基于Python Django的物流数据可视化分析系统开发实录
项目背景
随着物流行业数据量的激增,企业对数据分析和可视化的需求日益增长。传统的Excel分析方式难以满足多维度、实时、交互式的数据洞察需求。为此,我们开发了一个基于Python Django的物流年度销售收入数据可视化分析系统,实现了从数据导入、管理、分析到可视化的一站式解决方案。
需求分析
- 业务需求 :
- 快速掌握年度销售、利润、客户、产品等核心指标
- 支持多维度(时间、地区、产品、客户)分析
- 交互式图表,便于业务人员自主探索数据
- 数据质量保障,避免误导性分析
- 支持数据导入、导出、收藏、日志追踪等管理功能
- 技术需求 :
- 前后端分离,API接口标准化
- 支持大数据量高效查询
- 易于二次开发和维护
典型业务场景举例
- 年度经营复盘:管理层可一键查看全年收入、利润、订单量等关键指标,辅助年度总结与战略调整。
- 区域市场分析:市场部门可通过地区分布图快速识别高潜力市场,优化资源投放。
- 产品结构优化:产品经理可分析热门产品排行和利润贡献,调整产品线结构。
- 客户价值挖掘:销售团队可基于客户分群和价值分析,制定差异化营销策略。
- 异常监控与预警:系统支持对数据异常波动(如收入骤降)进行可视化提示,便于及时响应。
系统架构
graph TD;
A[前端界面<br/>(Bootstrap+Chart.js)] --API/页面请求--> B[Django视图层]
B --ORM--> C[MySQL数据库]
B --Pandas/NumPy--> D[数据处理与分析]
B --SimpleUI--> E[管理后台]
技术选型
- 后端:Python 3.8+、Django 4.2.7、Django REST Framework、MySQL
- 数据处理:Pandas、NumPy
- 前端:Bootstrap 5、Chart.js、jQuery
- 管理后台:django-simpleui
项目演示
🐳 项目源码获取,码界筑梦坊各平台同名,博客底部含联系方式卡片,欢迎咨询!
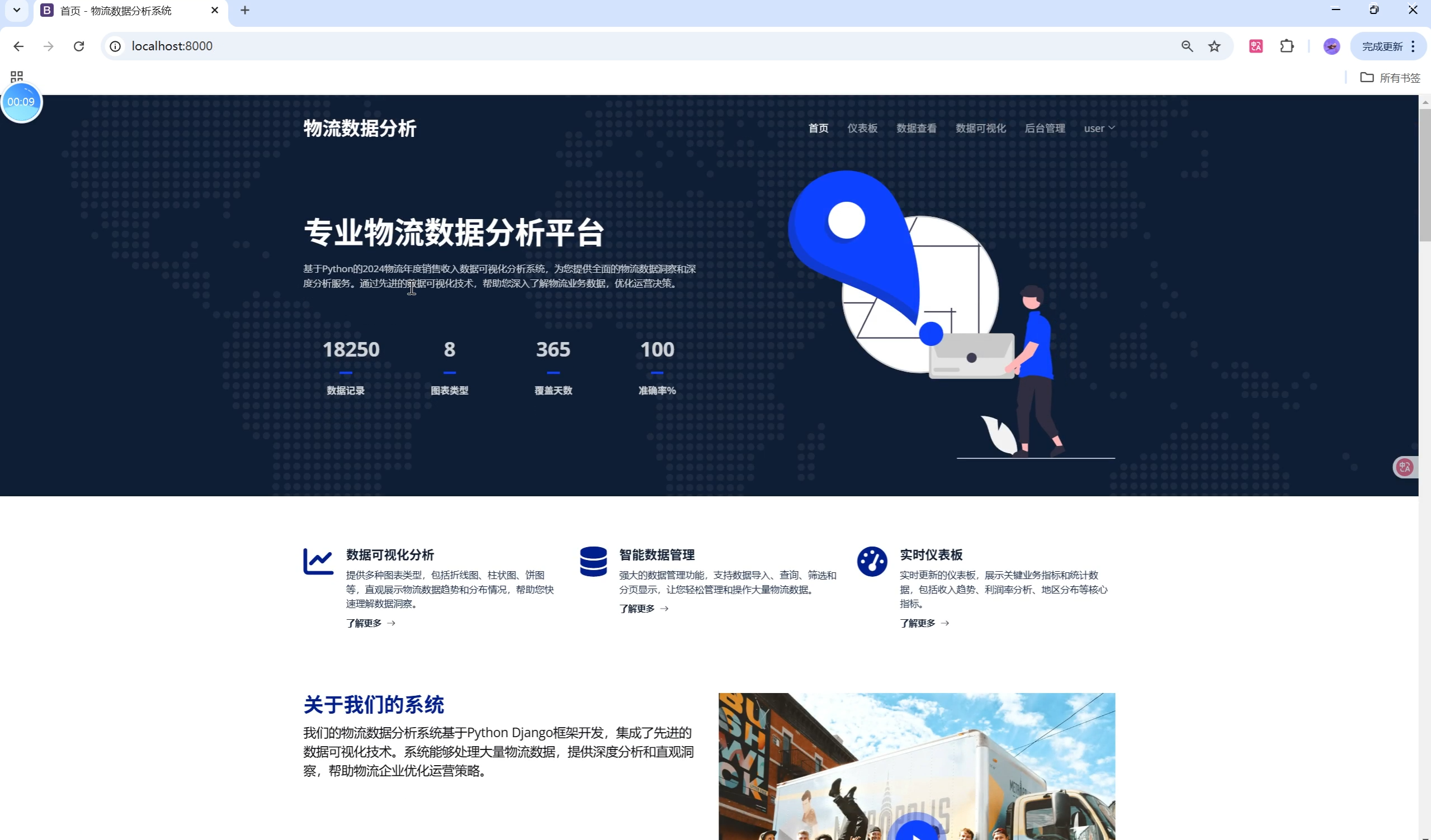
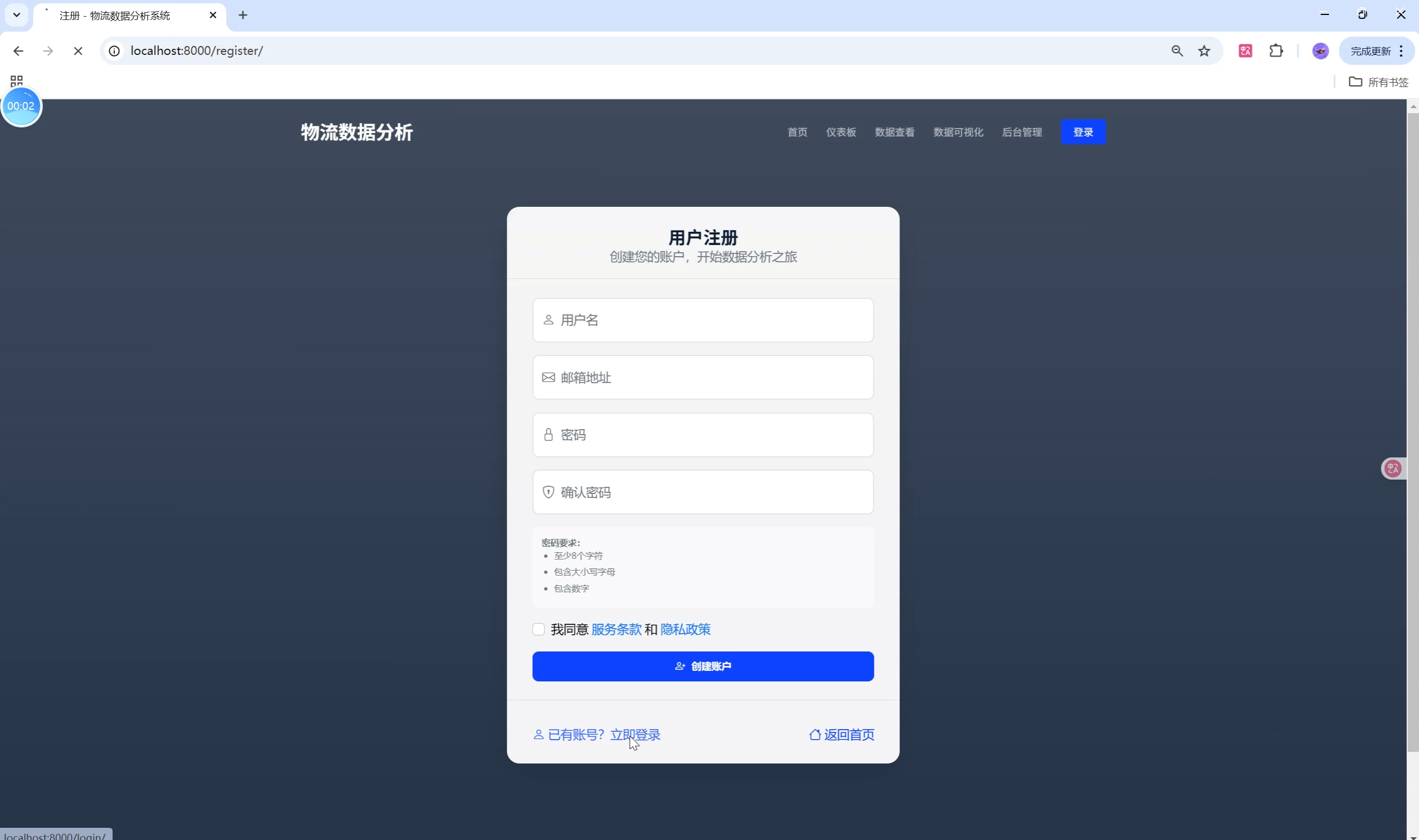
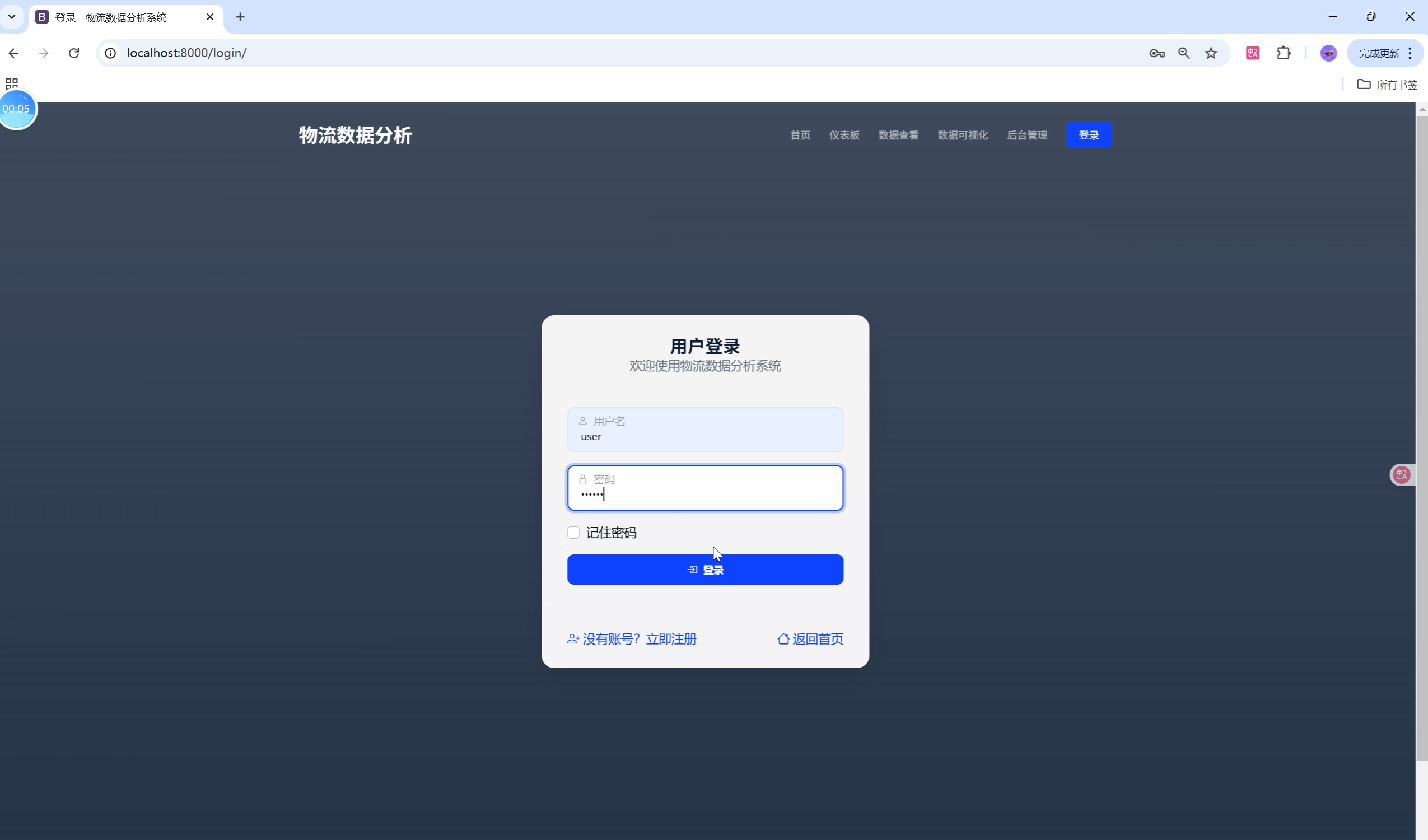
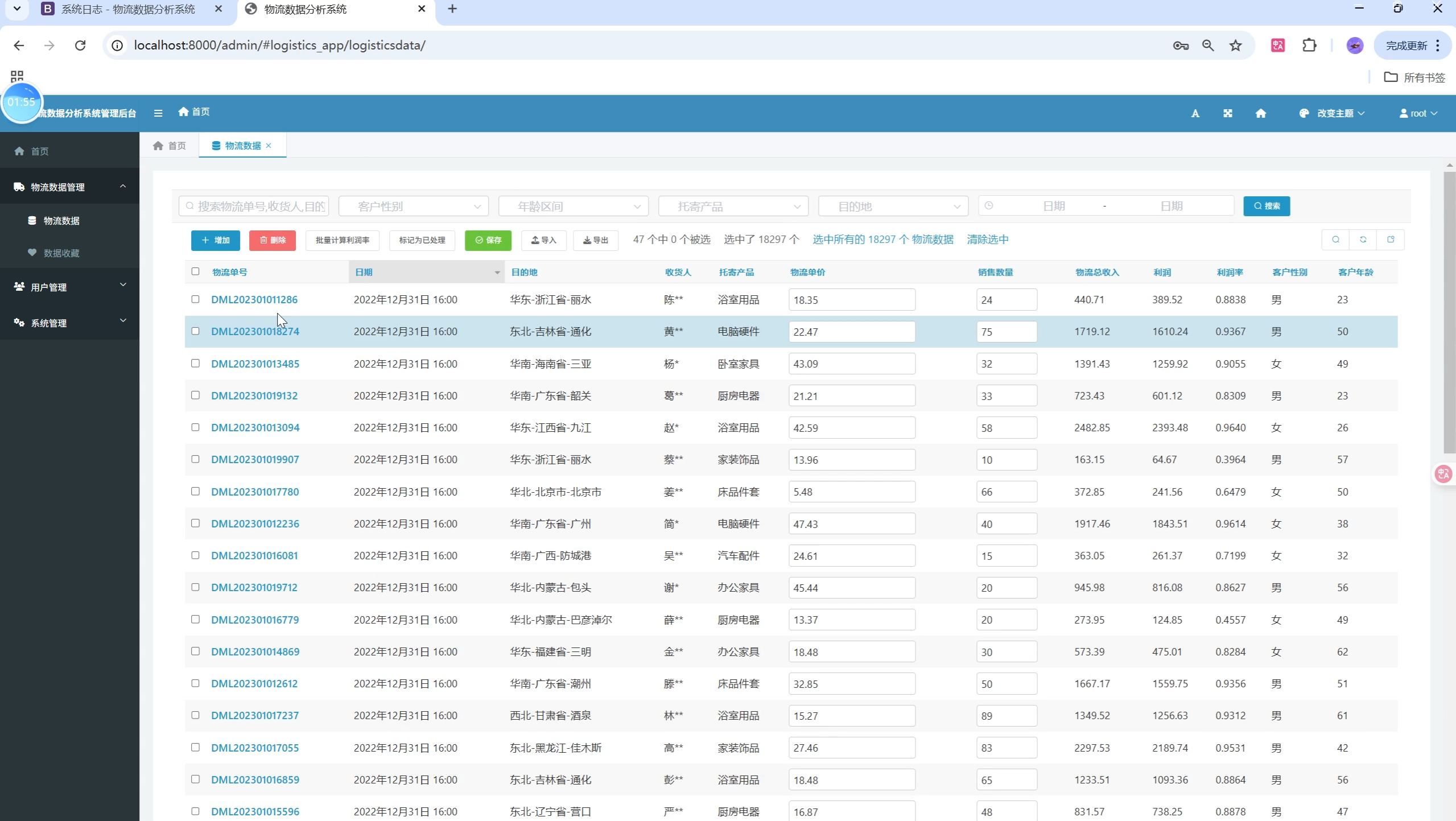
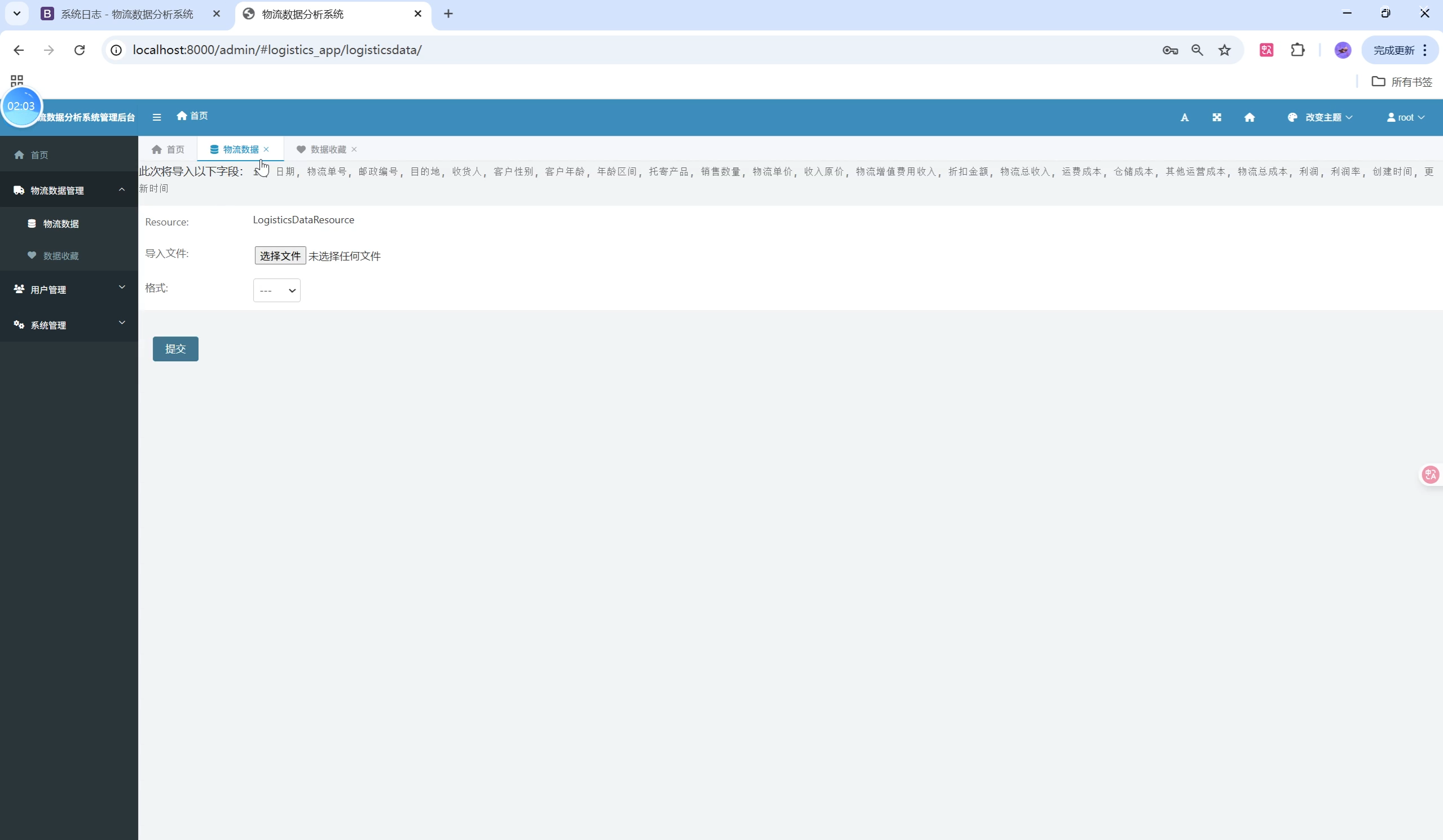
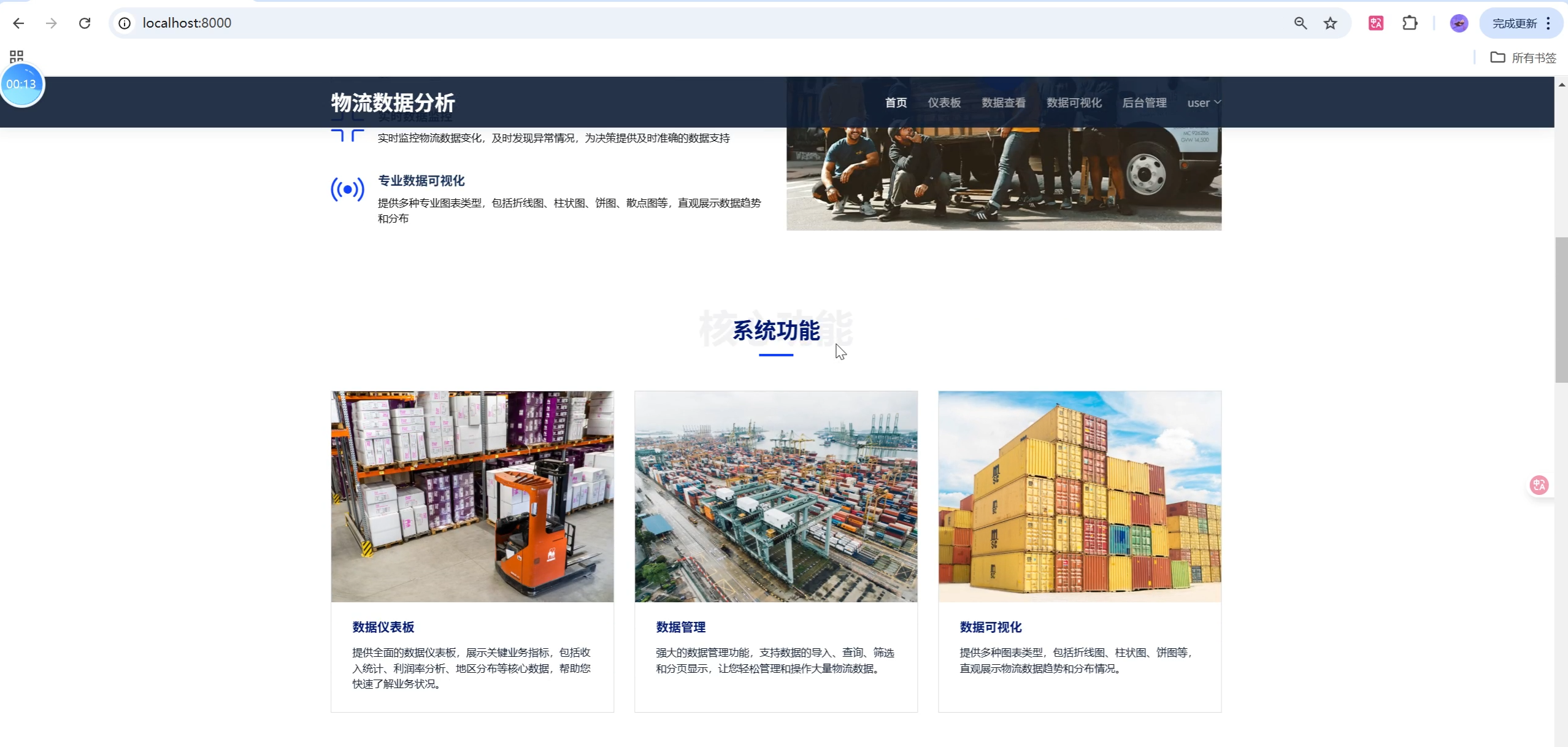
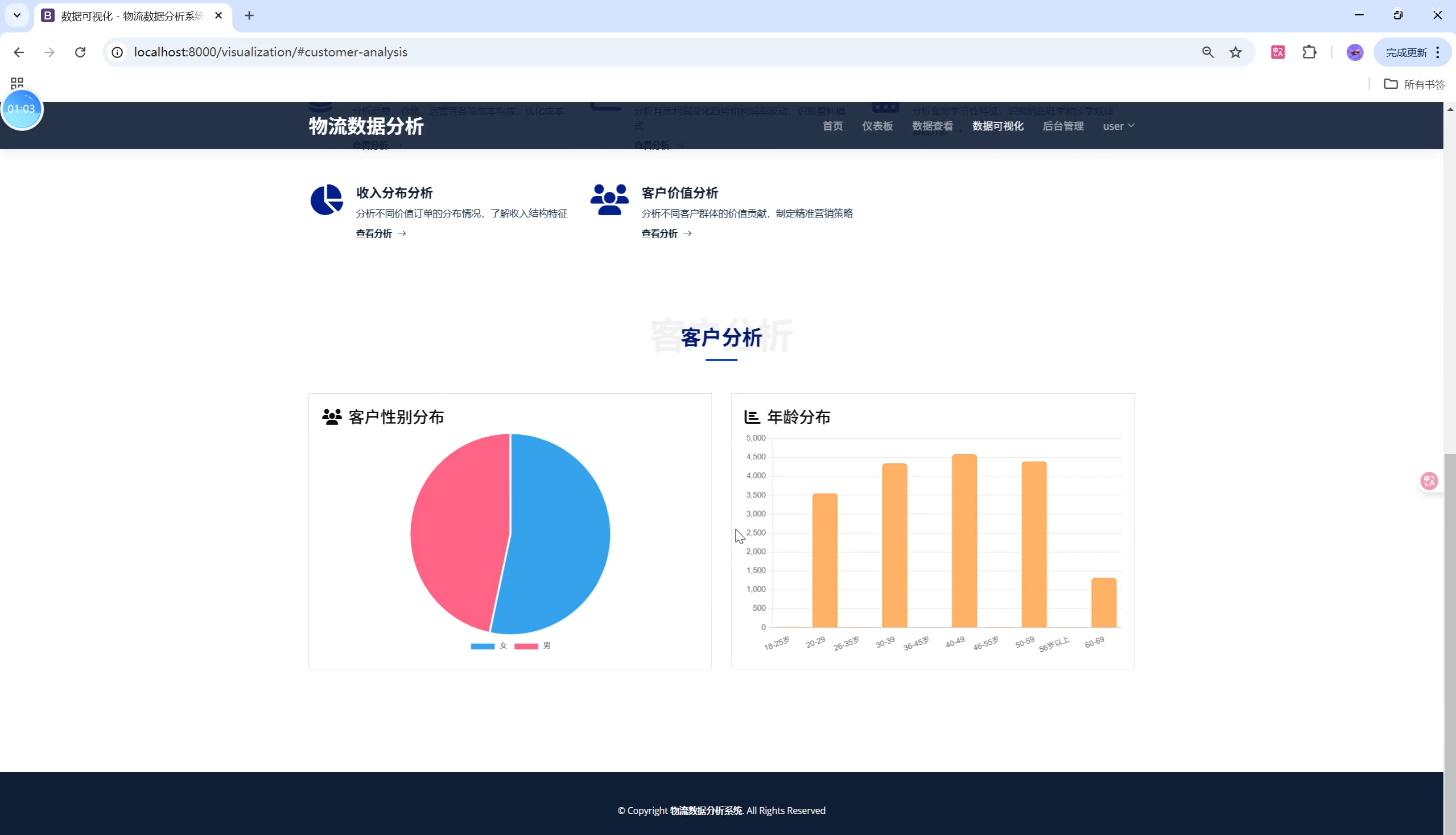
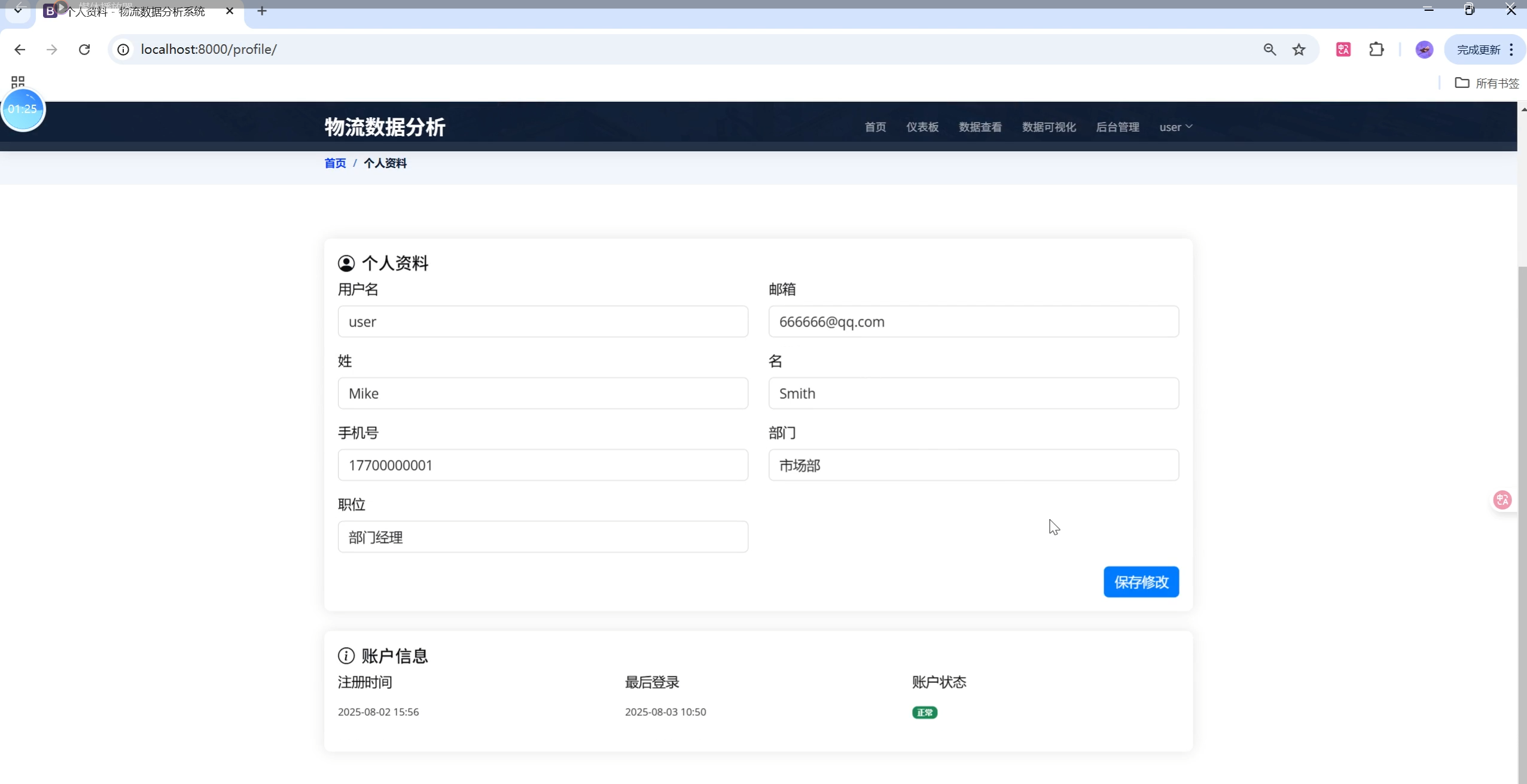
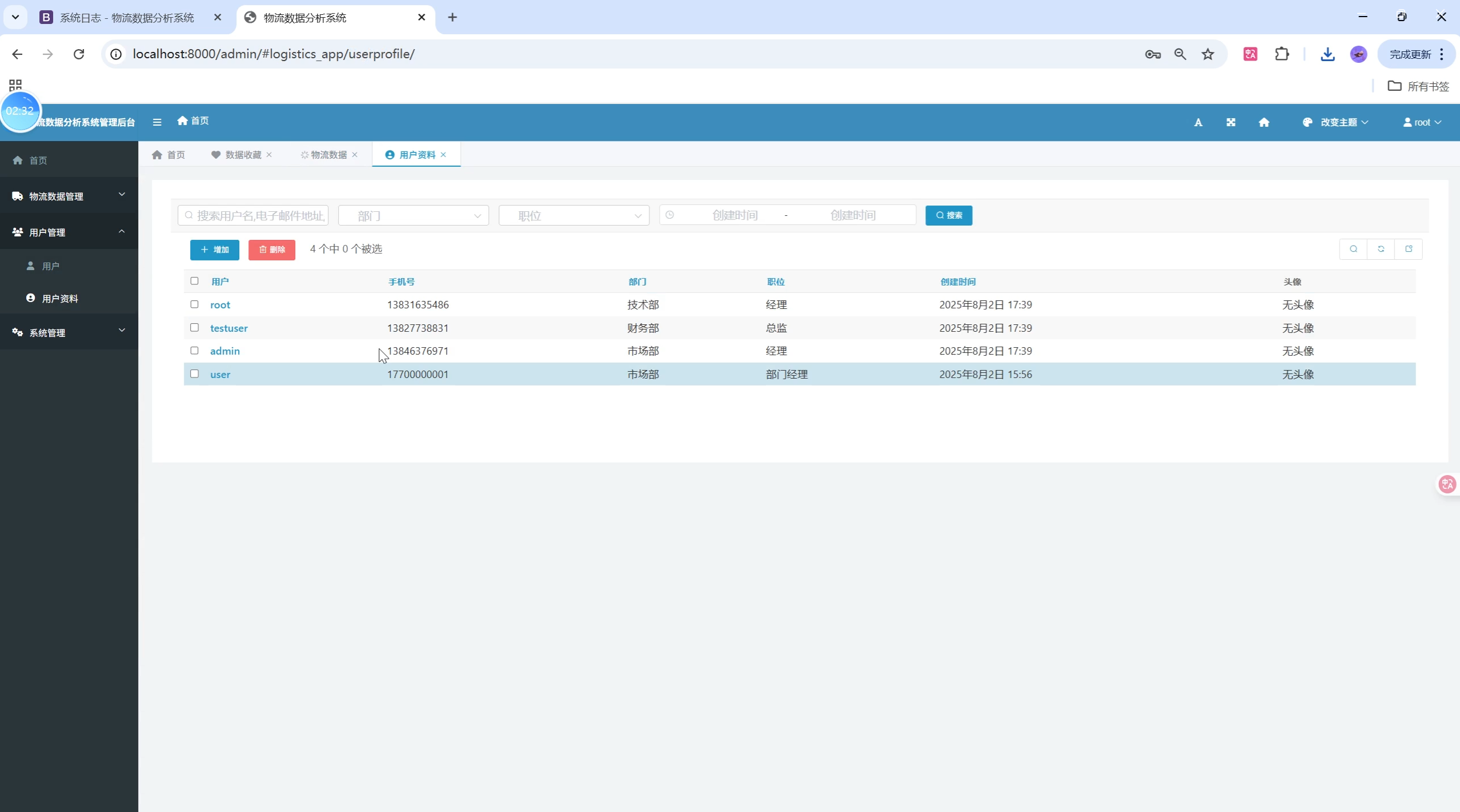
关键页面UI设计与用户体验优化
- 登录/注册页:极简风格,支持前后端双重表单校验,错误提示即时反馈。
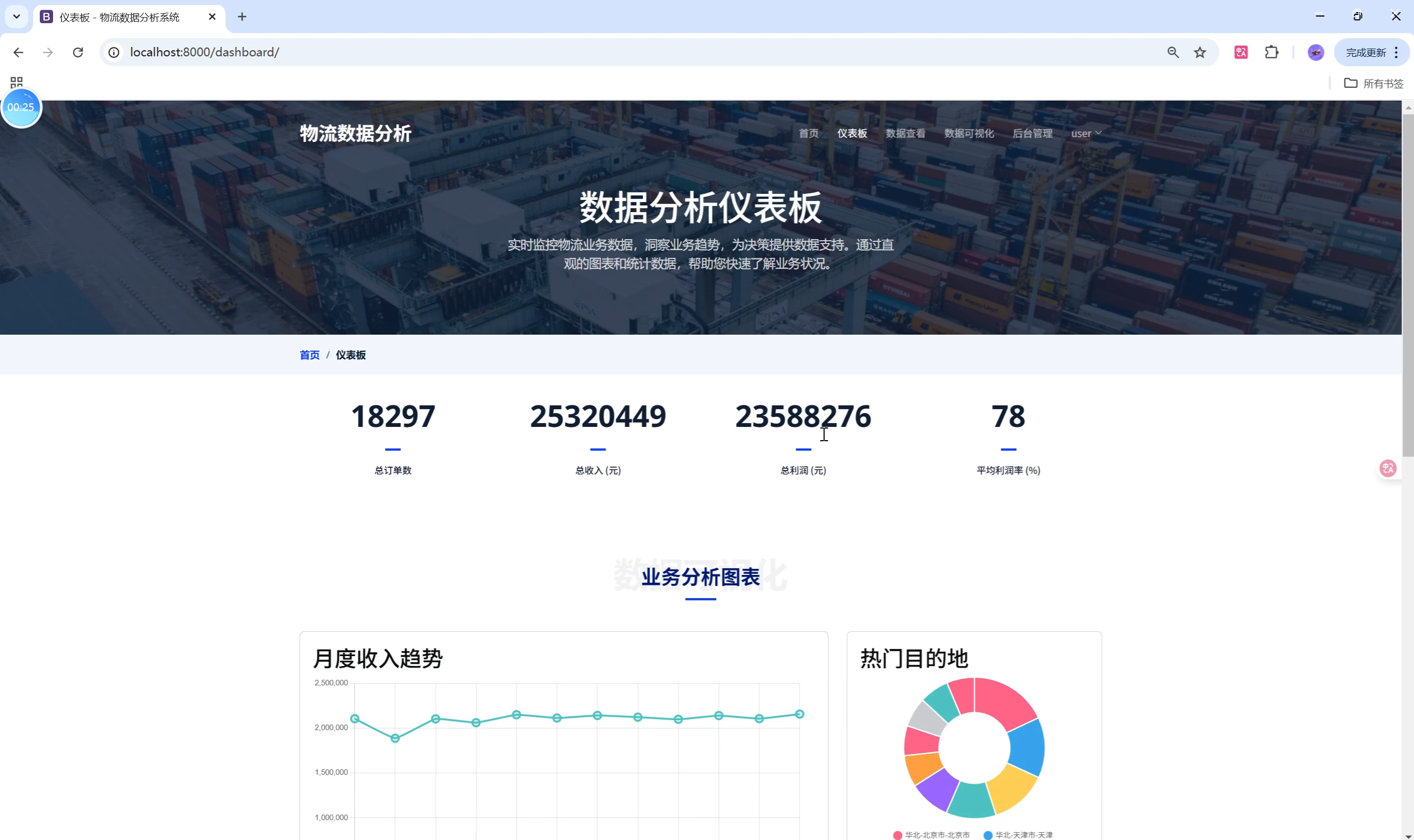
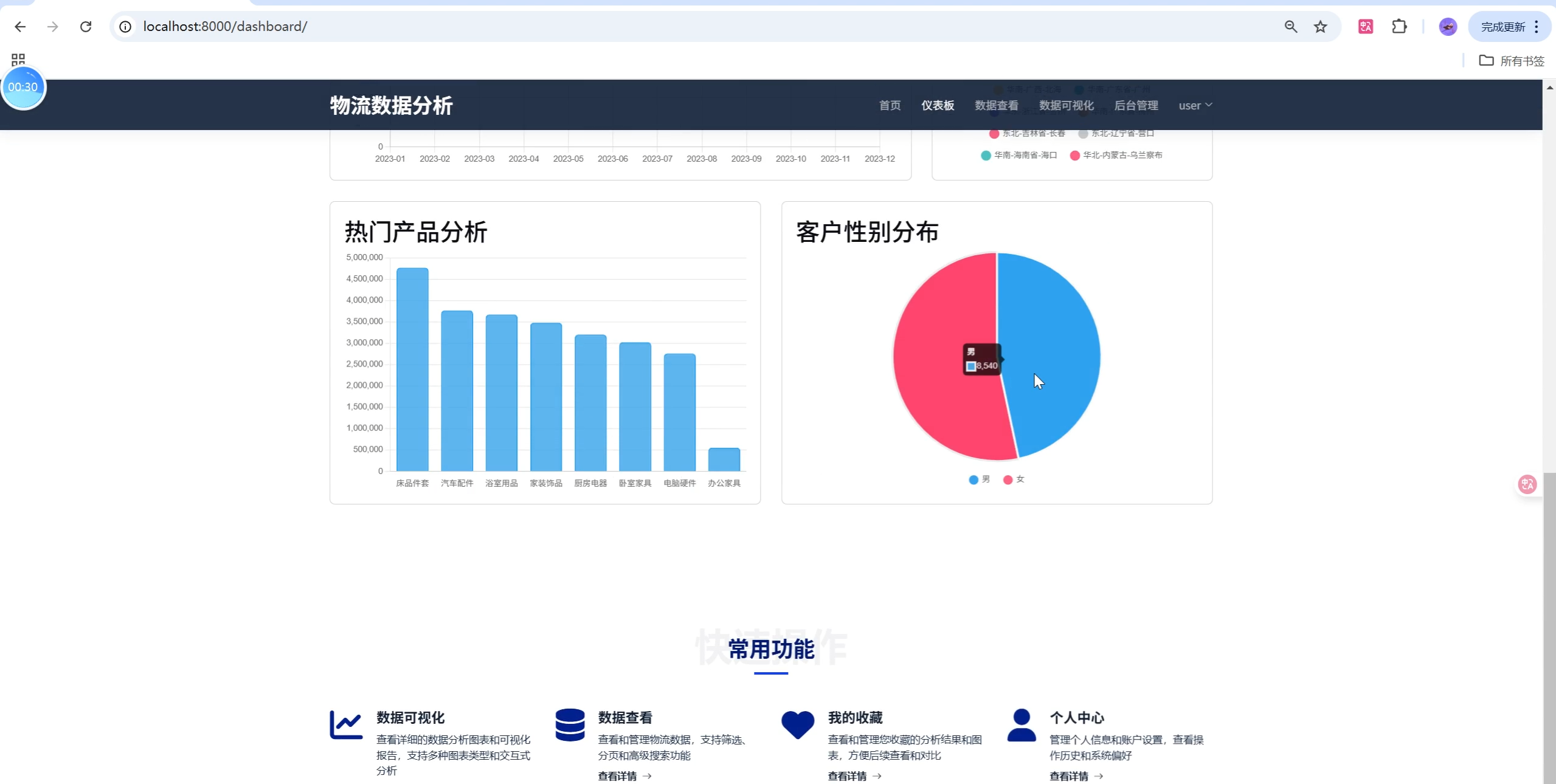
- 仪表板首页:卡片式布局,核心指标一目了然,图表支持缩放、悬停、筛选。
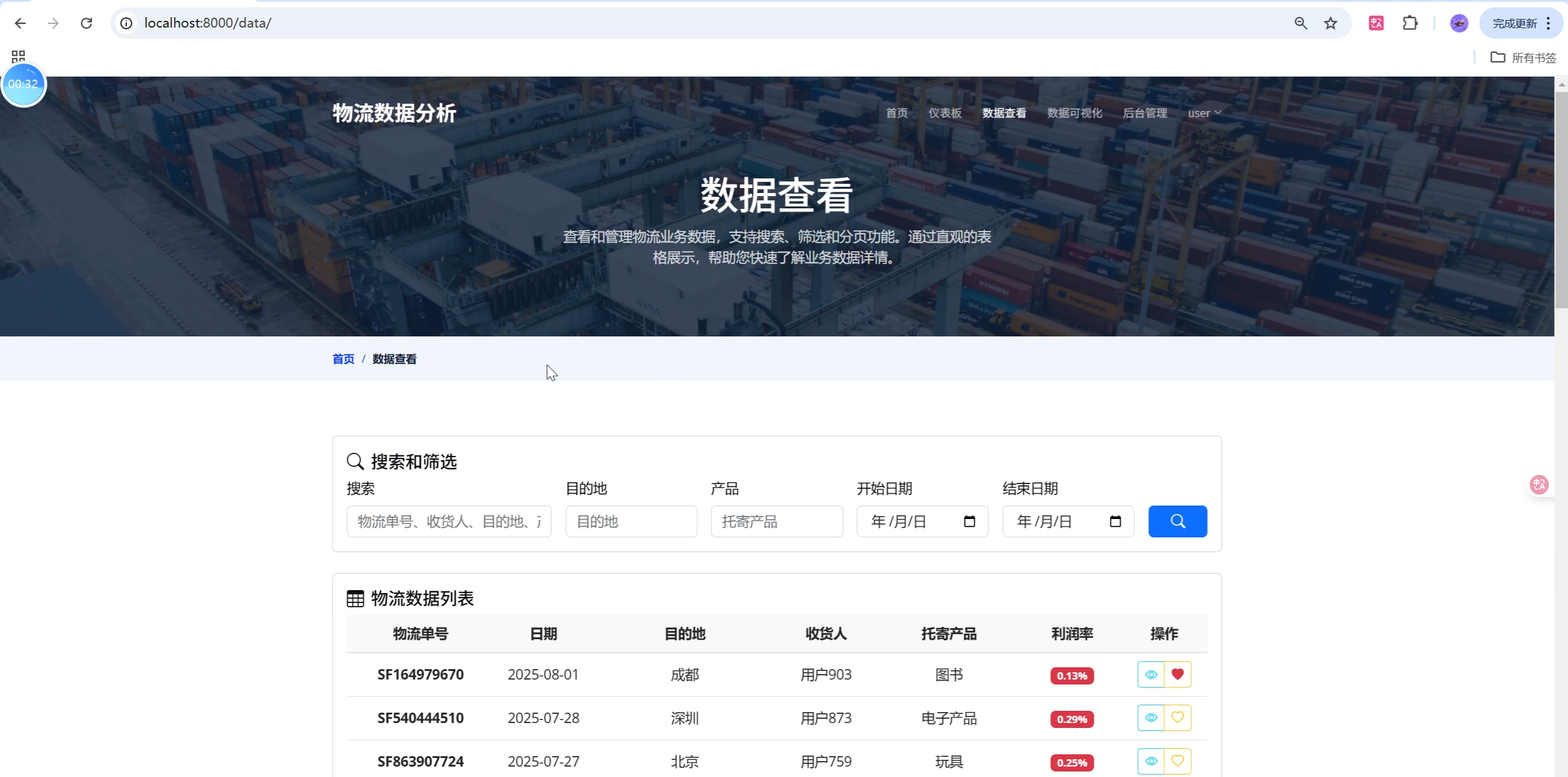
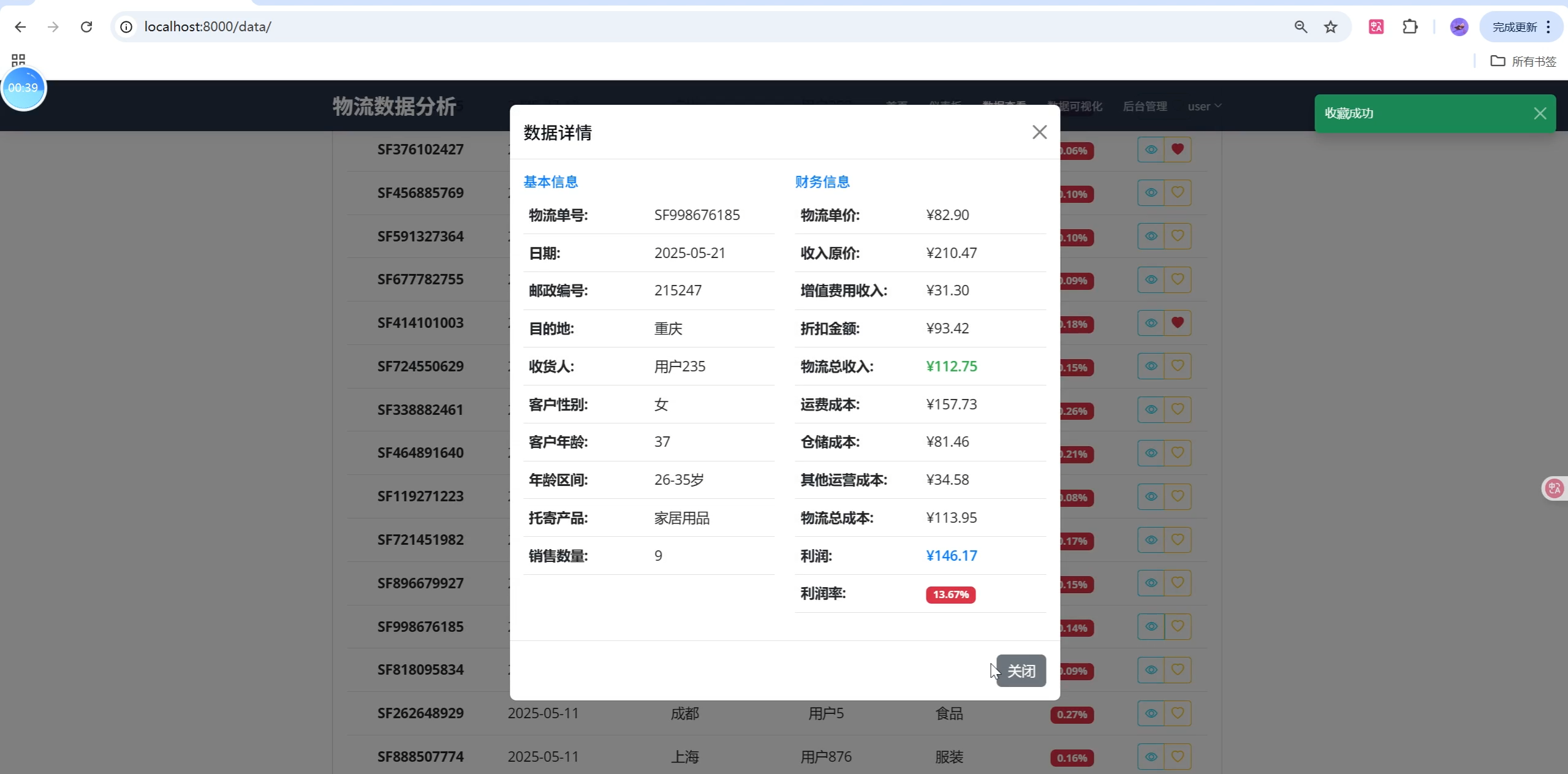
- 数据列表页:支持多条件筛选、分页、关键字搜索,表格交互流畅。
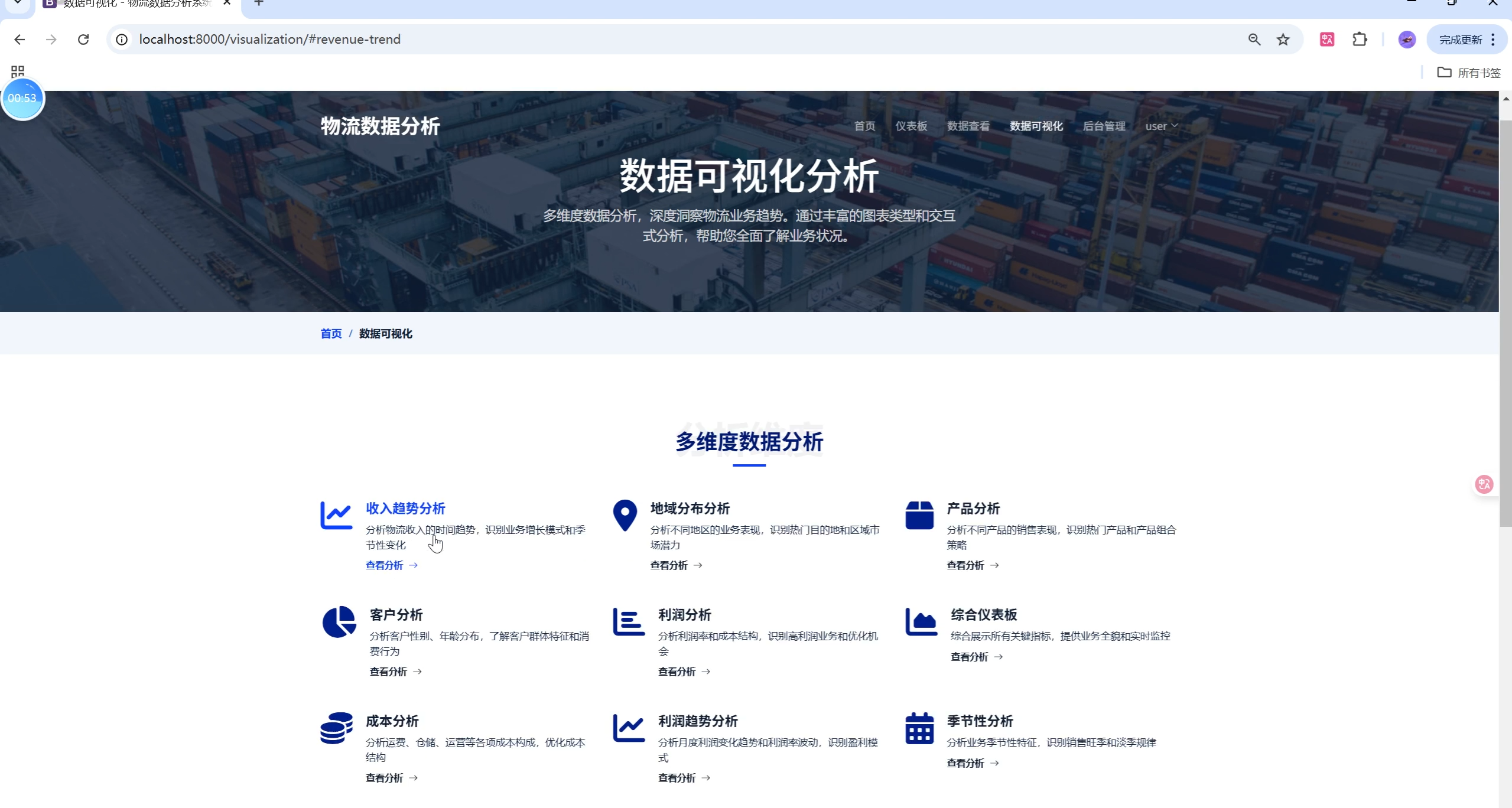
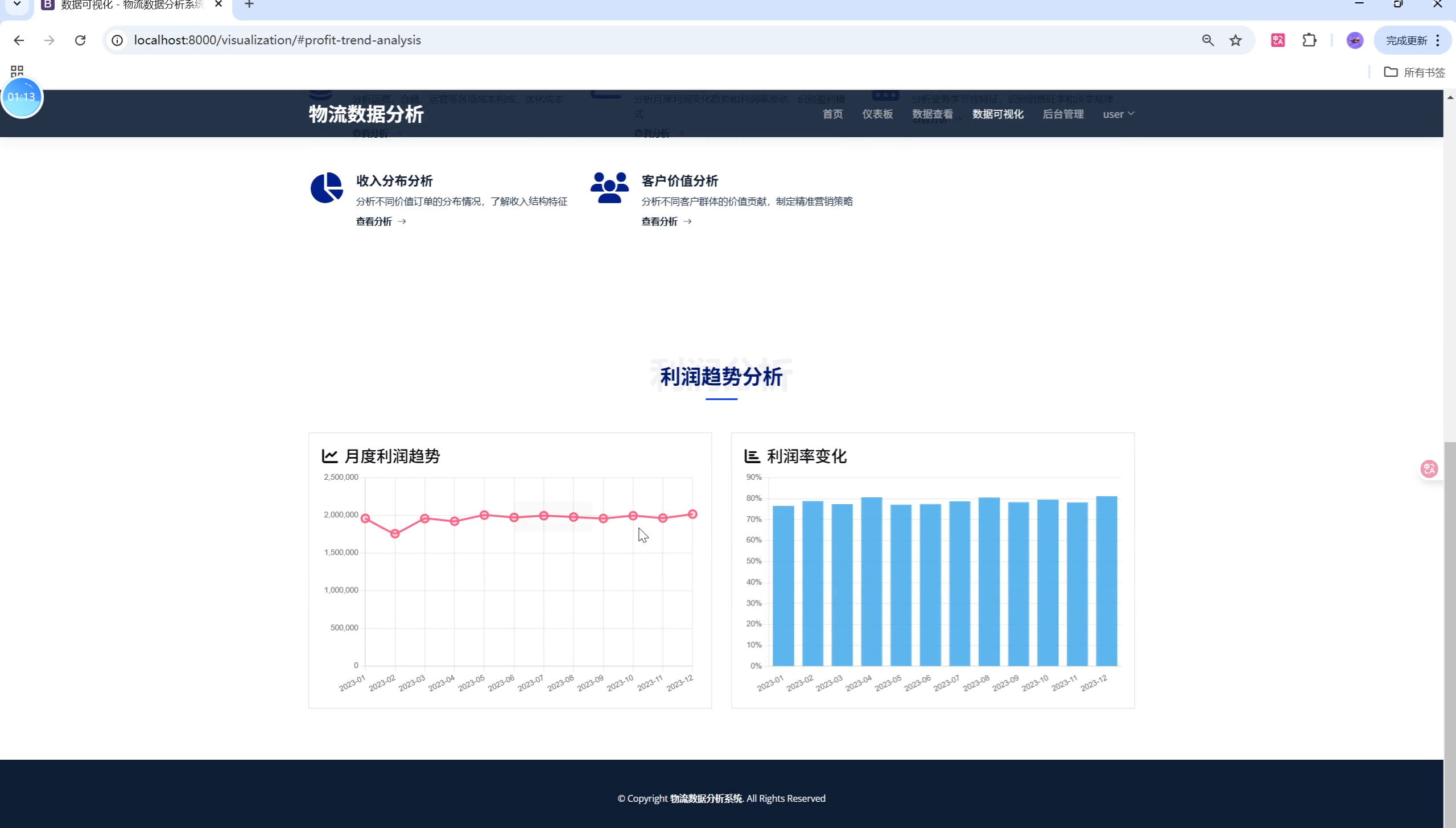
- 可视化分析页:多图表联动,支持导出图片,图例/标签自适应。
- 个人中心:资料编辑、收藏管理、操作日志一站式管理。
- 移动端适配:所有页面均采用响应式设计,兼容主流移动设备。
用户体验细节举例:
- 登录后自动跳转仪表板,欢迎语个性化
- 退出登录彻底清除会话和消息,防止信息泄露
- 图表加载时有loading动画,避免空白等待
- 表单输入错误自动聚焦到对应字段
主要功能模块
1. 用户与权限管理
- 用户注册、登录、身份验证、资料管理、权限控制、会话安全退出
- 完善的表单验证与错误提示
2. 物流数据管理
- 数据导入(支持CSV批量导入,自动清洗)
- 分页浏览、筛选、搜索、详情查看
- 数据收藏、收藏管理
3. 数据可视化分析
- 仪表板:关键指标、月度趋势、热门目的地/产品、客户分布
- 多类型图表:折线、柱状、饼图、散点、地区分布等
- 数据质量过滤(如每月≥100条、产品/目的地≥50条)
- 交互式图表,支持缩放、悬停、筛选
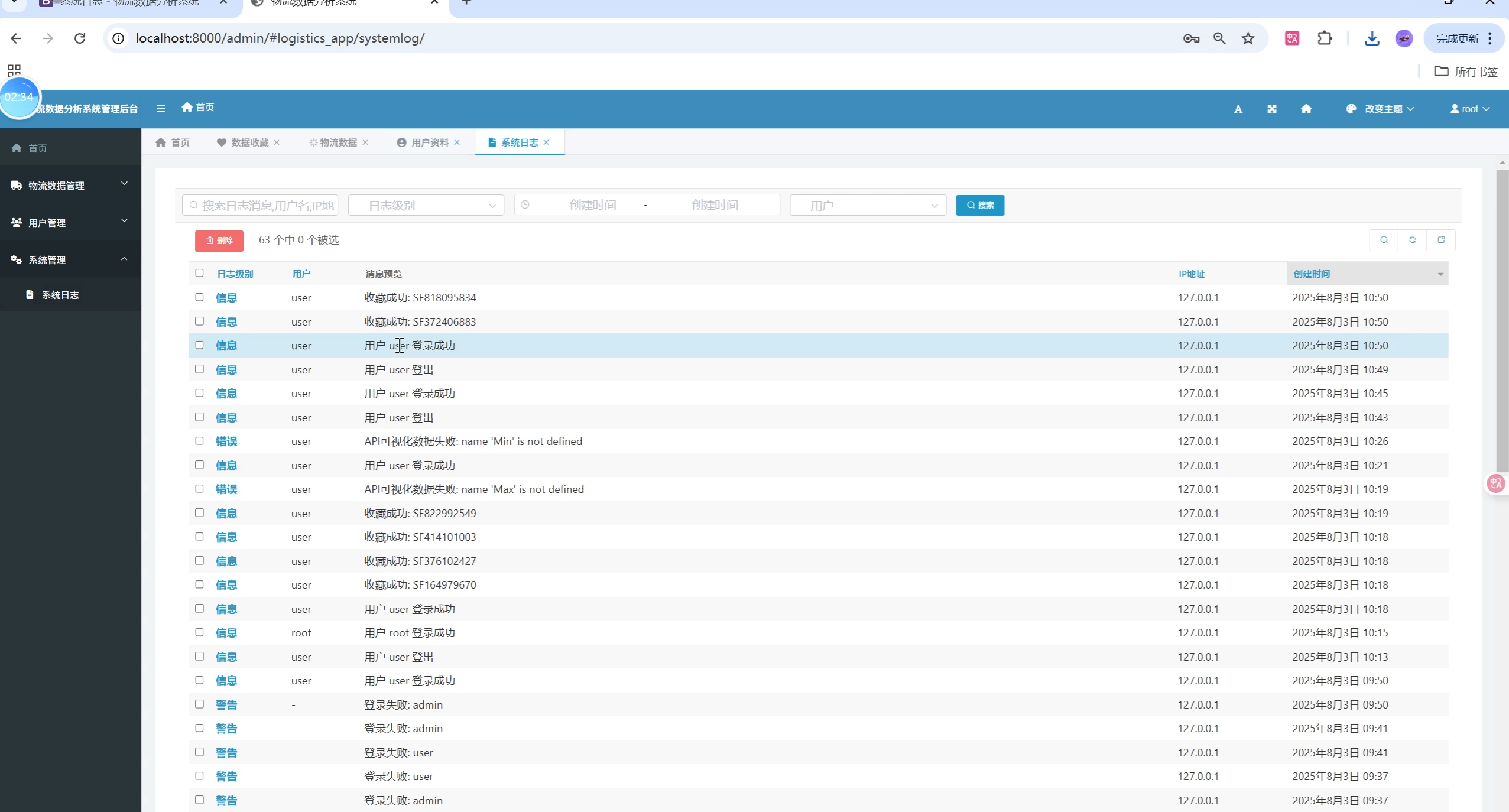
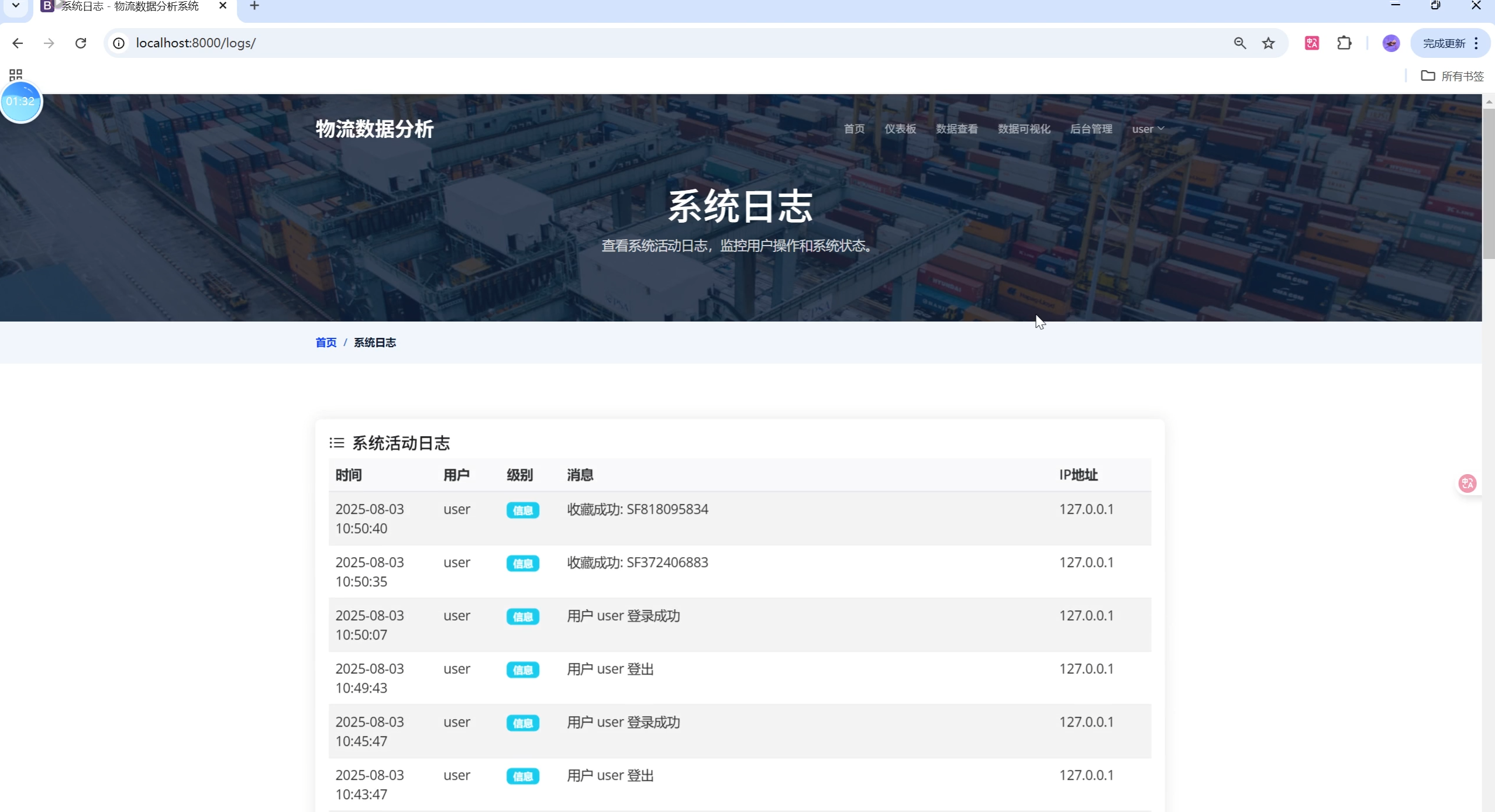
4. 系统管理与日志
- 日志记录、数据导出、系统监控、现代化后台
- 操作历史、错误日志、系统状态监控
5. 个人中心
- 个人信息、收藏管理、操作日志
6. API服务
- 仪表板、可视化、数据详情、收藏等API接口
数据安全与权限控制实践
- Django认证系统:所有敏感操作均需登录,未登录自动跳转登录页。
- 权限分级:普通用户、管理员、超级管理员多级权限,后台管理仅限授权用户。
- CSRF防护:所有POST请求均启用Django CSRF保护。
- 数据隔离:用户只能访问和操作自己的收藏、日志等私有数据。
- 日志追踪:所有关键操作(登录、登出、数据导入、收藏等)均有日志记录,便于审计。
数据导入与清洗
数据导入采用Django自定义管理命令,支持大批量CSV文件导入,并自动进行数据清洗和预处理:
python
def import_csv_data(csv_file_path):
df = pd.read_csv(csv_file_path, encoding='utf-8')
df['日期'] = pd.to_datetime(df['日期'])
# 处理缺失值、异常值等
df = df.dropna(subset=['日期', '物流单号', '目的地'])
# ...更多清洗逻辑
# 批量写入数据库
for _, row in df.iterrows():
LogisticsData.objects.create(...)数据质量过滤机制
项目实现了统一的数据质量过滤标准,确保所有图表和分析结果都基于高质量数据:
python
# 月度收入趋势过滤
monthly_revenue = LogisticsData.objects.extra(
select={'month': "DATE_FORMAT(日期, '%%Y-%%m')"}
).values('month').annotate(
revenue=Sum('物流总收入'),
profit=Sum('利润'),
count=Count('id')
).order_by('month')
filtered_monthly_revenue = [item for item in monthly_revenue if item['count'] >= 100]性能优化措施与测试方法
- 数据库优化:为常用筛选字段(日期、目的地、产品)添加索引,显著提升查询速度。
- 分页与懒加载:数据列表、图表数据均采用分页/懒加载,避免一次性加载大数据量。
- 缓存机制:对热门API接口和图表数据结果进行缓存,减少数据库压力。
- 前端异步加载:所有图表和数据均异步加载,提升页面响应速度。
- 自动化测试:编写单元测试、API测试脚本,持续集成保障质量。
测试代码示例:
python
def test_dashboard_api(self):
response = self.client.get('/api/dashboard-data/')
self.assertEqual(response.status_code, 200)
self.assertIn('monthly_data', response.json())前后端交互说明
- API接口:所有可视化和数据管理均通过RESTful API实现,前端通过AJAX/Fetch获取数据。
- 示例:获取月度收入趋势
javascript
fetch('/api/visualization-data/?type=revenue_trend')
.then(res => res.json())
.then(data => {
// 渲染Chart.js图表
new Chart(ctx, { ... });
});- API端点示例:
python
@csrf_exempt
@login_required
def api_visualization_data(request):
chart_type = request.GET.get('type', 'revenue_trend')
if chart_type == 'revenue_trend':
# ...见上方过滤代码
return JsonResponse({'data': list(filtered_monthly_revenue)})团队协作与敏捷开发流程
- 需求评审:与业务方反复沟通,梳理核心需求与优先级。
- 敏捷迭代:采用Scrum,每周迭代开发、评审、回顾。
- 代码管理:使用Git分支管理,PR审核,代码合并前自动化测试。
- 文档完善:每个模块、API、数据结构均有详细文档,便于新成员快速上手。
- 定期分享:团队每两周技术分享,交流难点与最佳实践。
可视化设计思路
- 仪表板:展示关键业务指标,采用卡片+图表布局,突出趋势与对比
- 趋势图:折线图展示月度收入/利润,过滤稀疏月份
- 分布图:饼图/柱状图展示热门目的地、产品、客户分布,过滤低频项
- 交互体验:所有图表支持悬停、缩放、筛选,提升数据探索效率
可视化图片展示(预留)
下方可插入系统实际运行时的可视化图表截图

部署与运维
-
克隆项目并进入目录
bashgit clone <项目地址> cd logistics-analysis-system -
创建虚拟环境并安装依赖
bashpython -m venv venv source venv/bin/activate # Windows下用 venv\Scripts\activate pip install -r requirements.txt -
配置数据库和环境变量,执行迁移
bashpython manage.py migrate python manage.py createsuperuser -
导入数据并运行服务
bashpython manage.py import_logistics_data python manage.py runserver -
可选:Docker部署、Nginx反代、静态文件优化
开发心得与难点
- 数据过滤与性能:如何在大数据量下高效过滤和聚合,避免前端卡顿和后端超时。
- 前后端分离:API接口标准化,前端异步渲染,提升用户体验。
- 可视化交互:Chart.js自定义配置,支持多种交互操作。
- 用户体验:表单验证、消息提示、错误处理、会话安全等细节打磨。
- 团队协作:代码规范、模块分工、文档完善,便于后期维护和扩展。
未来展望
- 增加AI预测分析、智能推荐等高级功能
- 支持多租户和更细粒度的权限管理
- 优化大数据量下的查询和渲染性能
- 丰富可视化图表类型,支持自定义报表
- 移动端适配与PWA支持
结语与个人成长收获
本项目让我深刻体会到数据驱动决策的力量,也锻炼了我在全栈开发、团队协作、需求分析、性能优化等多方面的能力。希望这份分享能为有类似需求的开发者和团队提供参考和启发。
全等细节打磨。
- 团队协作:代码规范、模块分工、文档完善,便于后期维护和扩展。
未来展望
- 增加AI预测分析、智能推荐等高级功能
- 支持多租户和更细粒度的权限管理
- 优化大数据量下的查询和渲染性能
- 丰富可视化图表类型,支持自定义报表
- 移动端适配与PWA支持
结语与个人成长收获
本项目让我深刻体会到数据驱动决策的力量,也锻炼了我在全栈开发、团队协作、需求分析、性能优化等多方面的能力。希望这份分享能为有类似需求的开发者和团队提供参考和启发。
欢迎交流、建议与Star!