作者:来自 Elastic Jedr Blaszyk

了解使用 LLMs 构建自定义 Elastic connector 是多么简单。我们将为 Elastic 的 Connector Framework 创建一个 Crawl4AI connector。
想要获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧!
Elasticsearch 拥有大量新功能,帮助你为你的使用场景构建最佳搜索解决方案。深入学习我们的示例笔记本,了解更多信息,开始免费的云试用,或者现在就在本地机器上试用 Elastic。
数据摄取通常涉及管理复杂的基础设施,如调度、重试、日志和监控。Elastic 的 Connector Framework 简化了这一切:你只需专注于提取数据,其余的都由它来处理。
借助像 Cursor 或 Claude Code 这样的 AI 工具,即使编写一个 connector 也很容易。你只需要定义配置模式,描述你的需求,然后让 AI 处理繁重的工作。你可以在几分钟内从一个想法变成一个可用的 connector。
在这篇文章中,我们将演示构建一个新的自定义 Elastic connector 是多么容易。我们的实际示例将涉及使用流行的 crawl4ai 库构建一个对 LLM 友好的爬虫。你将看到如何通过结构化提示和理解项目上下文的 AI 代码编辑器,从需求到可用代码的全过程。
为什么构建新 connector 从未如此简单
Connector 接口 :每个 connector 都遵循一个清晰的结构:定义配置,实现同步逻辑,并生成文档以供 Elasticsearch 摄取。一旦你构建了一个,你就能再构建十个。而且,AI 助手甚至可以参考现有教程或其他 connector 实现,使这个过程更稳健。
开放代码:Elastic 的 connector 和大多数库都是开放代码。LLM 熟悉这些开放库,并能生成符合其结构和约定的代码。即使某个库刚刚更新,现代 AI 代码助手也可以实时查找在线文档来保持兼容。
AI 代码编辑器是你的超级力量:像 Cursor 或 Claude Code 这样的工具将本地代码库与 AI 连接起来,让它实时访问你的代码、文件布局和整体上下文。这不仅仅是自动补全;这些工具理解你的项目布局,并能生成具有改进上下文的代码。
构建一个 Crawl4AI connector
让我们来构建一个新的 connector。我们将使用 crawl4ai 库创建一个爬虫。
你不需要是爬虫专家。只需要清楚描述这个 connector 应该做什么、如何配置,以及它应该生成什么样的文档。有了这些,像 Cursor 和 LLM 这样的工具就能处理大部分繁重的工作。
前提条件
你需要克隆 elastic/connectors 仓库,并在你的机器上安装 Python 3.10 或 3.11。
bash
`
1. git clone git@github.com:elastic/connectors.git
2. cd connectors
`AI写代码你还需要访问一个正在运行的 Elasticsearch 实例(本地或云端)。在本地启动 Elasticsearch 最简单的方法是使用一行命令 start-local。
在开发时,使用连接到强大 LLM 的 AI 驱动代码编辑器(如 Cursor、Claude Code 或 Windsurf)。确保在编辑器中打开 connectors 项目。
现在你应该能在顶层项目结构中看到例如 README.md 文件。
让我们构建一个好的 prompt
为了确保 AI 能生成开箱即用的内容,你的 prompt 应该包含三个关键要素:
- 上下文,让它了解 Elastic Connector Framework 的具体情况。
- 功能需求,让它明白 connector 必须实现的目标。
- 技术细节,让它生成与你的环境兼容的代码。
有了这些要素,模型不仅仅是在猜测,而是在构建你真正需要的内容。现在,让我们看看我们实际使用的 prompt 以及如何为最佳结果进行结构化。
让我们从以下开始:
vbnet
`You are building a Crawl4AI Connector for Elastic's Connector Framework, using the latest available version of Crawl4AI. Check the latest Crawl4AI version online.` AI写代码设置场景。明确说明使用的 Connector Framework 和数据源库。提及确切版本有助于模型生成兼容代码,尤其是如果模型是在早期版本上训练的情况下。
功能需求
这一部分定义了 connector 应该做什么,以及为了正常工作必须满足的期望。
在这种情况下,我已经对 Crawl4Ai 库中的关键概念有了大致了解,所以我明确要求 LLM 使用它们,而不是重新发明轮子。
AI 生成代码的一个常见问题是倾向于为库已经处理的内容编写自定义逻辑。为了避免这种情况,我让模型严格遵循,尽可能引导它使用现有的抽象。我们自己写的代码越少越好。
Crawl4AI 的核心功能之一是从网页生成干净、结构化的 markdown,所以我将其作为一个需求。Markdown 内容非常适合与 LLM 一起驱动对话体验。
vbnet
``1. ## Requirements
2. - Support sitemap discovery, domain restrictions, URL filtering, and binary content extraction
3. - Run crawler in HTTP mode for speed and simplicity, don't use headless browser mode
4. - Normalize URL fragments to prevent duplicate `#section` crawling
5. - Support full sync with async get_docs() function
6. - Use `AsyncWebCrawler` with http only crawling, use crawl4ai `BFSDeepCrawlStrategy` for link discovery, BFS crawl strategy should keep track of link discovery
7. - If `allowed_domains` empty, extract domains from `start_urls`
8. - Support include and exclude patterns with crawl4ai URLPatternFilter
9. - Ingest LLM-friendly markdown output`` AI写代码配置模式
Elastic connector 通过一个 Python 方法定义面向用户的配置。这个模块将配置字段映射到 Elastic UI:标签、提示、输入类型、默认值和依赖关系。
yaml
`
1. get_default_configuration():
2. start_urls: {type: "list", display: "textarea", value: "https://example.com"}
3. allowed_domains: {type: "list", value: "", required: false}
4. sitemap_urls: {type: "list", value: "", required: false}
5. ...
`AI写代码从我观察来看,最好尽早定义这一部分。这样,LLM 可以调整代码,使其完美匹配配置界面。
你也可以选择不严格定义,依赖 LLM 根据其他实现推断 connector 配置模式。但为了本文的目的,这种方法更稳健。
输出格式
告诉模型你的 connector 应该生成什么。Elastic Connector Framework 期望返回一个元组:一个文档(doc)和一个下载协程。由于我们只抓取网页内容,可以跳过协程,因为文本提取已经由 crawl4ai 库处理。
markdown
`
1. doc = {
2. "_id": hash_id(url),
3. "url": url,
4. "title": title,
5. "content": content,
6. "depth": depth
7. }
8. yield doc, None # No download coroutine needed
`AI写代码连接位置
告诉模型新 connector 应该放在哪里,以及需要修改什么:
markdown
``
1. ## Files
2. - `connectors/sources/crawl4ai.py` - Main connector
3. - Add `crawl4ai=={most recent version}` to `requirements/framework.txt`
4. - Register in `connectors/config.py`
``AI写代码最后但同样重要
在 prompt 的最后,最好加入一个简短提示,鼓励模型在编码前先思考。这个轻量级指令能带来比你预期更好的结果。它帮助 LLM 切换到规划模式,分解问题,并生成更干净、更连贯的代码。对于像这样的结构化 connector,这个小小的停顿通常能提升代码质量。
javascript
``Reference `connectors/sources/directory.py` for Elastic connector patterns. Use built-in crawl4ai features wherever possible, the less logic we own the better. Create yourself a task-list for tracking action items, lookup information online if needed. When trying to execute console scripts you need to activate .venv.``AI写代码最终 prompt
将这个结构化 prompt 粘贴到例如 Cursor 中,以生成与 Elastic Connector Framework 期望接口一致的完整 connector 实现。从那里,你只需要进行验证、测试和调整。
css
``
1. You are building a Crawl4AI Connector for Elastic's Connector Framework, using the latest available version of Crawl4AI. Check the latest Crawl4AI version online.
3. ## Requirements
4. - Support sitemap discovery, domain restrictions, URL filtering, and binary content extraction
5. - Run crawler in HTTP mode for speed and simplicity, don't use headless browser mode
6. - Normalize URL fragments to prevent duplicate `#section` crawling
7. - Support full sync with async get_docs() function
8. - Use `AsyncWebCrawler` with http only crawling, use crawl4ai `BFSDeepCrawlStrategy` for link discovery, BFS crawl strategy should keep track of link discovery
9. - If `allowed_domains` empty, extract domains from `start_urls`
10. - Support include and exclude url filtering patterns with crawl4ai URLPatternFilter
11. - Ingest LLM-friendly markdown output
13. ## Connector Configuration
15. ```
16. get_default_configuration():
17. start_urls: {type: "list", display: "textarea", value: "https://example.com"}
18. allowed_domains: {type: "list", display: "textarea", value: "", required: false}
19. sitemap_urls: {type: "list", display: "textarea", value: "", required: false}
20. url_include_patterns: {type: "list", display: "textarea", value: "*", required: false}
21. url_exclude_patterns: {type: "list", display: "textarea", value: "", required: false}
22. max_crawl_depth: {type: "int", display: "numeric", value: 2}
23. extract_full_content: {type: "bool", display: "toggle", value: true}
24. extract_binary_content: {type: "bool", display: "toggle", value: false}
25. binary_file_extensions: {type: "list", depends_on: [{"field": "extract_binary_content", "value": True}], value: "pdf,docx,pptx"}
26. ```
28. Note, list elements are comma-separated, Connector framework will take care of parsing all config values, we don't need extra logic.
30. ## Document Output
31. ```
32. doc = {
33. "_id": hash_id(url),
34. "url": url,
35. "title": title,
36. "content": content,
37. "depth": depth,
38. }
39. yield doc, None # No download coroutine needed
40. ```
42. ## Required Structure
43. - Inherit from `BaseDataSource`
44. - implement `get_docs()` and `ping()`
47. ## Files
48. - `connectors/sources/crawl4ai.py` - connector implementation
49. - Add `crawl4ai=={most recent version}` to `requirements/framework.txt`
50. - Register in `connectors/config.py`
52. Reference `connectors/sources/directory.py` for Elastic connector patterns. Use built-in crawl4ai features wherever possible, the less logic we own the better. Create yourself a task list for tracking action items, lookup information online if needed. When trying to execute console scripts you need to activate .venv.
``AI写代码附注 :你可以在我们的 Elasticsearch Labs Prompt 库中找到这个和其他 prompt,它们能解锁使用 Elasticsearch 的更强大方式。
生成代码
我使用 Cursor 来生成 connector 代码。对于这个任务,我选择了功能强大的 Claude Sonnet 4 推理模型。
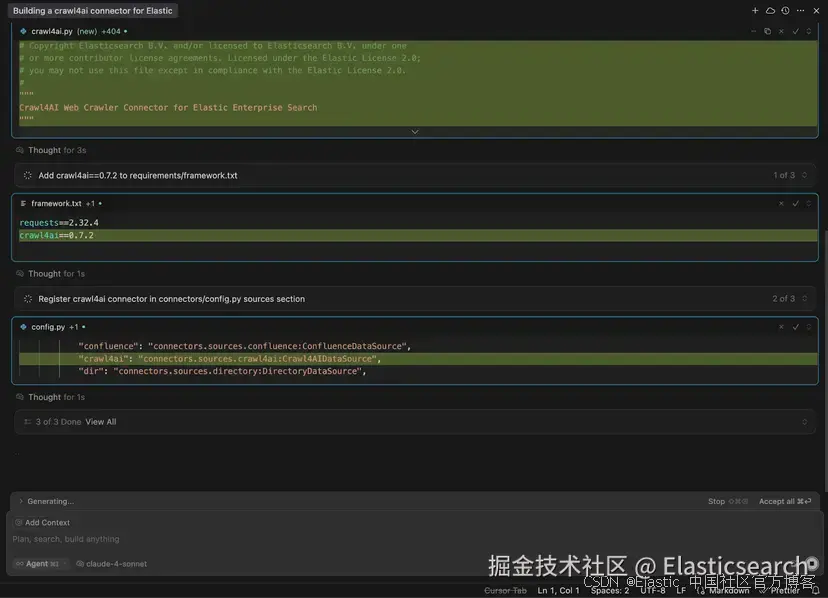
运行并测试 connector
检查清单
-
Connector 文件存在:connectors/sources/crawl4ai.py 继承自 BaseDataSource 并实现 get_docs() 和 ping()。
-
在框架中注册:connectors/config.py 将 service_type: "crawl4ai" 映射到你的类并添加到注册表。
-
添加依赖:requirements/framework.txt 包含 crawl4ai==
到现在,你生成的代码应该大致如下。
连接到 Elasticsearch
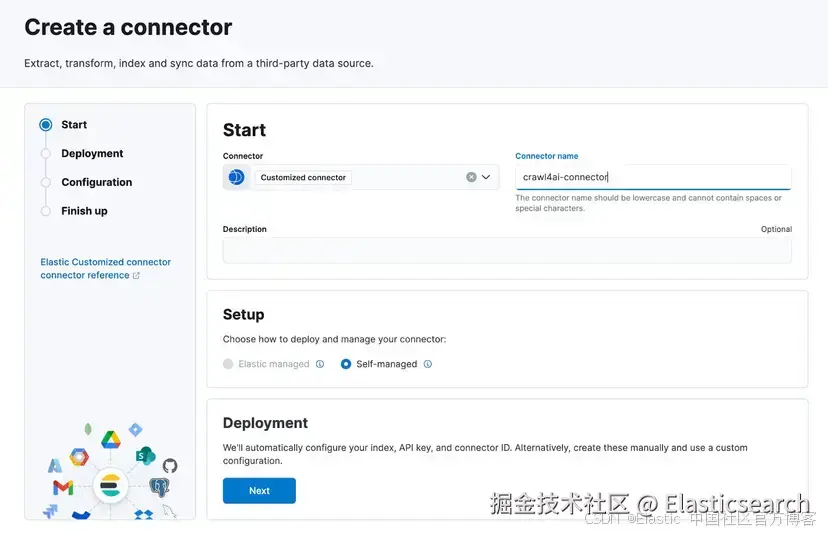
一旦生成了 connector 代码,使用 config.yml 将其连接到你的 Elastic Cloud 实例:
你可以通过点击 Elastic 中的 "Create new connector" 并选择 "Customized connector" 类型来获取 connector_id:
yaml
`
1. connectors:
2. - connector_id: DT7OUJgB8cYukRa7-wpW
3. service_type: crawl4ai
4. elasticsearch:
5. host: https://......elastic.cloud:443
6. api_key: ... (generate api key in home page)
`AI写代码运行 connector
一旦 config.yml 准备好,运行 Connector Framework:
arduino
`make run`AI写代码让 LLM 修复任何问题
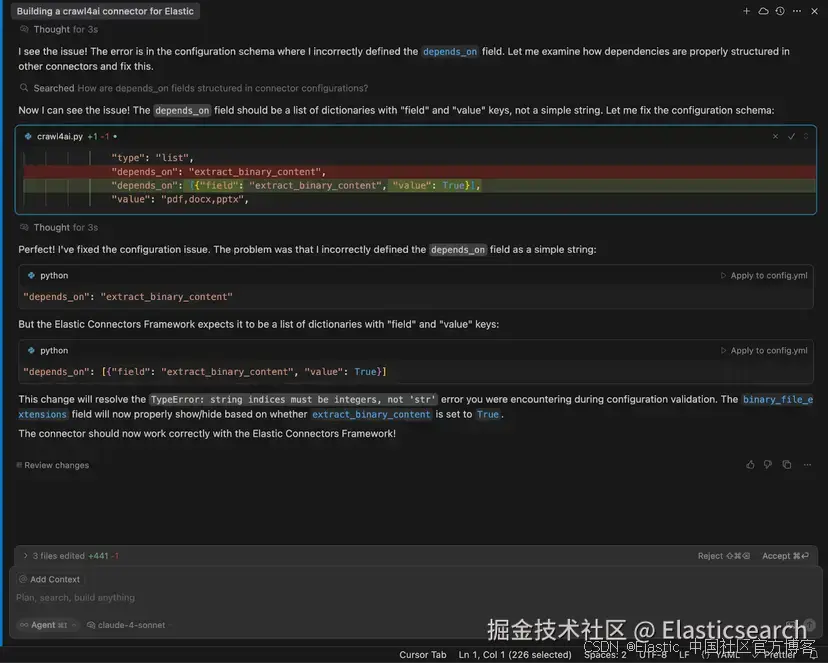
如果遇到错误,就像我在这个示例中遇到的那样,只需将其复制粘贴到 Cursor,LLM 会帮助你修复。
在我的例子中,原始 prompt 对 connector 配置中 depends_on 字段的作用说明不够清楚。LLM 能够查找其他 connector 中该属性的用法,从而确定正确的定义。
配置并开始同步数据
在我们的例子中,我们将 Elasticsearch Labs 博客抓取到我们的索引中。一旦配置好 connector,将其附加到你的索引并开始同步。
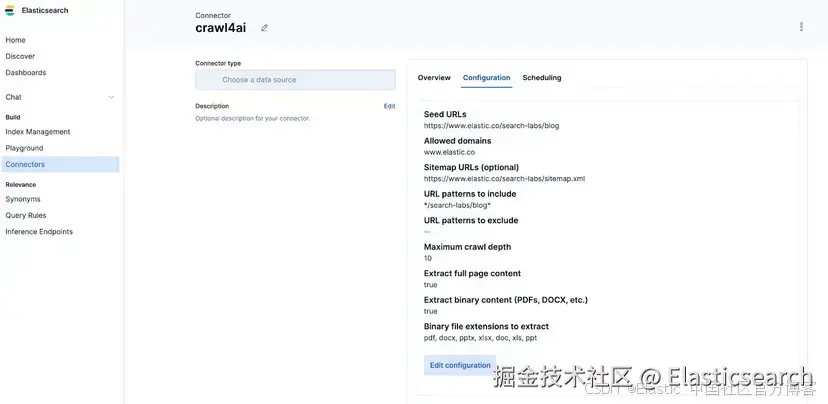
如果一切连接正确,你的 connector 就会开始摄取数据。如果遇到问题,将错误粘贴到 Cursor 中,并在修复后重新运行框架。
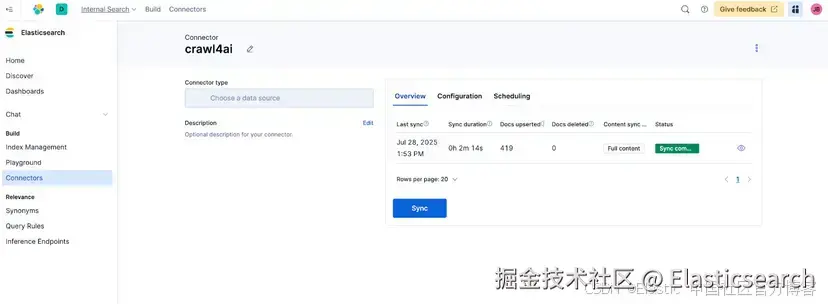
🎉 成功!我们的 connector 已经抓取并同步了来自 Elasticsearch Labs 的 419 篇博客文章。
测试和文档
一旦代码可用,你可以开始添加单元测试、端到端测试和文档。
支持语义搜索
为了增强搜索的语义能力,可以使用 ELSER embeddings,例如对内容和标题:
bash
`
1. PUT crawler-search-labs/_mapping
2. {
3. "properties": {
4. "content": {
5. "type": "text",
6. "fields": {
7. "keyword": {
8. "type": "keyword",
9. "ignore_above": 256
10. }
11. },
12. "copy_to": [
13. "semantic_text"
14. ]
15. },
16. "title": {
17. "type": "text",
18. "fields": {
19. "keyword": {
20. "type": "keyword",
21. "ignore_above": 256
22. }
23. },
24. "copy_to": [
25. "semantic_text"
26. ]
27. },
28. "semantic_text": {
29. "type": "semantic_text"
30. }
31. }
32. }
`AI写代码这可以对你的内容启用语义搜索,对于构建对话或问答体验尤其有用。生成 embeddings 的过程与使用 Elastic 的 Open Crawler 摄取数据时相同。
这是一个 ES|QL 自然语言查询的示例:
sql
`FROM crawler-search-labs METADATA _score | WHERE semantic_text : "how semantic_text works in ES" | SORT _score DESC | LIMIT 5`AI写代码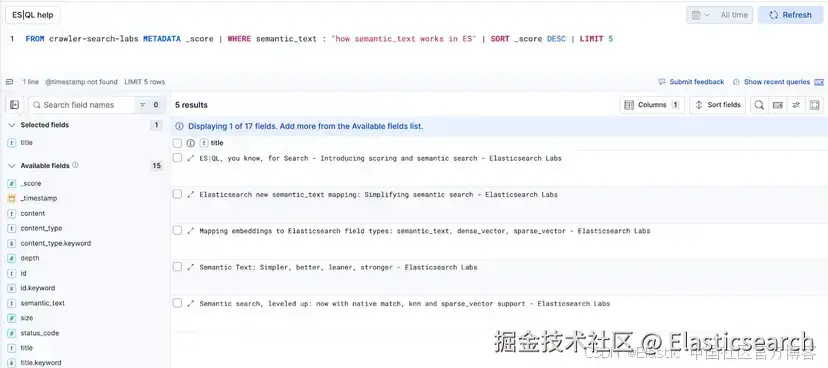
可用实现
我在 vibecoding 会话中的结果如下:
如果你只想使用 crawl4ai connector,而不深入代码生成部分,可以直接使用上面链接的源代码。
为什么要将 Crawl4AI 包装成 Elastic connector?
使用 Elastic connector 运行 Crawl4Ai 可以让常规爬取保持简单,并与 Elasticsearch 无缝集成。Connector Framework 负责数据摄取,在需要时处理摄取背压,并在页面被删除时自动保持索引同步。你还可以使用 Kibana UI 配置 connector、监控同步任务和设置调度,而无需自己构建这些功能。
结论
本指南帮助我们生成了一个可工作的 connector,可以同步支持语义搜索的数据。我们遵循了三个主要步骤:
-
有效提示 LLM:提供上下文、需求和结构,使其生成可投入生产的代码。
-
测试和验证 connector:运行它,在 AI 帮助下快速修复问题,并将其接入 Elastic Connector Framework。
-
增强语义搜索:添加 embeddings,使你的数据支持更丰富、更具对话性的体验。
正如你所见,通过 AI 辅助工具和 Elastic 的 Connector Framework,构建自定义 connector 可以从几天缩短到几分钟。结构良好的 prompt 使 LLM 能快速生成可用实现,这样你就可以专注于挖掘产品价值,而不是写样板代码。
现在你已经看到了整个流程,接下来你会连接什么? 🚀
原文:Using LLMs to build an Elastic connector fast: A Crawl4AI tutorial - Elasticsearch Labs