**作业:**day43的时候我们安排大家对自己找的数据集用简单cnn训练,现在可以尝试下借助这几天的知识来实现精度的进一步提高
数据预处理
python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import os
from sklearn.model_selection import train_test_split
from shutil import copyfile
data_root = "flowers" # 数据集根目录
classes = ["daisy", "tulip", "rose", "sunflower", "dandelion"]
for folder in ["train", "val", "test"]:
os.makedirs(os.path.join(data_root, folder), exist_ok=True)
# 数据集划分
for cls in classes:
cls_path = os.path.join(data_root, cls)
if not os.path.isdir(cls_path):
raise FileNotFoundError(f"类别文件夹{cls}不存在!请检查数据集路径。")
imgs = [f for f in os.listdir(cls_path) if f.lower().endswith((".jpg", ".jpeg", ".png"))]
if not imgs:
raise ValueError(f"类别{cls}中没有图片文件!")
# 划分数据集(测试集20%,验证集20% of 剩余数据,训练集60%)
train_val, test = train_test_split(imgs, test_size=0.2, random_state=42)
train, val = train_test_split(train_val, test_size=0.25, random_state=42) # 0.8*0.25=0.2(验证集占比)
# 复制到train/val/test下的类别子文件夹
for split, imgs_list in zip(["train", "val", "test"], [train, val, test]):
split_class_path = os.path.join(data_root, split, cls)
os.makedirs(split_class_path, exist_ok=True)
for img in imgs_list:
src_path = os.path.join(cls_path, img)
dst_path = os.path.join(split_class_path, img)
copyfile(src_path, dst_path)
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 训练集数据增强
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomCrop(224, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
# 测试集预处理
test_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
# 加载数据集
train_dataset = datasets.ImageFolder(
root=os.path.join(data_root, "train"),
transform=train_transform
)
val_dataset = datasets.ImageFolder(
root=os.path.join(data_root, "val"),
transform=test_transform
)
test_dataset = datasets.ImageFolder(
root=os.path.join(data_root, "test"),
transform=test_transform
)
# 创建数据加载器
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=2)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=2)
# 获取类别名称
class_names = train_dataset.classes
print(f"检测到的类别: {class_names}")通道注意力
python
class ChannelAttention(nn.Module):
"""通道注意力模块(Squeeze-and-Excitation)"""
def __init__(self, in_channels, reduction_ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(in_channels, in_channels // reduction_ratio, bias=False),
nn.ReLU(inplace=True),
nn.Linear(in_channels // reduction_ratio, in_channels, bias=False),
nn.Sigmoid()
)
def forward(self, x):
batch_size, channels, _, _ = x.size()
avg_pool_output = self.avg_pool(x).view(batch_size, channels)
channel_weights = self.fc(avg_pool_output).view(batch_size, channels, 1, 1)
return x * channel_weights空间注意力
python
class SpatialAttention(nn.Module):
"""空间注意力模块"""
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 沿通道维度计算均值和最大值
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
# 拼接均值和最大值特征
concat = torch.cat([avg_out, max_out], dim=1)
# 卷积操作生成空间注意力图
spatial_att = self.conv(concat)
spatial_att = self.sigmoid(spatial_att)
# 应用空间注意力
return x * spatial_attCBAM注意力
python
class CBAM(nn.Module):
"""CBAM注意力模块:结合通道注意力和空间注意力"""
def __init__(self, in_channels, reduction_ratio=16, kernel_size=7):
super(CBAM, self).__init__()
self.channel_attention = ChannelAttention(in_channels, reduction_ratio)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
# 先应用通道注意力
x = self.channel_attention(x)
# 再应用空间注意力
x = self.spatial_attention(x)
return x定义带CBAM的ResNet18模型
python
class FlowerCNN(nn.Module):
def __init__(self, num_classes=5):
super(FlowerCNN, self).__init__()
# 加载预训练ResNet18
resnet = models.resnet18(pretrained=True)
# 构建特征提取器,在每个残差块阶段后插入CBAM模块
self.features = nn.Sequential(
resnet.conv1,
resnet.bn1,
resnet.relu,
resnet.maxpool,
resnet.layer1, # 输出通道64
CBAM(64), # CBAM模块(64通道)
resnet.layer2, # 输出通道128
CBAM(128), # CBAM模块(128通道)
resnet.layer3, # 输出通道256
CBAM(256), # CBAM模块(256通道)
resnet.layer4, # 输出通道512
CBAM(512) # CBAM模块(512通道)
)
self.gap = nn.AdaptiveAvgPool2d(1)
# 自定义分类头
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(512, num_classes)
)
def forward(self, x):
x = self.features(x)
x = self.gap(x)
x = self.fc(x)
return x初始化模型
python
model = FlowerCNN(num_classes=5).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', patience=3)
def train_model(model, train_loader, val_loader, epochs=10):
best_val_acc = 0.0
train_loss_history = []
val_loss_history = []
train_acc_history = []
val_acc_history = []
for epoch in range(epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(data)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
if (batch_idx+1) % 50 == 0:
print(f"Epoch [{epoch+1}/{epochs}] Batch {batch_idx+1}/{len(train_loader)} "
f"Loss: {loss.item():.4f} Acc: {(100*correct/total):.2f}%")
epoch_train_loss = running_loss / len(train_loader)
epoch_train_acc = 100. * correct / total
# 验证集评估
model.eval()
val_loss = 0.0
val_correct = 0
val_total = 0
with torch.no_grad():
for data, target in val_loader:
data, target = data.to(device), target.to(device)
outputs = model(data)
val_loss += criterion(outputs, target).item()
_, predicted = torch.max(outputs.data, 1)
val_total += target.size(0)
val_correct += (predicted == target).sum().item()
epoch_val_loss = val_loss / len(val_loader)
epoch_val_acc = 100. * val_correct / val_total
scheduler.step(epoch_val_loss)
train_loss_history.append(epoch_train_loss)
val_loss_history.append(epoch_val_loss)
train_acc_history.append(epoch_train_acc)
val_acc_history.append(epoch_val_acc)
print(f"Epoch {epoch+1} 完成 | 训练损失: {epoch_train_loss:.4f} 验证准确率: {epoch_val_acc:.2f}%")
if epoch_val_acc > best_val_acc:
torch.save(model.state_dict(), "best_flower_model.pth")
best_val_acc = epoch_val_acc
print("保存最佳模型...")
# 绘制训练曲线
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_loss_history, label='训练损失')
plt.plot(val_loss_history, label='验证损失')
plt.title('损失曲线')
plt.xlabel('Epoch')
plt.ylabel('损失值')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(train_acc_history, label='训练准确率')
plt.plot(val_acc_history, label='验证准确率')
plt.title('准确率曲线')
plt.xlabel('Epoch')
plt.ylabel('准确率 (%)')
plt.legend()
plt.tight_layout()
plt.show()
return best_val_acc训练模型
python
print("开始训练...")
final_acc = train_model(model, train_loader, val_loader, epochs=15)
print(f"训练完成!最佳验证准确率: {final_acc:.2f}%")
from torch.nn import functional as F
import cv2
import numpy as np
import torchvision.transforms as transforms
class GradCAM:
def __init__(self, model, target_layer_name="features.10.1.conv2"):
"""
target_layer_name说明:
- features.10 对应resnet.layer4(索引10)
- .1.conv2 对应layer4中第二个残差块的第二个卷积层
"""
self.model = model.eval()
self.target_layer_name = target_layer_name
self.gradients = None
self.activations = None
for name, module in model.named_modules():
if name == target_layer_name:
module.register_forward_hook(self.forward_hook)
module.register_backward_hook(self.backward_hook)
break
def forward_hook(self, module, input, output):
self.activations = output.detach()
def backward_hook(self, module, grad_input, grad_output):
self.gradients = grad_output[0].detach()
def generate(self, input_image, target_class=None):
outputs = self.model(input_image)
if target_class is None:
target_class = torch.argmax(outputs, dim=1).item()
self.model.zero_grad()
one_hot = torch.zeros_like(outputs)
one_hot[0, target_class] = 1
outputs.backward(gradient=one_hot)
gradients = self.gradients
activations = self.activations
weights = torch.mean(gradients, dim=(2, 3))
cam = torch.sum(activations[0] * weights[0][:, None, None], dim=0)
cam = F.relu(cam)
cam = (cam - cam.min()) / (cam.max() - cam.min() + 1e-8)
cam = F.interpolate(
cam.unsqueeze(0).unsqueeze(0),
size=(224, 224),
mode='bilinear',
align_corners=False
).squeeze()
return cam.cpu().numpy(), target_class
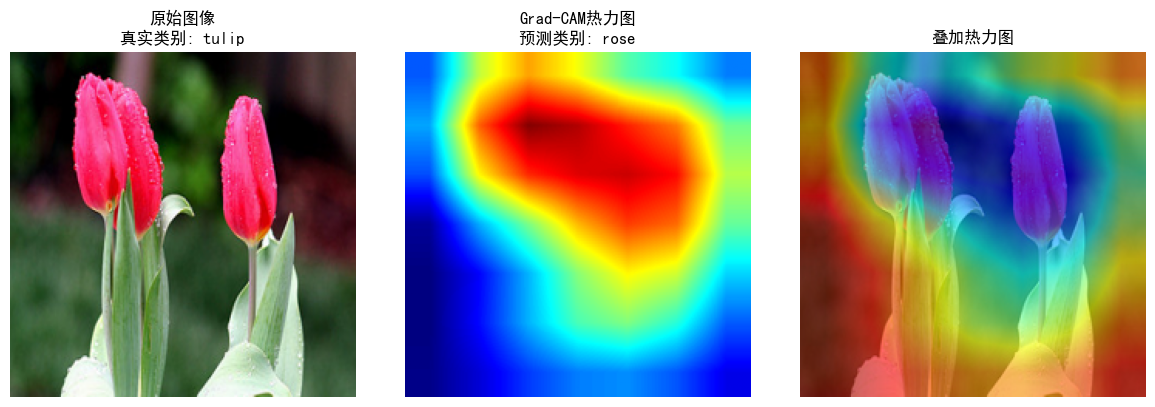
def visualize_gradcam(img_path, model, class_names, alpha=0.6):
img = Image.open(img_path).convert("RGB")
img = img.resize((224, 224))
img_np = np.array(img) / 255.0
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(
mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225)
)
])
input_tensor = transform(img).unsqueeze(0).to(device)
grad_cam = GradCAM(model, target_layer_name="features.10.1.conv2")
heatmap, pred_class = grad_cam.generate(input_tensor)
heatmap = np.uint8(255 * heatmap)
heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET)
heatmap = heatmap / 255.0
heatmap_rgb = heatmap[:, :, ::-1]
superimposed = cv2.addWeighted(img_np, 1 - alpha, heatmap, alpha, 0)
plt.figure(figsize=(12, 4))
plt.subplot(1, 3, 1)
plt.imshow(img_np)
plt.title(f"原始图像\n真实类别: {img_path.split('/')[-2]}")
plt.axis('off')
plt.subplot(1, 3, 2)
plt.imshow(heatmap_rgb)
plt.title(f"Grad-CAM热力图\n预测类别: {class_names[pred_class]}")
plt.axis('off')
plt.subplot(1, 3, 3)
plt.imshow(superimposed)
plt.title("叠加热力图")
plt.axis('off')
plt.tight_layout()
plt.show()
python
开始训练...
Epoch [1/15] Batch 50/81 Loss: 0.6559 Acc: 70.81%
Epoch 1 完成 | 训练损失: 0.7685 验证准确率: 62.54%
保存最佳模型...
Epoch [2/15] Batch 50/81 Loss: 0.4877 Acc: 79.75%
Epoch 2 完成 | 训练损失: 0.5815 验证准确率: 72.83%
保存最佳模型...
Epoch [3/15] Batch 50/81 Loss: 0.4116 Acc: 82.88%
Epoch 3 完成 | 训练损失: 0.4738 验证准确率: 83.24%
保存最佳模型...
Epoch [4/15] Batch 50/81 Loss: 0.3755 Acc: 85.00%
Epoch 4 完成 | 训练损失: 0.4515 验证准确率: 82.31%
Epoch [5/15] Batch 50/81 Loss: 0.6060 Acc: 85.81%
Epoch 5 完成 | 训练损失: 0.3845 验证准确率: 75.84%
Epoch [6/15] Batch 50/81 Loss: 0.4477 Acc: 86.94%
Epoch 6 完成 | 训练损失: 0.3705 验证准确率: 82.77%
Epoch [7/15] Batch 50/81 Loss: 0.3701 Acc: 89.38%
Epoch 7 完成 | 训练损失: 0.3345 验证准确率: 84.97%
保存最佳模型...
Epoch [8/15] Batch 50/81 Loss: 0.2666 Acc: 89.75%
Epoch 8 完成 | 训练损失: 0.3281 验证准确率: 83.93%
Epoch [9/15] Batch 50/81 Loss: 0.1533 Acc: 89.44%
Epoch 9 完成 | 训练损失: 0.3294 验证准确率: 83.47%
Epoch [10/15] Batch 50/81 Loss: 0.2991 Acc: 90.94%
Epoch 10 完成 | 训练损失: 0.2643 验证准确率: 83.82%
Epoch [11/15] Batch 50/81 Loss: 0.4048 Acc: 90.94%
Epoch 11 完成 | 训练损失: 0.2640 验证准确率: 89.25%
保存最佳模型...
Epoch [12/15] Batch 50/81 Loss: 0.1055 Acc: 92.50%
Epoch 12 完成 | 训练损失: 0.2396 验证准确率: 81.62%
Epoch [13/15] Batch 50/81 Loss: 0.3020 Acc: 92.81%
Epoch 13 完成 | 训练损失: 0.2298 验证准确率: 83.24%
Epoch [14/15] Batch 50/81 Loss: 0.1166 Acc: 92.69%
Epoch 14 完成 | 训练损失: 0.2228 验证准确率: 86.47%
Epoch [15/15] Batch 50/81 Loss: 0.1193 Acc: 93.38%
Epoch 15 完成 | 训练损失: 0.2004 验证准确率: 85.43%
训练完成!最佳验证准确率: 89.25%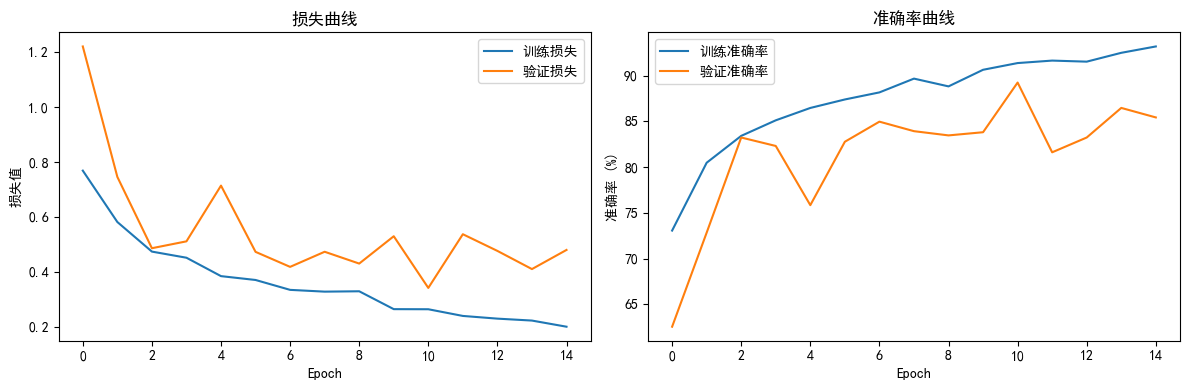
选择训练图像
python
test_image_path = "flowers/tulip/100930342_92e8746431_n.jpg"
visualize_gradcam(test_image_path, model, class_names)