- 正则表达式
正则表达式用于查找符合规则的字符串。正则表达式具备通用性,所以是用处最广泛的字符串匹配语法,无论是Python、Java、PHP,还是数据库语言SQL,它的语法规则是基本通用的。
比如:
'哈哈哈哈哈哈我爱你' → 匹配 '我爱你'
Python中如何使用正则表达式
- 导入模块
- import re # Python标准库
- 使用方法进行匹配
例如:match()方法
- result = re.match('正则表达式', '目标字符串')
- 获得匹配结果
- print(result.group()) # 获取匹配结果
基本使用示例:
-
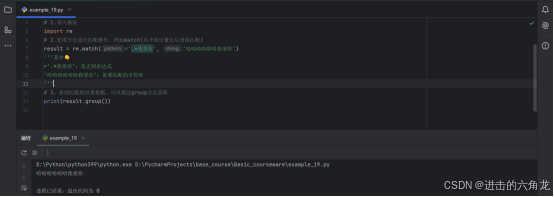
1.导入模块
- import re
-
2.使用方法进行匹配操作,例如match(从开始位置往后查找匹配)
- result = re.match(r'.*我爱你', '哈哈哈哈哈哈我爱你')
- '''其中��
- r'.*我爱你':是正则表达式
- '哈哈哈哈哈哈我爱你':是要匹配的字符串
- '''
-
3、拿到匹配的结果数据,可以通过group方法获取
- print(result.group())
- 匹配规则
匹配单个字符
表格:
|------------|----------------------|
| 符号 | 功能 |
| . | 匹配任意字符(除\n) |
| \[\] | 匹配括号内任意字符(比如abc) |
| \d | 匹配数字(0-9) |
| \D | 匹配非数字 |
| \s | 匹配空白(空格、\t、\n) |
| \S | 匹配非空白 |
| \w | 匹配单词字符(a-zA-Z0-9_汉字) |
| \W | 匹配非单词字符 |
- .匹配任意字符(除换行符 \n**)**
- import re
-
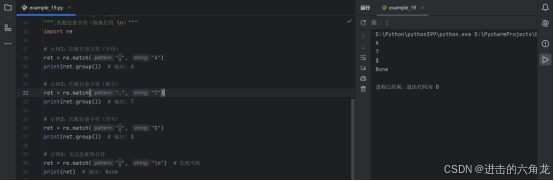
示例1:匹配任意字符(字母)
- ret = re.match(".", "A")
- print(ret.group()) # 输出: A
-
示例2:匹配任意字符(数字)
- ret = re.match(".", "7")
- print(ret.group()) # 输出: 7
-
示例3:匹配任意字符(符号)
- ret = re.match(".", "$")
- print(ret.group()) # 输出: $
-
示例4:无法匹配换行符
- ret = re.match(".", "\n") # 匹配失败
- print(ret) # 输出: None
2. \[\] :匹配括号内任意一个字符
- import re
-
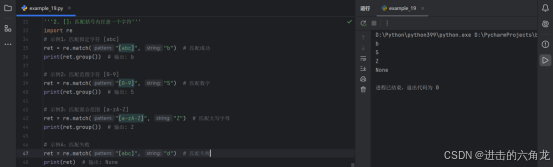
示例1:匹配指定字符 abc
- ret = re.match("abc", "b") # 匹配成功
- print(ret.group()) # 输出: b
-
示例2:匹配范围字符 0-9
- ret = re.match("0-9", "5") # 匹配数字
- print(ret.group()) # 输出: 5
-
示例3:匹配混合范围 a-zA-Z
- ret = re.match("a-zA-Z", "Z") # 匹配大写字母
- print(ret.group()) # 输出: Z
-
示例4:匹配失败
- ret = re.match("abc", "d") # 匹配失败
- print(ret) # 输出: None
3. \d :匹配数字(0-9)
- import re
-
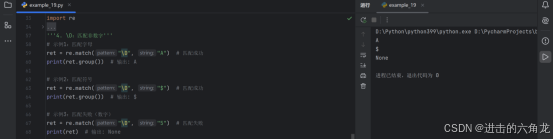
示例1:匹配数字
- ret = re.match("\d", "9") # 匹配成功
- print(ret.group()) # 输出: 9
-
示例2:匹配失败(非数字)
- ret = re.match("\d", "a") # 匹配失败
- print(ret) # 输出: None

4. \D :匹配非数字
-
示例1:匹配字母
- ret = re.match("\D", "A") # 匹配成功
- print(ret.group()) # 输出: A
-
示例2:匹配符号
- ret = re.match("\D", "$") # 匹配成功
- print(ret.group()) # 输出: $
-
示例3:匹配失败(数字)
- ret = re.match("\D", "5") # 匹配失败
- print(ret) # 输出: None
5. \s :匹配空白字符(空格、 \t 、 \n )
- import re
-
示例1:匹配空格
- ret = re.match("\s", " ") # 匹配成功
- print(repr(ret.group())) # 输出: ' '
-
示例2:匹配制表符 `\t`
- ret = re.match("\s", "\t") # 匹配成功
- print(repr(ret.group())) # 输出: '\t'
-
示例3:匹配换行符 `\n`
- ret = re.match("\s", "\n") # 匹配成功
- print(repr(ret.group())) # 输出: '\n'
-
示例4:匹配失败(非空白)
- ret = re.match("\s", "a") # 匹配失败
- print(ret) # 输出: None
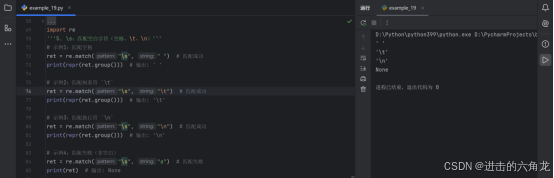
6. \S :匹配非空白字符
- import re
-
示例1:匹配字母
- ret = re.match("\S", "A") # 匹配成功
- print(ret.group()) # 输出: A
-
示例2:匹配数字
- ret = re.match("\S", "5") # 匹配成功
- print(ret.group()) # 输出: 5
-
示例3:匹配失败(空白符)
- ret = re.match("\S", "\t") # 匹配失败
- print(ret) # 输出: None
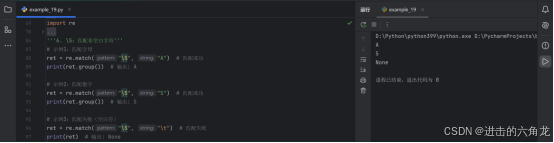
7. \w :匹配单词字符(字母、数字、下划线、汉字)
- import re
- '''7. \w:匹配单词字符(字母、数字、下划线、汉字)'''
-
示例1:匹配字母
- ret = re.match("\w", "a") # 匹配成功
- print(ret.group()) # 输出: a
-
示例2:匹配数字
- ret = re.match("\w", "7") # 匹配成功
- print(ret.group()) # 输出: 7
-
示例3:匹配下划线
- ret = re.match("\w", "_") # 匹配成功
- print(ret.group()) # 输出: _
-
示例4:匹配汉字
- ret = re.match("\w", "周") # 匹配成功
- print(ret.group()) # 输出: 周
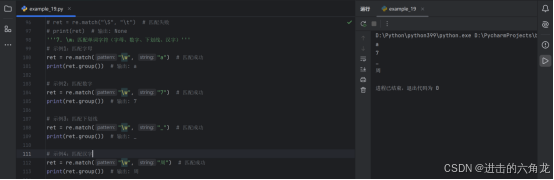
8. \W :匹配非单词字符(符号、空格等)
- import re
-
示例1:匹配符号
- ret = re.match("\W", "$") # 匹配成功
- print(ret.group()) # 输出: $
-
示例2:匹配空格
- ret = re.match("\W", " ") # 匹配成功
- print(repr(ret.group())) # 输出: ' '
-
示例3:匹配失败(单词字符)
- ret = re.match("\W", "a") # 匹配失败
- print(ret) # 输出: None
匹配多个字符
|------------|--------------------|
| 符号 | 功能 |
| * | 匹配前一个字符0次或多次(贪婪模式) |
| + | 匹配前一个字符1次或多次 |
| ? | 匹配前一个字符0次或1次 |
| {m} | 精确匹配m次 |
| {m,n} | 匹配m到n次 |
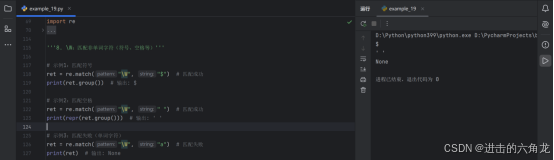
1. *:匹配前一个字符 0次或多次(贪婪模式)
- import re
-
示例1:匹配小写字母0次或多次(允许大写后无小写)
- ret = re.match("A-Za-z*", "M") # 匹配成功(0次小写)
- print(ret.group()) # 输出: M
-
示例2:匹配多个小写字母
- ret = re.match("A-Za-z*", "MdueD6Ddas") # 匹配到第一个非小写字母前
- print(ret.group()) # 输出: Mdue
-
示例3:匹配数字0次或多次
- ret = re.match("\d*", "abc") # 匹配空字符串(0次数字)
- print(ret.group()) # 输出: (空字符串,无报错)
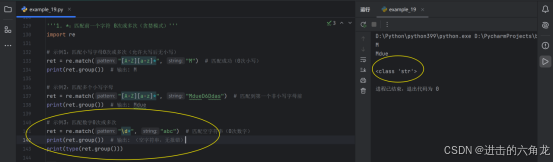
2. +:匹配前一个字符 1次或多次(至少一次)
-
示例1:匹配小写字母至少一次
- ret = re.match("A-Za-z+", "Hello") # 匹配成功
- print(ret.group()) # 输出: Hello
-
示例2:匹配失败(小写字母不足一次)
- ret = re.match("A-Za-z+", "H") # 匹配失败
- print(ret) # 输出: None
-
示例3:匹配连续数字
- ret = re.match("\d+", "138abc") # 匹配到第一个非数字前
- print(ret.group()) # 输出: 138
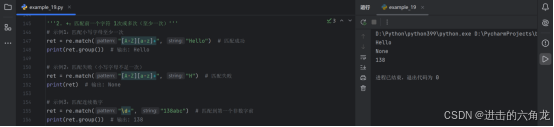
3. ?:匹配前一个字符 0次或1次(可选匹配)
-
示例1:匹配可选字符(http或https)
- ret = re.match("https?", "http") # 匹配成功(0次s)
- print(ret.group()) # 输出: http
- ret = re.match("https?", "https") # 匹配成功(1次s)
- print(ret.group()) # 输出: https
-
示例2:匹配可选数字
- ret = re.match("周周\d?", "周周") # 匹配成功(0次数字)
- print(ret.group()) # 输出: 周周
- ret = re.match("周周\d?", "周周5") # 匹配成功(1次数字)
- print(ret.group()) # 输出: 周周5
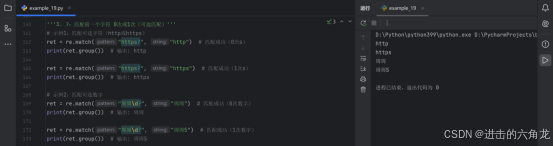
4. {m}:精确匹配前一个字符 m次
-
示例1:精确匹配11位手机号
- ret = re.match("\d{11}", "13847758302") # 匹配成功
- print(ret.group()) # 输出: 13847758302
-
示例2:匹配失败(不足m次)
- ret = re.match("\d{3}", "12") # 匹配失败
- print(ret) # 输出: None

5. {m,n}:匹配前一个字符 m到n次(贪婪模式)
-
示例1:匹配6~10位数字
- ret = re.match("\d{6,10}", "1384775830245678") # 匹配前10位
- print(ret.group()) # 输出: 1384775830
-
示例2:匹配失败(不足m次)
- ret = re.match("\d{6,10}", "13567") # 匹配失败(仅5位)
- print(ret) # 输出: None

匹配开头结尾
|------------|------------|
| 符号 | 功能 |
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
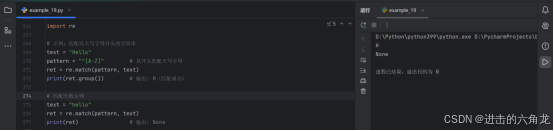
- ^:匹配字符串开头
强制匹配从字符串的第一个字符开始 。
- import re
-
示例:匹配以大写字母开头的字符串
- text = "Hello"
- pattern = "^A-Z" # 从开头匹配大写字母
- ret = re.match(pattern, text)
- print(ret.group()) # 输出: H
-
匹配失败示例
- text = "hello"
- ret = re.match(pattern, text)
- print(ret) # 输出: None
2. $ :匹配字符串结尾
\d$ 匹配结尾数字:
-
示例:匹配以数字结尾的字符串
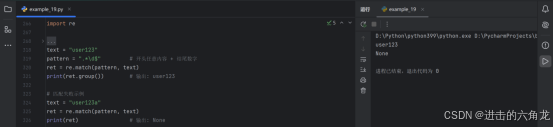
- text = "user123"
- pattern = ".*\d$" # 开头任意内容 + 结尾数字
- ret = re.match(pattern, text)
- print(ret.group()) # 输出: user123
-
匹配失败示例
- text = "user123a"
- ret = re.match(pattern, text)
- print(ret) # 输出: None
3. ^ 和 $ 联合使用:精确匹配整个字符串
确保字符串完全符合 指定模式。
-
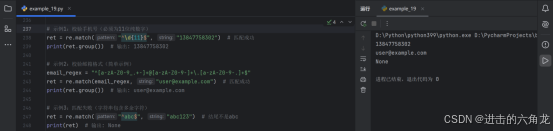
示例1:校验手机号(必须为11位纯数字)
- ret = re.match("^\d{11}$", "13847758302") # 匹配成功
- print(ret.group()) # 输出: 13847758302
-
示例2:校验邮箱格式(简单示例)
- email_regex = "^a-zA-Z0-9_.+-+@a-zA-Z0-9-+\.a-zA-Z0-9-.+$"
- ret = re.match(email_regex, "user@example.com") # 匹配成功
- print(ret.group()) # 输出: user@example.com
-
示例3:匹配失败(字符串包含多余字符)
- ret = re.match("^abc$", "abc123") # 结尾不是abc
- print(ret) # 输出: None
4. 转义字符:匹配字面意义的 ^ 或 $
使用 \ 转义符号本身。(这里用的方法是search(),后面有对该方法的使用详解。)
-
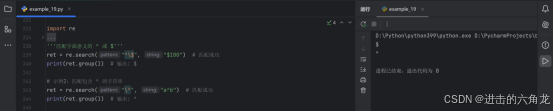
示例1:匹配以 $ 开头的字符串
- ret = re.search("^\", "100") # 匹配成功
- print(ret.group()) # 输出: $
-
示例2:匹配包含 ^ 的字符串
- ret = re.search("\^", "a^b") # 匹配成功
- print(ret.group()) # 输出: ^
匹配分组
|--------------|--------------------|
| 符号 | 功能 |
| | | 匹配左右任意一个表达式 |
| (ab) | 将括号中字符作为一个分组 |
| \num | 引用分组num匹配到的字符串 |
| (?P<name>) | 分组起别名 |
| (?P=name) | 引用别名为name分组匹配到的字符串 |
1. | :匹配左右任意一个表达式
用于逻辑"或"操作,通常在分组内定义多个候选模式。
- import re
-
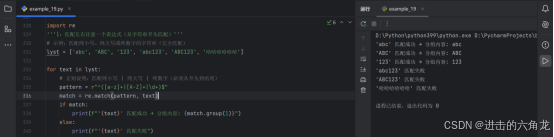
示例:匹配纯小写、纯大写或纯数字的字符串(完全匹配)
- lyst = 'abc', 'ABC', '123', 'abc123', 'ABC123', '哈哈哈哈哈哈'
- for text in lyst:
-
正则说明:匹配纯小写 | 纯大写 | 纯数字(必须从开头到结尾)
- pattern = r"^(a-z+|A-Z+|\d+)$"
- match = re.match(pattern, text)
- if match:
- print(f"'{text}' 匹配成功 → 分组内容: {match.group(1)}")
- else:
- print(f"'{text}' 匹配失败")
-
输出:
-
'abc' 匹配成功 → 分组内容: abc
-
'ABC' 匹配成功 → 分组内容: ABC
-
'123' 匹配成功 → 分组内容: 123
-
'abc123' 匹配失败
-
'ABC123' 匹配失败
-
'哈哈哈哈哈哈' 匹配失败
2. (ab) 与\num
(ab) :创建捕获分组。将括号内内容作为一个分组,后续可通过索引提取。
\num:引用分组。通过 \1 、 \2 等格式引用前面分组的匹配结果(索引从 1 开始)。
-
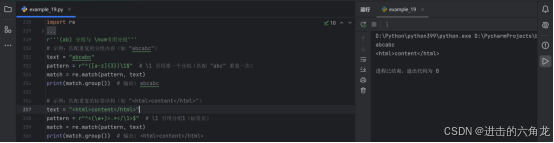
示例:匹配重复的分组内容(如 "abcabc")
- text = "abcabc"
- pattern = r"^(a-z{3})\1$" # \1 引用第一个分组(匹配 "abc" 重复一次)
- match = re.match(pattern, text)
- print(match.group()) # 输出: abcabc
-
示例:匹配重复的标签结构(如 "<html>content</html>")
- text = "<html>content</html>"
- pattern = r"^<(\w+)>.*</\1>$" # \1 引用分组1(标签名)
- match = re.match(pattern, text)
- print(match.group()) # 输出: <html>content</html>
3. (?P<name>) 与(?P=name)
(?P<name>) :命名分组。为分组指定别名,通过名称提取内容(提高可读性)。
(?P=name):引用命名分组。通过别名引用之前的分组匹配结果。
-
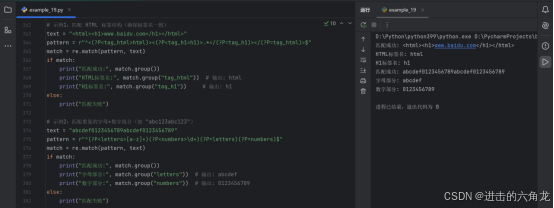
示例1:匹配 HTML 标签结构(确保标签名一致)
- text = "<html><h1>www.baidu.com</h1></html>"
- pattern = r"^<(?P<tag_html>html)><(?P<tag_h1>h1)>.*</(?P=tag_h1)></(?P=tag_html)>$"
- match = re.match(pattern, text)
- if match:
- print("匹配成功:", match.group())
- print("HTML标签名:", match.group("tag_html")) # 输出: html
- print("H1标签名:", match.group("tag_h1")) # 输出: h1
- else:
- print("匹配失败")
-
示例2:匹配重复的字母+数字组合(如 "abc123abc123")
- text = "abcdef0123456789abcdef0123456789"
- pattern = r"^(?P<letters>a-z+)(?P<numbers>\d+)(?P=letters)(?P=numbers)$"
- match = re.match(pattern, text)
- if match:
- print("匹配成功:", match.group())
- print("字母部分:", match.group("letters")) # 输出: abcdef
- print("数字部分:", match.group("numbers")) # 输出: 0123456789
- else:
- print("匹配失败")
- re模块的其它匹配用法。
上面的正则匹配规则中,多数用到的都是match方法,其实re模块中还要很多其它的方法。下面举几个常用的用法一一讲解。
1. re.match(pattern, string)
- 功能 :从字符串开头 匹配正则表达式,若开头不匹配则返回 None。
- 参数说明 :
- pattern:正则表达式(字符串或预编译对象)。
- string:要匹配的目标字符串。
- 返回值 :Match 对象(匹配成功)或 None。
- 示例 :
- import re
-
示例:匹配以大写字母开头的单词
- text = "Hello World"
- match = re.match(r"^A-Z\w+", text)
- if match:
- print(match.group())
- else:
- print('不匹配')

2. re.search(pattern, string)
- 功能 :扫描整个字符串,返回第一个 匹配项。
- 参数说明 :
- pattern:正则表达式。
- string:目标字符串。
- 返回值 :Match 对象或 None。
- 示例 :
-
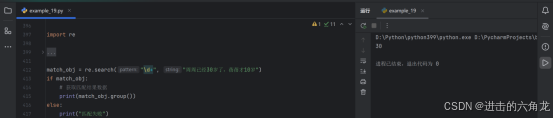
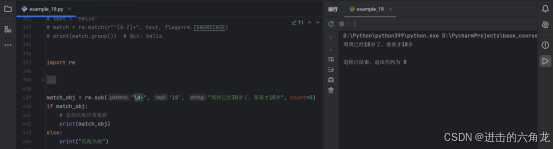
示例:查找字符串中的第一个数字
- match_obj = re.search("\d+", "周周已经30岁了,蓓蓓才10岁")
- if match_obj:
-
获取匹配结果数据
- print(match_obj.group())
- else:
- print("匹配失败")
3. re.findall(pattern, string)
- 功能 :返回所有非重叠匹配项 的列表。
- 参数说明 :
- pattern:正则表达式。
- string:目标字符串。
- 返回值 :
- 无分组时:字符串列表(如 'a', 'b')。
- 有分组时:元组列表(如 ('2023', '10'), ('2024', '01'))。
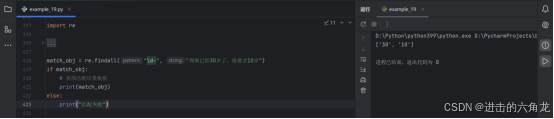
- 示例 :
- match_obj = re.findall("\d+", "周周已经30岁了,蓓蓓才10岁")
- if match_obj:
-
获取匹配结果数据
- print(match_obj)
- else:
- print("匹配失败")
分组对匹配结果的影响:
-
------------ 示例1:无分组时匹配所有字母和数字组合 ------------
- a = "abc123_abc456"
- b = re.findall(r"a-z+\d*", a)
- print(b) # 输出: 'abc123', 'abc456'
-
------------ 示例2:分组时仅提取分组内容 ------------
- a = "abc123_abc456_789"
- b = re.findall(r"a-z+(\d*)", a) # 强调只提取括号内的 \d*
- print(b) # 输出: '123', '456', ''(注意最后一个匹配的 \d* 为空)
-
------------ 示例3:多分组时提取元组列表 ------------
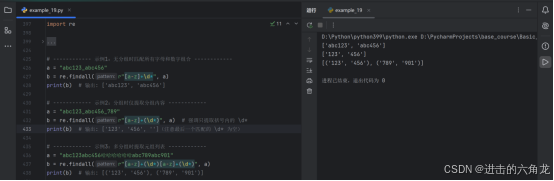
- a = "abc123abc456哈哈哈哈哈哈abc789abc901"
- b = re.findall(r"a-z+(\d*)a-z+(\d*)", a)
- print(b) # 输出: ('123', '456'), ('789', '901')
4. re.sub(pattern, repl, string, count=0)
- 功能 :替换所有匹配项(或前 count 个)。
- 参数说明 :
- pattern:正则表达式。
- repl:替换内容(字符串或函数)。
- string:目标字符串。
- count:最大替换次数(默认 0 表示全部替换)。
- 返回值 :替换后的新字符串。
- 示例 :
- match_obj = re.sub("\d+", '18', "周周已经30岁了,蓓蓓才10岁", count=0)
- if match_obj:
-
获取匹配结果数据
- print(match_obj)
- else:
- print("匹配失败")
5. re.split(pattern, string, maxsplit=0)
- 功能 :按正则表达式分割字符串。
- 参数说明 :
- pattern:正则表达式。
- string:目标字符串。
- maxsplit:最大分割次数(默认 0 表示全部分割)。
- 返回值 :分割后的字符串列表。
- 示例 :
-
------------ 示例1:使用正则表达式分割复杂分隔符 ------------
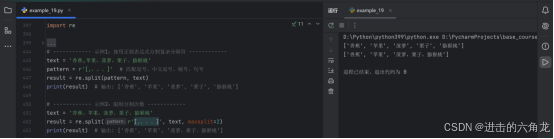
- text = '香蕉,苹果、菠萝,栗子。猕猴桃'
- pattern = r',,、。' # 匹配逗号、中文逗号、顿号、句号
- result = re.split(pattern, text)
- print(result) # 输出: '香蕉', '苹果', '菠萝', '栗子', '猕猴桃'
-
------------ 示例2:限制分割次数 ------------
- text = '香蕉、苹果、菠萝,栗子。猕猴桃'
- result = re.split(r',,、。', text, maxsplit=2)
- print(result) # 输出: '香蕉', '苹果', '菠萝,栗子。猕猴桃'
高级技巧【拓展】
- flags参数:
正则表达式的 flags 参数用于控制匹配模式,所有方法均支持此参数(如 re.match(), re.search(), re.findall(), re.sub(), re.split() 等)。以下是常用修饰符:
|---------------|------------|-------------------|----------------------|
| 修饰符 | 简写 | 作用 | 示例场景 |
| re.IGNORECASE | re.I | 忽略大小写 | 匹配 "Hello" 和 "hello" |
| re.MULTILINE | re.M | 多行模式(^ 和 $ 匹配每行) | 处理多行日志 |
| re.DOTALL | re.S | . 匹配包括换行符的所有字符 | 提取跨行文本 |
| re.ASCII | - | 仅匹配 ASCII 字符 | 过滤非英文字符 |
使用示例:
-
示例1:忽略大小写匹配(re.IGNORECASE)
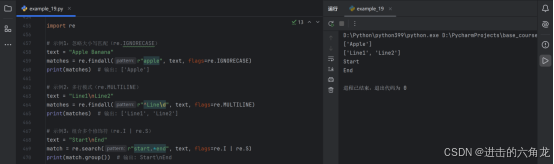
- text = "Apple Banana"
- matches = re.findall(r"apple", text, flags=re.IGNORECASE)
- print(matches) # 输出: 'Apple'
-
示例2:多行模式(re.MULTILINE)
- text = "Line1\nLine2"
- matches = re.findall(r"^Line\d", text, flags=re.MULTILINE)
- print(matches) # 输出: 'Line1', 'Line2'
-
示例3:组合多个修饰符(re.I | re.S)
- text = "Start\nEnd"
- match = re.search(r"start.*end", text, flags=re.I | re.S)
- print(match.group()) # 输出: Start\nEnd
2. 预编译正则表达式
什么是预编译正则表达式?
- 定义 :通过 re.compile() 将正则表达式字符串转换为 Pattern 对象,后续可直接调用该对象的方法(如 match(), search())。
- 核心作用 :提升性能 (避免重复解析正则表达式),并简化代码复用。
基本使用方法示例:
步骤 :
-
- 使用 re.compile() 编译正则表达式,生成 Pattern 对象。
- 调用 pattern 对象的方法(如 match(), search()),参数与原 re 模块方法一致。
-
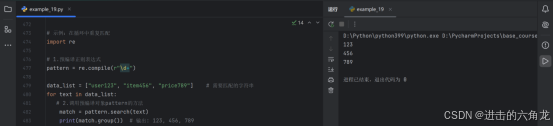
示例:在循环中重复匹配
- import re
-
1.预编译正则表达式
- pattern = re.compile(r"\d+")
- data_list = "user123", "item456", "price789" # 需要匹配的字符串
- for text in data_list:
-
2.调用预编译对象pattern的方法
- match = pattern.search(text)
- print(match.group()) # 输出: 123, 456, 789
多方法复用示例:
就是同一正则表达式需用于 match、search、findall 等多种操作时。
- pattern = re.compile(r"\b\w+\b") # 预编译
- text = "hello world"
-
复用同一个 Pattern 对象
- print(pattern.match(text).group()) # 输出: hello
- print(pattern.findall(text)) # 输出: 'hello', 'world'

- 贪婪和非贪婪匹配
1. 贪婪匹配
- 定义 :默认模式,匹配时尽可能多地 吞并字符,直到无法满足后续条件为止。
- 语法 :使用 *, +, ?, {n,m} 等量词时,默认是贪婪的。
- 示例 :
- import re
- s = "A phone number 130-9411-2846"
- r = re.match(r"(.+)(\d+-\d+-\d+)", s)
- print(r.group(1)) # 输出: A phone number 13
- print(r.group(2)) # 输出: 0-9411-2846(不符合预期!)
-
- 问题原因 :.+ 贪婪吞并尽可能多字符,直到最后一个 \d 才停止。

2. 非贪婪匹配
- 定义 :匹配时尽可能少地 吞并字符,一旦满足条件立即结束。
- 语法 :在量词后添加 ?,如 *?, +?, ??。
- 示例 :
- s = "A phone number 130-9411-2846"
- r = re.match(r"(.+?)(\d+-\d+-\d+)", s)
- print(r.group(1)) # 输出: A phone number
- print(r.group(2)) # 输出: 130-9411-2846(正确分割!)
-
- 解决原因 :.+? 非贪婪匹配到第一个 \d 前即停止。

3. 对比总结
|------------|------------|------------|--------------|
| 类型 | 语法 | 行为 | 适用场景 |
| 贪婪匹配 | .+ | 尽可能多匹配字符 | 需要吞并大部分内容时 |
| 非贪婪匹配 | .+? | 尽可能少匹配字符 | 需要精准分割前后内容时 |
- 原生字符串 r 的作用
之前的正则中,需要用反斜杠 \ 对一些特殊字符进行转译,但是如果我们就是需要去匹配反斜杠呢?此时可以用到r写在正则的匹配规则之前,做到将正则的规则字符串看作原生的字符,即为不需要再去转译的字符。
- 反斜杠 \ 的转义冲突 :
正则表达式中需用 \d、\w 等语法,而 Python 字符串本身用 \ 表示转义,导致需写多个 \。
- 示例 :
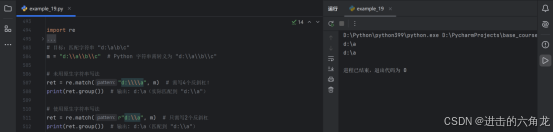
-
目标:匹配字符串 "d:\a\b\c"
- m = "d:\\a\\b\\c" # Python 字符串需转义为 "d:\\a\\b\\c"
-
未用原生字符串写法
- ret = re.match("d:\\\\a", m) # 需写4个反斜杠!
- print(ret.group()) # 输出: d:\a(实际匹配到 "d:\\a")
-
使用原生字符串写法
- ret = re.match(r"d:\\a", m) # 只需写2个反斜杠
- print(ret.group()) # 输出: d:\a(匹配到 "d:\\a")
2. 原生字符串 r 的作用
- 功能 :取消 Python 字符串的转义,使 \ 直接表示字面意义。
- 语法 :在字符串前加 r,如 r"\d+"。
- 对比示例 :
- print("\\") # 输出: \
- print(r"\\") # 输出: \\

-
示例:非贪婪匹配 + 原生字符串
- text = "Price: 100.99, Tax: 20.5"
- pattern = re.compile(r"\$(.+?)\b") # 匹配金额(非贪婪)
- matches = pattern.findall(text)
- print(matches) # 输出: '100.99', '20.5'