特征提取方法,由两部分组成:
1. 词频(TF,Term Frequency)
TF 衡量一个词在当前文档中出现的相对频率,计算公式为:
TF(t,d) = (词 t 在文档 d 中出现的次数) / (文档 d 的总词数)应用场景:在一篇关于水果的文档中,"apple"出现频率自然比"computer"要高,TF值能反映这种词频差异。
示例计算:
- 文档 d 有 100 个词
- 单词 "apple" 出现 5 次
- 则 TF("apple", d) = 5 / 100 = 0.05
注意事项:
- 常用对数化或归一化处理来平滑极端值
- 短文档中个别高频词可能产生过大的TF值
2. 逆文档频率(IDF,Inverse Document Frequency)
IDF 衡量一个词在整个语料库中的稀有程度,出现越少的词权重越高:
IDF(t,D) = log[ (语料库中文档总数 N) / (包含词 t 的文档数 + 1) ]改进说明:
- 加1平滑处理(+1)是为了避免某些词未出现在语料库中导致分母为0
- 对数运算(通常以10为底)可以压缩数值范围
示例计算:
- 语料库有1000篇文档
- "apple"在100篇文档中出现过
- 则 IDF("apple", D) = log(1000 / (100 + 1)) ≈ log(9.90) ≈ 2.30
特殊案例:
- 停用词(如"the"、"is")几乎出现在所有文档中,IDF值会趋近于0
- 专业术语通常具有较高的IDF值
3. TF-IDF 最终计算
将TF和IDF相乘得到最终权重:
TF-IDF(t,d,D) = TF(t,d) × IDF(t,D)示例计算:
- TF("apple", d) = 0.05
- IDF("apple", D) ≈ 2.30
- 则 TF-IDF("apple", d, D) = 0.05 × 2.30 ≈ 0.115
实际应用注意事项:
- 语料库规模会影响IDF值
- 不同领域的文档需要分别计算IDF
- 通常会进行归一化处理(如L2归一化)
- 可以结合停用词过滤提高效果
变体公式: 一些实现会使用不同的对数底数或调整平滑方式,例如:
- IDF(t,D) = log1 + (N/(df(t)+1))
- 使用自然对数(ln)代替常用对数(log10)
TF-IDF 的 Python 实现
Scikit-learn: TfidfVectorizer
用途:将文本转换为 TF-IDF 特征矩阵,适用于机器学习任务。
核心参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
input |
str | 'content' |
输入类型('filename'、'file'、'content') |
encoding |
str | 'utf-8' |
文本编码方式 |
lowercase |
bool | True |
是否转换为小写 |
stop_words |
str/list | None |
停用词表('english'或自定义列表) |
max_features |
int | None |
最大特征数(按词频排序) |
ngram_range |
tuple | (1, 1) |
N-gram 范围(如 (1, 2)包含 1-gram 和 2-gram) |
min_df |
int/float | 1 |
忽略词频低于此值的词(整数=次数,浮点数=比例) |
max_df |
int/float | 1.0 |
忽略词频高于此值的词(整数=次数,浮点数=比例) |
norm |
str | 'l2' |
归一化方式('l1'、'l2'或 None) |
use_idf |
bool | True |
是否启用 IDF 权重 |
smooth_idf |
bool | True |
是否平滑 IDF(避免除零错误) |
关键方法
| 方法 | 说明 |
|---|---|
fit(raw_documents) |
学习词汇和 IDF |
transform(raw_documents) |
将文档转换为 TF-IDF 矩阵 |
fit_transform(raw_documents) |
合并 fit和 transform |
get_feature_names_out() |
获取词汇表(Python ≥3.6) |
get_stop_words() |
获取停用词列表 |
python
# 导入必要的库
from sklearn.feature_extraction.text import TfidfVectorizer # 导入TF-IDF向量化工具
import pandas as pd # 导入pandas用于数据处理
# 读取文本文件
file = open('task2_1.txt', 'r') # 打开名为'task2_1.txt'的文本文件
data = file.readlines() # 读取文件的所有行,存储在列表data中
# 初始化TF-IDF向量化器
vectorizer = TfidfVectorizer() # 创建TF-IDF向量化器对象
# 计算TF-IDF矩阵
vetft = vectorizer.fit_transform(data) # 对数据进行拟合和转换,得到TF-IDF矩阵(稀疏矩阵)
print(vetft) # 打印TF-IDF矩阵(显示稀疏矩阵的存储格式)
# 获取特征词(词汇表)
words = vectorizer.get_feature_names_out() # 获取所有特征词(即词汇表)
print(words) # 打印特征词列表
# 将TF-IDF矩阵转换为DataFrame
# vetft.T 转置矩阵(行变列,列变行)
# .todense() 将稀疏矩阵转换为稠密矩阵
# index=words 使用特征词作为行索引
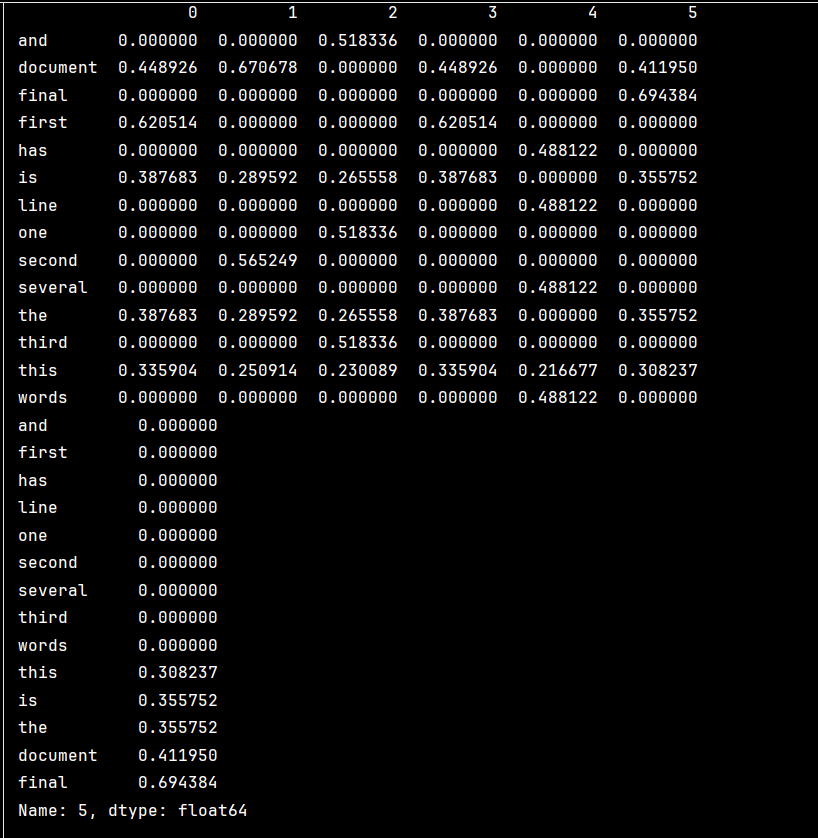
df = pd.DataFrame(vetft.T.todense(), index=words) # 创建DataFrame,行是特征词,列是文档
print(df, end='\n') # 打印DataFrame
# 提取特定文档(第6列,索引为5)的TF-IDF特征
features = df.iloc[:, 5] # 获取第6个文档的所有特征值(Python从0开始计数)
features.index = words # 设置索引为特征词(确保顺序一致)
results = features.sort_values() # 对特征值进行排序(默认升序)
print(results) # 打印排序后的结果(显示每个词在该文档中的TF-IDF值,按值从小到大排列)