目录
[一、什么是 Profiling?](#一、什么是 Profiling?)
[二、Nsight 家族简介](#二、Nsight 家族简介)
[三、Profiling 的核心指标](#三、Profiling 的核心指标)
[四、Profiling 流程示例(CUDA 核心分析)](#四、Profiling 流程示例(CUDA 核心分析))
[五、Profiling 案例分享](#五、Profiling 案例分享)
[六、 5 分钟上手:单机 CUDA 程序](#六、 5 分钟上手:单机 CUDA 程序)
[6.1 安装(Ubuntu 22.04)](#6.1 安装(Ubuntu 22.04))
[6.2 采集 & 可视化](#6.2 采集 & 可视化)
[6.3 Nsight Compute 深度分析](#6.3 Nsight Compute 深度分析)
[6.4 实战案例:让 Stable Diffusion 提速 2.7×](#6.4 实战案例:让 Stable Diffusion 提速 2.7×)
[6.5 性能优化闭环](#6.5 性能优化闭环)
随着深度学习、图形渲染和高性能计算的快速发展,GPU 已成为关键计算单元。但是,如何发现 GPU 程序的性能瓶颈,优化代码效率,是每位开发者必须掌握的技能。NVIDIA 提供的 Nsight 工具,让 GPU 性能分析(Profiling)变得直观、高效。
本文将从 Nsight 的功能、Profiling 的概念到实战案例,为你揭开 GPU 性能优化的神秘面纱。
一、什么是 Profiling?
Profiling(性能分析),通俗地说,就是"给程序做体检",找出它运行中"哪里慢、为什么慢"。
在 GPU 上,Profiling 可以帮助我们回答几个关键问题:
-
核函数(Kernel)执行效率如何?
-
每个核函数在 GPU 上运行的时间。
-
执行线程块是否充分利用 GPU 核心。
-
-
内存访问效率如何?
-
GPU 内存分层(Global、Shared、L1/L2 Cache)使用情况。
-
是否存在内存瓶颈或非对齐访问。
-
-
计算资源利用率如何?
-
SM(Streaming Multiprocessor)占用率。
-
指令调度和吞吐量是否充分。
-
-
瓶颈定位
-
是计算密集型?还是内存带宽限制?
-
是否有核函数阻塞其他操作?
-
💡 小知识:Profiling 不会直接改变程序逻辑,它只是"观察者",记录数据,帮助开发者决策优化策略。
二、Nsight 家族简介
NVIDIA 提供了几款主要的 Nsight 工具:
| 工具名称 | 功能定位 | 使用场景 |
|---|---|---|
| Nsight Systems | 系统级分析 | 跨 CPU-GPU 调度、任务序列、延迟瓶颈 |
| Nsight Compute | 核函数级分析 | 单个 CUDA kernel 性能剖析 |
| Nsight Graphics | 图形渲染分析 | Vulkan、OpenGL、DirectX 渲染优化 |
| Nsight Eclipse / Visual Studio Edition | IDE 集成 | 开发与调试 GPU 程序 |
🔹 总结:Nsight Systems 更宏观,Nsight Compute 更微观。
三、Profiling 的核心指标
使用 Nsight Profiling 时,常见的指标包括:
-
Kernel Execution Time(核函数执行时间)
直接反映 GPU 执行耗时。
-
Occupancy(占用率)
-
每个 SM 上活动线程数占理论最大值的比例。
-
占用率低 → GPU 核心资源未被充分利用。
-
-
Memory Throughput(内存吞吐量)
测量全局、共享内存的带宽利用情况。
-
Divergence(分支发散)
GPU 同一 warp 内线程执行不同分支,降低效率。
四、Profiling 流程示例(CUDA 核心分析)
假设我们有一个 CUDA 程序,需要分析核函数性能:
编译程序
nvcc -arch=sm_80 my_kernel.cu -o my_kernel启动 Nsight Compute
ncu ./my_kernel查看 Profiling 报告
-
核函数执行时间
-
内存访问效率
-
吞吐量和占用率
定位瓶颈 & 优化
-
低占用率 → 增加线程块或调整核函数结构
-
内存带宽低 → 使用 Shared Memory 或优化内存访问模式
-
分支发散严重 → 优化条件判断或 warp 设计
🔹 小技巧:Nsight Compute 支持导出 CSV 或 HTML 报告,方便团队协作与数据分析。
五、Profiling 案例分享
假设我们有一个矩阵乘法 CUDA kernel:
-
初始执行时间:12ms
-
Nsight Compute 分析显示:Global Memory 带宽利用率仅 30%,SM 占用率 50%
优化策略:
-
使用 Shared Memory 加速数据访问
-
增加线程块数量,提高 Occupancy
-
减少分支发散
优化结果: 执行时间降至 6ms,内存带宽利用率提升至 80%,GPU 核心资源几乎充分利用。
六、 5 分钟上手:单机 CUDA 程序
6.1 安装(Ubuntu 22.04)
sudo apt install nsight-systems-cli nsight-compute6.2 采集 & 可视化
# 1. 采集
nsys profile -o myAppReport ./myCudaApp
# 2. 可视化
nsys-ui myAppReport.qdrep6.3 Nsight Compute 深度分析
ncu -o saxpy_report ./saxpy
ncu-ui saxpy_report.ncu-rep6.4 实战案例:让 Stable Diffusion 提速 2.7×
症状:A100 上 512×512 出图 6.2it/s,GPU 利用率 45%。
Nsight Systems 发现:
-
大量
cudaStreamSynchronize阻塞 → CPU 前处理慢 -
UNet kernel 碎片化 → 平均时长 < 20 μs
优化:
-
把
clip.encode()放独立 stream,异步执行 -
合并 3×3 Conv → 单一
cudnnConvolutionForward -
结果:9.8 it/s,利用率 78%,提速 2.7×。
6.5 性能优化闭环
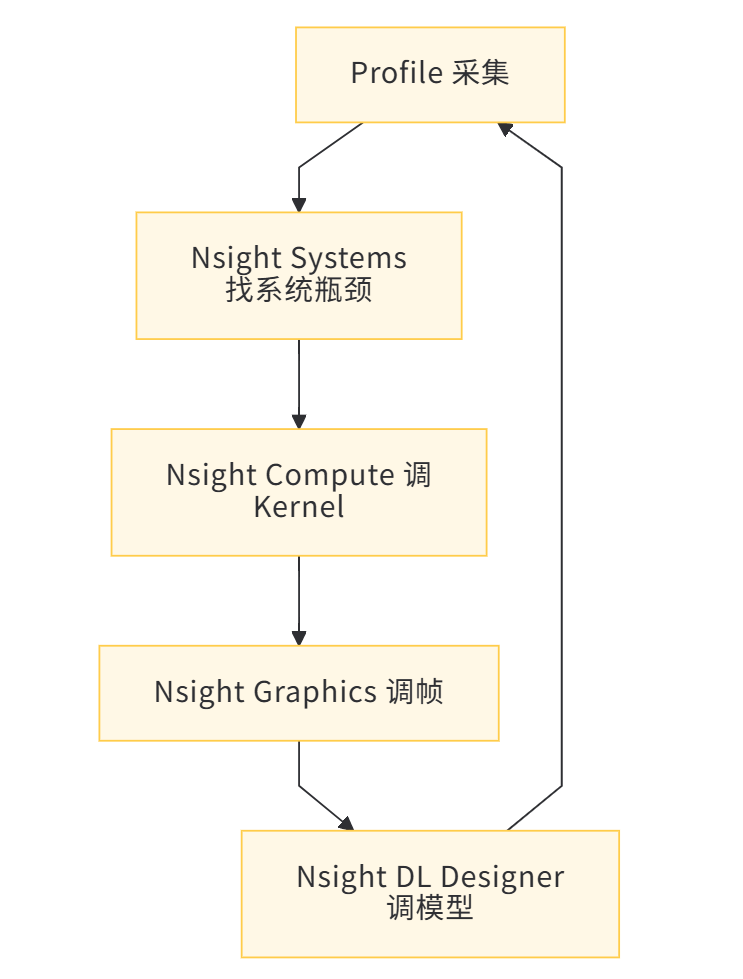
记住:不 Nsight,不优化!
七、总结
-
Profiling 是 GPU 性能优化的第一步,帮你发现"慢在哪里"。
-
Nsight 系列工具功能丰富:宏观到系统级,微观到核函数级,全覆盖。
-
优化策略需结合指标:Execution Time、Occupancy、Memory Throughput、Divergence。
-
持续迭代分析:Profiling → 优化 → 再 Profiling,才能最大化 GPU 性能。
💡 延伸阅读:
-
《CUDA by Example》:入门 CUDA 核函数性能优化必读