大模型相关工作
CLIP
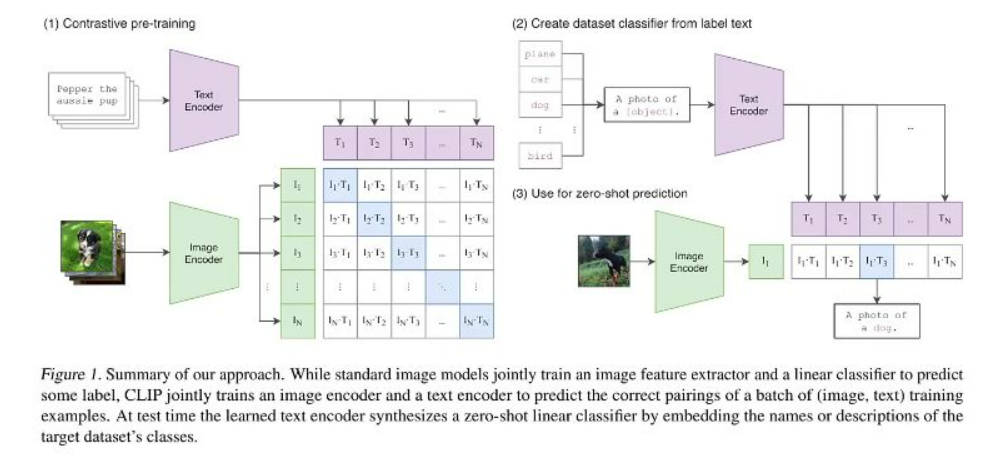
- 核心思想:通过对比学习实现图像和文本的跨模态对齐,将两者映射到同一特征空间
- 训练方式:
- 对比预训练:批量处理(image, text)配对数据,正样本对特征相近,负样本对特征相远
- 零样本分类:通过文本编码器生成类别描述的特征(如"a photo of a dog"),与图像特征计算相似度
- 创新点:
- 首次实现无需下游任务微调的零样本迁移能力
- 使用4亿规模的网络图像-文本对进行训练
- 局限性:无法处理复杂语义(如物体属性和空间关系)和多轮对话交互
BLIP-2
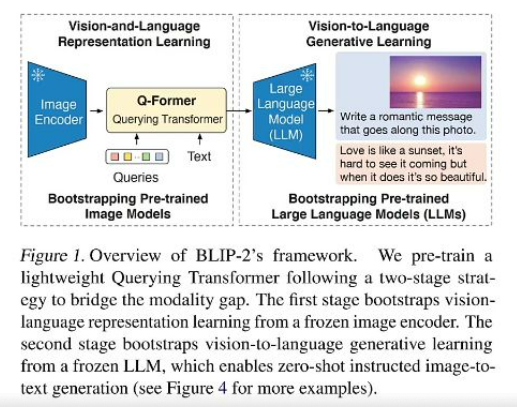
-
核心贡献:提出轻量级Querying Transformer(Q-Former)桥接冻结的视觉编码器和语言模型
-
两阶段训练:
- 表示学习阶段:通过三种任务训练Q-Former:
- 图像-文本对比学习(类似CLIP)
- 基于图像的文本生成(单向注意力)
- 图像-文本匹配(双向注意力)
- 生成学习阶段:将Q-Former输出适配到冻结LLM的输入空间
- 表示学习阶段:通过三种任务训练Q-Former:
-
关键技术:
- 特征降维:将高分辨率图像的数百token压缩至80个左右
- 注意力掩码设计:根据不同任务需求控制query-text交互方式
-
经济优势:仅需训练0.1%参数即可实现多模态能力,大幅降低计算成本
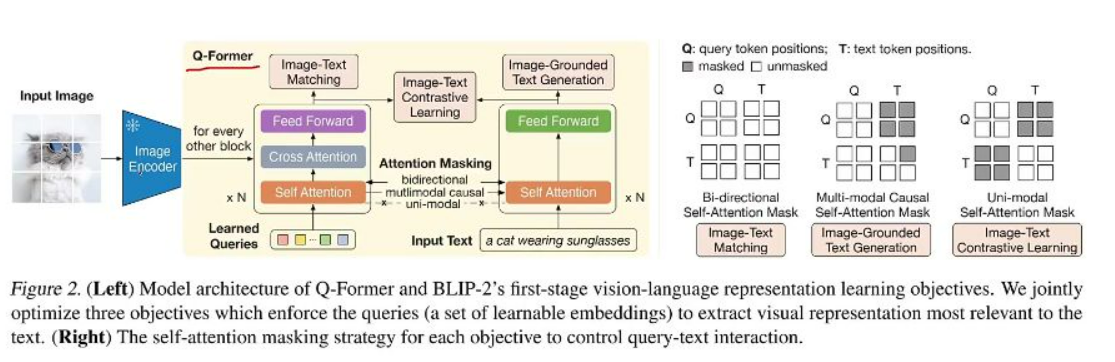
-
多任务训练:
- 对比学习:图像和文本特征独立提取后比对
- 文本生成:文本token可关注图像特征但禁止反向关注
- 匹配分类:双向交互判断图像文本是否匹配
Qwen-VL
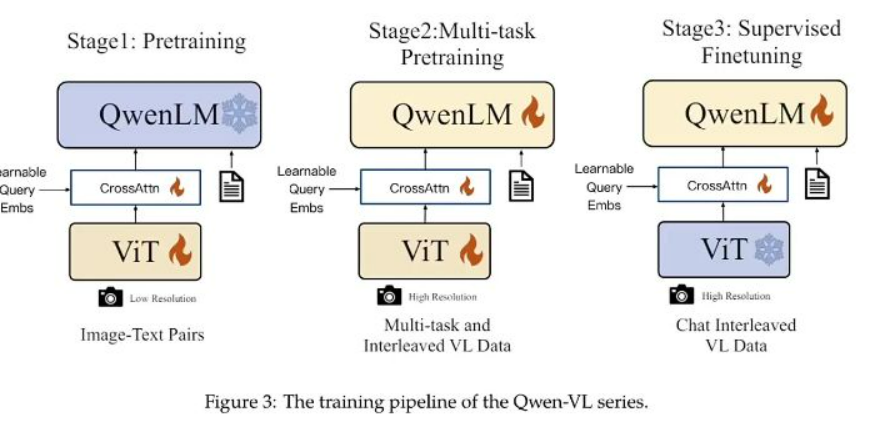
- 三阶段训练:
- 预训练:低分辨率图像+文本对基础对齐
- 多任务微调:高分辨率图像+多样化任务(VQA、OCR等)
- 监督微调:多轮对话数据增强交互能力
- 能力特点:
- 支持多图输入和长文本阅读理解
- 实现细粒度视觉定位(如指出图中特定区域)
- 多语言对话能力(中英文混合)
- 与BLIP-2区别:全参数微调视觉和语言模型,需要更大计算资源
DriveGPT4
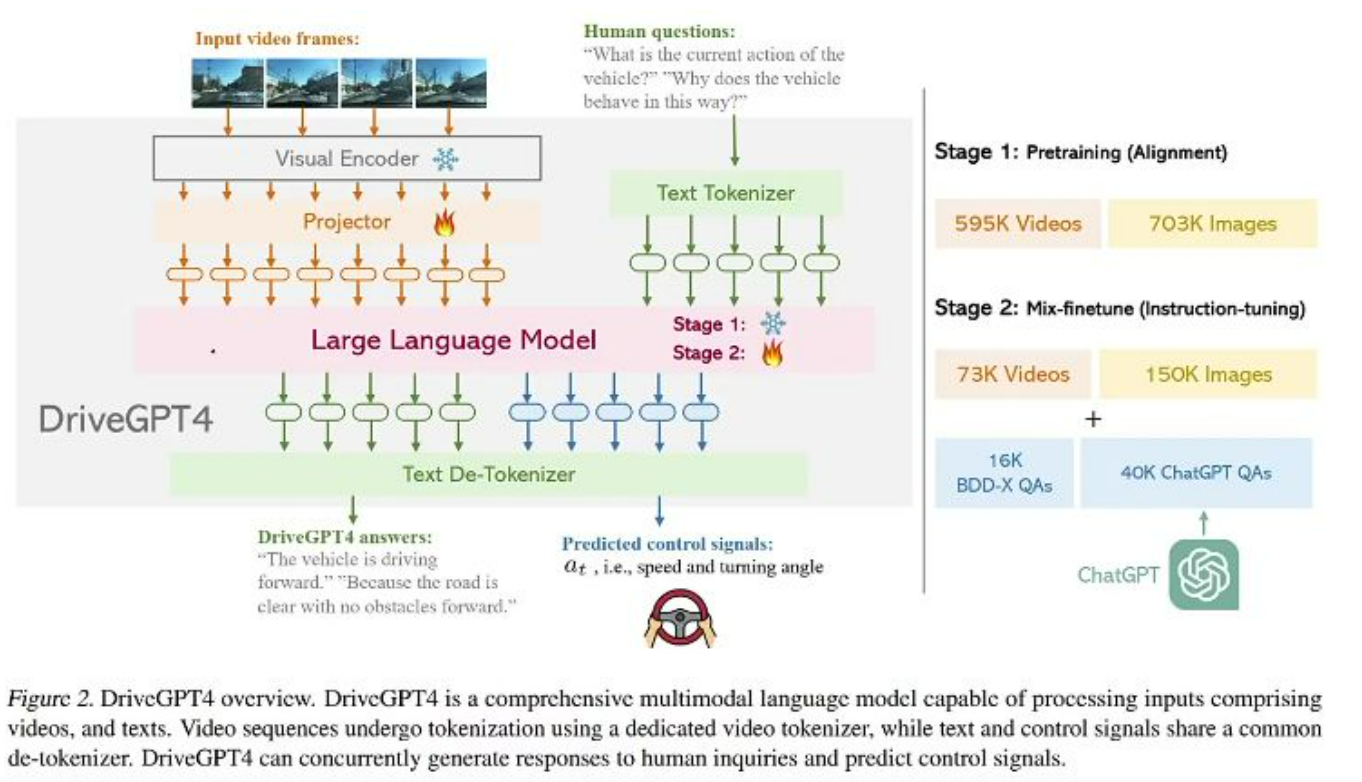
-
核心创新:将自动驾驶场景理解转化为语言模型任务
-
数据增强:
- 使用YOLOv8检测环境物体
- 通过ChatGPT自动生成丰富QA对(比原始BDD-X数据量增加40倍)
-
双阶段训练:
- 59.5万视频+70.3万图像预训练对齐模块
- 7.3万视频+15万图像混合微调
-
多任务输出:
- 自然语言解释驾驶行为("因红灯停车")
- 直接预测控制信号(速度,转向角)
- 风险提示和驾驶建议

-
可解释性设计:
- Action Description:当前行为描述(如"向右变道")
- Action Justification:行为依据(如"右侧车道车流更快")
- 控制信号预测:未来时段的连续运动参数
-
领域优势:
- 准确理解驾驶场景动态变化
- 数值控制信号预测能力(GPT-4V无法实现)
- 专业风险识别(如盲区车辆预判)
LMDrive 闭环自动驾驶
摘要
- 创新点: 提出首个语言引导的闭环端到端驾驶框架LMDrive,整合多模态传感器数据和自然语言指令
- 核心功能: 实时处理"Turn right at next intersection"等导航指令和"Watch for walkers up front"等注意指令
- 问题背景: 现有自动驾驶系统在长尾突发事件和复杂城市场景中表现不佳,缺乏语言理解和人机交互能力
- 数据集贡献: 公开包含64K指令跟随数据片段的数据集和LangAuto基准测试
本文贡献
- 框架创新:
- 闭环系统: 首个基于LLM的闭环端到端自动驾驶框架,支持持续驾驶
- 多模态整合: 同时处理多视角相机、LiDAR数据和语言指令
- 数据资源:
- 64K数据片段: 每个片段包含2-20秒的导航指令、注意指令、传感器数据和控制信号
- LangAuto基准: 测试误导/长指令和对抗性驾驶场景的处理能力
数据准备
- 指令类型:
- 导航指令: "Just move to the left and get ready to leave the highway"
- 注意指令: "Please watch out for the pedestrians up ahead"
- 多样化设计:
- Follow类: "Maintain your current course until the upcoming intersection"
- Turn类: "After x meters, take a left"
- Notice类: "Watch for walkers up front"(使用表示具体距离数值)
模型结构
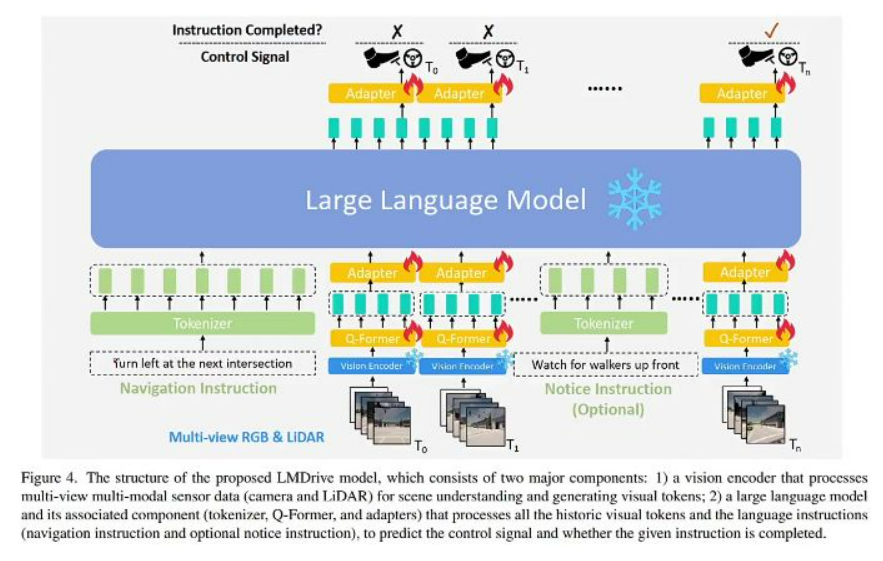
-
双组件设计:
- 视觉编码器: 处理多视角RGB和LiDAR数据,生成视觉token
- 语言模型组件: 包含tokenizer、Q-Former和适配器,处理历史视觉token和语言指令
-
输出机制:
- 控制信号预测: 通过PID控制器转换为刹车、油门和转向信号
- 指令完成检测: 判断当前帧是否已完成给定指令(如"前方50米左转"的完成状态)
-
感知模块预训练框架
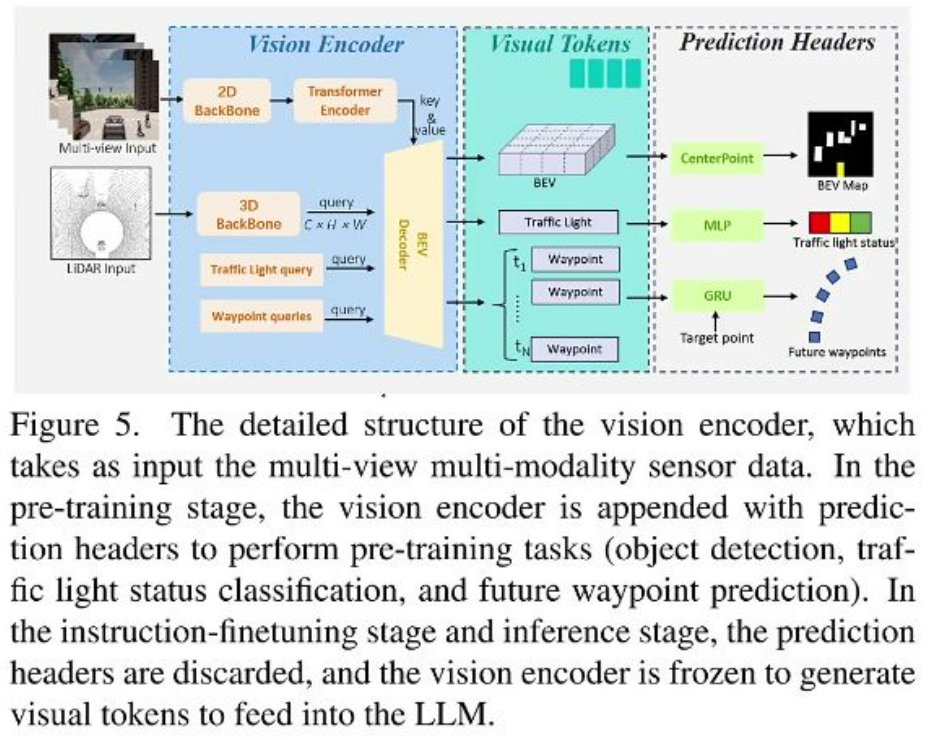
-
预训练任务:
- 目标检测: 生成BEV地图token
- 交通灯状态分类: 输出交通灯状态token
- 未来路径点预测: 通过GRU生成路径点token
-
训练阶段:
- 预训练阶段: 保留预测头进行监督学习
- 微调阶段: 冻结视觉编码器,仅生成视觉token供LLM使用
损失函数
- 多任务学习:
- 路径点损失:损失函数用于轨迹预测
- 分类损失: 交叉熵损失判断指令完成状态
- 时序监督:
- 历史帧预测: 训练时对所有历史帧进行预测增强监督信号
- 推理优化: 仅执行最新帧的预测以提高效率
消融实验
不同backbone比较
- 性能对比:
- 多模态优势: LLaVA-v1.5(36.2 DS)优于单模态LLaMA(31.3 DS)和Vicuna(33.5 DS)
- 规模效应: 参数量越大性能越好,但计算成本增加
- 评估指标:
- DS(驾驶分数)、RC(路线完成率)、IS(违规分数)三个维度综合评估
关键发现
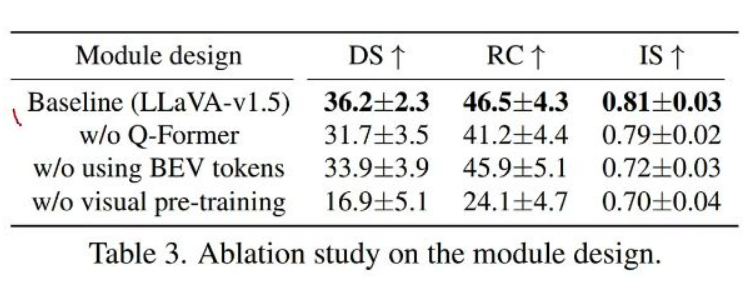
- Q-Former必要性: 去除后DS从36.2降至31.7,显示跨模态对齐的重要性
- BEV tokens贡献: 不使用BEV token导致IS从0.81降至0.72
- 预训练关键性: 无视觉预训练时性能急剧下降(DS 16.9)
不同实验设定

- 场景分类:
- LangAuto: 基础路线(>500米)
- LangAuto-Short: 中等路线(150-500米)
- LangAuto-Tiny: 短路线(<150米)
- 扩展场景:
- Notice轨道: 增加实时注意指令模拟乘客提醒
- Sequential轨道: 合并连续2-3条指令测试长指令理解
- 不同实验设定的比较
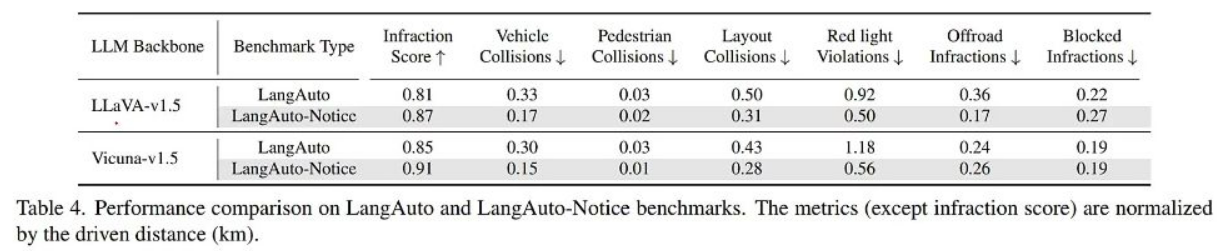
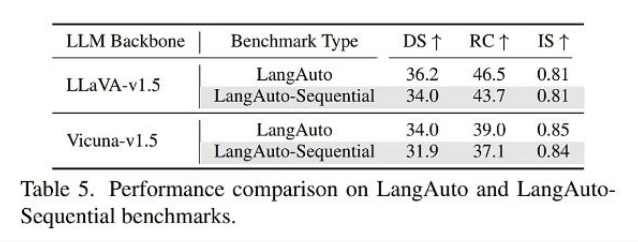
-
Notice效果:
- 安全提升: 加入注意指令后行人碰撞从0.03降至0.01
- 违规减少: 闯红灯违规从1.18降至0.56
-
Sequential挑战:
- 性能下降: DS从36.2降至34.0,显示合并指令增加理解难度
-
ChatGPT辅助生成指示

- 多样化生成:
- 变体创建: 对"Turn Right"生成8种不同表达方式
- 错误指令: 包含"Change to left-hand lane"(单车道)等违规指令
- 鲁棒性训练:
- 误导指令处理: 模型能拒绝"right on left-only lane"等错误指令
- 多指令组合: 测试"turn right up ahead and proceeding along this route"等复杂指令理解能力
- 多样化生成:
-
快慢双系统自动驾驶
方法
-
场景描述

- 环境总结: 输出天气(Ewhether)、时间(Etime)、道路类型(Eroad)和车道状况(Elane)等关键环境要素,例如"晴天/白天/城市道路/右车道不可通行"
- 危险目标识别: 检测可能影响驾驶决策的关键对象,如警车、施工区域等,需记录其类别和位置坐标(xi,yi)
- 数据形式: 结构化输出包含环境总结和危险目标列表,如图2所示案例中的施工人员与施工区域标注
-
场景分析

-
目标特性分析: 对危险目标进行三维度解析:
- 静态属性(Cs): 如卡车超限货物、路边广告牌等固有特征
- 运动状态(Cm): 包含位置、方向等动态信息,用于预测轨迹
- 特殊行为(Cb): 如交警手势等直接影响驾驶决策的行为
-
场景总结: 生成high-level的综合性描述,如"当前车辆正以恒定速度行驶,前方道路左侧有3名施工人员"
-
-
多层级规划

-
元动作生成: 从17类预定义动作中选择,如减速/左转/换道等,形成序列A={a1,a2,a3...}
-
决策描述: 细化动作为三元组(动作A +对象+S 时长D ),例如"等待(A )行人(S )通过后(D)加速"
-
轨迹生成: 输出未来时段内的路径点,Δt时间间隔为
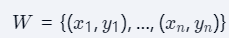
-
执行流程: 先通过语言交互生成粗粒度策略,再逐步细化为可执行轨迹
-
快慢双系统
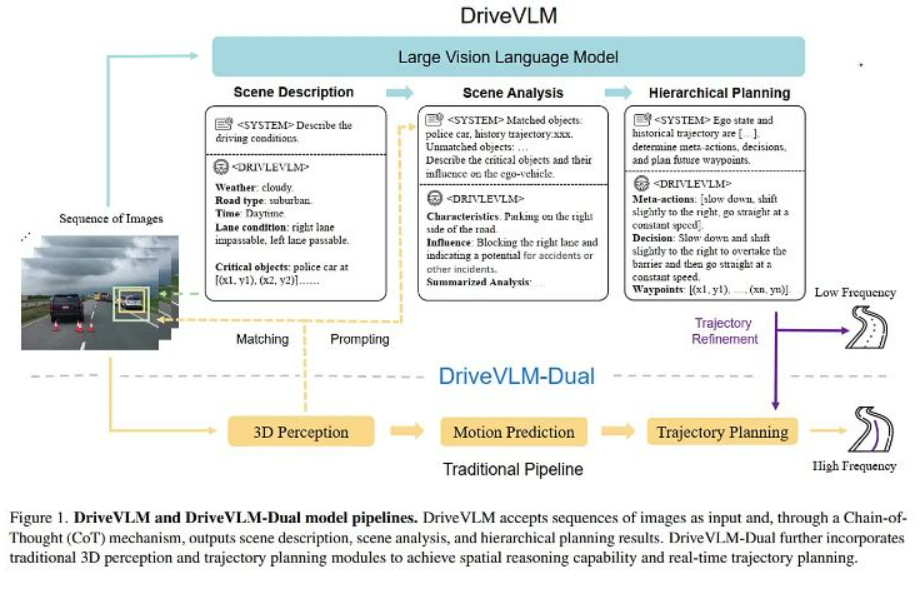
- 系统构成:
- DriveVLM: 纯VLM系统,通过思维链(CoT)机制实现2Hz低频推理
- DriveVLM-Dual: 融合传统AD模块(3D感知+轨迹规划)实现30Hz高频输出
- 感知匹配:
- 通过改进IoU算法(αIOU > t)对齐VLM识别的关键对象O_critical与3D检测结果O_3d
- 匹配对象用于增强提示,未匹配对象单独处理
- 轨迹优化:
- 低频轨迹Wslow作为传统规划器的初始解
- 优化公式:f为附加特征

- 实时性: 在Orin平台实现0.3s/场景的推理速度,与传统AD系统相当
总结
-
核心价值:
- 解释性: 通过场景描述和分析提供决策依据(如"因右侧警车需左偏")
- 数据增强: 利用GPT-4生成多样化动作序列(如4种变道方案)
- 评估体系: 采用GPT-4V量化评估场景描述的准确性(相似度评分机制)
-
实验表现:
- 在SUP-AD数据集上,Qwen驱动的DriveVLM在场景描述(0.71)和元动作(0.37)指标显著优于GPT-4V
- nuScenes测试中,Dual系统将3s碰撞率从0.35%降至0.10%,L2误差降低37%
-
未来方向:
- 数据获取: 构建自动化pipeline挖掘长尾场景
- 系统融合: 探索中间层特征交互而不仅是最终轨迹融合
- 实时优化: 平衡VLM推理质量(1.5s/场景)与实时性要求(0.3s/场景)