揭秘词嵌入的魔力
在我们深入 Word2Vec 这个迷人的世界之前,让我们先厘清一件事 ------ 对计算机而言,单词就如同天文学家眼中的星星:它们美丽、数量众多,且要完全理解相当复杂。然而,就像望远镜帮助天文学家了解星星一样,词嵌入帮助计算机理解单词。
什么是词嵌入?
想象你在一个热闹的市场,每个摊位都是字典里的一个单词。词嵌入就像一张神奇的地图,把售卖相似商品(意思相近的单词)的摊位放在彼此较近的位置。这些 "摊位" 并非随机排列,而是根据它们所提供的 "商品"(含义和用法)精心组织的。
例如,"国王(king)" 这个词可能会放在 "女王(queen)" 附近,而离 "卷心菜(cabbage)" 较远,因为在意义的范畴里,皇室与蔬菜相去甚远。
语境的本质:CBOW
连续词袋(CBOW)模型就像一个文字游戏,你根据提示猜一个单词。想想这个句子:"The cat sat on the ___." 你的大脑可能会很快想到 "mat""couch" 或 "lap"。
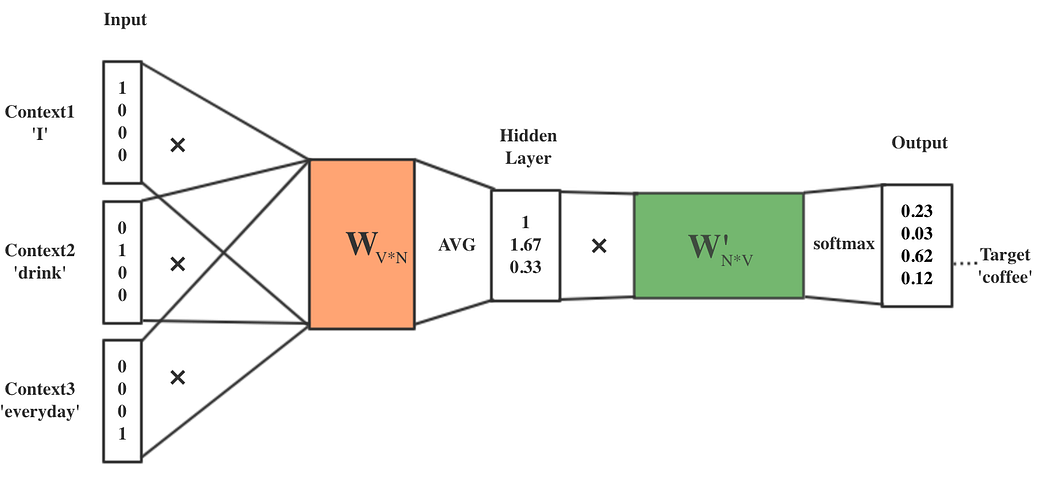
CBOW 工作原理:该模型接收周围的单词(提示)并预测缺失的单词(猜测的词)。这就像句子中有空白,让别人去填补,只不过这个 "别人" 是一个在海量文本语料上训练过的算法。
训练一瞥:在训练阶段,CBOW 获取周围的单词,融合它们的含义,并利用这种融合来猜测中心词。它在数百万个示例上不断优化自己的猜测。训练得越多,它在这个猜词游戏中表现就越好。
反向水晶球:Skip - Gram
现在,让我们用 Skip - Gram 模型来反转这个水晶球。给定单词 "sat",Skip - Gram 的任务是预测周围的单词。它与 CBOW 相反,就像知道答案后试图找出问题一样。
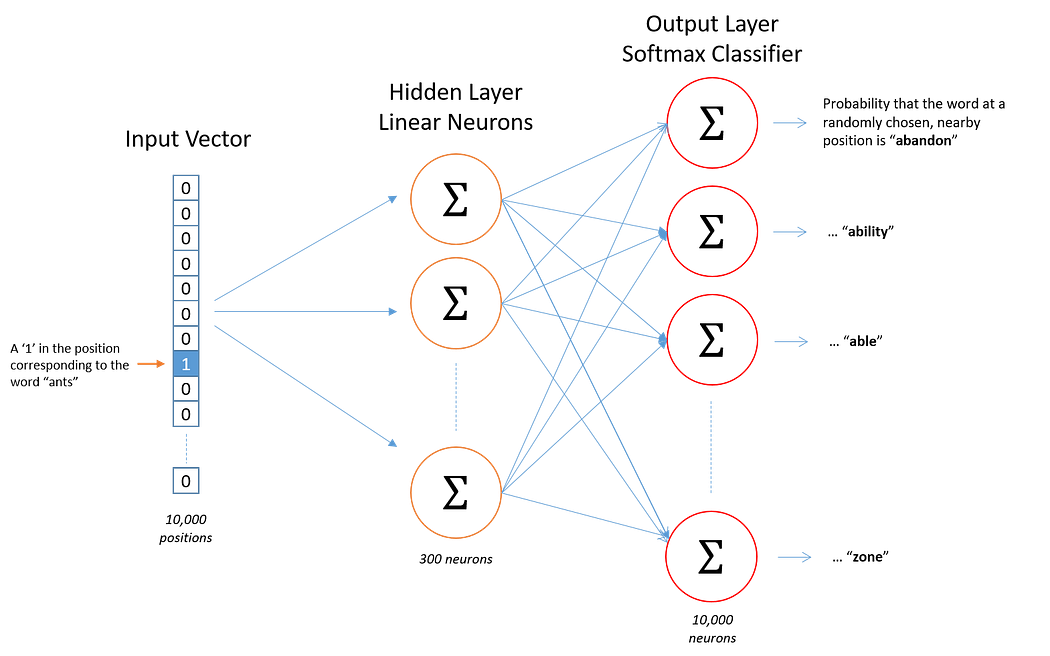
Skip - Gram 的洞察力:这个模型接收目标词并预测语境。它特别擅长理解生僻词或短语,因为它对每个词都有大量的练习 ------ 有点像专家一次专注于一个谜题。
训练简介:Skip - Gram 的训练包括向模型展示目标词,然后调整它对语境词的猜测。通过反复调整,模型学会了最可能出现的周围单词,提高了其预测能力。
Word2Vec 在 ChatGPT 中的作用
Word2Vec 不仅仅是一个用于映射单词的巧妙工具。它是像 ChatGPT 这样的模型的基础。通过 Word2Vec,ChatGPT 不仅学习单词,还学习思想、概念以及语言的微妙变化。当 ChatGPT 创作一首诗或解释量子物理时,它借鉴的是由 Word2Vec 编织的丰富的单词关系网络。
理解 Word2Vec 就像拥有一个 ChatGPT 的解码环。它揭示了一串字符如何成为智慧、机智和同理心的源泉。所以,下次你和 ChatGPT 聊天时,请记住 Word2Vec 在后台默默进行的复杂工作,它让人类的词汇变得有意义。
Word2Vec 模型(如 CBOW 和 Skip - Gram)以数学的优雅拥抱语言的复杂性,彻底改变了我们处理自然语言的方法。它们让我们能够量化定性的东西,测量不可测量的东西,并教会机器人类表达的艺术。词嵌入是弥合人机沟通鸿沟的无声英雄,而 Word2Vec 则是坚定的桥梁建设者。
附录:CBOW 和 Skip - Gram 在现实商业中的例子
Word2Vec 的应用已经遍及各个领域,证明了它是企业和组织的一个多功能工具。让我们探讨连续词袋(CBOW)和 Skip - Gram 模型在高等教育、法律、医疗保健和高科技等不同行业的应用。
高等教育
在高等教育领域,院校处理大量的文本数据,从学术论文到论坛帖子和学生反馈。
CBOW:想象一所大学想根据课程描述向学生推荐课程。CBOW 可以分析课程描述的文本,并根据学生当前或过去的注册情况所提供的语境,帮助预测学生可能感兴趣的其他课程。
Skip - Gram:为了加强研究,Skip - Gram 可用于筛选数千篇学术论文,根据摘要中的关键词预测相关概念或研究领域。这样,研究人员可以发现与自己工作有微妙关联的新领域。
法律行业
律师事务所和法律部门已经开始利用自然语言处理(NLP)来简化案例研究、文档分析和合同审查。
CBOW:律师事务所可以使用 CBOW 来识别先例。给定一个法律论点,CBOW 可以通过理解论点的语境来预测相关的判例法,大大缩短研究时间。
Skip - Gram:在法律分析中,Skip - Gram 可以根据案例描述和过去的裁决所提供的语境,预测法律案件的潜在结果,帮助律师制定策略。
医疗保健
医疗保健通过处理临床文档、改善患者护理和进行研究而从自然语言处理中受益。
CBOW:医疗服务提供者可以使用 CBOW 来解读患者的笔记。通过分析患者病史中描述的症状语境,CBOW 可以预测潜在的诊断,有助于更快地制定治疗计划。
Skip - Gram:在医学研究中,Skip - Gram 可以识别医学文献中记录的症状或治疗方法之间可能存在的关联,帮助研究人员理解疾病的更广泛背景。
高科技
始终走在创新前沿的高科技行业,将 Word2Vec 等先进模型应用于各种领域,从搜索引擎到语音识别系统。
CBOW:科技公司可能会使用 CBOW 来改进其搜索引擎。通过理解搜索查询的语境,CBOW 可以预测最相关的网页,从而提高搜索结果的准确性。
Skip - Gram:在人工智能驱动的客户支持中,Skip - Gram 可以分析单个支持工单并预测一系列相关问题,帮助支持人员更有效地预测和解决客户问题。
这些例子仅说明了 Word2Vec 模型(如 CBOW 和 Skip - Gram)在商业世界中的部分潜在应用。随着公司继续拥抱人工智能和机器学习,这些模型的采用率注定会增加,推动各个行业的创新和效率提升。
附录:在 Colab 中进行 Word2Vec 及可视化的分步指南
本指南使用一个相对较小的数据集来实际演示 Word2Vec。我们将使用 Python 中的gensim库和 Google Colab 来训练我们的模型,并以词嵌入的可视化表示结束。
步骤 1:设置环境
首先,我们需要在 Colab 中安装gensim并导入必要的库。
!pip install gensim matplotlib sklearn步骤 2:准备数据集
为了演示,我们将使用一个小数据集。让我们创建一个句子列表。
# 样本数据集:一小组句子
sentences = [
"the quick brown fox jumps over the lazy dog",
"king arthur draws the sword from the stone",
"the palace gates are open today",
"word embeddings are useful in natural language processing"
]我们需要对文本进行预处理并将句子分词。
from gensim.utils import simple_preprocess
# 将句子分词为单词
tokenized_sentences = [simple_preprocess(sentence) for sentence in sentences]步骤 3:训练 Word2Vec 模型
现在我们将使用 CBOW 和 Skip - Gram 架构训练 Word2Vec 模型。
from gensim.models import Word2Vec
# 使用CBOW训练Word2Vec模型
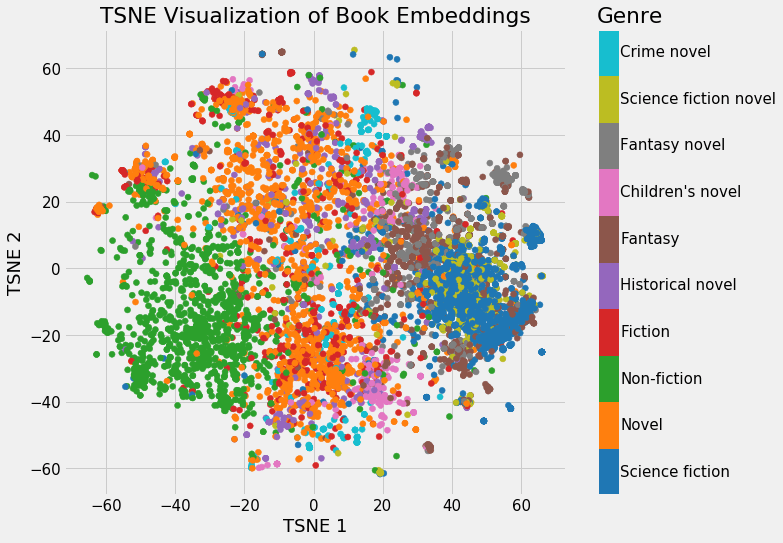
model_cbow = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=2, min_count=1, sg=0)
# 使用Skip - Gram训练Word2Vec模型
model_skipgram = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=2, min_count=1, sg=1)vector_size是词嵌入向量的大小。window是句子中当前词和预测词之间的最大距离。min_count是训练模型时要考虑的单词的最小出现次数;出现次数少于此计数的单词将被忽略。sg控制训练算法:0表示 CBOW,1表示 Skip - Gram。
步骤 4:探索结果
让我们探索模型学到的词向量。我们将以单词 "king" 为例。
# 从CBOW模型中获取一个单词的向量
vector_king_cbow = model_cbow.wv['king']
# 从Skip - Gram模型中获取一个单词的向量
vector_king_skipgram = model_skipgram.wv['king']步骤 5:可视化词嵌入
为了可视化词嵌入,我们将使用 t - SNE 降低向量的维度,并用matplotlib绘制它们。
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
# 从CBOW模型中检索所有向量
word_vectors_cbow = model_cbow.wv.vectors
# # 使用t - SNE将维度减少到2
# 假设'word_vectors_cbow'是你的Word2Vec模型中的词向量列表
num_samples = len(word_vectors_cbow)
tsne_perplexity = min(30, num_samples - 1) # 困惑度必须小于样本数量
tsne = TSNE(n_components=2, perplexity=tsne_perplexity, random_state=0)
word_vectors_cbow_2d = tsne.fit_transform(word_vectors_cbow)
# 绘制向量
plt.figure(figsize=(10, 10))
for i, word in enumerate(model_cbow.wv.index_to_key):
plt.scatter(word_vectors_cbow_2d[i, 0], word_vectors_cbow_2d[i, 1])
plt.annotate(word, xy=(word_vectors_cbow_2d[i, 0], word_vectors_cbow_2d[i, 1]), xytext=(5, 2),
textcoords='offset points', ha='right', va='bottom')
plt.show()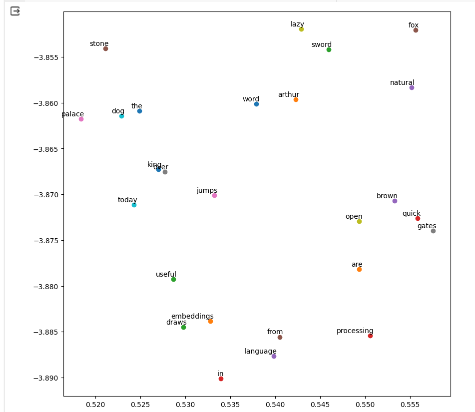
这将绘制缩减到二维空间的词向量,使我们能够看到单词在向量空间中的相对位置。具有相似语境或含义的单词应该彼此更接近。
通过遵循这些步骤,你将在一个小数据集上训练 CBOW 和 Skip - Gram 模型,并可视化生成的词嵌入。这应该能让你清晰直观地理解 Word2Vec 如何将单词的本质捕捉为适合机器学习应用的数值形式。
让我们找到最常见的单词:
# 在CBOW模型中找到与'king'最相似的单词
similar_words_cbow = model_cbow.wv.most_similar(positive=[vector_king_cbow], topn=5)
# 在Skip - Gram模型中找到与'king'最相似的单词
similar_words_skipgram = model_skipgram.wv.most_similar(positive=[vector_king_skipgram], topn=5)
# 打印相似的单词及其相似度分数
print("CBOW模型中与'king'相似的单词:", similar_words_cbow)
print("Skip - Gram模型中与'king'相似的单词:", similar_words_skipgram)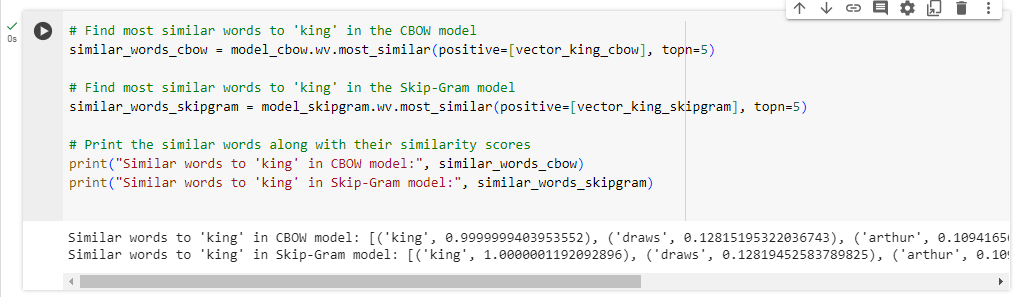
most_similar函数将返回与给定向量最相似的前n个单词。positive参数用于指定你想要找到相似度的词向量。topn参数指定要检索的最相似单词的数量。
通过运行此代码,你将得到两个模型中与单词 "king" 相似的单词列表及其相似度分数。这些单词是模型根据学到的词向量预测为最相似的单词,从而让你了解模型从提供的句子的语境中对 "king" 这个词的理解。
再附一个解释
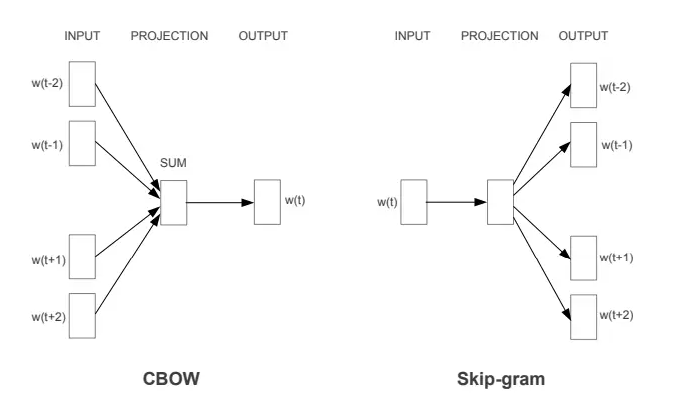
好吧,让我们用一个直观的分步方法,结合例句 "The quick brown fox jumps over the lazy dog." 来解释图像中描述的连续词袋(CBOW)和 Skip - Gram 模型。
用例句解释 CBOW 模型
语境选择:
- 假设我们的目标词w(t)是 "fox"。
- 对于 CBOW,我们定义一个语境窗口,即我们考虑的目标词两侧的单词数量。如果我们的语境窗口大小为 2,我们的输入词将是w(t−2)、w(t−1)、w(t+1)和w(t+2),分别对应 "quick""brown""jumps" 和 "over"。
输入层:
- 这些语境词中的每一个都被映射到一个独特的向量(通常在训练开始时随机初始化)。这些向量是图中的 INPUT。
投影(隐藏层):
- 在 CBOW 模型中,这些语境词的向量被组合起来产生一个新的向量。最常见的组合方法是取平均值,但也可以求和。
- 图中的 SUM 指的是组合输入层向量的这个过程。本质上,它将所有语境词的向量取平均值,得到一个代表目标词语境的单一向量。
输出层:
- 组合后的向量(SUM 之后)随后用于预测目标词w(t)------ 在我们的例子中是 "fox"。
- OUTPUT 是一个应该代表 "fox" 的向量,但在训练开始时,它不会准确地做到这一点。模型会将这个输出向量与词汇表中的所有向量进行比较,看看它最接近哪个。
训练目标:
- 模型的目标是调整其向量,使组合的语境向量接近实际目标词的向量。
- 通过多次迭代和调整(训练),模型中每个词的向量变得更加精确,并开始基于语境准确预测目标词。
用例句解释 Skip - Gram 模型
语境选择:
- 过程开始时是一样的;我们选择目标词 "fox"。
- 然而,与 CBOW 不同,我们将使用 "fox" 来预测其语境。
输入层:
- 目标词 "fox" 的向量是 Skip - Gram 模型图中的 INPUT。
投影(隐藏层):
- 输入向量随后被投影到隐藏层,但与 CBOW 不同,由于我们一次只处理一个单词,所以没有求和或平均。
输出层:
- Skip - Gram 模型随后使用目标词分别预测每个语境词。
- 对于语境窗口中的每个位置,模型将输出一个它认为代表语境词的向量。所以对于w(t−2)、w(t−1)、w(t+1)和w(t+2),它试图输出与 "quick""brown""jumps" 和 "over" 的实际向量相匹配的内容。
训练目标:
- 模型调整其向量,以最大化在给定目标词的情况下正确预测语境词的概率。
- 随着时间的推移,这使得模型学习到擅长预测单词语境的向量表示。
过程可视化
想象一群人站成一个圆圈(语境词),试图描述中间的一个人(目标词)。在 CBOW 中,所有人的描述被组合起来猜测中间是谁。在 Skip - Gram 中,中间的人试图根据自己的视角猜测周围站着谁。
"投影" 步骤就像在猜测之前将这些描述翻译成一种共同的语言。CBOW 中的 "SUM" 是将所有描述组合成一个的过程。在 "输出" 步骤中,模型然后根据组合的描述猜测中心的人(CBOW),或者根据中心人的描述猜测周围的人(Skip - Gram)。
训练类似于反复玩这个猜谜游戏,每一轮都给出反馈,因此猜测会越来越好。
"投影(隐藏层)" 确实是 Word2Vec 架构的关键部分。让我们结合前面的例句,更深入地探讨 Skip - Gram 模型在投影到隐藏层过程中发生的事情。
Skip - Gram 模型:投影层解释
在 Skip - Gram 模型中,与 CBOW 相比,投影到隐藏层的过程相对简单。没有多个语境词向量的组合 ------ 相反,我们只关注目标词。
例句:"The quick brown fox jumps over the lazy dog."
语境:假设我们再次关注目标词 "fox"。
输入层:
- 单词 "fox" 在输入层表示为一个独热向量。这是一个与词汇表长度相同的二进制向量,在对应 "fox" 的位置为 "1",其他位置为 "0"。
投影到隐藏层:
- 独热向量与权重矩阵(神经网络的第一个权重矩阵)相乘,产生隐藏层输出。这个操作有效地从权重矩阵中选择对应 "fox" 的行。
- 所选的行是 "fox" 的 "词向量"。这个向量包含在连续向量空间中表示 "fox" 的学习权重。这个空间的维度由模型定义(例如 100 维)。这个向量就是 "输入向量" 被投影到隐藏层的含义。
没有求和或平均:
- 在 Skip - Gram 模型中,由于我们一次只处理一个单词,所以不需要对多个输入词向量进行求和或平均。投影本身就是词向量。
输出层:
- 这个词向量(投影)随后用于预测语境词。它与另一个权重矩阵(神经网络的第二个权重矩阵)相乘,产生一组新的向量,每个潜在的语境词对应一个。
- 然后使用 softmax 函数将这些向量转换为概率,告诉我们词汇表中的每个词在 "fox" 的语境中出现的可能性有多大。
直观示例:
想象 "fox" 是一个参加派对的人。这个人有一定的个性、兴趣和与他人互动的方式(由 "fox" 的词向量表示)。当 "fox" 进入一场对话(语境)时,我们可以根据他已知的个性(投影到隐藏层)预测 "fox" 将如何与每个人互动。
隐藏层投影就像我们对 "fox" 有一个心理模型,我们用它来模拟或预测他在各种语境中的互动。每次互动都被单独考虑,这就是为什么不需要求和或平均 ------ 我们不是将 "fox" 与其他人组合;我们只是利用我们对 "fox" 的理解来预测他与周围人的行为。
在神经网络的背景下,"fox" 的投影不会根据语境而改变;在训练更新它之前,它是一个固定的向量。变化的是第二个矩阵中的权重,这些权重有助于从这个固定的 "fox" 向量预测语境。学习过程是关于完善这个心理模型("fox" 向量)和预测过程(第二个矩阵中的权重),以提高语境预测的准确性。