Snowflake 是一个数据库 ,因此它具备与其他数据库类似的管理功能。它也是最早的数据仓库即服务(DWaaS)之一,这意味着终端用户可以最大限度地减少运维与维护。
本章概述了管理 Snowflake 账户的多种选项,主要面向 Snowflake 管理员;但终端用户也能借此了解 Snowflake 管理与运维的关键概念。
管理员通常需要承担的主要任务包括:
- 管理角色与用户
- 基于角色的访问控制(RBAC)
- 管理账户参数
- 管理数据库与虚拟仓库
- 管理数据共享
- 管理数据库对象
- 管理聚簇表
本章将逐一介绍这些主题,并通过我们的 Snowflake 演示来展示其工作方式。
管理角色与用户(Administering Roles and Users)
Snowflake 使用角色(roles)来管理访问与操作。换言之,你可以创建自定义角色 并赋予一组权限(privileges) ,以控制授予访问的粒度 。例如,我们想为市场团队 创建一个角色,让团队成员能够访问相关数据,并使用虚拟仓库 运行 SQL 查询。按照 Snowflake 的模型,对可保护对象(securable objects)的访问是通过分配给角色的权限 来管理的;此外,角色可以被分配给其他角色与用户。
Snowflake 现已支持灵活的层级角色结构 与多级继承 ,可高效建模复杂的访问模式。另外,动态数据脱敏(dynamic data masking)与 行访问策略(row access policies)提供了与角色绑定的细粒度访问控制。
Snowflake 采用以下访问控制模型:
- 自主访问控制(DAC) :每个对象都有一个所有者,该所有者可以管理该对象的访问。
- 基于角色的访问控制(RBAC) :先创建角色并赋予其权限,再将角色分配给用户。
**可保护对象(securable object)**指可被授予访问权的 Snowflake 实体(如数据库、表、仓库等)。权限(privilege)则是对对象的一种访问级别。
图 4-1 示意了一个营销角色 的示例:该角色为营销用户在 DATABASE 与 WAREHOUSE 等可保护对象上授予 USAGE(使用) 、**MODIFY(修改)**与 OPERATE(操作) 等权限。
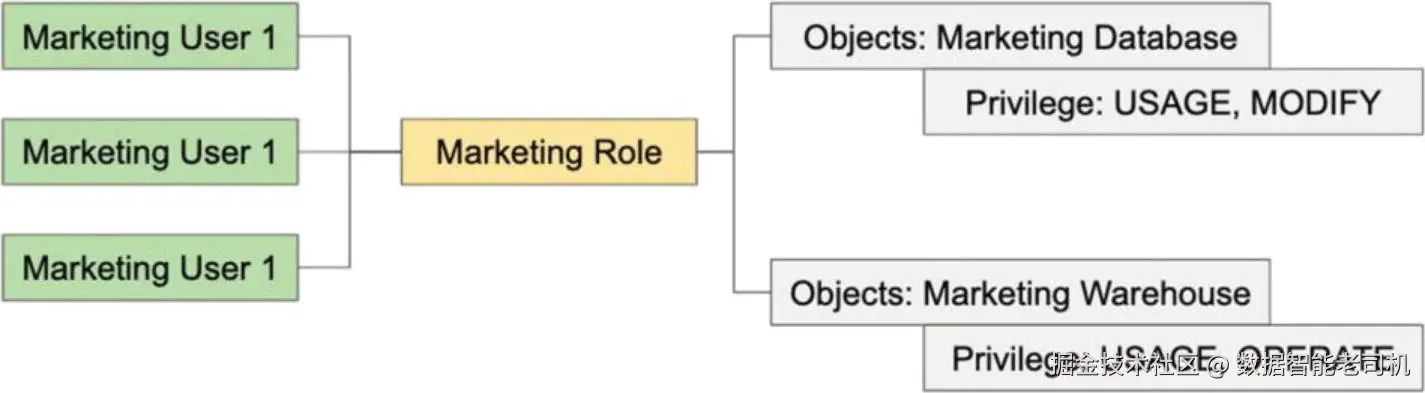
当我们启动示例的 Snowflake 账户时,里面已经包含若干预定义的默认角色:
- ACCOUNTADMIN :账户管理员角色;Snowflake 账户中的最高级角色。
- SYSADMIN :系统管理员角色;用于创建与管理数据库和虚拟仓库。
- PUBLIC :一种伪角色(pseudo-role) ;可以授予给任何对象------授予给 PUBLIC 的对象对账户内所有用户可见/可用。
- SECURITYADMIN :安全管理员角色;用于创建并管理角色与用户。
- USERADMIN :专职用户账户管理 ,包括创建、修改、冻结/解冻、删除用户,以及其认证设置的管理。
- ORGADMIN :仅在多账户组织 中可用;提供组织层面的跨账户管理能力。
要创建自定义角色 ,通常使用 SECURITYADMIN 角色;也可以把 CREATE ROLE 权限授予其他角色来完成。应谨慎设计 Snowflake 的角色层级 ,以确保访问与职责得到恰当的委派;可通过 ACCESS_HISTORY 视图定期审计角色,以确保符合访问策略要求。
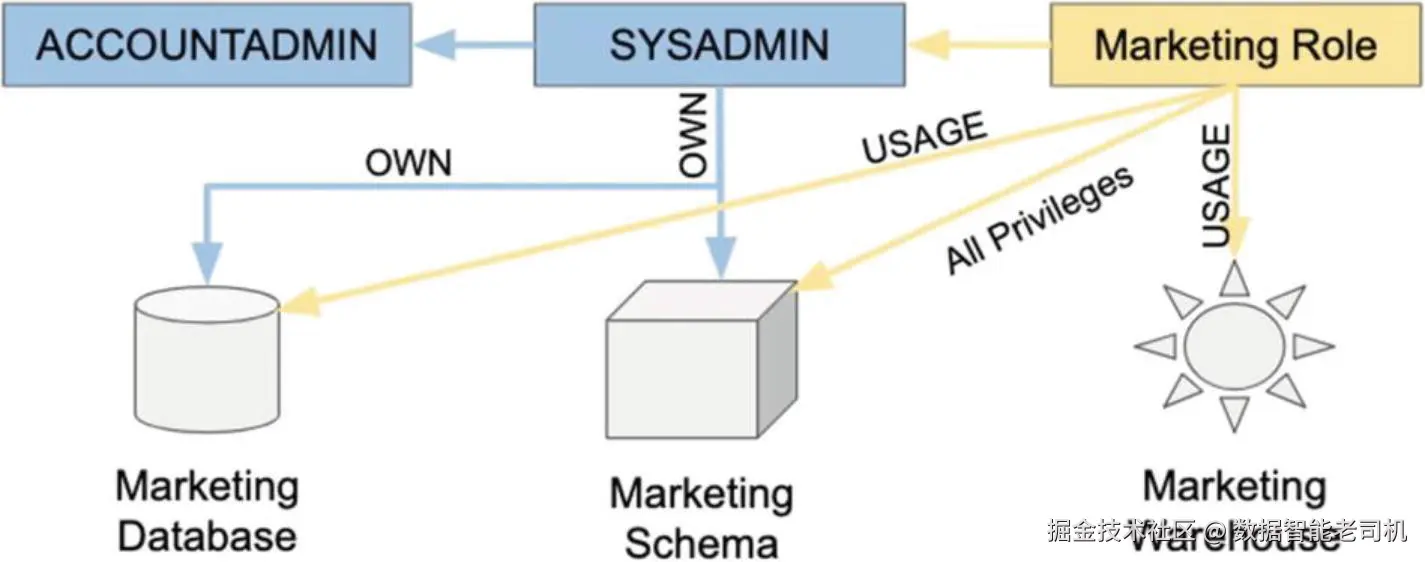
图 4-2 展示了一个层级示例:Marketing 角色被授予对 营销数据库、Schema 与仓库 的相应权限;这些对象由 SYSADMIN 角色创建/拥有。
权限生效模型(Enforcement Model)
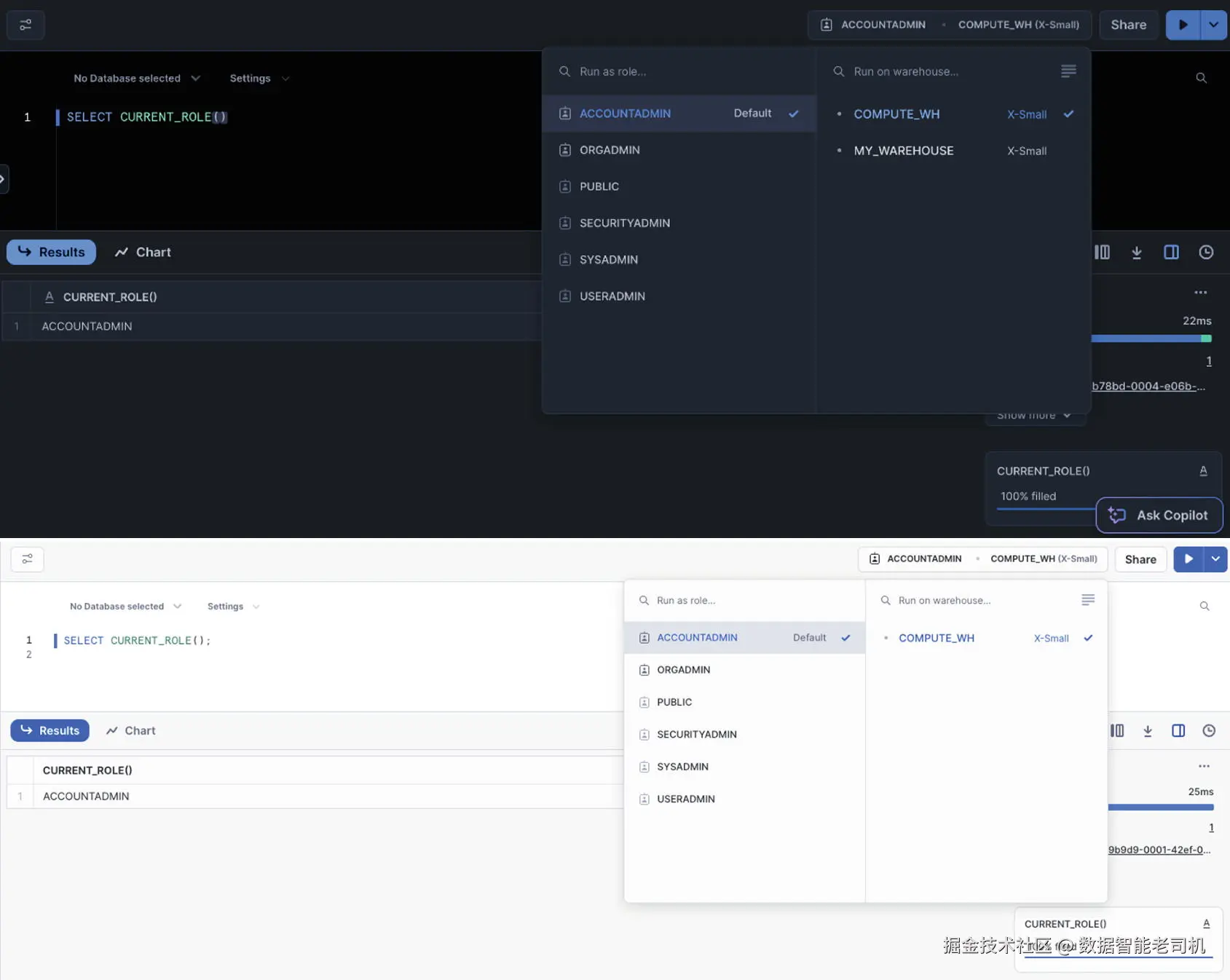
当你通过 Web 界面或 ODBC/JDBC 客户端登录 Snowflake 账户时,会启动一个会话(session)。在该会话中,系统会自动为你设置一个当前角色(current role) ,它决定了你在本次会话中的权限范围。若你被授予了多个角色,可在会话期间手动切换角色:既可以使用 USE ROLE 命令,也可以在你正在使用的工作表右上角的菜单中进行切换(见图 4-3)。
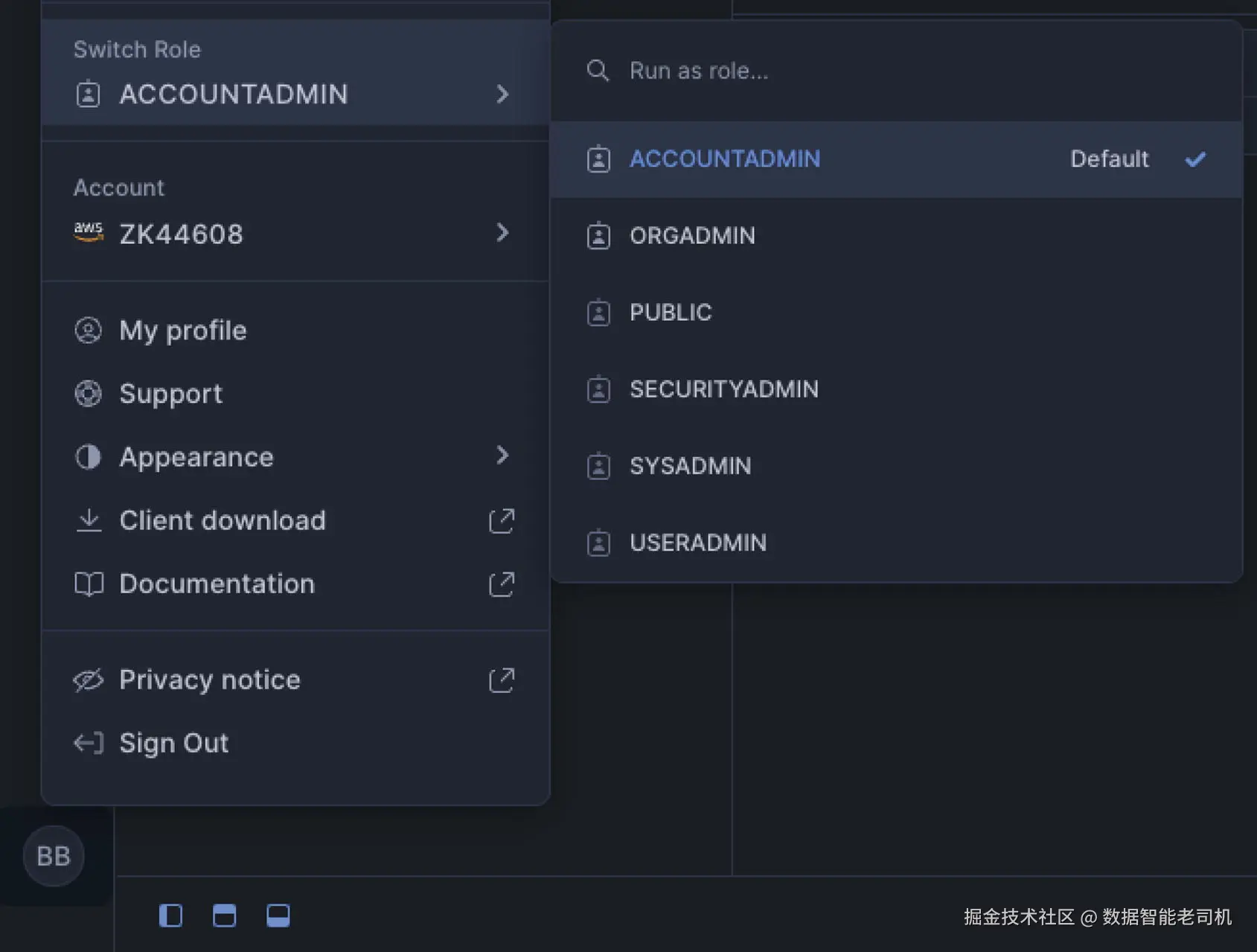
也可以在左下角 点击个人资料(Profile) 图标进行切换(见图 4-4)。
当用户在 Snowflake 中尝试执行任意操作时,Snowflake 会将用户当前角色 所拥有的权限 与该操作所需权限进行比对。
注 :在其他数据库中你也许熟悉"超级用户/超级角色"的概念,但 Snowflake 并不提供 这种功能。任何访问都必须 具备相应的访问权限。
次级角色(Secondary Roles)
Snowflake 支持次级角色 :除主角色外,用户还能在同一会话中同时激活多个角色 。这能简化角色管理,减少会话期间频繁切换角色的需要。启用次级角色后,只要这些角色已分配给该用户,用户即可同时 使用所有已激活角色所授予的权限。
这在如下场景尤为有用:用户需要在一个 Schema 中读 数据、在另一个 Schema 中写 数据、并管理任务 ------而这些操作分别依赖不同角色。
可通过如下语句启用次级角色:
ini
ALTER SESSION SET SECONDARY_ROLES = ('ALL');在 RBAC 下管理角色与用户(Working with Roles and Users with RBAC)
Snowflake 允许在角色 粒度上精细控制数据仓库。你可以通过 DDL 命令或 Web 界面创建角色。常用的角色管理命令包括:
CREATE ROLE:创建新角色ALTER ROLE:修改现有角色DROP ROLE:删除现有角色SHOW ROLES:显示可用角色列表USE ROLE:在会话中切换活动角色
创建角色前,确保你以具备相应权限的角色(如 SECURITYADMIN)登录:
ini
CREATE ROLE MARKETING_TEAM;
CREATE ROLE DATA_SCIENCE_TEAM;以上命令会创建两个新角色:MARKETING_TEAM(面向市场分析师)与 DATA_SCIENCE_TEAM(面向数据科学家)。
接下来,为角色授予权限并关联用户。用户管理相关命令包括:
CREATE USER:创建新用户ALTER USER:修改现有用户DESCRIBE USER:查看用户详情SHOW PARAMETERS:显示与用户关联的参数
此外,创建/修改用户时可指定:
userProperties:如密码、显示名、邮箱等sessionParams:如默认仓库、命名空间、查询超时等
示例:创建新用户并将其加入 MARKETING_TEAM 角色:
ini
CREATE USER marketing_analyst
PASSWORD = 'RockYourData'
COMMENT = 'Marketing Analyst'
LOGIN_NAME = 'marketing_user1'
DISPLAY_NAME = 'Marketing_Analyst'
DEFAULT_ROLE = "MARKETING_TEAM"
DEFAULT_WAREHOUSE = 'COMPUTE_WH'
MUST_CHANGE_PASSWORD = TRUE;
GRANT ROLE "MARKETING_TEAM" TO USER marketing_analyst;为了让 MARKETING_TEAM 能运行 SQL 查询,需要在虚拟仓库上授予相应权限:
vbnet
GRANT USAGE
ON WAREHOUSE COMPUTE_WH
TO ROLE MARKETING_TEAM;此时,MARKETING_TEAM 可以使用 COMPUTE_WH 执行查询,但不能挂起或恢复该仓库。
再创建一个数据科学用户并授予更高的仓库权限:
ini
CREATE USER data_scientist
PASSWORD = 'SecurePassword'
COMMENT = 'Data Scientist'
LOGIN_NAME = 'data_sci_user1'
DISPLAY_NAME = 'Data_Scientist'
DEFAULT_ROLE = "DATA_SCIENCE_TEAM"
DEFAULT_WAREHOUSE = 'COMPUTE_WH'
MUST_CHANGE_PASSWORD = TRUE;
GRANT ROLE "DATA_SCIENCE_TEAM" TO USER data_scientist;
GRANT USAGE
ON WAREHOUSE COMPUTE_WH
TO ROLE DATA_SCIENCE_TEAM;
GRANT OPERATE
ON WAREHOUSE COMPUTE_WH
TO ROLE DATA_SCIENCE_TEAM;DATA_SCIENCE_TEAM 既可使用 仓库运行查询(USAGE),也可管理 仓库(如挂起与恢复,OPERATE)。
注 :
COMPUTE_WH是默认创建的 X-Small 虚拟仓库;实际使用中你也可以选用自己的仓库。演示环境建议使用最小规格以节省成本。
同样的操作也可通过 Web 界面 完成。随后你可以用新用户(如登录名 marketing_user1)登录并运行示例查询:
sql
SELECT * FROM "SNOWFLAKE_SAMPLE_DATA"."TPCH_SF1"."REGION";以上所有操作均可在 Snowflake 的 Web 界面 中完成。要管理角色、用户与权限 ,请在左侧导航栏进入 Admin 菜单,并选择 Users & Roles 选项卡(见图 4-5)。
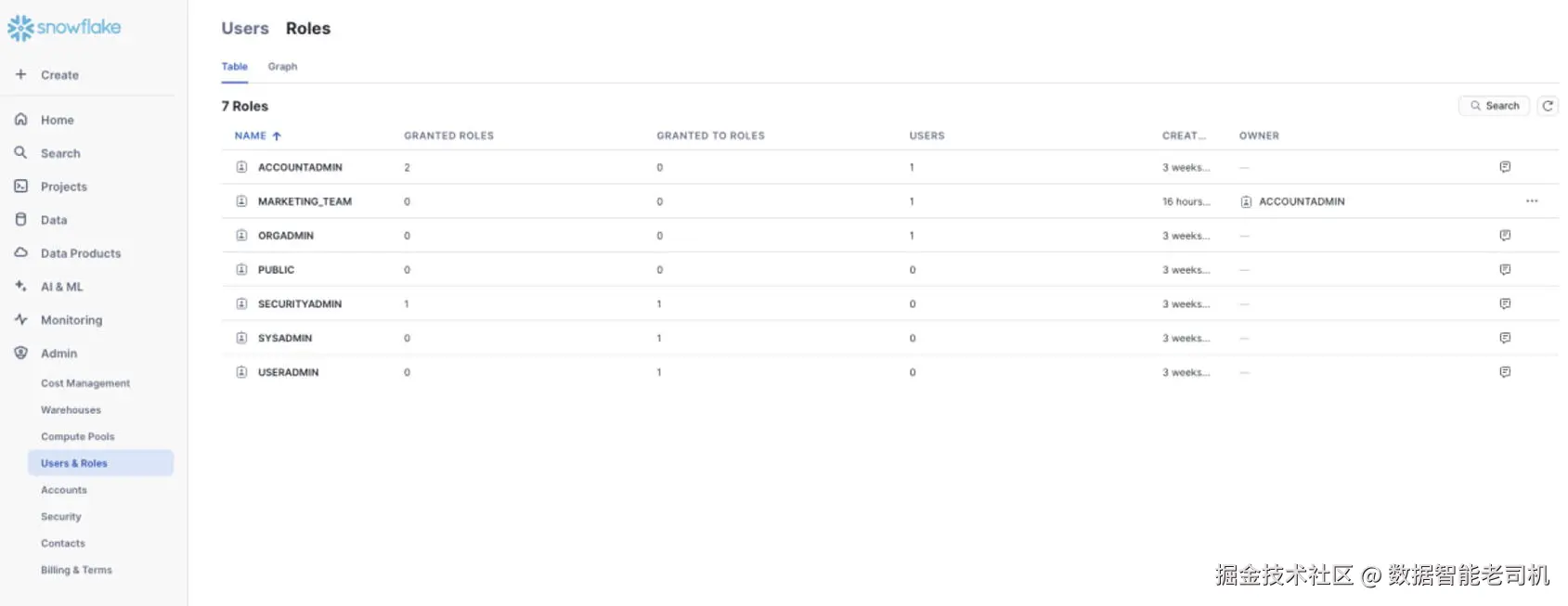
默认情况下,Admin 菜单对 ACCOUNTADMIN 角色可见。 该菜单通常由 Snowflake 管理员访问,用于管理用户与角色 、控制 Credit 使用等。
以下是 RBAC 的最佳实践:
- 最小权限(Least privilege) :始终只为用户分配完成其工作所必需的最小权限。例:
MARKETING_TEAM仅应拥有USAGE,而DATA_SCIENCE_TEAM可拥有更强的OPERATE等权限。 - 角色层级(Role hierarchy) :可以创建继承 其他角色权限的附加角色。例如,一个
ADMIN角色可继承DATA_SCIENCE_TEAM的所有权限,以更高层级管理仓库。 - 审计(Audit) :定期审查已授予的角色与权限,确保无人拥有超出必要的访问。重点监控具有
OPERATE等强权限用户的操作。
通过实施 RBAC ,可确保你的 Snowflake 环境安全、有序 ,并使访问权限贴合每位用户的实际需求。
新的角色类型:数据库角色与应用角色(Database Roles & Application Roles)
除传统的账户级 角色外,Snowflake 现已支持数据库角色(database roles)与应用角色(application roles) ,以提供更模块化、更安全的访问控制。
数据库角色 限定在单个数据库范围内,便于本地化的权限管理 ,并可随数据库一同迁移------这对数据产品团队 或跨环境部署 尤为有价值。
应用角色 用于 Snowflake Native Apps ,确保对应用内对象 的访问独立于账户级角色 进行治理。
这些新角色类型有助于构建可复用、隔离、安全的组件,使访问模式更契合现代数据架构实践。
在 Snowflake 中使用 Permifrost 管理 RBAC
Permifrost (pypi.org/project/per...)是一个开源工具,可用声明式 YAML 文件定义 Snowflake 的角色、用户与权限 ,从而简化 RBAC 策略的管理与部署,确保访问控制一致 且易于维护。
前置条件:
- 具备 Snowflake 管理权限的账户(如
SECURITYADMIN或等效)以管理角色与权限 - 你的机器已安装 Python(Permifrost 为 Python 工具)
- 拥有用于认证的 Snowflake 用户账户与私钥
1. 安装 Permifrost
pip install permifrost2. 新建 YAML(如 rbac_config.yaml)定义角色、用户与权限:
yaml
roles:
- name: MARKETING_TEAM
grants:
warehouses:
- name: COMPUTE_WH
privileges:
- USAGE
schemas:
- name: "SNOWFLAKE_SAMPLE_DATA.TPCH_SF1"
privileges:
- USAGE
- SELECT
- name: DATA_SCIENCE_TEAM
grants:
warehouses:
- name: COMPUTE_WH
privileges:
- USAGE
- OPERATE
schemas:
- name: "SNOWFLAKE_SAMPLE_DATA.TPCH_SF1"
privileges:
- USAGE
- SELECT
users:
- name: marketing_analyst
default_role: MARKETING_TEAM
roles:
- MARKETING_TEAM
- name: data_scientist
default_role: DATA_SCIENCE_TEAM
roles:
- DATA_SCIENCE_TEAM该配置中的角色:
MARKETING_TEAM可使用COMPUTE_WH仓库并访问TPCH_SF1schema 的数据DATA_SCIENCE_TEAM额外拥有管理(OPERATE)COMPUTE_WH仓库的权限
该配置中的用户:
marketing_analyst绑定MARKETING_TEAMdata_scientist绑定DATA_SCIENCE_TEAM
3. 应用 RBAC 策略:
arduino
permifrost apply --config rbac_config.yamlPermifrost 将连接到你的 Snowflake 账户,确保定义的角色、用户与权限 配置正确。你也可在 Snowflake 中直接验证已应用的 RBAC 配置。
使用 Permifrost 的收益:
- 一致性 :所有 RBAC 策略以 YAML 声明式管理
- 自动化:简化跨环境的角色与权限部署
- 可审计性 :YAML 文件即 RBAC 配置的文档
- 易用性:免去大量手写 SQL,降低出错风险
借助 Permifrost,Snowflake 中的 RBAC 管理将更加流畅、可复现 ,并符合访问控制最佳实践。
动态数据脱敏(Dynamic Data Masking)
Snowflake 常用于存储与处理敏感数据 ,包括**个人可识别信息(PII)**及其他机密业务数据。确保数据安全与隐私对于遵循 GDPR、CCPA、HIPAA 及内部政策至关重要。
处理 PII 与机密数据的最佳实践:
- 数据分类 :识别并分类存储于 Snowflake 的敏感数据;使用标签 与元数据管理为 PII/机密数据打标
- 访问控制与基于角色的安全 :利用 RBAC 确保仅授权用户可访问敏感数据;遵循最小权限原则
- 数据脱敏 :使用动态数据脱敏 对未授权用户遮蔽 PII;Snowflake 提供列级内置脱敏策略
- 行级安全 :实施行访问策略,确保用户仅能看到与其角色职责相关的数据
- 加密 :确保数据传输中与静态存储 均已加密;Snowflake 提供AES-256 存储加密与 TLS 传输加密
- 代币化与匿名化 :对高度敏感数据考虑代币化 或匿名化,以伪名替换 PII,降低风险暴露
- 审计与监控 :启用 Account Usage 视图与查询历史,监控敏感数据的访问与使用;必要时对接外部安全监控
- 数据保留与清理 :制定留存与删除策略以符合法规;谨慎使用 Time Travel 与 Fail-Safe 管理数据生命周期
- 安全数据共享 :对外共享时使用 Secure Data Sharing,在不传输原始数据的情况下控制访问;可叠加脱敏与行访问策略
- 用户培训与意识:定期培训员工的数据安全最佳实践,确保其理解处理 PII 的风险与合规要求
Snowflake 的动态数据脱敏 会根据用户角色与权限 动态修改查询结果:未授权用户仅看到遮蔽值 ,授权用户可见原始数据。
你可以在 Snowsight 中创建脱敏策略:
sql
CREATE MASKING POLICY ssn_masking_policy AS (val STRING)
RETURNS STRING ->
CASE
WHEN CURRENT_ROLE() IN ('PII_ADMIN', 'DATA_ANALYST') THEN val
ELSE 'XXX-XX-XXXX'
END;然后将该策略应用到列上:
sql
ALTER TABLE customers
MODIFY COLUMN ssn
SET MASKING POLICY ssn_masking_policy;验证脱敏效果:
sql
SELECT ssn FROM customers;若当前角色不在 PII_ADMIN 或 DATA_ANALYST 中,输出将显示遮蔽值 (XXX-XX-XXXX);否则显示真实 SSN 。更多信息参见官方文档:docs.snowflake.com/en/user-gui...。
管理数据库与仓库(Administering Databases and Warehouses)
Snowflake 支持通过 Web 界面 或 SQL 命令来管理数据库与虚拟仓库(warehouse)。本节聚焦与数据库及仓库相关的常见管理操作。
管理仓库(Managing Warehouses)
作为管理员,你可以对仓库使用以下命令:
- CREATE WAREHOUSE:创建新的虚拟仓库
- DROP WAREHOUSE:删除现有仓库
- ALTER WAREHOUSE:修改仓库属性(如规格、挂起设置及其他参数)
- USE WAREHOUSE:为当前会话设置活动仓库
使用 ACCOUNTADMIN 角色执行以下命令创建新仓库:
ini
CREATE WAREHOUSE RYD
WITH WAREHOUSE_SIZE = 'XSMALL'
WAREHOUSE_TYPE = 'STANDARD'
AUTO_SUSPEND = 300
AUTO_RESUME = TRUE
COMMENT = 'Rock Your Data Virtual Warehouse';本例说明如下:
WAREHOUSE_SIZE = 'XSMALL':指定最小仓库规格AUTO_SUSPEND:空闲 300 秒后自动挂起AUTO_RESUME:有查询需要时自动恢复
你也可以使用 ALTER WAREHOUSE 调整仓库规格;最后,可用 USE WAREHOUSE 指定当前会话使用的仓库。
注 :
ALTER WAREHOUSE是 Snowflake 独有 特性。它可挂起/恢复 虚拟仓库,或中止 该仓库上的所有查询(及其他 SQL 语句);也可用于重命名 仓库及设置/取消 属性。详情见:docs.snowflake.com/en/sql-refe...。
管理数据库(Managing Databases)
在 Snowflake 中,所有数据都存放于数据库表 中(列与行的集合)。每个数据库可以包含一个或多个 schema ,在 schema 内可以创建诸如表 、视图等数据库对象。
注 :Snowflake 对数据库、schema 或数据库对象的数量没有硬性上限。
常用的数据库管理命令包括:
- CREATE DATABASE:创建新数据库
- CREATE DATABASE CLONE :创建现有数据库的零拷贝克隆
- ALTER DATABASE:修改数据库属性
- DROP DATABASE:删除数据库
- UNDROP DATABASE :在保留期内恢复最近被删除的数据库
- USE DATABASE:为会话指定活动数据库
- SHOW DATABASES:列出当前角色可见的所有数据库
这些命令既可通过 Web 界面执行,也可直接用 SQL。示例:创建一个数据库
ini
CREATE DATABASE MARKETING_SANDBOX;你还可以为特定角色授予诸如 CREATE SCHEMA、MODIFY、MONITOR、USAGE 等数据库管理权限。
总体来看,操作与传统数据库相似,但有两项值得一提的独特功能:
UNDROP DATABASE(撤销删除)
设想你不小心删除了生产数据库;在传统环境中,从备份恢复可能至少需要一天。而在 Snowflake 中,只要仍处于保留期窗口 ,使用 UNDROP DATABASE 即可即时恢复最近版本的已删数据库。
该保留期由参数 DATA_RETENTION_TIME_IN_DAYS 控制,决定诸如数据库、schema、表等可恢复 的时长。默认值为 1 天 ;对 Enterprise 版及以上 账户,可提高到最多 90 天。
零拷贝克隆(Zero-Copy Cloning)
另一项独特功能是零拷贝克隆 :它会创建数据库的快照 ,且该快照是可写且独立的。这对数仓 DBA 而言堪称"梦想功能"。
许多场景需要复制数据库进行测试或试验,以避免改动敏感的生产库;但传统复制需要物理搬迁全部数据 ,既费时又昂贵(两份数据都要付费)。生产库一旦更新,副本还会过期并需要再次更新。
Snowflake 采用不同思路:它允许你在数秒内 复制数据库,且不进行物理拷贝 。系统持续引用原始数据 ,仅在你更新/更改 数据时写入新增记录 ;因此每条唯一记录只付费一次 。此外,你可以将零拷贝克隆 与 Time Travel 功能结合使用。
图 4-6 展示了通过 Web 界面克隆数据库的选项。
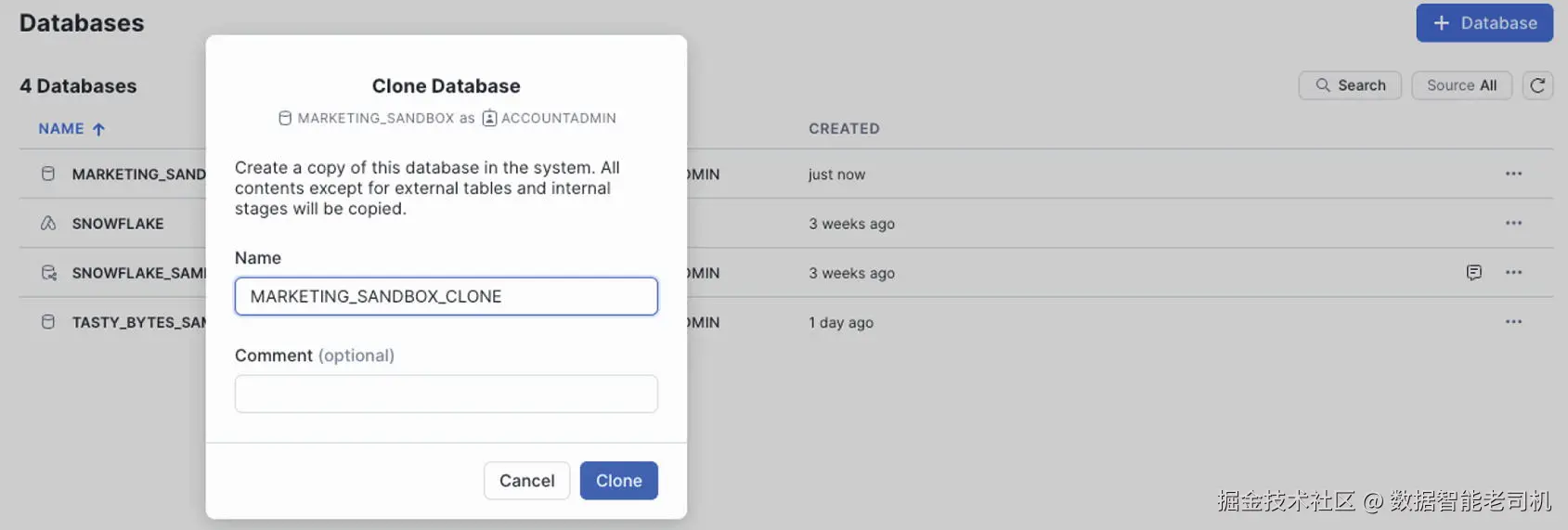
一如既往,你也可以选择用命令来完成操作。 下面给出带说明的示例命令。
sql
-- 克隆当前状态下的整个数据库及其所有对象:
CREATE DATABASE mytestdb_clone
CLONE mytestdb;
-- 克隆当前状态下的某个 schema 及其所有对象:
CREATE SCHEMA mytestschema_clone
CLONE testschema;
-- 克隆当前状态下的一张表:
CREATE TABLE orders_clone
CLONE orders;
-- 按指定时间点之前的状态克隆一个 schema:
CREATE SCHEMA mytestschema_clone_restore
CLONE testschema BEFORE (TIMESTAMP => DATEADD(DAY, -7, CURRENT_TIMESTAMP));
-- 按指定时间点的精确状态克隆一张表:
CREATE TABLE orders_clone_restore
CLONE orders AT (TIMESTAMP => TO_TIMESTAMP_TZ('04/05/2023 01:02:03', 'MM/DD/YYYY HH24:MI:SS'));管理账户参数(Administering Account Parameters)
Snowflake 中的参数 用于控制账户 、单个用户会话 以及特定对象的行为,可分为三类:
- 账户参数(Account parameters) :在账户级设置,全局生效。
- 会话参数(Sessions parameters,居多) :可在会话/用户/账户 级设置,通常影响查询执行 与会话行为。
- 对象参数(Object parameters) :针对特定对象 (如数据库、仓库)设置,也可在账户级统一控制。
要覆盖默认参数,可使用以下命令:
ALTER ACCOUNT:修改账户级参数。ALTER SESSION:调整当前会话的参数。CREATE <object>或ALTER <object>:在创建/修改对象时设置其参数。
查看可用参数及其选项:
ini
SHOW PARAMETERS;你也可以查看特定数据库或仓库的参数。
参数示例:
-
STATEMENT_TIMEOUT_IN_SECONDS:指定系统取消正在运行的 SQL 的超时时间,防止"失控"或资源密集查询。iniALTER SESSION SET STATEMENT_TIMEOUT_IN_SECONDS = 300; -- 5 分钟 -
MAX_CONCURRENCY_LEVEL:设置某仓库集群可并发执行 的 SQL 最大数量,控制并发度。iniALTER WAREHOUSE my_warehouse SET MAX_CONCURRENCY_LEVEL = 10; -
TIMEZONE:为会话设置时区,影响与时间戳相关的操作。iniALTER SESSION SET TIMEZONE = 'Europe/Lisbon';
管理数据库对象(Administering Database Objects)
Snowflake 中常见的运维任务之一是管理数据库对象(tables、views、schemas、stages、file formats 等)。
所有数据库对象均创建在某个 schema 下。传统对象(表、视图、物化视图、序列等)拥有类似操作:
CREATE:创建对象ALTER:修改既有对象DROP:删除对象SHOW:列出对象详情DESCRIBE:查看对象的详细元数据
此外,管理员还可利用 Snowflake 的独特能力 ,如 UNDROP 与零拷贝克隆。
Snowflake 还支持一组schema 级对象,例如:
-
Stage(阶段/暂存区) :用于存放数据文件,既可内部 (Snowflake 内部),也可外部(S3、Azure Blob 等)。
iniCREATE STAGE my_stage URL='s3://my-bucket/data/' CREDENTIALS=(AWS_KEY_ID='key' AWS_SECRET_KEY='secret'); -
File format(文件格式) :指定装载/卸载文件的结构。
iniCREATE FILE FORMAT my_format TYPE = 'CSV' FIELD_OPTIONALLY_ENCLOSED_BY = '"'; -
Pipe :借助 Snowpipe 实现连续摄取的数据加载自动化。
sqlCREATE PIPE my_pipe AS COPY INTO my_table FROM @my_stage FILE_FORMAT = (FORMAT_NAME = my_format); -
UDF :使用 SQL 或 JavaScript 创建自定义函数。
sqlCREATE FUNCTION my_udf(x INT) RETURNS INT LANGUAGE SQL AS 'x * 2';
管理数据共享(Administering Data Shares)
安全数据共享(Secure Data Sharing)是 Snowflake 的一项独特功能,可在不复制数据 的情况下实现无缝共享。管理员可作为数据提供方创建 share,常用命令:
CREATE SHARE:创建新 shareALTER SHARE:修改现有 shareDROP SHARE:删除 shareDESCRIBE SHARE:查看 share 详情SHOW SHARES:列出可用 share
注 :作为 share 创建者,你对数据安全 负责。创建 share 前应充分了解数据与用例,避免共享敏感数据 。创建 share 时安全视图 与 UDF 很有用。
创建 share 后,可用以下命令查看/授予/撤销数据库对象访问:
GRANT <privilege> TO SHARE:为 share 授权对象访问REVOKE <privilege> TO SHARE:撤销 share 对对象的访问SHOW GRANTS TO SHARE:显示授予某 share 的所有对象权限SHOW GRANTS OF SHARE:列出使用该 share 的所有账户/消费者
如不再需要共享并准备删除,应先评估对下游消费者 的影响;也可选择先撤销部分对象授权观察效果。
管理聚簇表(Administering Clustered Tables)
作为 DWaaS ,Snowflake 通过自动 处理数据分布、排序与统计等,简化了运维。
性能关键之一是 微分区(micro-partitioning) :加载数据时,Snowflake 会自动将其划分为约 50--500 MB(压缩后)的微分区,并按列式 组织;同时收集并存储微分区元数据,借助**分区裁剪(partition pruning)**优化查询计划、减少不必要的扫描。
Snowflake 还会在表中沿自然维度 (如日期/地域)尝试排序,这称为数据聚簇(clustering) ,对大表 尤为重要。默认启用自动聚簇 。某些情况下,你可在 CREATE TABLE 中显式定义聚簇键 以改变默认行为,但这应是少数例外 :
最佳实践 是避免 手动聚簇,除非存在特定查询模式 无法满足 SLA ;一般而言,未到至少 1TB 的表 通常无需聚簇。
作为管理员,你可能需要评估表的聚簇情况 并适时重聚簇,以识别问题表并尽可能优化性能。
可用两个系统函数监控聚簇信息:
SYSTEM$CLUSTERING_DEPTH:计算某表的平均聚簇深度。SYSTEM$CLUSTERING_INFORMATION:提供指定表的详细聚簇指标(含深度)。
若需改进聚簇,可新建带新聚簇键 的表并将数据导入;或使用物化视图基于新聚簇键创建表的"版本",由物化视图机制自动与基表新增数据保持同步。
注 :定义了聚簇键的表被视为已聚簇 。是否使用聚簇取决于表规模 与查询性能 ,最适用于TB 级以上的大表。
Snowflake 物化视图(Materialized Views)
按照 Snowflake 的定义,物化视图 是依据视图定义中的查询(SELECT)预先计算 得到的数据集,并被持久存储 以供后续使用。由于数据已被预计算,查询物化视图通常比直接执行原始查询更快 ;当查询频繁运行 或足够复杂时,这种性能差异会尤为明显。
注 :物化视图旨在提升由常见、重复 查询模式组成的工作负载的查询性能;但物化 中间结果会产生额外成本 。因此,在创建物化视图之前,应评估复用预计算结果 带来的节省能否抵消其成本。
以下场景中,物化视图特别有价值:
-
相较于基表 (定义视图所基于的表),查询结果只包含较少的行和/或列。
-
查询结果需要大量处理,例如:
- 对半结构化数据(如 JSON、Avro)的分析
- 计算耗时较长的聚合
Snowflake 物化视图的主要优势在于:它解决了传统物化视图的痛点 。Snowflake 会自动维护 这些视图:当基表发生变化时,后台服务会对其进行更新。与在应用层手动维护 等效结果相比,这种方式更高效、也更不易出错。
表 4-1 展示了表、常规视图、查询结果缓存 与物化视图 之间的关键相同点与差异。
表 4-1 关键相同点与差异(Key Similarities and Differences)
| 性能收益 (Performance Benefits) | 安全收益 (Security Benefits) | 简化查询逻辑 (Simplifies Query Logic) | 支持聚簇 (Supports Clustering) | 占用存储 (Uses Storage) | 维护耗费 Credits (Uses Credits for Maintenance) | |
|---|---|---|---|---|---|---|
| 常规表(Regular table) | ||||||
| 常规视图(Regular view) | ||||||
| 查询结果缓存(Cached query result) | ||||||
| 物化视图(Materialized view) |
说明:表格用于对比上述对象的特性;具体打勾/适用性请参考原表格或官方文档。
小结(Summary)
本章涵盖了 Snowflake 的主要管理职责 (如用户与角色管理)、RBAC 与 Permifrost ,并介绍了关键对象(如仓库 与Schema 级对象 )。同时回顾了计费与用量 信息,并讨论了数据共享 、数据聚簇 概念以及物化视图。
下一章将探讨云分析的关键要素之一:安全。