文章目录
文章目录
- [01 什么是逻辑回归](#01 什么是逻辑回归)
- [02 逻辑回归数学模型](#02 逻辑回归数学模型)
- [03 逻辑回归、线性回归、岭回归的区别?](#03 逻辑回归、线性回归、岭回归的区别?)
- [04 基于逻辑回归算法的乳腺癌数据集分类代码分析](#04 基于逻辑回归算法的乳腺癌数据集分类代码分析)
- [05 基于逻辑回归算法的乳腺癌数据集分类代码](#05 基于逻辑回归算法的乳腺癌数据集分类代码)
- [06 基于逻辑回归算法的乳腺癌数据集分类源码](#06 基于逻辑回归算法的乳腺癌数据集分类源码)
01 什么是逻辑回归
逻辑回归(Logistic Regression)是一种用于解决二分类(或多元分类)问题的统计学习方法。虽然名字里带"回归",但它本质上是分类算法,主要用于估计某个事件发生的概率。
假设你想预测一封邮件是否是垃圾邮件(1 = 垃圾邮件,0 = 正常邮件)。
- 输入特征:是否包含"免费"、"中奖"、"点击链接"等关键词;
- 输出:一个 0 到 1 之间的概率,比如 0.87,表示这封邮件有 87% 的可能性是垃圾邮件。
02 逻辑回归数学模型

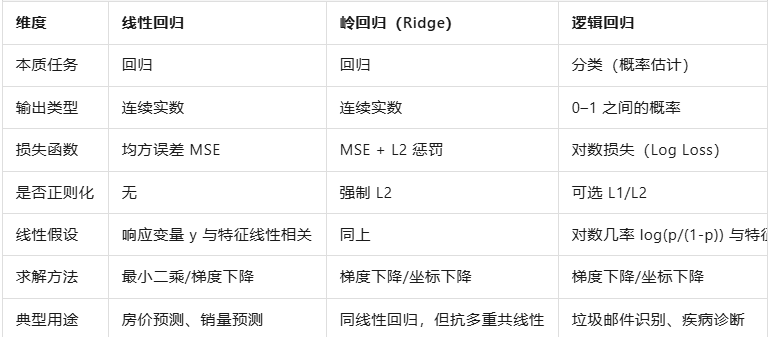
03 逻辑回归、线性回归、岭回归的区别?
线性回归直接拟合连续值,没有任何正则化。
岭回归就是给线性回归加上 L2 惩罚,让系数变小、模型更稳。
逻辑回归虽然名字带"回归",其实是用来算概率、做分类的。
04 基于逻辑回归算法的乳腺癌数据集分类代码分析
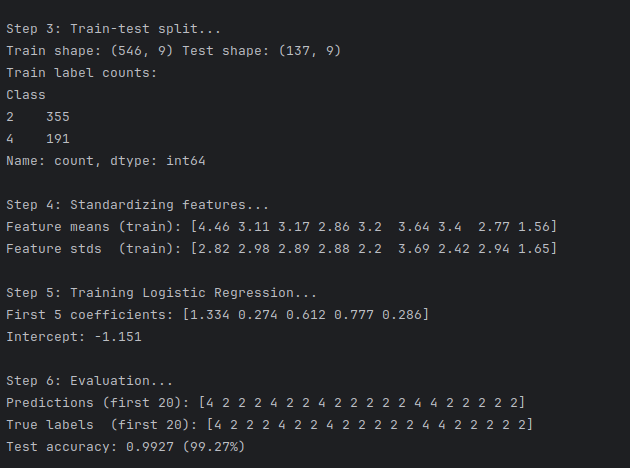
下载乳腺癌数据集。
把缺失值替换成 NaN 再删除。
用最后 9 个医学特征做 X,类别标签做 y。
80 % 训练集 + 20 % 测试集。
对特征做标准化(均值 0,方差 1)。
训练逻辑回归模型。
打印前 20 条预测值、真实值和总体准确率。
05 基于逻辑回归算法的乳腺癌数据集分类代码
python
print("\nStep 2: Data cleaning...")
data = data.replace("?", np.nan)
print("Missing values per column:")
print(data.isnull().sum())
data = data.dropna()
print("After dropping NA shape:", data.shape)
# 2.2 Features and target
X = data.iloc[:, 1:-1]
y = data["Class"]
print("Feature shape:", X.shape, "Target shape:", y.shape)
print("Feature columns:", list(X.columns))
# 2.3 Train-test split
print("\nStep 3: Train-test split...")
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=22, stratify=y
)
print("Train shape:", X_train.shape, "Test shape:", X_test.shape)
print("Train label counts:")
print(y_train.value_counts())
# 3. Standardization
print("\nStep 4: Standardizing features...")
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
print("Feature means (train):", scaler.mean_.round(2))
print("Feature stds (train):", scaler.scale_.round(2))
# 4. Fit Logistic Regression
print("\nStep 5: Training Logistic Regression...")
clf = LogisticRegression(max_iter=1000)
clf.fit(X_train, y_train)
print("First 5 coefficients:", clf.coef_[0][:5].round(3))
print("Intercept:", clf.intercept_[0].round(3))
# 5. Evaluation
print("\nStep 6: Evaluation...")
y_pred = clf.predict(X_test)
acc = clf.score(X_test, y_test)
print("Predictions (first 20):", y_pred[:20])
print("True labels (first 20):", y_test.values[:20])
print("Test accuracy:", round(acc, 4), f"({round(acc*100, 2)}%)")06 基于逻辑回归算法的乳腺癌数据集分类源码
提供了Python的实现代码,使得用户可以根据自己的需求进行调整和应用。
Python代码下载地址
