前言
在Redis的众多数据结构中,Hash(哈希)类型占据着至关重要的地位。Redis本身就是一个高性能的键值(Key-Value)数据库,其底层的键值对便是通过哈希方式组织的。而Hash数据类型则更进一步,它允许在Value层级再构建一个键值对集合,形成一种"域-值"(Field-Value)的映射关系。这种结构使得Hash特别适合用来存储对象信息,您可以将一个对象的多个属性高效地聚合在一个Redis键中
之前学过的所有数据结构中,最最重要的
redis自身已经是键值对的结构了
redis自身的键值对就是通过哈希的方式来组织的额
把key这一层组织完成之后,到了value这一层,value的其中一种类型还可以是哈希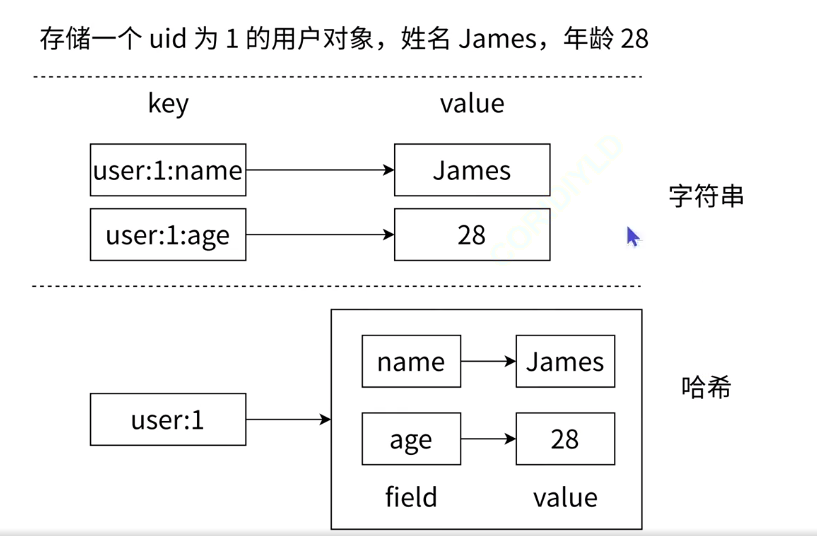
hset、hget
hset就是设置键值对
field->value
返回值是设置成功的键值对(field--value)
bash
hset key field value [field value...]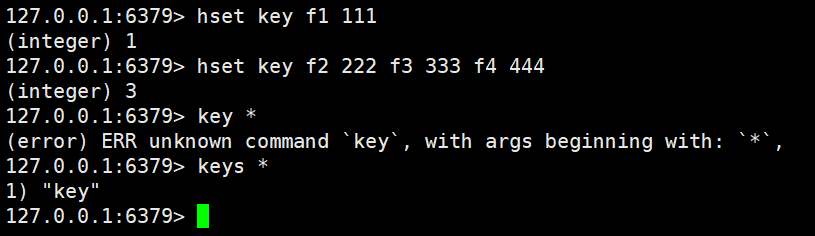
然后我们使用hget进行key里面键值对的获取
bash
hget key field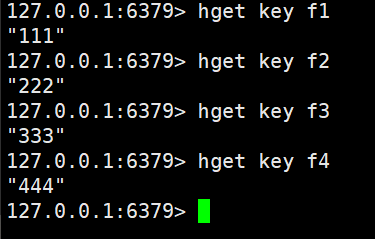
如果要查询的内容不存在的话就返回nil
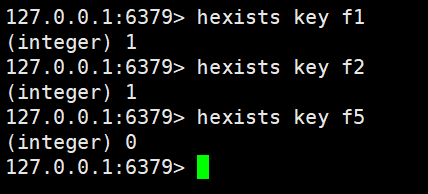
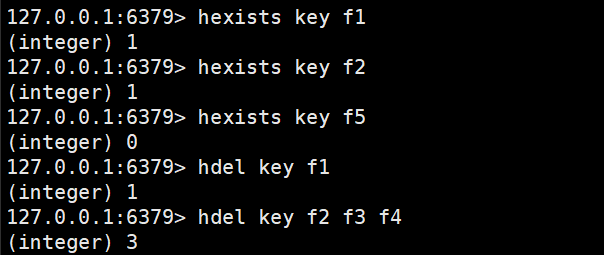
hexists
判断hash中是否有指定的字段
bash
hexists key field返回1就是存在,返回0就是不存在
hdel
删除hash中指定的字段
del删除的是key
hdel删除的是field
bash
hdel key field [field]都是先指定key,再来指定一个或者多个field
返回值就是本次操作删除的字段个数
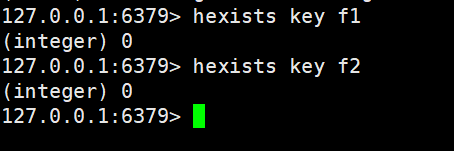
查看是否存在我们是查不到的,因为已经删除了
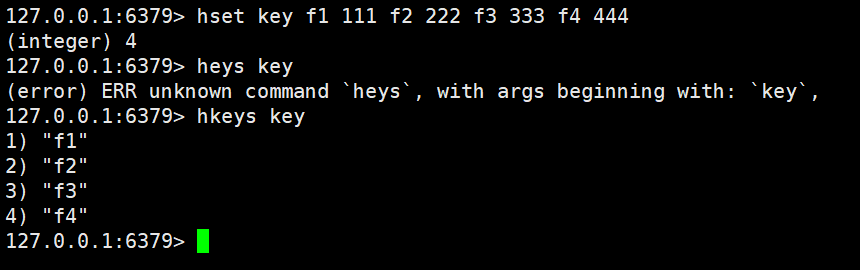
hkeys 、hvals
获取hash中的所有字段
bash
hkeys key返回值:字段列表
时间复杂度:O(N)
原理就是根据Key找到对应的hash O(1)
然后遍历hash O(N)这个N是hash的元素个数
这个查询到的就是我们当前hash中的所有的Key了
这个操作也是存在一定风险的,类似于之前介绍的keys *
主要是我们也不知道某个hash钟是否存在大量的field
可能会造成阻塞
bash
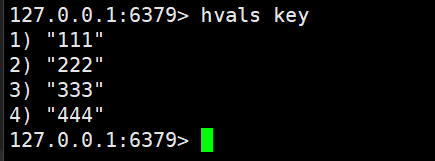
hvals key能够获取hash中所有的value
h系列的命令必须保证key对应的value得是哈希类型的
hgetall 、hmget
hegtall获取hash中的所有字段以及对应的值
bash
hgetall key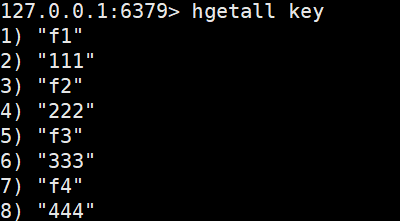
hmget类似于之前的mget,可以一次查询多个field
hget只能查询一个field,但是hmget可以查询多个field
bash
hmget key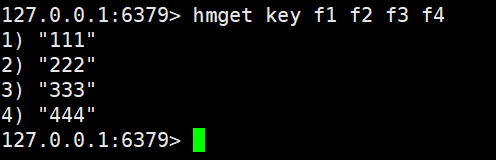
多个value的顺序和value是匹配的
有没有hmset,一次设置多个field和value呢?
有,但是并不需要,因为hset已经支持一次设置多个field和value了
hkeys,hvals,hgetall都是存在一定风险的,hash的元素个数太多了,执行的耗时会比较长,从而阻塞redis
hscan遍历redis的hash,但是他是属于渐进式遍历,就是敲一次命令,遍历一小部分,再敲一次,再遍历一小部分
连续执行多次,就可以完成整个的遍历过程了
hlen、hsetnx
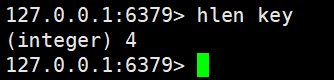
hlen获取hash中的所有字段的个数
bash
hlen key这个获取hash中的某个字段的个数我们是不需要进行遍历的
hsetnx
在字段不存在的情况下,设置hash中的字段和值,和之前的setnx很相似的
bash
hsetnx key field value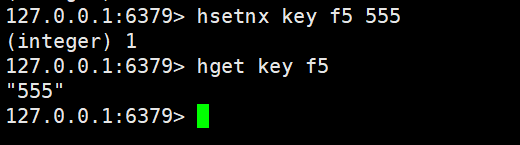
hincrby 、hincrbyfloat
hash这里的value,也可以当做数字来处理
hincrby就可以加减整数,返回计算后的结果
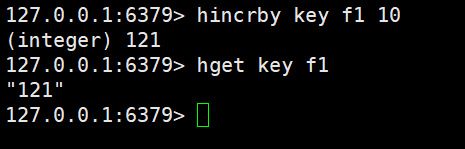
hincrbyfloat可以加减小数
好的,这是根据图片内容生成的表格:
命令小结
| 命令 | 执行效果 | 时间复杂度 |
|---|---|---|
| hset key field value | 设置值 | O(1) |
| hget key field | 获取值 | O(1) |
| hdel key field field ... | 删除 field | O(k), k 是 field 个数 |
| hlen key | 计算 field 个数 | O(1) |
| hgetall key | 获取所有的 field-value | O(k), k 是 field 个数 |
| hmget field field ... | 批量获取 field-value | O(k), k 是 field 个数 |
| hmset field value field value ... | 批量获取 field-value | O(k), k 是 field 个数 |
| hexists key field | 判断 field 是否存在 | O(1) |
| hkeys key | 获取所有的 field | O(k), k 是 field 个数 |
| hvals key | 获取所有的 value | O(k), k 是 field 个数 |
| hsetnx key field value | 设置值,但必须在 field 不存在时才能设置成功 | O(1) |
| hincrby key field n | 对应 field-value +n | O(1) |
| hincrbyfloat key field n | 对应 field-value +n | O(1) |
| hstrlen key field | 计算 value 的字符串长度 | O(1) |
hash内部编码
哈希的内部编码有两种:
- ziplist(压缩列表):当哈希类型元素个数⼩于 hash-max-ziplist-entries 配置(默认 512 个)、同时所有值都⼩于 hash-max-ziplist-value 配置(默认 64 字节)时,Redis 会使⽤ ziplist 作为哈希的内部实现,ziplist 使⽤更加紧凑的结构实现多个元素的连续存储,所以在节省内存⽅⾯⽐hashtable 更加优秀。
- hashtable(哈希表):当哈希类型⽆法满⾜ ziplist 的条件时,Redis 会使⽤ hashtable 作为哈希的内部实现,因为此时 ziplist 的读写效率会下降,⽽ hashtable 的读写时间复杂度为 O(1)。
压缩的本质是针对数据进行重新编码
ziplist付出的代价,进行读写元素,速度是比较慢的
哈希中的元素比较少,使用ziplist,元素多的话就使用hashtable
每个value的长度比较短,使用ziplist
如果太长了的话,也会转换成hashtable
使用场景
关系型数据表保存用户信息
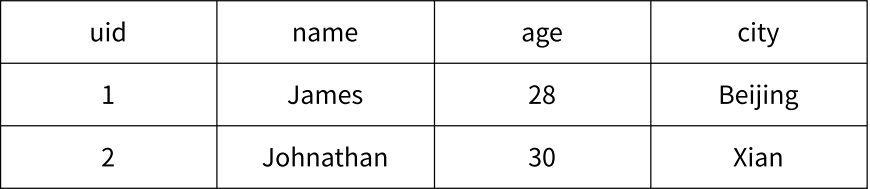
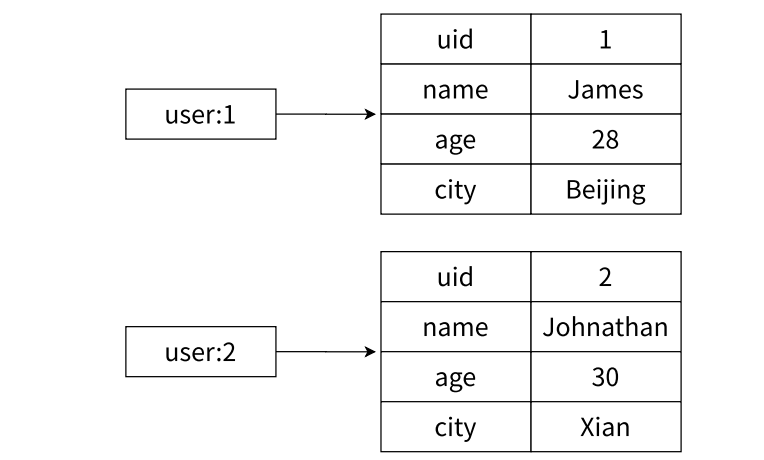
高内聚低耦合
Redis Hash因其结构化的数据存储方式和高效的字段访问能力,在实际应用中非常广泛。
-
缓存对象信息:这是最经典的使用场景。例如,用户信息、商品信息、会话数据等都可以存储在Hash中。 相比于将整个对象序列化为JSON字符串再存入Redis,使用Hash可以让您独立地更新或获取对象的某个属性,而无需读取和重写整个对象,这在并发更新时能避免数据覆盖问题并提升性能。
- 示例: 一个用户对象可以这样存储:HSET user:1001 name "Alice" age 30 email "
-
购物车:电商应用中的购物车功能与Hash结构完美契合。可以用用户ID作为键(key),商品ID作为域(field),商品数量作为值(value)。
- 示例: HSET cart:1001 product:558 2 表示用户1001的购物车中有2件ID为558的商品。通过HINCRBY可以方便地增减商品数量。
-
计数器聚合:当需要对一个对象的多个指标进行计数时,Hash非常有用。例如,记录一篇文章的点赞数、评论数、分享数。
- 示例: HINCRBY article:998 likes 1,HINCRBY article:998 comments 1。
- 、
总结
Redis的Hash数据类型提供了一种在单个键下存储多个键值对的高效方式,是模拟和存储对象数据的理想选择。它通过提供丰富的命令,实现了对对象属性的灵活、高效操作。相比于使用JSON字符串存储,Hash在更新部分字段时性能优势明显,且更加节省网络带宽。理解并善用ziplist和hashtable两种内部编码的特点,可以在内存效率和执行性能之间找到最佳平衡点,从而更好地发挥Redis的强大能力。