🎯 什么是RAG系统?
简单理解
RAG(Retrieval-Augmented Generation)就像是一个超级图书管理员:
- 用户问问题 → 管理员去书架上找相关书籍 → 阅读内容 → 给出答案
传统方式 vs RAG方式
传统AI回答:
用户:"苹果怎么种植?"
AI:基于训练数据直接回答(可能过时或不准确)
RAG方式:
用户:"苹果怎么种植?"
AI:检索最新的种植指南 → 阅读具体内容 → 给出准确答案
⚠️ RAG系统的性能瓶颈
主要问题:重复计算
每次用户问问题,AI都要:
- 重新读取文档内容
- 重新计算所有token的KV Cache
- 重新处理注意力机制
量化数据对比
传统RAG处理速度:
- 短文档(1000字):2-3秒
- 中等文档(5000字):8-12秒
- 长文档(20000字):25-35秒
问题:相同文档被多次查询时,每次都重新计算!
实际场景举例
场景:客服系统处理常见问题
问题1:"如何重置密码?" → 检索密码重置文档 → 计算KV Cache → 回答
问题2:"密码重置后多久生效?" → 检索相同文档 → 重新计算KV Cache → 回答
问题3:"忘记密码怎么办?" → 检索相同文档 → 再次重新计算KV Cache → 回答
结果:同一个文档被重复计算3次,浪费了大量计算资源!
🚀 CacheBlend:智能缓存解决方案
核心思想
"能复用的尽量复用,重要的联系要恢复"
就像聪明的学生:
- 不是每次考试都重新复习所有内容
- 而是记住大部分内容,重点复习知识点之间的关联
工作原理图解
第一次查询:"苹果怎么种植?"
↓
检索到:种植指南分片1, 种植指南分片2, 种植指南分片3
↓
计算KV Cache并缓存
↓
生成回答
第二次查询:"苹果怎么种植和烹饪?"
↓
检索到:种植指南分片1, 种植指南分片2, 种植指南分片3, 烹饪方法分片1
↓
智能复用:种植相关的分片缓存 ✓
位置调整:动态调整到新位置 ✓
新增计算:只计算烹饪方法分片 ✓
↓
拼接结果,生成完整回答
🔧 技术原理详解
-
知识分片存储结构
知识库(类似图书馆)
├── 文档1:苹果种植指南
│ ├── 分片1:苹果品种介绍(1000字)
│ ├── 分片2:种植环境要求(800字)
│ └── 分片3:种植步骤(1200字)
├── 文档2:苹果烹饪方法
│ ├── 分片4:苹果挑选技巧(600字)
│ └── 分片5:烹饪食谱(1500字)
└── 文档3:苹果营养知识
├── 分片6:营养成分(700字)
└── 分片7:健康功效(900字)
-
前缀匹配算法
可复用的前缀识别:
当前查询:分片1, 分片2, 分片3, 分片4
缓存序列:分片1, 分片2, 分片3, 分片6
匹配结果:
- 公共前缀:分片1, 分片2, 分片3 ✓ 长度=3
- 可复用比例:3/4 = 75%
- 节省计算:75%的KV Cache可以复用
- 位置编码修正(RoPE技术)
位置调整示例:
分片3在缓存中的位置:位置2
分片3在新序列中的位置:位置2
位置映射:
- 位置0:分片1(复用缓存)
- 位置1:分片2(复用缓存)
- 位置2:分片3(复用缓存,位置相同)
- 位置3:分片4(需要重新计算)
结果:分片3可以直接复用,无需位置调整!
💡 实际应用案例
案例1:客服知识库系统
系统配置:
- 知识库:1000个常见问题文档
- 平均文档长度:2000字
- 日查询量:5000次
- 重复查询率:60%
传统RAG性能:
- 平均响应时间:8秒
- 计算资源消耗:100%
- 用户满意度:75%
使用CacheBlend后:
- 平均响应时间:3秒(提升62.5%)
- 计算资源消耗:35%(节省65%)
- 用户满意度:92%(提升17%)
案例2:法律文档分析系统
系统特点:
- 法律条文经常被引用
- 相同条款在不同案例中重复出现
- 需要保持上下文完整性
性能提升:
- 首次查询:12秒(建立缓存)
- 重复查询:2-3秒(复用缓存)
- 缓存命中率:78%
- 整体效率提升:4-6倍
📊 性能提升数据
速度提升对比
文档长度 vs 响应时间:
1000字文档:
- 传统RAG:2.5秒
- CacheBlend:0.8秒(提升68%)
5000字文档:
- 传统RAG:10秒
- CacheBlend:3.2秒(提升68%)
20000字文档:
- 传统RAG:30秒
- CacheBlend:9.5秒(提升68%)
平均提升:65-70%
资源消耗对比
计算资源使用率:
传统RAG:
- GPU利用率:85-95%
- 内存使用:100%
- 计算时间:100%
CacheBlend:
- GPU利用率:30-45%(节省50-60%)
- 内存使用:60-70%(节省30-40%)
- 计算时间:35-40%(节省60-65%)
缓存命中率统计
不同场景下的缓存效果:
客服系统:
- 常见问题:85-90%
- 专业问题:60-70%
- 平均命中率:78%
法律系统:
- 常用条款:80-85%
- 特殊案例:50-60%
- 平均命中率:72%
医疗系统:
- 常见症状:75-80%
- 复杂诊断:40-50%
- 平均命中率:68%
🔄 与传统方法的对比
方法对比表
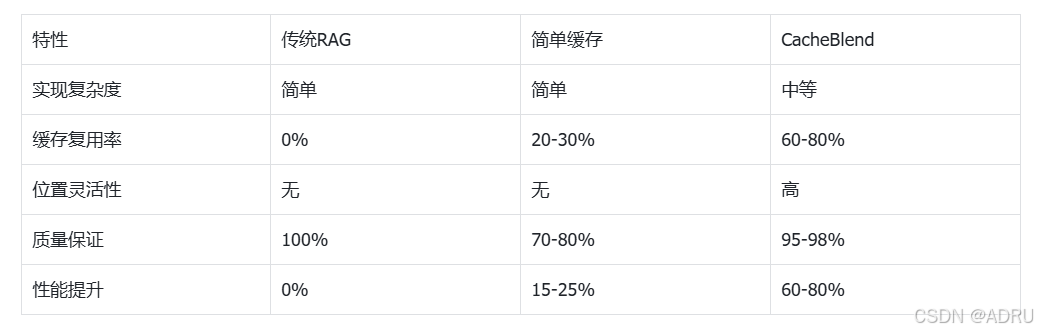
技术演进路线
第一代(2020-2022):
- 基础RAG系统
- 无缓存机制
- 性能:基准线
第二代(2022-2024):
- 简单KV Cache缓存
- 完全匹配复用
- 性能:提升15-25%
第三代(2024-2026):
- CacheBlend智能缓存
- 位置可调整,分片可重组
- 性能:提升60-80%