📚 DeepSeek系列文章
随着大语言模型不断突破规模极限,Mixture-of-Experts(MoE) 成为提升模型容量与计算效率的关键路径之一。然而,MoE 在专家利用率、路由稳定性、跨任务泛化能力上仍存在瓶颈。
为此,DeepSeek 团队发布了创新性工作 ------ DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models,为专家网络注入全新机制,显著提升模型性能并解决长期存在的 MoE 局限。
在了解 DeepSeekMoE 的核心架构之前,不妨带着以下三个问题来阅读这篇文章:
- 传统 MoE 模型在专家选择上存在哪些问题?
- DeepSeekMoE 如何实现高效又稳定的专家利用?
- 在保持计算成本不变的前提下,DeepSeekMoE 如何提升模型性能?
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
一、MoE 的挑战与瓶颈
Mixture-of-Experts 模型通过引入多个"专家子网络",只激活其中部分专家来计算,从而在不线性增加推理计算的前提下提升模型容量。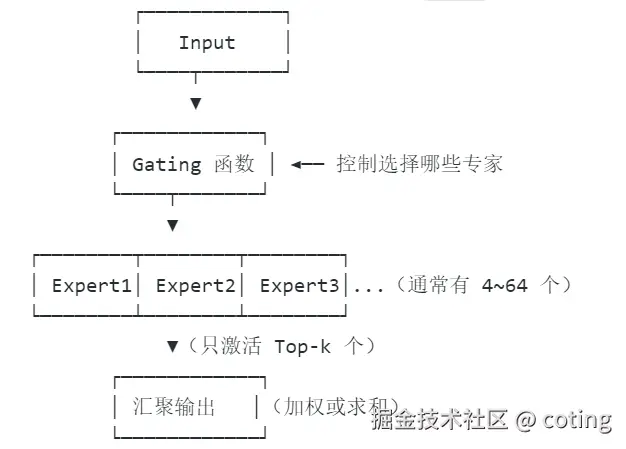
但现实中,MoE 面临诸多挑战:
- 专家选择不稳定,路由器输出随输入轻微扰动而变化剧烈
- 专家负载不均,部分专家被频繁调用,另一些则长期闲置
- 多任务学习能力弱,容易产生任务间干扰(Task Interference)
二、DeepSeekMoE 的关键创新
为应对上述挑战,DeepSeekMoE 提出了两个核心机制:
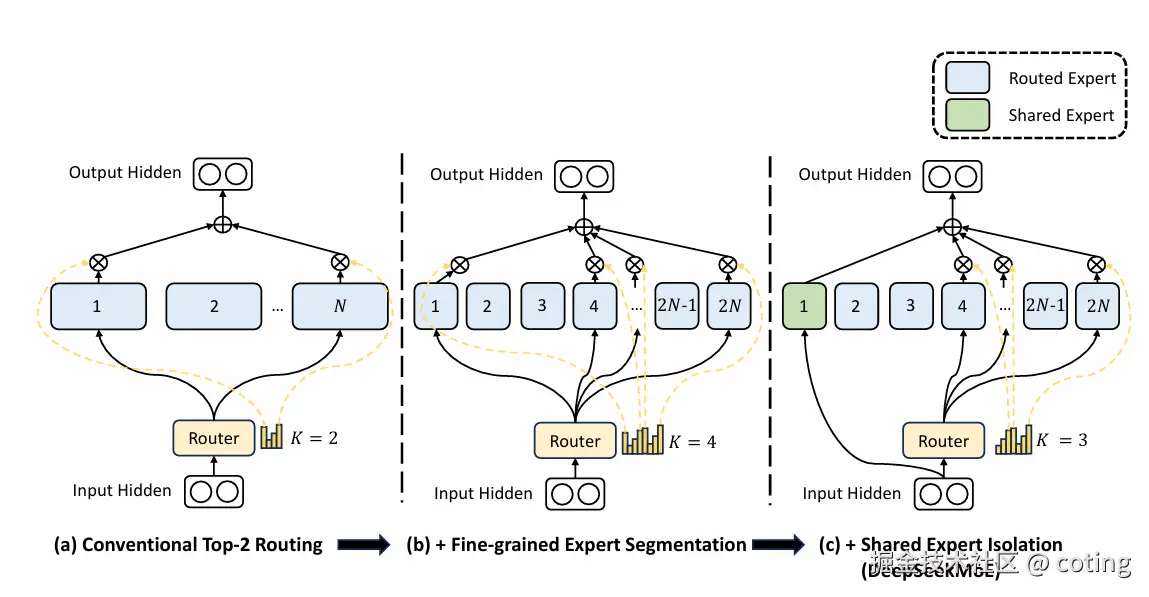
1. Fine-Grained Expert Segmentation(FGES)
将每个专家进一步划分为多个更小的"微专家"(sub-experts):
- 每个 token 不再选择 1~2 个专家,而是选择多个微专家组合;
- 更细粒度的组合方式,提升了专家多样性与表达能力;
- 强化模型的泛化能力,避免单一专家过拟合特定模式。
2. Shared Expert Isolation(SEI)
引入"共享专家隔离"机制,用于缓解任务间的干扰。
MoE 模型中的专家原本是"共享"的 ------ 所有任务都使用同一批专家模块。但这样会带来两个问题:
- 路由器会偏向某些专家,导致少数专家被过度使用;
- 不同任务之间相互干扰,尤其在分布差异较大的任务上,专家参数容易被不同任务"拉扯",降低泛化性能。
SEI 通过在专家的管理方式上引入「共享 + 特定」的结构,将专家分为两类:
1. 任务特定专家(Task-Specific Experts)
- 每个任务独占一部分专家,仅供该任务调用;
- 避免了任务之间争抢参数、互相干扰;
- 强化任务特化能力。
2. 共享专家(Shared Experts)
- 所有任务都可以访问,但需谨慎使用;
- 引入正则项约束路由器 :鼓励路由器优先调用任务特定专家,抑制对共享专家的过度依赖;
- 正则项可以视为给路由器一个"惩罚",告诉它"不要老是用共享专家"。
通过 SEI,模型内部形成了一种结构上的"信息防火墙":
- 对于不同任务,其专属专家可独立学习特定模式,保持信息纯度;
- 对于通用能力(如语言建模),可通过共享专家进行泛化学习;
- 正则机制则控制了信息交流的边界,既保证共享,又防止"污染"。
三、架构设计与实现细节
DeepSeekMoE 在 DeepSeek 基础模型上应用上述策略,具体架构如下:
| 模型规模 | 总参数量 | 激活参数量 | MoE 层数 | 每层专家数 | Top-k 选择 |
|---|---|---|---|---|---|
| 145B | 145B | 36.4B | 48 | 64 | 2 |
- 基于 Transformer 架构,采用 SwiGLU 激活、RoPE 位置编码;
- 所有 MoE 层均使用 GShard 路由器,Top-2 选择策略;
- 微专家(Sub-Experts)在内部分组,路由器可灵活组合调用;
- 支持 FP8 混合精度训练,优化训练吞吐量与稳定性。
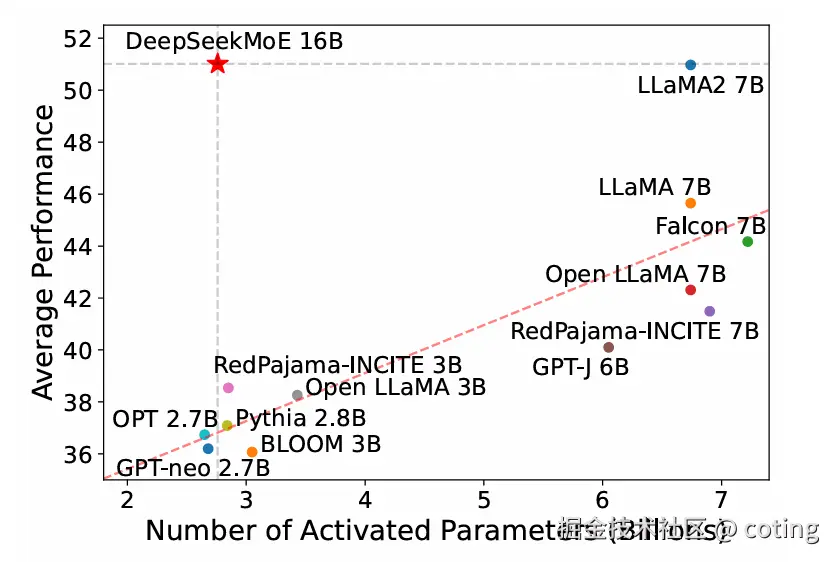
此外,DeepSeekMoE 模型在多个下游任务上取得了比肩甚至超过 Dense 模型的性能,尤其在多任务泛化能力方面表现出色。
四、训练与推理效率的双赢
DeepSeekMoE 并没有牺牲计算效率来换取模型表现,而是在保持 相同推理 FLOPs 的前提下取得显著提升:
- 推理阶段:仅激活少量专家,KV 缓存显著减少;
- 训练阶段:采用专家负载平衡损失、异步加载机制,确保训练稳定;
- 部署阶段:灵活微专家组合结构,使模型可扩展性更强;
实验证明,DeepSeekMoE 在多个权衡指标中取得了更优解:
📌 结语
DeepSeekMoE 不只是 MoE 架构的又一次实验探索,它是对专家网络未来发展路径的深度思考。通过微专家化与任务隔离机制,DeepSeekMoE 让专家模型"用得上、用得稳、用得广",为构建强大、泛化能力强、成本可控的大模型提供了全新范式。
如果你正在关注 MoE 模型、探索训练效率与推理表现的最佳平衡,DeepSeekMoE 值得你深入研究与借鉴。
最后我们回答一下文章开头提出的三个问题:
1. 传统 MoE 模型在专家选择上存在哪些问题?
传统 MoE 面临专家路由不稳定、负载不均、多任务干扰等问题,导致性能提升有限甚至出现退化。
2. DeepSeekMoE 如何实现高效又稳定的专家利用?
通过引入 Fine-Grained Expert Segmentation 提高组合灵活性,Shared Expert Isolation 缓解任务干扰,实现高质量专家选择与负载平衡。
3. 在计算成本不变的前提下,DeepSeekMoE 如何提升性能?
在相同的 FLOPs 下,激活更少参数、优化路由策略和专家划分,使模型表现全面超越传统 Dense 和 MoE 架构。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号算法coting!