库操作:
创建数据库:create database name;本质是在/var/lib/mysql目录下建立新的目录。
查看数据库:show databases;
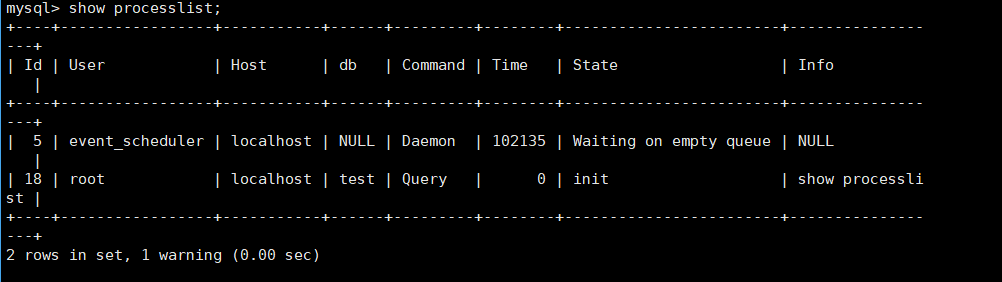
查看使用者:show processlist;
删除数据库:drop databases name;本质是在/var/lib/mysql目录下删除指定的目录。
修改数据库:
使用数据库:use 库name;
确认当前所处数据库:select database();
查看创建数据库相关命令:show creat database name;

;创建数据库时有两个重要的编码集:
1.数据库编码集--数据库未来存储数据
2.数据库校验集--支持数据库进行字段比较使用的编码,本质也是一种读取数据库中数据的采用的编码格式。
数据库中无论对数据做任何操作,都须保证操作和编码必须是一致的。
查看字符集与编码集操作:
查看字符集:show variables like 'charactor_set_database';

查看校验集:show variables like 'collation_database';

查看数据库支持的字符集:show charset;
查看数据库支持的字符集:show collation;
创建数据库案例
创建名为 db1 的数据库
create database db3;
说明:当我们创建数据库没有指定字符集和校验规则时,系统使用默认字符集:utf8,校验规则是:utf8_general_ ci
创建一个使用utf8字符集的 db2 数据库
create database db3 charset=utf8;
create database db3 charactor set utf8;
创建一个使用utf字符集,并带校对规则的 db3 数据库。
create database db3 charset=utf8 collate utf8_general_ci;
资源备份和恢复
备份:mysqldump -P3306 -uroot -p -B 【表名称】> 【新文件名】
备份后删除数据想恢复数据:模板:source 路径/备份文件名
校验指定查询:select * from name where name=target;
以下用 MySQL 代码示例**展示字符串校验规则中"区分大小写"和"不区分大小写"的差异,**主要通过不同的字符集校验规则( COLLATE )来实现:
- 创建测试表(分别指定不同校验规则)
sql-- 表1:使用区分大小写的校验规则(utf8mb4_bin) CREATE TABLE test_case_sensitive ( id INT PRIMARY KEY AUTO_INCREMENT, str VARCHAR(50) COLLATE utf8mb4_bin -- bin 后缀表示二进制校验,严格区分大小写 ); -- 表2:使用不区分大小写的校验规则(utf8mb4_general_ci) -- ci 表示 case insensitive(不区分大小写),MySQL 默认多为此类 CREATE TABLE test_case_insensitive ( id INT PRIMARY KEY AUTO_INCREMENT, str VARCHAR(50) COLLATE utf8mb4_general_ci );
- 插入测试数据
sql-- 向两个表插入相同的混合大小写数据 INSERT INTO test_case_sensitive (str) VALUES ('Apple'), ('apple'), ('APPLE'); INSERT INTO test_case_insensitive (str) VALUES ('Apple'), ('apple'), ('APPLE');
- 查询对比(体现差异)
(1)区分大小写的查询(test_case_sensitive 表)
cpp-- 搜索 'apple' 时,仅匹配完全一致的小写 SELECT * FROM test_case_sensitive WHERE str = 'apple';结果:仅返回 ('apple') 这一行。
(2)不区分大小写的查询(test_case_insensitive 表)
sql-- 搜索 'apple' 时,匹配所有大小写形式 SELECT * FROM test_case_insensitive WHERE str = 'apple';结果:返回 ('Apple') 、 ('apple') 、 ('APPLE') 三行。
关键说明
校验规则由字段的 COLLATE 属性决定,不同数据库的命名规则略有差异(如 PostgreSQL 中区分大小写的校验规则可能是 utf8mb4_cs )。
若未显式指定 COLLATE ,则默认继承数据库或表的校验规则(大部分场景默认不区分大小写)。
区分大小写的场景常见于密码存储、精确匹配等需求,不区分大小写则更符合日常搜索习惯(如用户名查询)。
表操作:
创建表: 
field 表示列名
datatype 表示列的类型
character set 字符集,如果没有指定字符集,则以所在数据库的字符集为准
collate 校验规则,如果没有指定校验规则,则以所在数据库的校验规则为准
例:
删除表:删drop table 表名称;
修改表:
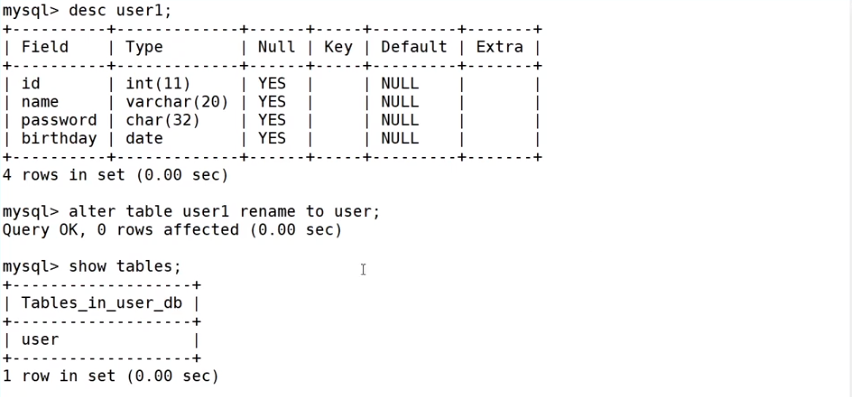
重命名:alter table old name rename to/'' new name;
插入数据:例:INSERT INTO students (name, age, gender) VALUES ('张三', 18, '男');

新增列:
例:

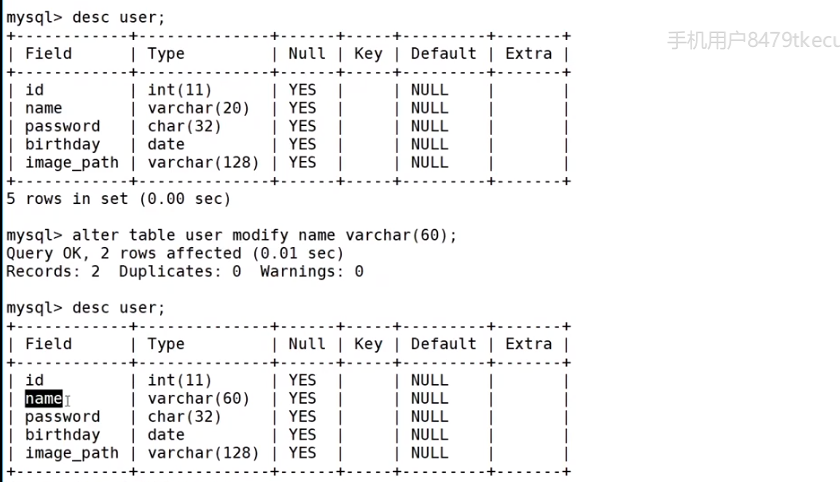
修改列的类型属性(开辟空间大小):
例:alter table old name modi费用 属性 类型及大小
删除一列:alter table name drop 列名;
修改列名称:alter table table name change old field name new field name 类型(大小)default NULL;
查看表:
show tables;
查看表结构:desc name;

查看表内容:select * from name;

查看创建表时候的详细信息表:show create table 表名称;
show create table 表名称 /G
