读写分离的基本结构:
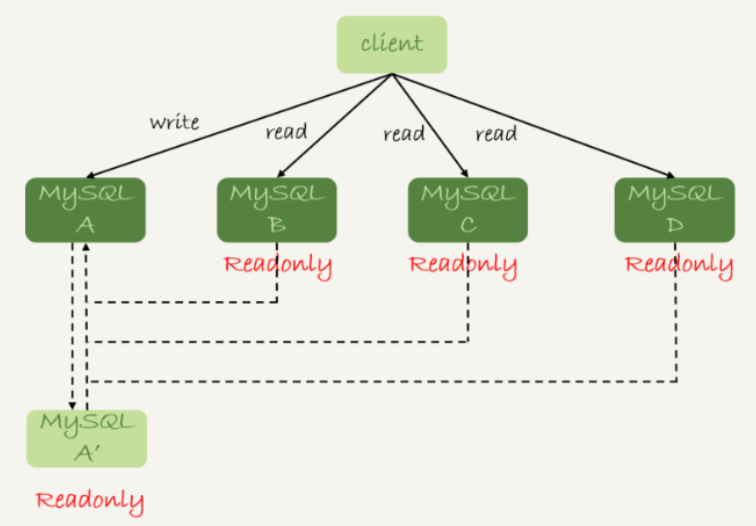
上图的结构是客户端主动做负载均衡,这种模式下一般会把数据库连接信息放在客户端的连接层,由客户端选择后端数据库进行查询。
还有一种架构是在MySQL和客户端间加入中间代理层proxy,客户端只连接proxy,由proxy根据请求类型和上下文决定请求的分发路线:
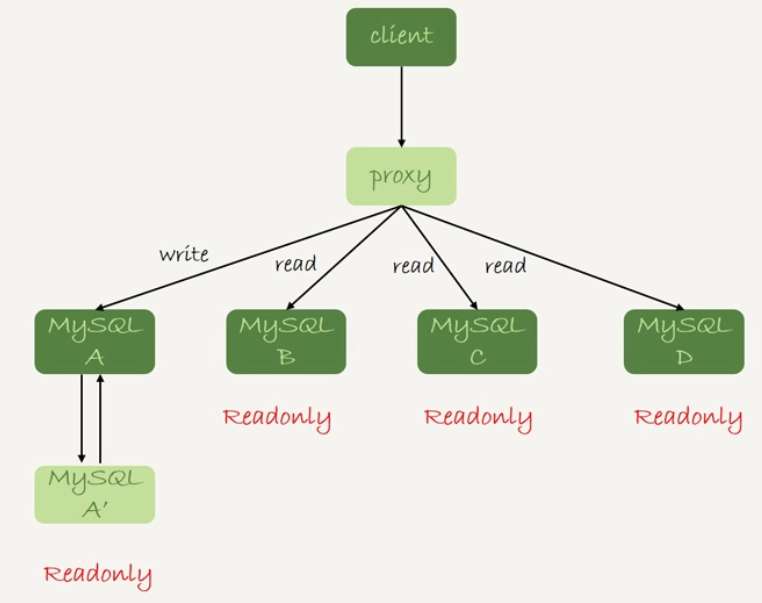
比较这两种架构:
-
客户端直连:少了一层,查询性能会好一点,且整体架构简单,排查问题更方便。但在主备切换、库迁移等操作的时候,客户端有感知,需要调整数据库连接信息,一般会用Zookeeper等进行后端管理;
-
proxy架构:客户端不需要关注后端细节,但对维护proxy的团队要求更高,整体架构复杂。
但不论使用哪种架构,由于主从延迟,客户端执行完一个更新事务后马上发起查询,如果查询选择的是从库,都有可能读到刚刚的事务更新之前的状态。
暂时称这种"在从库上读到系统的一个过期状态"的现象为过期读。客户端肯定希望查询从库的数据结果和查主库的数据结果相同,因此接下来就讨论如何处理过期读问题,本文涉及到的处理方案有:
-
强制走主库方案;
-
sleep方案;
-
判断主备无延迟方案;
-
配合semi-sync方案;
-
等主库位点方案;
-
等GTID方案。
强制走主库方案
强制走主库其实就是将查询请求做分类,通常查询请求分为两类:
-
对于必须要拿到最新结果的请求,强制将其发到主库上,比如一个交易平台,卖家发布商品以后要返回主页面查看是否发布成功,该请求必须走主库;
-
对于可以读到旧数据的请求,将其发到从库上,比如买家逛商铺页面,就算晚几秒看到最新商品也是能接受的。
该方案的最大问题是有时候碰到所有查询都必须拿到最新结果的需求,所有读写压力实际上都在主库,即放弃了读写分离。
Sleep方案
主库更新后,读从库之前先sleep,比如执行一条select sleep(1)命令。该方案就是假设大多数情况下主备延迟在1秒内,sleep有很大概率拿到最新数据。
比如卖家发布商品,商品发布后用Ajax直接把客户端输入的内容作为新的商品显示在页面,这样卖家通过显示就已经确认产品发布成功,等到再刷新页面去查看商品,其实已经过了一段时间,也就达到了sleep的目的。
该方案的问题是不精确:
-
如果查询请求本来0.5秒就可以在从库上拿到正确请求,也会等1秒;
-
如果延迟超过一秒,还是会出现过期读。
判断主备无延迟方案
确保备库无延迟,通常有三种做法。
第一种确保主备无延迟的方法是,每次从库执行查询请求前,先判断seconds_behind_master是否已经等于0,如果不等于0就等到这个参数变成0才能执行查询请求。
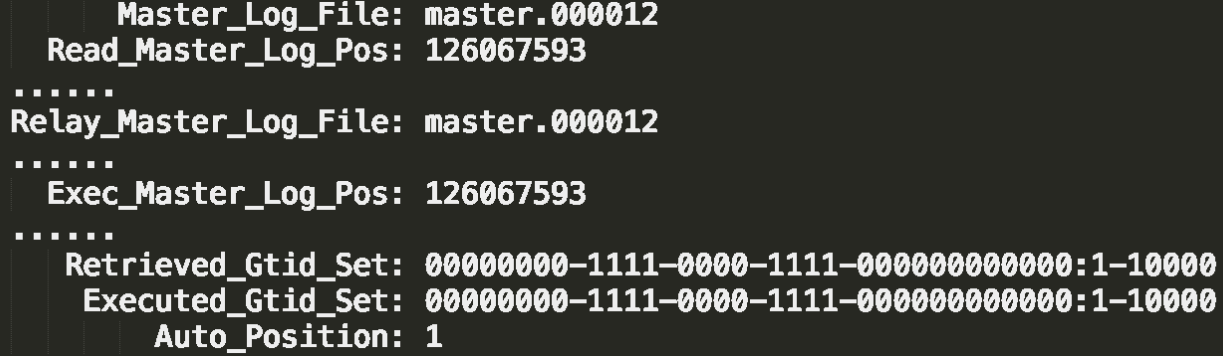
第二种是对比位点。比如有一个show slave status结果的部分截图:
-
Master_Log_File和Read_Master_Log_Pos:表示读到的主库的最新位点;
-
Relay_Master_Log_File和Exec_Master_Log_Pos:表示备库执行的最新位点。
如果两组值完全相同,就表示接收到的日志已经同步完成。
第三种是对比GTID集合确保主备无延迟:
-
Auto_Position=1,表示这对主备关系使用了GTID协议;
-
Retrieved_Gtid_Set,是备库收到的所有日志的GTID集合;
-
Executed_Gtid_Set,是备库所有已经执行完成的GTID集合。
如果这两个集合相同,表示备库接收到的日志都已经同步完成。
这些方法相比sleep准确度提升了很多,但是还是没达到精确的程度。
接下来看看为什么说没达到精确。先回顾一个事务的binlog在主备库间的状态:
-
主库执行完成,写入binlog并反馈给客户端;
-
binlog被从主库发给备库,备库接收;
-
备库执行binlog完成。
上面的方法判断主备无延迟的逻辑是备库收到的日志都执行完成,但是有些日志处于客户端已经收到提交确认,而备库还没收到的状态,如下图:
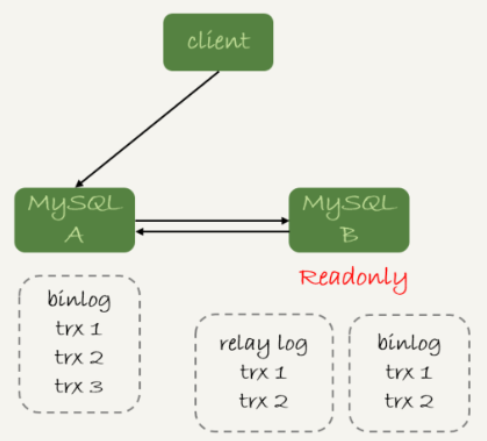
主库上执行完成三个事务trx1、trx2、trx3,其中:
-
trx1、trx2已经传到从库并执行完成;
-
trx3在主库执行完成并且回复给客户端,但还没传到从库中。
如果此时在从库B上执行查询请求,按照上面方法,从库认为没有同步延迟,但实际上查不到trx3,严格说就是出现了过期读。
配合semi-sync
要解决上面的问题,就要引入半同步复制semi-sync replication。
semi-sync做了设计:
-
事务提交的时候,主库把binlog发给从库;
-
从库收到binlog后,发回给主库一个ack,表示收到了;
-
主库收到这个ack后,才能给客户端返回事务完成的确认。
即所有给客户端发送过确认的事务,都确保了备库已经收到这个日志。
semi-sync加位点判断的方案,能避免过期读。但该方案只对一主一备的场景成立,在一主多从场景中,主库只要等到一个从库的ack就开始给客户端返回确认,此时在从库查询就有两种情况:
-
如果查询落在这个响应了ack的从库上,能确保读到最新数据;
-
如果查询落到其他从库,它们可能还没有收到最新的日志,就会产生过期读问题。
判断同步位点方案还有另一个潜在问题:如果在业务更新的高峰期,主库位点或者GTID集合更新很快,那么上面两个位点等值判断就会一直不成立。
实际上,当发起一个查询请求后,要得到准确的结果,其实并不需要等到主备完全同步。比如下面的时序图:
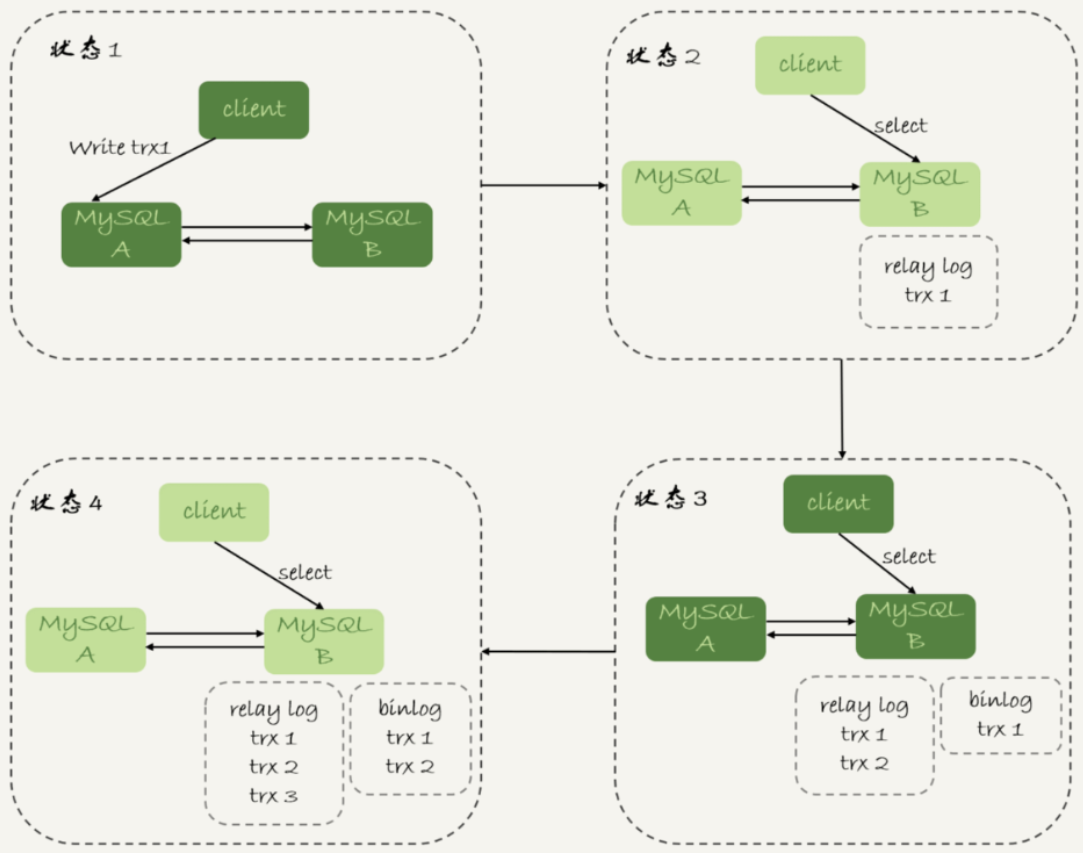
上图中,从状态1到状态4,一直处于延迟一个事务的状态,那么如果按上面必须等到无延迟才能查询的方案,select语句直到状态4都不能被执行。但客户端是在发完trx1更新后发起的select语句,只需要确保trx1执行完就可以select了,即状态3执行查询请求其实就能获得预期结果了。
总结semi-sync配合判断主备无延迟的方案存在的问题:
-
一主多从,在某些从库执行查询请求会存在过期读的现象;
-
在持续延迟情况下,可能出现过度等待。
接下来介绍等主库位点方案,可以解决这两个问题。
等主库位点方案
先介绍一条命令:
sql
select master_pos_wait(file, pos[, timeout]);该命令的逻辑为:
-
该命令在从库执行;
-
file和pos指主库上的文件名和位置;
-
timeout可选,设置为正整数N表示这个函数最多等待N秒。
该命令正常返回结果是一个正整数M,表示从命令开始执行,到应用完file和pos表示的binlog位置执行了多少事务。此外还有其他结果:
-
如果执行期间,备库同步线程发生异常,则返回null;
-
如果等待超过N秒返回-1;
-
如果刚开始执行时候,发现已经执行过这个位置,返回0。
那么对于之前先执行trx1再执行一个select的逻辑,要保证能查到正确数据,可以使用的逻辑:
-
trx1事务更新完成后,马上执行show master status得到当前主库执行到的file和position;
-
选定一个从库执行select;
-
在从库上执行
select master_pos_wait(file, position, 1); -
如果返回值大于等于0,则在这个从库执行查询语句;
-
否则,到主库执行查询。
整个流程为:
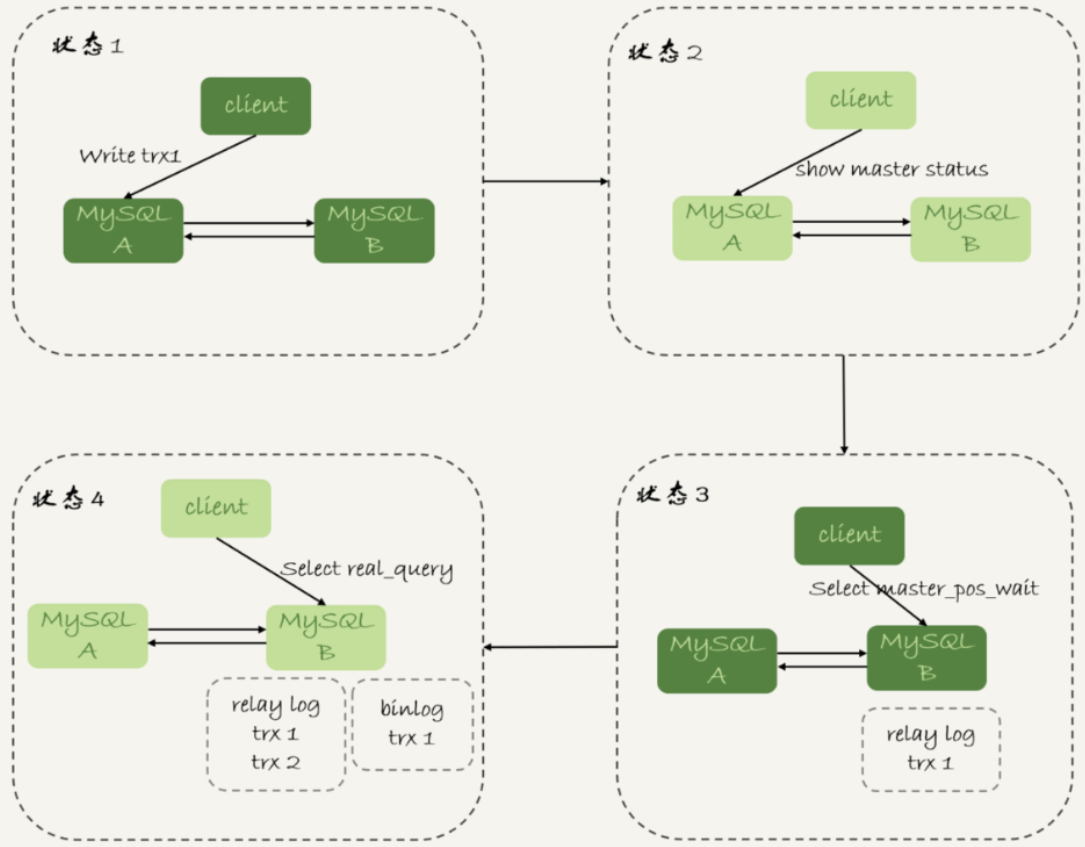
这里假设这条select最多在从库上等待一秒,那么如果一秒内master_pos_wait返回一个大于等于0的整数,就确保从库上执行的查询结果包含trx1的数据。
最后一步到主库执行查询,是这类方案常用的退化机制,因为不能无限等待从库。
GTID方案
如果数据库开启了GTID模式,对应的也有等待GTID的方案。
MySQL提供了一个类似的命令:
sql
select wait_for_executed_gtid_set(gtid_set, 1);其逻辑为:
-
等待,直到这个库执行的事务中包含传入的gtid_set,返回0;
-
超时返回1。
在前面等位点的方案中,执行完事务后,还要主动去主库执行show master status。而MySQL 5.7.6版本开始,允许在执行完更新类事务后,把这个事务的GTID返回给客户端,这样等GTID的方案就可以减少一次查询。
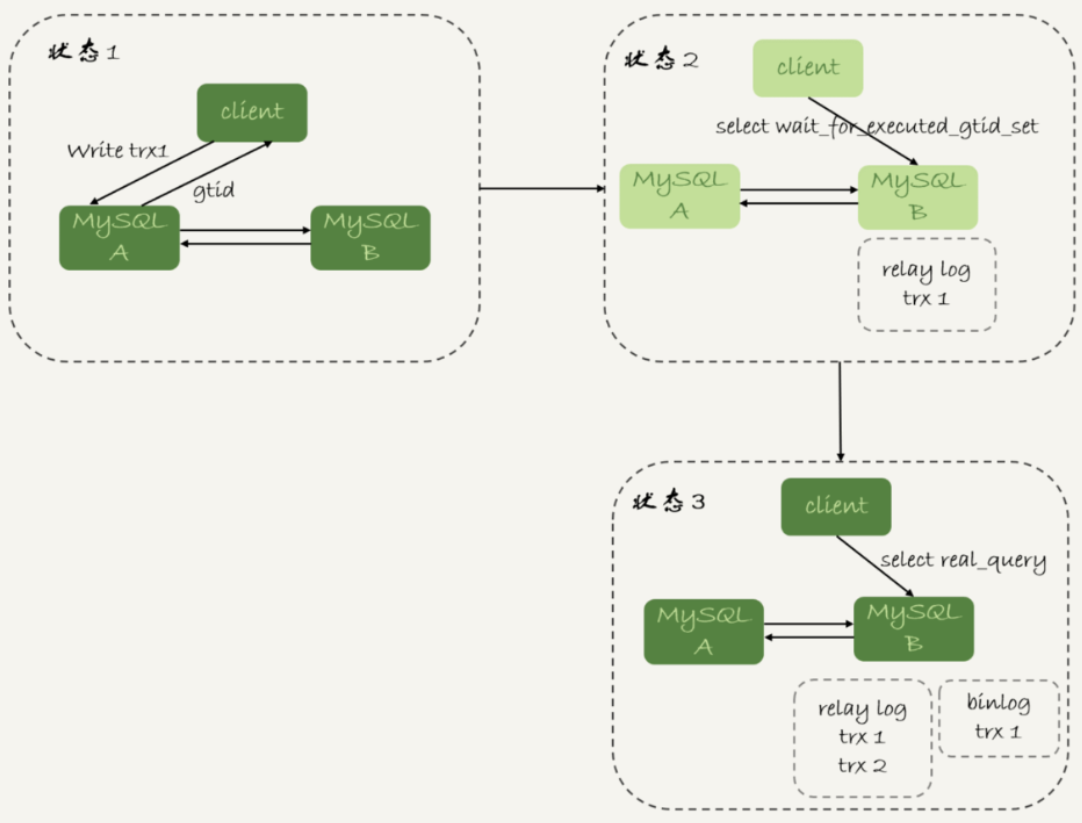
此时执行流程变为:
-
trx1事务更新完成后,从返回包直接获取这个事务的GTID,记为gtid1;
-
选定一个从库执行查询语句;
-
在从库上执行select wait_for_executed_gtid_set(gtid1, 1);
-
如果返回值是0,则在这个从库执行查询语句;
-
否则,到主库执行查询语句。
流程图:
为了让第一步MySQL执行完事务在返回包带上GTID,需要将参数session_track_gtids设置为OWN_GTID,然后通过API接口mysql_session_track_get_first从返回包解析出GTID的值。