DeerFlow作为一个模块化、可扩展的框架,旨在简化多智能体系统的构建和实验。它为用户提供了一个灵活的平台,可以轻松集成不同的LLM、工具和数据源,从而进行复杂的AI任务。传统的公网部署可能涉及购买固定IP、配置复杂的防火墙规则等,这对于个人用户来说既耗时又耗力。本文将从面向中国读者的视角出发,结合实际操作经验,详细讲解如何利用内网穿透技术,以极低的成本和简化的步骤,实现DeerFlow的公网访问,助你轻松驾驭DeerFlow,开启大模型探索之旅。
准备工作
在开始部署DeerFlow之前,我们需要进行一些必要的准备工作,这主要包括了解服务器基础信息以及配置内网穿透服务,一个清晰的准备流程将确保后续的部署顺利进行。
网络配置
为了确保DeerFlow及其相关服务能够正常工作,我们需要配置相应的入站(Inbound)和出站(Outbound)端口规则。
请确保服务器防火墙或云服务商的安全组(Security Group)中,已经正确配置了上述端口规则,以便DeerFlow的后端服务(通常运行在8000端口)和前端服务(通常运行在3000端口)能够正常对外提供服务。
内网穿透
对于个人用户或小型团队而言,购买固定IP地址和配置复杂的网络环境往往成本较高。内网穿透技术应运而生,它允许将本地服务暴露到公网,而无需公网IP。Ngrok是其中一个广受欢迎的工具,它提供了一个安全的隧道,将本地端口映射到公网域名上,实现低成本、快速的公网访问。
Ngrok的作用和优势
- 低成本: 无需购买昂贵的公网IP或进行复杂的网络配置。
- 快速部署: 几条简单的命令即可实现内网穿透。
- 安全性: Ngrok提供加密隧道,确保数据传输安全。
- 灵活性: 支持HTTP、HTTPS、TCP等多种协议,满足不同应用需求。
Ngrok注册与授权
-
访问Ngrok官网并注册:
需要访问 Ngrok官网 进行注册。注册过程通常很简单,可以使用GitHub或Google账号快速登录。
-
获取Authtoken并添加到服务器:
注册并登录后,访问Ngrok的"Get Started"页面(通常是 dashboard.ngrok.com/get-started...),会看到一个类似于
ngrok config add-authtoken <YOUR_AUTHTOKEN>的命令。复制该命令,并在服务器终端中执行,将<YOUR_AUTHTOKEN>替换为自己的授权码。这将把授权信息保存到Ngrok的配置文件中,以便后续使用。bashngrok config add-authtoken xxxxx(请将
xxxxx替换为实际授权码)
Ngrok配置
Ngrok的配置主要通过编辑其配置文件 ~/.config/ngrok/ngrok.yml 来完成。我们需要配置两个隧道:一个用于DeerFlow的后端服务(API),另一个用于前端服务(Web界面)。
-
编辑配置文件:
使用文本编辑器(如
vim)打开Ngrok配置文件:bashvim ~/.config/ngrok/ngrok.yml -
添加隧道配置:
在文件中添加以下内容。请注意,
domain: xxxx.app需要替换为在Ngrok控制台获取的静态域名(如果是免费用户,可能需要使用随机域名或付费获取静态域名)。yamlversion: "3" agent: authtoken: xxxxx # 授权码,通常在执行 `ngrok config add-authtoken` 后会自动生成 tunnels: backend: proto: http addr: 8000 domain: xxxx.app # 替换为Ngrok静态域名,用于后端API访问 frontend: proto: http addr: 3000
-
backend隧道:proto: http:指定隧道协议为HTTP。addr: 8000:指定DeerFlow后端服务在服务器上监听的端口,DeerFlow后端默认使用8000端口。domain: xxxx.app:这是Ngrok分配的公网域名,用于外部访问DeerFlow的后端API。
-
frontend隧道:proto: http:指定隧道协议为HTTP。addr: 3000:指定DeerFlow前端服务在服务器上监听的端口,DeerFlow前端默认使用3000端口。
启动Ngrok
配置完成后,可以在服务器上以后台模式启动Ngrok,确保它在您退出终端后仍然运行。
-
后台模式启动命令:
bashsetsid nohup ngrok start --all > /home/azureuser/log/ngrok.log 2>&1 < /dev/null &这条命令的含义是:
setsid: 将进程从控制终端分离,使其成为一个独立的会话。nohup: 即使终端关闭,也阻止进程接收挂断信号。ngrok start --all: 启动ngrok.yml中配置的所有隧道。> /home/azureuser/log/ngrok.log 2>&1: 将标准输出和标准错误重定向到/home/azureuser/log/ngrok.log文件中,方便查看日志。< /dev/null: 将标准输入重定向到/dev/null,避免进程等待用户输入。&: 将命令放到后台执行。
-
查看分配域名信息: Ngrok启动后,可以通过访问本地的Ngrok管理API来查看当前分配的公网域名和隧道信息。这对于验证Ngrok是否成功启动以及获取动态域名非常有用。
bashcurl http://localhost:4040/api/tunnels执行此命令后,将看到一个JSON格式的输出,其中包含了每个隧道的公网URL。记录下
backend和frontend隧道对应的公网域名。
DeerFlow配置修改
成功配置并启动Ngrok后,我们需要修改DeerFlow的配置文件。这主要涉及到修改 .env 、 conf.yaml 和 docker-compose.yml 文件,以及后端服务的CORS(跨域资源共享)设置。
配置文件路径
DeerFlow的主要配置文件位于其应用目录下。根据参考文档,这些文件通常在:
.../deer-flow/.env.../deer-flow/conf.yaml.../deer-flow/docker-compose.yml
.env 文件修改
.env 文件包含了DeerFlow应用的环境变量,其中最重要的是 NEXT_PUBLIC_API_URL,它指定了前端服务调用后端API的地址。我们需要将其指向Ngrok为后端服务分配的公网域名。
-
编辑
.env文件:使用文本编辑器打开
.env文件:bashcd deer-flow cp .env.example .env vim .env -
修改
NEXT_PUBLIC_API_URL和ALLOWED_ORIGINS:找到并修改以下两行:
plaintext# docker build args ### 静态域名(后端服务) NEXT_PUBLIC_API_URL=https://xxxx.app/api ALLOWED_ORIGINS=*
NEXT_PUBLIC_API_URL: 将https://xxxx.app替换为Ngrok后端隧道(backend)分配的公网域名。请注意,这里需要加上/api后缀。ALLOWED_ORIGINS: 设置为*表示允许所有来源的跨域请求。这在开发和测试阶段非常方便。但在生产环境中,强烈建议将其修改为前端服务实际的域名,以提高安全性,防止恶意网站进行跨域攻击。
conf.yaml 文件修改
-
编辑
conf.yaml文件:使用文本编辑器打开
conf.yaml文件:bashcd deer-flow cp conf.yaml.example conf.yaml vim conf.yaml -
配置模型 BASIC_MODEL: base_url: xxx model: "xxx" api_key: xxxx # max_retries: 3 # Maximum number of retries for LLM calls # verify_ssl: false # Uncomment this line to disable SSL certificate verification for self-signed certificates
yamlREASONING_MODEL: base_url: xxx model: "xxx" api_key: xxxx max_retries: 3 # Maximum number of retries for LLM calls
docker-compose.yml 端口映射
docker-compose.yml 文件定义了DeerFlow服务的Docker容器配置,包括端口映射。DeerFlow的后端服务运行在容器的8000端口,前端服务运行在容器的3000端口。我们需要确保这些端口正确地映射到宿主机上,以便Ngrok能够访问到它们。
-
编辑
docker-compose.yml文件: 使用文本编辑器打开docker-compose.yml文件:bashvim docker-compose.yml -
检查端口映射: 确认
backend和frontend服务下的ports配置如下:yamlbackend: ports: - "8000:8000" # 宿主机8000端口映射到容器8000端口 frontend: ports: - "3000:3000" # 宿主机3000端口映射到容器3000端口
后端CORS配置 (src/server/app.py)
除了 .env 文件中的 ALLOWED_ORIGINS,DeerFlow的后端代码中也包含CORS配置。为了确保跨域请求能够被正确处理,我们需要检查并修改 src/server/app.py 文件。
-
编辑
app.py文件:使用文本编辑器打开
app.py文件:bashvim .../deer-flow/src/server/app.py -
修改
allowed_origins变量:找到以下代码段,并确保
allowed_origins变量被设置为["*"]:python# Add CORS middleware # It's recommended to load the allowed origins from an # environment variable for better security and flexibility across different # environments. # allowed_origins_str = os.getenv("ALLOWED_ORIGINS", # "http://localhost:3000") # allowed_origins = [origin.strip() for origin in # allowed_origins_str.split(",")] allowed_origins = ["*"]- 将
allowed_origins直接设置为["*"]意味着允许所有来源的请求。这与.env文件中的ALLOWED_ORIGINS=*保持一致,确保了跨域访问的顺畅。同样,在生产环境中,出于安全考虑,建议将["*"]替换为您的前端服务实际的域名列表。
- 将
完成以上配置修改后,DeerFlow就能够通过Ngrok提供的公网域名进行访问了。接下来,我们将介绍如何启动和管理DeerFlow服务。
DeerFlow操作
完成所有配置后,我们就可以启动DeerFlow服务了。DeerFlow使用Docker Compose进行容器化部署,这使得服务的启动、停止和管理变得非常便捷。请确保已经在服务器上安装了Docker和Docker Compose。
首先,进入DeerFlow的应用目录:
bash
cd .../deer-flow启动DeerFlow
-
首次启动: 如果是第一次启动DeerFlow,或者对Docker镜像进行了更新,需要使用
--build参数来构建或重建Docker镜像。bashdocker compose -p deerflow up --build -d首次启动可能需要一些时间来下载Docker镜像和构建服务,请耐心等待。
-
后续启动: 如果DeerFlow服务已经构建过,并且只是想重新启动它,或者在服务停止后再次启动,则无需重新构建镜像,可以省略
--build参数。bashdocker compose -p deerflow up -d

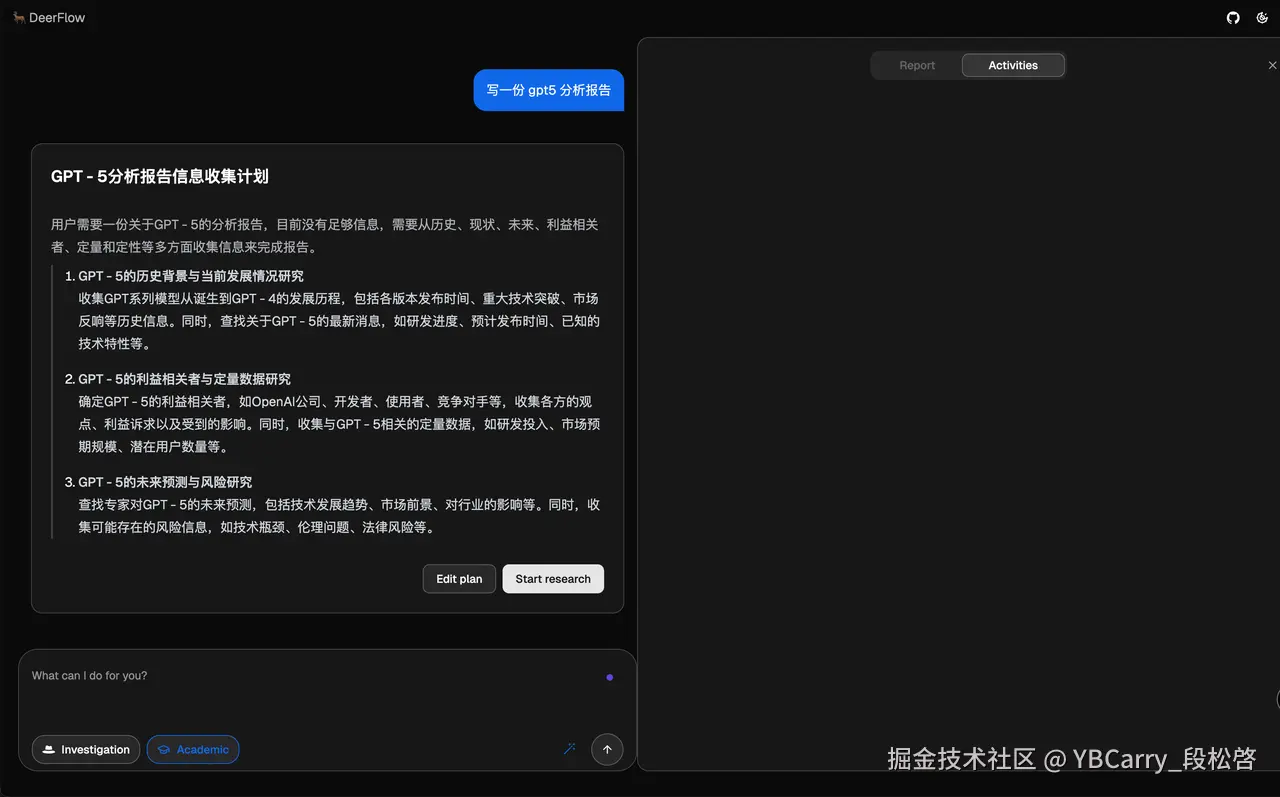
关闭DeerFlow
当需要停止DeerFlow服务时,可以使用 down 命令。这会停止并移除Docker Compose项目中的所有容器、网络和卷。
bash
docker compose -p deerflow down查看服务状态
要检查DeerFlow服务的运行状态,可以使用 ps 命令。它会列出Docker Compose项目中所有服务的当前状态。
bash
docker compose -p deerflow ps -a查看日志
在调试或监控DeerFlow服务时,查看日志是非常重要的。logs 命令可以显示服务的标准输出和标准错误。
bash
docker compose -p deerflow logs -f通过上述命令,可以方便地管理DeerFlow服务的生命周期,确保其稳定运行。
结语
通过本文讲解,你应该已经掌握了如何利用Ngrok内网穿透技术,以单服务器、低成本的方式实现DeerFlow的公网访问。这种部署方式极大地降低了个人用户和小型团队体验和开发大语言模型应用的门槛,让DeerFlow的强大功能能够被更广泛地利用。
DeerFlow作为字节跳动开源的创新项目,为大语言模型的研究和应用提供了坚实的基础。结合内网穿透技术,它不再受限于本地网络环境,可以轻松地与外部服务集成,或者作为远程访问的AI服务。这对于远程协作、演示、或者构建个人AI助手都具有重要意义。
我们鼓励你亲自动手尝试本文所介绍的配置方案,并根据实际需求进行调整和优化。随着大语言模型技术的不断成熟,DeerFlow这类工具将变得越来越重要,而掌握其部署和访问方式,无疑将为您打开通往AI世界的新大门。如果在实践过程中遇到任何问题,欢迎在评论区留言交流,共同进步。