转载请注明出处:小锋学长生活大爆炸xfxuezhagn.cn
如果本文帮助到了你,欢迎***点赞、收藏、关注***哦~
目录
整体流程

每步详细
1、接受后,会自动进入到发表流程,会收到邮件提醒。
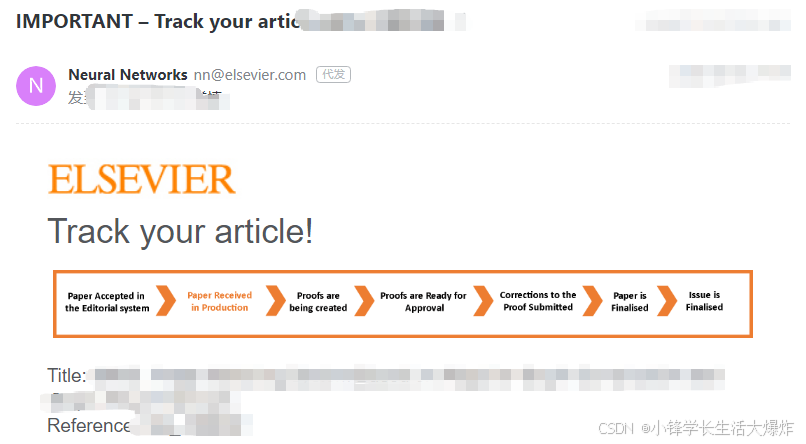
2、(等流转到了再更新)
监听脚本
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import os
import re
import time
import logging
import requests
from typing import Dict, List, Tuple, Any, Optional
from email.utils import formatdate # 保留导入以便需要时扩展
from bs4 import BeautifulSoup
# ---------------- 固定配置 ----------------
URL = "https://authors.elsevier.com/tracking/article/details.do?aid=<>&jid=<>&surname=<>"
INTERVAL_SECONDS = 3600 # 间隔一小时
REQUEST_TIMEOUT = 20
MAX_RETRIES = 3
# -----------------------------------------
# -------- 通知接口 --------
NOTIFY_URL = "http://14.103.144.178:7790/send/friend"
TARGET_ID = ["wxid_043", "wxid_lg"]
API_KEY = "xxxx"
def do_send_notification(target_id: str, message: str) -> None:
"""发送通知(单个目标)。使用 params 以确保正确编码。"""
try:
params = {"target": target_id, "key": API_KEY, "msg": message}
resp = requests.get(NOTIFY_URL, params=params, timeout=10)
if resp.status_code == 200:
print(f"[通知] 已发送成功 → {target_id}")
else:
print(f"[通知] 发送失败 → {target_id},状态码: {resp.status_code},响应: {resp.text[:200]}")
except Exception as e:
print(f"[通知] 请求发送失败 → {target_id}: {e}")
def send_notification(message: str) -> None:
"""批量发送通知"""
if isinstance(TARGET_ID, list):
for tid in TARGET_ID:
do_send_notification(tid, message)
time.sleep(1)
else:
do_send_notification(TARGET_ID, message)
# ---------------------------------------------------------------
HEADERS = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0 Safari/537.36",
"Accept-Language": "en,zh-CN;q=0.9,zh;q=0.8",
}
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s %(levelname)s: %(message)s"
)
_stop = False
def _handle_signal(signum, frame):
global _stop
logging.info("Received signal %s; preparing to stop after current cycle...", signum)
_stop = True
try:
import signal
for sig in (signal.SIGINT, signal.SIGTERM):
signal.signal(sig, _handle_signal)
except Exception:
pass
def _norm_text(s: str) -> str:
if not s: return ""
import re as _re
return _re.sub(r"\s+", " ", str(s)).strip()
def fetch_html(url: str, retries: int = MAX_RETRIES, timeout: int = REQUEST_TIMEOUT) -> str:
last_exc = None
for i in range(retries):
try:
with requests.Session() as s:
s.headers.update(HEADERS)
resp = s.get(url, timeout=timeout, allow_redirects=True)
resp.raise_for_status()
return resp.text
except Exception as e:
last_exc = e
logging.warning("Fetch attempt %s failed: %s", i+1, e)
time.sleep(2 * (i + 1))
raise RuntimeError(f"Failed to fetch page after {retries} attempts: {last_exc}")
def parse_snapshot(html: str) -> Dict[str, Any]:
"""
返回包含三项信息的快照:
- lastUpdatedDate: str
- statusComment: str
- productionEvents: List[Dict[str, str]] (键:date, event)
"""
soup = BeautifulSoup(html, "html.parser")
# 1) lastUpdatedDate
last_updated = ""
el = soup.select_one("#lastUpdatedDate")
if el:
last_updated = _norm_text(el.get_text())
else:
candidates = soup.find_all(string=re.compile(r"Last update", re.I))
if candidates:
node = candidates[0].parent
last_updated = _norm_text(node.get_text())
# 2) Status comment
status_comment = ""
label = soup.find(string=re.compile(r"Status comment", re.I))
if label:
container = label.parent
dd = container.find_next(["dd","p","span","div"])
status_comment = _norm_text((dd.get_text() if dd else container.get_text()).replace(str(label), ""))
if not status_comment: status_comment = _norm_text(container.find_next(string=True) or "")
else:
possible = soup.find_all(string=re.compile(r"(Status comment|status:|status\s+comment)", re.I))
if possible: status_comment = _norm_text(possible[0])
# 3) Production events
production_events: List[Dict[str, str]] = []
head = soup.find(string=re.compile(r"Production events", re.I))
if head:
sec = head.parent
table = sec.find_next("table")
if table:
rows = table.find_all("tr")
for r in rows:
cols = [ _norm_text(c.get_text()) for c in r.find_all(["td","th"]) ]
if len(cols) >= 2:
date, event = cols[0], cols[1]
if re.match(r"(?i)date", date) and re.match(r"(?i)event", event): continue
if date or event: production_events.append({"date": date, "event": event})
else:
ul = sec.find_next("ul")
if ul:
for li in ul.find_all("li"):
txt = _norm_text(li.get_text())
m = re.match(r"^(\d{1,4}[-/]\d{1,2}[-/]\d{1,2}).*?[----]\s*(.+)$", txt)
if m: production_events.append({"date": m.group(1), "event": m.group(2)})
else: production_events.append({"date": "", "event": txt})
return {
"lastUpdatedDate": last_updated,
"statusComment": status_comment,
"productionEvents": production_events,
}
def diff_snapshots(old: Optional[Dict[str, Any]], new: Dict[str, Any]) -> Tuple[bool, str]:
if not old:
return False, "Baseline initialized." # 启动即基线,不通知
changes = []
if old.get("lastUpdatedDate") != new.get("lastUpdatedDate"):
changes.append(f"• lastUpdatedDate: '{old.get('lastUpdatedDate')}' → '{new.get('lastUpdatedDate')}'")
if _norm_text(old.get("statusComment","")) != _norm_text(new.get("statusComment","")):
changes.append(f"• Status comment changed:\n OLD: {old.get('statusComment')}\n NEW: {new.get('statusComment')}")
old_events = old.get("productionEvents", [])
new_events = new.get("productionEvents", [])
if old_events != new_events:
old_set = {(e.get("date",""), e.get("event","")) for e in old_events}
new_set = {(e.get("date",""), e.get("event","")) for e in new_events}
added = new_set - old_set
removed = old_set - new_set
if added: changes.append("• Production events --- ADDED:\n " + "\n ".join([f"{d} --- {ev}" for d,ev in added]))
if removed: changes.append("• Production events --- REMOVED:\n " + "\n ".join([f"{d} --- {ev}" for d,ev in removed]))
if not added and not removed: changes.append("• Production events changed order/content.")
if not changes: return False, "No change detected."
return True, "\n".join(changes)
def format_snapshot_for_message(snap: Dict[str, Any], url: str) -> str:
lines = [
f"URL: {url}",
f"LastUpdatedDate: {snap.get('lastUpdatedDate','')}",
f"Status comment: {snap.get('statusComment','')}",
"Production events:"
]
events = snap.get("productionEvents") or []
if not events:
lines.append(" (none)")
else:
for e in events: lines.append(f" - {e.get('date','')} --- {e.get('event','')}")
return "\n".join(lines)
def run_daemon():
prev_snap: Optional[Dict[str, Any]] = None
backoff = 300 # 错误时等待 5 分钟再试
while not _stop:
try:
html = fetch_html(URL)
new_snap = parse_snapshot(html)
changed, diff_msg = diff_snapshots(prev_snap, new_snap)
if prev_snap is None:
logging.info("初始化成功:\n%s", format_snapshot_for_message(new_snap, URL))
elif changed:
snapshot_text = format_snapshot_for_message(new_snap, URL)
message = f"{diff_msg}\n\n状态已更新:\n{snapshot_text}"
send_notification(message)
logging.info("通知已发送.")
else:
logging.info("状态无变化.")
prev_snap = new_snap
# 等待固定间隔
for _ in range(int(INTERVAL_SECONDS)):
if _stop: break
time.sleep(1)
except Exception as e:
logging.exception("Cycle failed: %s", e)
# 失败则短暂退避后重试
for _ in range(backoff):
if _stop: break
time.sleep(1)
if __name__ == "__main__":
run_daemon()