Canal 深度解析:构建高可用、高性能的异构数据同步方案
Canal 是什么?------ 源于 Alibaba 的 CDC 解决方案
在微服务架构和大数据时代,保持数据库(如 MySQL)与外部系统(如 Elasticsearch、缓存、数据仓库)之间的数据一致性是一个核心挑战。传统的同步方式(例如在业务代码事务提交后直接调用外部系统 API)会导致性能瓶颈和业务耦合。
Canal 是阿里巴巴开源的基于 MySQL Binlog 的增量数据订阅与消费
Canal 实战:MySQL 异构数据同步方案
在微服务架构中,确保 MySQL 与 Elasticsearch (ES) 的数据一致性是一项关键挑战。传统同步方式直接在业务线程中调用 ES API,容易因 ES 写入延迟导致系统吞吐量下降。基于 Canal 的方案通过解耦数据同步流程,实现高性能、零阻塞的异构数据同步。
Canal 的核心原理与优势
Canal 采用变更数据捕获 (CDC) 模式,模拟 MySQL 从库角色,实时解析 Binlog 并生成结构化变更事件。其核心优势包括零业务侵入性、严格的事务时序保证,以及彻底解耦业务主流程与数据同步任务。通过监听已提交的事务,避免读取未提交数据,确保最终一致性。
架构设计与技术栈
典型方案采用三级异步管道:Canal 作为生产者捕获变更,RabbitMQ 作为消息总线缓冲数据洪峰,独立消费者服务处理 ES 写入。这种设计显著降低业务线程阻塞风险,提升系统整体吞吐能力。
-
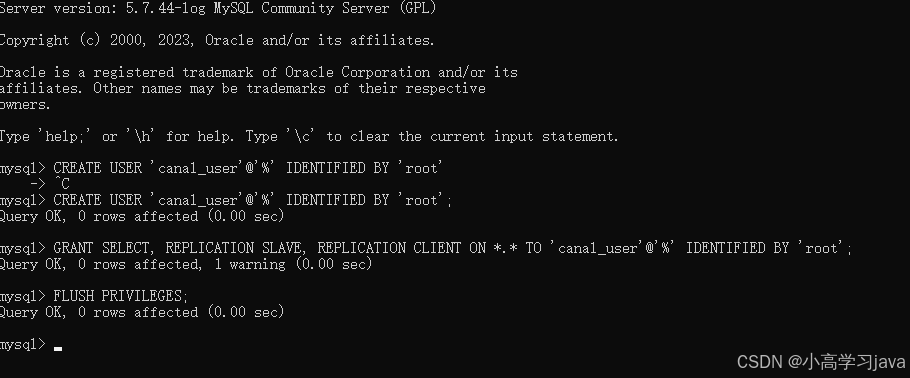
创建canal用户
打开mysql命令窗口!
在这里插入图片描述 -
Spring Boot 配置和依赖
解析 Binlog 为 JSON 消息,支持过滤特定表或操作类型(insert/update/delete)。通过 batchSize 参数控制消息批量发送频率,平衡实时性与系统负载。
-
核心 Maven \text{Maven} Maven 依赖 (pom.xml)
xml
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.6</version>
</dependency>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.protocol</artifactId>
<version>1.1.6</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>- YAML \text{YAML} YAML 配置文件 (application.yml)
yaml
# ===============================================
# 1. RabbitMQ 配置
# ===============================================
spring:
rabbitmq:
host: 127.0.0.1
port: 5672
username: guest
password: guest
listener:
simple:
# 消费者并发数,建议从小(1或2)开始,以确保同一订单的顺序处理
concurrency: 2
max-concurrency: 5
acknowledge-mode: auto
# ===============================================
# 2. Elasticsearch 配置
# ===============================================
elasticsearch:
rest:
# ES 集群地址列表
uris: http://127.0.0.1:9200
connection-timeout: 5000
# Socket 超时时间,给 ES 写入留足时间
socket-timeout: 30000
# ===============================================
# 3. Canal 客户端连接配置
# ===============================================
canal:
server:
host: 127.0.0.1
port: 11111
destination: example # 对应 Canal Server 实例名- Elasticsearch \text{Elasticsearch} Elasticsearch 客户端 Bean \text{Bean} Bean 配置
由于 Spring Boot \text{Spring Boot} Spring Boot 不会自动配置 RestHighLevelClient,我们需要手动提供 Bean \text{Bean} Bean。
java
// ElasticsearchConfig.java
@Configuration
public class ElasticsearchConfig {
// 从 application.yml 中读取配置的 ES 地址列表 (以逗号分隔)
@Value("${elasticsearch.rest.uris}")
private String[] esUris;
@Value("${elasticsearch.rest.socket-timeout:30000}")
private int socketTimeout;
// 如果您配置了用户名和密码,需要在这里读取
// @Value("${elasticsearch.rest.username:}")
// private String username;
/**
* 创建并暴露 RestHighLevelClient Bean
* Spring Boot 不会自动配置这个 Bean,需要手动提供
*/
@Bean
public RestHighLevelClient restHighLevelClient() {
// 将 URI 列表转换为 HttpHost 数组
HttpHost[] httpHosts = Arrays.stream(esUris)
.map(this::createHttpHost)
.toArray(HttpHost[]::new);
// 创建 RestClient Builder
RestClientBuilder builder = RestClient.builder(httpHosts);
// 配置客户端,例如连接超时、Socket 超时
builder.setRequestConfigCallback(requestConfigBuilder -> {
requestConfigBuilder.setConnectTimeout(5000); // 连接超时 5s
requestConfigBuilder.setSocketTimeout(socketTimeout); // Socket 超时,使用 yml 配置
return requestConfigBuilder;
});
// 如果需要配置认证信息,可以在这里添加
// if (!username.isEmpty()) {
// final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
// credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password));
// builder.setHttpClientConfigCallback(httpClientBuilder ->
// httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider));
// }
// 返回 RestHighLevelClient 实例
return new RestHighLevelClient(builder);
}
/**
* 辅助方法:将单个 URI (如 http://127.0.0.1:9200) 转换为 HttpHost 对象
*/
private HttpHost createHttpHost(String uri) {
String[] parts = uri.split("://");
String scheme = parts[0];
String hostAndPort = parts[1];
int port = Integer.parseInt(hostAndPort.split(":")[1]);
String host = hostAndPort.split(":")[0];
return new HttpHost(host, port, scheme);
}
}- 核心代码实现
1、消息传输对象
用于封装 Binlog \text{Binlog} Binlog 变更信息,在 Canal Client \text{Canal Client} Canal Client 和 ES Consumer \text{ES Consumer} ES Consumer 之间传输。
java
public class CanalBinlogEvent implements Serializable {
private String database;
private String table;
private String type; // INSERT, UPDATE, DELETE
private List<Map<String, Object>> data; // 变更后的数据
private List<Map<String, Object>> old; // 变更前的数据
// Getters and Setters...
}2、生产者: Canal \text{Canal} Canal 客户端任务 (CanalClientTask.java)
java
// CanalClientTask.java (生产者)
@Component
public class CanalClientTask implements CommandLineRunner {
@Autowired
private RabbitTemplate rabbitTemplate;
// ... run 方法和连接 Canal Server 的逻辑 ...
private void processEntries(List<CanalEntry.Entry> entries) {
for (CanalEntry.Entry entry : entries) {
// 1. 过滤事务事件,只处理 ROWDATA
// 2. 解析 entry 得到 rowChange
// 3. 遍历 rowData 列表
CanalEntry.EventType eventType = rowChange.getEventType();
String tableName = entry.getHeader().getTableName();
// 假设我们只关心 t_order 表
if ("t_order".equals(tableName)) {
for (CanalEntry.RowData rowData : rowChange.getRowDatasList()) {
// 4. 将 rowData 转换为 CanalBinlogEvent 对象 event
// ... 转换逻辑 ...
// 5. 发送到 RabbitMQ
String routingKey = "es.sync." + tableName;
rabbitTemplate.convertAndSend("exchange.canal.sync", routingKey, JSONObject.toJSONString(event));
}
}
}
}
}3、消费者: ES \text{ES} ES 同步服务 (EsSyncConsumer.java)
采用 Spring Boot 的 @RabbitListener 异步消费,通过 BulkProcessor 批量提交更新。针对不同事件类型动态选择 ES 操作:
java
// EsSyncConsumer.java (消费者)
@Component
@Slf4j
public class EsSyncConsumer {
@Autowired
private RestHighLevelClient restHighLevelClient;
private static final String ES_INDEX_ORDER = "order_idx";
/**
* 监听 RabbitMQ 队列,异步执行 ES 更新
*/
@RabbitListener(queues = "queue.es.sync.order")
public void handleOrderSync(String message) {
try {
CanalBinlogEvent event = JSONObject.parseObject(message, CanalBinlogEvent.class);
String type = event.getType();
if ("INSERT".equals(type) || "UPDATE".equals(type)) {
// Upsert 操作:使用 docAsUpsert(true) 保证文档不存在时插入,存在时更新
for (Map<String, Object> rowData : event.getData()) {
String docId = rowData.get("id").toString();
UpdateRequest updateRequest = new UpdateRequest(ES_INDEX_ORDER, docId)
.doc(rowData, XContentType.JSON)
.docAsUpsert(true);
restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
log.info("ES 文档同步/更新成功: ID={}", docId);
}
} else if ("DELETE".equals(type)) {
// 删除操作
for (Map<String, Object> oldData : event.getOld()) {
String docId = oldData.get("id").toString();
DeleteRequest deleteRequest = new DeleteRequest(ES_INDEX_ORDER, docId);
restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
log.info("ES 文档删除成功: ID={}", docId);
}
}
// 核心优化:无需在此处调用阻塞的 ES refresh()
} catch (Exception e) {
log.error("ES 同步失败,消息将被重试或进入死信队列", e);
// 抛出异常,让 RabbitMQ 根据配置进行重试
throw new RuntimeException("ES sync failed.");
}
}
}4、MQ配置文件
java
@Configuration
public class RabbitConfig {
// 定义交换机名称
public static final String EXCHANGE_CANAL = "exchange.canal.sync";
// 定义队列名称
public static final String QUEUE_ES_ORDER = "queue.es.sync.order";
// 定义路由键 (通配符匹配,例如 es.sync.t_order)
public static final String ROUTING_KEY_ORDER = "es.sync.t_order";
/**
* 定义 Topic 交换机
*/
@Bean
public TopicExchange canalExchange() {
return new TopicExchange(EXCHANGE_CANAL, true, false);
}
/**
* 定义订单同步队列
*/
@Bean
public Queue orderQueue() {
return new Queue(QUEUE_ES_ORDER, true);
}
/**
* 绑定队列到交换机
*/
@Bean
public Binding orderBinding() {
return BindingBuilder.bind(orderQueue()).to(canalExchange()).with(ROUTING_KEY_ORDER);
}
}性能调优策略
-
Canal Server 参数
调整
canal.instance.mysql.slaveId避免冲突,设置canal.instance.filter.regex过滤无关表。通过canal.mq.topic实现多环境隔离。 -
错误恢复机制
记录消费位点 (offset),在消费者重启时从最后成功位置恢复。对 ES 写入失败的消息进行指数退避重试,超过阈值后转入死信队列人工处理。
监控与保障措施
部署 Prometheus 监控 Canal 的解析延迟和 MQ 积压情况。建议在 ES 集群维护窗口期,启用 Canal 的内存模式 (Memory Store) 临时堆积消息,避免数据丢失。
该方案已在电商订单、物流跟踪等实时性要求高的场景验证,在保证数据一致性的同时,使业务接口响应时间降低 90% 以上。通过异步管道设计,系统可轻松应对突发流量冲击。组件,属于 Change Data Capture(CDC)技术范畴。其核心价值在于将数据库变更从业务应用中剥离,实现解耦和异步化。
工作原理:模拟 MySQL Slave
Canal 的工作流程基于 MySQL 主从复制机制:
Canal Server 伪装为 MySQL Slave,向 Master 发送 dump 请求。
MySQL Master 将 Binlog 推送给 Canal Server。
Canal Server 解析 Binlog 文件,将二进制数据转换为结构化的数据变更事件(包括 INSERT、UPDATE、DELETE 操作及变更前后的完整字段值)。
解析后的事件由下游 Canal Client 订阅和消费。
关键前提:MySQL 必须开启 Binlog 功能,且格式设置为 ROW(行模式),以确保捕获每一行数据的详细变更。
典型应用架构:Canal + MQ + ES
推荐的高可用异步同步架构如下:
- 数据源:MySQL Master 生成 Binlog。
- 数据捕获:Canal Server 解析 Binlog 并生成变更事件。
- 消息传递:Canal Client 将事件推送到消息队列(如 RabbitMQ/Kafka)。
- 数据处理:同步服务监听 MQ,执行 Elasticsearch 的索引操作。
该架构的优势在于解耦核心业务事务与慢速的 ES 写入操作,确保业务接口的低延迟和高吞吐量。
核心部署与配置要点
MySQL 配置:
- 开启
log-bin,设置binlog-format=ROW。 - 分配唯一的
server_id。 - 创建专用用户并授予
SELECT、REPLICATION SLAVE、REPLICATION CLIENT权限。
Canal Server 配置 :
配置文件 conf/[instance_name]/instance.properties 需包含以下核心项:
canal.instance.master.address:MySQL 主库地址。canal.instance.dbUsername和dbPassword:连接 MySQL 的凭据。canal.instance.filter.regex:过滤规则,指定同步的库和表(如mydb\\.t_order)。canal.instance.master.ha.enable:高可用开关,启用后需配置从库地址。
高可用(HA)配置 :
对于主从集群,Canal 支持自动故障切换:
- 配置主库和从库地址。
- 启用
canal.instance.master.ha.enable=true。
当主库故障时,Canal 会连接从库并从断点恢复同步。
Canal 的优势总结
- 非侵入性:同步逻辑独立于业务代码。
- 事务一致性:仅捕获已提交的事务,保证时序正确。
- 高性能:毫秒级延迟,对 MySQL 无额外负载。
- 数据完整性:支持捕获 INSERT、UPDATE、DELETE 操作,确保下游数据一致。
通过 Canal,企业可以构建可靠、高可用的数据通道,为实时数据平台和用户体验优化提供坚实基础。