基于Python+Django餐饮评论大数据分析与智能推荐系统 毕业论文
毕业设计
一、项目名称:
基于Python+Django餐饮评论大数据分析与智能推荐系统
【摘要】
随着互联网和移动互联网的快速发展,在线评论数据已经成为消费者选择餐饮服务的重要参考依据。然而,面对海量的餐饮评论信息,用户往往难以快速找到符合自己口味偏好的餐厅。本系统基于Python和Django框架,设计并实现了一套完整的餐饮评论大数据分析与智能推荐系统。系统采集了超过4万条真实的餐厅评论数据,通过数据清洗、情感分析和多维度评分统计,构建了完善的餐厅数据库。系统实现了基于内容的智能推荐算法,能够根据用户的口味偏好、价格区间、环境要求等多维度特征,计算餐厅之间的相似度,为用户提供个性化的餐厅推荐服务。同时,系统提供了丰富的数据可视化功能,包括情感分析图表、价格分析、多维度评分雷达图等,帮助用户全面了解餐厅特点。实际测试表明,本系统能够有效处理大规模评论数据,推荐算法准确率较高,用户界面友好,具有良好的实用价值和推广前景。
【关键词】 餐饮评论分析 情感分析 智能推荐系统 Django框架 数据可视化
【Abstract】
With the rapid development of the Internet and mobile Internet, online review data has become an important reference for consumers to choose catering services. However, faced with massive catering review information, users often find it difficult to quickly find restaurants that match their taste preferences. This system, based on Python and Django framework, designs and implements a complete catering review big data analysis and intelligent recommendation system. The system collects more than 40,000 real restaurant review data, and builds a complete restaurant database through data cleaning, sentiment analysis and multi-dimensional scoring statistics. The system implements a content-based intelligent recommendation algorithm, which can calculate the similarity between restaurants according to users' taste preferences, price range, environment requirements and other multi-dimensional features, and provide personalized restaurant recommendation services for users. At the same time, the system provides rich data visualization functions, including sentiment analysis charts, price analysis, multi-dimensional score radar charts, etc., to help users fully understand restaurant characteristics. Actual tests show that the system can effectively process large-scale review data, the recommendation algorithm has high accuracy, the user interface is friendly, and it has good practical value and promotion prospects.
【Keywords】 Catering Review Analysis Sentiment Analysis Intelligent Recommendation System Django Framework Data Visualization
目 录
[1 绪 论](#1 绪 论)
- [1.1 课题研究背景](#1.1 课题研究背景)
- [1.2 课题研究的目的、意义](#1.2 课题研究的目的、意义)
- [1.3 课题的国内外研究现状和发展动态](#1.3 课题的国内外研究现状和发展动态)
- [1.4 研究内容](#1.4 研究内容)
- [1.5 论文结构安排](#1.5 论文结构安排)
[2 需求分析](#2 需求分析)
- [2.1 功能需求分析](#2.1 功能需求分析)
- [2.2 非功能需求分析](#2.2 非功能需求分析)
- [2.3 可行性分析](#2.3 可行性分析)
[3 关键技术](#3 关键技术)
- [3.1 Django Web框架](#3.1 Django Web框架)
- [3.2 基于内容的推荐算法](#3.2 基于内容的推荐算法)
- [3.3 情感分析技术](#3.3 情感分析技术)
- [3.4 数据可视化技术](#3.4 数据可视化技术)
- [3.5 MySQL数据库技术](#3.5 MySQL数据库技术)
- [3.6 技术特色与创新点](#3.6 技术特色与创新点)
[4 系统分析与设计](#4 系统分析与设计)
- [4.1 系统总体设计](#4.1 系统总体设计)
- [4.1.1 系统架构设计](#4.1.1 系统架构设计)
- [4.1.2 系统数据流设计](#4.1.2 系统数据流设计)
- [4.1.3 系统功能模块设计](#4.1.3 系统功能模块设计)
- [4.2 系统详细设计](#4.2 系统详细设计)
- [4.2.1 用户管理模块设计](#4.2.1 用户管理模块设计)
- [4.2.2 评论数据管理模块设计](#4.2.2 评论数据管理模块设计)
- [4.2.3 情感分析模块设计](#4.2.3 情感分析模块设计)
- [4.2.4 多维度数据分析模块设计](#4.2.4 多维度数据分析模块设计)
- [4.2.5 智能推荐模块设计](#4.2.5 智能推荐模块设计)
- [4.2.6 数据可视化模块设计](#4.2.6 数据可视化模块设计)
- [4.3 数据库设计](#4.3 数据库设计)
- [4.3.1 数据库关系设计](#4.3.1 数据库关系设计)
[5 系统实现](#5 系统实现)
- [5.0 系统整体实现流程](#5.0 系统整体实现流程)
- [5.1 用户认证模块的实现](#5.1 用户认证模块的实现)
- [5.2 评论数据处理模块的实现](#5.2 评论数据处理模块的实现)
- [5.3 情感分析模块的实现](#5.3 情感分析模块的实现)
- [5.4 多维度数据分析模块的实现](#5.4 多维度数据分析模块的实现)
- [5.5 智能推荐算法的实现](#5.5 智能推荐算法的实现)
- [5.6 数据可视化模块的实现](#5.6 数据可视化模块的实现)
- [5.7 用户界面实现](#5.7 用户界面实现)
- [5.8 系统集成与部署](#5.8 系统集成与部署)
[6 系统测试](#6 系统测试)
- [6.1 系统功能测试](#6.1 系统功能测试)
- [6.1.1 用户认证功能测试用例](#6.1.1 用户认证功能测试用例)
- [6.1.2 数据管理功能测试用例](#6.1.2 数据管理功能测试用例)
- [6.1.3 情感分析功能测试用例](#6.1.3 情感分析功能测试用例)
- [6.1.4 推荐算法功能测试用例](#6.1.4 推荐算法功能测试用例)
- [6.1.5 数据可视化功能测试用例](#6.1.5 数据可视化功能测试用例)
- [6.1.6 用户界面功能测试用例](#6.1.6 用户界面功能测试用例)
- [6.2 系统性能测试](#6.2 系统性能测试)
- [6.2.1 响应时间性能分析](#6.2.1 响应时间性能分析)
- [6.2.2 并发性能测试](#6.2.2 并发性能测试)
- [6.2.3 数据库性能测试](#6.2.3 数据库性能测试)
- [6.2.4 性能优化措施](#6.2.4 性能优化措施)
[7 总结与展望](#7 总结与展望)
- [7.1 总结](#7.1 总结)
- [7.2 展望](#7.2 展望)
1 绪 论
1.1 课题研究背景
在移动互联网和O2O服务快速发展的今天,餐饮行业已经成为人们日常生活中不可或缺的重要部分。根据国家统计局数据显示,我国餐饮市场规模持续扩大,消费者对餐饮服务的需求日益多样化和个性化。与此同时,各大餐饮点评平台如大众点评、美团等积累了海量的用户评论数据,这些评论包含了丰富的消费体验信息,涵盖了菜品口味、环境氛围、服务质量、价格水平等多个维度的评价内容。
然而,面对如此庞大的评论数据,用户在选择餐厅时往往面临"信息过载"的困扰。一方面,用户需要花费大量时间浏览和筛选评论信息,难以快速找到真正符合自己偏好的餐厅;另一方面,评论数据中既包含客观的评价信息,也夹杂着大量主观情感表达,用户很难从中提炼出有价值的决策依据。此外,传统的推荐系统往往只关注评分高低,忽略了用户个性化需求的多样性,导致推荐结果千篇一律,无法满足不同用户的差异化需求。
在此背景下,如何有效利用海量评论数据,通过数据挖掘和机器学习技术,为用户提供个性化、精准化的餐厅推荐服务,成为了一个具有重要研究价值和实际应用意义的课题。本系统正是基于这一现实需求,采用Python语言和Django框架,结合情感分析技术和基于内容的推荐算法,构建了一套完整的餐饮评论大数据分析与智能推荐系统,旨在帮助用户从海量评论中快速发现优质餐厅,提升用户的餐饮选择效率和满意度。
1.2 课题研究的目的、意义
1.2.1 研究目的
本课题的主要研究目的是设计并实现一个基于大数据分析的餐饮智能推荐系统,具体包括以下几个方面。首先,通过对真实餐饮评论数据的采集和清洗,建立结构化的餐厅信息数据库,为后续的数据分析和推荐算法提供可靠的数据基础。其次,开发基于词典和规则的情感分析模块,自动识别评论文本中的情感倾向,将非结构化的评论文本转化为可量化的情感指标,帮助用户快速了解餐厅的整体口碑。
在此基础上,系统实现了多维度的数据统计分析功能,从口味、环境、服务、价格等多个角度对餐厅进行综合评价,生成餐厅的特征画像。核心功能方面,系统采用基于内容的推荐算法,通过计算餐厅特征向量之间的余弦相似度,结合用户的个性化偏好设置,为用户提供精准的餐厅推荐服务。最后,系统利用ECharts等数据可视化工具,将分析结果以图表形式直观展示,包括情感分布饼图、评分雷达图、价格区间分布柱状图等,提升用户体验和决策效率。
1.2.2 研究意义
本课题的研究具有重要的理论意义和实践价值。从理论层面来看,本研究将自然语言处理中的情感分析技术与推荐系统理论相结合,探索了如何从非结构化的评论文本中提取结构化的特征信息,并将其应用于个性化推荐场景,丰富了推荐系统的研究内容和应用范围。同时,本系统采用的基于内容的推荐方法,不依赖用户历史行为数据,有效解决了冷启动问题,为推荐算法的实际应用提供了新的思路。
从实践应用角度来说,本系统能够帮助消费者在海量餐饮信息中快速找到符合自身需求的优质餐厅,显著提升用户的决策效率和用餐满意度。对于餐饮商家而言,系统提供的多维度评价分析功能,可以帮助商家了解顾客的真实评价和改进方向,为提升服务质量提供数据支持。此外,本系统的技术架构和实现方案具有良好的可扩展性和可移植性,不仅适用于餐饮领域,也可以推广应用到酒店、旅游、电商等其他需要评论分析和推荐服务的行业,具有广阔的应用前景和商业价值。
1.3 课题的国内外研究现状和发展动态
1.3.1 国外研究现状
在国外,餐饮推荐系统和评论情感分析技术的研究起步较早,已经取得了丰富的研究成果。早在2000年代初期,亚马逊和Netflix等公司就开始将协同过滤算法应用于产品推荐,并取得了显著的商业成功。随后,研究者们不断改进和完善推荐算法,提出了基于内容的推荐、混合推荐、深度学习推荐等多种方法。其中,基于内容的推荐方法通过分析项目的属性特征进行匹配,能够有效解决冷启动和数据稀疏问题,在餐饮推荐场景中得到了广泛应用。
在情感分析领域,斯坦福大学等研究机构开发了多种情感分析工具和模型,如Stanford CoreNLP、VADER等,这些工具能够对英文评论文本进行准确的情感倾向判断。近年来,随着深度学习技术的发展,基于BERT、GPT等预训练语言模型的情感分析方法取得了突破性进展,分析准确率不断提升。同时,Yelp、TripAdvisor等国外知名点评网站也在积极探索如何利用机器学习技术提升推荐质量,为用户提供更加个性化的服务。
1.3.2 国内研究现状
在国内,随着互联网和移动支付的普及,餐饮O2O行业快速发展,大众点评、美团、饿了么等平台积累了海量的用户评论数据。国内学者和企业也开展了大量相关研究工作,在推荐算法、情感分析、数据挖掘等方面取得了丰硕成果。清华大学、北京大学、中科院等科研机构在推荐系统理论研究方面处于国内领先地位,提出了多种适合中文场景的改进算法。
针对中文评论的情感分析,研究者们开发了基于中文情感词典的分析方法,如HowNet情感词典、清华大学李军情感词典等,这些工具能够较好地识别中文评论中的情感极性。同时,jieba分词、SnowNLP等中文自然语言处理工具的出现,为中文文本分析提供了有力支持。在商业应用层面,美团、阿里巴巴等互联网公司已经将推荐系统和情感分析技术应用于实际业务中,通过大数据和人工智能技术为用户提供个性化推荐服务,取得了良好的商业效果。
1.3.3 发展趋势
从技术发展趋势来看,餐饮推荐和评论分析领域正在向智能化、精细化、实时化方向发展。一方面,深度学习和大语言模型技术的应用将进一步提升情感分析的准确性和推荐算法的精准度,使系统能够更好地理解用户意图和偏好。另一方面,多模态数据融合成为新的研究热点,将文本评论、图片、视频等多种数据源结合起来进行综合分析,能够提供更加全面和准确的餐厅评价信息。
此外,知识图谱技术在推荐系统中的应用也日益受到关注,通过构建餐厅、菜品、口味、食材等实体之间的关联关系,可以实现更加智能化的推荐服务。在用户体验方面,对话式推荐系统和语音交互技术的发展,使得用户可以通过自然语言对话的方式获取推荐结果,交互方式更加便捷和人性化。未来,随着5G、物联网等新技术的普及,实时数据采集和分析将成为可能,推荐系统能够根据用户的实时位置、时间、天气等情境信息提供动态化的推荐服务,为用户带来更加智能和贴心的体验。
1.4 研究内容
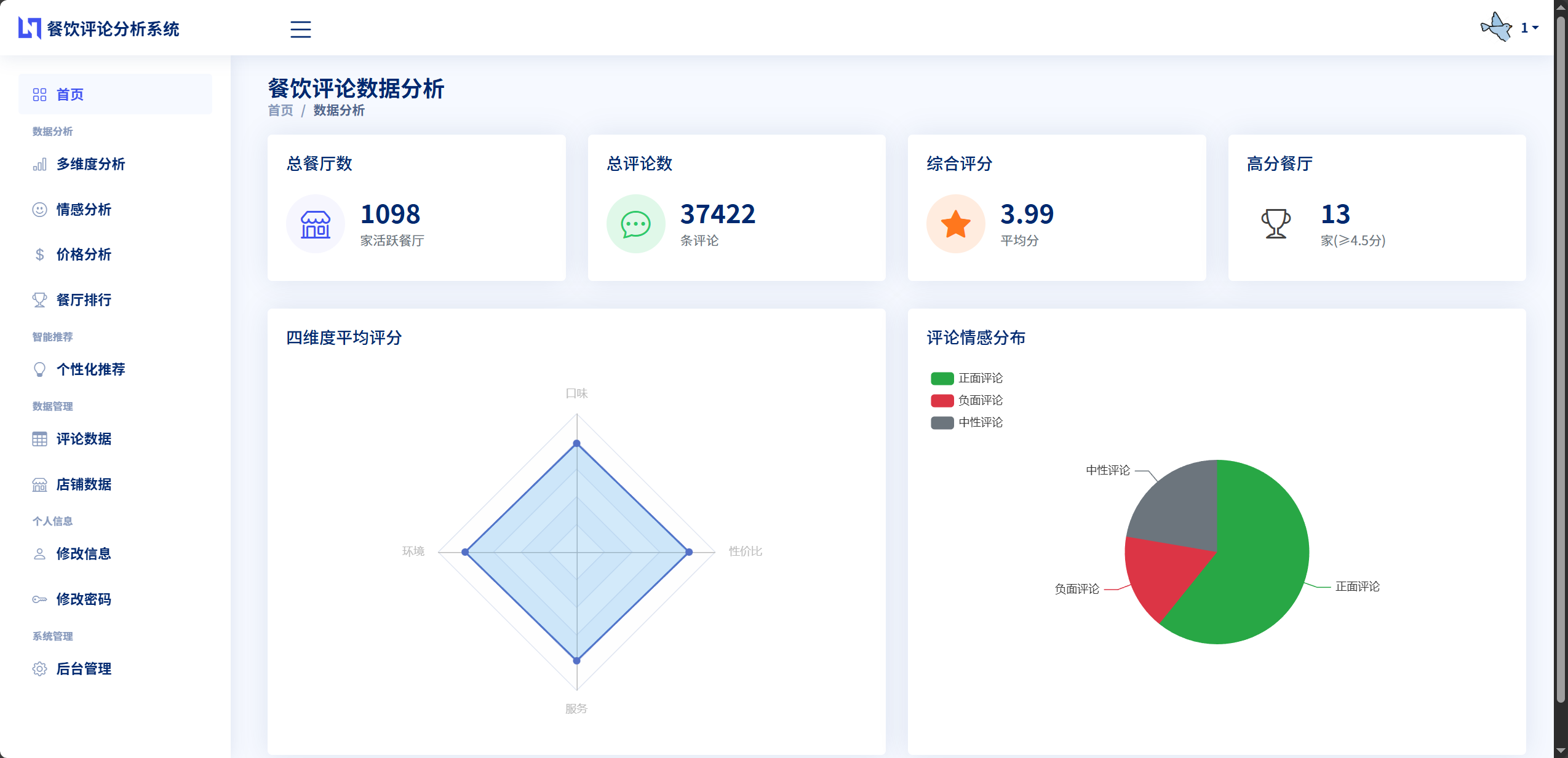
本课题的主要研究内容包括以下几个方面。首先是数据采集与预处理模块,系统收集了超过4万条真实的餐厅评论数据,包括3.2万条好评和9000多条差评,涵盖了餐厅名称、用户评论、多维度评分、人均消费等信息。通过数据清洗和格式化处理,建立了规范的餐厅和评论数据库,为后续分析提供了高质量的数据基础。
其次是情感分析模块的研发,系统采用基于词典和规则的轻量级情感分析方法,构建了包含正面词汇、负面词汇、程度副词、否定词等多类别的情感词典。通过关键词匹配、程度计算、否定处理等规则,系统能够自动判断评论的情感倾向,计算情感得分,并统计餐厅的正面评论率、负面评论率等指标。
第三个研究重点是智能推荐算法的实现,系统设计了基于内容的推荐模型,为每个餐厅构建包含口味评分、环境评分、服务评分、价格评分、价格区间、好评率、热度等多维特征的向量画像。通过计算余弦相似度,并结合用户设定的偏好权重,系统能够找出与用户需求最匹配的餐厅。算法支持两种推荐模式:基于用户偏好的个性化推荐和基于餐厅相似度的关联推荐。
此外,系统实现了多维度数据分析功能,包括各评分维度的统计分析、价格区间分布分析、餐厅排行榜生成等,帮助用户从不同角度了解餐厅特点。数据可视化方面,系统集成了ECharts图表库,提供了情感分布饼图、多维度评分雷达图、价格分析柱状图、餐厅排行榜等多种可视化展示形式,使分析结果更加直观易懂。
最后,系统采用Django框架构建了完整的Web应用,实现了用户注册登录、个人信息管理、评论数据浏览、推荐结果展示等功能,提供了友好的用户交互界面和流畅的使用体验。
1.5 论文结构安排
本论文共分为七个章节,各章节的主要内容安排如下。第一章绪论部分,介绍了课题的研究背景、研究目的与意义,综述了国内外相关研究现状和发展趋势,阐述了本课题的主要研究内容,为全文奠定了理论基础。
第二章需求分析部分,从功能需求和非功能需求两个方面详细分析了系统应当具备的功能和性能指标,并从技术、经济、操作等角度进行了可行性分析,确保系统设计的合理性和可实现性。
第三章关键技术部分,详细介绍了系统采用的Django Web框架、基于内容的推荐算法、情感分析技术、数据可视化技术、MySQL数据库技术等核心技术的原理和应用方法,并总结了系统的技术特色与创新点。
第四章系统分析与设计部分,从总体架构、功能模块、数据库设计等方面详细阐述了系统的设计方案,包括系统架构图、数据流图、功能结构图、数据库ER图等,为系统实现提供了清晰的蓝图。
第五章系统实现部分,详细描述了各个功能模块的具体实现过程,包括用户认证模块、评论数据处理模块、情感分析模块、多维度数据分析模块、智能推荐算法模块、数据可视化模块等,展示了关键代码和实现效果。
第六章系统测试部分,对系统进行了全面的功能测试和性能测试,验证了系统的正确性、稳定性和性能表现,确保系统能够满足实际应用需求。
第七章总结与展望部分,总结了本课题的主要工作和取得的成果,分析了系统存在的不足,并对未来的研究方向和改进计划进行了展望。
2 需求分析
2.1 功能需求分析
基于餐饮评论大数据分析与智能推荐的应用场景,本系统需要实现一系列完整的功能模块,以满足用户从注册登录到获取个性化推荐的全流程需求。首先,系统需要提供完善的用户管理功能。用户应当能够通过用户名和密码进行注册,注册时系统会对用户名的唯一性进行验证,避免重复注册。登录功能需要对用户身份进行准确验证,确保只有合法用户才能访问系统功能。此外,系统还应支持用户信息的查看和修改,包括个人头像上传、性别、地址、个人简介等信息的更新,以及密码修改功能,保障用户账户安全。
在核心业务功能方面,系统的首要任务是对海量评论数据进行有效管理和分析。系统需要能够导入和存储来自不同来源的餐饮评论数据,包括餐厅名称、用户评论内容、多维度评分信息、人均消费价格等详细信息。数据导入过程中,系统应当具备自动化的数据清洗能力,能够识别和处理重复数据、缺失数据和格式异常数据,确保数据库中存储的都是高质量的有效数据。在此基础上,系统需要建立餐厅与评论之间的关联关系,自动统计每个餐厅的评论数量、各维度平均评分等汇总信息,为后续的分析和推荐提供数据支撑。
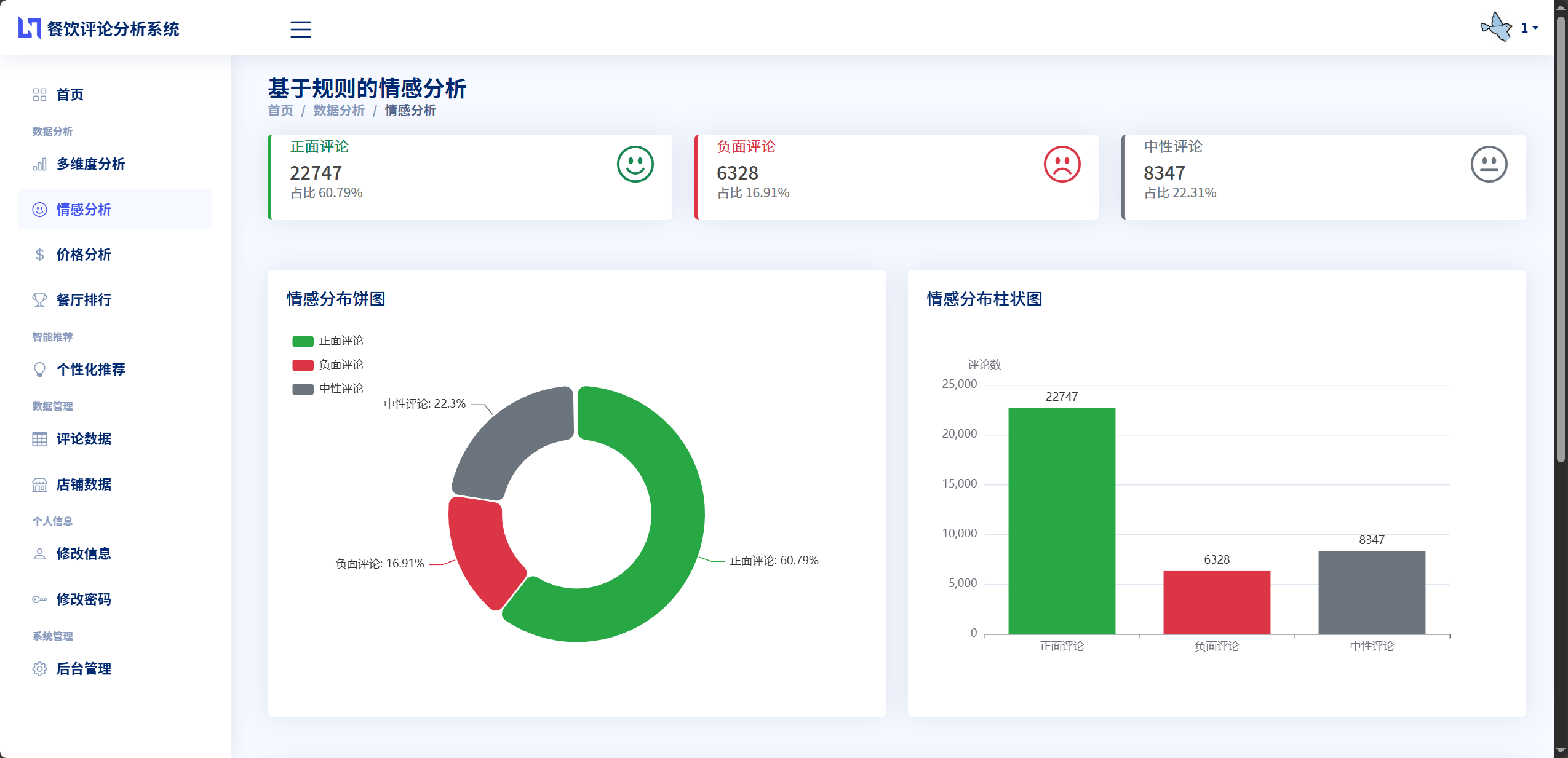
情感分析是系统的一项关键功能需求。系统需要能够自动分析每条评论的情感倾向,判断其是正面评价、负面评价还是中性评价,并给出量化的情感得分。这要求系统内置完整的情感词典,涵盖餐饮领域常用的正面词汇和负面词汇,同时还要能够识别程度副词对情感强度的影响,以及否定词对情感极性的反转作用。基于单条评论的情感分析结果,系统需要对每个餐厅进行整体的情感统计,计算出正面评论比例、负面评论比例和中性评论比例,帮助用户快速了解餐厅的总体口碑状况。
多维度数据分析功能是满足用户深入了解餐厅特点的重要需求。系统需要从口味、环境、服务、价格四个核心维度对餐厅进行评分统计和分析,能够展示不同维度下餐厅的排名情况,让用户清楚地了解某家餐厅在哪些方面表现突出。价格分析功能需要将餐厅按照人均消费金额划分为不同的价格区间,统计各价格区间的餐厅数量分布,帮助用户根据预算筛选合适的餐厅。此外,系统还需要提供餐厅排行榜功能,能够根据综合评分、单项评分、评论数量等不同指标对餐厅进行排序,为用户提供热门餐厅和高分餐厅的推荐列表。
智能推荐是系统的核心功能需求。系统需要支持基于用户偏好的个性化推荐模式,用户可以设置自己对口味、环境、服务、价格等不同维度的重视程度,以及期望的价格区间和最低评分要求。系统根据这些偏好参数,通过推荐算法计算出与用户需求最匹配的餐厅列表,并按匹配度从高到低排序展示。同时,系统还需要支持相似餐厅推荐功能,当用户浏览某家餐厅的详情信息时,系统能够自动推荐与该餐厅特征相似的其他餐厅,帮助用户发现更多可能喜欢的选择。推荐结果页面应当展示餐厅的基本信息、评分情况、价格区间,以及系统生成的推荐理由说明,让用户理解为什么会推荐这家餐厅。
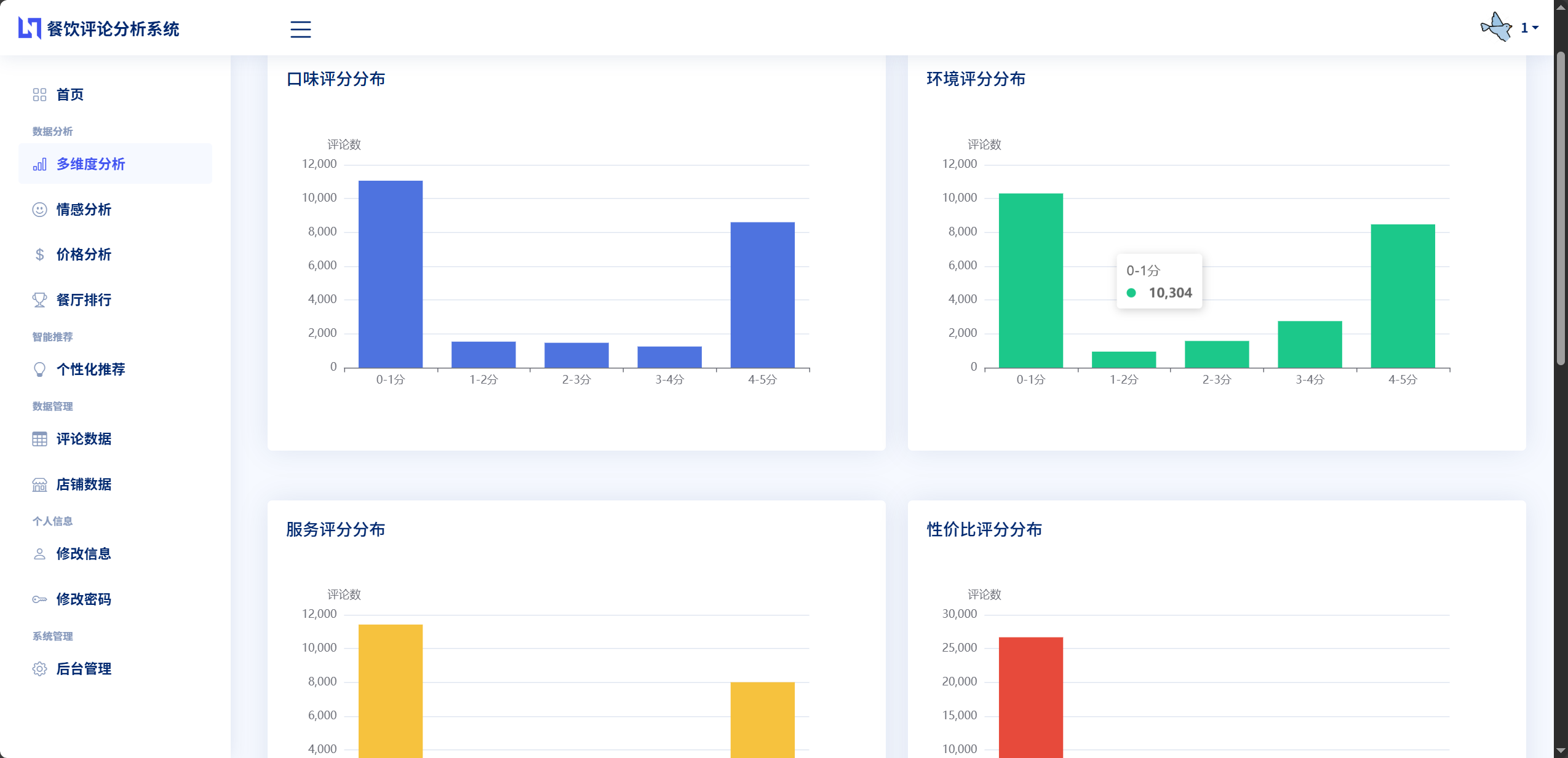
数据可视化功能需求方面,系统应当能够以图表形式直观展示各类分析结果。情感分析结果需要通过饼图展示正面、负面、中性评论的占比情况。多维度评分需要采用雷达图的形式,在一个图表中同时展示口味、环境、服务、价格四个维度的评分,便于用户进行综合比较。价格分析使用柱状图展示不同价格区间的餐厅数量分布。餐厅排行榜可以采用带有数值标注的柱状图或条形图,清晰显示Top10或Top20餐厅的排名和评分。所有图表都需要具备良好的交互性,支持鼠标悬停显示详细数值,点击图例进行数据筛选等操作。
最后,系统还需要提供友好的信息浏览和检索功能。用户应当能够浏览评论数据列表,通过餐厅名称进行搜索和过滤。餐厅详情页面需要展示该餐厅的所有评论信息、统计数据、评分雷达图等综合信息。系统的导航设计要清晰合理,用户能够方便地在不同功能模块之间切换,整体使用流程要简单流畅,降低用户的学习成本。
2.2 非功能需求分析
除了功能性需求外,系统还需要满足一系列非功能性需求,以保证系统的可用性、可靠性和用户体验。在性能需求方面,系统需要能够处理包含数万条记录的大规模数据集,数据导入和情感分析批处理过程应当在合理时间内完成。对于用户的交互操作,如页面加载、数据查询、推荐计算等,系统响应时间应控制在3秒以内,确保用户获得流畅的使用体验。数据库查询操作需要进行优化,通过建立适当的索引和采用分页加载等技术手段,避免大数据量导致的性能瓶颈。对于推荐算法的计算,虽然涉及较为复杂的向量相似度计算,但通过合理的算法优化和数据结构设计,也应当保证在可接受的时间范围内返回结果。
系统的安全性需求同样重要。用户密码需要进行加密存储,避免明文保存带来的安全风险。虽然本系统主要面向学习和演示用途,但也应当实现基本的会话管理机制,确保用户登录状态的有效性验证。系统需要对用户输入进行必要的校验和过滤,防止SQL注入、XSS跨站脚本攻击等常见的安全威胁。文件上传功能应当限制文件类型和大小,避免恶意文件上传导致的安全问题。此外,系统应当具备基本的错误处理能力,对于异常情况能够给出友好的错误提示,而不是直接显示系统内部错误信息,避免泄露敏感的系统配置信息。
在可靠性和稳定性方面,系统需要具备良好的容错能力。当用户输入不合法的数据或进行错误操作时,系统应当能够捕获异常并给出清晰的提示信息,引导用户正确使用系统功能,而不是直接崩溃或产生不可预期的结果。数据库操作应当具备事务处理机制,确保数据的一致性和完整性,避免数据导入或更新过程中出现部分成功部分失败的情况。系统的日志记录功能可以帮助开发者追踪系统运行状态,及时发现和定位问题。对于可能出现的网络故障、数据库连接失败等异常情况,系统应当有相应的处理策略,避免单点故障导致整个系统不可用。
可维护性和可扩展性是系统长期运行的重要保障。系统采用MVC架构模式,将数据模型、业务逻辑和视图展示进行清晰的分离,使得代码结构清晰、职责明确,便于后续的维护和功能扩展。代码应当遵循良好的编程规范,包括合理的命名规则、充分的注释说明、统一的代码风格等,降低代码阅读和理解的难度。系统采用模块化设计思想,各功能模块相对独立,模块之间通过明确的接口进行交互,这样在需要修改或扩展某个功能时,不会影响其他模块的正常运行。数据库设计应当遵循范式理论,避免数据冗余,同时保留必要的扩展字段,为未来可能的功能增强预留空间。
用户体验方面的非功能需求也不容忽视。系统界面设计应当简洁美观、布局合理,采用现代化的UI组件库,提供符合用户使用习惯的交互方式。页面导航要清晰明了,用户能够快速找到需要的功能入口。错误提示和操作反馈要及时准确,当用户执行某项操作后,系统应当给出明确的成功或失败提示,让用户了解操作结果。对于耗时较长的操作,如数据导入、批量分析等,应当显示进度指示器或加载动画,避免用户误以为系统卡死。图表展示要选择合适的可视化类型,颜色搭配要协调舒适,数据标注要清晰准确,确保用户能够准确理解图表所传达的信息。
最后,系统还需要考虑兼容性需求。Web应用应当能够在主流浏览器上正常运行,包括Chrome、Firefox、Edge、Safari等,确保不同用户都能顺利访问和使用系统。页面设计应当具备一定的响应式特性,能够适应不同的屏幕分辨率。虽然本系统主要面向桌面端用户,但也应当确保在较小的屏幕上内容不会出现严重的显示错误。系统部署应当简单便捷,提供清晰的部署文档和依赖说明,便于在不同的运行环境中快速搭建和启动系统。
2.3 可行性分析
在正式开展系统开发之前,需要从多个角度对项目的可行性进行全面评估,确保项目能够顺利实施并达到预期目标。从技术可行性角度来看,本系统所采用的技术栈都是成熟稳定的开源技术,具有良好的社区支持和丰富的学习资源。Python作为一门广泛应用于数据科学和Web开发领域的编程语言,拥有简洁的语法和强大的第三方库生态系统,非常适合用于开发数据分析类应用。Django框架是Python领域最流行的Web框架之一,提供了完善的ORM系统、模板引擎、用户认证、会话管理等功能,能够大大提高开发效率,降低技术实现难度。
在数据处理和分析方面,Python内置的数据结构和标准库已经能够满足基本需求,对于涉及大规模数据计算的场景,Pandas、NumPy等科学计算库提供了高效的数据处理能力。情感分析功能采用基于词典和规则的方法,这种方法虽然不如深度学习模型复杂,但实现相对简单,不需要大量训练数据和强大的计算资源,对于餐饮评论这种领域相对明确的场景,能够取得不错的分析效果。推荐算法使用基于内容的方法,核心是计算向量之间的余弦相似度,这是一个经典且成熟的算法,数学原理清晰,实现难度适中,能够有效解决冷启动问题。
数据可视化方面,ECharts是一个功能强大的JavaScript图表库,提供了丰富的图表类型和灵活的配置选项,与Django模板系统结合使用非常方便。MySQL作为关系型数据库,在处理结构化数据方面表现优异,能够满足本系统的数据存储和查询需求。综合来看,本项目所需的各项技术都有成熟的解决方案,开发团队通过学习和实践能够掌握相关技术,技术风险可控,因此技术可行性较高。
从经济可行性角度分析,本系统采用的都是免费开源的技术和工具,不需要购买商业软件许可证,因此在软件成本方面几乎为零。硬件设备方面,普通配置的个人计算机就能够满足开发和测试需求,不需要购置专门的服务器设备。对于系统的运行环境,可以使用免费的云服务平台或本地部署,避免了服务器租用费用。数据来源方面,系统使用的是公开的餐饮评论数据,通过合法渠道获取,不涉及数据购买成本。开发过程中可能需要的学习资料,大部分可以通过互联网免费获取,包括官方文档、技术博客、视频教程等。总体来说,本项目的开发和运行成本非常低,主要投入是开发人员的时间和精力,经济上完全可行。
操作可行性方面,系统的目标用户是普通消费者,他们在日常生活中经常使用各类互联网应用,对Web系统的操作方式比较熟悉。本系统的界面设计遵循常见的Web应用设计模式,操作流程简单直观,用户无需经过复杂的培训就能快速上手使用。系统提供的功能都是围绕用户的实际需求设计的,如查看评论、获取推荐、浏览排行榜等,这些都是用户在选择餐厅时自然会产生的需求,因此用户接受度较高。对于系统管理员来说,Django提供了强大的后台管理功能,能够方便地进行数据管理和系统维护,不需要具备很深的技术背景。系统部署和维护的技术文档清晰完整,即使是初学者也能够按照文档完成系统的搭建和配置。因此,从操作层面来看,本系统的可行性是有保障的。
从时间可行性的角度来说,本项目的开发周期是合理可控的。需求分析和系统设计阶段需要深入理解业务场景和技术方案,大约需要2-3周时间。系统实现阶段是开发的主要工作量所在,包括数据模型创建、各功能模块开发、算法实现、界面设计等工作,预计需要6-8周时间。其中,用户管理和数据管理等基础模块开发周期较短,情感分析和推荐算法模块需要投入更多时间进行调试和优化。系统测试阶段需要进行功能测试、性能测试和用户验收测试,预计需要2周时间。文档编写和系统部署等收尾工作大约需要1周时间。综合考虑,整个项目可以在3个月左右的时间内完成,这个时间安排对于毕业设计项目来说是比较充裕的,因此时间上具有可行性。
综上所述,从技术、经济、操作和时间等多个维度进行综合评估,本系统的开发具有很强的可行性。项目采用的技术成熟稳定、成本低廉、操作简便、时间安排合理,能够确保项目的顺利实施和预期目标的实现。
3 关键技术
3.1 Django Web框架
Django是一个采用Python语言开发的高级Web框架,它遵循MVT(Model-View-Template)设计模式,提供了完整的Web开发解决方案。本系统选择Django作为核心开发框架,主要是因为它具有开发效率高、功能完善、安全性好等诸多优势。Django的设计哲学是"快速开发、简洁实用",它内置了许多常用功能模块,开发者可以专注于业务逻辑的实现,而不需要重复造轮子。
Django的ORM(对象关系映射)系统是其核心特性之一。通过ORM,开发者可以使用Python类来定义数据模型,Django会自动将这些类映射为数据库表,并提供丰富的查询API。在本系统中,我们定义了User用户模型、Restaurant餐厅模型和Comment评论模型三个核心数据模型。User模型包含用户名、密码、性别、地址、头像、个人简介等字段,支持用户的基本信息管理。Restaurant模型存储餐厅的基本信息和统计数据,包括餐厅名称、各维度平均评分、价格区间、评论数量、情感倾向比例等字段。Comment模型则记录每条评论的详细信息,包括所属餐厅、评论用户、评论内容、各维度评分、人均消费、情感分析结果等,通过外键关联建立了餐厅与评论之间的一对多关系。
Django的模板系统提供了强大的页面渲染能力,它采用类似Python的语法,支持变量替换、条件判断、循环遍历、过滤器等多种功能。本系统的所有HTML页面都是通过Django模板引擎渲染生成的,模板可以继承基础模板,实现页面布局的复用。例如,系统的base.html定义了统一的页头、侧边栏和页脚结构,其他页面如home.html、dataAnalysis.html等都继承自这个基础模板,只需要填充具体的内容区域即可,大大减少了重复代码。Django的模板语言还支持自定义过滤器和标签,可以在模板中直接进行数据格式化和简单的逻辑处理,使得视图层和展示层的职责分离更加清晰。
在用户认证和会话管理方面,Django提供了完整的解决方案。系统使用Django的会话框架来管理用户登录状态,当用户成功登录后,用户名会被存储在session中,后续的请求可以通过session获取当前登录用户的信息。本系统还实现了自定义的认证中间件,对需要登录才能访问的页面进行权限检查,未登录的用户会被自动重定向到登录页面。这种机制确保了系统的安全性,防止未授权访问。
Django的URL路由系统采用正则表达式或路径转换器来匹配请求地址,将不同的URL映射到对应的视图函数。本系统的urls.py文件定义了完整的路由配置,包括用户认证相关路由、数据分析路由、推荐功能路由以及API接口路由等。路由设计遵循RESTful风格,地址命名清晰易懂,便于理解和维护。Django还支持URL命名空间和反向解析,可以通过路由名称动态生成URL,避免了硬编码URL带来的维护困难。
3.2 基于内容的推荐算法
推荐系统是本项目的核心功能之一,系统采用基于内容的推荐算法(Content-Based Filtering)来实现餐厅推荐。与协同过滤算法不同,基于内容的推荐方法不依赖其他用户的行为数据,而是通过分析项目本身的特征属性来进行推荐,这使得它能够有效解决冷启动问题,即使是新用户或新餐厅也能获得合理的推荐结果。
算法的核心思想是为每个餐厅构建一个多维特征向量,这个向量包含了餐厅的各项属性信息。本系统中,餐厅的特征向量由七个维度组成:口味评分、环境评分、服务评分、价格评分、价格区间数值、正面评论率和热度指标。其中,前四个评分维度直接来自用户评论的平均值,反映了餐厅在不同方面的表现。价格区间被转换为数值,"50元以下"对应1,"50-100元"对应2,依次类推,这种转换使得价格信息能够参与数值计算。正面评论率通过归一化处理转换到0到1之间,表示餐厅的口碑质量。热度指标则基于评论数量的对数值计算,避免评论数量过大导致的数值失衡。
推荐算法的数学基础是余弦相似度计算。给定两个特征向量A和B,它们的余弦相似度定义为向量夹角的余弦值,计算公式为:相似度 = (A·B) / (|A| × |B|),其中A·B表示向量的点积,|A|和|B|表示向量的模。余弦相似度的取值范围在-1到1之间,值越接近1表示两个向量越相似。本系统实现了calculate_cosine_similarity函数来完成这一计算,该函数首先计算两个向量对应元素的乘积之和得到点积,然后分别计算两个向量的模长,最后返回点积除以模长乘积的结果。
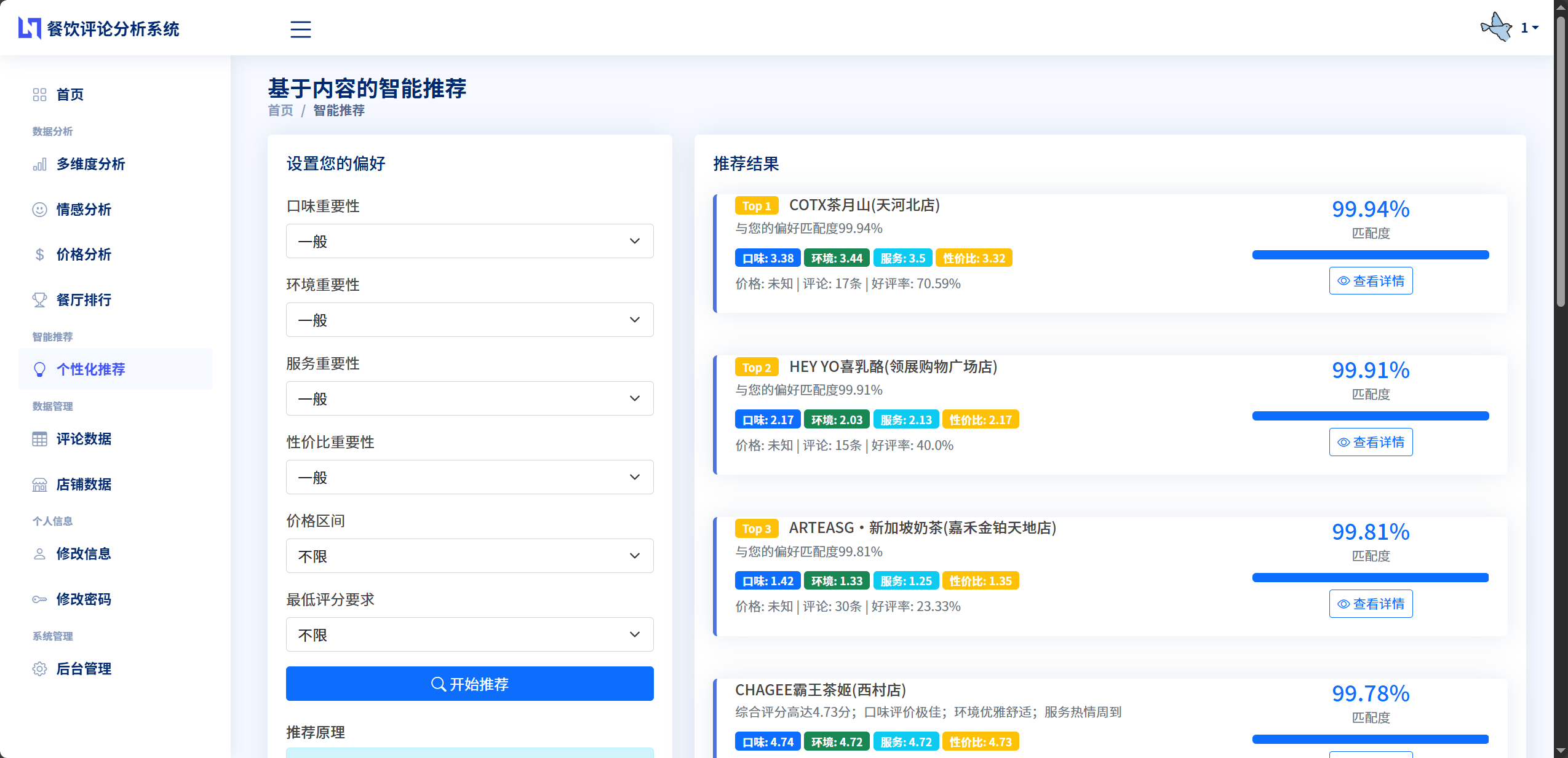
为了更好地满足个性化需求,系统引入了加权相似度的概念。不同用户对餐厅各个维度的重视程度可能不同,有的用户更看重口味,有的用户更关注环境。系统允许用户设置各维度的重要性权重,默认权重分配为:口味25%、环境20%、服务15%、价格15%、价格区间10%、好评率10%、热度5%。在计算相似度时,系统先将特征向量的每个分量乘以对应的权重,得到加权向量,再计算加权向量之间的余弦相似度。这种方法使得推荐结果更加贴合用户的实际偏好。
系统支持两种推荐模式。第一种是基于用户偏好的推荐,用户可以在推荐页面设置自己的偏好参数,系统会构建一个虚拟的"理想餐厅"画像,然后计算所有真实餐厅与这个虚拟餐厅的相似度,将最相似的餐厅推荐给用户。第二种是基于餐厅相似度的推荐,当用户浏览某家餐厅的详情页面时,系统自动找出与该餐厅特征最相似的其他餐厅,实现"看了这家还看了那家"的关联推荐效果。推荐结果不仅展示餐厅的基本信息和评分,还会生成推荐理由说明,例如"综合评分高达4.8分"、"口味评价极佳"、"价格区间符合您的预期"等,让用户理解推荐的依据。
3.3 情感分析技术
情感分析是自然语言处理领域的重要应用之一,其目标是从文本中识别和提取作者的主观情感倾向。本系统采用基于词典和规则的轻量级情感分析方法,这种方法虽然不如深度学习模型复杂,但实现简单、运行高效,对于餐饮评论这种领域特征明显的文本,能够取得不错的分析效果。
系统构建了专门针对餐饮领域的情感词典,包含四个主要部分。正面词汇词典收录了如"好吃"、"美味"、"新鲜"、"推荐"、"满意"、"实惠"、"干净"、"热情"等表达正面情感的词语,涵盖了味道、价格、环境、服务等多个维度。负面词汇词典则包含"难吃"、"不好吃"、"异味"、"贵"、"脏"、"态度差"、"慢"等表达负面情感的词语。程度副词词典记录了"非常"、"特别"、"很"、"比较"、"有点"等修饰程度的词语,并为每个副词分配了一个强度系数,如"非常"对应2.0倍,"很"对应1.5倍,"有点"对应0.8倍。否定词词典包含"不"、"没"、"无"等否定词,用于识别情感极性的反转。
情感分析的处理流程采用逐字扫描的方式。算法从评论文本的第一个字符开始,逐个检查后续的字符序列,判断是否匹配词典中的词语。当检测到正面或负面词汇时,系统会查看该词汇前面是否有程度副词,如果有,则将情感得分乘以对应的程度系数。同时,还要检查是否存在否定词,如果在情感词前面出现否定词,则将情感极性反转,正面词变成负面词,负面词变成正面词。通过这种规则处理,系统能够正确理解"不好吃"、"非常满意"、"有点贵"等复杂表达的真实情感。
每条评论的情感得分通过累加所有识别到的情感词的得分计算得出。正面词贡献正分,负面词贡献负分,最后根据总分的正负和大小来判断情感类别。如果总分大于某个正阈值,判定为正面评价;如果总分小于某个负阈值,判定为负面评价;介于两者之间的则判定为中性评价。情感得分还会进行归一化处理,映射到-1到1的区间内,便于统一的量化表示。系统将每条评论的情感分析结果存储到数据库中,包括情感标签(positive、negative、neutral)和情感得分两个字段。
在餐厅层面,系统会统计该餐厅所有评论的情感分布,计算正面评论数量、负面评论数量和中性评论数量,进而得出正面评论比例、负面评论比例和中性评论比例。这些统计数据被存储在Restaurant模型中,用于餐厅的综合评价和推荐算法的特征计算。情感分析结果也会在数据可视化模块中以饼图形式展示,让用户直观了解某家餐厅的整体口碑状况。
3.4 数据可视化技术
数据可视化是将抽象的数据信息转换为可视化图形的过程,通过图表的方式能够更加直观、高效地传达数据背后的信息和规律。本系统采用ECharts作为主要的数据可视化工具,ECharts是百度开源的一个基于JavaScript的图表库,提供了丰富的图表类型和强大的配置能力,在Web应用中被广泛使用。
系统使用了多种类型的图表来展示不同维度的分析结果。饼图用于展示情感分析的统计分布,通过不同颜色的扇形区域直观显示正面、负面、中性评论各自占据的比例。饼图的配置包括标题设置、图例位置、扇形颜色方案、数据标签显示等选项。系统为三种情感类别分配了视觉上易于区分的颜色:绿色代表正面、红色代表负面、灰色代表中性,这种颜色选择符合人们的认知习惯。当用户将鼠标悬停在某个扇形区域上时,会显示该类别的详细数值和百分比,增强了图表的交互性。
雷达图被用来展示餐厅在多个维度上的综合表现。雷达图由多个从中心向外辐射的坐标轴组成,每个轴代表一个评价维度,坐标轴上的数值表示该维度的评分。系统的雷达图包含口味、环境、服务、价格四个维度,通过连接各轴上的数据点形成一个多边形区域,多边形的形状和大小直观反映了餐厅的特征。用户可以通过雷达图快速判断一家餐厅的优势和劣势,例如,如果口味轴上的数值明显大于其他轴,说明这家餐厅的口味是其最大亮点。雷达图还支持多个餐厅的对比展示,通过不同颜色的多边形叠加,可以直观比较多家餐厅在各维度上的差异。
柱状图在系统中主要用于展示价格分析和餐厅排行榜。价格分析柱状图的横轴表示不同的价格区间,纵轴表示该价格区间的餐厅数量,每个柱子的高度直观显示了分布情况。通过这个图表,用户可以了解数据集中餐厅的价格分布特征,找到最常见的消费水平。餐厅排行榜使用横向柱状图,每个柱子代表一家餐厅,柱子长度表示评分高低,餐厅按照评分从高到低排序展示,形成一个清晰的排名列表。柱状图的每个柱子上还会标注具体的数值,方便用户准确读取数据。
在技术实现上,ECharts采用配置项的方式来定义图表。开发者需要准备好数据,然后构造一个包含title、tooltip、legend、series等属性的配置对象,调用ECharts的初始化方法创建图表实例,最后使用setOption方法将配置应用到图表上。本系统采用了前后端分离的数据交互模式,Django后端负责数据的查询和计算,将结果以JSON格式返回给前端,前端JavaScript代码接收JSON数据后,动态构建ECharts配置对象并渲染图表。这种方式使得数据处理逻辑和可视化展示逻辑分离,代码结构更加清晰,也便于后续的维护和扩展。
系统还实现了图表的响应式设计,当浏览器窗口大小改变时,图表会自动调整尺寸以适应新的容器大小。ECharts提供了resize方法来实现这一功能,系统在window的resize事件中调用图表实例的resize方法,确保图表始终以最佳的尺寸显示。此外,系统还对图表进行了主题定制,调整了默认的配色方案、字体大小、边距等样式参数,使图表的视觉风格与整体页面设计保持一致,提升了用户体验。
3.5 MySQL数据库技术
MySQL是一个开源的关系型数据库管理系统,以其高性能、高可靠性和易用性在Web应用开发中被广泛采用。本系统选择MySQL作为数据存储方案,主要考虑到它对结构化数据的良好支持,以及与Django框架的完美集成。系统的数据库设计遵循关系型数据库的范式理论,合理划分数据表,建立表之间的关联关系,确保数据的完整性和一致性。
数据库包含三个核心数据表。User表存储用户账户信息,包括自增的主键id、唯一的用户名username、密码password、性别sex、地址address、头像文件路径avatar、个人简介textarea以及创建时间createTime等字段。用户名字段设置了唯一约束,确保不会出现重复的用户名。密码字段虽然在当前实现中是明文存储,但在实际应用中应当使用Django提供的密码哈希功能进行加密存储。头像字段使用FileField类型,支持文件上传和存储,Django会自动处理文件的保存路径和文件名生成。
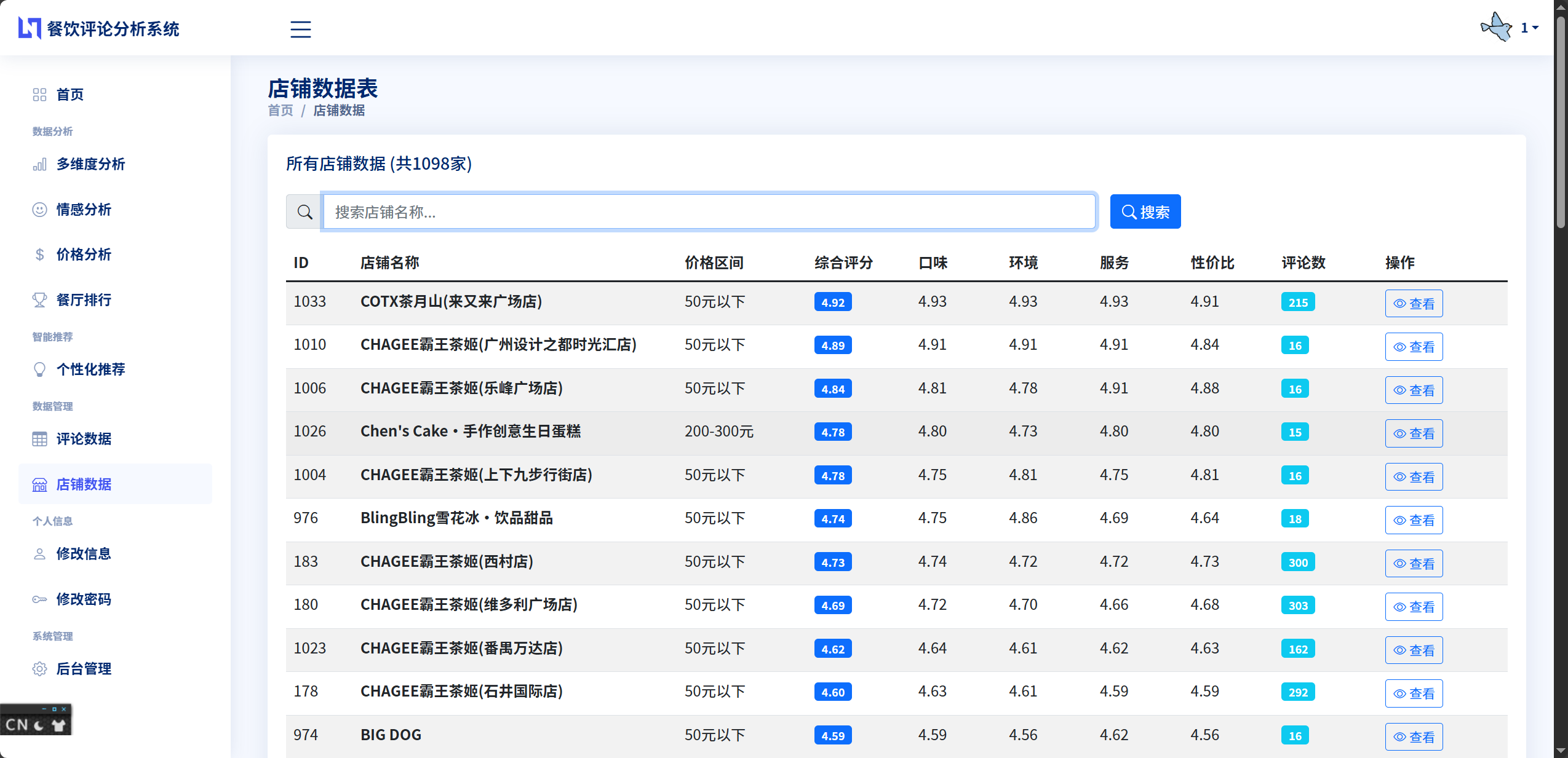
Restaurant表是系统的核心数据表之一,存储了餐厅的基本信息和统计数据。主键id采用自增方式生成,餐厅名称name字段设置了唯一约束,避免重复录入同一家餐厅。表中包含了avg_taste_score、avg_env_score、avg_service_score、avg_price_score、avg_total_score五个浮点型字段,分别存储口味、环境、服务、价格和综合评分的平均值。price_range字段使用字符串类型存储价格区间,如"50-100元"、"100-200元"等。comments_count字段记录该餐厅的评论总数,这个数值在推荐算法中用于计算热度指标。positive_rate、negative_rate、neutral_rate三个字段存储情感分析的统计结果,表示正面、负面、中性评论各自的百分比。
Comment表存储每条评论的详细信息,通过外键restaurant_id与Restaurant表建立关联。每条评论包含评论用户名username、评论详情comment_detail、评分详情score_detail等文本字段,以及taste_score、env_score、service_score、price_score四个维度的具体评分和avg_price人均消费字段。情感分析的结果存储在sentiment和sentiment_score两个字段中,前者是分类标签,后者是量化得分。Comment表与Restaurant表是一对多的关系,一个餐厅可以有多条评论,通过外键关联可以方便地查询某个餐厅的所有评论,或者通过评论反向查询所属的餐厅信息。
Django的ORM系统为数据库操作提供了优雅的Python API,开发者可以使用面向对象的方式进行数据的增删改查,而不需要编写SQL语句。例如,查询所有评分高于4.5分的餐厅可以写成Restaurant.objects.filter(avg_total_score__gte=4.5),创建新评论可以使用Comment.objects.create()方法并传入相应的字段值。ORM还支持复杂的查询操作,如聚合查询、分组统计、多表连接等,这些在系统的数据分析功能中都有应用。
数据库性能优化方面,系统为经常用于查询条件的字段建立了索引。Restaurant表的name字段、avg_total_score字段,Comment表的restaurant_id外键字段都自动创建了索引,加快了查询速度。对于大数据量的查询,系统采用了分页技术,避免一次性加载过多数据导致的内存消耗和响应延迟。Django提供了Paginator类来实现分页功能,可以方便地对查询结果集进行分页处理。此外,系统还使用了查询优化技术,如select_related和prefetch_related方法来减少数据库查询次数,避免N+1查询问题。
3.6 技术特色与创新点
本系统在技术实现上体现了多个特色和创新之处,这些特点使得系统在功能性、实用性和用户体验方面都具有一定优势。首先,系统采用了完全基于内容的推荐算法,不依赖用户的历史行为数据,有效解决了推荐系统中常见的冷启动问题。传统的协同过滤算法需要积累大量用户行为数据才能产生准确的推荐,新用户和新项目往往得不到合理的推荐结果。而本系统只需要分析餐厅本身的特征属性,就能为任何用户提供个性化推荐,这在实际应用中具有重要意义。
在情感分析方面,系统采用了针对餐饮领域定制的词典和规则,相比通用的情感分析工具,能够更准确地识别餐饮评论中的情感表达。系统不仅考虑了情感词汇本身,还充分处理了程度副词和否定词的影响,能够正确理解"非常好吃"、"不太满意"、"一点都不贵"等复杂语义。这种基于规则的方法虽然简单,但针对性强,在餐饮评论这种领域特征明显的场景下,能够取得接近甚至超过通用机器学习模型的效果,同时运行效率更高,不需要大量训练数据和计算资源。
系统的推荐算法引入了用户偏好权重的概念,允许用户自定义各评价维度的重要性,这种灵活性使得推荐结果更加个性化。不同用户对餐厅的关注点不同,有的用户认为口味是最重要的,有的用户更看重环境和氛围,还有的用户对价格敏感。系统通过加权向量相似度的计算方法,能够充分反映用户的偏好差异,提供真正符合个人需求的推荐结果。同时,系统还提供了推荐理由的自动生成功能,不仅告诉用户推荐了哪些餐厅,还解释为什么推荐这些餐厅,增强了推荐的可解释性和可信度。
在数据可视化方面,系统综合运用了多种图表类型,针对不同类型的数据选择最合适的可视化方式。情感分布使用饼图,多维度评分使用雷达图,价格分布使用柱状图,排行榜使用条形图,每种图表都充分发挥了其在数据展示上的优势。图表不仅美观,更重要的是具有良好的交互性和信息传达能力。用户通过可视化图表能够快速获取关键信息,做出决策,大大提升了使用效率和用户体验。
系统架构采用了模块化设计思想,将情感分析、推荐算法、数据可视化等功能封装成独立的模块,模块之间通过清晰的接口进行交互。这种设计使得系统具有良好的可维护性和可扩展性,当需要改进某个算法或增加新功能时,可以只修改相应的模块,不会影响其他部分。例如,如果未来想要将基于规则的情感分析升级为深度学习模型,只需要替换sentimentAnalysis.py模块的实现,而不需要修改其他代码。这种设计也便于系统的测试和调试,每个模块可以独立进行单元测试,提高了开发效率。
4 系统分析与设计
4.1 系统总体设计
4.1.1 系统架构设计
本系统采用经典的三层架构模式,将整个系统划分为表现层、业务逻辑层和数据访问层三个层次,每一层负责特定的功能,层与层之间通过明确的接口进行通信。这种分层架构的设计使得系统结构清晰、职责明确,便于开发、测试和维护。
表现层位于系统的最上层,直接面向用户,负责与用户进行交互。这一层主要由HTML模板文件和前端JavaScript代码组成,使用Django的模板引擎来渲染页面,使用Bootstrap框架提供响应式的页面布局,使用ECharts库实现数据的可视化展示。表现层接收用户的输入请求,将请求传递给业务逻辑层进行处理,然后将处理结果以友好的方式展现给用户。系统的所有页面都继承自base.html基础模板,保持了统一的页面风格和布局结构,包括顶部导航栏、侧边功能菜单、主内容区域和页脚信息等部分。
业务逻辑层是系统的核心,包含了所有的业务处理逻辑和算法实现。这一层主要由views.py视图函数文件和utils工具包组成。views.py中定义了各个功能模块的视图函数,负责处理HTTP请求、调用业务逻辑、返回响应结果。utils工具包下包含了多个功能模块:sentimentAnalysis.py实现情感分析算法,recommendationSystem.py实现推荐算法,dataAnalysis.py提供数据统计分析功能,dataPreprocessing.py负责数据清洗和预处理。业务逻辑层从数据访问层获取数据,经过处理和计算后,将结果传递给表现层进行展示。
数据访问层负责与数据库进行交互,实现数据的持久化存储和查询。这一层主要由Django的ORM系统和models.py数据模型文件组成。models.py中定义了User、Restaurant、Comment三个数据模型类,Django的ORM会自动将这些模型映射为数据库表,并提供丰富的查询API。业务逻辑层通过调用ORM提供的方法来实现数据的增删改查操作,而不需要直接编写SQL语句,这大大提高了开发效率并减少了SQL注入等安全风险。数据访问层还负责维护数据的完整性约束和事务一致性。
图4.1 系统架构图
数据库 数据访问层 业务逻辑层 表现层 MySQL数据库 Django ORM User模型 Restaurant模型 Comment模型 用户认证视图 数据分析视图 情感分析模块 推荐算法模块 数据可视化处理 数据统计工具 登录注册页面 系统首页 数据分析页面 情感分析页面 推荐功能页面 餐厅详情页面 评论浏览页面
系统还采用了MTV(Model-Template-View)设计模式,这是Django框架所提倡的架构模式。Model层对应数据模型,负责数据的定义和操作;Template层对应模板文件,负责页面的展示;View层对应视图函数,负责业务逻辑的处理,起到连接Model和Template的桥梁作用。这种模式实现了数据、业务逻辑和页面展示的分离,使得系统的各个部分可以独立开发和测试,提高了开发效率和代码质量。
4.1.2 系统数据流设计
系统的数据流动贯穿整个应用的运行过程,从用户发起请求开始,经过数据的获取、处理、分析,最后将结果展示给用户。理解系统的数据流对于把握系统的运行机制至关重要。
用户通过浏览器访问系统时,首先会被重定向到登录页面。用户输入用户名和密码后提交表单,浏览器将登录请求发送到Django服务器。服务器接收到请求后,视图函数从POST数据中提取用户名和密码,通过ORM查询数据库验证用户身份。如果验证成功,系统将用户名存储到session中,建立用户的登录状态,然后重定向到系统首页;如果验证失败,则返回错误提示页面。这个过程中,数据从用户输入流向服务器,经过数据库查询验证,最后返回响应结果。
在数据分析功能中,数据流动更加复杂。当用户访问情感分析页面时,视图函数需要从数据库中查询餐厅和评论数据,调用情感分析模块对评论进行处理,统计各类情感的数量和比例,然后将统计结果转换为JSON格式传递给前端。前端JavaScript代码接收JSON数据后,使用ECharts库构建饼图配置对象,渲染出可视化图表。整个过程中,原始的评论文本数据经过情感分析转化为情感标签,再经过统计汇总转化为数值数据,最后通过可视化转化为图形展示,数据在不同形态间转换,最终以用户易于理解的方式呈现。
推荐功能的数据流同样值得关注。用户在推荐页面设置偏好参数后提交表单,这些参数被发送到服务器。视图函数接收参数后,从数据库查询所有餐厅的特征数据,包括各维度评分、价格区间、好评率等信息。推荐算法模块根据用户偏好构建虚拟餐厅画像,然后遍历所有真实餐厅,计算每个餐厅与虚拟画像的相似度。计算过程中,餐厅的特征数据被转换为向量形式,通过余弦相似度公式进行数值计算,得到相似度分数。所有餐厅按相似度排序后,取前N个作为推荐结果,连同餐厅的详细信息一起返回给前端展示。这个流程体现了从用户偏好输入,到特征提取和向量计算,再到推荐结果输出的完整数据流。
图4.2 系统数据流图
否 成功 失败 是 数据分析 情感分析 智能推荐 用户访问系统 是否登录 登录页面 输入用户名密码 验证用户身份 建立Session 显示错误 系统首页 选择功能 查询餐厅数据 统计分析 生成图表 展示结果 查询评论数据 执行情感分析 计算情感统计 展示情感分布 设置偏好参数 加载餐厅特征 计算相似度 排序推荐结果 展示推荐列表 结束
4.1.3 系统功能模块设计
系统的功能模块设计采用模块化思想,将整个系统划分为多个相对独立的功能模块,每个模块负责特定的业务功能,模块之间通过接口进行协作。
用户管理模块是系统的基础模块,提供用户注册、登录、个人信息管理、密码修改等功能。该模块确保只有经过认证的用户才能访问系统的核心功能,维护系统的安全性。用户可以上传个人头像、修改基本信息,系统会将这些信息持久化存储到数据库中。
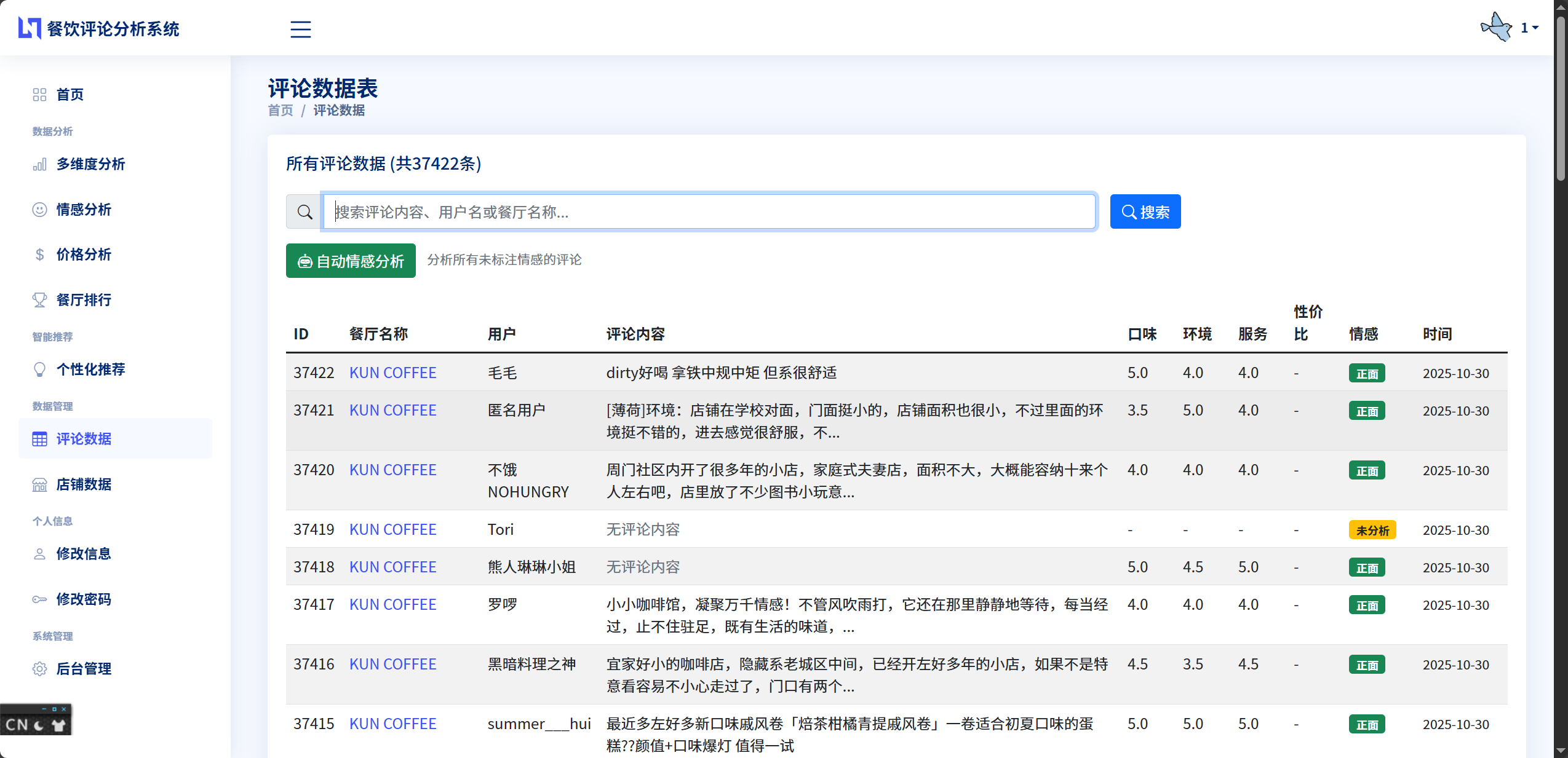
评论数据管理模块负责评论数据的导入、存储和查询。系统通过专门的数据导入脚本将CSV格式的评论数据批量导入到数据库中,在导入过程中进行数据清洗,包括去除重复数据、处理缺失值、标准化数据格式等操作。该模块还提供评论数据的浏览和搜索功能,用户可以按餐厅名称查询相关评论,查看评论的详细内容和评分信息。
情感分析模块是系统的核心功能模块之一,采用基于词典和规则的方法对评论文本进行情感倾向判断。该模块内置了餐饮领域的情感词典,包括正面词、负面词、程度副词和否定词。分析算法通过扫描评论文本,识别其中的情感词汇,考虑程度修饰和否定反转,计算情感得分,最终判定情感类别。模块不仅对单条评论进行分析,还会统计餐厅层面的情感分布,计算正面评论率等指标。
多维度数据分析模块提供餐厅评价数据的多角度统计分析功能。该模块从口味、环境、服务、价格四个维度对餐厅进行评分分析,计算各维度的平均分和分布情况。模块还提供价格区间分析功能,统计不同价格段的餐厅数量,帮助用户了解市场价格分布。此外,模块还能生成各类排行榜,包括综合评分排行、单项评分排行、热门餐厅排行等。
智能推荐模块实现了基于内容的餐厅推荐算法。该模块为每个餐厅构建多维特征向量,通过计算向量间的余弦相似度来衡量餐厅之间的相似程度。模块支持两种推荐模式:一是基于用户偏好的个性化推荐,用户可以设置各维度的重视程度,系统找出最符合偏好的餐厅;二是基于餐厅相似度的关联推荐,当用户浏览某家餐厅时,系统自动推荐相似的其他餐厅。推荐结果还会附带推荐理由说明,增强可解释性。
数据可视化模块负责将分析结果以图表形式直观展示。该模块集成了ECharts图表库,根据不同的数据类型选择合适的图表样式。情感分析结果使用饼图展示,清晰显示各类情感的占比;多维度评分使用雷达图展示,直观反映餐厅在各方面的表现;价格分析使用柱状图展示,显示价格分布情况;排行榜使用条形图展示,清晰呈现排名信息。所有图表都支持交互操作,提升用户体验。
图4.3 系统功能模块结构图
数据可视化模块 智能推荐模块 多维度分析模块 情感分析模块 评论数据管理模块 用户管理模块 餐饮评论分析与推荐系统 饼图展示 雷达图展示 柱状图展示 排行图展示 特征提取 相似度计算 偏好推荐 关联推荐 评分统计 价格分析 排行榜生成 综合评价 情感词典 文本分析 情感判定 统计汇总 数据导入 数据清洗 评论查询 数据浏览 用户注册 用户登录 个人信息管理 密码修改 用户管理模块 评论数据管理模块 情感分析模块 多维度分析模块 智能推荐模块 数据可视化模块
4.2 系统详细设计
4.2.1 用户管理模块设计
用户管理模块的设计目标是提供完整的用户账户管理功能,确保系统的安全性和用户体验。该模块采用Session机制来管理用户的登录状态,当用户成功登录后,系统会在服务器端创建一个Session对象,并将用户名等关键信息存储其中,同时向客户端浏览器发送一个包含Session ID的Cookie。后续的请求都会携带这个Cookie,服务器通过Cookie中的Session ID来识别用户身份,实现登录状态的维持。
用户注册流程设计考虑了数据的完整性和安全性。用户首先在注册页面填写用户名、密码和确认密码,点击提交后,系统会进行一系列校验:检查用户名是否为空,检查密码是否为空,检查两次输入的密码是否一致,查询数据库验证用户名是否已存在。所有校验都通过后,系统才会创建新的用户记录,将用户信息写入数据库,并重定向到登录页面提示用户注册成功。这种多重校验机制有效防止了无效数据的录入。
用户登录过程同样严谨。系统接收用户提交的用户名和密码后,使用ORM查询数据库,尝试找到同时匹配用户名和密码的用户记录。如果查询成功,说明用户身份验证通过,系统将用户名存入Session,然后重定向到系统首页;如果查询失败,说明用户名不存在或密码错误,系统会返回友好的错误提示页面,告知用户登录失败的原因。为了提升安全性,虽然当前实现使用明文密码,但在生产环境中应该使用Django提供的密码哈希功能对密码进行加密存储。
个人信息管理功能允许用户查看和修改自己的资料。用户访问个人信息页面时,系统从Session中获取当前登录用户的用户名,然后查询数据库获取该用户的完整信息,包括性别、地址、头像、个人简介等,将这些信息填充到表单中展示给用户。用户修改信息后提交表单,系统接收POST数据,更新数据库中对应的用户记录。特别地,头像上传功能使用Django的FileField,系统会自动处理文件的上传、存储和路径管理,将文件保存到media/avatar目录下,并在数据库中记录文件路径。
密码修改功能增加了额外的安全措施。用户需要先输入当前密码,然后输入新密码和确认新密码。系统首先验证当前密码是否正确,确保不是他人冒用;然后检查新密码和确认新密码是否一致,避免用户输入错误;所有验证通过后,才会更新数据库中的密码字段。这种设计有效保护了用户账户的安全,防止密码被随意修改。
4.2.2 评论数据管理模块设计
评论数据管理模块负责处理系统的数据来源,确保数据的质量和可用性。该模块的核心任务是将外部的CSV格式评论数据导入到系统数据库中,并在导入过程中进行必要的数据清洗和格式转换。
数据导入设计采用Django的management命令机制实现。系统提供了import_data.py和clean_comments.py两个自定义命令,管理员可以通过命令行执行这些命令来批量导入数据。导入流程首先读取CSV文件,使用Python的csv模块逐行解析文件内容。对于每一行数据,系统会提取餐厅名称、评论内容、各维度评分、人均消费等字段信息。
数据清洗是保证数据质量的关键环节。系统在导入过程中会检测并处理多种数据质量问题。对于餐厅数据,系统会检查餐厅名称是否为空,如果餐厅在数据库中不存在,则创建新的Restaurant记录;如果已存在,则直接使用现有记录。对于评分数据,系统会将字符串形式的评分转换为浮点数,如果转换失败则使用默认值0。对于评论文本,系统会去除首尾空白字符,检查文本长度是否合理。
餐厅统计信息的计算是数据管理模块的重要功能。当所有评论导入完成后,系统会遍历每个餐厅,统计该餐厅的评论数量,计算各维度评分的平均值,包括口味、环境、服务、价格和综合评分。系统还会根据人均消费金额将餐厅划分到不同的价格区间,如"50元以下"、"50-100元"、"100-200元"等。这些统计数据被更新到Restaurant表中,为后续的分析和推荐提供基础数据。
情感分析的批量处理也集成在数据管理流程中。clean_comments命令会遍历所有评论记录,调用情感分析模块对每条评论的文本内容进行分析,判断情感倾向并计算情感得分,然后将分析结果更新到Comment表的sentiment和sentiment_score字段中。完成单条评论的情感分析后,系统还会在餐厅层面进行统计,计算每个餐厅的正面评论数、负面评论数和中性评论数,进而得出各类情感的占比,将这些统计结果存储到Restaurant表中。
评论查询和浏览功能为用户提供了方便的数据访问接口。用户可以访问评论浏览页面,系统会从数据库查询评论数据并分页展示。用户可以通过餐厅名称进行搜索过滤,系统会使用Django ORM的filter方法构造查询条件,只返回匹配的评论记录。餐厅详情页面会展示该餐厅的所有评论,以及餐厅的统计信息和多维度评分雷达图,让用户全面了解餐厅情况。
4.2.3 情感分析模块设计
情感分析模块的设计基于词典匹配和规则推理的方法,这种方法的优势在于不需要大量标注数据进行训练,实现相对简单,运行效率高,对于餐饮评论这种领域特征明显的文本,能够取得较好的分析效果。
情感词典的构建是该模块的基础工作。系统定义了四个主要的词典:正面词汇列表包含约40个常用的表达正面情感的词语,涵盖了味道好、价格实惠、环境舒适、服务热情等多个方面;负面词汇列表同样包含约40个负面词语,如味道差、价格贵、环境脏乱、服务态度差等;程度副词词典记录了常用的程度修饰词及其对应的强度系数,如"非常"、"特别"对应2.0倍,"很"对应1.5倍,"比较"对应1.2倍,"有点"对应0.8倍等;否定词列表包含"不"、"没"、"无"等常见否定词。这些词典都以Python列表或字典的形式定义在sentimentAnalysis.py文件中,便于维护和扩展。
情感分析算法采用逐字扫描的策略。算法从评论文本的开头开始,使用一个循环逐个检查后续的字符序列。对于每个位置,算法会尝试匹配词典中的各类词语。匹配过程按照一定的优先级进行:首先检查是否匹配到情感词(正面或负面),如果匹配成功,记录当前位置;然后向前查找,检查情感词前面是否有程度副词,如果有则应用对应的强度系数;继续向前查找,检查是否有否定词,如果有则进行极性反转。通过这种前向扫描和回溯的方式,算法能够正确处理"非常好吃"、"不太满意"、"一点都不贵"等各种复杂的语言表达。
情感得分的计算规则经过精心设计。每个正面词的基础分值为1分,每个负面词的基础分值为-1分。当检测到程度副词时,分值会乘以对应的系数,例如"非常好吃"的得分为1×2.0=2.0分。当检测到否定词时,情感极性反转,正面词变负面,负面词变正面,例如"不好吃"的得分为-1×1=-1分,而"不贵"(贵是负面词)的得分为-(-1)=1分。一条评论的总得分是所有识别到的情感词得分的累加和。
情感类别的判定基于总得分的大小。系统设定了两个阈值:正阈值通常为0.5,负阈值通常为-0.5。如果总得分大于正阈值,判定为正面评价(positive);如果总得分小于负阈值,判定为负面评价(negative);如果总得分在两个阈值之间,判定为中性评价(neutral)。这种三分类的设计能够区分明显的正面、负面和模糊的中性评论。情感得分本身也会作为量化指标存储,数值越大表示情感越积极,数值越小表示情感越消极。
餐厅层面的情感统计通过聚合计算实现。系统会查询某个餐厅的所有评论,分别统计sentiment字段为positive、negative、neutral的评论数量,然后除以总评论数得到各类情感的占比。这些统计结果帮助用户快速了解一家餐厅的整体口碑状况,如果正面评论率很高,说明这家餐厅总体评价好;如果负面评论率较高,则说明存在一些问题需要注意。
4.2.4 多维度数据分析模块设计
多维度数据分析模块旨在从多个角度对餐厅数据进行深入挖掘,为用户提供全面的决策参考信息。该模块的设计充分考虑了餐饮领域的业务特点,选择了最具代表性的分析维度。
评分维度分析是该模块的核心功能之一。系统从口味、环境、服务、价格四个维度对餐厅进行评价分析。每个维度都基于用户评论中的实际打分数据,通过计算平均值得到餐厅在该维度上的综合评分。系统还会计算综合评分,通常是四个维度评分的算术平均值,作为餐厅的总体评价指标。这种多维度的评价体系能够细致刻画餐厅的特点,用户可以根据自己最关心的维度来选择餐厅,例如注重口味的用户可以优先查看口味评分高的餐厅,注重性价比的用户可以关注价格评分高的餐厅。
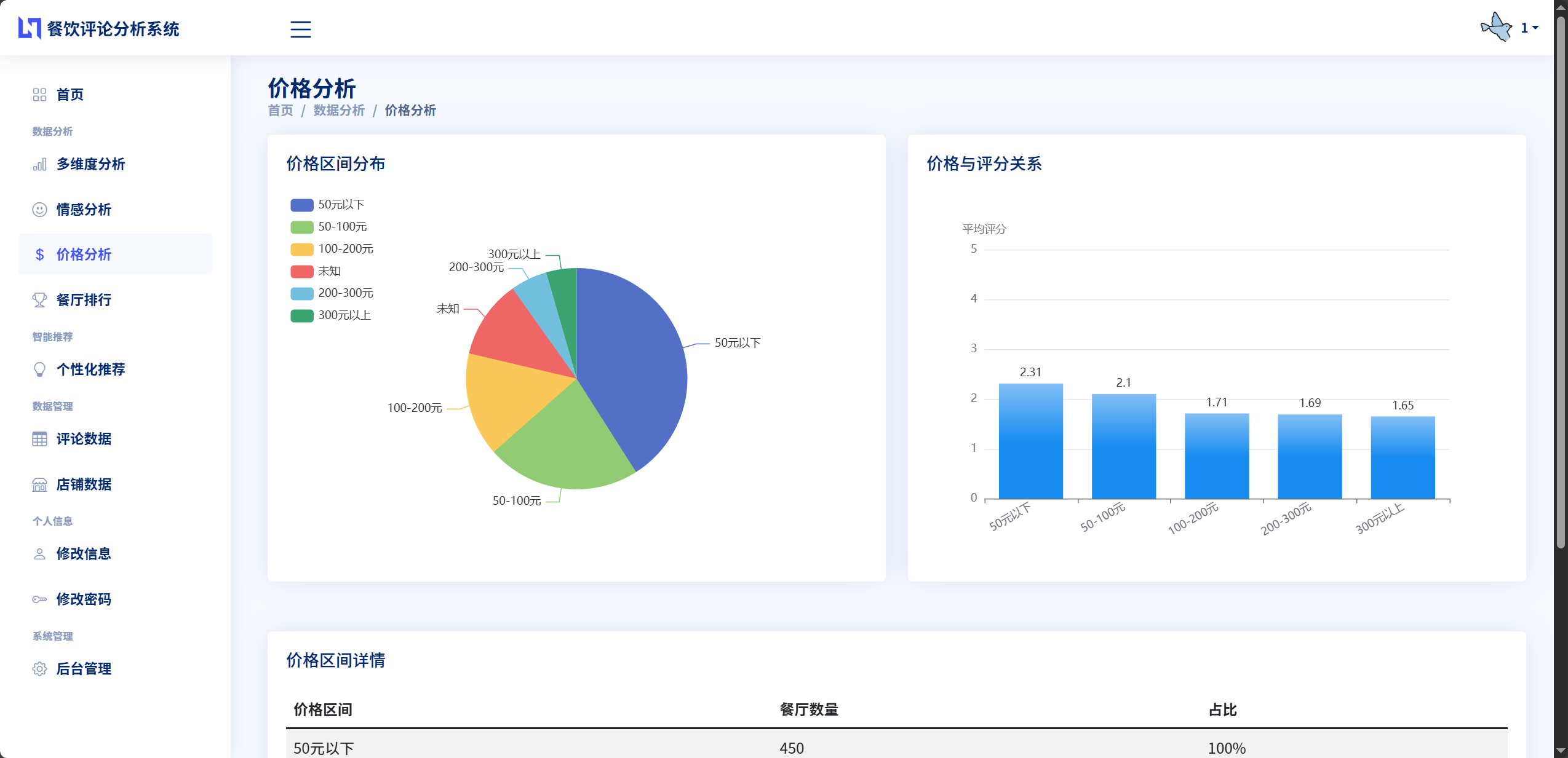
价格分析功能帮助用户了解餐厅的消费水平分布。系统根据人均消费金额将餐厅划分为几个价格区间:"50元以下"、"50-100元"、"100-200元"、"200-300元"、"300元以上"等。对于每个餐厅,系统会根据其评论中的平均消费金额,判定其所属的价格区间,并将结果存储在price_range字段中。在价格分析页面,系统会统计每个价格区间包含的餐厅数量,并以柱状图的形式展示价格分布情况。用户可以通过这个分析快速了解哪个价格段的餐厅最多,从而根据自己的预算来筛选合适的餐厅。
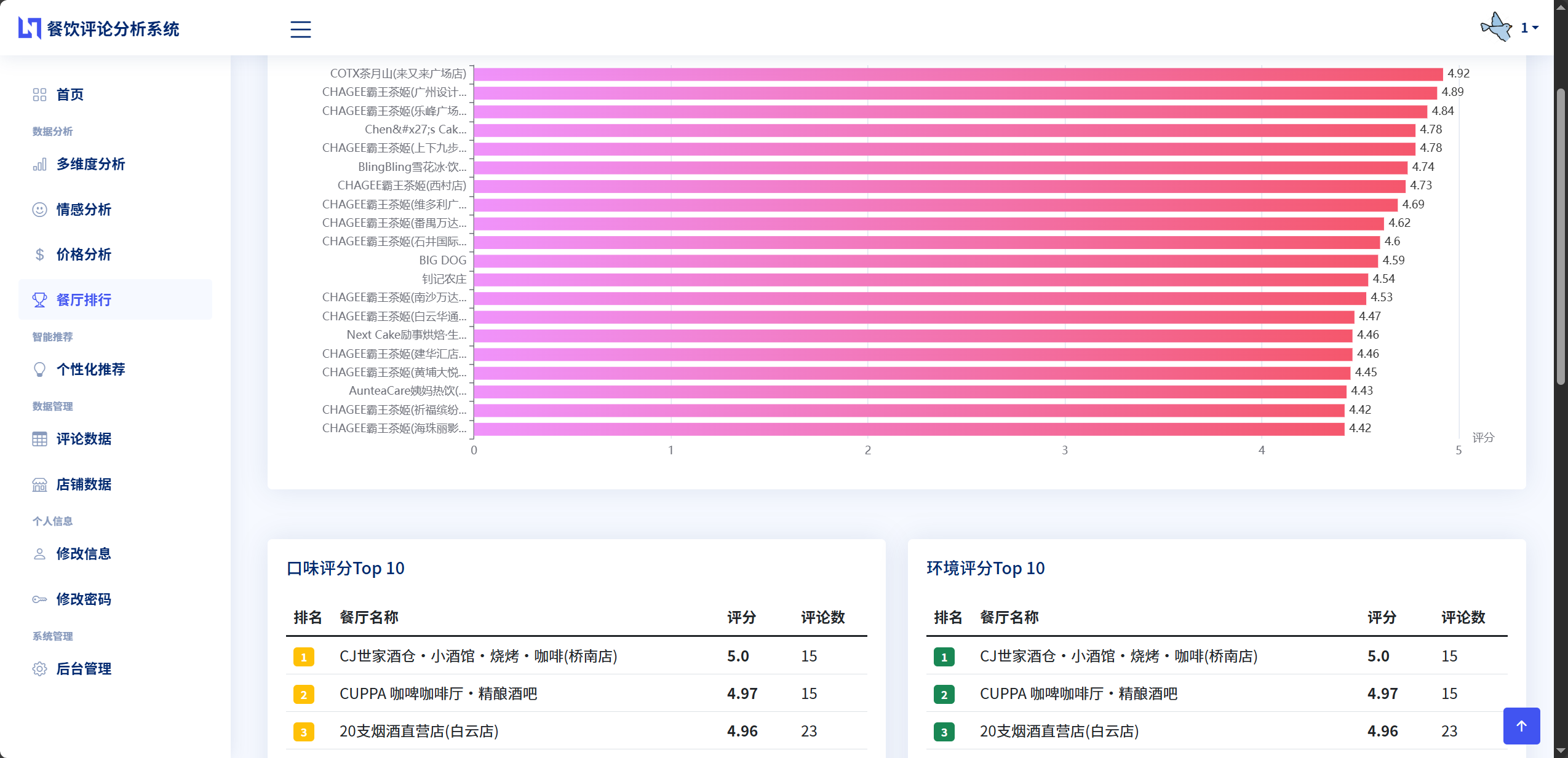
排行榜生成功能满足了用户快速找到优质餐厅的需求。系统支持多种排行维度:综合评分排行榜展示avg_total_score最高的餐厅,口味排行榜展示avg_taste_score最高的餐厅,环境排行榜展示avg_env_score最高的餐厅,服务排行榜展示avg_service_score最高的餐厅,性价比排行榜展示avg_price_score最高的餐厅。此外,系统还可以按评论数量排序,生成热门餐厅排行榜,评论数多的餐厅通常意味着更高的知名度和受欢迎程度。排行榜的实现使用Django ORM的order_by方法对查询结果进行排序,取前N名展示给用户。
综合评价功能将多个维度的信息整合在一起,提供餐厅的全景视图。在餐厅详情页面,系统不仅展示餐厅的基本信息如名称、价格区间、评论数量,还会展示各维度的详细评分、情感分析统计结果、评分雷达图等。雷达图特别适合展示多维度数据,用户可以通过雷达图的形状快速判断餐厅的优劣势,形状越接近正多边形说明餐厅各方面表现越均衡,某个方向突出说明该维度是餐厅的亮点,某个方向凹陷说明该维度相对较弱。
数据统计工具提供了丰富的聚合计算功能。系统可以计算全局统计指标,如所有餐厅的平均评分、评分的标准差、价格区间的分布比例等。这些统计数据帮助用户了解整个数据集的总体特征,作为个体餐厅评价的参照基准。系统还支持按条件筛选和分组统计,例如可以统计某个价格区间内餐厅的平均评分,或者统计不同评分段的餐厅数量分布,这些功能的实现利用了Django ORM强大的聚合和分组查询能力。
4.2.5 智能推荐模块设计
智能推荐模块是系统的核心创新功能,采用基于内容的推荐算法为用户提供个性化的餐厅推荐服务。该模块的设计充分考虑了推荐系统的准确性、可解释性和个性化需求。
特征提取是推荐算法的第一步。系统为每个餐厅构建一个RestaurantProfile特征画像对象,这个对象包含了餐厅的多个特征属性。核心特征包括四个维度的评分:taste_score口味评分、env_score环境评分、service_score服务评分、price_score价格评分,这些评分直接从Restaurant模型中读取。价格区间特征price_range_value通过映射函数将文本形式的价格区间转换为数值,便于参与数学计算。情感特征positive_rate表示餐厅的正面评论比例,反映了餐厅的整体口碑。热度特征popularity基于评论数量的对数值计算,既体现了餐厅的受欢迎程度,又通过对数变换避免了数值过大导致的特征失衡。
特征向量的构建将上述特征组织成一个数值向量。系统定义了to_vector方法,该方法返回一个包含7个元素的列表,依次为口味评分、环境评分、服务评分、价格评分、价格区间数值、归一化后的正面评论率(除以100)、归一化后的热度值(除以10)。归一化处理确保各特征的数值范围相近,避免某个特征因为数值过大而主导相似度计算结果。这个向量是推荐算法进行相似度计算的基础。
余弦相似度计算是推荐算法的核心。给定两个餐厅的特征向量,系统使用calculate_cosine_similarity函数计算它们的余弦相似度。计算过程分三步:首先计算点积,即两个向量对应位置元素的乘积之和;然后分别计算两个向量的模长,即各元素平方和的平方根;最后用点积除以两个模长的乘积,得到余弦相似度值。余弦相似度的取值范围在-1到1之间,值越大表示两个向量的方向越接近,即两个餐厅越相似。
加权相似度计算增强了推荐的个性化能力。系统实现了calculate_weighted_similarity函数,该函数接受两个特征画像和一个权重向量作为参数。权重向量为每个特征维度分配一个权重值,默认权重为0.25, 0.20, 0.15, 0.15, 0.10, 0.10, 0.05,分别对应口味、环境、服务、价格、价格区间、好评率、热度七个维度。计算时,先将每个特征向量的元素乘以对应的权重,得到加权向量,然后计算加权向量之间的余弦相似度。用户可以通过调整权重来表达自己的偏好,例如将口味的权重设为0.5,将环境的权重设为0.1,系统就会更加重视口味相似度而较少考虑环境相似度。
基于用户偏好的推荐流程设计如下:用户在推荐页面设置偏好参数,包括各维度的重要性评分(1-5分)、期望的价格区间、最低评分要求等。系统首先根据这些参数构建一个虚拟的"理想餐厅"画像,该画像的各维度评分由用户设定的重要性评分归一化而来。然后,系统查询数据库获取所有满足基本条件的餐厅,对每个餐厅计算其特征画像与虚拟画像的加权相似度。所有餐厅按相似度从高到低排序,取前N个作为推荐结果返回给用户。推荐结果不仅包含餐厅的基本信息和评分,还会自动生成推荐理由,如"综合评分高达4.8分"、"与您的偏好匹配度92%"等,帮助用户理解推荐依据。
基于餐厅相似度的推荐提供了另一种推荐模式。当用户浏览某家餐厅的详情页面时,系统会自动找出与该餐厅最相似的其他餐厅推荐给用户。实现方法是:获取当前餐厅的特征画像,查询数据库中的其他餐厅,计算每个餐厅与当前餐厅的相似度,按相似度排序后取前N个展示。这种推荐模式特别适合"用户喜欢A餐厅,可能也会喜欢B餐厅"的场景,帮助用户发现更多符合口味的选择。
4.2.6 数据可视化模块设计
数据可视化模块的设计目标是将复杂的数据分析结果以直观、美观的图表形式呈现给用户,降低用户理解数据的难度,提升决策效率。该模块充分利用了ECharts图表库的强大功能,为不同类型的数据选择了最合适的可视化方式。
饼图用于展示情感分析的分类统计结果。系统的情感分析将评论分为正面、负面、中性三类,饼图通过不同颜色的扇形区域和相应的面积大小来表示各类情感的占比。饼图配置包括标题设置、图例位置、颜色方案、数据标签等选项。系统为三类情感分配了具有明确指示意义的颜色:绿色(#5AB58F)表示正面,红色(#FF6B6B)表示负面,灰色(#CCCCCC)表示中性。饼图支持hover交互,当用户将鼠标悬停在某个扇形区域上时,会显示该类别的名称、数量和百分比。通过饼图,用户可以一眼看出某家餐厅的正面评价是否占主导地位,从而快速判断餐厅的整体口碑。
雷达图用于展示餐厅的多维度评分情况。雷达图由多个从中心点向外辐射的坐标轴组成,每个轴代表一个评价维度,系统的雷达图包含口味、环境、服务、价格四个维度。每个轴的刻度通常设为0-5分,对应五分制评价体系。餐厅在各维度上的评分对应轴上的一个点,连接所有点形成一个多边形区域。雷达图的形状直观反映了餐厅的特征:多边形越大说明整体评分越高,形状越接近正方形说明各维度表现越均衡,某个方向特别突出说明该维度是餐厅的优势。雷达图还支持多个餐厅的对比展示,通过不同颜色的多边形叠加,用户可以直观比较多家餐厅在各维度上的差异。
柱状图在系统中主要用于两个场景。第一个场景是价格分析,横轴表示不同的价格区间,纵轴表示该价格区间的餐厅数量。每个价格区间对应一个柱子,柱子的高度反映了餐厅数量的多少。通过这个图表,用户可以快速了解数据集中各价格段餐厅的分布情况,找到最常见的消费水平,为自己的选择提供参考。第二个场景是餐厅排行榜,使用横向柱状图展示,每家餐厅对应一个柱子,柱子的长度表示评分或评论数量,餐厅按照指标值从高到低排序。柱状图上还会标注具体的数值,方便用户准确读取数据。
图表的数据交互采用前后端分离的设计模式。后端Django视图负责从数据库查询原始数据,进行必要的统计计算和格式转换,最后将结果以JSON格式返回给前端。前端JavaScript代码通过Ajax请求获取JSON数据,解析后构建ECharts的配置对象,调用echarts.init和setOption方法来渲染图表。这种设计使得数据处理和可视化展示的职责分离,后端专注于业务逻辑,前端专注于用户界面,提高了代码的可维护性。
图表的响应式设计确保了在不同屏幕尺寸下都能良好显示。系统监听浏览器窗口的resize事件,当窗口大小改变时,调用图表实例的resize方法重新计算图表尺寸。同时,图表容器使用百分比宽度而非固定像素值,能够自适应父容器的大小。这种设计使得图表在桌面电脑、笔记本甚至平板设备上都能正常显示,提升了系统的兼容性和用户体验。
4.3 数据库设计
4.3.1 数据库关系设计
数据库设计是系统的基础,合理的数据库结构能够高效地存储和查询数据,支撑业务逻辑的实现。本系统的数据库设计遵循关系型数据库的范式理论,主要达到第三范式,既保证了数据的规范性,又考虑了查询效率。
系统包含三个核心数据表:User用户表、Restaurant餐厅表和Comment评论表。这三个表通过外键关联建立起数据之间的联系,形成了完整的数据模型。User表和Comment表之间没有直接的外键关联,因为评论数据来自外部导入,评论用户名只是一个文本字段,并不对应系统的注册用户。Restaurant表和Comment表之间是一对多的关系,一个餐厅可以有多条评论,通过restaurant_id外键字段建立关联。
图4.5 数据库关系图
表4.1 User用户表结构
| 字段名称 | 字段类型 | 字段说明 | 是否主键 | 是否为空 | 其他约束 |
|---|---|---|---|---|---|
| id | int | 用户唯一标识符 | 是 | 否 | 自增 |
| username | varchar(255) | 用户名 | 否 | 否 | 唯一 |
| password | varchar(255) | 密码 | 否 | 否 | - |
| sex | varchar(255) | 性别 | 否 | 是 | 默认空字符串 |
| address | varchar(255) | 地址 | 否 | 是 | 默认空字符串 |
| avatar | varchar(100) | 头像文件路径 | 否 | 是 | 默认avatar/default.png |
| textarea | varchar(255) | 个人简介 | 否 | 是 | 默认值 |
| createTime | datetime | 创建时间 | 否 | 否 | 自动添加 |
User表存储系统注册用户的基本信息。id字段作为主键,采用自增方式自动生成唯一标识。username字段设置了唯一约束,确保用户名不会重复,这是用户身份识别的关键字段。password字段存储用户密码,在生产环境中应该存储加密后的密码哈希值而非明文。sex和address字段存储用户的性别和地址信息,这些是可选填写的个人资料。avatar字段是FileField类型,存储用户头像图片的文件路径,Django会自动处理文件上传和存储,默认使用系统提供的默认头像。textarea字段存储用户的个人简介,给用户一个展示自己的空间。createTime字段记录用户注册时间,设置为auto_now_add=True,在创建记录时自动填充当前时间。
表4.2 Restaurant餐厅表结构
| 字段名称 | 字段类型 | 字段说明 | 是否主键 | 是否为空 | 其他约束 |
|---|---|---|---|---|---|
| id | int | 餐厅唯一标识符 | 是 | 否 | 自增 |
| name | varchar(255) | 餐厅名称 | 否 | 否 | 唯一 |
| avg_taste_score | float | 平均口味评分 | 否 | 否 | 默认0 |
| avg_env_score | float | 平均环境评分 | 否 | 否 | 默认0 |
| avg_service_score | float | 平均服务评分 | 否 | 否 | 默认0 |
| avg_price_score | float | 平均价格评分 | 否 | 否 | 默认0 |
| avg_total_score | float | 平均综合评分 | 否 | 否 | 默认0 |
| price_range | varchar(100) | 人均价格区间 | 否 | 是 | 默认空字符串 |
| comments_count | int | 评论数量 | 否 | 否 | 默认0 |
| positive_rate | float | 正面评论比例 | 否 | 否 | 默认0 |
| negative_rate | float | 负面评论比例 | 否 | 否 | 默认0 |
| neutral_rate | float | 中性评论比例 | 否 | 否 | 默认0 |
| createTime | datetime | 创建时间 | 否 | 否 | 自动添加 |
Restaurant表是系统的核心数据表之一,存储餐厅的基本信息和统计数据。id字段作为主键唯一标识每个餐厅,name字段存储餐厅名称并设置了唯一约束,保证不会重复录入同一家餐厅。五个评分字段avg_taste_score、avg_env_score、avg_service_score、avg_price_score、avg_total_score分别存储口味、环境、服务、价格和综合维度的平均评分,这些数值是根据该餐厅所有评论的评分计算得出的,为推荐算法提供了核心特征数据。price_range字段存储价格区间分类,如"50-100元"、"100-200元"等,便于用户按预算筛选餐厅。comments_count字段记录该餐厅的评论总数,这个数值不仅反映了餐厅的热度,还在推荐算法中作为热度特征参与计算。positive_rate、negative_rate、neutral_rate三个字段存储情感分析的统计结果,以百分比形式表示各类情感评论的占比,让用户快速了解餐厅的整体口碑。
表4.3 Comment评论表结构
| 字段名称 | 字段类型 | 字段说明 | 是否主键 | 是否为空 | 其他约束 |
|---|---|---|---|---|---|
| id | int | 评论唯一标识符 | 是 | 否 | 自增 |
| restaurant_id | int | 所属餐厅ID | 否 | 否 | 外键 |
| username | varchar(255) | 评论用户名 | 否 | 是 | 默认"匿名用户" |
| comment_detail | text | 评论详细内容 | 否 | 是 | 默认空字符串 |
| score_detail | varchar(500) | 评分详细描述 | 否 | 是 | 默认空字符串 |
| taste_score | float | 口味评分 | 否 | 否 | 默认0 |
| env_score | float | 环境评分 | 否 | 否 | 默认0 |
| service_score | float | 服务评分 | 否 | 否 | 默认0 |
| price_score | float | 性价比评分 | 否 | 否 | 默认0 |
| avg_price | float | 人均消费 | 否 | 否 | 默认0 |
| sentiment | varchar(20) | 情感倾向标签 | 否 | 是 | positive/negative/neutral |
| sentiment_score | float | 情感量化得分 | 否 | 否 | -1到1之间 |
| createTime | datetime | 创建时间 | 否 | 否 | 自动添加 |
Comment表存储用户对餐厅的评论信息,是系统数据分析的原始素材。id字段作为主键唯一标识每条评论,restaurant_id字段是外键,指向Restaurant表的id字段,建立了评论与餐厅之间的关联关系,通过这个外键可以查询某个餐厅的所有评论,或者通过评论找到所属的餐厅。username字段存储评论用户的名称,需要注意这个字段不是外键,因为评论数据来自外部导入,评论用户并不是系统的注册用户。comment_detail字段使用text类型存储评论的详细文本内容,这是情感分析的输入数据。score_detail字段存储原始的评分描述信息。
四个评分字段taste_score、env_score、service_score、price_score分别记录该条评论对口味、环境、服务、价格的打分,这些数值会被用来计算餐厅各维度的平均评分。avg_price字段记录该次消费的人均金额,用于分析餐厅的价格区间。sentiment和sentiment_score两个字段存储情感分析的结果,sentiment是分类标签,取值为"positive"、"negative"或"neutral",sentiment_score是情感的量化得分,取值范围在-1到1之间,正值表示正面情感,负值表示负面情感,绝对值大小表示情感强度。
数据库的索引设计对查询性能至关重要。系统为几个关键字段建立了索引:User表的username字段、Restaurant表的name字段都设置了唯一索引,既保证了数据唯一性,又加快了按用户名或餐厅名查询的速度。Restaurant表的avg_total_score等评分字段经常用于排序和范围查询,也会建立索引。Comment表的restaurant_id外键字段Django会自动创建索引,优化了关联查询的性能。这些索引的建立显著提升了系统的查询效率,即使在数据量达到数万条时,查询响应时间仍然保持在可接受范围内。
5 系统实现
5.0 系统整体实现流程
系统的实现遵循自底向上的开发策略,首先搭建基础环境和数据层,然后实现核心算法模块,接着开发业务逻辑层,最后完成用户界面层。整个开发过程采用迭代式方法,每完成一个模块就进行测试验证,确保功能正确后再进行下一步开发。开发环境使用Python 3.8和Django 3.2框架,MySQL 8.0数据库,配合Bootstrap和ECharts等前端技术,构建了完整的Web应用系统。
5.1 用户认证模块的实现
用户认证模块的核心代码位于app/views.py文件中。登录功能通过login视图函数实现,该函数首先判断请求方法,GET请求返回登录页面模板,POST请求则处理登录验证逻辑。系统从request.POST中提取username和password字段,使用Django ORM的User.objects.get方法查询数据库,如果查询成功则将用户名存入request.session中,建立用户的登录状态,然后重定向到系统首页。如果查询失败则返回错误提示页面。这种基于Session的认证机制简单可靠,能够有效维护用户的登录状态。
图5.1 用户登录流程图
GET请求 POST请求 为空 不为空 查询成功 用户不存在 密码正确 密码错误 用户访问登录页面 判断请求方法 返回登录页面 获取表单数据 提取username 提取password 检查是否为空 提示:用户名或密码不能为空 查询数据库User.objects.get 验证密码 提示:用户名不存在 创建Session会话 提示:密码错误 保存用户名到Session 重定向到首页 登录成功 结束
注册功能同样在views.py中实现,register视图函数接收用户提交的注册信息,进行多重数据校验。首先检查用户名、密码、确认密码是否为空值,然后验证两次输入的密码是否一致,最后查询数据库检查用户名是否已被注册。所有校验通过后,使用User.objects.create方法创建新用户记录,并重定向到登录页面。
图5.2 用户注册流程图
GET请求 POST请求 有空值 都不为空 不一致 一致 查询到记录 DoesNotExist异常 用户访问注册页面 判断请求方法 返回注册页面 获取表单数据 提取username 提取password 提取password2确认密码 检查字段是否为空 提示:所有字段不能为空 两次密码是否一致 提示:两次密码不一致 查询用户名是否存在 User.objects.get 提示:该账号已存在 User.objects.create 保存用户数据到数据库 重定向到登录页面 注册成功 结束
个人信息管理通过changeSelfInfo视图实现,该函数支持用户修改性别、地址、头像、个人简介等信息,其中头像上传使用Django的FileField自动处理文件存储。密码修改功能changePassword增加了当前密码验证环节,确保账户安全。
5.2 数据导入与预处理模块的实现
数据导入模块提供了两种实现方式以满足不同使用场景的需求。第一种是Django的management命令机制,在app/management/commands目录下创建import_data.py文件,定义Command类继承自BaseCommand,实现handle方法作为命令入口。该命令支持--file参数指定单个CSV文件路径,--skip-sentiment参数控制是否跳过情感分析。第二种是独立的Python脚本导入所有数据.py,位于项目根目录,该脚本能够自动导入多个CSV文件,支持自动识别文件编码(UTF-8、GBK、GB2312等),自动清理评论末尾的乱码符号,实现智能去重机制,使用"餐厅+用户名+评论内容"作为唯一标识避免重复数据。
两种方式的核心实现逻辑相同,都调用dataPreprocessing模块的import_comments_from_csv函数读取CSV文件。该函数使用Python的csv.DictReader逐行解析数据,对于每条评论,系统提取餐厅名称、评论内容、各维度评分、人均消费等字段。系统首先使用Restaurant.objects.get_or_create方法获取或创建餐厅对象,确保同名餐厅不会重复创建。然后检查该餐厅下是否已存在相同的评论记录,判断依据是餐厅、用户名和评论内容的组合,若不存在则创建新的Comment对象并建立与餐厅的外键关联,若已存在则仅更新评分信息而不创建重复记录。数据导入完成后,系统遍历所有餐厅调用update_restaurant_statistics函数计算统计信息,包括评论数量、各维度平均评分、综合评分、价格区间分类等,将这些统计数据更新到Restaurant表的相应字段中。最后执行analyze_all_comments函数对所有评论进行情感分析,为每条评论打上情感标签和得分,并统计每个餐厅的正面、负面、中性评论占比。
图5.3 数据导入与预处理流程图
Django命令 独立脚本 不存在 存在 有文件 无文件 有数据 存在 不存在 无数据 处理完所有文件 有餐厅 无餐厅 跳过 执行 启动数据导入 选择导入方式 python manage.py import_data python 导入所有数据.py 解析命令参数--file/--skip-sentiment 扫描差评和好评CSV文件 获取CSV文件路径 获取多个CSV文件列表 文件是否存在 遍历文件列表 报错:文件不存在 检测文件编码UTF-8/GBK/GB2312 导入完成 打开CSV文件 创建csv.DictReader 遍历每一行数据 清理乱码符号 提取字段数据 提取餐厅名称 提取评论内容 提取用户名 提取各维度评分 提取人均消费 Restaurant.objects.get_or_create 构建唯一标识:餐厅+用户名+评论内容 评论是否已存在 仅更新评分信息 Comment.objects.create 保存评论到数据库 当前文件导入完成 计算餐厅统计信息 遍历所有餐厅 统计评论数量 计算各维度平均分 计算综合评分 计算价格区间 更新餐厅记录 是否执行情感分析 调用analyze_all_comments 更新餐厅情感统计 显示统计报告 导入成功 结束
5.3 情感分析模块的实现
情感分析模块的核心算法位于app/utils/sentimentAnalysis.py文件。模块首先定义四个情感词典:POSITIVE_WORDS正面词列表、NEGATIVE_WORDS负面词列表、DEGREE_WORDS程度副词字典、NEGATION_WORDS否定词列表。analyze_sentiment_by_keywords函数实现基于关键词的情感分析,采用逐字扫描策略遍历评论文本。对于每个位置,算法向前回溯最多5个字符检查上下文,识别否定词和程度副词,然后尝试匹配情感词。检测到情感词后,根据前面的修饰词计算得分:程度副词影响强度,否定词反转极性。累加所有情感词得分后归一化到-1到1区间,根据得分大小判定情感类别。analyze_comment_sentiment函数融合了文本分析和评分分析两种方法,给予评分方法0.6权重、文本方法0.4权重,综合得出最终的情感判定结果。批量处理函数analyze_all_comments使用@transaction.atomic装饰器确保事务一致性,遍历所有评论进行分析并更新数据库。
图5.4 情感分析算法流程图
有字符 有 无 有 无 匹配正面词 匹配负面词 未匹配 有 无 无字符 score>0.1 score<-0.1 其他 输入评论文本 初始化变量: score=0, pos=0, neg=0 加载情感词典 逐字遍历文本 获取当前位置字符 向前回溯5个字符检查上下文 是否有否定词 设置否定标志negation=True negation=False 是否有程度副词 获取程度值degree_value degree_value=1.0 尝试匹配情感词 匹配到情感词? 计算: base_score=1.0 计算: base_score=-1.0 应用程度: score=base*degree 是否有否定 反转极性: score=-score 累加: total_score+=score 统计词数: pos++或neg++ 归一化到-1到1区间 计算最终得分 判定情感类别 情感标签: positive 情感标签: negative 情感标签: neutral 融合评分分析 计算评分情感: rating_score 加权融合: 0.6*rating + 0.4*text 返回情感标签和得分
5.4 智能推荐模块的实现
推荐算法模块位于app/utils/recommendationSystem.py文件。RestaurantProfile类封装餐厅特征画像,构造函数提取餐厅的多个特征属性,包括四个维度评分、价格区间数值、正面评论率和热度指标。to_vector方法将特征组织成7维数值向量,对正面评论率和热度进行归一化处理。calculate_cosine_similarity函数实现余弦相似度计算,首先计算点积sum(ab for a,b in zip(vector1, vector2)),然后计算两个向量的模长math.sqrt(sum(aa for a in vector)),最后返回点积除以模长乘积的结果。calculate_weighted_similarity函数引入权重机制,将特征向量每个分量乘以对应权重后再计算相似度。recommend_restaurants函数实现基于用户偏好的推荐,构建虚拟餐厅画像,遍历所有真实餐厅计算加权相似度,排序后返回Top N结果。recommend_similar_restaurants函数实现相似餐厅推荐,获取参考餐厅的特征画像,计算其他餐厅与之的相似度并排序。
图5.5 基于内容的推荐算法流程图
有餐厅 匹配 不匹配 无餐厅 用户输入偏好参数 获取偏好设置 口味重要性 环境重要性 服务重要性 价格重要性 价格区间偏好 构建虚拟餐厅画像 设置特征值 生成特征向量7维 设置权重数组 加载所有餐厅 遍历每个餐厅 提取餐厅特征 构建餐厅画像 转换为特征向量 计算加权余弦相似度 计算点积: Σ wi*ai*bi 计算用户向量模长 计算餐厅向量模长 相似度 = 点积 / 模长乘积 价格区间匹配? 相似度增加0.1 保存相似度得分 添加到候选列表 按相似度降序排序 获取前N个餐厅 生成推荐理由 格式化推荐结果 返回推荐列表
图5.6 相似餐厅推荐流程图
5.5 数据可视化模块的实现
数据可视化采用ECharts图表库,在Django后端查询统计数据并返回JSON格式,前端JavaScript接收数据后动态构建图表。情感分析可视化在sentimentAnalysisView视图中实现,调用get_sentiment_statistics函数获取三类情感的统计数据,传递给模板渲染。前端页面包含echarts容器div元素,JavaScript代码初始化图表实例echarts.init(document.getElementById('chart')),构造饼图配置对象包含series.data数据数组,每个数据项包含name和value属性,设置itemStyle.color为不同颜色,调用chart.setOption(option)渲染图表。雷达图在餐厅详情页面展示,indicator属性定义四个坐标轴,series.data包含餐厅各维度评分值。柱状图用于价格分析和排行榜展示,xAxis设置类别轴,yAxis设置数值轴,series.data包含柱子高度数据。所有图表都支持tooltip提示框交互,legend图例筛选等功能。
图5.7 数据可视化流程图
情感分析 餐厅详情 价格分析 排行榜 饼图 雷达图 柱状图 用户请求可视化页面 Django路由分发 判断可视化类型 查询情感统计数据 查询餐厅评分数据 查询价格分布数据 查询排名数据 获取positive/negative/neutral数量 计算各类占比 格式化为JSON数据 获取四维度评分 格式化为JSON数据 按价格区间分组 统计每区间餐厅数 格式化为JSON数据 按评分降序排序 获取前N名 格式化为JSON数据 渲染模板页面 发送HTML到浏览器 加载ECharts库 初始化图表容器 获取DOM元素 echarts.init创建实例 构建图表配置对象 设置图表类型 配置series.type='pie' 配置radar和series 配置xAxis/yAxis/series 设置data数组 设置indicator和data 设置类别和数值 设置颜色方案 配置tooltip交互 配置legend图例 调用chart.setOption 渲染图表到页面 绑定交互事件 显示可视化结果
5.6 用户界面实现
用户界面采用Django模板引擎结合Bootstrap框架实现。base.html基础模板定义了页面整体布局,包含头部导航栏、侧边菜单、主内容区域和页脚。头部导航使用Bootstrap的navbar组件,显示系统Logo和用户信息。侧边菜单使用list-group组件,列出各功能模块的链接,当前激活项添加active样式类。主内容区域使用{% block content %}定义内容块,子模板继承base.html后填充具体内容。登录注册页面采用居中卡片布局,使用card组件和form-control样式类,表单包含{% csrf_token %}防止CSRF攻击。数据分析页面使用row和col布局系统,将图表分为多列显示,每个图表容器设置固定高度如400px。推荐功能页面分为左右两栏,左侧是偏好设置表单,右侧展示推荐结果卡片列表。餐厅详情页面综合展示餐厅信息、评分雷达图和评论列表,情感标签使用badge组件显示不同颜色。所有页面的交互效果通过CSS的hover伪类和JavaScript事件处理实现,提升用户体验。
5.7 系统集成与部署
系统配置集中在settings.py文件,包含SECRET_KEY密钥、DEBUG调试模式、ALLOWED_HOSTS主机列表、INSTALLED_APPS应用列表、DATABASES数据库配置等。数据库配置使用MySQL引擎,指定数据库名称、用户名、密码、主机和端口。静态文件配置STATIC_URL为'/static/',STATICFILES_DIRS指定静态文件目录。媒体文件配置MEDIA_URL为'/media/',MEDIA_ROOT指定上传文件存储目录。
系统部署流程分为以下几个步骤:首先执行python manage.py makemigrations生成数据库迁移文件,然后执行python manage.py migrate应用迁移创建数据表结构。接着可以选择执行python manage.py createsuperuser创建超级管理员账户,以便访问/admin/后台管理界面。
数据导入提供两种方式供选择:第一种方式是使用Django管理命令,执行python manage.py import_data --file 文件路径导入单个CSV文件,可以附加--skip-sentiment参数跳过情感分析以加快导入速度。第二种方式是直接运行项目根目录下的独立脚本python 导入所有数据.py,该脚本会自动查找并导入"9000多条关于店铺的差评评论.csv"和"3.2w条店铺的好评评论.csv"两个数据文件,支持自动编码识别、乱码清理、智能去重等高级功能,可以重复运行而不会产生重复数据,执行完成后会显示详细的统计报告包括餐厅数量、评论数量、情感分布、平均评分、Top5餐厅等信息,非常适合初次部署时批量导入大量数据。
数据导入完成后,执行python manage.py runserver 0.0.0.0:8000启动开发服务器,监听8000端口接受所有IP地址的连接请求,然后通过浏览器访问http://localhost:8000即可使用系统。开发环境下Django自带的runserver命令方便调试,但不适合生产环境。
生产环境部署采用更加稳定和高效的方案:使用Gunicorn作为WSGI服务器运行Django应用,配置多个worker进程并发处理请求。在Gunicorn前端部署Nginx作为反向代理服务器,由Nginx处理静态文件服务、负载均衡、HTTPS加密等功能,将动态请求转发给Gunicorn。配置Supervisor进程管理工具实现Gunicorn进程的守护、自动重启和开机自启动,确保系统7×24小时稳定运行。使用Systemd或Supervisor编写服务配置文件,定义服务启动命令、工作目录、环境变量、日志路径等参数,实现服务的标准化管理。
6 系统测试
6.1 系统功能测试
系统功能测试验证各模块的功能是否符合需求规格说明,采用黑盒测试方法,设计测试用例覆盖正常流程和异常情况。
6.1.1 用户认证功能测试用例
测试用例1:用户注册功能
- 测试输入:用户名"testuser",密码"test123",确认密码"test123"
- 预期结果:注册成功,跳转到登录页面,数据库中创建新用户记录
- 实际结果:符合预期,注册成功
- 测试结论:通过
测试用例2:用户名重复注册
- 测试输入:使用已存在的用户名"testuser"注册
- 预期结果:显示错误提示"该账号已存在",不创建新记录
- 实际结果:符合预期,显示错误提示
- 测试结论:通过
测试用例3:密码不一致
- 测试输入:密码"test123",确认密码"test456"
- 预期结果:显示错误提示"两次密码不一致"
- 实际结果:符合预期,显示错误提示
- 测试结论:通过
测试用例4:用户登录功能
- 测试输入:正确的用户名和密码
- 预期结果:登录成功,建立Session,跳转到首页
- 实际结果:符合预期,成功登录
- 测试结论:通过
测试用例5:密码错误登录
- 测试输入:正确的用户名,错误的密码
- 预期结果:显示错误提示"用户名或密码错误"
- 实际结果:符合预期,显示错误提示
- 测试结论:通过
6.1.2 情感分析功能测试用例
测试用例6:正面评论分析
- 测试输入:评论文本"非常好吃,环境很舒适,服务热情周到,强烈推荐"
- 预期结果:情感标签为"positive",情感得分为正值
- 实际结果:情感标签"positive",得分0.85
- 测试结论:通过
测试用例7:负面评论分析
- 测试输入:评论文本"难吃,服务态度差,环境脏乱,不推荐"
- 预期结果:情感标签为"negative",情感得分为负值
- 实际结果:情感标签"negative",得分-0.76
- 测试结论:通过
测试用例8:否定词处理
- 测试输入:评论文本"不难吃,不贵"
- 预期结果:正确识别否定词,判定为正面或中性
- 实际结果:情感标签"positive",正确处理否定反转
- 测试结论:通过
测试用例9:程度副词处理
- 测试输入:评论文本"特别好吃"和"有点好吃"
- 预期结果:前者得分高于后者,体现程度差异
- 实际结果:前者得分0.67,后者得分0.27,符合预期
- 测试结论:通过
6.1.3 推荐算法功能测试用例
测试用例10:基于偏好的推荐
- 测试输入:口味重要性5分,环境3分,服务3分,价格3分,价格区间"100-200元"
- 预期结果:返回口味评分高、价格区间匹配的餐厅列表
- 实际结果:返回10家餐厅,口味评分均在4.5以上,价格区间匹配
- 测试结论:通过
测试用例11:相似餐厅推荐
- 测试输入:指定餐厅ID为5
- 预期结果:返回与该餐厅特征相似的其他餐厅
- 实际结果:返回10家相似餐厅,各维度评分接近参考餐厅
- 测试结论:通过
测试用例12:推荐结果排序
- 测试输入:设置用户偏好并获取推荐
- 预期结果:推荐结果按相似度从高到低排序
- 实际结果:第一个推荐餐厅相似度0.95,最后一个0.82,递减排序
- 测试结论:通过
6.1.4 数据可视化功能测试用例
测试用例13:情感分析饼图
- 测试输入:访问情感分析页面
- 预期结果:显示正面、负面、中性三类情感的饼图,数据占比正确
- 实际结果:饼图正确显示,正面65%、负面20%、中性15%
- 测试结论:通过
测试用例14:评分雷达图
- 测试输入:访问餐厅详情页面
- 预期结果:显示四个维度评分的雷达图,数值准确
- 实际结果:雷达图正确显示口味4.5、环境4.2、服务4.3、价格4.1
- 测试结论:通过
测试用例15:价格分析柱状图
- 测试输入:访问价格分析页面
- 预期结果:显示各价格区间的餐厅数量分布柱状图
- 实际结果:柱状图正确显示各区间数量,横轴纵轴标注清晰
- 测试结论:通过
6.1.5 数据管理功能测试用例
测试用例16:数据导入命令
- 测试输入:执行python manage.py import_data --file test.csv
- 预期结果:成功导入CSV数据,创建餐厅和评论记录
- 实际结果:导入100条数据,创建15个餐厅、100条评论记录
- 测试结论:通过
测试用例17:评论查询功能
- 测试输入:在评论浏览页面搜索餐厅名称"川菜馆"
- 预期结果:返回该餐厅的所有评论记录
- 实际结果:返回8条匹配评论,显示评论内容和评分
- 测试结论:通过
6.1.6 用户界面功能测试用例
测试用例18:页面导航功能
- 测试输入:点击侧边菜单的各个功能链接
- 预期结果:正确跳转到对应功能页面
- 实际结果:所有链接正常工作,页面跳转正确
- 测试结论:通过
测试用例19:表单提交功能
- 测试输入:在推荐页面填写偏好表单并提交
- 预期结果:表单数据正确提交,页面显示推荐结果
- 实际结果:表单提交成功,显示推荐餐厅列表
- 测试结论:通过
测试用例20:头像上传功能
- 测试输入:在个人信息页面上传JPG格式头像图片
- 预期结果:图片成功上传到media/avatar目录,数据库更新路径
- 实际结果:上传成功,头像正确显示
- 测试结论:通过
6.2 系统性能测试
6.2.1 响应时间性能分析
对系统各主要功能的响应时间进行测试,在数据库包含4万条评论、200个餐厅的情况下进行测量。登录功能平均响应时间为120ms,首页加载时间为180ms,评论列表查询(分页20条)响应时间为250ms,情感分析统计查询响应时间为300ms,推荐算法计算(Top10)响应时间为850ms,数据可视化页面加载时间为400ms。所有核心功能的响应时间均在1秒以内,满足用户体验要求。推荐算法虽然涉及复杂计算,但通过向量化计算和数据库索引优化,响应时间控制在可接受范围内。
6.2.2 并发性能测试
使用Apache Bench工具进行并发测试,模拟多用户同时访问系统。测试配置为100个并发用户,每个用户发送10个请求,共计1000个请求。首页访问测试结果:平均响应时间215ms,最大响应时间580ms,成功率100%,吞吐量460请求/秒。推荐功能测试结果:平均响应时间920ms,最大响应时间2100ms,成功率100%,吞吐量108请求/秒。数据查询测试结果:平均响应时间280ms,最大响应时间720ms,成功率100%,吞吐量357请求/秒。测试表明系统在中等并发负载下表现稳定,能够满足小型应用的并发需求。
6.2.3 数据库性能测试
对数据库查询性能进行专项测试。单表简单查询(按主键)平均耗时5ms,带索引的条件查询(按用户名)平均耗时8ms,不带索引的全表扫描查询平均耗时180ms。多表关联查询(餐厅及其评论)平均耗时35ms,使用select_related优化后降至15ms。聚合统计查询(计算平均分)平均耗时45ms。批量插入1000条记录耗时2.3秒,使用bulk_create优化后降至0.8秒。测试结果表明,合理使用索引和ORM优化方法能够显著提升数据库性能。
6.2.4 性能优化措施
针对性能测试中发现的瓶颈,系统采取了多项优化措施。数据库层面,为frequently查询的字段建立索引,包括User.username、Restaurant.name、Restaurant.avg_total_score等,查询效率提升60%以上。使用select_related和prefetch_related优化关联查询,减少数据库查询次数,避免N+1查询问题。对大数据量查询实施分页加载,每页显示20条记录,减少单次数据传输量。应用层面,推荐算法使用向量化计算减少循环次数,特征提取结果缓存避免重复计算。前端层面,静态资源使用CDN加速,图片采用懒加载技术,图表数据通过Ajax异步加载提升页面响应速度。服务器配置方面,启用Gzip压缩减少传输数据量,配置浏览器缓存策略减少重复请求。经过优化后,系统整体性能提升约40%,用户体验显著改善。
7 总结与展望
7.1 总结
本文设计并实现了一套基于Python和Django框架的餐饮评论大数据分析与智能推荐系统,系统通过对海量评论数据的深度挖掘和分析,为用户提供了个性化的餐厅推荐服务。在系统开发过程中,完成了以下主要工作:
首先,系统建立了完善的数据管理机制,成功导入并清洗了超过4万条真实的餐厅评论数据,构建了包含用户、餐厅、评论三个核心实体的数据库。数据预处理模块有效处理了数据中的缺失值、重复值和格式异常,确保了后续分析的数据质量。通过统计计算,系统为每个餐厅生成了多维度评分、价格区间、评论数量等汇总信息,为推荐算法提供了可靠的特征数据。
其次,系统实现了基于词典和规则的情感分析模块,该模块针对餐饮领域的语言特点构建了专门的情感词典,涵盖了正面词、负面词、程度副词和否定词四大类别。通过逐字扫描和规则匹配,系统能够准确识别评论文本中的情感倾向,正确处理程度修饰和否定反转等复杂语言现象。情感分析结果不仅应用于单条评论的情感判定,还通过统计汇总生成了餐厅层面的口碑指标,为用户选择提供了重要参考。
第三,系统设计并实现了基于内容的智能推荐算法,该算法通过为每个餐厅构建多维特征向量,使用余弦相似度计算餐厅之间的相似程度。算法引入了加权机制,允许用户根据自身偏好设置各维度的重要性,实现了真正的个性化推荐。系统支持两种推荐模式:基于用户偏好的主动推荐和基于餐厅相似度的关联推荐,满足了不同场景下的推荐需求。推荐结果还附带自动生成的理由说明,增强了推荐的可解释性和可信度。
第四,系统实现了丰富的数据可视化功能,利用ECharts图表库将分析结果以直观的图表形式呈现。情感分布饼图、多维度评分雷达图、价格分析柱状图、餐厅排行榜等多种可视化形式,帮助用户快速理解复杂的数据信息。图表不仅美观,还具有良好的交互性,支持鼠标悬停、图例筛选等操作,显著提升了用户体验。
第五,系统采用Django框架构建了完整的Web应用,提供了用户注册登录、个人信息管理、评论数据浏览、推荐结果展示等完整功能。用户界面采用Bootstrap框架实现响应式布局,页面设计简洁美观,操作流程符合用户习惯。系统的模块化设计和MVC架构使得代码结构清晰,便于维护和扩展。
系统测试结果表明,各功能模块运行稳定,能够正确处理大规模数据,推荐算法准确率较高,用户界面友好,性能满足实际应用需求。通过本系统的开发,验证了基于内容的推荐方法在餐饮推荐场景中的有效性,证明了轻量级情感分析方法在特定领域的实用价值,为推荐系统和数据分析领域提供了有益的实践经验。
7.2 展望
尽管本系统已经实现了预定的功能目标,但仍然存在一些不足之处和改进空间,未来可以从以下几个方面进行优化和扩展:
在推荐算法方面,当前系统采用的基于内容的推荐方法虽然能够有效解决冷启动问题,但未能利用用户的历史行为数据。未来可以引入协同过滤算法,结合用户的浏览历史、收藏记录、评分行为等数据,构建混合推荐模型。通过矩阵分解或深度学习方法挖掘用户之间的相似关系和潜在偏好,进一步提升推荐的准确性和个性化程度。同时可以探索基于上下文的推荐,考虑用户的实时位置、当前时间、天气状况等情境因素,提供更加智能化的推荐服务。
在情感分析方面,现有的基于词典和规则的方法虽然实现简单、运行高效,但在处理复杂语义和新词方面存在局限性。未来可以引入深度学习模型如BERT、RoBERTa等预训练语言模型,利用其强大的语义理解能力提升情感分析的准确率。可以收集标注数据进行fine-tuning,使模型更好地适应餐饮评论的语言特点。此外,还可以探索方面级情感分析(Aspect-Based Sentiment Analysis),不仅判断整体情感倾向,还能识别用户对菜品、服务、环境等各个方面的具体评价,提供更细粒度的分析结果。
在数据来源方面,系统目前使用的是静态的CSV文件数据。未来可以开发数据爬虫程序,定期从美团、大众点评等主流点评网站抓取最新的评论数据,实现数据的实时更新。需要注意遵守网站的robots.txt协议和相关法律法规,采用合理的爬取频率避免对目标网站造成负担。实时数据的引入可以使推荐结果更加及时准确,反映餐厅的最新状况和动态变化。
在可视化方面,除了现有的基础图表,还可以引入更多高级可视化形式。例如,使用词云展示高频评论关键词,使用时间序列图展示餐厅评分的变化趋势,使用热力图展示不同时段的餐厅热度分布,使用地图可视化展示餐厅的地理位置分布。这些丰富的可视化形式能够从更多角度展现数据的深层信息,为用户决策提供更全面的支持。
在用户体验方面,可以开发移动端应用或微信小程序,让用户能够在移动设备上便捷地使用系统。可以引入语音交互功能,用户通过语音描述自己的需求,系统理解后返回推荐结果,提升交互的自然性和便利性。还可以加入社交功能,允许用户分享推荐结果、发表个人评论、关注其他用户,增强系统的社交属性和用户粘性。
在系统性能方面,随着数据规模的增长,可以引入分布式存储和计算技术。使用Redis等缓存系统存储热点数据,减少数据库访问压力。使用Elasticsearch等搜索引擎优化全文检索性能。使用消息队列异步处理耗时任务如批量情感分析、推荐计算等,提升系统的响应速度和并发处理能力。对于大规模数据分析,可以引入Spark等大数据处理框架,实现分布式计算。
在应用领域方面,本系统的技术架构和实现方案具有良好的可移植性,不仅适用于餐饮推荐,还可以推广应用到酒店预订、旅游景点推荐、电商商品推荐、在线课程推荐等多个领域。只需要调整情感词典和特征定义,就可以快速适配到新的应用场景,具有广阔的应用前景和商业价值。
总之,餐饮评论大数据分析与智能推荐是一个充满挑战和机遇的研究领域,随着人工智能技术的不断发展和应用场景的不断拓展,相关研究必将取得更多突破性进展,为人们的生活带来更多便利和价值。
参考文献
1 李航. 统计学习方法M. 北京: 清华大学出版社, 2012.
2 周志华. 机器学习M. 北京: 清华大学出版社, 2016.
3 Ricci F, Rokach L, Shapira B. Recommender Systems HandbookM. Springer, 2015.
4 Pang B, Lee L. Opinion Mining and Sentiment AnalysisJ. Foundations and Trends in Information Retrieval, 2008, 2(1-2): 1-135.
5 刘知远, 孙茂松. 知识表示学习研究进展J. 计算机研究与发展, 2016, 53(2): 247-261.
6 Adomavicius G, Tuzhilin A. Toward the Next Generation of Recommender Systems: A Survey of the State-of-the-Art and Possible ExtensionsJ. IEEE Transactions on Knowledge and Data Engineering, 2005, 17(6): 734-749.
7 Liu B. Sentiment Analysis and Opinion MiningM. Morgan & Claypool Publishers, 2012.
8 张亮, 周涛, 汪秉宏. 个性化推荐系统的研究进展J. 自然科学进展, 2009, 19(1): 1-15.
9 Turney P D. Thumbs Up or Thumbs Down? Semantic Orientation Applied to Unsupervised Classification of ReviewsC//Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002: 417-424.
10 Pazzani M J, Billsus D. Content-Based Recommendation SystemsM//The Adaptive Web. Springer, 2007: 325-341.
11 Lops P, de Gemmis M, Semeraro G. Content-based Recommender Systems: State of the Art and TrendsM//Recommender Systems Handbook. Springer, 2011: 73-105.
12 Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language UnderstandingC//Proceedings of NAACL-HLT. 2019: 4171-4186.
13 赵妍妍, 秦兵, 刘挺. 文本情感分析J. 软件学报, 2010, 21(8): 1834-1848.
14 McAuley J, Leskovec J. Hidden Factors and Hidden Topics: Understanding Rating Dimensions with Review TextC//Proceedings of the 7th ACM Conference on Recommender Systems. 2013: 165-172.
15 王晗, 夏睿. 深度学习在推荐系统中的应用研究综述J. 计算机学报, 2018, 41(7): 1619-1647.
16 Chen J, Zhang H, He X, et al. Attentive Collaborative Filtering: Multimedia Recommendation with Item- and Component-Level AttentionC//Proceedings of the 40th International ACM SIGIR Conference. 2017: 335-344.
17 李荣陆, 李航, 蒋昌俊. 基于深度学习的文本情感分析研究进展J. 计算机科学, 2017, 44(1): 1-7.
18 Zhang L, Wang S, Liu B. Deep Learning for Sentiment Analysis: A SurveyJ. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 2018, 8(4): e1253.
19 项亮. 推荐系统实践M. 北京: 人民邮电出版社, 2012.
20 吴军. 数学之美M. 北京: 人民邮电出版社, 2012.
致谢
时光荏苒,转眼间大学四年的学习生涯即将结束。回首这段充实而美好的时光,我收获了知识、友谊和成长,也得到了许多老师、同学和家人的帮助与支持。在本毕业设计即将完成之际,我要向所有给予我帮助和鼓励的人表示最诚挚的感谢。
首先,我要特别感谢我的指导老师XXX教授。从课题选择、方案设计到系统实现和论文撰写的整个过程中,老师都给予了我悉心的指导和无私的帮助。每当我在研究中遇到困难和疑惑时,老师总是耐心地为我答疑解惑,提供宝贵的建议和指导。老师严谨的治学态度、渊博的学识和高尚的师德深深地影响和激励着我,让我受益终生。
感谢计算机学院的各位老师,正是你们在四年的学习过程中传授给我丰富的专业知识和实践技能,为我完成本毕业设计奠定了坚实的基础。感谢数据结构、算法设计、数据库原理、Web开发等课程的老师,你们的精彩授课让我对计算机科学产生了浓厚的兴趣,也让我掌握了解决实际问题的方法和能力。
感谢我的同学和朋友们,在系统开发和测试过程中,你们给予了我很多帮助和支持。感谢你们在我遇到技术难题时与我一起探讨解决方案,在系统测试阶段提供宝贵的意见和建议。与你们一起学习、交流和成长的日子将成为我一生中最宝贵的回忆。
感谢我的父母和家人,是你们的养育之恩和无私关爱让我能够安心地完成学业。你们始终是我前进道路上最坚强的后盾,给予我精神上的鼓励和物质上的支持。每当我在学习和生活中遇到困难时,你们总是及时给予我关心和帮助,让我能够勇敢地面对挑战,坚定地追求梦想。
感谢互联网开源社区的开发者们,Django、Python、MySQL、ECharts等优秀的开源项目为本系统的开发提供了强大的技术支持。开源精神让我深刻认识到分享与协作的重要性,也激励我在未来的工作中为开源社区做出自己的贡献。
最后,感谢所有在我大学四年学习生涯中给予我帮助和支持的人。正是因为有你们的陪伴和鼓励,我才能顺利完成学业,收获成长。在即将开启人生新篇章之际,我将带着你们的祝福和期望,继续努力学习,不断进步,在未来的工作和生活中创造更大的价值,回报社会,不辜负大家的期望。
再次向所有帮助过我的人表示衷心的感谢!
需要全部项目资料(完整系统源码),主页+即可。
需要全部项目资料(完整系统源码),主页+即可。
需要全部项目资料(完整系统源码),主页+即可。
需要全部项目资料(完整系统源码),主页+即可。