使用 OpenAI Responses API 构建生产级应用的终极指南
------ 状态、流式、异步与文件处理
本文是一份面向开发者的全面技术指南,介绍如何使用 OpenAI Responses API 构建下一代 有状态、可观测、异步、具备文件处理能力的智能体级应用 。
重点涵盖四大核心支柱:状态管理、流式传输、异步执行与文件处理。
一、从无状态提示到有状态代理
背景:无状态的限制
在早期的 LLM 应用中,API 是无状态 的:
每次调用都是独立的,模型并不会"记得"过去的对话。开发者不得不在每次请求中手动附加完整的对话历史。
问题:
- 成本指数级上升:每次都为相同历史重复付费。
- 上下文窗口受限:对话增长后会超出模型 token 限制。
Responses API 的诞生
为了解决这些核心问题,OpenAI 推出了 统一的 Responses API (/v1/responses)。
它整合了:
- 状态管理
- 工具调用 (Tool Use)
- 异步任务 (Background Jobs)
- 文件与视觉处理 (Files & Vision)
这不仅是 API 的升级,而是一次架构级的范式转变 :
从无状态机器人 (bots) 到有状态代理 (agents)。
二、对话核心:状态管理 (State)
1. 无状态的痛点
| 问题 | 描述 |
|---|---|
| 成本高 | 每次请求都要重新提交完整聊天历史 |
| 有限上下文 | 最终会触及模型 token 限制 |
| 延迟大 | 数据冗余导致性能下降 |
2. 传统变通方案(及其缺陷)
| 方法 | 优点 | 缺点 |
|---|---|---|
| 窗口化 (Windowing) | 简单 | 丢失上下文 |
| 摘要化 (Summarization) | 节省 token | 成本高、易丢信息 |
| Embedding + RAG | 精确召回 | 复杂、昂贵 |
3. Responses API 内置机制
✅ 机制 1:store: true
默认启用。OpenAI 会在服务器端自动维护"回合到回合"的上下文状态。
✅ 机制 2:previous_response_id
这是实现状态的关键参数。
无需重复发送整个 messages 历史,只需提交:
- 当前用户输入
input - 上一轮响应的
previous_response_id
原理:
OpenAI 会根据该 ID 从缓存恢复完整上下文,仅处理新的输入。
因此只为增量部分付费,显著降低成本。
4. 有状态对话代码示例
python
from openai import OpenAI
client = OpenAI(api_key="YOUR_API_KEY")
last_id = None
print("Chat session started. Type 'exit' to quit.")
while True:
user_input = input("\n> ")
if user_input.lower() in ["exit", "quit"]:
break
response = client.responses.create(
model="gpt-4o",
input=user_input,
**({"previous_response_id": last_id} if last_id else {})
)
last_id = response.id
print("\n" + response.output_text)三、实时体验:流式传输 (Streaming)
1. 问题:阻塞式等待
传统调用会在模型生成完全部响应后才返回,导致 UX 极差。
2. 解决方案:stream: true
启用流式传输后,API 使用 SSE (Server-Sent Events) 持续推送事件流。
3. Python 示例
python
from openai import OpenAI
client = OpenAI()
stream = client.responses.create(
model="gpt-4o",
input="Explain quantum computing simply.",
stream=True,
)
for event in stream:
if event.type == "response.output_text.delta":
print(event.delta, end="")4. Node.js 示例
js
import { OpenAI } from "openai";
const client = new OpenAI();
const stream = await client.responses.create({
model: "gpt-4o",
input: "Explain quantum computing simply.",
stream: true,
});
for await (const event of stream) {
if (event.type === "response.output_text.delta") {
process.stdout.write(event.delta);
}
}5. 流式事件的真正意义:可观测代理
| 事件类型 | 含义 |
|---|---|
response.output_text.delta |
模型正在生成文字 |
ResponseFileSearchCallInProgress |
正在执行文件检索 |
ResponseCodeInterpreterInProgress |
正在运行代码 |
response.completed |
响应结束 |
这意味着前端 UI 可以展示更丰富的状态提示,例如:
🧠 正在推理中...
🔍 正在搜索文件...
💻 正在执行代码...
✅ 已生成答案!
四、长任务处理:异步模式 (Asynchrony)
1. 问题:HTTP 超时
生成长文本、分析大型文件可能需要几分钟。普通 HTTP 请求会超时。
2. 解决方案:background: true
此模式会立即返回一个任务 ID,而模型在后台继续运行。
python
from openai import OpenAI
client = OpenAI()
resp = client.responses.create(
model="o3",
input="Write a long novel about otters in space.",
background=True,
)
print(f"Job submitted. ID: {resp.id}, Status: {resp.status}")3. 获取结果:轮询模式
python
from time import sleep
while resp.status in {"queued", "in_progress"}:
sleep(2)
resp = client.responses.retrieve(resp.id)
print(resp.output_text)4. 生产级方案:Webhook 通知
在 OpenAI 控制台配置 Webhook,让模型在后台任务完成时主动回调你的服务。
✅ Python 示例 (Flask)
python
from openai import OpenAI, InvalidWebhookSignatureError
from flask import Flask, request, Response
import os
app = Flask(__name__)
client = OpenAI(webhook_secret=os.environ["OPENAI_WEBHOOK_SECRET"])
@app.route("/webhook", methods=["POST"])
def webhook():
try:
event = client.webhooks.unwrap(request.data, request.headers)
if event.type == "response.completed":
print(f"Response completed: {event.data.id}")
return Response(status=200)
except InvalidWebhookSignatureError:
return Response("Invalid signature", status=400)五、文件与 PDF 处理 (Files)
文件交互有四种主要模式:
| 方法 | 场景 | 复杂度 | 成本 |
|---|---|---|---|
| ① Vision 直接分析 | 视觉+文本混合 PDF | 低 | 高 |
| ② Assistants RAG | 有状态文档问答 | 中 | 中 |
| ③ Responses RAG | 无状态 API 调用 | 中 | 中 |
| ④ 手动 RAG | 完全自定义管线 | 高 | 可变 |
方法 1:使用 GPT-4o 直接分析文件
python
file = client.files.create(file=open("report.pdf", "rb"), purpose="user_data")
response = client.responses.create(
model="gpt-4o",
input=[{
"role": "user",
"content": [
{"type": "input_file", "file_id": file.id},
{"type": "input_text", "text": "请总结第3页的图表内容"}
]
}]
)
print(response.output_text)方法 2:Assistants API 自动 RAG
OpenAI 自动管理文件分块、嵌入与检索:
python
assistant = client.beta.assistants.create(
name="Financial Analyst Assistant",
model="gpt-4o",
tools=[{"type": "file_search"}],
)方法 3:Responses RAG(灵活版)
结合 Responses API + Vector Store:
python
response = client.responses.create(
model="gpt-4.1",
input="Explain Deep Research by OpenAI.",
tools=[{"type": "file_search", "vector_store_ids": ["vs_123..."]}],
)
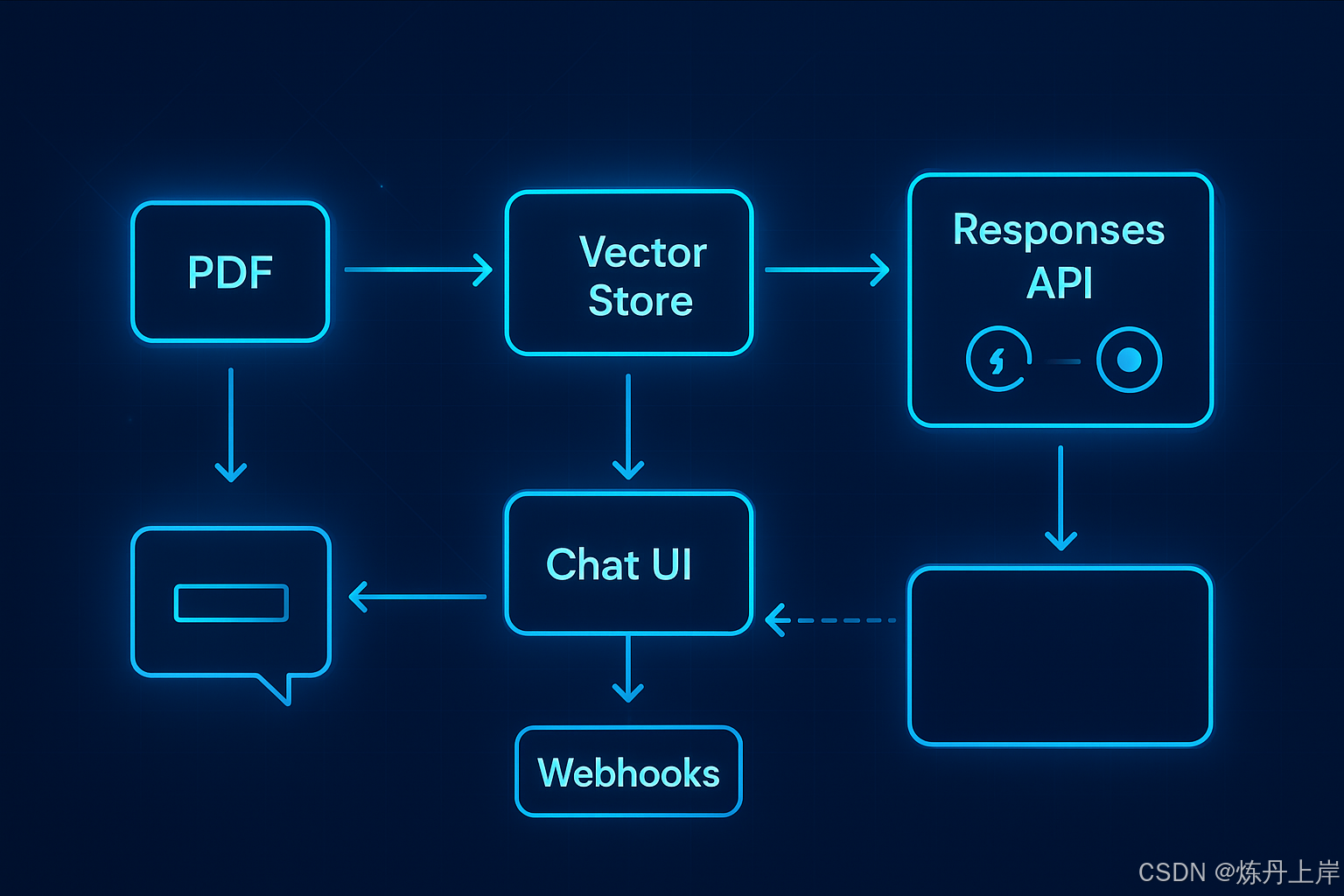
print(response.output_text)六、综合案例:异步 RAG 代理架构
项目目标:
构建一个 Web 应用:
- 用户上传大型 PDF(>100页)
- 后台异步解析与嵌入
- 前端聊天界面实时流式交互
技术结构:
- 上传阶段 →
/v1/files→ 存储并关联vector_store - 后台阶段 →
background: true异步预处理 - 对话阶段 →
responses.create(stream=True)流式实时聊天 - Webhook 通知 → 任务完成后自动更新状态
七、结语:下一代智能体开发的关键
Responses API 是 OpenAI 的统一智能体层 。
它打通了过去分散的能力边界,成为:
🧠「一个可以思考、记忆、观察、行动的通用接口」。
未来,所有基于 GPT 的生产应用------无论是对话、工作流还是自动化智能体------都将以 Responses API 为核心。