文章目录
- 一、Redis入门介绍
- [二 、Redis的数据结构介绍及通用命令](#二 、Redis的数据结构介绍及通用命令)
-
- 1.Redis的数据结构(重要)
- 2.通用/常用命令(相当于sql语句,了解)
-
- [2.1 字符串类型](#2.1 字符串类型)
- 2.2、哈希类型hash
- 2.3、列表类型list
- 2.4、集合类型set
- 2.5、有序集合类型`zset`
- 2.6、通用命令
- 三、SpringBoot整合Redis
- [Spring Data Redis的使用:](#Spring Data Redis的使用:)
-
- 1、新建SpringBoot工程并引入依赖
- 2、添加Redis相关配置
- [3.方案一 :注入Spring Data Redis依赖](#3.方案一 :注入Spring Data Redis依赖)
- 4.续方案一:关于RedisTemplate及其子类
- 5.方案二:StringRedisTemplate
- 总结
- [补充 :测试哈希结构](#补充 :测试哈希结构)
一、Redis入门介绍
之前学的mysql就是有表有约束
redis是键值数据库:没有库没有表,属于是NoSQL数据库

多数情况下不会拆分存储,而是存成JSON形式:

1.SQL和NoSQL的对比及数据库的选择
SQL:关系型数据库
NoSQL:非关系型数据库,键值对的形式,没有强约束,数据库结构相对 松散
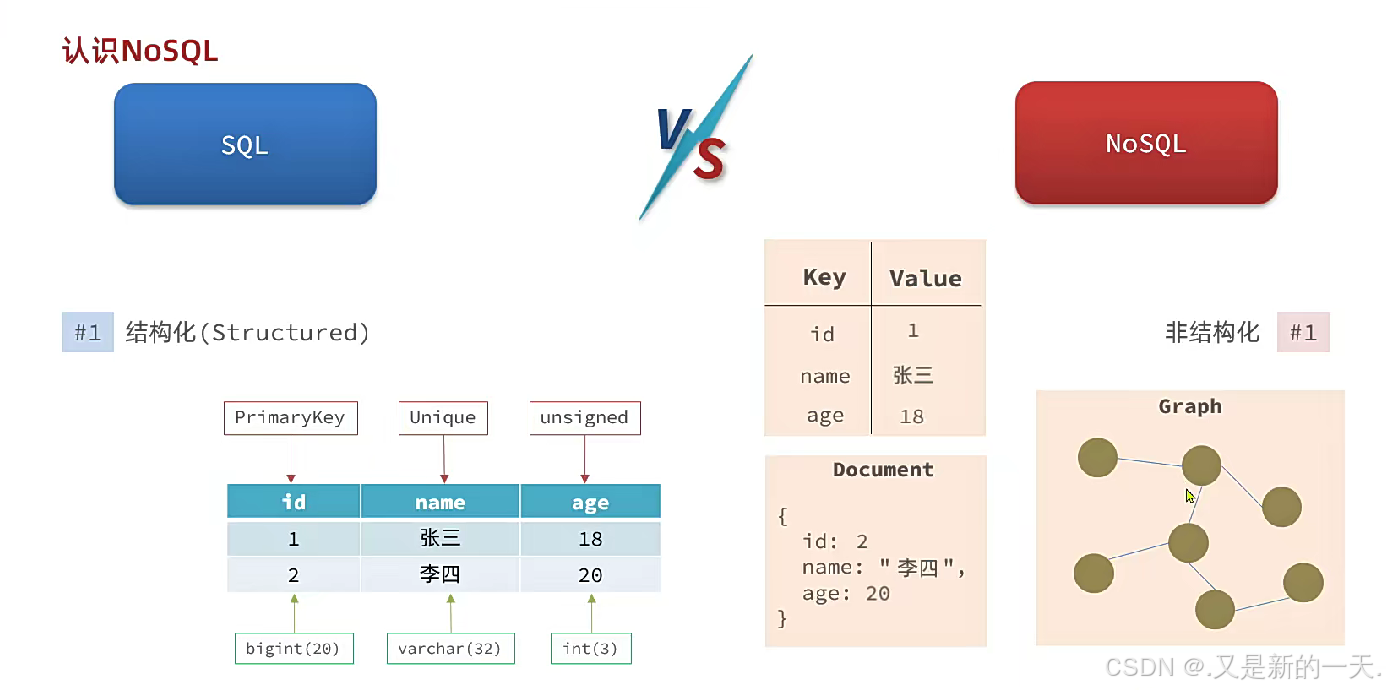
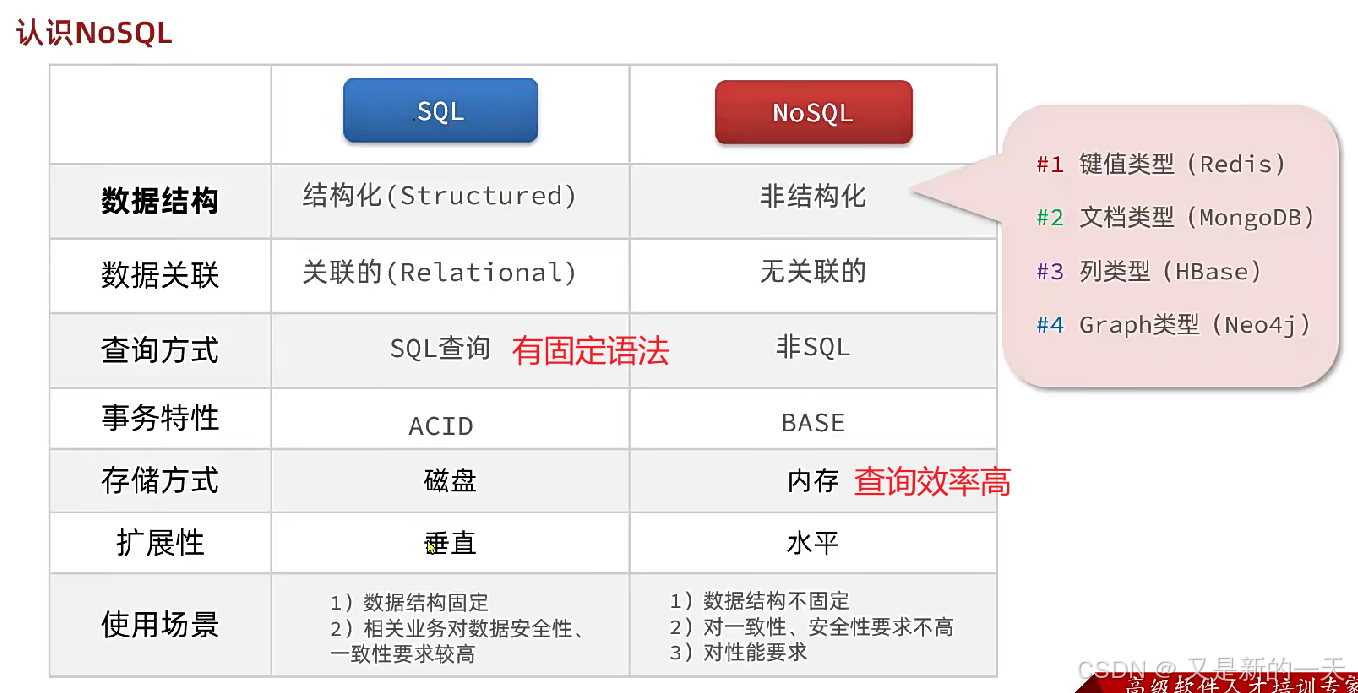
数据库的选择:
关系型数据库 :数据结构比较固定,对数据安全性一致性要求比较高
非关系型数据库:对查询性能要求较高的,把冗余的数据可以放到非关系型数据库中,提高查询效率 ,二者一般结合使用
2.认识Redis
Redis特征:
Redis 核心命令部分还是单线程

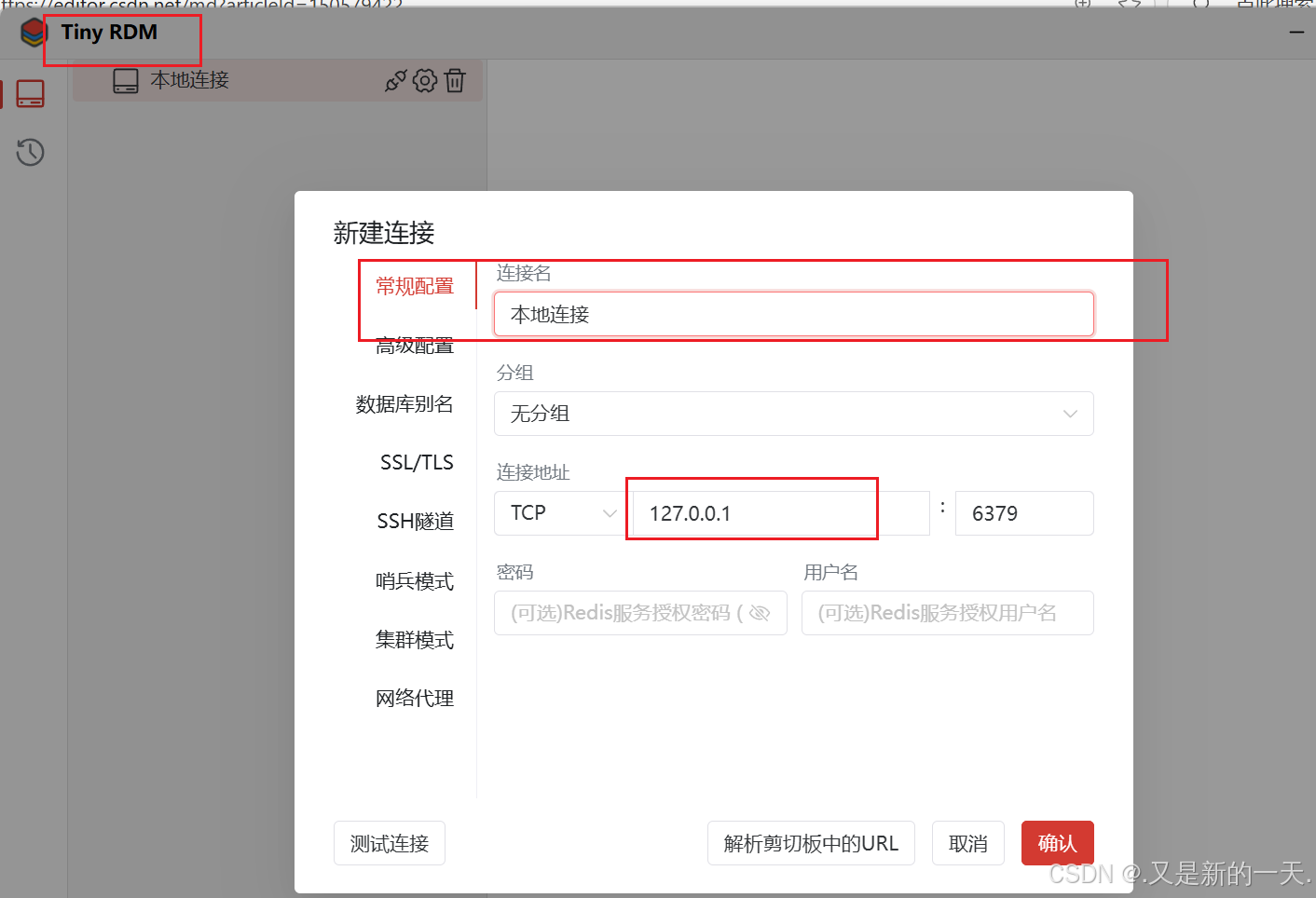
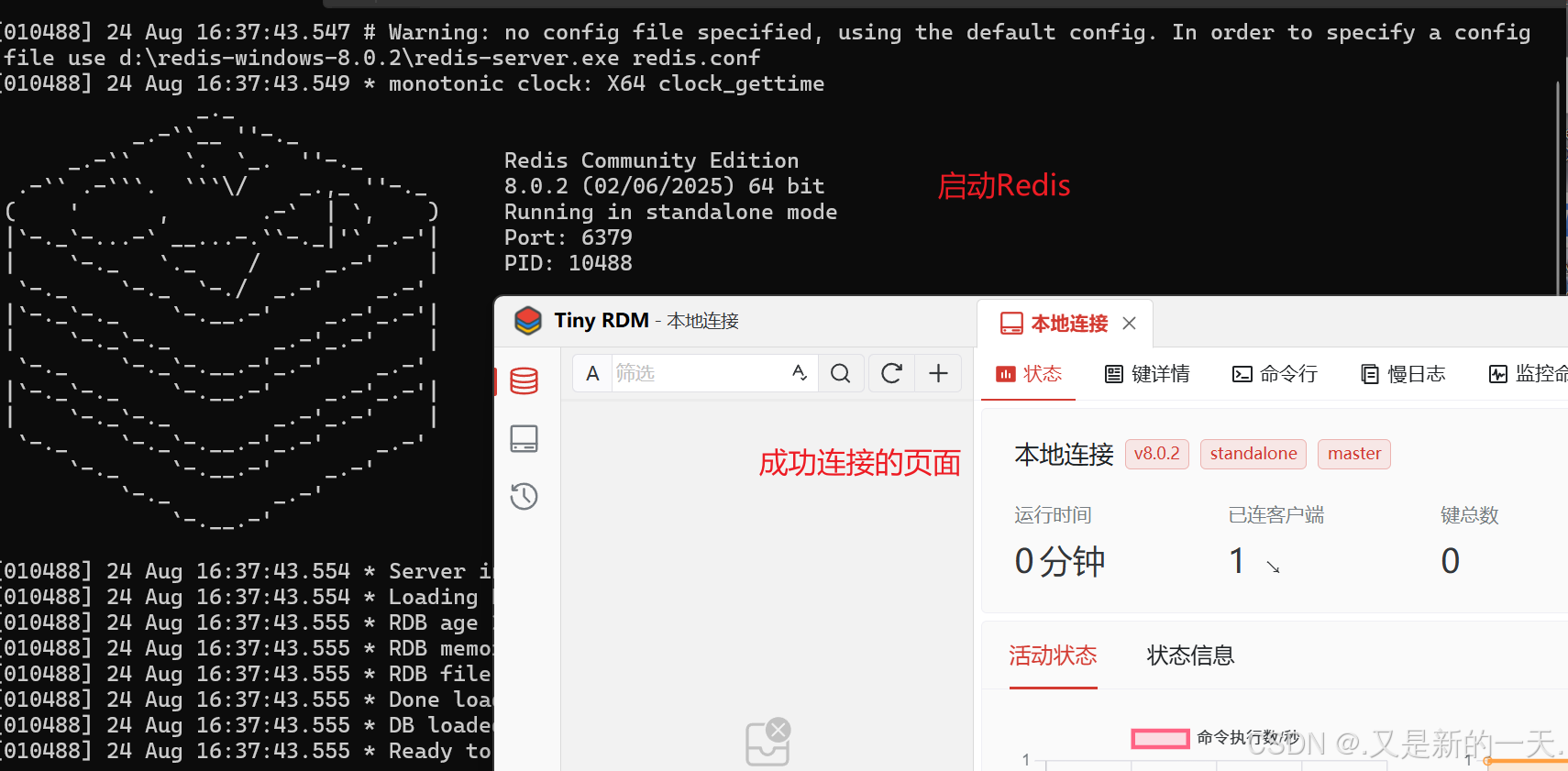
3.Redis下载安装测试
图形页面工具:客户端操作:比如输入命令啥的
二 、Redis的数据结构介绍及通用命令
1.Redis的数据结构(重要)

Value的五种基本数据类型:

2.通用/常用命令(相当于sql语句,了解)
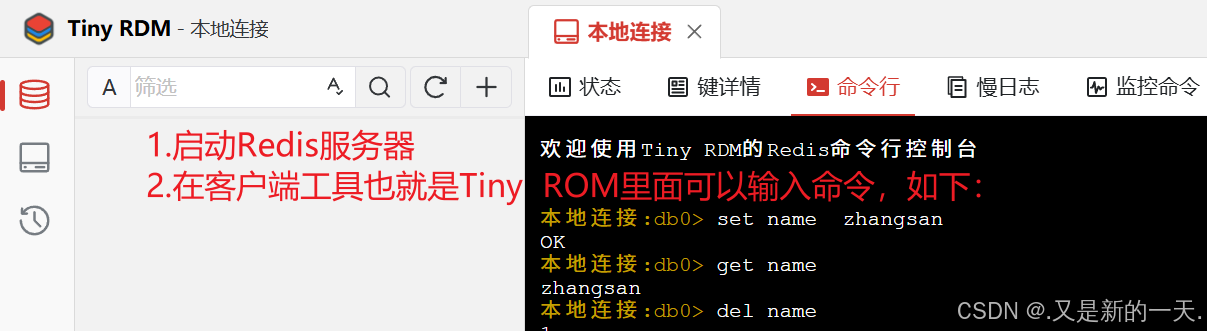
学习目的 :用命令去操作Redis
无论是学关系型数据库还是学习非关系型数据库,本质都是用来存东西的,无非就是增删改查内容
2.1 字符串类型
存储:
set key value
bash127.0.0.1:6379> set username Peter OK获取:
get key
bash127.0.0.1:6379> get username "Peter"删除:
del key
bash127.0.0.1:6379> del username (integer) 1 127.0.0.1:6379> get username (nil)批量添加:
mset k1 v1 [k2 v2 k3 v3]
bash127.0.0.1:6379> mset username zs age 10 addr qd OK批量取值:
mget k1 [k2 k3...]
bash127.0.0.1:6379> mget username age addr 1) "zs" 2) "10" 3) "qd"自增和自减
必须对"数值"进行操作
在
key对应的value上自增 +1:incr key
bash127.0.0.1:6379> incr age (integer) 11在key对应的value上自减 -1:
decr key
bash127.0.0.1:6379> decr age (integer) 10在key对应的value上+v:
incrby key v
bash127.0.0.1:6379> incrby age 5 (integer) 15在key对应的value上-v:
decrby key v
bash127.0.0.1:6379> decrby age 5 (integer) 10添加键值对,并设置过期时间(TTL):
setex key time(seconds) value
bash127.0.0.1:6379> setex age 10 30 OK设置值,如果
key不存在则成功添加,如果key存在则添加失败(不做修改操作):setnx key value设置 --- 不存在就添加,存在不做任何操作
bash127.0.0.1:6379> setnx age 10 (integer) 1 127.0.0.1:6379> get age "10" 127.0.0.1:6379> setnx age 20 (integer) 0 127.0.0.1:6379> get age "10"在指定的
key对应value拼接字符串:append key value
bash127.0.0.1:6379> append addr _snq (integer) 6 127.0.0.1:6379> get addr "qd_snq"获取
key对应的字符串的长度:strlen key
bash127.0.0.1:6379> strlen addr (integer) 6
2.2、哈希类型hash
其实也是键值对,只不过v又包含若干个键值对
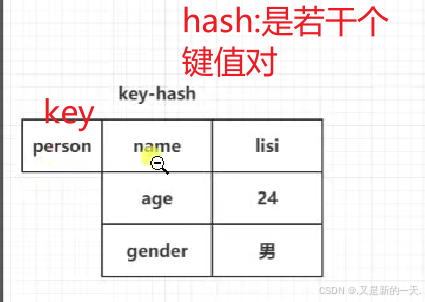
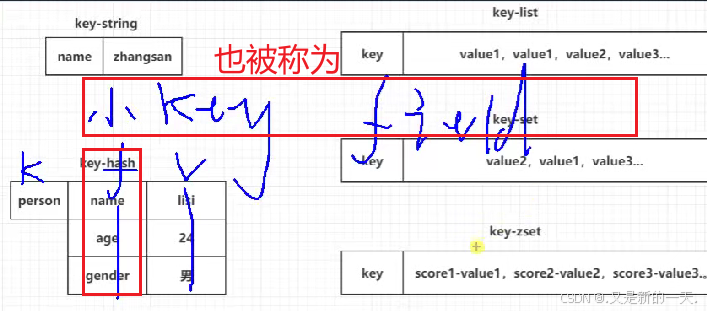
向
key对应的hash中添加键值对:hset key field value
bash127.0.0.1:6379> hset Person username Peter (integer) 1 127.0.0.1:6379> hset Person age 10 (integer) 1 127.0.0.1:6379> hset Person address Beijing (integer) 1获取指定的
field对应的值:hget key field
bash127.0.0.1:6379> hget Person age "10" 127.0.0.1:6379> hget Person username "Peter"hdel 127.0.0.1:6379> hget Person address "Beijing"向
key对应的hash结构中批量添加键值对:hmset key f1 v1 [f2 v2 ...]
bash127.0.0.1:6379> hmset person name zs age 10 addr bj OK在
key对应的hash中的field对应value上加v:hincrby key field v
bash127.0.0.1:6379> hincrby person age 1 (integer) 11获取所有的
field和value:hgetall key
bash127.0.0.1:6379> hgetall Person 1) "username" 2) "Peter" 3) "age" 4) "10" 5) "address" 6) "Beijing"获取
key对应的hash中所有的field:hkeys key
bash127.0.0.1:6379> hkeys person 1) "name" 2) "age" 3) "addr"获取
key对应的hash中所有的value:hvals key
bash127.0.0.1:6379> hvals person 1) "zs" 2) "11" 3) "bj"检查
key对应的hash中是否有指定的field:hexists key field
bash127.0.0.1:6379> hexists person height (integer) 0 127.0.0.1:6379> hexists person name (integer) 1获取
key对应的hash中键值对的个数:hlen key
bash127.0.0.1:6379> hlen person (integer) 3
- 向
key对应的hash结构中添加k-v,如果field在hash中已经存在,则添加失败:hsetnx key field value
bash127.0.0.1:6379> hsetnx person name aaa (integer) 0 127.0.0.1:6379> hgetall person 1) "name" 2) "zs" 3) "age" 4) "11" 5) "addr" 6) "bj" 127.0.0.1:6379> hsetnx person height 180 (integer) 1 127.0.0.1:6379> hgetall person 1) "name" 2) "zs" 3) "age" 4) "11"删除单个域:
hdel key field
bash127.0.0.1:6379> hdel Person age (integer) 1 127.0.0.1:6379> hgetall Person 1) "username" 2) "Peter" 3) "address" 4) "Beijing"删除多个域:
hdel key field1 field2 field3...
bash127.0.0.1:6379> hdel Person username address (integer) 2 127.0.0.1:6379> hgetall Person (empty list or set)
2.3、列表类型list
可以添加一个元素到列表的头部(左侧)或者尾部(右侧),允许元素重复。
元素是有顺序的,索引从
0开始同侧存取:实现了堆栈结构,后进先出;
异侧存取:实现了队列结构,先进先出。
left左
right右
push推入
pop弹出
将元素加入列表左侧:
lpush key value
bash127.0.0.1:6379> lpush username tom (integer) 1 127.0.0.1:6379> lpush username John (integer) 2将元素加入列表右侧:
rpush key value
bash127.0.0.1:6379> rpush username Smith (integer) 3 127.0.0.1:6379> rpush username Lucy (integer) 4删除列表最左边的元素,并将元素返回:
lpop key
bash127.0.0.1:6379> lpop username "John" 127.0.0.1:6379> lrange username 0 -1 1) "tom" 2) "Smith" 3) "Lucy"删除列表最右边的元素,并将元素返回:
rpop key
bash127.0.0.1:6379> rpop username "Lucy" 127.0.0.1:6379> lrange username 0 -1 1) "tom" 2) "Smith" 127.0.0.1:6379>获取:
lrange key start end
bash# 0:第0个元素 # -1:最后一个元素 127.0.0.1:6379> lrange username 0 -1 1) "John" 2) "tom" 3) "Smith" 4) "Lucy" 127.0.0.1:6379> lrange username 0 1 1) "John" 2) "tom"查看key对应的列表中index索引对应的值:
lindex key index
bash127.0.0.1:6379> lindex username 0 "zl"获取key对应的列表中的元素个数:
llen key
bash127.0.0.1:6379> llen username (integer) 4从key对应的列表中截取key在start,stop范围的值,不在此范围的数据一律被清除掉:
ltrim key start stop
bash127.0.0.1:6379> ltrim username 1 2 OK 127.0.0.1:6379> llen username (integer) 2 127.0.0.1:6379> lrange username 0 -1 1) "ww" 2) "ls"从k1右侧取出一个数据存放到k2的左侧:
rpoplpush k1 k2
bash127.0.0.1:6379> lpush test1 aaa bbb ccc (integer) 3 127.0.0.1:6379> lpush test2 mmm nnn (integer) 2 127.0.0.1:6379> rpoplpush test2 test1 "mmm" 127.0.0.1:6379> lrange test1 0 -1 1) "mmm" 2) "ccc"f'l 3) "bbb" 4) "aaa" 127.0.0.1:6379> lrange test2 0 -1 1) "nnn"修改数据:
lset key index value
bash127.0.0.1:6379> lrange username 0 -1 1) "ww" 2) "ls" 127.0.0.1:6379> lset username 0 zs OK 127.0.0.1:6379> lrange username 0 -1 1) "zs" 2) "ls"
2.4、集合类型set
不允许元素重复,"无序"。
添加:
sadd key value [value1 value2 value3...]
bash127.0.0.1:6379> sadd username Tom (integer) 1 127.0.0.1:6379> sadd username Bob (integer) 1 127.0.0.1:6379> sadd username Peter (integer) 1 127.0.0.1:6379> sadd username Lucy (integer) 1 127.0.0.1:6379> sadd addr bj qd nj jn sh sz (integer) 6获取所有元素:
smembers key
bash127.0.0.1:6379> smembers username 1) "Peter" 2) "Bob" 3) "Tom" 4) "Lucy"删除:
srem key value
bash127.0.0.1:6379> srem username Bob (integer) 1 127.0.0.1:6379> smembers username 1) "Peter" 2) "Tom" 3) "Lucy"随机从
key集合中获取一个值(出栈):spop key
bash127.0.0.1:6379> spop addr "qd" 127.0.0.1:6379> smembers addr 1) "bj" 2) "sh" 3) "nj" 4) "jn" 5) "sz"交集:
sinter key1 key2
bash127.0.0.1:6379> sadd username1 zs ls ww zl (integer) 4 127.0.0.1:6379> sadd username2 zs ls bob tom peter (integer) 5 127.0.0.1:6379> sinter username1 username2 1) "zs" 2) "ls" 127.0.0.1:6379>并集:
sunion key1 key2
bash127.0.0.1:6379> sunion username1 username2 1) "tom" 2) "bob" 3) "ls" 4) "zl" 5) "ww" 6) "zs" 7) "peter"差集:
sdiff key1 key2
bash# 返回由第一个集合和所有连续集合之间的差异引起的集合成员 127.0.0.1:6379> sdiff username1 username2 1) "ww" 2) "zl" 127.0.0.1:6379> sdiff username2 username1 1) "tom" 2) "bob" 3) "peter" 127.0.0.1:6379> sadd username1 bob (integer) 1 127.0.0.1:6379> sdiff username1 username2 1) "ww" 2) "zl" 127.0.0.1:6379> sdiff username2 username1 1) "tom" 2) "peter"检查
key对应的集合中是否有指定的value:sismember key value
she127.0.0.1:6379> sismember username1 zs (integer) 1 127.0.0.1:6379> sismember username1 eee (integer) 0
2.5、有序集合类型zset
不允许重复元素,且元素有顺序。每个元素都会关联一个double类型的分数。Redis正是通过分数来为集合中的成员进行从小到大的排序。
添加:
zadd key score value [score value...]
bash127.0.0.1:6379> zadd mysort 10 Zhangsan (integer) 1 127.0.0.1:6379> zadd mysort 20 John (integer) 1 127.0.0.1:6379> zadd mysort 100 Peter (integer) 1获取:
zrange key start end [withscores]
bash# start和end指的不是score,而是元素在有序集合中的索引 127.0.0.1:6379> zrange mysort 0 -1 1) "Zhangsan" 2) "John" 3) "Peter" 127.0.0.1:6379> zrange mysort 0 -1 withscores 1) "Zhangsan" 2) "10" 3) "John" 4) "20" 5) "Peter" 6) "100"查看member元素在key对应的有序集合中的索引:
zscore key member
bash127.0.0.1:6379> zscore mysort zs "1" 127.0.0.1:6379> zscore mysort zl "101"获取key对应的zset中的元素个数:
zcard key
bash127.0.0.1:6379> zcard mysort (integer) 4获取key对应的zset中,score在min,max范围内的member个数:
zcount key min max
bash127.0.0.1:6379> zcount mysort 2 100 (integer) 2删除:
zrem key value
bash127.0.0.1:6379> zrem mysort zs (integer) 1 127.0.0.1:6379> zrange mysort 0 -1 withscores 1) "ls" 2) "2" 3) "ww" 4) "100" 5) "zl" 6) "101"查看key对应的有序集合中索引start,stop数据------按照score值由大到小:
zrevrange key start stop
shel127.0.0.1:6379> zrevrange mysort 0 -1 withscores 1) "zl" 2) "101" 3) "ww" 4) "100" 5) "ls" 6) "2"
2.6、通用命令
查询所有的键:
keys *
bash127.0.0.1:6379> keys * 1) "username" 2) "mysort"查看指定的key谁否存在:
exists key
bash127.0.0.1:6379> exists addr (integer) 1获取键对应的value的类型:
type key
bash127.0.0.1:6379> type mysort zset 127.0.0.1:6379> type username set删除指定的key-value:
del key
bash127.0.0.1:6379> del mysort (integer) 1 127.0.0.1:6379> type username set切换数据库:
select index
redis中默认有16个db,编号0-15将键值对从当前
db移动到目标db:move key index删除当前数据库中所有的
key:flushdb删除所有库所有的
key:flushall查看当前
db中k-v个数:dbsize清除屏幕:
clear
三、SpringBoot整合Redis
SpringBoot整合Redis相比于Spring整合Redis要简单。
Spring Data Redis的使用:
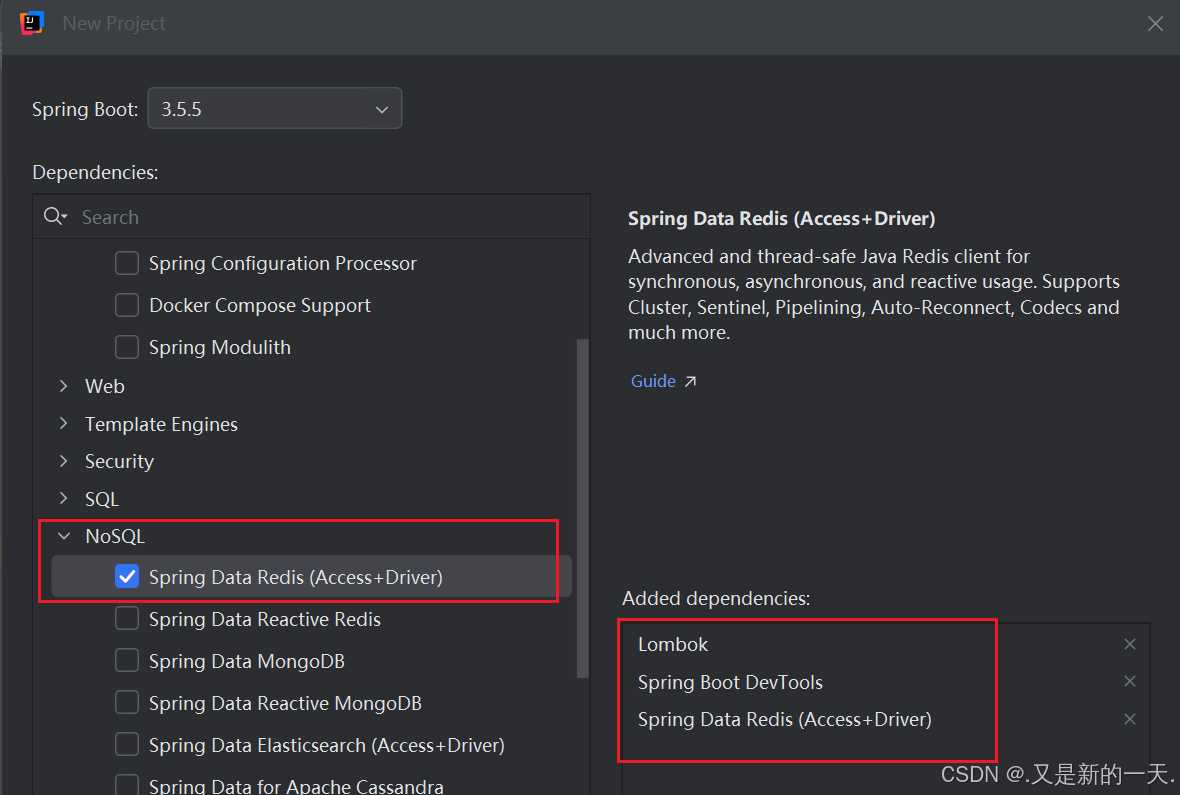
1、新建SpringBoot工程并引入依赖
新建SpringBoot工程时注意选择Nosql下的
Spring Data Redis以保证添加Redis相关依赖。Spring Data Redis介绍:
然后手动添加另一个依赖:
<dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> </dependency>
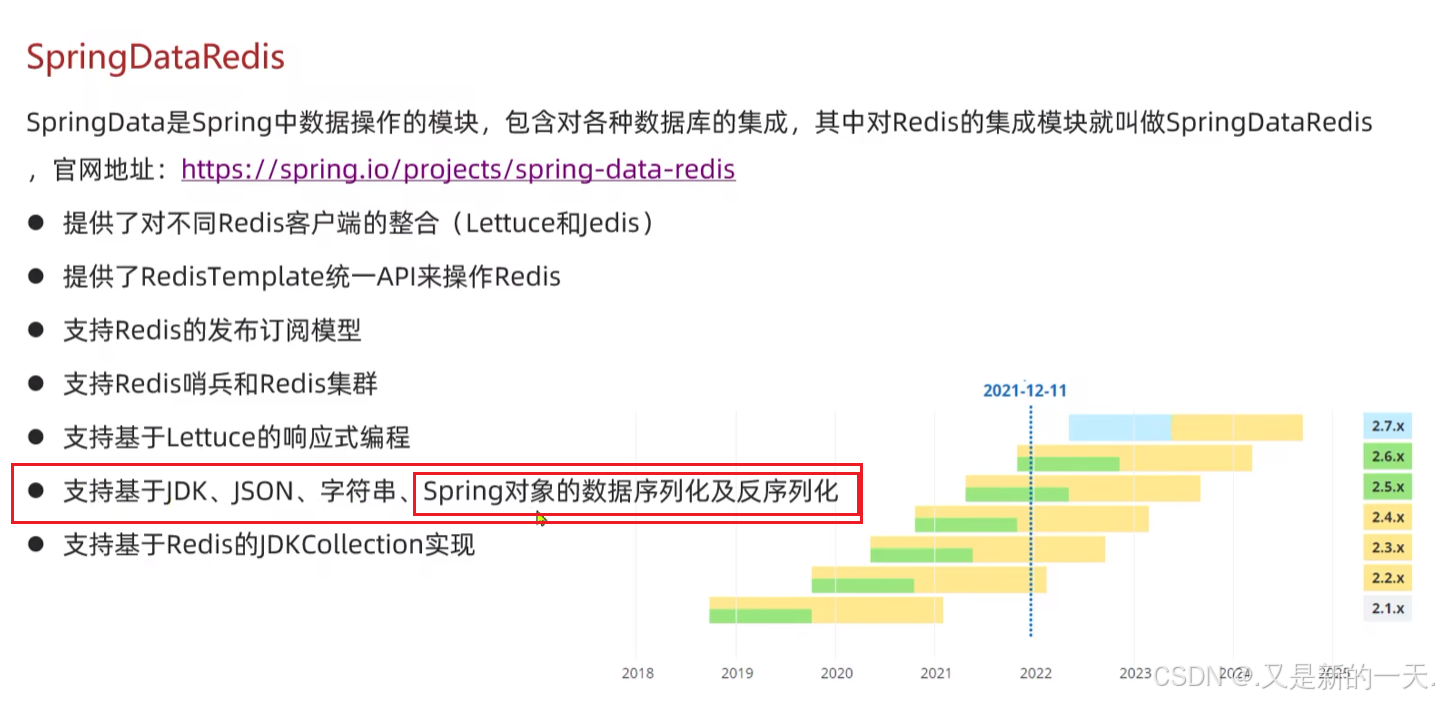
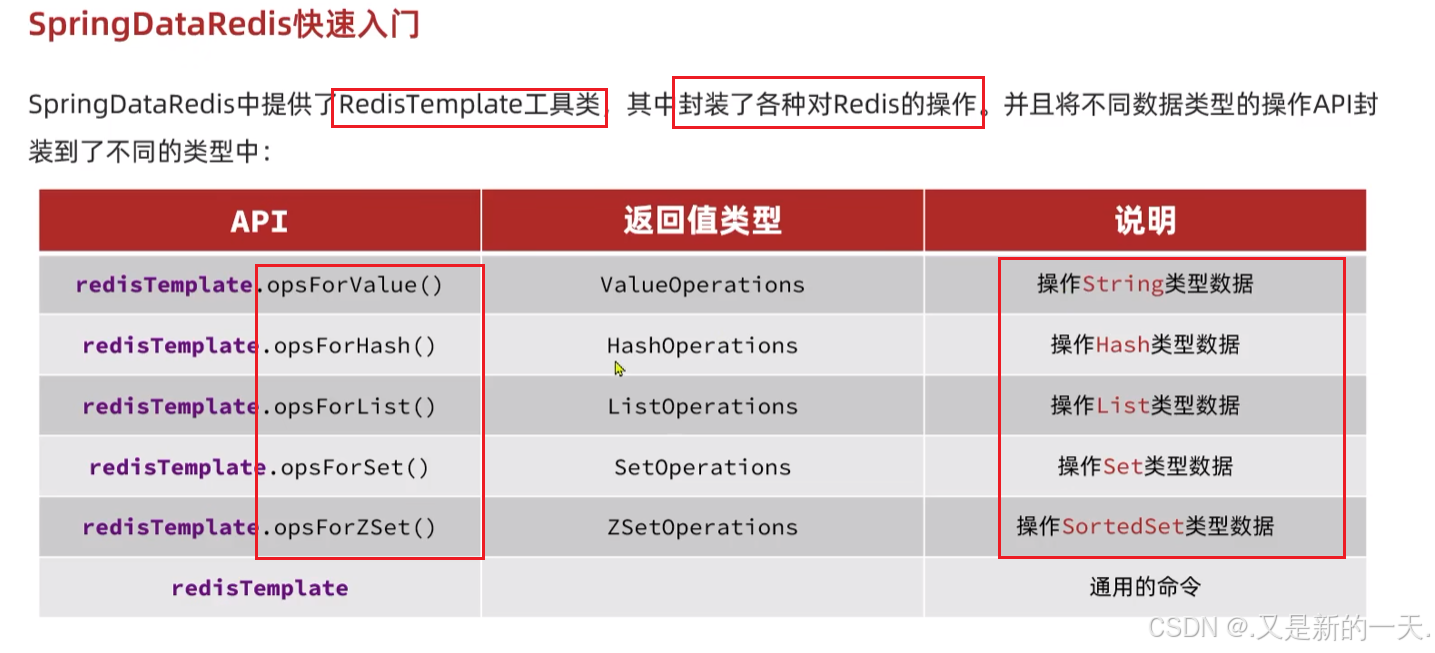
2、添加Redis相关配置
application.yml
yaml
spring:
data:
redis:
host: localhost
port: 6379
passworrd: 自定义的密码
lettuce:
pool:
max-active: 8 #最大连接
max-idle: 8 #最大空闲连接
min-idle: 0 #最小空闲连接
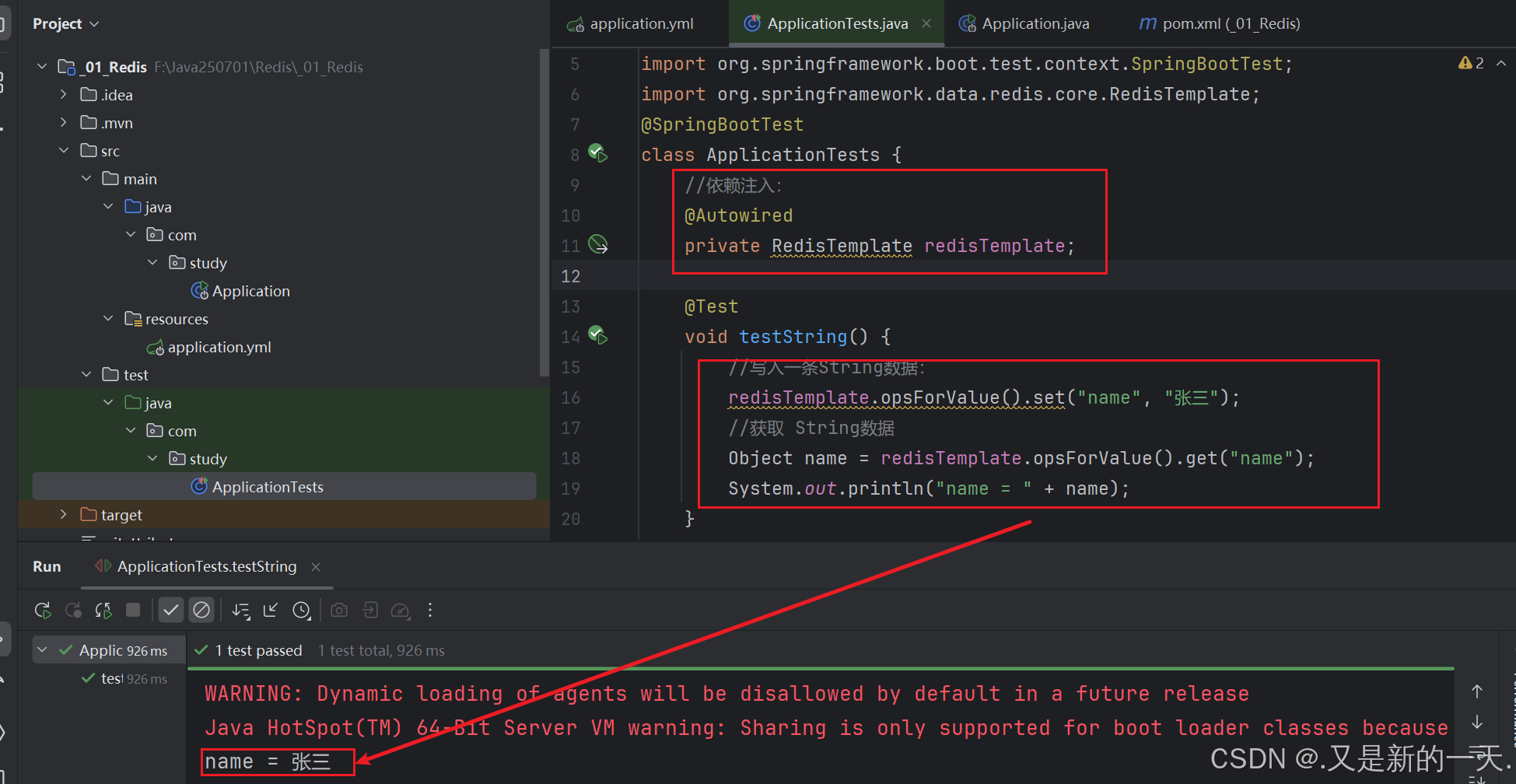
max-wait: 100ms #最大等待时间3.方案一 :注入Spring Data Redis依赖
总结:

查看效果:

原因 :
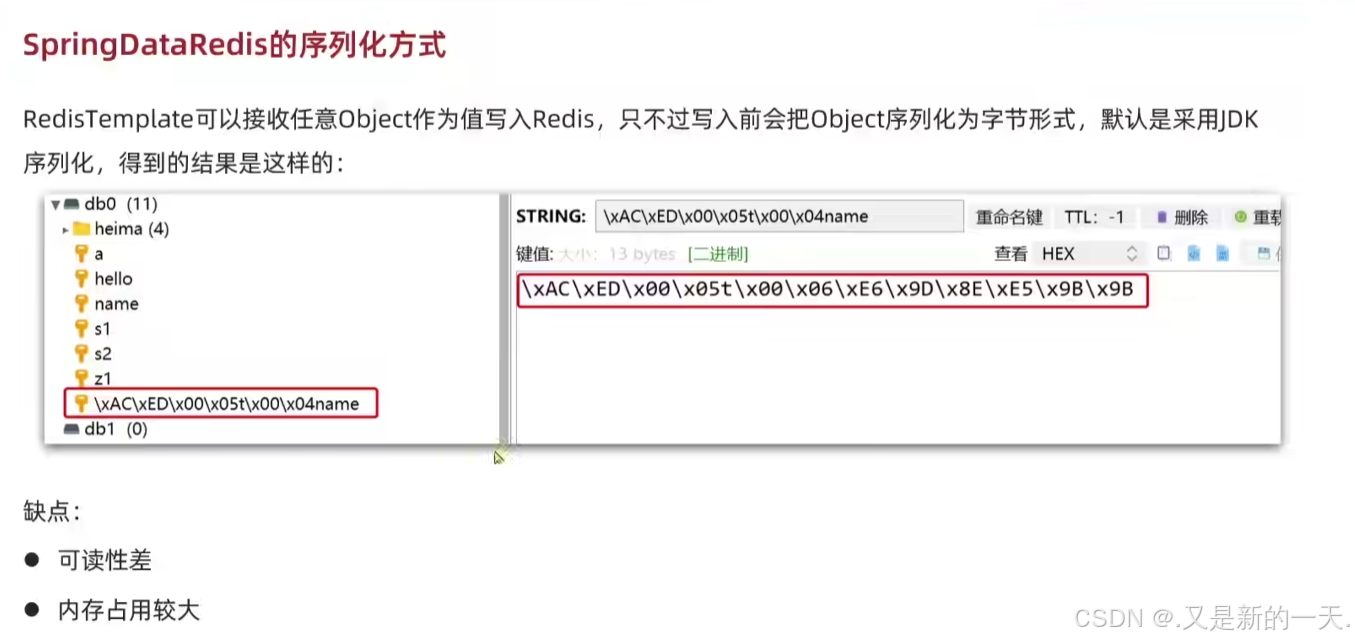
解决办法:修改序列化方式,不使用默认的JDK序列方式
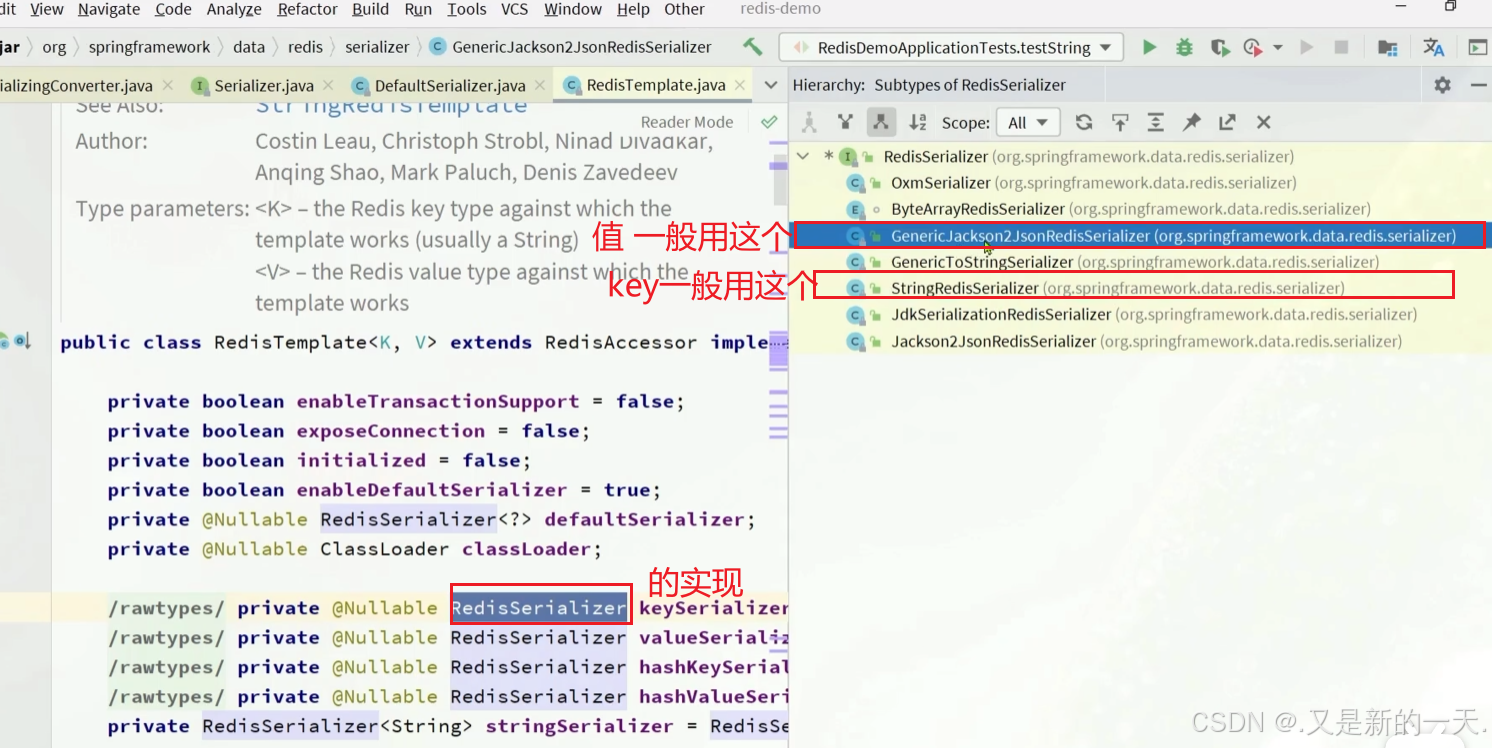
4.续方案一:关于RedisTemplate及其子类
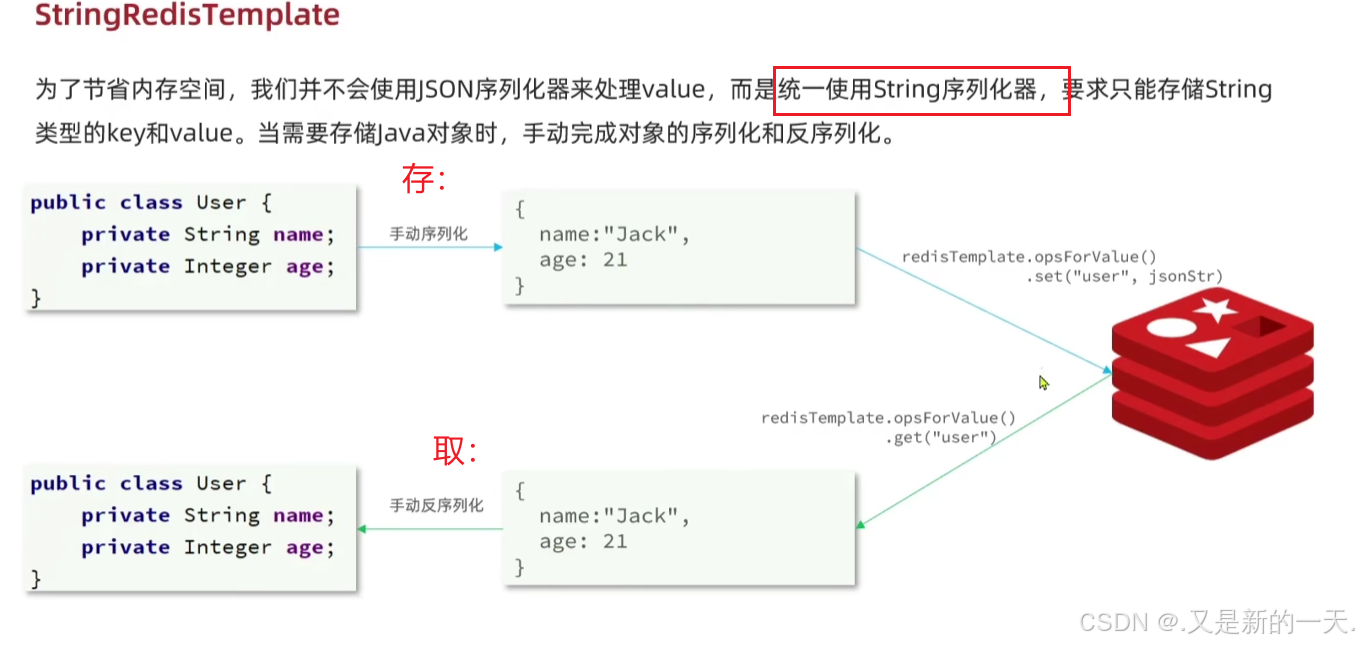
StringRedisTemplate继承自RedisTemplate,因此它也继承了RedisTemplate的所有方法。RedisTemplate是一个更通用的模板类,它允许键和值是任何类型的对象。RedisTemplate默认使用JdkSerializationRedisSerializer进行对象的序列化,而StringRedisTemplate使用StringRedisSerializer,这意味着它更适合处理简单的字符串数据。
结论 :
在实际应用中,如果你需要存储和检索的对象是字符串类型,那么
StringRedisTemplate是一个更简单、更高效的选择。如果你需要存储复杂的对象,那么可能需要使用RedisTemplate并配置适当的序列化器。
配置序列化器:
java
package com.study.redis.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String,Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
//创建RedisTemplate对象
RedisTemplate<String, Object> template = new RedisTemplate<>();
//设置连接工厂
template.setConnectionFactory(redisConnectionFactory);
//创建JSON工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
//设置key的序列化
template.setKeySerializer(jsonRedisSerializer);
template.setHashKeySerializer(jsonRedisSerializer);
//设置value的序列化:
template.setValueSerializer(jsonRedisSerializer);
template.setHashValueSerializer(jsonRedisSerializer);
//返回:
return template;
}
}测试类:
java
package com.study;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
@SpringBootTest
class ApplicationTests {
//依赖注入:
@Autowired
private RedisTemplate<String,Object> redisTemplate;
@Test
void testString() {
//写入一条String数据:
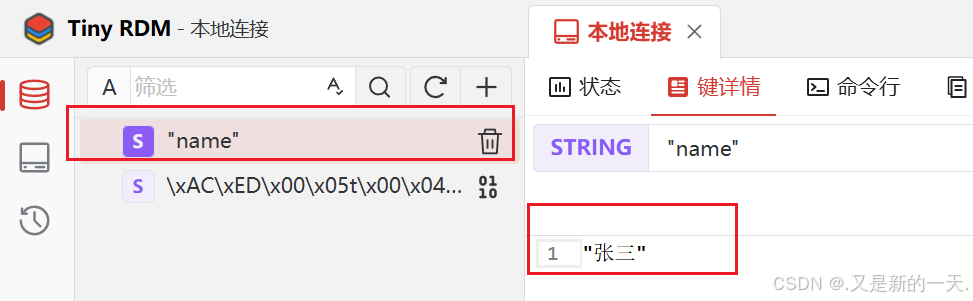
redisTemplate.opsForValue().set("name", "张三");
//获取 String数据
Object name = redisTemplate.opsForValue().get("name");
System.out.println("name = " + name);
}
}实现效果:
这对于复杂的自定义类型也是适用的:
新建自定义实体类:
java
package com.study.redis.bean;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
public class User {
private String name;
private Integer age;
}测试:
java
@Test
public void testUser(){
//写入数据:
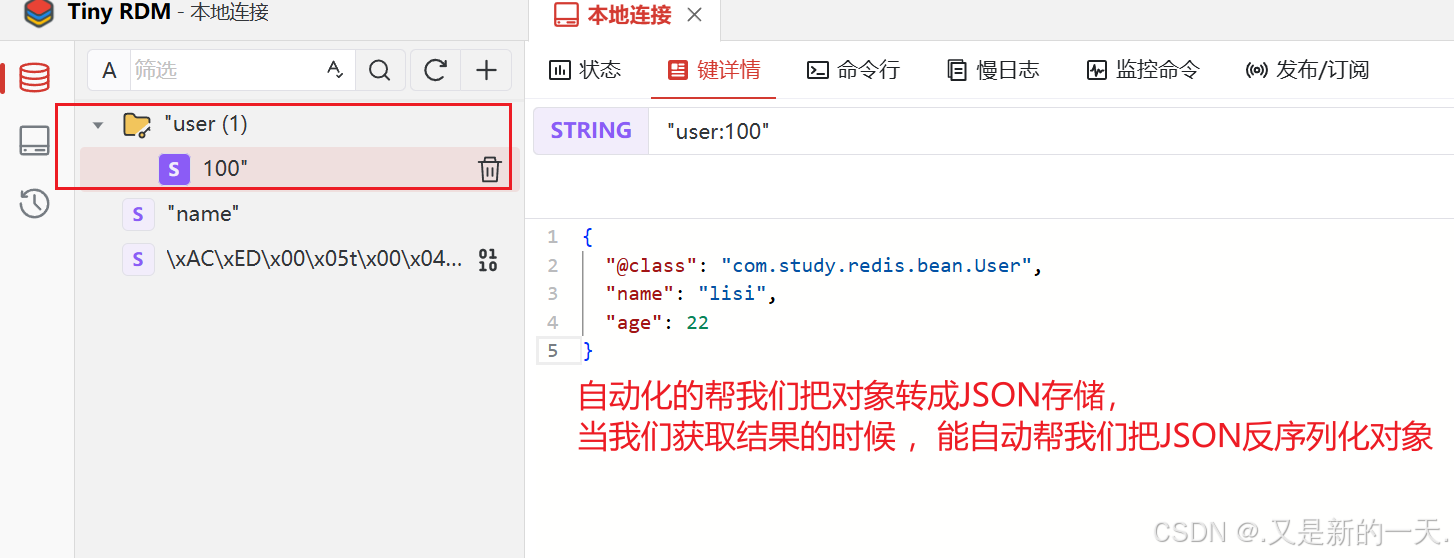
redisTemplate.opsForValue().set("user:100",new User("lisi",22));
//获取数据:
User o = (User) redisTemplate.opsForValue().get("user:100");
System.out.println(o);
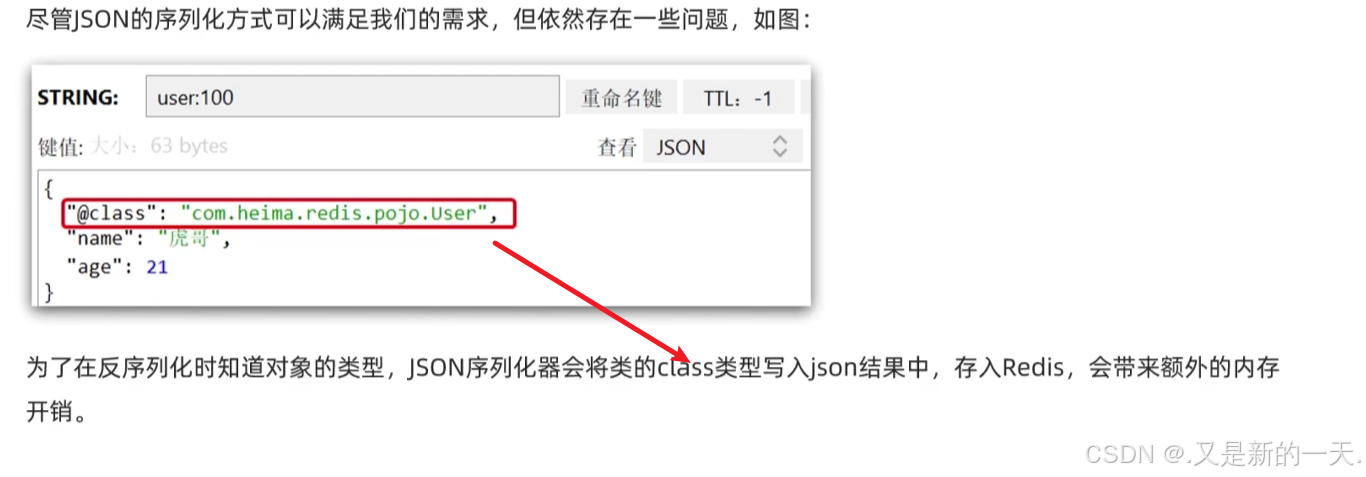
}结果:正是因为存了class属性,对应的是类的字节码名称,能够利用反射帮我们完成反序列化
5.方案二:StringRedisTemplate
上面存在的问题
解决方案 :
代码示例 :
java
package com.study;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.study.redis.bean.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.StringRedisTemplate;
import java.util.Map;
@SpringBootTest
class RedisString {
//依赖注入:StringRedisTemplate
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
void testString() {
//写入一条String数据:
stringRedisTemplate.opsForValue().set("name", "张三");
//获取 String数据
Object name = stringRedisTemplate.opsForValue().get("name");
System.out.println("name = " + name);
}
//测试存对象 :
//JSON序列化工具:手动序列化
private static final ObjectMapper mapper = new ObjectMapper();
@Test
public void testUser() throws JsonProcessingException {
//创建对象:
User user = new User("张三", 23);
//手动序列化
String json = mapper.writeValueAsString(user);
//写入数据:
stringRedisTemplate.opsForValue().set("user:200",json);
//获取数据:
String jsonUser = stringRedisTemplate.opsForValue().get("user:200");
//手动反序列化:
User user1 = mapper.readValue(jsonUser, User.class);
System.out.println(user1);
}
@Test
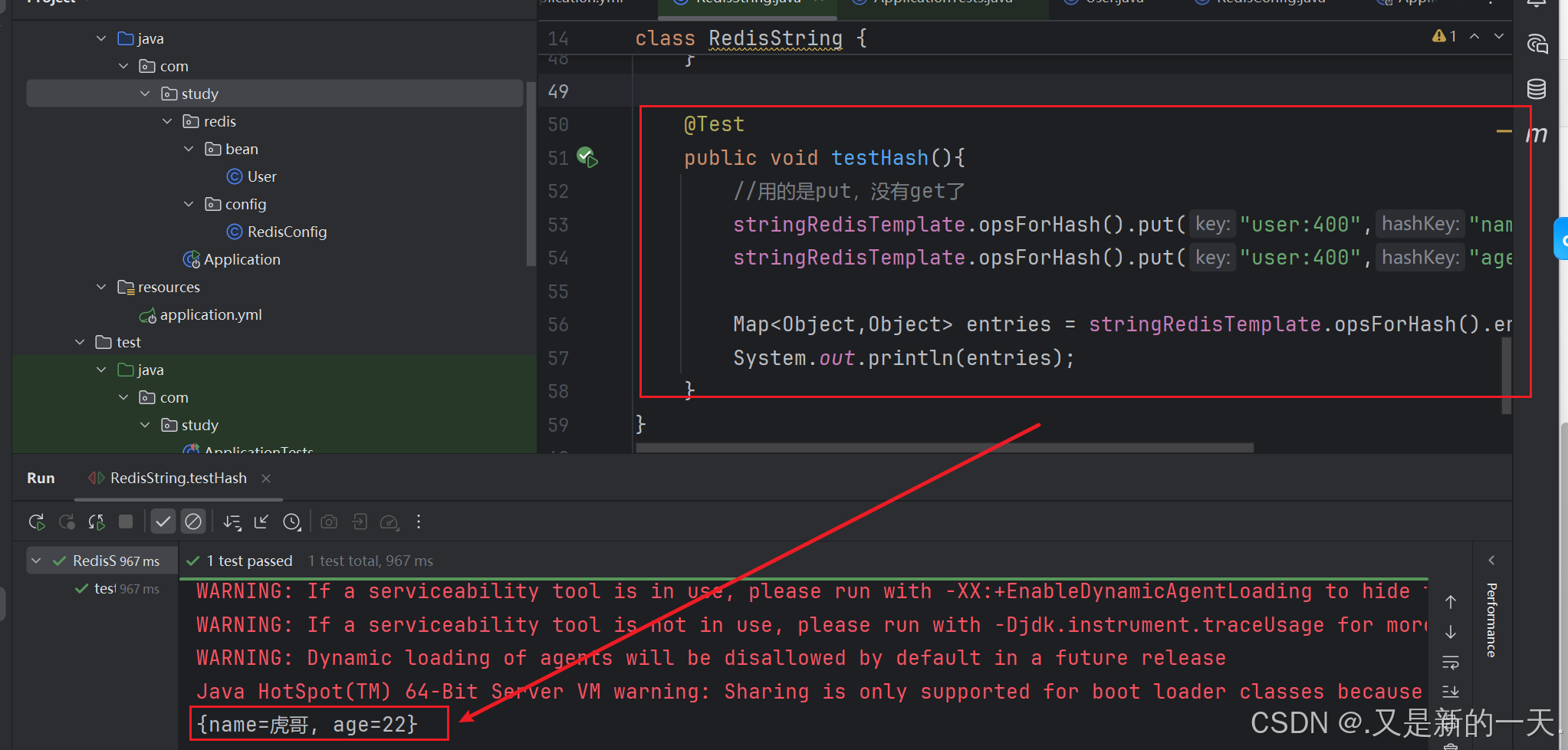
public void testHash(){
//用的是put,没有get了
stringRedisTemplate.opsForHash().put("user:400","name","虎哥");
stringRedisTemplate.opsForHash().put("user:400","age","22");
Map<Object,Object> entries = stringRedisTemplate.opsForHash().entries("user:400");
System.out.println(entries);
}
}总结

补充 :测试哈希结构
哈希里面:一个键对应多个字段和值
java
@Test
public void testHash(){
//用的是put,没有get了
stringRedisTemplate.opsForHash().put("user:400","name","虎哥");
stringRedisTemplate.opsForHash().put("user:400","age","22");
Map<Object,Object> entries = stringRedisTemplate.opsForHash().entries("user:400");
System.out.println(entries);
}效果;