一、引言
spdlog是一个开源、高性能、跨平台的C++日志库,基于C++11实现,旨在提供极致的性能与易用性。它在GitHub上获得了广泛的关注和应用,已成为C++社区中最受欢迎的日志库之一。spdlog具有以下特性:
- 卓越性能:spdlog专为高速记录而设计,异步模式下可达数百万条/秒的日志吞吐量,相比glog、log4cplus等传统日志库有显著性能优势。
- 高度可扩展:支持多种输出目标(Sink),包括文件(带轮转功能)、控制台、系统日志、TCP传输等,并允许用户自定义Sink。
- 线程安全:所有组件均设计为线程安全,多线程环境下无需额外同步
- 灵活格式化**:内置高性能异步日志机制,通过线程池处理日志写入,避免I/O操作阻塞主线程
- 高效的格式化: 基于fmt库提供丰富的格式定制功能,支持类似Python的格式化语法。
- 轻量级:支持Head-only模式,只需包含头文件即可集成到项目中
- 多日志级别:提供trace、debug、info、warn、error和critical等多种日志级别,支持运行时动态调整
除性能强大外,spdlog 也是学习 C++ 编程的优质素材。项目代码量适中,功能清晰易懂,无需额外背景知识,源码可读性强。其中涉及的设计模式、模板编程等技巧,非常值得像笔者这样的编程不够优雅的初学者学习。
本文将先介绍 spdlog 的基本使用,再分析其项目架构设计,并结合核心特性解析源码实现。
二、使用方法
2.1 集成方式
spdlog可以通过两种方式集成到项目中:
- Head-only version: 只需将库中的头文件复制到项目目录下,即可在项目中使用
- Compiled version:需要先将spdlog编译成静态库,然后在项目中链接使用
Head-only其实就是在头文件中也包含了函数的实现,所以缺点是同样的函数实现每次包含头文件都会重复编译一遍,会有点开销。好处就是使用起来很简单,直接在文件里#include "spdlog/spdlog.h"基本就能使用了
2.1.1 Head-only version
首先先下载项目源文件:
shell
$ git clone https://github.com/gabime/spdlog.git然后将其中的/include文件夹拷贝到自己的项目里就可以使用了
2.1.2 Compiled version
同样先下载源文件,源文件里提供了CMakeLists.txt文件,只需要在对应的平台执行对应的cmake命令就行
- Linux,先创建
/build目录用来存放编译产生的文件,然后执行cmake相关命令,编译出静态库libspdlog.a
shell
$ cd spdlog
$ mkdir build && cd build
$ cmake .. && cmake --build .- Windows,如果使用minGW,按以下方式编译,编译出静态库
libspdlog.a
shell
$ cd spdlog
$ mkdir build && cd build
$ cmake .. -G "MinGW Makefiles"
$ cmake --build .如果使用MSVC,以Visual Studio 2022为例
shell
$ cd spdlog
$ mkdir build && cd build
$ cmake -G "Visual Studio 17 2022" -A x64 ..会在/build目录下生成一系列工程文件,打开其中的spdlog.sln,并在VS里点击"生成->生成解决方案",即可完成编译,静态库是Debug或Release目录下的spdlog.lib
2.2 功能介绍
2.2.1 基础示例
spdlog支持的日志级别从低到高包括:trace, debug, info, warn, error, critical, off, 枚举定义如下:
c++
#define SPDLOG_LEVEL_TRACE 0
#define SPDLOG_LEVEL_DEBUG 1
#define SPDLOG_LEVEL_INFO 2
#define SPDLOG_LEVEL_WARN 3
#define SPDLOG_LEVEL_ERROR 4
#define SPDLOG_LEVEL_CRITICAL 5
#define SPDLOG_LEVEL_OFF 6
// Log level enum
namespace level {
enum level_enum : int {
trace = SPDLOG_LEVEL_TRACE,
debug = SPDLOG_LEVEL_DEBUG,
info = SPDLOG_LEVEL_INFO,
warn = SPDLOG_LEVEL_WARN,
err = SPDLOG_LEVEL_ERROR,
critical = SPDLOG_LEVEL_CRITICAL,
off = SPDLOG_LEVEL_OFF,
n_levels
};包含了必要的头文件后,可以直接使用spdlog::info(), spdlog::error()这样的接口输出日志
c++
#include "spdlog/spdlog.h"
int main()
{
// 可以直接输出一行字符串
spdlog::info("Welcome to spdlog!");
// 也可以支持字符串格式化输出
spdlog::error("Some error message with arg: {}", 1);
// d 表示十进制整数, 08表示总宽度为8位,不足部分用0填充
spdlog::warn("Easy padding in numbers like {:08d}", 12);
// 输出整数 42 的不同进制表示 d-十进制 x-十六进制 o-八进制 b-二进制, 冒号左边的0表示参数的索引
spdlog::critical("Support for int: {0:d}; hex: {0:x}; oct: {0:o}; bin: {0:b}", 42);
// 03表示总宽度为3位,不足用0填充; .2表示保留两位小数
spdlog::info("Support for floats {:03.2f}", 1.23456);
// 支持在{}中指定位置参数
spdlog::info("Positional args are {1} {0}..", "too", "supported");
// 左对齐, 总宽度30个字符
spdlog::info("{:<30}", "left aligned");
// 设置全局日志等级为debug(默认是info), 之后 >=debug 的日志都可以输出
spdlog::set_level(spdlog::level::debug); // Set *global* log level to debug
spdlog::debug("This message should be displayed..");
// 支持自定义日志格式
spdlog::set_pattern("[%H:%M:%S %z] [%n] [%^---%L---%$] [thread %t] %v");
// 另外也可以通过宏来输出日志
// 需注意的是它们不受set_pattern的影响, 只取决编译时 SPDLOG_ACTIVE_LEVEL 的值
// 默认 #define SPDLOG_ACTIVE_LEVEL SPDLOG_LEVEL_INFO
SPDLOG_TRACE("Some trace message with param {}", 42);
SPDLOG_DEBUG("Some debug message");
}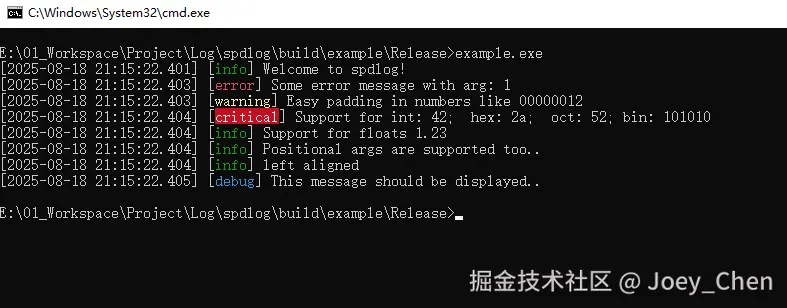
直接使用spdlog::info()等接口,日志内容默认是输出到控制台,即标准输出stdout
2.2.2 创建logger对象: 标准输出(stdout)/标准错误(stderr)
spdlog是通过logger对象来完成日志输出的,内部通过一个map来维护所有logger,每个logger会有一个对应的名字。初始化时会创建一个名字为空串的default_logger_,直接调用sdplog::info()其实是通过这个default_logger_来完成操作。
可以通过接口手动创建多个logger对象并指定其名字,然后调用特定的logger对象输出日志。如下所示:
c++
#include "spdlog/spdlog.h"
#include "spdlog/sinks/stdout_color_sinks.h"
void stdout_example()
{
auto console = spdlog::stdout_color_mt("console");
auto err_logger = spdlog::stderr_color_mt("stderr");
spdlog::get("console")->info("loggers can be retrieved from a global registry using the spdlog::get(logger_name)");
}2.2.3 基础日志文件
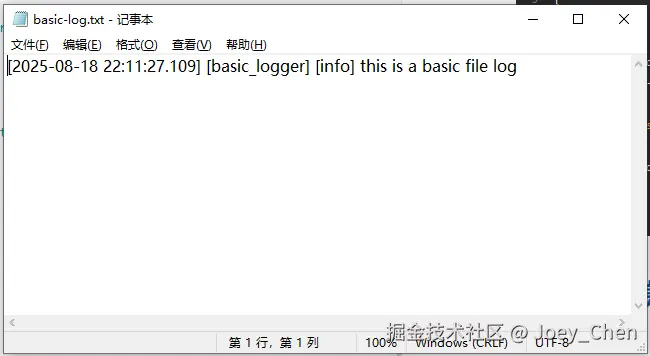
通常我们更习惯于将日志输出到文件中,便于查看日志信息。sdplog支持将日志输出到文件中,如下所示:
c++
#include "spdlog/sinks/basic_file_sink.h"
void basic_logfile_example()
{
try
{
auto logger = spdlog::basic_logger_mt("basic_logger", "logs/basic-log.txt");
logger->info("this is a basic file log");
}
catch (const spdlog::spdlog_ex &ex)
{
std::cout << "Log init failed: " << ex.what() << std::endl;
}
}
2.2.4 按大小轮转的文件
系统长时间工作时,如果所有日志信息都保存在单个文件内,会导致单个文件过大。spdlog支持基于文件大小的自动轮转机制,可以设置单个文件大小阈值和总文件数量。
当日志文件达到预设的 max_size 阈值时,自动触发轮转流程,将当前文件重命名为序号文件(如log.txt → log.1.txt),同时创建新的主日志文件。日志文件总数限制为max_files,当新的文件生成时,如果文件总数超过max_files,将会删除最早的那一份文件。
c++
#include "spdlog/sinks/rotating_file_sink.h"
void rotating_example()
{
// 创建轮转日志, 单个文件大小限制为5MB, 文件总数限制为3个
auto max_size = 1048576 * 5;
auto max_files = 3;
auto logger = spdlog::rotating_logger_mt("some_logger_name", "logs/rotating.txt", max_size, max_files);
}2.2.5 每日定时创建新文件
日志轮转始终会丢失一些早期的日志信息,如果既要保留所有的信息,又要防止单个文件过大,一个折中的方法是每天都新建一个文件来记录日志:
c++
#include "spdlog/sinks/daily_file_sink.h"
void daily_example()
{
// 每天 2:30 am 定时创建新文件
auto logger = spdlog::daily_logger_mt("daily_logger", "logs/daily.txt", 2, 30);
}2.2.6 同时支持多个输出方式
如果想让记录的日志既输出到控制台可以实时查看,又保存到文件便于日后排查,可以为logger对象设置两个目标对象,每个目标对象可以单独设置日志等级和日志格式:
c++
// The console will show only warnings or errors, while the file will log all.
void multi_sink_example()
{
auto console_sink = std::make_shared<spdlog::sinks::stdout_color_sink_mt>();
console_sink->set_level(spdlog::level::warn);
console_sink->set_pattern("[multi_sink_example] [%^%l%$] %v");
auto file_sink = std::make_shared<spdlog::sinks::basic_file_sink_mt>("logs/multisink.txt", true);
file_sink->set_level(spdlog::level::trace);
spdlog::logger logger("multi_sink", {console_sink, file_sink});
logger.warn("this should appear in both console and file");
logger.info("this message should not appear in the console, only in the file");
}2.2.7 异步日志
以上介绍的都是同步日志,例如线程运行到spdlog::info()时,需要等待日志操作完成,才能继续往下执行。
spdlog支持异步日志,可以将日志消息发送到一个单独的线程进行处理,从而减少对主线程性能的影响。
c++
#include "spdlog/async.h"
#include "spdlog/sinks/basic_file_sink.h"
void async_example()
{
// default thread pool settings can be modified *before* creating the async logger:
// spdlog::init_thread_pool(8192, 1); // queue with 8k items and 1 backing thread.
auto async_file = spdlog::basic_logger_mt<spdlog::async_factory>("async_file_logger", "logs/async_log.txt");
// alternatively:
// auto async_file = spdlog::create_async<spdlog::sinks::basic_file_sink_mt>("async_file_logger", "logs/async_log.txt");
}三、源码赏析
3.1 架构设计
txt
spdlog
├─example // 示例代码
├─include
│ └─spdlog // 核心实现目录
│ ├─details // 内部功能实现
│ ├─fmt // {fmt} 格式化库
│ ├─sinks // 日志输出目标实现
│ └─*.h // 接口与异步模式实现
├─src // .cpp 文件,用于生成静态库
├─test // 测试代码spdlog项目代码结构如上所示,其中include/spdlog是核心实现目录,sdplog的项目架构设计如下图所示:
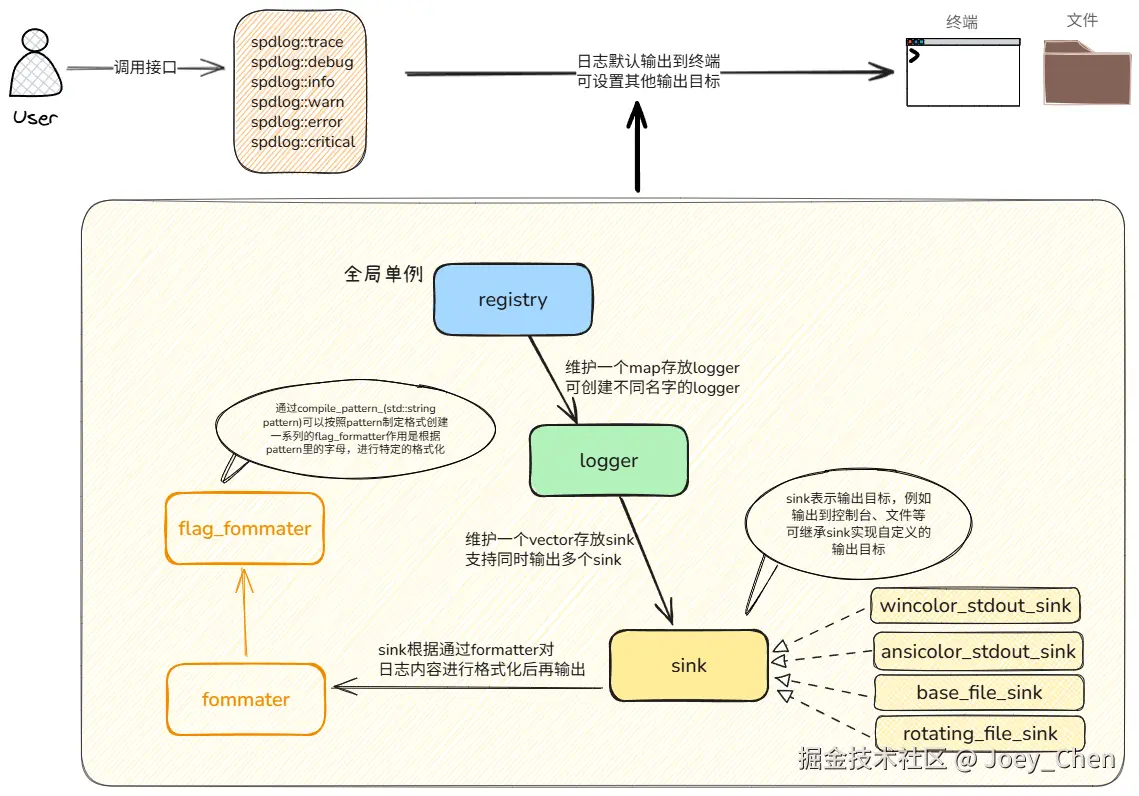
registry
该类通过集中管理日志器生命周期、全局配置和后台任务,实现了spdlog库的核心架构设计,是连接日志器、格式化器、 sinks和线程池的关键组件
-
日志器生命周期管理
- 唯一注册机制:通过
register_logger和register_or_replace方法维护全局唯一的日志器名称映射(loggers_成员),防止重复创建同名日志器 - 统一销毁接口:提供
drop、drop_all和shutdown实现日志器的精细化销毁和资源清理
- 唯一注册机制:通过
-
全局配置中心
- 日志级别管理:通过
set_level和set_levels控制全局和特定日志器的日志级别 - 格式化器设置:
set_formatter为所有日志器统一设置日志格式 - 刷新策略配置:提供
flush_on和flush_every控制日志刷新级别和周期
- 日志级别管理:通过
-
线程池与后台任务协调
- 线程池管理:通过
set_tp和get_tp管理全局线程池,为异步日志器提供工作线程 - 周期任务调度:使用
periodic_worker实现定期刷新日志功能(periodic_flusher_成员)
- 线程池管理:通过
-
单例模式与线程安全
- 单例实现:通过
instance保证全局唯一实例,避免多实例冲突 - 线程同步:使用
logger_map_mutex_、flusher_mutex_和tp_mutex_等互斥量确保多线程环境下的操作安全
- 单例实现:通过
-
辅助功能
- 默认日志器:
default_logger和set_default_logger提供便捷的默认日志器访问方式 - 错误处理:
set_error_handler设置全局日志错误处理器 - 回溯功能:
enable_backtrace和disable_backtrace控制日志回溯功能
- 默认日志器:
logger
logger类负责协调日志的生成、格式化、分发和输出
-
作为日志操作的入口
logger是用户直接操作的对象,提供了一系列与日志级别对应的成员函数(如trace()、debug()、info()、warn()、error()、critical()),用户通过调用这些函数生成日志消息。 -
管理关联的
sink集合一个
logger可以关联一个或多个sink(通过构造函数传入),实现 "一条日志同时输出到多个目标"。c++class SPDLOG_API logger { public: // Empty logger explicit logger(std::string name) : name_(std::move(name)), sinks_() {} // Logger with range on sinks template <typename It> logger(std::string name, It begin, It end) : name_(std::move(name)), sinks_(begin, end) {} // Logger with single sink logger(std::string name, sink_ptr single_sink) : logger(std::move(name), {std::move(single_sink)}) {} // Logger with sinks init list logger(std::string name, sinks_init_list sinks) : logger(std::move(name), sinks.begin(), sinks.end()) {} ... protected: std::vector<sink_ptr> sinks_; ... } -
日志级别过滤
logger可以设置一个最低日志级别(通过set_level()方法),只有级别大于等于该值的日志才会被处理并分发到sinkc++bool should_log(level::level_enum msg_level) const { return msg_level >= level_.load(std::memory_order_relaxed); } void log(log_clock::time_point log_time, source_loc loc, level::level_enum lvl, string_view_t msg) { bool log_enabled = should_log(lvl); bool traceback_enabled = tracer_.enabled(); if (!log_enabled && !traceback_enabled) { return; } details::log_msg log_msg(log_time, loc, name_, lvl, msg); log_it_(log_msg, log_enabled, traceback_enabled); } // 分发给sink SPDLOG_INLINE void logger::log_it_(const spdlog::details::log_msg &log_msg, bool log_enabled, bool traceback_enabled) { if (log_enabled) { sink_it_(log_msg); } if (traceback_enabled) { tracer_.push_back(log_msg); } -
日志格式化
logger负责为管理的sink应用格式化规则(通过set_formatter()方法设置),定义日志的最终文本格式(如包含时间戳、日志级别、文件名、消息内容等)。formatter会被传递给sink,由sink完成格式化。c++SPDLOG_INLINE void logger::set_formatter(std::unique_ptr<formatter> f) { for (auto it = sinks_.begin(); it != sinks_.end(); ++it) { if (std::next(it) == sinks_.end()) { // last element - we can be move it. (*it)->set_formatter(std::move(f)); break; // to prevent clang-tidy warning } else { (*it)->set_formatter(f->clone()); } }
} ```
-
线程安全保障
logger内部通过互斥锁(mutex)保证多线程环境下的安全性,避免并发写入导致的日志错乱。spdlog 提供的默认logger实现(如stdout_logger_mt中的mt即multi-thread)均为线程安全版本。
sink
sink类的作用是定义日志消息的最终输出目标和输出方式
-
抽象日志输出目标
sink是对 "日志输出目的地" 的抽象。spdlog 通过sink接口屏蔽了不同输出目标的实现细节,使得日志系统可以统一处理各种输出场景。例如:- 控制台输出(
stdout_sink、stderr_sink); - 文件输出(
basic_file_sink、rotating_file_sink带文件轮转、daily_file_sink按日期切割); - 系统日志(如 Windows 的 Event Log、Linux 的 syslog,通过
syslog_sink); - 网络传输(如
tcp_sink发送到远程服务器)。
- 控制台输出(
-
封装输出逻辑
每个
sink都封装了特定的输出逻辑,包括:- 如何打开 / 关闭输出目标(如文件的打开、网络连接的建立);
- 如何写入日志消息(如文件 I/O 操作、控制台打印);
- 输出目标的特殊处理(如文件轮转策略、日志切割规则)。
例如,
rotating_file_sink会在文件达到指定大小后自动创建新文件(如log.txt满了就生成log.1.txt,再满就生成log.2.txt等),这些逻辑都封装在sink内部。 -
支持多目标输出
一个
logger可以关联多个sink,实现 "一条日志同时输出到多个目标"。例如:- 同一条日志既打印到控制台,又写入本地文件,还发送到远程日志服务器;
- 不同级别日志输出到不同目标(如
error级别日志写入错误日志文件,info级别日志写入普通日志文件)。
-
提供可扩展性
spdlog 允许用户通过继承
base_sink(基础输出器类)自定义sink,实现特定业务的输出需求。例如:- 将日志写入数据库;
- 按自定义格式输出到消息队列;
- 对日志进行加密后再输出。
自定义
sink只需重写sink_it_()(处理日志写入)和flush_()(刷新缓存)方法即可。 -
配合日志格式化与过滤
sink会接收logger设置的格式化规则(包含日志级别、时间、内容等),并格式化最终输出。sink还支持单独设置格式化器(formatter),实现不同输出目标使用不同的日志格式。
3.2 如何支持Head-only版本和Compiled版本
接下来分析一下sdplog是如何支持Head-only和Compiled两种模式的。
项目中可以看到spdlog.h和spdlog-inl.h这样成对出现的头文件,其中inl是inline的意思,表示该h文件是用来存放内联函数的。在spdlog.h最后可以看到关键的宏SPDLOG_HEADER_ONLY:
c++
#ifndef SPDLOG_H
#define SPDLOG_H
...
#ifdef SPDLOG_HEADER_ONLY
#include "spdlog-inl.h"
#endif
#endif // SPDLOG_H如果当前项目编译时定义了SPDLOG_HEADER_ONLY,那么在#include "spdlog.h"的同时也会#include "spdlog-inl.h,相当于直接将函数实现也包含进了当前的编译单元中,因此可以正常使用spdlog的api
那么SPDLOG_HEADER_ONLY是在哪里定义的呢?请看common.h中的代码:
c++
#ifdef SPDLOG_COMPILED_LIB
#undef SPDLOG_HEADER_ONLY
#if defined(SPDLOG_SHARED_LIB)
#if defined(_WIN32)
#ifdef spdlog_EXPORTS
#define SPDLOG_API __declspec(dllexport)
#else // !spdlog_EXPORTS
#define SPDLOG_API __declspec(dllimport)
#endif
#else // !defined(_WIN32)
#define SPDLOG_API __attribute__((visibility("default")))
#endif
#else // !defined(SPDLOG_SHARED_LIB)
#define SPDLOG_API
#endif
#define SPDLOG_INLINE
#else // !defined(SPDLOG_COMPILED_LIB)
#define SPDLOG_API
#define SPDLOG_HEADER_ONLY // 此时定义了宏
#define SPDLOG_INLINE inline
#endif // #ifdef SPDLOG_COMPILED_LIB可以看到,如果没有定义SPDLOG_COMPILED_LIB,就会定义SPDLOG_HEADER_ONLY。那么SPDLOG_COMPILED_LIB是在哪里定义的?请看CMakelists.txt:
make
...
add_library(spdlog::spdlog ALIAS spdlog)
set(SPDLOG_INCLUDES_LEVEL "")
if(SPDLOG_SYSTEM_INCLUDES)
set(SPDLOG_INCLUDES_LEVEL "SYSTEM")
endif()
target_compile_definitions(spdlog PUBLIC SPDLOG_COMPILED_LIB) # 这里添加了宏定义
...SPDLOG_COMPILED_LIB这个宏是在调用cmake编sodlog库的时候定义的,并且使用到了PUBLIC,意味着引入sdplog库依赖的项目也会有SPDLOG_COMPILED_LIB定义,此时用的就是Compiled version。
无论是Head-only version还是Compiled version,使用时都需要先#include "spdlog/spdlog.h",spdlog.h中包含common.h:
c++
#include <spdlog/common.h>
#include <spdlog/details/registry.h>
#include <spdlog/details/synchronous_factory.h>
#include <spdlog/logger.h>
#include <spdlog/version.h>根据上面分析,此时common.h的两种情况:
- Head-only version:定义
SPDLOG_HEADER_ONLY - Compiled version:不定义
SPDLOG_HEADER_ONLY
那么接下来在#include xxx.h时,Head-only version会同时包含对应的xxx-inl.h,函数内联实现;而Compiled version仅包含xxx.h,函数实现通过链接spdlog库来完成。
由此也可以看到两种方式各自的优缺点,Head-only version在不同地方包含同一个xxx-inl.h时会造成相同函数多次编译,但它的优点就是用起来很方便,直接添加头文件就能使用spdlog的api;Compiled version就得提前编译spdlog库,然后链接到项目中。
例如源码中给的example就是使用Compiled version,CMakeLists.txt中内的链接命令:
make
# ---------------------------------------------------------------------------------------
# Example of using pre-compiled library
# ---------------------------------------------------------------------------------------
add_executable(example example.cpp)
target_link_libraries(example PRIVATE spdlog::spdlog $<$<BOOL:${MINGW}>:ws2_32>)3.3 如何支持单线程和多线程日志输出
sdplog支持在单线程环境和多线程环境下运行,多线程环境下能够通过互斥锁或原子操作保证多线程环境下日志的完整性和一致性。
源码中,每一类sink都有单线程版本和多线程版本,后缀分别是_st和_mt,例如:
c++
using basic_file_sink_mt = basic_file_sink<std::mutex>;
using basic_file_sink_st = basic_file_sink<details::null_mutex>;
using wincolor_stdout_sink_mt = wincolor_stdout_sink<details::console_mutex>;
using wincolor_stdout_sink_st = wincolor_stdout_sink<details::console_nullmutex>;这里先明确一个问题:如果程序是单线程环境,可不可以用_mt版本的sink?
答案是可以,但是加锁解锁、线程同步是有开销的,这种情况下就白白增加了不必要的开销,因此肯定不建议单线程环境下用_mt,所以sdplog给你提供了_st版本。
为了避免代码的冗余,源码中使用模板编程实现单线程/多线程sink,接下来学习一下这种模板编程的方式。
首先思考一下,如果不用模板编程是个什么情况?以basic_finle_sink为例,显然我们要单独实现单线程类和多线程类,如:
c++
class basic_file_sink_st : public basic_sink
{
// ...
};
class basic_file_sink_mt : public basic_sink
{
// ...
};如果这样的话,写着写着就会发现两个类的接口和内部实现逻辑基本是完全一致的,唯一的区别在一_mt需要使用互斥量来保证线程安全,_st则不用。因此,这种情况下就可以考虑使用模板编程。
那么该怎么写?既然二者的区别在于互斥量,就可以把互斥量当作模板类型。一般函数中要加锁的话,会用std::lock_guard+std::mutex来实现,例如:
c++
std::mutext mtx;
void fun()
{
std::lock_gurad<std::mutex> lock(mtx);
// do_something
}std::lock_gurad的核心原理是RAII(Resource Acquisition Is Initialization,资源获取即初始化),通过对象的生命周期自动管理锁的获取与释放。在构造时会调用互斥量mtx的lock()方法,析构时调用mtx的unlock()方法。
那么如果某个互斥量的lock()方法和unlock()实际上不起作用,即使函数中有一行std::lock_gurad<std::mutex> lock(mtx);也不会真正进行加锁和解锁的动作。
因此,就可以考虑为basic_file_sink设置一个成员变量mutex_,它的实际类型通过模板参数控制,如下:
c++
// basic_file_sink 继承自 base_sink, base_sink 中定义了mutex_
template <typename Mutex>
class SPDLOG_API base_sink : public sink {
public:
// ...
protected:
Mutex mutex_;
//...
};然后为单线程版本创建一个空锁null_mutex,它的lock()方法和unlock()都是空的:
c++
struct null_mutex {
void lock() const {}
void unlock() const {}
};在函数中使用lock_gurad时,把Mutex mutex_传进去就行了:
c++
template <typename Mutex>
void SPDLOG_INLINE spdlog::sinks::base_sink<Mutex>::log(const details::log_msg &msg) {
std::lock_guard<Mutex> lock(mutex_);
sink_it_(msg);
}总结一下,单线程和多线程sink通过模板编程的方式,将互斥量作为模板参数,从而实现一套代码支持单线程和多线程,确实是很优雅的写法,值得学习。
3.4 如何实现异步模式
高频日志的场景下(如游戏服务器或金融交易系统),使用异步日志可以减少主线程的阻塞。源码中,负责异步日志的类是async_logger:
c++
class SPDLOG_API async_logger final : public std::enable_shared_from_this<async_logger>,
public logger {
friend class details::thread_pool;
public:
//...
protected:
void sink_it_(const details::log_msg &msg) override;
void flush_() override;
void backend_sink_it_(const details::log_msg &incoming_log_msg);
void backend_flush_();
private:
std::weak_ptr<details::thread_pool> thread_pool_;
async_overflow_policy overflow_policy_;
};
} // namespace spdlog和其他logger一样,sink_it_方法负责输出日志,async_logger的sink_it_方法会将日志扔到线程池中执行:
c++
SPDLOG_INLINE void spdlog::async_logger::sink_it_(const details::log_msg &msg){
SPDLOG_TRY{if (auto pool_ptr = thread_pool_.lock()){
pool_ptr -> post_log(shared_from_this(), msg, overflow_policy_); // 由于是异步操作,实际回调时调用者指针可能已经析构,这里shared_from_this()可以延长调用者生命周期
}
else {
throw_spdlog_ex("async log: thread pool doesn't exist anymore");
}
}
SPDLOG_LOGGER_CATCH(msg.source)
}线程池中,会将调用者的指针和日志内容封装成async_msg对象,添加到工作线程的消息队列中。工作线程的消息循环会取出该async_msg对象,然后根据async_msg中保存调用者指针和消息内容进行后台输出,不会阻塞主线程。
c++
// 将日志封装成消息对象进行投递
void SPDLOG_INLINE thread_pool::post_log(async_logger_ptr &&worker_ptr,
const details::log_msg &msg,
async_overflow_policy overflow_policy) {
async_msg async_m(std::move(worker_ptr), async_msg_type::log, msg);
post_async_msg_(std::move(async_m), overflow_policy);
}
// 消息入队
void SPDLOG_INLINE thread_pool::post_async_msg_(async_msg &&new_msg,
async_overflow_policy overflow_policy) {
if (overflow_policy == async_overflow_policy::block) {
q_.enqueue(std::move(new_msg));
} else if (overflow_policy == async_overflow_policy::overrun_oldest) {
q_.enqueue_nowait(std::move(new_msg));
} else {
assert(overflow_policy == async_overflow_policy::discard_new);
q_.enqueue_if_have_room(std::move(new_msg));
}
}
// 每个线程的消息循环,不断处理新消息
void SPDLOG_INLINE thread_pool::worker_loop_() {
while (process_next_msg_()) {
}
}
// 从消息队列中取出消息,执行后台输出
bool SPDLOG_INLINE thread_pool::process_next_msg_() {
async_msg incoming_async_msg;
q_.dequeue(incoming_async_msg);
switch (incoming_async_msg.msg_type) {
case async_msg_type::log: {
incoming_async_msg.worker_ptr->backend_sink_it_(incoming_async_msg);
return true;
}
// ...
}
return true;
}
c++
// 工作线程回调backend_sink_it_方法进行最终的输出
SPDLOG_INLINE void spdlog::async_logger::backend_sink_it_(const details::log_msg &msg) {
for (auto &sink : sinks_) {
if (sink->should_log(msg.level)) {
SPDLOG_TRY { sink->log(msg); }
SPDLOG_LOGGER_CATCH(msg.source)
}
}
if (should_flush_(msg)) {
backend_flush_();
}
}总结一下,异步模式的机制是主线程将消息抛给线程池来执行,从而避免主线程的阻塞。其中线程池的实现、生产者-消费者模式的写法也是很值得学习的。