对话过程是open webui的核心逻辑,本文针对最简单的一个对话中的一次交互进行分析,暂不涉及知识库、推理、function calling、过滤、搜索、多模态等功能。
一、更新对话数据
创建对话后,前端马上发起一次请求更新对话数据,对应入口为:
http://{ip:port}/api/v1/chats/{chat_id}。请求数据如下:
{
chat:{
"id": "4ce79017-9cc5-499d-9b1f-c9e37048e763",
"title": "新对话",
"models": [
"deepseek-r1:1.5b"
],
"params": {},
"history": {
"messages": {
"b4e671e4-1ce1-43cc-a041-9a8e3c3904c4": {#创建对话时请求中的消息ID
"id": "b4e671e4-1ce1-43cc-a041-9a8e3c3904c4",
"parentId": null,
"childrenIds": [
"f1107cfa-9f69-4a38-88b5-8e284f9fa5ed"
],
"role": "user",
"content": "五代十国第一猛将是谁?",
"timestamp": 1755305425,
"models": [
"deepseek-r1:1.5b"
]
},
#前端生成,作为助手应答占位。该ID作为后继补足请求的消息ID
"2268a3da-9a78-4bd9-8cae-d399bed04f2a": {
"parentId": "1b4e671e4-1ce1-43cc-a041-9a8e3c3904c4",
"id": "2268a3da-9a78-4bd9-8cae-d399bed04f2a",
"childrenIds": \[\],
"role": "assistant",
"content": "",
"model": "deepseek-r1:1.5b",
"modelName": "deepseek-r1:1.5b",
"modelIdx": 0,
"timestamp": 1755305425
}
},
"currentId": "2268a3da-9a78-4bd9-8cae-d399bed04f2a"
},
"messages": [
{
"id": "191b6fe3-5dbd-4910-84e6-d4fe971e502d",
"parentId": null,
"childrenIds": [
"f1107cfa-9f69-4a38-88b5-8e284f9fa5ed"
],
"role": "user",
"content": "五代十国第一猛将是谁?",
"timestamp": 1755305425,
"models": [
"deepseek-r1:1.5b"
]
},
{
"parentId": "191b6fe3-5dbd-4910-84e6-d4fe971e502d",
"id": "f1107cfa-9f69-4a38-88b5-8e284f9fa5ed",
"childrenIds": \[\],
"role": "assistant",
"content": "",
"model": "deepseek-r1:1.5b",
"modelName": "deepseek-r1:1.5b",
"modelIdx": 0,
"timestamp": 1755305425
}
],
"tags": \[\],
"timestamp": 1755305425309,
"files": \[\]
}
}
对于入口处理函数为update_chat_by_id,处理逻辑比较简单,用本地请求数据更新数据库中chat表的chat字段,并把完整的聊天记录返回前端。
@router.post("/{id}", response_model=OptionalChatResponse)
async def update_chat_by_id(
id: str, form_data: ChatForm, user=Depends(get_verified_user)
):
#根据chat_id从数据库查找对应对话的chat字段
chat = Chats.get_chat_by_id_and_user_id(id, user.id)
if chat:
#对数据中存储的对话数据和请求中的对话数据做并集,同名属性后者覆盖前者
updated_chat = {**chat.chat, **form_data.chat}
chat = Chats.update_chat_by_id(id, updated_chat)#更新数据库中数据
return ChatResponse(**chat.model_dump())
else:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail=ERROR_MESSAGES.ACCESS_PROHIBITED,
)
二、发起competion
发起会话对应入口为:http://{ip:port}/api/chat/completions,对应的请求数据如下:
{
"stream": true,
"model": "deepseek-r1:1.5b",
"messages": [ #用户提问
{
"role": "user",
"content": "五代十国第一猛将是谁?"
}
],
"params": {},
"tool_servers": \[\],
"features": {#高级特性,暂不关注
"image_generation": false,
"code_interpreter": false,
"web_search": false,
"memory": false
},
"variables": { #前端传入的登录相关信息
"{{USER_NAME}}": "acaluis",
"{{USER_LOCATION}}": "Unknown",
"{{CURRENT_DATETIME}}": "2025-08-13 21:26:15",
"{{CURRENT_DATE}}": "2025-08-13",
"{{CURRENT_TIME}}": "21:26:15",
"{{CURRENT_WEEKDAY}}": "Wednesday",
"{{CURRENT_TIMEZONE}}": "Etc/GMT-8",
"{{USER_LANGUAGE}}": "zh-CN"
},
"model_item": {#大模型信息,使用了deepseek蒸馏模型
"id": "deepseek-r1:1.5b",
"name": "deepseek-r1:1.5b",
"object": "model",
"created": 1755089334,
"owned_by": "ollama",
"ollama": {
"name": "deepseek-r1:1.5b",
"model": "deepseek-r1:1.5b",
"modified_at": "2025-08-13T12:47:37.058323295Z",
"size": 1117322768,
"digest": "e0*d7",
"details": {
"parent_model": "",
"format": "gguf",
"family": "qwen2",
"families": [
"qwen2"
],
"parameter_size": "1.8B",
"quantization_level": "Q4_K_M"
},
"connection_type": "local",
"urls": [
0
],
"expires_at": 1755089575
},
"connection_type": "local",
"tags": \[\],
"actions": \[\],
"filters": \[\]
},
"session_id": "vc0sbdfwW0jkvteMAAAF", #websocket对应的session_id
"chat_id": "4ce79017-9cc5-499d-9b1f-c9e37048e763",#创建会话时生成的会话ID
"id": "2268a3da-9a78-4bd9-8cae-d399bed04f2a",#更新对话请求数据中助手消息ID
"background_tasks": {#后台任务启用设置
"title_generation": true, #启用自动生成标题任务
"tags_generation": true, #启用自动生成标签任务
"follow_up_generation": true #启用自动生成跟随问题任务
}
}
对应入口函数为chat_completion,具体分析如下:
流程如下:
1)判断是否有可用模型,如果没有则从本地数据库查询
2)获取用户使用的模型信息
3)元数据metadata设置
4)调用process_chat_payload对请求进行预处理
5)调用chat_completion_handler方法向ollama平台发起competion请求
6)调用process_chat_response方法以SSE方式完成应答
@app.post("/api/chat/completions")
async def chat_completion(
request: Request,
form_data: dict,
user=Depends(get_verified_user),
):
#后台任务已经从ollama请求获取了可用模型列表,所以不会进入内部的逻辑
if not request.app.state.MODELS:
await get_all_models(request, user=user)
model_item = form_data.pop("model_item", {}) #从请求中获取模型信息
tasks = form_data.pop("background_tasks", None) #从请求中获取需启用后台任务列表
metadata = {}
try:
#进入如下分支
if not model_item.get("direct", False):
model_id = form_data.get("model", None)
if model_id not in request.app.state.MODELS: #检查是否在预先拉取的模型列表中
raise Exception("Model not found")
model = request.app.state.MODELSmodel_id
model_info = Models.get_model_by_id(model_id)#获取模型信息
检查用户权限
if not BYPASS_MODEL_ACCESS_CONTROL and user.role == "user":
try:
check_model_access(user, model)
except Exception as e:
raise e
else: #如果open webui直接连接公有大模型,则进入如下分支,在此不予分析
model = model_item
model_info = None
request.state.direct = True
request.state.model = model
'''
对表单一级数据进行瘦身,把chat_id,id,session_id,filter_ids,tool_servers删 除并追加到metadata中。同时在metadata中追加ser_id,files,features,variables,model
和function_calling。再把metadata设置到全局request.state中和表单数据中。
'''
metadata = {
"user_id": user.id,
"chat_id": form_data.pop("chat_id", None),
"message_id": form_data.pop("id", None),
"session_id": form_data.pop("session_id", None),
"filter_ids": form_data.pop("filter_ids", \[\]),
"tool_ids": form_data.get("tool_ids", None),
"tool_servers": form_data.pop("tool_servers", None),
"files": form_data.get("files", None),
"features": form_data.get("features", {}),
"variables": form_data.get("variables", {}),
"model": model,
"direct": model_item.get("direct", False),
**(
{"function_calling": "native"}
if form_data.get("params", {}).get("function_calling") == "native"
or (
model_info
and model_info.params.model_dump().get("function_calling")
== "native"
)
else {}
),
}
request.state.metadata = metadata
form_data"metadata" = metadata
form_data, metadata, events = await process_chat_payload(
request, form_data, user, metadata, model
)
......#异常处理代码不予关注
try:
response = await chat_completion_handler(request, form_data, user)
return await process_chat_response(
request, response, form_data, user, metadata, model, events, tasks
)
......#异常处理代码不予关注
下面对process_chat_payload函数进行分析:
流程如下:
1)确定执行任务的大模型,也就是当前会话选择的大模型
2)处理知识库,生成知识库文件列表
3)流水线处理
4)过滤器处理
5)高级特性,包括代码生成,文生图,内存搜索和web搜索
6)function calling处理
7)模型知识处理,发送请求到前端等待处理
async def process_chat_payload(request, form_data, user, metadata, model):
#针对请求中的params做处理,因为params为空,所以没有任何处理
form_data = apply_params_to_form_data(form_data, model)
log.debug(f"form_data: {form_data}")
#与前端websocket通信方法设置
event_emitter = get_event_emitter(metadata)
event_call = get_event_call(metadata)
extra_params = {
"event_emitter": event_emitter,
"event_call": event_call,
"user": user.model_dump() if isinstance(user, UserModel) else {},
"metadata": metadata,
"request": request,
"model": model,
}
'''
确定执行任务的大模型
''''
if getattr(request.state, "direct", False) and hasattr(request.state, "model"):
models = {
request.state.model"id": request.state.model,
}
else:
models = request.app.state.MODELS
task_model_id = get_task_model_id(
form_data"model", //zbl:模型名,比如deepseek-chat
request.app.state.config.TASK_MODEL,
request.app.state.config.TASK_MODEL_EXTERNAL,
models, //zbl:{deepseek-chat: model_item}
)
events = \[\] #保存发送到客户端的事件
sources = \[\] #保存上下文和应用数据
#从请求中获取用户的问话
user_message = get_last_user_message(form_data"messages")
#根据模型信息确定是否挂载了知识库,并执行对应的处理
model_knowledge = model.get("info", {}).get("meta", {}).get("knowledge", False)
if model_knowledge: #处理外挂知识库的情况
await event_emitter(#通过websocket发送知识库查询请求到前端
{
"type": "status",
"data": {
"action": "knowledge_search",
"query": user_message,
"done": False,
},
}
)
knowledge_files = \[\]
for item in model_knowledge:#把向量库集合增加到 knowledge_files中
if item.get("collection_name"):
knowledge_files.append(
{
"id": item.get("collection_name"),
"name": item.get("name"),
"legacy": True,
}
)
elif item.get("collection_names"):
knowledge_files.append(
{
"name": item.get("name"),
"type": "collection",
"collection_names": item.get("collection_names"),
"legacy": True,
}
)
else:
knowledge_files.append(item)
files = form_data.get("files", \[\]) #获取请求中的所有文件
files.extend(knowledge_files) #把knowledge_files追加到files列表中
form_data"files" = files #更新表单中的files
variables = form_data.pop("variables", None) #垃圾代码,后面未用到
以下代码对表单数据进行流水线处理,后继再对process_pipeline_inlet_filter进行分析
try:
form_data = await process_pipeline_inlet_filter(
request, form_data, user, models
)
except Exception as e:
raise e
#以下代码进行过滤器处理,后继再专门分析
try:
filter_functions = [#获取所有的过滤函数
Functions.get_function_by_id(filter_id)
for filter_id in get_sorted_filter_ids(
request, model, metadata.get("filter_ids", \[\])
)
]
form_data, flags = await process_filter_functions(#进行过滤处理
request=request,
filter_functions=filter_functions,
filter_type="inlet",
form_data=form_data,
extra_params=extra_params,
)
except Exception as e:
raise Exception(f"Error: {e}")
#以下代码处理高级特性,包括内存、web搜索、生成图片和生成代码。后继再分析
features = form_data.pop("features", None)
if features:
if "memory" in features and features"memory":
form_data = await chat_memory_handler(#从向量库查询匹配文档
request, form_data, extra_params, user
)
if "web_search" in features and features"web_search":
form_data = await chat_web_search_handler(#推送数据到前端进行搜索
request, form_data, extra_params, user
)
if "image_generation" in features and features"image_generation":
form_data = await chat_image_generation_handler(#生成图片
request, form_data, extra_params, user
)
if "code_interpreter" in features and features"code_interpreter":
#在表单数据中的messages中,增加CODE_INTERPRETER_PROMPT_TEMPLATE
form_data"messages" = add_or_update_user_message(
(
request.app.state.config.CODE_INTERPRETER_PROMPT_TEMPLATE
if request.app.state.config.CODE_INTERPRETER_PROMPT_TEMPLATE != ""
else DEFAULT_CODE_INTERPRETER_PROMPT
),
form_data"messages",
)
#从表单弹出客户端工具标识列表tool_ids
tool_ids = form_data.pop("tool_ids", None)
files = form_data.pop("files", None)
Remove files duplicates
if files: #对表单中的files列表去重
files = list({json.dumps(f, sort_keys=True): f for f in files}.values())
metadata = {#以下代码中tool_ids和files设置重复,主函数中已经完成了设置
**metadata,
"tool_ids": tool_ids,
"files": files,
}
form_data"metadata" = metadata
'''
以下代码处理工具,本文不展开。
'''
服务侧工具列表
tool_ids = metadata.get("tool_ids", None)
客户端工具列表
tool_servers = metadata.get("tool_servers", None)
log.debug(f"{tool_ids=}")
log.debug(f"{tool_servers=}")
tools_dict = {}
if tool_ids:
tools_dict = get_tools(#根据tool_ids获取tool字典
request,
tool_ids,
user,
{
**extra_params,
"model": modelstask_model_id,
"messages": form_data"messages",
"files": metadata.get("files", \[\]),
},
)
if tool_servers:#把客户侧工具追加到工具字典中
for tool_server in tool_servers:
tool_specs = tool_server.pop("specs", \[\])
for tool in tool_specs:
tools_dicttool\["name"] = {
"spec": tool,
"direct": True,
"server": tool_server,
}
if tools_dict:#处理函数调用
if metadata.get("function_calling") == "native":
如果function_calling是本地调用,则获取本地函数句柄
metadata"tools" = tools_dict
form_data"tools" = [
{"type": "function", "function": tool.get("spec", {})}
for tool in tools_dict.values()
]
else:
如果function_calling非本地调用,则走function calling流程
try:
form_data, flags = await chat_completion_tools_handler(
request, form_data, extra_params, user, models, tools_dict
)#获取到函数调用结果,一般是向量库匹配的文档
sources.extend(flags.get("sources", \[\]))
except Exception as e:
log.exception(e)
try:
#本地调用function calling流程
form_data, flags = await chat_completion_files_handler(request, form_data, user)
sources.extend(flags.get("sources", \[\])) #把 context文件保存到sources列表中
except Exception as e:
log.exception(e)
#把查询到的上下文追加到messages中
if len(sources) > 0:
context_string = ""
citation_idx = {}
for source in sources:
if "document" in source:
for doc_context, doc_meta in zip(
source"document", source"metadata"
):
source_name = source.get("source", {}).get("name", None)
citation_id = (
doc_meta.get("source", None)
or source.get("source", {}).get("id", None)
or "N/A"
)
if citation_id not in citation_idx:
citation_idxcitation_id = len(citation_idx) + 1
context_string += (
f'<source id="{citation_idxcitation_id}"'
(f' name="{source_name}"' if source_name else "")
f">{doc_context}</source>\n"
)
context_string = context_string.strip()
prompt = get_last_user_message(form_data"messages")
if prompt is None:
raise Exception("No user message found")
if (
request.app.state.config.RELEVANCE_THRESHOLD == 0
and context_string.strip() == ""
):
log.debug(
f"With a 0 relevancy threshold for RAG, the context cannot be empty"
)
Workaround for Ollama 2.0+ system prompt issue
TODO: replace with add_or_update_system_message
if model.get("owned_by") == "ollama":
form_data"messages" = prepend_to_first_user_message_content(
rag_template(
request.app.state.config.RAG_TEMPLATE, context_string, prompt
),
form_data"messages",
)
else:
form_data"messages" = add_or_update_system_message(
rag_template(
request.app.state.config.RAG_TEMPLATE, context_string, prompt
),
form_data"messages",
)
If there are citations, add them to the data_items
sources = [
source
for source in sources
if source.get("source", {}).get("name", "")
or source.get("source", {}).get("id", "")
]
if len(sources) > 0:
events.append({"sources": sources})#把
if model_knowledge:#如果有知识库,则发送知识查询请求到前端
await event_emitter(
{
"type": "status",
"data": {
"action": "knowledge_search",
"query": user_message,
"done": True,
"hidden": True,
},
}
)
return form_data, metadata, events
下面对chat_completion_handler函数进行分析。该方法基于原始的请求和process_chat_payload的处理结果,直接通过接口调用ollama中的大模型,获取大模型的应答。chat_completion_handler实际为generate_chat_complete。
流程如下:
1)根据表单中的model参数确定使用的大模型类型
2)评估处理
3)管道相关处理
4)请求数据格式适配openai->ollama,调用ollama api,应答数据格式适配ollama->openai并返回流式应答
async def generate_chat_completion(
request: Request,
form_data: dict,
user: Any,
bypass_filter: bool = False,
):
log.debug(f"generate_chat_completion: {form_data}")
if BYPASS_MODEL_ACCESS_CONTROL: #判断是否绕过模型访问进行控制,缺省为否
bypass_filter = True
if hasattr(request.state, "metadata"):#把request.state.metadata追加到表单中
if "metadata" not in form_data:
form_data"metadata" = request.state.metadata
else:
form_data"metadata" = {
**form_data"metadata",
**request.state.metadata,
}
#确定使用的大模型类型
if getattr(request.state, "direct", False) and hasattr(request.state, "model"):
models = {
request.state.model"id": request.state.model,
}
log.debug(f"direct connection to model: {models}")
else: #对接ollama
models = request.app.state.MODELS
model_id = form_data"model"
if model_id not in models:
raise Exception("Model not found")
model = modelsmodel_id
if getattr(request.state, "direct", False):#前端直连大模型时使用,不予关注
return await generate_direct_chat_completion(
request, form_data, user=user, models=models
)
else:#前端未直连大模型走本分支
用户权限检查
if not bypass_filter and user.role == "user":
try:
check_model_access(user, model)
except Exception as e:
raise e
if model.get("owned_by") == "arena":#处于arena模式时,进入本分支,后继再分析。
model_ids = model.get("info", {}).get("meta", {}).get("model_ids")
filter_mode = model.get("info", {}).get("meta", {}).get("filter_mode")
if model_ids and filter_mode == "exclude":
model_ids = [
model"id"
for model in list(request.app.state.MODELS.values())
if model.get("owned_by") != "arena" and model"id" not in model_ids
]
selected_model_id = None
if isinstance(model_ids, list) and model_ids:
selected_model_id = random.choice(model_ids)
else:
model_ids = [
model"id"
for model in list(request.app.state.MODELS.values())
if model.get("owned_by") != "arena"
]
selected_model_id = random.choice(model_ids)
form_data"model" = selected_model_id
if form_data.get("stream") == True:
async def stream_wrapper(stream):
yield f"data: {json.dumps({'selected_model_id': selected_model_id})}\n\n"
async for chunk in stream:
yield chunk
response = await generate_chat_completion(
request, form_data, user, bypass_filter=True
)
return StreamingResponse(
stream_wrapper(response.body_iterator),
media_type="text/event-stream",
background=response.background,
)
else:
return {
**(
await generate_chat_completion(
request, form_data, user, bypass_filter=True
)
),
"selected_model_id": selected_model_id,
}
#管道处理,目前还没有分析清楚,且跟主流程关系不大,后继再分析
if model.get("pipe"):
Below does not require bypass_filter because this is the only route the uses this function and it is already bypassing the filter
return await generate_function_chat_completion(
request, form_data, user=user, models=models
)
if model.get("owned_by") == "ollama": #重点在这里
调用 /ollama/api/chat,所以要把openai格式的请求表单转换为ollama格式的表单
form_data = convert_payload_openai_to_ollama(form_data)
#发送请求到ollama,接受ollama返回的大模型生成的应答
response = await generate_ollama_chat_completion(
request=request,
form_data=form_data,
user=user,
bypass_filter=bypass_filter,
)
if form_data.get("stream"):#流式应答。一般走这个分支
response.headers"content-type" = "text/event-stream"
return StreamingResponse(
#把ollama的流式应答转换为openai流式应答
convert_streaming_response_ollama_to_openai(response),
headers=dict(response.headers),
background=response.background,
)
else:
return convert_response_ollama_to_openai(response)
else:
return await generate_openai_chat_completion(
request=request,
form_data=form_data,
user=user,
bypass_filter=bypass_filter,
)
下面对入口函数中调用的最后一个函数process_chat_response进行分析。该函数可以说是openwebui中逻辑最复杂的函数,1400多行代码,多层函数嵌套,读起来很吃力,所以首先把该函数内部嵌套声明和调用的函数关系梳理处理,具体如下图所示:
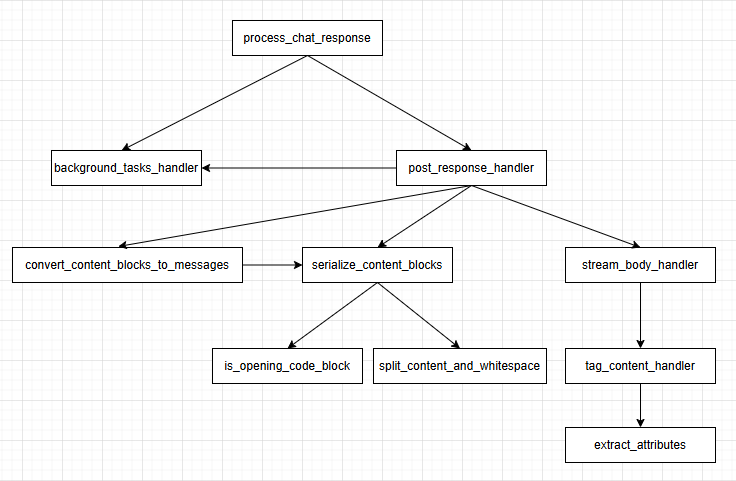
基于上图,按照从上到下的顺序process_chat_response方法进行拆解。为便于分析,在分析过程中把嵌套函数删除,仅保留调用。首先分析最上层的process_chat_response。
流程如下;
1)创建websocket发送工具和调用工具
2)非流式应答检查,不会用到
3)非标准应答处理
4)更新chat表聊天字段
5)创建异步任务执行post_response_handle方法
6)给前端返回{"status": True, "task_id": task_id}
async def process_chat_response(
request, response, form_data, user, metadata, model, events, tasks
):
'''
创建通过websocket给前端发送数据的方法示例,其中event_emitter仅发送数据,无需
应答,event_caller则可以得到前端的应答
'''
event_emitter = None
event_caller = None
if ( #因为在入口已经把chat_id,session_id和id设置到了metadata中,所以走本分支
"session_id" in metadata
and metadata"session_id"
and "chat_id" in metadata
and metadata"chat_id"
and "message_id" in metadata
and metadata"message_id"
):
event_emitter = get_event_emitter(metadata)
event_caller = get_event_call(metadata)
#下面是非流式应答,基本用不到,所以不做忽略
if not isinstance(response, StreamingResponse):
......
#对于非标的应答,直接返回
if not any(
content_type in response.headers"Content-Type"
for content_type in "text/event-stream", "application/x-ndjson"
):
return response
#设置extra_params,后面process_filter_functions方法中使用
extra_params = {
"event_emitter": event_emitter,
"event_call": event_caller,
"user": user.model_dump() if isinstance(user, UserModel) else {},
"metadata": metadata,
"request": request,
"model": model,
}
#获取过滤器函数列表,暂不用关注
filter_functions = [
Functions.get_function_by_id(filter_id)
for filter_id in get_sorted_filter_ids(
request, model, metadata.get("filter_ids", \[\])
)
]
#对应答进行流式响应处理
if event_emitter and event_caller:
task_id = str(uuid4()) # 用UUID生成任务ID
model_id = form_data.get("model", "")
#{"model":"deepseek-r1"}插入到当前对话的history:messages对应的消息中
Chats.upsert_message_to_chat_by_id_and_message_id(
metadata"chat_id",
metadata"message_id",
{
"model": model_id,
},
)
#创建异步任务执行post_response_handle,完成流式应答处理
task_id, _ = await create_task(
request, post_response_handler(response, events), id=metadata"chat_id"
)
return {"status": True, "task_id": task_id}
else: #前后端没有websocket通信时走本路径,不予关注
return StreamingResponse(
stream_wrapper(response.body_iterator, events),
headers=dict(response.headers),
background=response.background,
)
下面分析 post_response_handler方法。
async def post_response_handler(response, events):
#根据消息ID从数据库获取当前消息数据
message = Chats.get_message_by_id_and_message_id(
metadata"chat_id", metadata"message_id"
)
tool_calls = \[\]
#从表单messages中获取助手的应答内容,并设置到content_blocks中
last_assistant_message = None
try: #如果请求表单中最后一个消息是助手消息,则获取助手回复内容
if form_data"messages"-1"role" == "assistant":
last_assistant_message = get_last_assistant_message(
form_data"messages"
)
except Exception as e:
pass
'''如果数据库中存在该消息,则不管content是否存在,都赋值给content,否则使用请
求表单中携带的助手回复内容'''
content = (
message.get("content", "")
if message
else last_assistant_message if last_assistant_message else ""
)
content_blocks = [#用来汇总流式应答中的答复内容,用上面的content初始化
{
"type": "text",
"content": content,
}
]
以下三个常量用于支持推理、解决方案和代码解释,暂不必关注
DETECT_REASONING = True
DETECT_SOLUTION = True
DETECT_CODE_INTERPRETER = metadata.get("features", {}).get(
"code_interpreter", False
)
reasoning_tags = [
("think", "/think"),
("thinking", "/thinking"),
("reason", "/reason"),
("reasoning", "/reasoning"),
("thought", "/thought"),
("Thought", "/Thought"),
("|begin_of_thought|", "|end_of_thought|"),
]
code_interpreter_tags = ("code_interpreter", "/code_interpreter")
solution_tags = ("\|begin_of_solution\|", "\|end_of_solution\|")
try:
for event in events:
await event_emitter(#把event数据推送到前端
{
"type": "chat:completion",
"data": event,
}
)
'''
把process_chat_payload中返回的events插入到chat表
chat:history:message_id中
'''
Chats.upsert_message_to_chat_by_id_and_message_id(
metadata"chat_id",
metadata"message_id",
{
**event,
},
)#endfor
#调用stream_body_handler方法,生成工具调用列表,各种消息处理及通知前端
await stream_body_handler(response)
#以下代码进行函数调用,然后调用generate_chat_completion生成应答
MAX_TOOL_CALL_RETRIES = 10
tool_call_retries = 0
while len(tool_calls) > 0 and tool_call_retries < MAX_TOOL_CALL_RETRIES:
tool_call_retries += 1
response_tool_calls = tool_calls.pop(0)
content_blocks.append(
{
"type": "tool_calls",
"content": response_tool_calls,
}
)
await event_emitter(
{
"type": "chat:completion",
"data": {
"content": serialize_content_blocks(content_blocks),
},
}
)
tools = metadata.get("tools", {})
results = \[\]
for tool_call in response_tool_calls:
tool_call_id = tool_call.get("id", "")
tool_name = tool_call.get("function", {}).get("name", "")
tool_function_params = {}
try:
json.loads cannot be used because some models do not produce valid JSON
tool_function_params = ast.literal_eval(
tool_call.get("function", {}).get("arguments", "{}")
)
except Exception as e:
log.debug(e)
Fallback to JSON parsing
try:
tool_function_params = json.loads(
tool_call.get("function", {}).get("arguments", "{}")
)
except Exception as e:
log.debug(
f"Error parsing tool call arguments: {tool_call.get('function', {}).get('arguments', '{}')}"
)
tool_result = None
if tool_name in tools:
tool = toolstool_name
spec = tool.get("spec", {})
try:
allowed_params = (
spec.get("parameters", {})
.get("properties", {})
.keys()
)
tool_function_params = {
k: v
for k, v in tool_function_params.items()
if k in allowed_params
}
if tool.get("direct", False):
tool_result = await event_caller(
{
"type": "execute:tool",
"data": {
"id": str(uuid4()),
"name": tool_name,
"params": tool_function_params,
"server": tool.get("server", {}),
"session_id": metadata.get(
"session_id", None
),
},
}
)
else:
tool_function = tool"callable"
tool_result = await tool_function(
**tool_function_params
)
except Exception as e:
tool_result = str(e)
tool_result_files = \[\]
if isinstance(tool_result, list):
for item in tool_result:
check if string
if isinstance(item, str) and item.startswith("data:"):
tool_result_files.append(item)
tool_result.remove(item)
if isinstance(tool_result, dict) or isinstance(
tool_result, list
):
tool_result = json.dumps(tool_result, indent=2)
results.append(
{
"tool_call_id": tool_call_id,
"content": tool_result,
**(
{"files": tool_result_files}
if tool_result_files
else {}
),
}
)
content_blocks-1"results" = results
content_blocks.append(
{
"type": "text",
"content": "",
}
)
await event_emitter(
{
"type": "chat:completion",
"data": {
"content": serialize_content_blocks(content_blocks),
},
}
)
try:
res = await generate_chat_completion(
request,
{
"model": model_id,
"stream": True,
"tools": form_data"tools",
"messages": [
*form_data"messages",
*convert_content_blocks_to_messages(content_blocks),
],
},
user,
)
if isinstance(res, StreamingResponse):
await stream_body_handler(res)
else:
break
except Exception as e:
log.debug(e)
break#end while
if DETECT_CODE_INTERPRETER:
MAX_RETRIES = 5
retries = 0
while (
content_blocks-1"type" == "code_interpreter"
and retries < MAX_RETRIES
):
await event_emitter(
{
"type": "chat:completion",
"data": {
"content": serialize_content_blocks(content_blocks),
},
}
)
retries += 1
log.debug(f"Attempt count: {retries}")
output = ""
try:
if content_blocks-1"attributes".get("type") == "code":
code = content_blocks-1"content"
if (
request.app.state.config.CODE_INTERPRETER_ENGINE
== "pyodide"
):
output = await event_caller(
{
"type": "execute:python",
"data": {
"id": str(uuid4()),
"code": code,
"session_id": metadata.get(
"session_id", None
),
},
}
)
elif (
request.app.state.config.CODE_INTERPRETER_ENGINE
== "jupyter"
):
output = await execute_code_jupyter(
request.app.state.config.CODE_INTERPRETER_JUPYTER_URL,
code,
(
request.app.state.config.CODE_INTERPRETER_JUPYTER_AUTH_TOKEN
if request.app.state.config.CODE_INTERPRETER_JUPYTER_AUTH
== "token"
else None
),
(
request.app.state.config.CODE_INTERPRETER_JUPYTER_AUTH_PASSWORD
if request.app.state.config.CODE_INTERPRETER_JUPYTER_AUTH
== "password"
else None
),
request.app.state.config.CODE_INTERPRETER_JUPYTER_TIMEOUT,
)
else:
output = {
"stdout": "Code interpreter engine not configured."
}
log.debug(f"Code interpreter output: {output}")
if isinstance(output, dict):
stdout = output.get("stdout", "")
if isinstance(stdout, str):
stdoutLines = stdout.split("\n")
for idx, line in enumerate(stdoutLines):
if "data:image/png;base64" in line:
image_url = ""
Extract base64 image data from the line
image_data, content_type = (
load_b64_image_data(line)
)
if image_data is not None:
image_url = upload_image(
request,
image_data,
content_type,
metadata,
user,
)
stdoutLinesidx = (
f"!Output Image({image_url})"
)
output"stdout" = "\n".join(stdoutLines)
result = output.get("result", "")
if isinstance(result, str):
resultLines = result.split("\n")
for idx, line in enumerate(resultLines):
if "data:image/png;base64" in line:
image_url = ""
Extract base64 image data from the line
image_data, content_type = (
load_b64_image_data(line)
)
if image_data is not None:
image_url = upload_image(
request,
image_data,
content_type,
metadata,
user,
)
resultLinesidx = (
f"!Output Image({image_url})"
)
output"result" = "\n".join(resultLines)
except Exception as e:
output = str(e)
content_blocks-1"output" = output
content_blocks.append(
{
"type": "text",
"content": "",
}
)
await event_emitter(
{
"type": "chat:completion",
"data": {
"content": serialize_content_blocks(content_blocks),
},
}
)
try:
res = await generate_chat_completion(
request,
{
"model": model_id,
"stream": True,
"messages": [
*form_data"messages",
{
"role": "assistant",
"content": serialize_content_blocks(
content_blocks, raw=True
),
},
],
},
user,
)
if isinstance(res, StreamingResponse):
await stream_body_handler(res)
else:
break
except Exception as e:
log.debug(e)
break#endwhile
#endif DETECT_CODE_INTERPRETER
#从数据库中根据chat_id获取当前会话的标题
title = Chats.get_chat_title_by_id(metadata"chat_id")
data = {#组织完成应答后推送到前端的数据,包括状态、标题和完整的应答
"done": True,
"content": serialize_content_blocks(content_blocks),
"title": title,
}
#把大模型的应答更新到chat表chat字段的Assistant应答数据中
if not ENABLE_REALTIME_CHAT_SAVE:
Save message in the database
Chats.upsert_message_to_chat_by_id_and_message_id(
metadata"chat_id",
metadata"message_id",
{
"content": serialize_content_blocks(content_blocks),
},
)
#如果用户为非活跃状态,则通过webhook通知用户
if not get_active_status_by_user_id(user.id):
webhook_url = Users.get_user_webhook_url_by_id(user.id)
if webhook_url:
post_webhook(
request.app.state.WEBUI_NAME,
webhook_url,
f"{title} - {request.app.state.config.WEBUI_URL}/c/{metadata'chat_id'}\n\n{content}",
{
"action": "chat",
"message": content,
"title": title,
"url": f"{request.app.state.config.WEBUI_URL}/c/{metadata'chat_id'}",
},
)
'''
以下代码通过websocket把应答结束数据data推送到前端,通知前端补足结束,比如
{
"done": true,
"content": "王夫之是中国古代文人墨客中的一位重要人物。他不仅是一位伟大
的文学家,更是一位具有深远历史意义的政治家。\n\n王夫之在诗歌
创作上非常出色,他的诗歌语言流畅,情感深沉,被誉为"诗仙"。此
外,王夫之还是中国现代史上一些重要的事件的参与者。\n\n总的来
说,王夫之是中国古代文人墨客中的一位重要人物。他不仅是一位
伟大的文学家,更是一位具有深远历史意义的政治家。",
"title": "your concise title here"
}
'''
await event_emitter(
{
"type": "chat:completion",
"data": data,
}
)
await background_tasks_handler()
except asyncio.CancelledError:
log.warning("Task was cancelled!")
await event_emitter({"type": "task-cancelled"})
if not ENABLE_REALTIME_CHAT_SAVE:
Save message in the database
Chats.upsert_message_to_chat_by_id_and_message_id(
metadata"chat_id",
metadata"message_id",
{
"content": serialize_content_blocks(content_blocks),
},
)
if response.background is not None:
await response.background()
下面对stream_body_handler函数进行分析,该函数遍历从ollama返回符合openai格式的流,针对流中的每个chunk,从中提取应答内容,通过websocket发送到前端。为便于理解,把一个块内容贴到这里。
{
data:{
"choices": [
{
"delta": {
"content": "熹"
},
"finish_reason": null,
"index": 0,
"logprobs": null
}
],
"object": "chat.completion.chunk",
"usage": null,
"created": 1755398817,
"system_fingerprint": null,
"model": "qwen-max-0428",
"id": "chatcmpl-988e2281-f52d-9956-806d-e454c6cdcd68"
}
}
}
以下是stream_body_handler函数代码。
处理流程如下:
1)content和content_blocks声明为nonlocal,分别用于存放应答内容和内容块
2)遍历流中的块,进行如下处理
2.1)针对数据进行解码、防错和去前缀data:
2.2)过滤器处理
2.3)报错处理和usage处理,推送错误和usage数据到前端
2.4)tool_call处理
2.5)推理处理
2.6)从提取增量应答内容拼接到content中
2.7)把content追加到content_blocks最后一个块中并进行序列化
2.8)把最新的应答全量推送到前端
3)对content_blocks进行清理
4)其他处理
async def stream_body_handler(response):
nonlocal content #保存当前块之前所有块中content中的内容
nonlocal content_blocks
response_tool_calls = \[\]
#以下循环迭代处理流中的块
async for line in response.body_iterator:
''''以下几行代码做解码、防错和去前缀处理'''
#如果做了UTF8编码,则先解码
line = line.decode("utf-8") if isinstance(line, bytes) else line
data = line
如果内容为空则不处理
if not data.strip():
continue
如果非'data:'则不处理
if not data.startswith("data:"):
continue
#把'data:'删除
data = datalen("data:") :.strip()
try:
data = json.loads(data)
data, _ = await process_filter_functions(#过滤器处理,暂不关注
request=request,
filter_functions=filter_functions,
filter_type="stream",
form_data=data,
extra_params=extra_params,
)
if data:
if "event" in data:#如果数据块中有事件,则通过websocket发送到前端
await event_emitter(data.get("event", {}))
if "selected_model_id" in data: #暂不分析
model_id = data"selected_model_id"
Chats.upsert_message_to_chat_by_id_and_message_id(
metadata"chat_id",
metadata"message_id",
{
"selectedModelId": model_id,
},
)
else:
choices = data.get("choices", \[\])
if not choices:#数据中没有choices,往往是报错或者是单纯的usage数据
error = data.get("error", {})
if error: #如果是报错块,则把错误推送到前端
await event_emitter(
{
"type": "chat:completion",
"data": {
"error": error,
},
}
)
usage = data.get("usage", {})
if usage:#把使用情况推送到前端
await event_emitter(
{
"type": "chat:completion",
"data": {
"usage": usage,
},
}
)
continue
delta = choices0.get("delta", {}) #从报文中提取delta内容
delta_tool_calls = delta.get("tool_calls", None) #从delta中提取tool_calls内容
if delta_tool_calls: #工具调用效果相关处理,暂不分析
for delta_tool_call in delta_tool_calls:
tool_call_index = delta_tool_call.get(
"index"
)
if tool_call_index is not None:
Check if the tool call already exists
current_response_tool_call = None
for (
response_tool_call
) in response_tool_calls:
if (
response_tool_call.get("index")
== tool_call_index
):
current_response_tool_call = (
response_tool_call
)
break
if current_response_tool_call is None:
Add the new tool call
delta_tool_call.setdefault(
"function", {}
)
delta_tool_call[
"function"
].setdefault("name", "")
delta_tool_call[
"function"
].setdefault("arguments", "")
response_tool_calls.append(
delta_tool_call
)
else:
Update the existing tool call
delta_name = delta_tool_call.get(
"function", {}
).get("name")
delta_arguments = (
delta_tool_call.get(
"function", {}
).get("arguments")
)
if delta_name:
current_response_tool_call[
"function"
]"name" += delta_name
if delta_arguments:
current_response_tool_call[
"function"
][
"arguments"
] += delta_arguments
value = delta.get("content")
reasoning_content = (
delta.get("reasoning_content")
or delta.get("reasoning")
or delta.get("thinking")
)
if reasoning_content:#推理处理,暂不分析
if (
not content_blocks
or content_blocks-1"type" != "reasoning"
):
reasoning_block = {
"type": "reasoning",
"start_tag": "think",
"end_tag": "/think",
"attributes": {
"type": "reasoning_content"
},
"content": "",
"started_at": time.time(),
}
content_blocks.append(reasoning_block)
else:
reasoning_block = content_blocks-1
reasoning_block"content" += reasoning_content
data = {
"content": serialize_content_blocks(
content_blocks
)
}#endif
if value:
if (
content_blocks
and content_blocks-1"type"
== "reasoning"
and content_blocks-1
.get("attributes", {})
.get("type")
== "reasoning_content"
):#推理处理,暂不分析
reasoning_block = content_blocks-1
reasoning_block"ended_at" = time.time()
reasoning_block"duration" = int(
reasoning_block"ended_at"
- reasoning_block"started_at"
)
content_blocks.append(
{
"type": "text",
"content": "",
}
)
''''以下是无推理情况下收集分块中内容的关键代码'''
content = f"{content}{value}" #把当前块content中的内容拼接到content中
if not content_blocks:
content_blocks.append(
{
"type": "text",
"content": "",
}
)
#把当前块content中的内容拼接到content_blocks最后一个块的cotent中
content_blocks-1"content" = (
content_blocks-1"content" + value
)
if DETECT_REASONING: #推理处理
content, content_blocks, _ = (
tag_content_handler(
"reasoning",
reasoning_tags,
content,
content_blocks,
)
)
if DETECT_CODE_INTERPRETER:#代码解释
content, content_blocks, end = (
tag_content_handler(
"code_interpreter",
code_interpreter_tags,
content,
content_blocks,
)
)
if end:
break
if DETECT_SOLUTION: #解答
content, content_blocks, _ = (
tag_content_handler(
"solution",
solution_tags,
content,
content_blocks,
)
)
#是否把当前块content中的内容拼接到content_blocks
if ENABLE_REALTIME_CHAT_SAVE: #缺省不实时落地
Save message in the database
Chats.upsert_message_to_chat_by_id_and_message_id(
metadata"chat_id",
metadata"message_id",
{
"content": serialize_content_blocks(
content_blocks
),
},
)
else:#把数据序列化
data = {
"content": serialize_content_blocks(
content_blocks
),
}
'''
把前一步序列化后的内容推送到前端,比如以下是连续三个推送到前端数据:
{"type": "chat:completion","data": { "content": "王夫之是中国古代文人"}}
{"type": "chat:completion","data": { "content": "王夫之是中国古代文人墨"}}
{"type": "chat:completion","data": { "content": "王夫之是中国古代文人墨客"}}
推送到前端的内容是截止当前块所有的内容,并非增量内容
'''
await event_emitter(
{
"type": "chat:completion",
"data": data,
}
)
except Exception as e:
done = "data: DONE" in line
if done:
pass
else:
log.debug("Error: ", e)
continue
if content_blocks:#迭代完成流处理后的清理工作
如果最后一个块类型为'text',则删除开头和结尾的空格
if content_blocks-1"type" == "text":
content_blocks-1"content" = content_blocks-1[
"content"
].strip()
#如果当前块内容为空,则从content_blocks中删除
if not content_blocks-1"content":
content_blocks.pop()
#如果content_blocks是空数组,则增加一个内容为空的,类类型为text的块
if not content_blocks:
content_blocks.append(
{
"type": "text",
"content": "",
}
)
if response_tool_calls:#工具调用处理,暂不分析
tool_calls.append(response_tool_calls)
if response.background:#后台任务处理,暂不分析
await response.background()
三、结束处理
前端接受完一次请求的所有数据后,发起补足完成。入口地址为:http://{ip:port}/api/chat/completed,对应入口函数为chat_completed。请求数据如下:
{
"model": "qwen:0.5b",
"messages": [
{
"id": "b4e671e4-1ce1-43cc-a041-9a8e3c3904c4",
"role": "user",
"content": "你好",
"timestamp": 1755409340
},
{
"id": "2268a3da-9a78-4bd9-8cae-d399bed04f2a",
"role": "assistant",
"content": "你好!很高兴能为你提供帮助。如果你有任何问题或需要其他帮助,请随时告诉我,我会尽我所能来帮助你。",
"timestamp": 1755409340,
"usage": {
"response_token/s": 23.56,
"prompt_token/s": 74.05,
"total_duration": 1365798040,
"load_duration": 53633983,
"prompt_eval_count": 9,
"prompt_tokens": 9,
"prompt_eval_duration": 121541610,
"eval_count": 28,
"completion_tokens": 28,
"eval_duration": 1188287448,
"approximate_total": "0h0m1s",
"total_tokens": 37,
"completion_tokens_details": {
"reasoning_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
}
}
],
"model_item": {
"id": "qwen:0.5b",
"name": "qwen:0.5b",
"object": "model",
"created": 1755409331,
"owned_by": "ollama",
"ollama": {
"name": "qwen:0.5b",
"model": "qwen:0.5b",
"modified_at": "2025-08-17T05:40:18.859598053Z",
"size": 394998579,
"digest": "b5dc5e784f2a3ee1582373093acf69a2f4e2ac1710b253a001712b86a61f88bb",
"details": {
"parent_model": "",
"format": "gguf",
"family": "qwen2",
"families": "qwen2",
"parameter_size": "620M",
"quantization_level": "Q4_0"
},
"connection_type": "local",
"urls": 0,
"expires_at": 1755409520
},
"connection_type": "local",
"tags": \[\],
"actions": \[\],
"filters": \[\]
},
"chat_id": "4ce79017-9cc5-499d-9b1f-c9e37048e763",
"session_id": "pT8ZygWewqvn9ugvAAAd",
"id": "2268a3da-9a78-4bd9-8cae-d399bed04f2a"
}
本方法非常精简,在使用ollama时直接调用chat_completed_handler方法,代码如下:
@app.post("/api/chat/completed")
async def chat_completed(
request: Request, form_data: dict, user=Depends(get_verified_user)
):
try:
#从表单中弹出model_item,所以在应答中没有该项
model_item = form_data.pop("model_item", {})
if model_item.get("direct", False):
request.state.direct = True
request.state.model = model_item
return await chat_completed_handler(request, form_data, user)
except Exception as e:
raise HTTPException(
status_code=status.HTTP_400_BAD_REQUEST,
detail=str(e),
)
chat_completed_handler方法对应的是chat.py文件中的chat_completed方法,所以下面分析以下chat_completed。chat_completed中完成流水线处理和过滤器处理,当前分析中均没有处理,所以把请求原封不动的返回到前端,因为在 chat_completed已经把表单中的model_item删除,所以应答中不包含model_item内容。
async def chat_completed(request: Request, form_data: dict, user: Any):
if not request.app.state.MODELS:
await get_all_models(request, user=user)
#直连处理,不必关注
if getattr(request.state, "direct", False) and hasattr(request.state, "model"):
models = {
request.state.model"id": request.state.model,
}
else:
models = request.app.state.MODELS
data = form_data
model_id = data"model"
if model_id not in models:
raise Exception("Model not found")
model = modelsmodel_id #获取使用的模型
try: #流水线处理,暂不关注
data = await process_pipeline_outlet_filter(request, data, user, models)
except Exception as e:
return Exception(f"Error: {e}")
metadata = {
"chat_id": data"chat_id",
"message_id": data"id",
"filter_ids": data.get("filter_ids", \[\]),
"session_id": data"session_id",
"user_id": user.id,
}
extra_params = {
"event_emitter": get_event_emitter(metadata),
"event_call": get_event_call(metadata),
"user": user.model_dump() if isinstance(user, UserModel) else {},
"metadata": metadata,
"request": request,
"model": model,
}
try:
filter_functions = [
Functions.get_function_by_id(filter_id)
for filter_id in get_sorted_filter_ids(
request, model, metadata.get("filter_ids", \[\])
)
]
result, _ = await process_filter_functions(#过滤器处理,暂不关注
request=request,
filter_functions=filter_functions,
filter_type="outlet",
form_data=data,
extra_params=extra_params,
)
return result#数据原封不动返回
except Exception as e:
return Exception(f"Error: {e}")
应答数据为:
{
"model": "qwen:0.5b",
"messages": [
{
"id": "191489de-55b9-4d65-8ac6-7ae3f21b6802",
"role": "user",
"content": "你好",
"timestamp": 1755409340
},
{
"id": "d4ce313b-07ba-4941-81a1-0b114df1babe",
"role": "assistant",
"content": "你好!很高兴能为你提供帮助。如果你有任何问题或需要其他帮助,请随时告诉我,我会尽我所能来帮助你。",
"timestamp": 1755409340,
"usage": {
"response_token/s": 23.56,
"prompt_token/s": 74.05,
"total_duration": 1365798040,
"load_duration": 53633983,
"prompt_eval_count": 9,
"prompt_tokens": 9,
"prompt_eval_duration": 121541610,
"eval_count": 28,
"completion_tokens": 28,
"eval_duration": 1188287448,
"approximate_total": "0h0m1s",
"total_tokens": 37,
"completion_tokens_details": {
"reasoning_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
}
}
],
"chat_id": "b0e898f4-4299-49bd-87b7-27bd67dfc317",
"session_id": "pT8ZygWewqvn9ugvAAAd",
"id": "d4ce313b-07ba-4941-81a1-0b114df1babe"
}