Spring Cloud是基于Spring Boot构建的微服务开发框架,它通过集成一系列成熟的组件提供了微服务架构下的核心能力(如服务发现、配置管理、熔断降级等)。
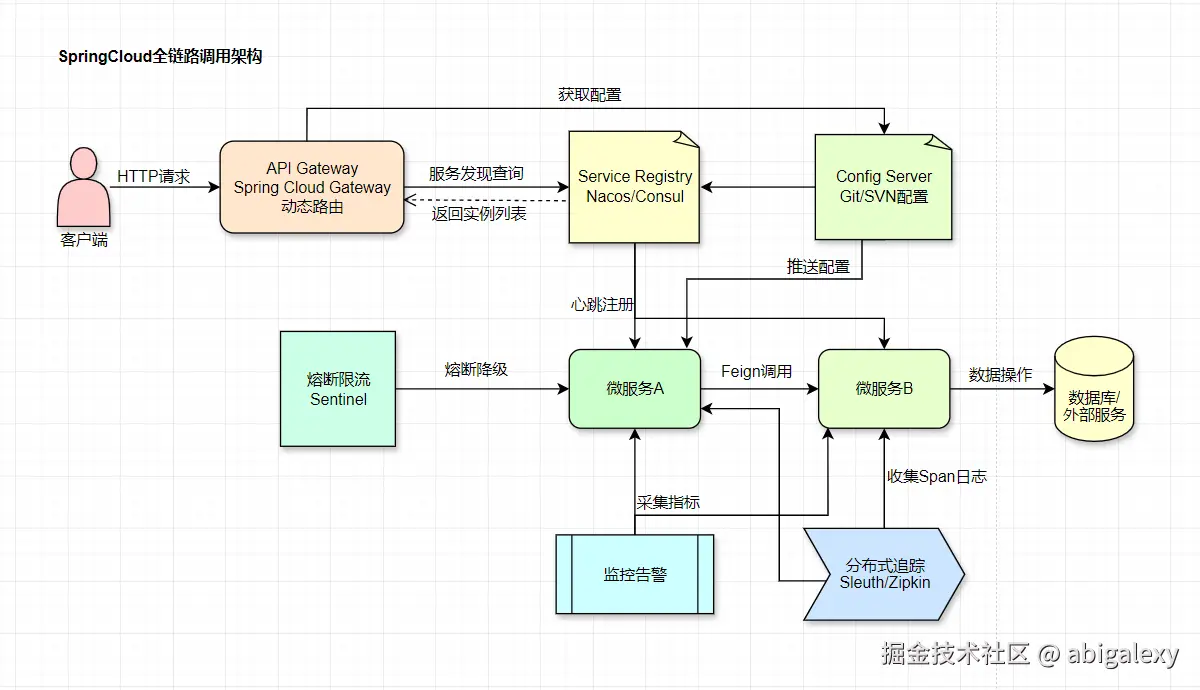
一、核心组件
(一)服务注册与发现(Service Discovery & Registration)
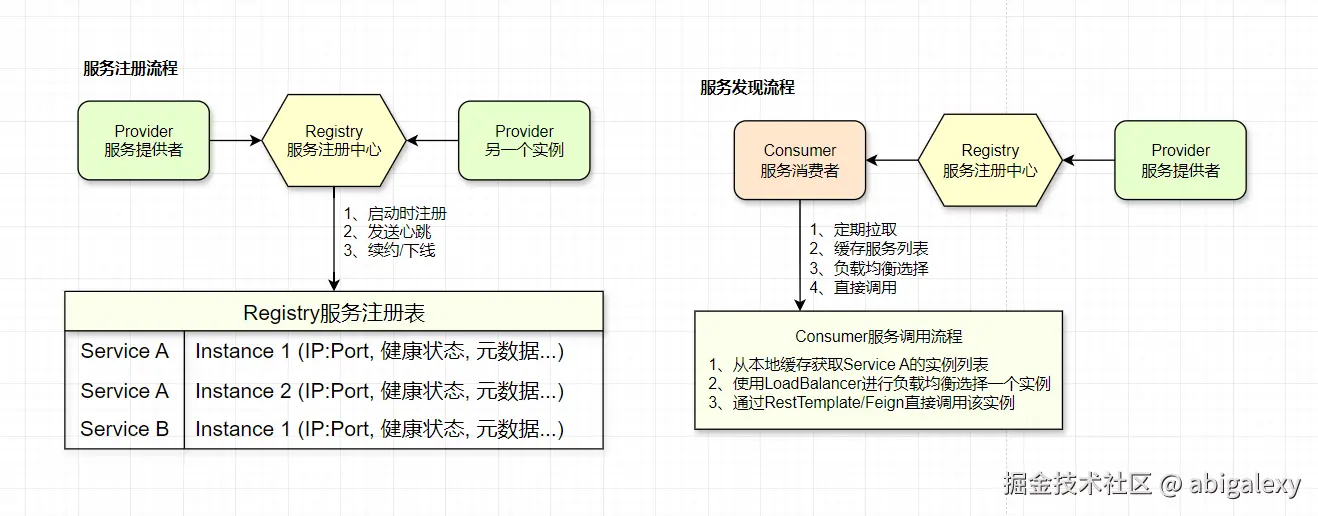
1、常用组件
1)Nacos
支持服务注册、配置管理和动态DNS服务,兼容Eureka和Consul的API。集成了服务注册发现和配置中心功能,支持动态服务发现、健康检查、配置管理(替代Eureka + Config + Bus)。
2)Consul/Zookeeper
第三方服务发现工具,通过 Spring Cloud Consul/Zookeeper集成。
2、底层原理
核心组件:
服务注册中心(Registry):如Eureka、Consul、Zookeeper、Nacos等
服务提供者(Provider):注册自身服务到注册中心
服务消费者(Consumer):从注册中心获取服务列表并调用
1)服务注册
服务提供者启动时,通过ServiceRegistry接口的实现类(如EurekaServiceRegistry)向注册中心注册
注册信息包括: 服务名、IP地址、端口、健康检查URL等元数据
采用心跳机制维持注册(默认30秒发送一次心跳)
关键代码:
java
// EurekaClientAutoConfiguration 自动配置类
@Bean
@ConditionalOnMissingBean(value = EurekaClientConfig.class)
public EurekaClientConfig eurekaClientConfig(..) {
// 配置Eureka客户端
}
// EurekaServiceRegistry 注册实现
public void register(EurekaRegistration reg) {
reg.getApplicationInfoManager().setInstanceStatus(reg.getInstanceConfig().getInitialStatus());
}2)服务发现
消费者启动时从注册中心拉取服务列表并缓存
通过DiscoveryClient(如EurekaDiscoveryClient)获取服务实例
Ribbon等负载均衡组件利用这些信息进行服务调用
关键代码:
java
// DiscoveryClient 接口
public interface DiscoveryClient {
List<ServiceInstance> getInstances(String serviceId);
}
// Eureka实现
public List<ServiceInstance> getInstances(String serviceId) {
List<InstanceInfo> infos = eurekaClient.getInstancesByVipAddress(serviceId, false);
// 转换为ServiceInstance
}3)健康检查与故障剔除
服务实例每30秒发送心跳(可配置)
注册中心若90秒内未收到心跳,则将该实例标记为下线
自我保护机制防止网络分区时过度剔除服务
3、底层通信
服务注册/发现通常通过HTTP REST或gRPC协议实现。
消费者本地缓存服务列表,减少对注册中心的依赖(如Eureka的Tiered Load Balancer)。
4、不同注册中心对比
| 特性 | Eureka | Nacos | Zookeeper | Consul |
|---|---|---|---|---|
| CAP理论 | AP (最终一致) | AP/CP可配置 | CP(强一致) | CP(强一致) |
| 健康检查 | 客户端心跳 | TCP/HTTP/自定义 | 临时节点心跳 | 支持多种检查方式 |
| 负载均衡 | 集成Ribbon | 内置 | 需额外组件 | 需额外组件 |
| 配置管理 | 不支持 | 支持 | 支持 | 支持 |
| 雪崩保护 | 有 | 有 | 无 | 无 |
| 访问协议 | HTTP | HTTP/gRPC | TCP | HTTP/DNS/gRPC |
(二)分布式配置中心(Configuration Management)
1、常用组件
1)Spring Cloud Config
集中管理所有微服务的配置文件(如 application.yml),支持从Git、SVN或本地文件系统加载配置;结合Bus,通过Spring Cloud Bus(如 RabbitMQ/Kafka)实现配置动态刷新,替代方案:Nacos、Apollo(携程开源,支持配置实时推送)
2)Nacos Config
Nacos提供的配置管理功能,支持动态更新和版本控制。
2、底层原理
2.1 核心角色和流程
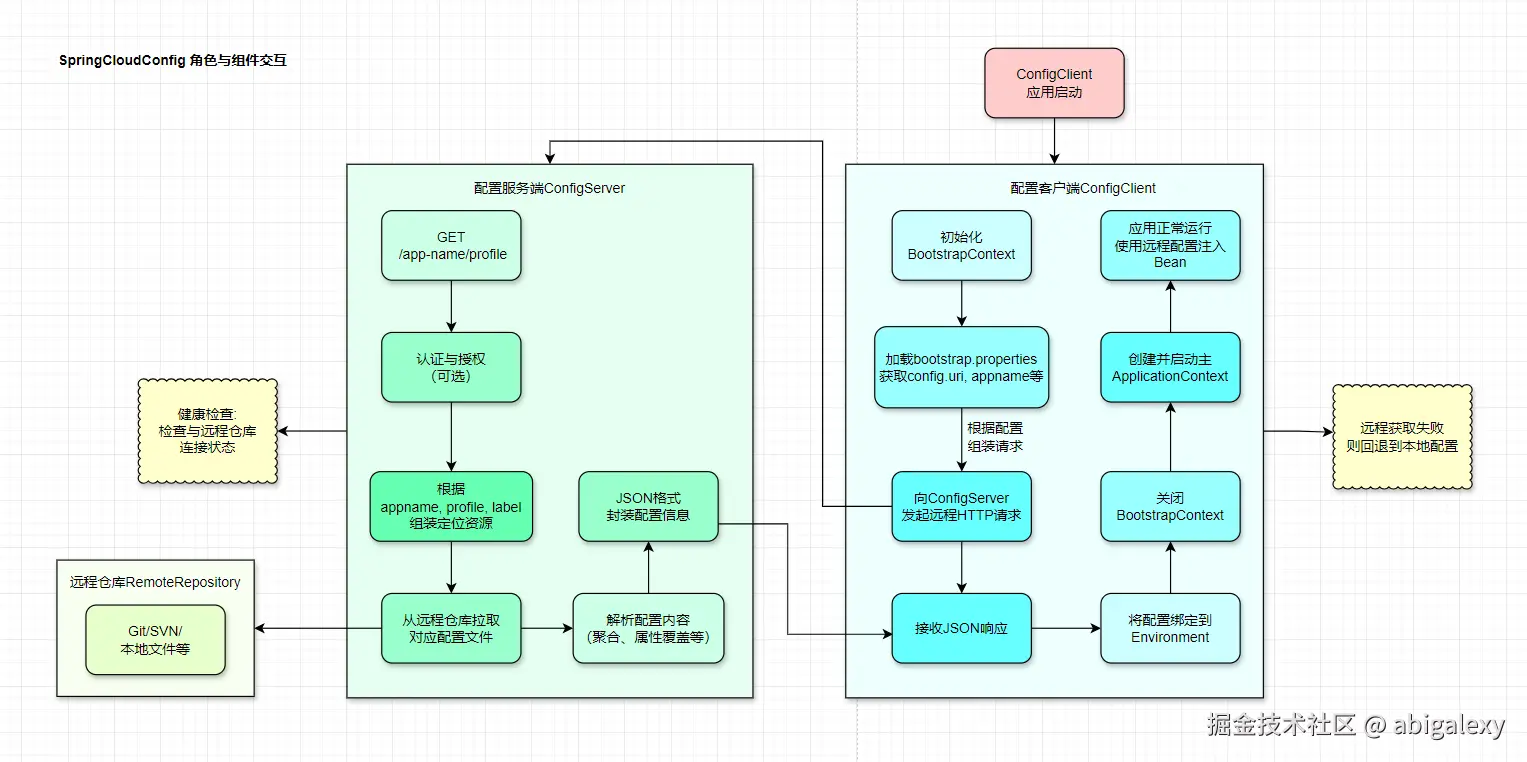
1)远程仓库 (Remote Repository)
配置的"唯一真相源"。通常使用 Git(如 GitHub, GitLab, Gitee)、SVN 或本地文件系统。所有应用的配置文件(如 myapp-dev.yml, myapp-test.yml)都集中存储在这里。
2)配置服务端 (Config Server)
一个独立的微服务,其核心职责是连接到远程仓库,对外暴露 RESTful API(如 /appname/profile 或 /appname-profile.yml),供客户端获取配置。它本质上是远程配置仓库的一个适配器和聚合器。
3)配置客户端 (Config Client)
各个业务微服务(Application Service)。它们在启动阶段(早于 Application Context 创建)会创建一个 Bootstrap Context,并向 Config Server 发起请求,获取所需的配置信息,然后用这些配置来初始化主应用上下文。
2.2 客户端启动流程(最核心的部分)
这是理解 Config 如何工作的关键。一个启用了Config Client的微服务(即加了 @EnableConfigClient 或依赖了 spring-cloud-starter-config)的启动过程如下:
1)初始化Bootstrap Context
Spring Cloud 构建了一个"父"上下文,称为 Bootstrap Context。这个上下文独立于我们熟悉的 main Application Context。
它负责加载 bootstrap.properties 或 bootstrap.yml 文件。这是为什么配置服务器的地址必须配置在 bootstrap 文件而不是 application 文件中的根本原因。因为 Application Context 尚未创建,而获取配置是启动的前提。
2)从Bootstrap配置中获取服务器地址
Bootstrap Context 读取 spring.cloud.config.uri,得知Config Server的位置。
3)组装标识,远程调用
客户端根据自身的spring.application.name、spring.profiles.active和spring.cloud.config.label(可选,用于 Git 分支)组装成一个唯一的标识。
客户端向Config Server的REST API发起调用,例如:GET <http://config-server:8888/my-app/dev>
4)服务端响应与配置拉取
Config Server接收到请求后,会根据应用名、Profil和Label去远程仓库(如Git)查找对应的配置文件(如 my-app-dev.yml)。
Config Server将找到的配置内容组装成一个JSON对象返回给客户端。这个JSON包含了配置的所有键值对,以及一些元数据(如使用的 label,状态等)。
5)绑定到Environment并启动主上下文
Config Client 接收到JSON响应后,将其中的配置属性解析并加载到当前应用的Environment中。至此,Bootstrap Context 的使命完成。之后,主 Application Context 被创建并启动。此时,所有在 @Value("${...}")、@ConfigurationProperties 等注解中引用的属性,其值都已经从 Config Server 获取并注入完毕。
6)应用正常启动
主上下文启动后,应用就像使用本地 application.properties 一样正常运行,毫无感知。
2.3 配置的动态刷新 (Spring Cloud Bus)
默认在客户端启动时一次性读取配置。之后如果远程仓库的配置发生变化,客户端应用是不会自动更新的。
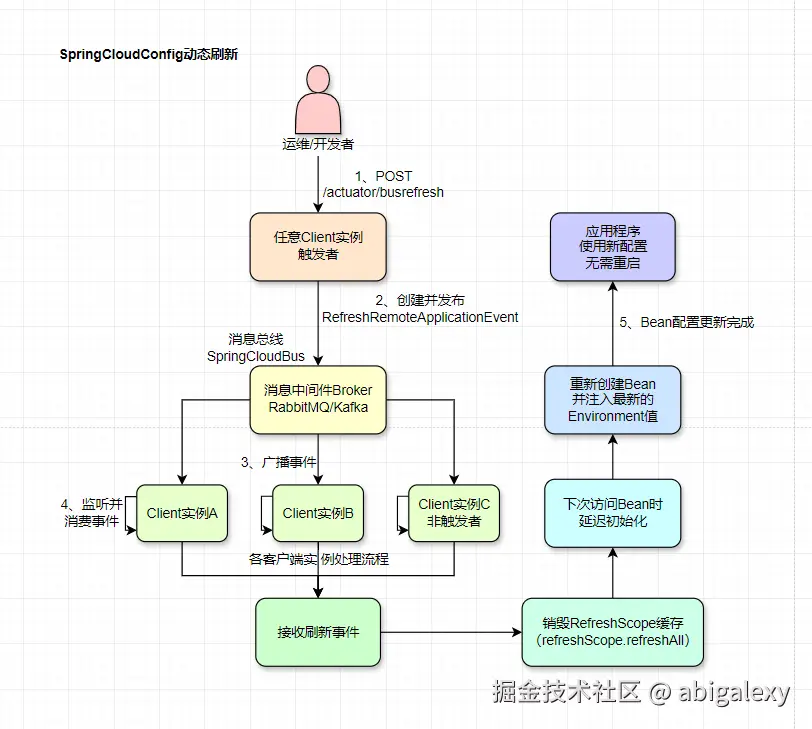
1)客户端暴露 /actuator/refresh 端点
在需要刷新的 Bean 上添加 @RefreshScope 注解,并确保引入了 spring-boot-starter-actuator。
2)手动触发
更改配置后,对每个客户端实例手动发送一个POST 请求到 http://client-host:port/actuator/refresh。该实例会重新连接 Config Server获取最新配置,并刷新所有标记了 @RefreshScope 的Bean。
3)自动广播(使用 Spring Cloud Bus)
Spring Cloud Bus使用一个轻量级的消息代理(如RabbitMQ 或Kafka)连接各个微服务实例。当你向任何一个客户端触发 /actuator/bus-refresh 端点时,该客户端会通过 Bus 将刷新事件广播给总线上的所有其他客户端。其他客户端收到事件后,都会自动执行 /actuator/refresh 的逻辑,从而实现全局配置的自动刷新。
2.4 配置定位机制
Config Server通过以下规则定位配置:
/{application}/{profile}/{label}
/{application}-{profile}.yml
/{label}/{application}-{profile}.yml
/{application}-{profile}.properties
/{label}/{application}-{profile}.properties
application:对应客户端的spring.application.name
profile:对应spring.profiles.active
label:Git分支名(默认为master)
2.5 配置加密解密
使用JCE(Java Cryptography Extension)实现:
yaml
# 加密配置示例
encrypt:
key: my-secret-key加密流程:
客户端发送/encrypt请求加密敏感数据
服务端返回加密字符串
客户端在配置文件中使用{cipher}前缀引用
2.6 健康检查与监控
Config Server提供以下端点:
/health:服务健康状态
/env:当前环境信息
/metrics:运行指标
2.7 核心类关系
java
EnvironmentRepository
↑
NativeEnvironmentRepository (本地文件)
↑
GitEnvironmentRepository (Git仓库)
↑
AbstractScmEnvironmentRepository (SCM抽象)
EnvironmentController (处理HTTP请求)
↓
PropertySourceLocator (定位属性源)3、配置规则
Config Server在查找配置时,遵循一种聚合和覆盖的规则:
应用名 + Profile:查找 {application}-{profile}.yml (或 .properties),这是最精确的匹配。
应用名:查找 {application}.yml,作为默认配置。
Label(分支):上述查找过程会在指定的 label(即分支)下进行。如果不指定,默认为 master。
3.1 配置优先级
Config Client 获取到的配置是多个源的聚合。后加载的配置会覆盖先加载的。优先级从高到低如下:
1)Config Server 远程仓库中的配置(最高优先级,覆盖本地配置)
2)客户端本地的 application-{profile}.yml
3)客户端本地的 application.yml
3.2 多环境配置管理
Git仓库结构示例:
sh
├── application.yml # 全局配置
├── config-client-dev.yml # 开发环境
├── config-client-prod.yml # 生产环境
└── config-client-test.yml # 测试环境4、常见问题解决方案
1)配置加载失败
检查spring.cloud.config.uri配置
验证后端存储权限
查看Config Server日志中的详细错误
2)动态刷新不生效
确保添加了@RefreshScope注解
检查Bus消息中间件连接状态
验证/actuator/refresh端点是否暴露
3)性能瓶颈
对大配置文件进行拆分
考虑使用数据库作为后端存储
实现配置预加载机制
(三)负载均衡(Load Balancing)
Spring Cloud中的负载均衡主要通过Ribbon(客户端负载均衡)和Spring Cloud LoadBalancer(官方推荐的新实现)实现,它们位于客户端,与Eureka等服务注册中心配合工作。
客户端负载均衡vs服务端负载均衡
客户端负载均衡:由服务消费者维护服务列表,自行选择服务实例(如Ribbon)
服务端负载均衡:由独立的负载均衡器(如Nginx、F5)进行请求分发
1、常用组件
1)Spring Cloud LoadBalancer
替代Netflix Ribbon 的客户端负载均衡器,支持轮询、随机等策略。
使用场景:在 RestTemplate 或 FeignClient 中自动路由请求到多个服务实例。
2、底层原理
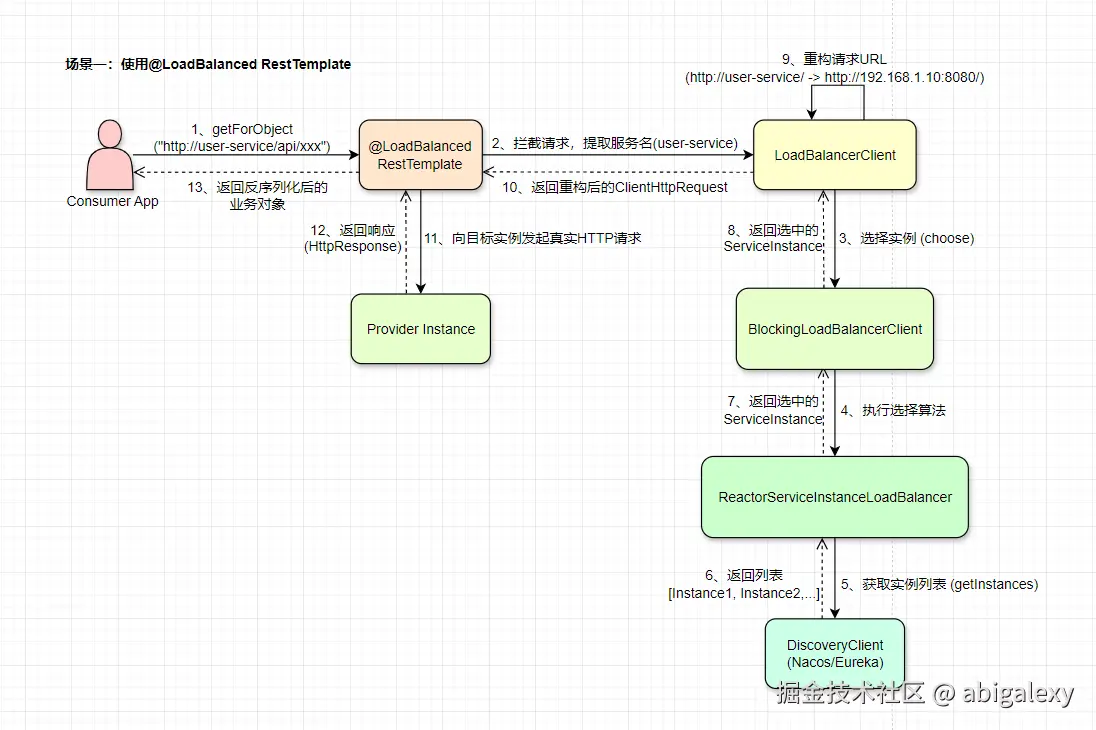
1)服务发现与缓存
服务列表获取:通过DiscoveryClient从Eureka获取服务实例列表
本地缓存:使用ILoadBalancer接口的实现类维护服务列表
java
// 代码示例
List<Server> servers = discoveryClient.getInstances("user-service")
.stream()
.map(instance -> new Server(instance.getHost(), instance.getPort()))
.collect(Collectors.toList());2)负载均衡策略
| 策略类 | 描述 |
|---|---|
| RoundRobinRule | 轮询(默认) |
| RandomRule | 随机 |
| RetryRule | 重试(先轮询,失败后重试其他) |
| WeightedResponseTimeRule | 响应时间加权 |
| BestAvailableRule | 选择并发请求最小的 |
| AvailabilityFilteringRule | 过滤掉不可用和并发高的 |
| ZoneAvoidanceRule | 复合判断(区域+服务器) |
3)请求拦截与转发
RestTemplate拦截:通过@LoadBalanced注解创建代理
Feign集成:Feign内部已集成Ribbon/Spring Cloud LoadBalancer
java
// RestTemplate配置示例
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
// 使用示例
restTemplate.getForObject("http://user-service/user/1", User.class);4)新实现核心类
java
LoadBalancerClientFactory
│
├─ ReactorServiceInstanceLoadBalancer (抽象接口)
│ ├─ RoundRobinLoadBalancer
│ └─ RandomLoadBalancer
│
└─ Response<ServiceInstance> (响应对象)5)自定义负载均衡策略
java
@Configuration
public class MyRibbonConfig {
@Bean
public IRule ribbonRule() {
// 自定义策略示例:优先访问本地实例
return new AbstractLoadBalancerRule() {
@Override
public Server choose(Object key) {
// 实现自定义逻辑
return chooseLocalFirst();
}
};
}
}
// 指定特定服务使用自定义配置
@RibbonClient(name = "user-service", configuration = MyRibbonConfig.class)6)重试机制
yaml
# application.yml配置示例
user-service:
ribbon:
MaxAutoRetries: 1 # 同一实例重试次数
MaxAutoRetriesNextServer: 1 # 切换实例重试次数
OkToRetryOnAllOperations: true # 对所有请求重试7)区域感知路由
yaml
spring:
cloud:
loadbalancer:
zone: ${spring.cloud.client.ip-address:} # 设置当前区域
user-service:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.ZoneAvoidanceRule(四)服务调用(Service Invocation)
1、常用组件
1)OpenFeign
声明式HTTP客户端,通过接口注解(如@FeignClient)简化服务间调用。声明式的 HTTP 客户端,通过注解定义接口即可调用远程服务,内置Ribbon实现负载均衡。
2)RestTemplate
Spring 提供的同步HTTP客户端,需手动实现负载均衡(配合LoadBalancer)。
2、底层原理
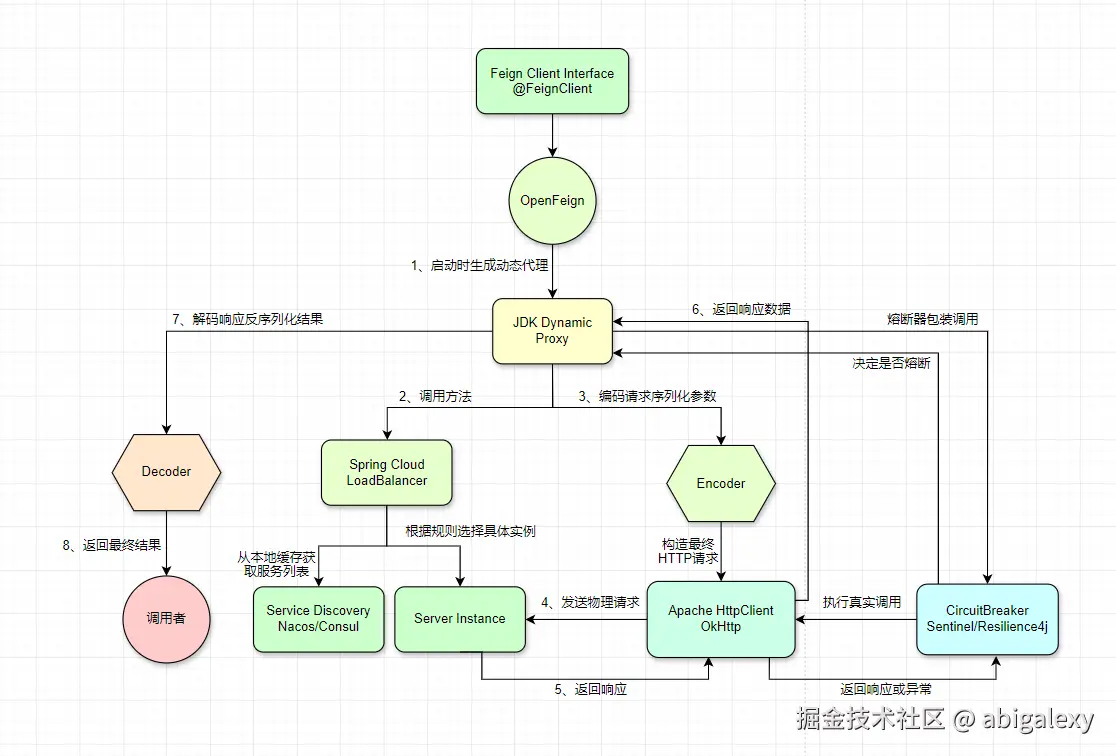
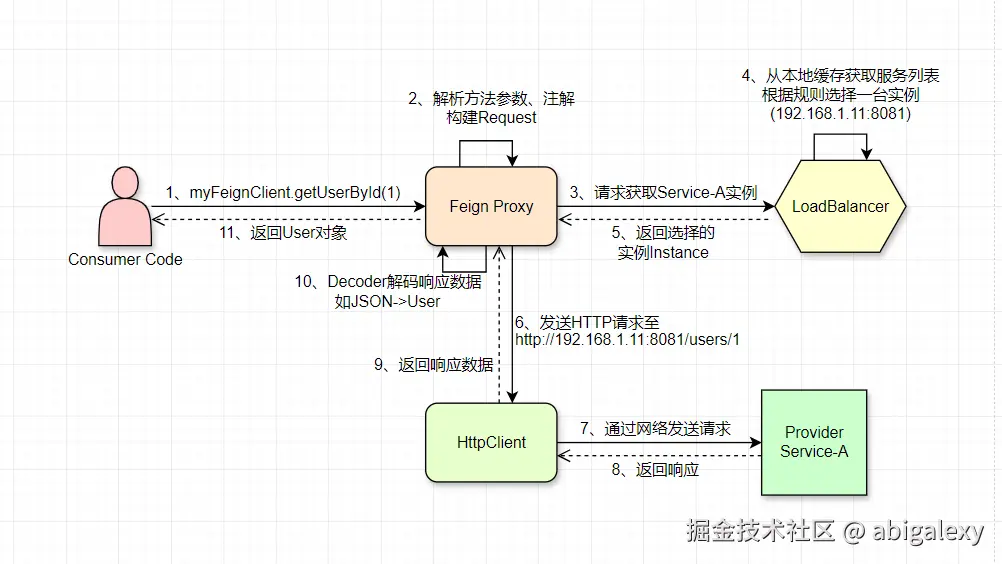
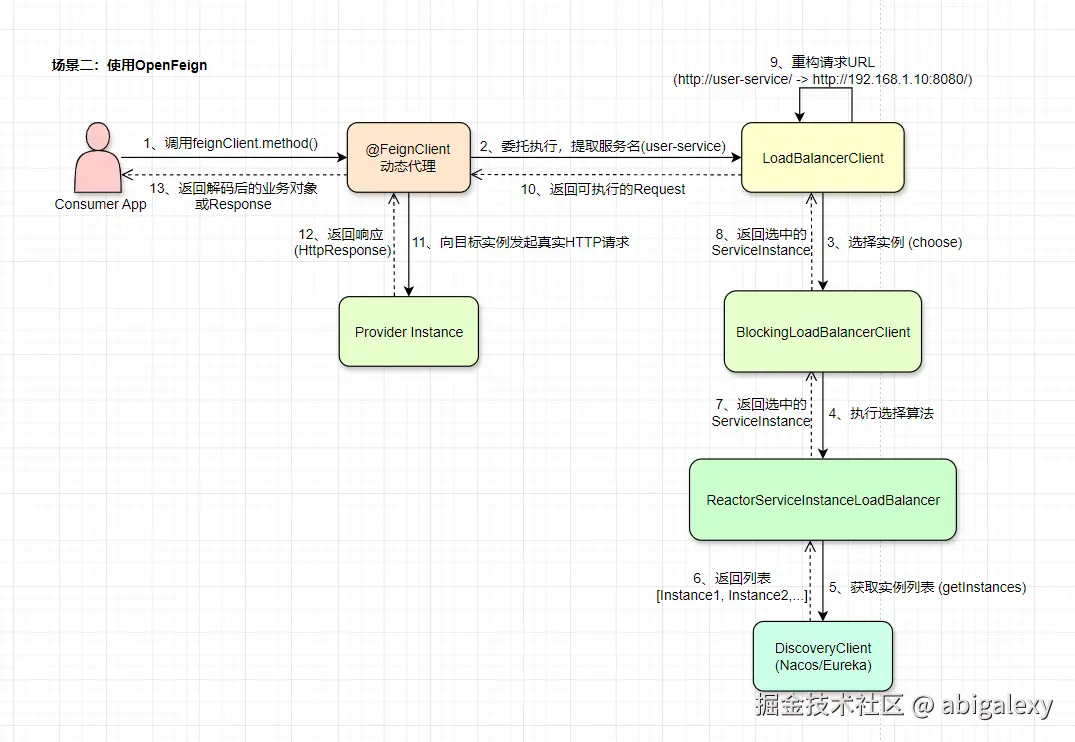
2.1 RestTemplate服务调用
RestTemplate是Spring提供的同步HTTP客户端,用于简化REST API调用。
核心组件:
ClientHttpRequestFactory:创建HTTP请求的工厂
RestTemplate:封装HTTP操作,提供统一接口
ClientHttpRequestInterceptor:请求拦截器(可用于日志、重试等)
2.2 Feign服务调用
Feign 是一个声明式的HTTP客户端,底层基于Ribbon和Hystrix(或Resilience4j)。
核心组件:
Feign Interface:定义服务接口
Feign.Builder:构建 Feign 客户端
Contract:接口定义与实现之间的契约
Encoder/Decoder:请求/响应编解码
Client:实际执行 HTTP 请求的客户端(默认使用Ribbon+RestTemplate)
LoadBalancer:负载均衡组件
2.3 OpenFeign与原版Feign区别
OpenFeign是Netflix Feign的开源替代品,Spring Cloud OpenFeign是其Spring Cloud集成版本。
更活跃的维护
更好的Spring集成
支持Spring MVC注解
内置对Spring Cloud LoadBalancer的支持
2.4 关键点
1)面向接口编程
开发者通过定义接口来声明远程调用,框架通过动态代理实现具体逻辑,实现了高度的解耦。
2)客户端负载均衡
负载均衡的决定是在服务消费者端做出的,而非传统的集中式负载均衡器(如Nginx)。这降低了中心节点的压力,但也要求每个客户端都维护服务列表。
3)"服务名"到"IP:端口"的转换
这是服务发现和负载均衡共同作用的结果。你始终只关心服务名,而不需要知道服务实例的具体地址。
4)模块化设计
Feign 的每个组件(Encoder、Decoder、Contract、Http Client、Logger)都是可插拔的,你可以根据需要定制或替换。
5)与注册中心解耦
OpenFeign 本身不关心服务发现是用 Nacos、Eureka 还是 Consul 实现的。它只依赖于 DiscoveryClient 这个标准接口。具体的实现由对应的 spring-cloud-starter-* 提供。
2.5 性能优化
1)连接池配置
对于 OkHttp/Apache HttpClient 配置连接池
示例 OkHttp 配置:
java
@Bean
public OkHttpClient okHttpClient() {
return new OkHttpClient.Builder()
.connectionPool(new ConnectionPool(20, 5, TimeUnit.MINUTES))
.build();
}2)超时设置
合理设置连接超时和读取超时
示例:
yaml
ribbon:
ReadTimeout: 5000
ConnectTimeout: 20003、OpenFeign与RestTemplate对比
| 特性 | OpenFeign | RestTemplate + @LoadBalanced |
|---|---|---|
| 代码风格 | 声明式:定义接口,像调用本地方法一样 | 命令式:在代码中手动构造URL和参数 |
| 可读性/维护性 | 高:接口集中管理,意图清晰 | 低:URL拼接分散在代码中,难以管理 |
| 集成度 | 高:天然集成SpringMVC注解,开箱即用 | 中:需要自己处理请求构造和响应解析 |
| 底层原理 | 动态代理+Ribbon/LoadBalancer | RestTemplate拦截器+LoadBalancer |
| 负载均衡 | 内置 | 需手动集成 |
| 熔断支持 | 内置(需Hystrix/Resilience4j) | 需手动集成 |
| 推荐场景 | 微服务间调用 | 简单HTTP调用 |
(五)熔断与容错(Circuit Breaker & Fault Tolerance)
1、常用组件
1)Spring Cloud Circuit Breaker
抽象层,支持多种熔断器实现(如 Resilience4j、Hystrix)。
2)Sentinel
功能:更轻量级的流量控制、熔断降级组件,支持实时监控和规则配置。
3)Resilience4j
推荐的替代方案,基于函数式编程,支持熔断、重试、限流等。
2、底层原理
舱壁模式:每个服务调用分配独立的线程池,避免故障扩散。
熔断机制:当失败率超过阈值(如 50%),打开熔断器,直接返回降级逻辑。
降级策略:通过 fallbackMethod 指定备用方法,或返回默认值。
2.1 状态转换
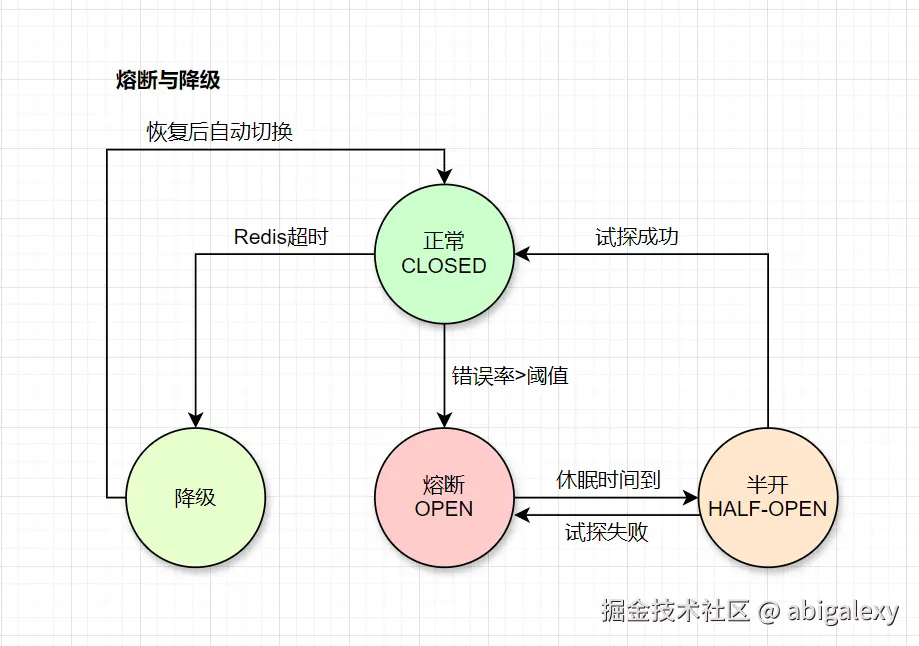
1)CLOSED (关闭状态)
初始状态,也是正常状态。
熔断器处于关闭状态,所有请求都正常地转发到目标服务。
底层原理:熔断器会持续监控这些调用的结果(成功、失败、超时)。它会维护一个时间窗口内的统计数据。
2)OPEN (打开状态)
熔断状态。
当失败(超时、异常等)的比率达到或超过设定的阈值时,熔断器会跳闸(Trip),进入 OPEN 状态。
在此状态下,所有对该服务的请求都会立即被拒绝,并直接执行降级逻辑(Fallback),不再真正发起远程调用。
设计目的:给被调用服务时间来自我修复,同时防止调用者因持续尝试而耗尽资源。
3)HALF-OPEN (半开状态)
试探恢复状态。
熔断器进入 OPEN 状态后,会启动一个休眠时间窗(Sleep Window)。计时结束后,熔断器会自动进入 HALF-OPEN 状态。
在此状态下,熔断器会允许少量试探请求通过,去尝试调用目标服务。
结果判断:
如果试探调用成功,则认为服务已恢复,熔断器状态切换回 CLOSED,并重置统计信息。
如果试探调用失败,则认为服务仍然不可用,熔断器状态重回 OPEN,并开启一个新的休眠时间窗。
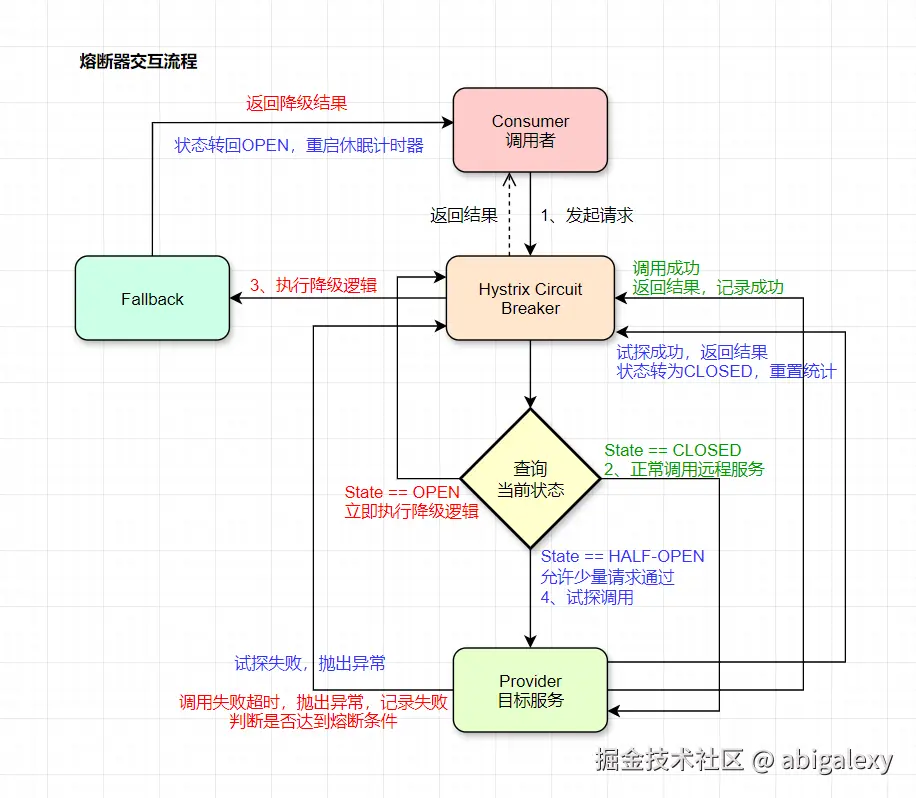
2.2 关键指标
错误率 = 错误请求数/总请求数
平均响应时间 = 总响应时间/成功请求数
线程池隔离 vs 信号量隔离
Hystrix默认使用线程池隔离,为每个依赖服务创建一个独立的线程池,这样某个服务的延迟只会拖垮自己的线程池,不会影响其他服务。
Resilience4j 则主要使用信号量隔离,开销更小。
指标收集
熔断器内部通过一个 "桶"(Bucket)的环形数组来滚动地统计指标。每个桶代表一个时间段(如 100ms),记录该时间段内的所有请求结果。时间推移时,丢弃最旧的桶,使用最新的桶,从而实现滑动窗口统计。
2.3 关键配置参数
1)circuitBreaker.requestVolumeThreshold (滑动窗口内的最小请求数)
含义:在单位时间窗口内,至少需要有多少个请求,熔断器才开始进行错误率的计算。
如果只有3个请求,失败了1个,错误率是33%,这并不具有统计意义。可能只是网络抖动。默认值通常是20,意味着如果10 秒内收到19 个请求,即使全部失败,也不会触发熔断。
2)circuitBreaker.errorThresholdPercentage (错误百分比阈值)
含义:当请求量超过 requestVolumeThreshold 后,如果失败请求的百分比超过此值,则触发熔断。例如,设置为 50%,表示时间窗口内超过一半的请求失败,熔断器就会进入OPEN状态。
3)circuitBreaker.sleepWindowInMilliseconds (休眠时间窗)
含义:熔断器从OPEN状态变为HALF-OPEN状态需要等待的时间(毫秒)。在此期间,所有请求都被立即拒绝。
4)metrics.rollingStats.timeInMilliseconds (统计时间窗口大小)
含义:设定滑动窗口的时间长度,例如10秒。Hystrix 会持续统计最近10秒内的请求数据。
5)metrics.rollingStats.numBuckets (滑动窗口的桶数量)
含义:将时间窗口划分为多个桶(Bucket),每个桶记录一段时间内(如1秒)的请求数据(成功、失败、超时数)。桶的数量必须能被时间窗口整除。这是一种滚动统计机制,保证了数据的时效性,总是取最近一段时间的数据进行计算。
3、Sentinel核心组件
Slot Chain\] → \[FlowSlot\] → \[DegradeSlot\] → \[SystemSlot\] → \[...其他Slot
FlowSlot:流量控制
DegradeSlot:熔断降级
SystemSlot:系统保护
4、Resilience4j 示例代码
java
// 创建熔断器配置
CircuitBreakerConfig config = CircuitBreakerConfig.custom()
.failureRateThreshold(50) // 错误率阈值 50%
.slidingWindowSize(10) // 滑动窗口大小 10个请求
.waitDurationInOpenState(Duration.ofMillis(10000)) // 休眠时间窗10秒
.build();
// 创建熔断器实例
CircuitBreaker circuitBreaker = CircuitBreaker.of("myService", config);
// 使用熔断器装饰业务逻辑
Supplier<String> decoratedSupplier = CircuitBreaker
.decorateSupplier(circuitBreaker, () -> restTemplate.getForObject("http://service-provider/hello", String.class));
// 执行请求,如果熔断则调用降级
String result = Try.ofSupplier(decoratedSupplier)
.recover(throwable -> "Fallback response").get();5、Hystrix、Resilience4j、Sentinel对比
| 对比维度 | Hystrix (Netflix) | Resilience4j | Sentinel (Alibaba) |
|---|---|---|---|
| 核心架构 | 基于命令模式HystrixCommand | 基于函数式接口Supplier/CheckedRunnable | 基于责任链模式Slot Chain |
| 隔离策略 | 线程池隔离/信号量隔离 | 信号量隔离(默认)+线程池隔离(可选) | 滑动窗口+令牌桶(无原生线程隔离) |
| 熔断机制 | 滑动窗口统计错误率,阈值触发熔断 | 滑动窗口统计错误率,支持自定义触发条件 | 滑动窗口统计实时指标,动态熔断规则 |
| 流量控制 | 不支持(需结合线程池限流) | 不支持(需结合外部组件) | 支持(QPS/线程数限流、集群流控) |
| 降级策略 | fallbackMethod 实现降级逻辑 | Retry/CircuitBreaker/ Fallback组合 | blockHandler/fallback 自定义降级 |
| 配置方式 | 注解+代码配置@HystrixCommand | 注解+配置文件YAML/Properties | 注解+动态数据源API/Nacos/Zookeeper |
| 实时监控 | Hystrix Dashboard(需配合Turbine聚合) | Micrometer+ Prometheus/Grafana | Sentinel Dashboard(实时指标可视化) |
| 线程模型 | 每个依赖服务独立线程池 | 调用方线程(信号量隔离)或独立线程池 | 调用方线程(无原生线程隔离) |
| 集群支持 | 不支持 | 不支持 | 支持(集群流控、熔断) |
| 动态规则 | 不支持(需重启) | 支持(通过配置中心热更新) | 支持(实时推送规则变更) |
| 适用场景 | 传统单体架构迁移微服务 | 轻量级微服务(Spring Boot 2+) | 高并发分布式系统(尤其阿里生态) |
(六)网关(API Gateway)
Spring Cloud Gateway 是Spring Cloud生态中的API网关组件,基于Reactor、WebFlux和Netty 等响应式编程技术构建,提供了路由转发、过滤、限流、熔断等核心功能。
1、常用组件
1)Spring Cloud Gateway
基于Reactor的高性能API网关,支持动态路由、请求过滤、限流等,非阻塞异步模型,替代Netflix Zuul(已停更)。
优势:高性能、动态路由、与 Spring Cloud 生态无缝集成。
2、底层原理
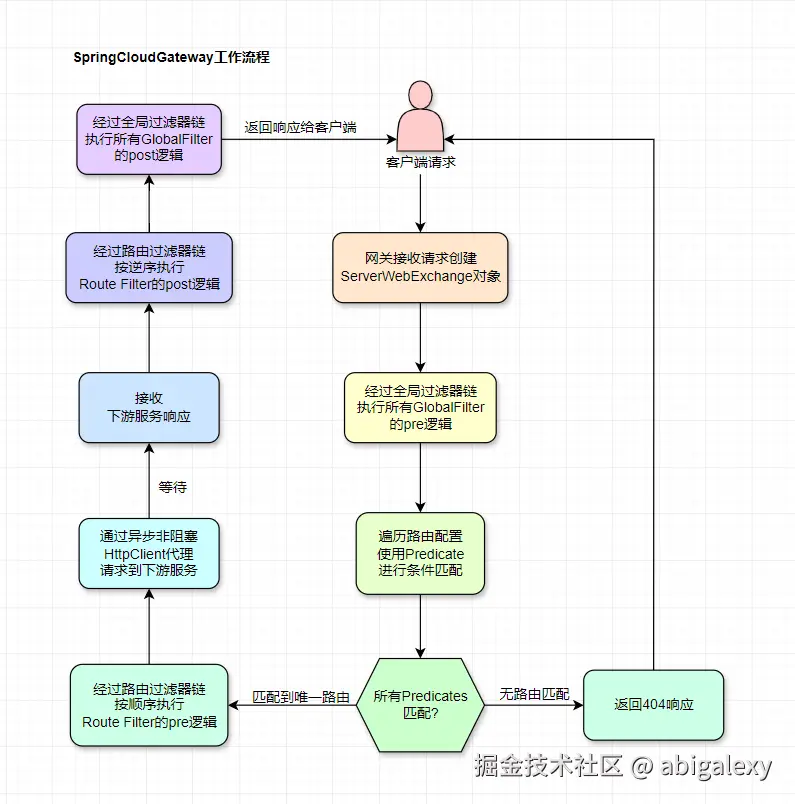
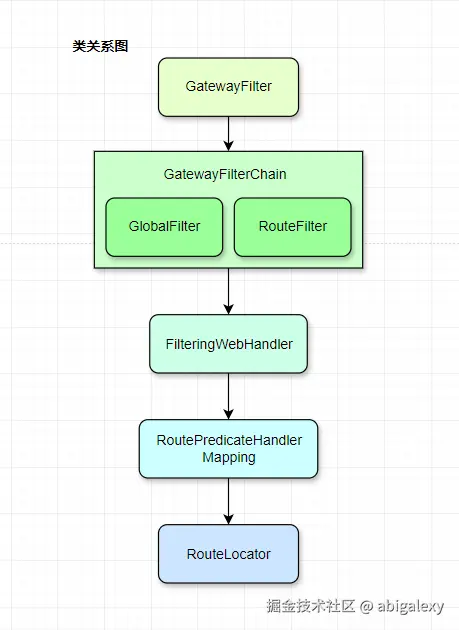
2.1 核心组件
1)路由 (Route)
路由是网关的基本构建块,由ID、目标URI、断言集合和过滤器集合组成
示例配置:
yaml
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://user-service
predicates:
- Path=/api/user/**
filters:
- AddRequestHeader=X-Request-Foo, Bar2)断言 (Predicate)
用于路由匹配的条件判断,支持多种内置断言:
Path: 路径匹配
Method: HTTP方法匹配
Header: 请求头匹配
Query: 查询参数匹配
Cookie: Cookie匹配
Host: 主机名匹配
etc.
3)过滤器 (Filter)
分两种类型:
GatewayFilter: 应用于单个路由
GlobalFilter: 全局过滤器,应用于所有路由
常见过滤器:
请求限流 (RequestRateLimiter)
熔断降级 (Hystrix/Resilience4j)
请求/响应修改 (AddRequestHeader, ModifyResponseBody)
认证授权 (JWT验证)
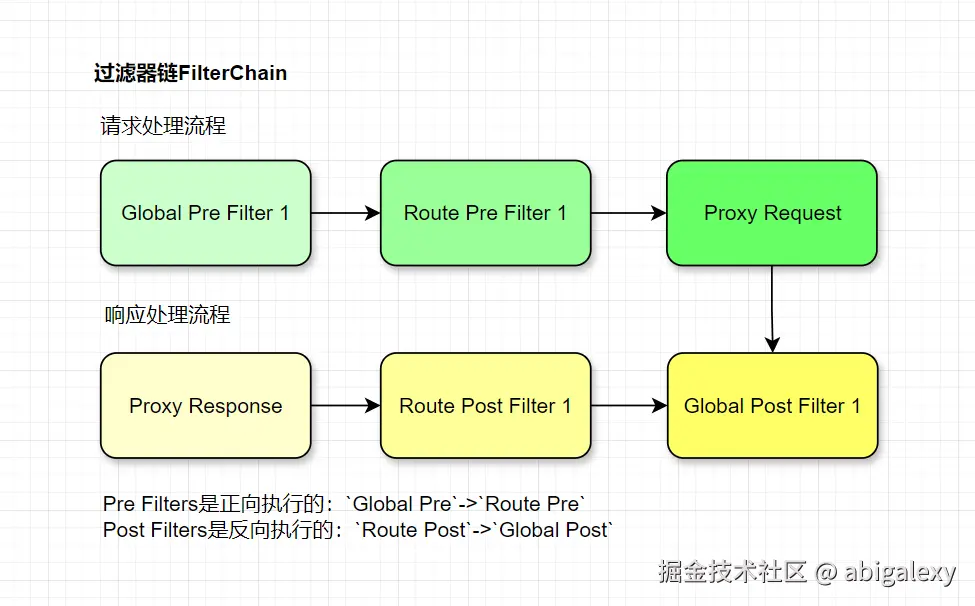
4)RouteLocator (路由定位器)
负责加载和刷新路由定义
包含两种实现:
PropertiesRouteDefinitionLocator: 从配置文件加载
DiscoveryClientRouteDefinitionLocator: 从服务发现加载
5)WebHandler (处理器)
基于Reactor的响应式处理链
核心处理流程:
java
Netty HTTP Request
→ RoutePredicateHandlerMapping (路由匹配)
→ FilteringWebHandler (过滤器链执行)
→ Netty WriteResponseFilter (响应返回)2.2 Reactive与Non-Blocking (响应式与非阻塞)
基于 Spring WebFlux,它使用了Project Reactor库(实现了Reactive Streams规范)。
核心类是 Mono (0-1个结果) 和 Flux (0-N个结果)。这使得网关可以用极少的线程(通常只有CPU核心数)处理大量并发连接,资源利用率高,特别适合IO密集型的网关场景。
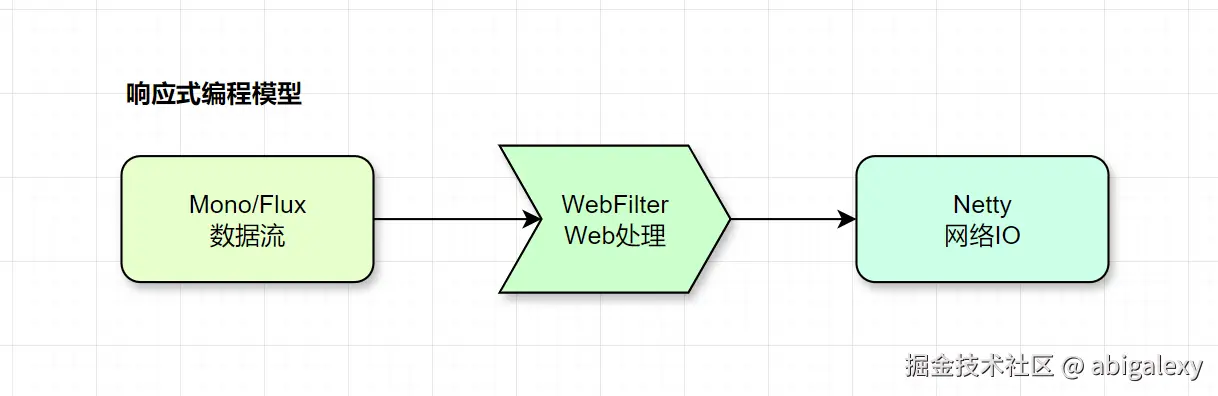
避免阻塞操作,合理使用subscribeOn和publishOn,批量操作使用Flux.buffer
2.3 Netty
WebFlux默认使用Netty作为Web服务器容器。Netty是一个高性能的异步事件驱动的网络应用框架。
网关向外暴露的服务和向下游服务发起请求的HttpClient都是基于Netty的。
3、调试与监控
1)路由信息端点
/actuator/gateway/routes: 查看所有路由
/actuator/gateway/refresh: 刷新路由缓存
2)关键指标
gateway.requests: 请求计数
gateway.response.status: 响应状态码分布
gateway.filters: 过滤器执行时间
3)日志配置
properties
logging.level.org.springframework.cloud.gateway=DEBUG
logging.level.reactor.netty=DEBUG4、性能优化
1)线程模型
使用Reactor的EventLoop线程模型
默认配置:
接收线程: Netty boss group
工作线程: Netty worker group (默认CPU核心数*2)
业务线程: Reactor调度线程 (parallel scheduler)
2)连接池配置
yaml
spring:
cloud:
gateway:
httpclient:
pool:
max-connections: 200
acquire-timeout: 45000(七)分布式链路追踪(Distributed Tracing)
1、常用组件
1)Sleuth
为微服务调用生成唯一的请求链路ID(TraceID、SpanID),便于日志追踪,集成Zipkin或Sentry实现分布式追踪。
2)Zipkin
收集和展示Sleuth产生的追踪数据,帮助开发者分析和诊断微服务之间的调用延迟问题。
3)SkyWalking
APM监控,第三方链路追踪系统,通过Sleuth收集数据并可视化调用链。
2、底层原理
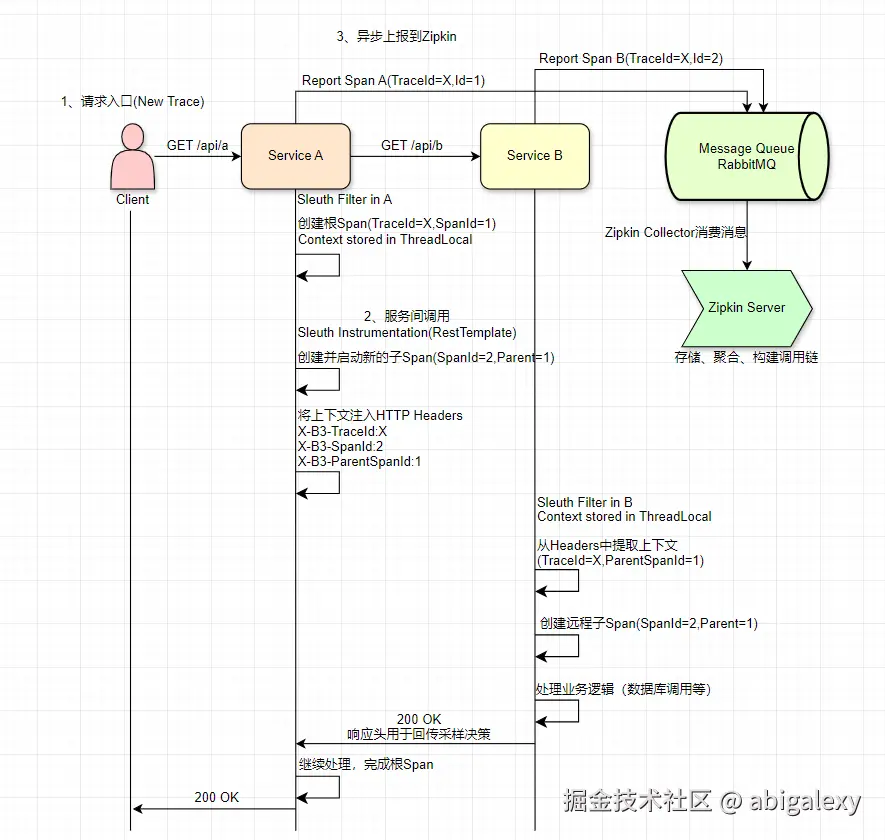
2.1 Sleuth核心组件
Trace ID:全局唯一标识,贯穿整个调用链
Span ID:标识单个操作单元
Parent Span ID:父子关系标识
Export:将追踪数据导出到存储系统
2.2 数据模型 (OpenTracing标准)
1)Trace
一个Trace代表一个完整的请求链路。它描述了一个请求从发出到被最终处理完毕的整个过程。
标识:用一个全局唯一的TraceId来标识。同一个请求链路上的所有Span都共享同一个TraceId。
类比:想象成一棵树(Trace),它由很多树枝(Span)组成。
2)Span
一个Span代表一个服务内部的工作单元或一个跨服务调用的节点。它是追踪的基本单位。例如,一次SQL查询、一次 HTTP 调用、一次方法执行都可以是一个Span。
标识:用一个全局唯一的SpanId来标识。
内容:一个 Span 通常包含:
操作名称(e.g., "/user/info")
开始时间戳和持续时间
Tags(键值对,记录一些附加数据,如 http.method=GET, db.statement="select...")
Logs(时间戳日志,用于记录特定事件,如异常信息)
SpanContext(包含 TraceId, SpanId以及需要传播到下游服务的baggage信息)
3)父子关系与上下文传播 (Context Propagation)
当一个服务(Span A)调用另一个服务时,调用者的 Span是父Span,被调用者产生的Span是子Span。
父 Span的SpanId 会作为子Span的ParentSpanId。
调用方需要将当前的TraceId和SpanId(以及其他信息)通过 HTTP Headers 等方式"注入"到请求中,传递给下游服务。
下游服务接收到请求后,从Headers中"提取"出这些信息,创建新的子Span,并建立父子关系。
数据模型示例
json
{
"traceId": "abc123",
"id": "def456",
"parentId": "ghi789",
"name": "get-user",
"timestamp": 1620000000000,
"duration": 100,
"tags": {
"http.method": "GET",
"http.path": "/api/user"
},
"localEndpoint": {
"serviceName": "service-a"
}
}2.3 Instrumentation (插桩)
Sleuth的核心是自动插桩。它通过一系列过滤器、拦截器、包装器自动完成 Span 的创建和上下文的传播,开发者通常只需添加依赖和配置,无需大量修改业务代码。
2.4 采样策略
AlwaysSampler:采样所有请求
PercentageBasedSampler:按比例采样
RateLimitingSampler:限速采样
自适应采样:根据系统负载动态调整
采样率决定收集多少比例的追踪数据(例如 10%)。Sleuth 支持配置采样策略,如固定速率采样、自适应采样等。
2.5 传播机制
上下文传播 (Context Propagation)
通过 TraceContext 和相关的注入器(Injector)与提取器(Extractor)实现的。
除了 HTTP,上下文还可以通过消息中间件(如 Kafka, RabbitMQ)、gRPC 等任何方式进行传播。
通过HTTP头传播追踪上下文:
sh
X-B3-TraceId: abc123
X-B3-SpanId: def456
X-B3-ParentSpanId: ghi789
X-B3-Sampled: 12.6 与Zipkin/Sleuth集成
Sleuth 负责生成和传播追踪数据。
Zipkin 负责接收(通过 Reporter)、存储(支持内存、Elasticsearch、Cassandra)和展示数据。
它们通过各自定义的 API(如 Zipkin 的 v1/v2 API)进行通信。
Spring Cloud Sleuth是Spring Cloud的分布式追踪解决方案,常与Zipkin配合使用:
java
// 添加依赖
implementation 'org.springframework.cloud:spring-cloud-starter-sleuth'
implementation 'org.springframework.cloud:spring-cloud-sleuth-zipkin'3、问题排查
TraceID不连续:检查传播头是否被修改/过滤
数据丢失:检查导出器配置和收集器健康状态
时间偏差:确保所有服务时间同步
采样率过低:调整采样策略配置
(八)消息总线(Message Bus)
1、常用组件
1)Spring Cloud Bus
通过RabbitMQ或Kafka广播配置变更消息,实现配置的动态刷新(如 /actuator/bus-refresh)。
2、底层原理
事件驱动:通过消息中间件(如 RabbitMQ、Kafka)广播配置变更事件。
应用场景:配合Config Server实现大规模集群的配置动态刷新。
工作流程:
配置更新时,Config Server发布事件到 Bus。
所有订阅了Bus的Config Client接收事件并刷新配置。
二、其他组件
Spring Cloud Stream:用于构建消息驱动的微服务。通过 Binder 抽象屏蔽了底层消息中间件(如 Kafka, RabbitMQ)的差异,使开发者可以专注于业务逻辑。
Spring Cloud Security:基于OAuth2的认证授权框架,集成Spring Security实现单点登录(SSO)和令牌验证。
Spring Cloud Kubernetes:将 Spring Cloud与Kubernetes生态集成。
三、Spring Cloud设计哲学
1、解耦与集成:通过抽象层(如DiscoveryClient、LoadBalancerClient)屏蔽底层实现差异。
2、约定优于配置:默认集成主流组件(如Eureka + Ribbon + Hystrix),降低学习成本。
3、响应式编程:Gateway和部分组件基于Reactor,适应高并发场景。
4、生态扩展性:支持替换组件(如用Nacos替代Eureka,Sentinel替代Hystrix)。
四、版本说明
1、Spring Cloud Netflix (已进入维护模式,但概念仍广泛使用)
1)Eureka:服务注册与发现组件。服务启动后向 Eureka Server 注册自身信息,其他服务通过 Eureka Server 发现并调用目标服务。
2)Ribbon:客户端负载均衡器。在服务消费者端,根据特定策略(如轮询、随机)选择一个服务实例进行调用。
3)Hystrix:服务容错保护(熔断器)。当服务出现故障或延迟时,提供降级、隔离、熔断和监控功能,防止雪崩效应。
4)Feign (现为OpenFeign):声明式的REST客户端。简化了服务间的HTTP调用,使用注解方式定义接口即可完成远程调用。
5)Zuul (现多被Spring Cloud Gateway取代):API 网关。提供路由、过滤、负载均衡、安全认证等功能,是微服务系统的统一入口。
2、Spring Cloud Alibaba (重要生态)
虽然不是 Spring Cloud官方项目,但已成为国内微服务开发的重要选择,提供了与阿里系技术栈集成的组件:
Nacos:集服务注册发现、配置中心于一体的动态服务发现与配置管理平台。
Sentinel:流量控制、熔断降级、系统负载保护的高可用防护组件。
RocketMQ:分布式消息中间件。
五、组件选型
服务发现:Nacos(推荐)> Consul
熔断:Resilience4j、Sentinel
网关:Spring Cloud Gateway
配置中心:Nacos Config > Spring Cloud Config
Spring Cloud通过模块化组件覆盖微服务全生命周期(注册、通信、容错、监控等),开发者可根据需求灵活组合。
示例:Nacos + Gateway + LoadBalancer + Resilience4j + Seata
六、参考
1、Spring Cloud主站
2、GitHub 仓库
3、关键组件文档
Spring Cloud Netflix (Eureka/Ribbon/Hystrix)
cloud.spring.io/spring-clou...
Spring Cloud Alibaba(Nacos/Sentinel)
Spring Cloud Gateway
Spring Cloud Config
cloud.spring.io/spring-clou...
4、Spring Cloud版本兼容性,各版本与Spring Boot的对应关系