摘要
本文记录了排查前端版本部署失败的过程,穿插讲解了前端程序的部署流程, HTTP 的强制缓存、协商缓存的实现方式,浏览器分区缓存的机制,部署流程的改进措施。 秉着写作即思考的原则,我希望能通过记录问题排查流程的方式,将解决实际工程问题的思路梳理清晰,积累工程经验,在日后debug过程中能有一个好的直觉。
问题描述
前端同学在支付页面上线一个新版本后,从我们网站的主页点击支付按钮跳转支付页仍然是老版本。我想,应该是浏览器直接使用本地缓存了;于是我刷新了支付页面,果然变成新版本了。可是,当我从再次重复以上过程,从网站主页点击支付按钮跳到支付页时,访问的还是老版本。
这就让我有点费解:
- 支付页的缓存不是应该刷新了吗?怎么又访问回老版本了?
- 这里为什么会对前端静态文件进行缓存,有缓存的话前端发布新版本不是不能立即生效了吗?
- 前端页面是如何进行部署的?具体机制是怎么样?(笔者是后端同学,对前端部署了解比较少,正好趁着查这个问题,把前端部署的流程梳理明白)
- 访问支付页面有两种方式,一种是从主页点击跳转(一直访问到老版本),一种是直接键入支付页链接(一直访问到新版本);这两种方式访问有区别吗?
排查思路
浏览器如何访问前端web页
带着以上疑问,我开始了解公司前端web页面部署的过程,大致流程如下:
-
通过 Next.js 框架导出静态文件,包括编译后的 JS、CSS、静态资源、html 文件
-
将静态文件上传到 OSS 的一个 bucket
-
后端了配置 CDN 域名的回源 host 为上述 bucket 的域名
综上所述,用户从浏览器访问 web 页面的过程中,有两层缓存可能导致上述问题
- 浏览器使用了本地缓存,并未请求 CDN 服务器,导致访问到了老版本
- 浏览器请求了 CDN 服务器,CDN 判断缓存并未过期,没有回源去请求 OSS,导致访问到了老版本
缓存的具体机制是什么样的
将流程梳理清楚后,我开始排查究竟是命中了哪一层的缓存,是浏览器本地缓存还是 CDN 缓存?
为了弄明白这个问题,我需要知道 HTTP 的缓存技术是如何实现的(没想到找工作时看的八股文这时用上了🤣,推荐大家看 小林coding的图解网络,讲得非常详细画图也很直观,在我找工作时给了我很大帮助)
这里我简单概括一下,HTTP 有两种缓存机制,强制缓存和协商缓存。
| 对比维度 | 强制缓存 | 协商缓存 |
|---|---|---|
| 核心机制 | 浏览器直接根据缓存规则判断是否使用本地缓存,不发送请求到服务器 | 浏览器先发送请求到服务器,由服务器判断是否使用本地缓存 |
| 是否发送请求 | 命中缓存时,不发送请求 | 无论是否命中缓存,都会发送请求 |
| 缓存有效性判断 | 由浏览器根据缓存时间等规则独立判断 | 由服务器根据请求头信息判断,并返回结果 |
| 控制字段 | - 响应头 Expires:指定缓存过期的绝对时间(HTTP/1.0)- 响应头 Cache-Control:通过 max-age(缓存有效秒数)、public/private 等指令控制(HTTP/1.1,优先级高于 Expires) | - 请求头 If-Modified-Since & 响应头 Last-Modified:基于文件修改时间判断,前者是请求时发送的上次修改时间,后者是服务器返回的最新修改时间- 请求头 If-None-Match & 响应头 ETag:基于文件内容生成的唯一标识判断,前者是请求时发送的上次标识,后者是服务器返回的最新标识(优先级高于 Last-Modified) |
| 状态码 | 命中缓存时返回 200 OK(from cache) | 命中缓存时返回 304 Not Modified;未命中时返回 200 OK 及新资源 |
| 适用场景 | 静态资源(如图片、CSS、JS),内容不常变化 | 动态资源或内容可能频繁变化的资源,需服务器确认有效性 |
搞明白 HTTP 缓存的机制后,我开始了排查过程
-
首先,确认 CDN 缓存的版本。我查看了我们阿里云 CDN 的配置,发现过期时间就 1s。(笔者在这里是挺想吐槽的,一秒过期配啥 CDN 啊!)不过先回到主线,至少说明 CDN 上肯定回源了新版本,CDN 的配置之后再调。
-
接着就是确认浏览器是否用了本地缓存了。这里有两种访问支付页的方式:一种是从主页点击支付按钮跳到支付页,一种是直接键入支付页链接。
-
先对点按钮跳转支付页抓包。由于这里是弹出一个新的 tab 所以需要将 DevTools Settings 的
Auto-open DevTools for popups的设置勾选上。这样才能抓到弹出新页面的那次网络请求。配置如下图所示
- 接着对支付页进行抓包,显示
from disk cache,果然是浏览器使用了强制缓存,压根儿就没有请求 CDN 服务。可是为什么浏览器会走强制缓存呢?我们也没有设置Cache-Control或者Expires字段啊。 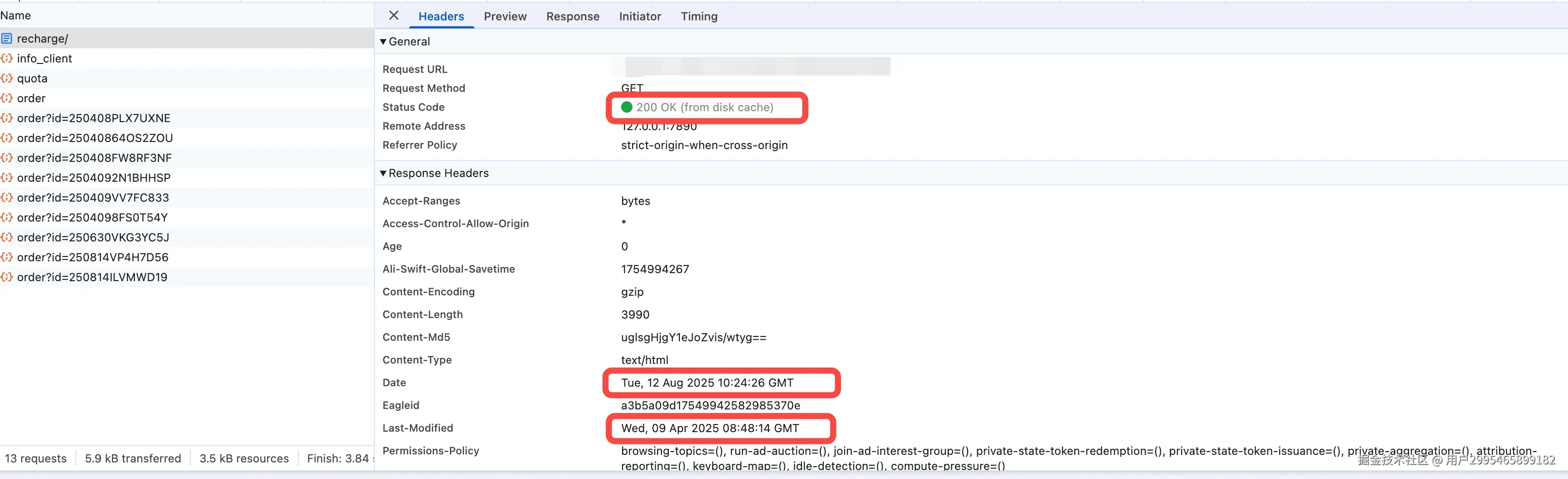
- 搜索一番资料后,发现当服务器没有设置
Expires和Cache-Control响应头时,浏览器会采用启发式缓存策略来决定是否缓存资源以及缓存的有效期:浏览器会将Last-Modified和Date之间的时间差(即资源在服务器上未修改的 "存活时间")作为参考,通常取这个时间差的 10% 作为缓存的有效期。在我们这个场景中,浏览器就是用了启发式缓存的机制,发现缓存有效,直接使用了老版本的前端代码。
-
那么为什么直接键入URL或者刷新页面可以访问到新版本呢?我们直接键入URL进行抓包,发现这里使用了协商缓存,并且拉到了最新的数据。这也是符合预期的,CDN 上已经存有最新的数据了,并且浏览器已经访问了这个页面拉到过新版本,这里显示 304 也是正常的。
-

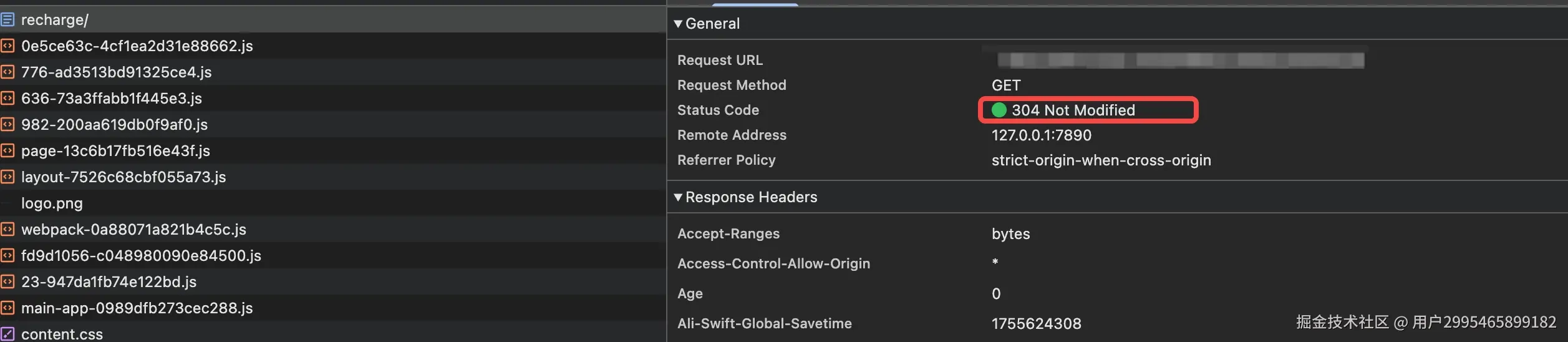
经过以上抓包排查后,我们已经能回答一些问题了:在主页点击按钮跳转是浏览器使用了启发式缓存机制,直接使用了本地缓存;而键入URL或者刷新页面一定会发起网络请求,并且 CDN 上也是最新数据,所以拉到了新版本。因为运用了两种缓存机制所以导致了版本横跳!
为什么同时存在两份缓存
那么现在的问题是,同样是访问这个支付页的URL,拉到过一次最新数据缓存不是应该刷新了吗?为什么旧版本的缓存依然存在?目前来看,浏览器是有两份缓存的。
我的第一想法是,浏览器的 cacheKey 不只是 URL,可能还带有 Referer或者 Origin,因为主页和支付页不在一个域名下,两种访问方式的 Referer和 Origin是不一样的,所以两者的缓存不会相互覆盖。查阅资料后,浏览器的 cacheKey 并不会拼接这些字段,倒是会拼接 Vary头,可是我检查了 Vary 都是 Accept-Encoding,并且两种访问方式带上的 Accept-Encoding 都是 gzip, deflate, br, zstd。
最后,发现浏览器有分区缓存的机制,比如按 Origin分区缓存,基于浏览器的 "同源策略" 实现。
- 源的定义:由 "协议 + 域名 + 端口" 三者共同组成(如example.com:443和
http://example.com:80属于不同源)。 - 分区逻辑:每个源拥有独立的缓存空间,不同源的缓存资源完全隔离。例如,
example.com的缓存不会与test.com的缓存互通,即使两者有同名资源(如 cdn.com/logo.png ),也会分别存储在各自的分区中。 - 作用:避免跨源资源混淆:不同源可能存在同名但内容不同的资源(如
/api/data.json),分区可防止错误引用其他源的缓存;保障安全性:防止恶意网站通过访问其他源的缓存获取用户数据(如登录状态、个人信息等)。
至此,我们的问题得到了全部的解答,浏览器具有分区缓存的机制,从不同域名访问支付页URL命中的是不同的缓存
改进措施
⚠️注意,笔者并非前端同学,这里只是结合上述浏览器和 CDN 缓存机制给出一个改进方案,并非最佳实践。大家可以在评论区留下更好的部署方案,讲的有问题的地方也欢迎大家批评指正。
首先,这次我们犯的一个错误是没有设置 Cache-Control字段,导致浏览器使用了启发式缓存机制,影响了我们版本发布的及时性;其次,我们虽然使用了 CDN 但是 1s 的过期时间没有发挥出 CDN 的效用。所以,我们这次的改进主要是针对这两点。
一般来说,Next.js 的打包出的静态资源如下,我们应该针对其资源类型进行分层配置缓存策略:
- 内容哈希命名的资源:
/_next/static/**(包含JS/CSS/ 图片等,比如main.8f2b3d.js、image.1a2b.png命名会随着内容变化 ) - 无哈希资源:
/*.html、/**/*.html(比如index.html、about.html)
| 资源类型 | CDN→OSS(CDN 节点缓存) | 浏览器→CDN(响应头 Cache-Control) | 目的说明 |
|---|---|---|---|
| 带哈希静态资源 | 缓存 1 年,忽略源站短缓存头 | public, max-age=31536000, immutable | CDN 和浏览器长期缓存,内容更新时通过新文件名自动失效 |
| 无哈希 HTML 资源 | 缓存 5 分钟(短缓存) | public, max-age=0, must-revalidate | CDN 频繁回源验证 HTML 更新,浏览器每次请求 CDN 获取最新 HTML |
| 其他无哈希静态资源(如 logo.png) | 缓存 1 小时,回源时验证 | public, max-age=3600, must-revalidate | 允许短期缓存,到期后验证是否更新(避免频繁回源) |