Rag流程分析
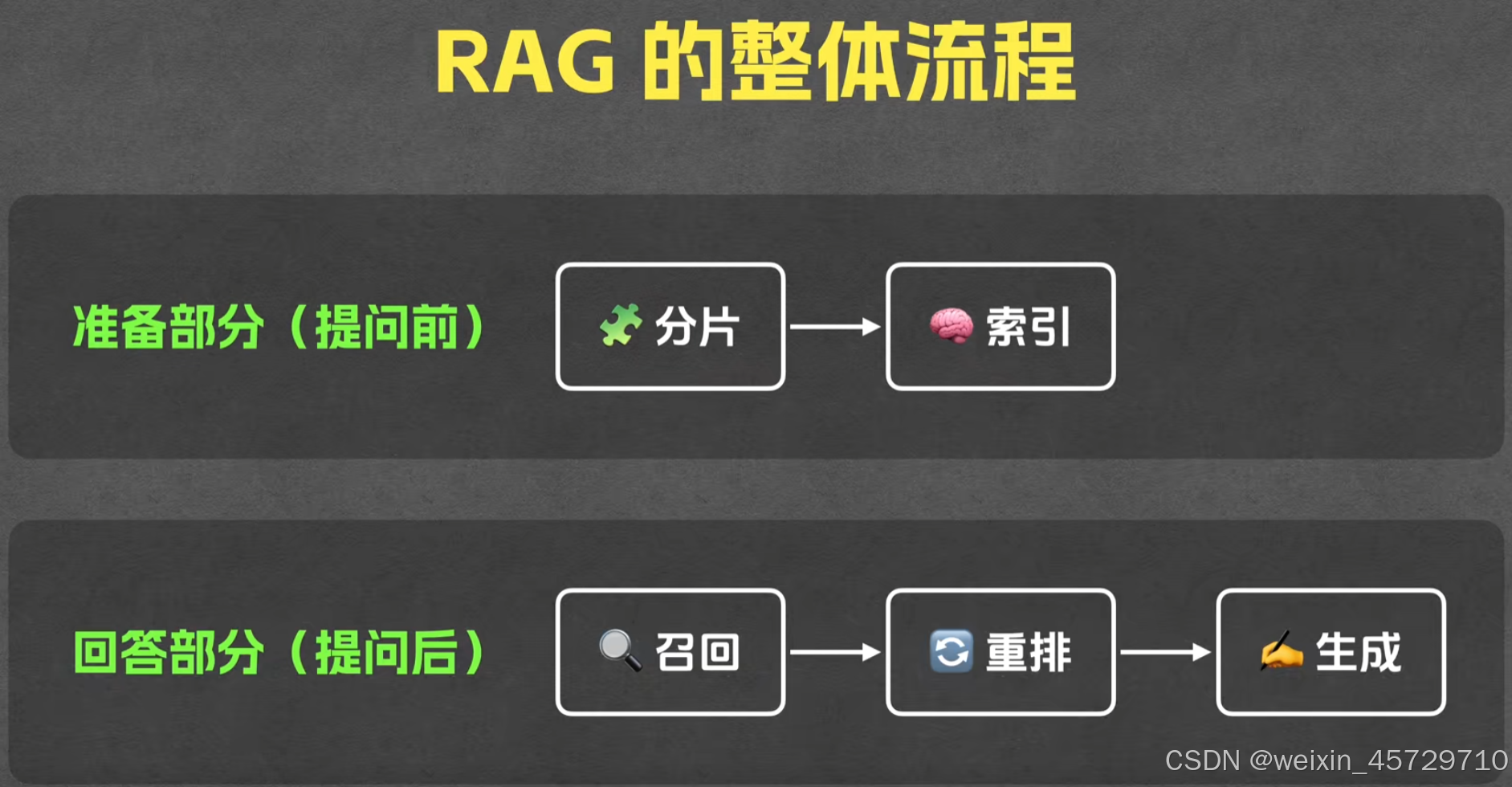
第一部分:数据处理与向量化
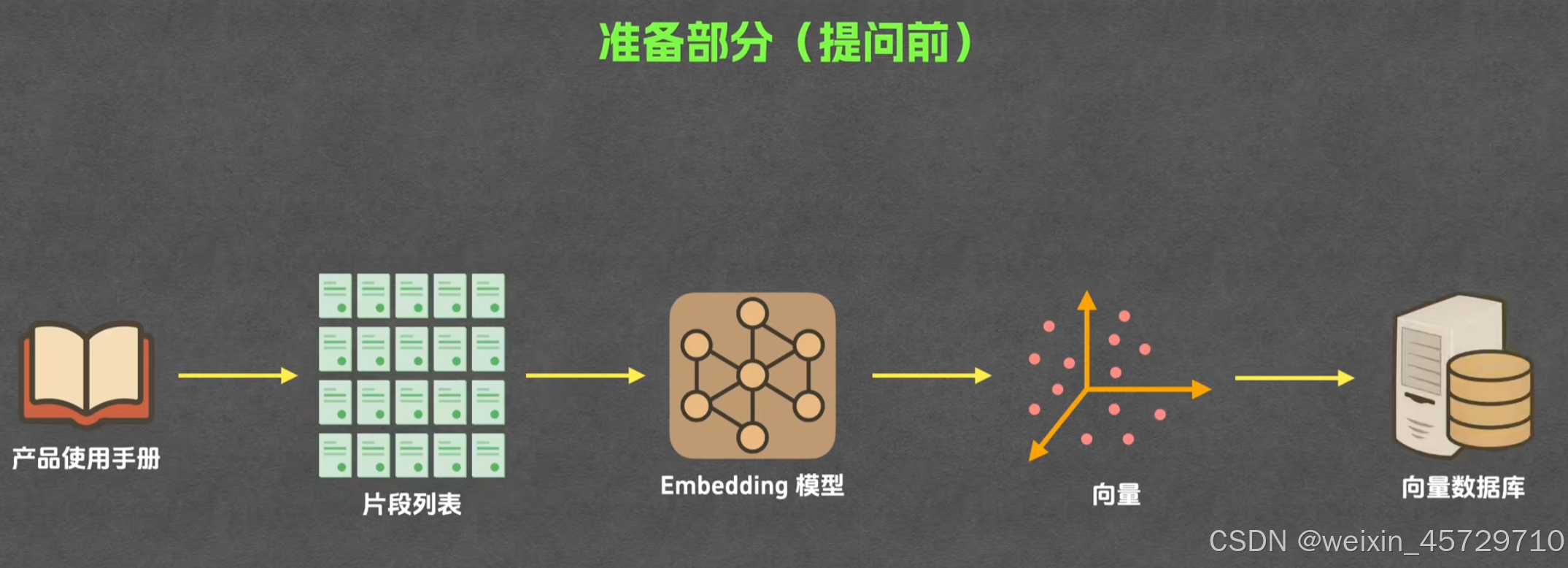
- 原始文档进入系统,先经过格式识别,把 pdf、docx、pptx、扫描图片等统一转成文字流。
- 文字流丢进分段器,按固定长度或语义边界切成若干文本块,每个块再生成唯一 id。
- 如果文档里有表格或图片,表格转成 markdown 表格文本,图片用 OCR 提文字后也并入相邻文本块。
- 每个文本块先过一遍实体抽取,抽到人名、地名、产品名,再把这些实体写进一张实体表备用。
- 同一块文本再交给嵌入模型,模型输出一串浮点数,这串数就是该块的向量。
- 向量被写到向量数据库,数据库里一条记录包含:块 id、原始文本、向量、实体列表、文件来源、页码。
- 实体表里的实体被写进图数据库,形成"实体-关系-实体"三元组,便于以后做图检索。
- 全文搜索引擎也同步建索引,把每个块的纯文本做成倒排索引,支持关键字快速查找。
- 当所有文档都完成 1-8 步,系统就得到一个"可检索知识库",包含向量库、实体图、全文索引三份数据。
- 以后新文档进来,只要重复 1-9 步即可增量更新,不需要重建全部索引。
第二部分:提问向量化然后返回结果
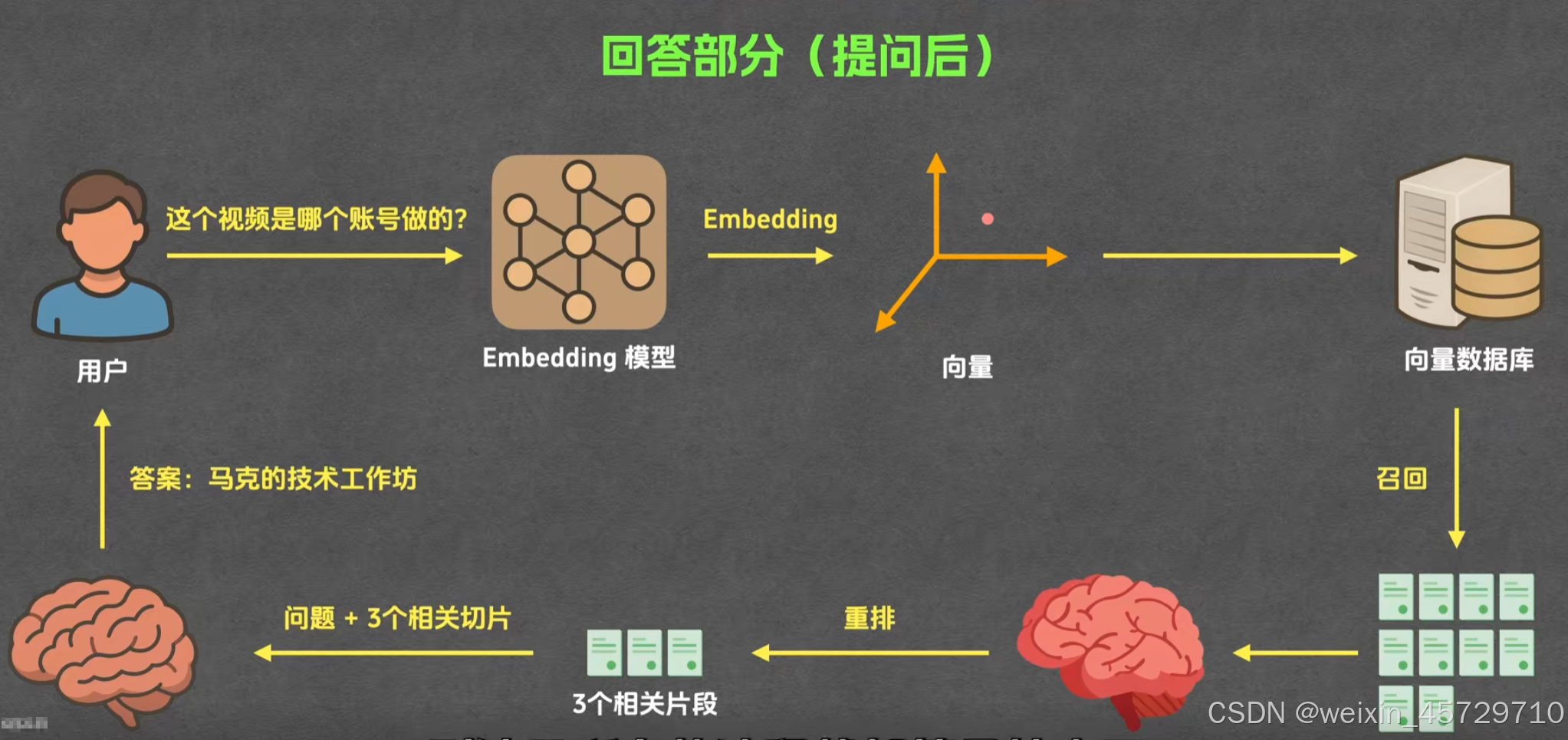
- 用户在前端输入自然语言问题,问题文本先进入查询理解模块。
- 查询理解模块用轻量模型判断问题意图,再把问题里的时间、地点、实体都抽取出来。
- 抽取后的结构化信息与原始问题一起被送入同型号的嵌入模型,生成问题的向量。
- 系统把问题向量发到向量数据库做近似最近邻搜索,召回最相似的 k 个文本块。
- 同时,系统用抽取到的实体去图数据库做一跳或多跳查询,拿到与这些实体直接相关的文档 id 列表。
- 全文搜索引擎也用扩展后的关键词做 BM25 搜索,召回另一批候选文档 id。
- 三路召回结果合并后,用交叉编码器重排模型给每条候选重新打分,保留分数最高的前 n 条文本块。
- 这些文本块按出现顺序拼接成一段上下文,上下文长度超过大模型窗口时就按相关性截断。
- 系统把上下文与原始问题一起塞进 prompt 模板,模板里明确要求大模型在回答中给出引用标记。
- 大模型生成答案文本,系统再解析答案里的引用标记,回链到原文位置,生成可点击的参考链接。
- 最后,答案与参考链接一起回传给前端,用户即可看到回答并可逐条跳转到原文验证。