概念(HIVE并非数据库)
Hive 是基于 Hadoop 的一个数据仓库工具,可以将 结构化的数据文件 映射为一张表
( 类似于 RDBMS 中的表 ) ,并提供类 SQL 查询功能; Hive 是由 Facebook 开源,用于解
决海量结构化日志的数据统计。
Hive 本质是:将 SQL 转换为 MapReduce 的任务进行运算
底层由 HDFS 来提供数据存储
可以将 Hive 理解为一个: 将 SQL 转换为 MapReduce 任务的工具
HIVE的安装配置
参考我这边文章装mysql:Linux------MySQL8安装(更新)_linux wgt安装mysql8-CSDN博客
下载网址:http://archive.apache.org/dist/hive/
mysql里边创建hive用户
bash
-- 创建用户设置口令、授权、刷新
CREATE USER 'hive'@'%' IDENTIFIED BY '12345678';
GRANT ALL ON *.* TO 'hive'@'%';
FLUSH PRIVILEGES;解压文件:tar zxvf apache-hive-2.3.7-bin.tar.gz -C ../servers/
重命名文件:mv apache-hive-2.3.7-bin hive-2.3.7
bash
# 在 /etc/profile 文件中增加环境变量
export HIVE_HOME=/opt/lxq/servers/hive-2.3.7
export PATH=$PATH:$HIVE_HOME/bin
# 执行并生效
source /etc/profilecd $HIVE_HOME/conf vi hive-site.xml 增加以下内容:
XML
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- hive元数据的存储位置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://linux123:3306/hivemetadata?createDatabaseIfNotExist=true&useSSL=false</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<!-- 指定驱动程序 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!-- 连接数据库的用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<!-- 连接数据库的口令 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>12345678</value>
<description>password to use against metastore database</description>
</property>
</configuration>将 mysql-connector-java-5.1.46.jar 拷贝到 $HIVE_HOME/lib
**初始化元数据库:**schematool -dbType mysql -initSchema
启动HIVE
启动 hive 服务之前,请先启动 hdfs 、 yarn 的服务
root@linux123 \~ $ hive
hive> show functions;
Hive****属性配置
hive-site.xml 中增加以下常用配置
XML
<property>
<!-- 数据默认的存储位置(HDFS) -->
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<property>
<!-- 在命令行中,显示当前操作的数据库 -->
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>
<property>
<!-- 在命令行中,显示数据的表头 -->
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<!-- 操作小规模数据时,使用本地模式,提高效率 -->
<name>hive.exec.mode.local.auto</name>
<value>true</value>
<description>Let Hive determine whether to run in local mode automatically</description>
</property>hive日志文件
Hive 的 log 默认存放在 /tmp/root 目录下( root 为当前用户名);这个位置可以修 改:
vi $HIVE_HOME /conf/hive-log4j2.properties添加以下内容:
property.hive.log.dir = /opt/lxq/servers/hive-2.3.7/logs
-- 查看全部参数
hive> set ;
-- 查看某个参数
hive> set hive .exec.mode.local.auto ;
hive .exec.mode.local.auto = false
1 、用户自定义配置文件 (hive-site.xml)
2 、启动 hive 时指定参数 (-hiveconf)
3 、 hive 命令行指定参数 (set)
配置信息的优先级:
set > -hiveconf > hive-site.xml > hive-default.xml
hive命令
bash
hive -e "select * from users"
# 执行文件中的SQL语句
hive -f hqlfile1.sql
# 执行文件中的SQL语句,将结果写入文件
hive -f hqlfile1.sql >> result1.log
exit; quit;
# 在命令行执行 shell 命令 / dfs 命令
hive> ! ls;
hive> ! clear;
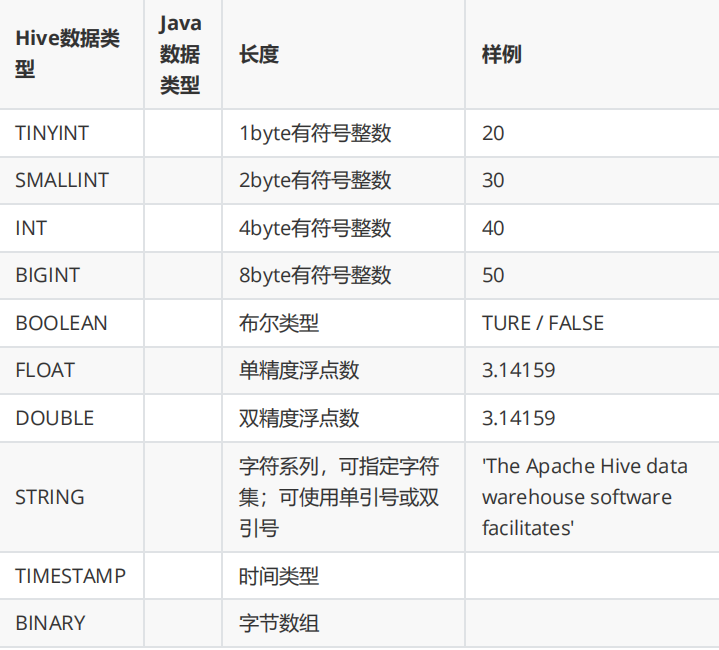
hive> dfs -ls / ;HIVE数据类型
基本类型
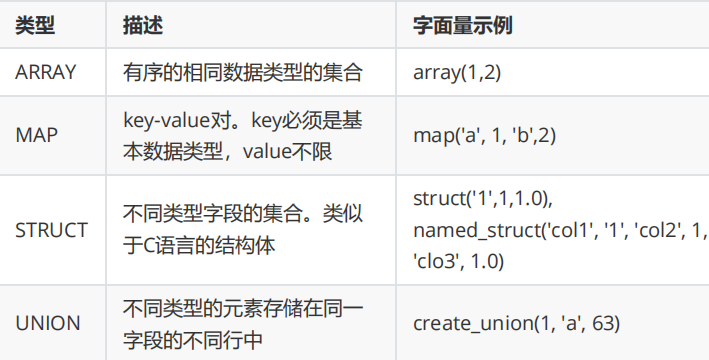
集合类型
HQL常用的一些DDL命令
-- 避免数据库已经存在时报错,使用 if not exists 进行判断【标准写法】
hive (default)> create database if not exists mydb;
-- 查看所有数据库
show databases;
-- 查看数据库信息
desc database mydb2;
desc database extended mydb2;
describe database extended mydb2
-- 使用数据库
use mydb;
-- 如果数据库不为空,使用 cascade 强制删除
drop database databasename cascade ;
默认情况下,创建内部表。如果要创建外部表,需要使用关键字 external
在删除内部表时,表的定义 ( 元数据 ) 和 数据 同时被删除
在删除外部表时,仅删除表的定义,数据被保留
在生产环境中,多使用外部表
-- 创建内部表 加上 external就是外部表 分桶规则:分桶字段 .hashCode % 分桶数
create external table t1(
id int ,
name string,
hobby array<string>,
addr map<string, string>
)
partitioned by (dt string)
clustered by (id) into 3 buckets
row format delimited
fields terminated by ";"
collection items terminated by ","
map keys terminated by ":" ;
-- 只能 通过 insert ... select ... 给桶表加载数据
insert into table course select * from course_common;
-- 显示表的定义,显示的信息较少
desc t1;
-- 显示表的定义,显示的信息多,格式友好
desc formatted t1;
-- 加载数据
load data local inpath '/home/hadoop/data/t1.dat' into table t1;
-- 加载数据到分区
load data local inpath "/home/hadoop/data/t1.dat" into table t3 partition(dt= "2024-06-01" );
insert overwrite table tabC partition(month= '202403' ) select id, name, area where month= '202402';
import table student2 partition(month= '201709' )
from '/user/hive/warehouse/export/student' ;
-- 删除表。表和数据同时被删除
drop table t1;
-- 内部表转外部表
alter table t1 set tblproperties( 'EXTERNAL' = 'TRUE' );
-- 查询表信息,是否转换成功
desc formatted t1;
-- 外部表转内部表。 EXTERNAL 大写, false 不区分大小
alter table t1 set tblproperties( 'EXTERNAL' = 'FALSE' );
-- 查询表信息,是否转换成功
desc formatted t1;
-- 查看分区
show partitions t3;
-- 增加一个分区,不加载数据 后边加了location就是加载数据
alter table t3 add partition(dt= '2024-06-03' ) partition(dt= '2024-06-06' )
location '/user/hive/warehouse/mydb.db/t3/dt=2024-06-07' ;
-- 修改分区的 hdfs 路径
alter table t3 partition(dt= '2024-06-01' ) set location '/user/hive/warehouse/t3/dt=2024-06-03' ;
-- 可以删除一个或多个分区,用逗号隔开
alter table t3 drop partition(dt= '2020-06-03' ), partition(dt= '2020-06-04' );
-- 修改表名。 rename
alter table course_common
rename to course_common1;
-- 修改列名。 change column
alter table course_common1
change column id cid int ;
-- 修改字段类型。 change column
alter table course_common1
change column cid cid string;
-- The following columns have types incompatible with the
existing columns in their respective positions
-- 修改字段数据类型时,要满足数据类型转换的要求。如 int 可以转为 string ,但是
string 不能转为 int
-- 增加字段。 add columns
alter table course_common1
add columns (common string);
-- 删除字段: replace columns
-- 这里仅仅只是在元数据中删除了字段,并没有改动 hdfs 上的数据文件
alter table course_common1
replace columns(
id string, cname string, score int );
-- 删除表
drop table course_common1;
-- 根据查询结果创建表
create table if not exists tabD
as select * from tabC;
-- 将查询结果导出到本地
insert overwrite local directory '/home/hadoop/data/tabC'
select * from tabC;
-- 将查询结果格式化输出到本地
insert overwrite local directory '/home/hadoop/data/tabC2'
row format delimited fields terminated by ' '
select * from tabC;
-- 将查询结果导出到 HDFS
insert overwrite directory '/user/hadoop/data/tabC3'
row format delimited fields terminated by ' '
select * from tabC;
-- hive 命令导出数据到本地。执行查询将查询结果重定向到文件
hive -e "select * from tabC" > a .log
-- export 导出数据到 HDFS 。使用 export 导出数据时,不仅有数还有表的元数据信
息
export table tabC to '/user/hadoop/data/tabC4' ;
-- export 导出的数据,可以使用 import 命令导入到 Hive 表中
-- 使用 like tname 创建的表结构与原表一致。 create ... as select ...
结构可能不一致
create table tabE like tabc;
import table tabE from '' /user/hadoop/data/tabC4 ';
-- 截断表,清空数据。 ( 注意:仅能操作内部表 )
truncate table tabE;
-- 以下语句报错,外部表不能执行 truncate 操作
alter table tabC set tblproperties("EXTERNAL"="TRUE");
truncate table tabC;
-- 查看系统自带函数
show functions;
-- 显示自带函数的用法
desc function upper;
desc function extended upper;
读时模式
在传统数据库中,在加载时发现数据不符合表的定义,则拒绝加载数据。数据在写入
数据库时对照表模式进行检查,这种模式称为 " 写时模式 " ( schema on write )。
写时模式 -> 写数据检查 -> RDBMS ;
Hive 中数据加载过程采用 " 读时模式 " (schema on read) ,加载数据时不进行数据格
式的校验,读取数据时如果不合法则显示 NULL 。这种模式的优点是加载数据迅速。
读时模式 -> 读时检查数据 -> Hive ;好处:加载数据快;问题:数据显示 NULL
感谢阅读!!!