一、前言
HarmonyOS 的 Image 组件,相信大家平时用得还是挺开心的:一个 url 往里一塞,咔咔就能显示,啥也不用管,直接起飞。
但是,用着用着你可能会发现一些"奇妙体验"------
- 图片只加载了一半,像是网断了。
- 图片加载失败了,但是给你一个毫无用处的错误码和错误信息。
- 最难搞的是,缓存你根本没法控制,它就那么一直卡着,死活不重新拉。
这就很尴尬了,本来以为是"开箱即用",结果掉坑里了。
老样子
如果您有任何疑问、对文章写的不满意、发现错误或者有更好的方法,如果你想支持下一期请务必点赞 ~,欢迎在评论 、私信 或邮件中提出,这真的对我很重要!非常感谢您的支持。🙏
二、关于Image缓存
Image的缓存策略
Image模块提供了三级Cache机制,解码后内存图片缓存、解码前数据缓存、物理磁盘缓存。在加载图片时会逐级查找,如果在Cache中找到之前加载过的图片则提前返回对应的结果。
Image组件如何配置打开和关闭缓存
- 内存图片缓存:通过setImageCacheCount接口打开缓存,如果希望每次联网都获取最新资源,可以不设置或设置为0不缓存。
- 磁盘缓存:磁盘缓存是默认开启的,默认值为100M,可以将setImageFileCacheSize的值设置为0关闭磁盘缓存。
- 解码前数据缓存:通过setImageRawDataCacheSize设置内存中缓存解码前图片数据的大小上限,单位为字节,提升再次加载同源图片的加载速度。如果不设置则默认为0,不进行缓存。
setImageCacheCount、setImageRawDataCacheSize、和setImageFileCacheSize这这三个图片缓存接口灵活性不足,后续不再演进,对于复杂情况,建议使用ImageKnife。(以上全是官方说的)
所以ImageKnife是如何将LRU算法、磁盘缓存和内存优化融为一体,以及为什么官方说复杂情况,建议使用ImageKnife呢。看官往下看。
三、缓存策略基础概念
ImageKnife采用了双层缓存架构,就像我们生活中的"短期记忆"和"长期存储"一样:
-
内存缓存(Memory Cache):相当于短期记忆,访问速度极快,但容量有限
-
磁盘缓存(File Cache):相当于长期存储,容量大但访问速度相对较慢
这种设计遵循了计算机科学中的缓存层次结构原理,通过不同层级的缓存来平衡访问速度和存储容量。
缓存策略枚举
ImageKnife提供了三种缓存策略,让开发者可以根据需求灵活选择:
ts
export enum CacheStrategy {
// 默认-写入/读取内存和文件缓存
Default = 0,
// 只写入/读取内存缓存
Memory = 1,
// 只写入/读取文件缓存
File = 2
}可能有人会说,为什么需要提供多种缓存策略,可实际上对于任何事物,都会存在频繁,和不频繁的,那么频繁访问的图片适合放在内存中,不常用图片更适合放在磁盘中。以及遇到了大图片那么也可能不适合常驻在内存,你也不想的吧?
四、LRU内存缓存机制
LRU,相信每个开发都非常的了解了。Least Recently Used算法就像图书馆的借阅系统:最近被借阅的书籍放在最显眼的位置,长期无人问津的书籍会被移到角落,甚至下架。这样可以确保最常用的资源始终在快速访问范围内。
在ImageKnife中,我们可以找到显眼的
ts
private memoryCache: IMemoryCache = new MemoryLruCache(256, 128 * 1024 * 1024);让我们看看MemoryLruCache的核心实现:
ts
export class MemoryLruCache implements IMemoryCache {
maxMemory: number = 0 // 最大内存限制
currentMemory: number = 0 // 当前已使用内存
maxSize: number = 0 // 最大缓存条目数
private lruCache: util.LRUCache<string, ImageKnifeData> // 鸿蒙系统LRU缓存
// 添加缓存的核心逻辑
put(key: string, value: ImageKnifeData): void {
let size = this.getImageKnifeDataSize(value)
// 如果缓存已满,按LRU方式删除最旧的条目
if (this.lruCache.length == this.maxSize && !this.lruCache.contains(key)) {
this.remove(this.lruCache.keys()[0]) // 删除第一个(最旧的)
} else if (this.lruCache.contains(key)) {
this.remove(key) // 如果key已存在,先删除旧的
}
this.lruCache.put(key, value)
this.currentMemory += size
this.trimToSize() // 确保内存不超限
}
}可以看到核心代码也非常简单。
- 容量检查:this.lruCache.length == this.maxSize 检查缓存条目数是否达到上限
- LRU删除:this.lruCache.keys()0 获取最旧的缓存条目
- 内存管理:trimToSize() 确保内存使用量不超过设定阈值
为了处理"更新现有缓存"的场景。如果key已存在,我们不需要删除其他条目,只需要替换现有值即可,所以在删除旧缓存时要先检查!this.lruCache.contains(key)
LRUCache
Harmony很贴心的给我们提供一个LRU的工具
LRUCache通过LinkedHashMap来实现LRU。LinkedHashMap继承于HashMap,HashMap用于快速查找数据,LinkedHashMap双向链表用于记录数据的顺序关系。因此,对于get()、put()、remove()等操作,LinkedHashMap除了包含HashMap的功能,还需要实现调整Entry顺序链表的工作。其数据结构如下图所示:
图1 LRUCache的LinkedHashMap数据结构图 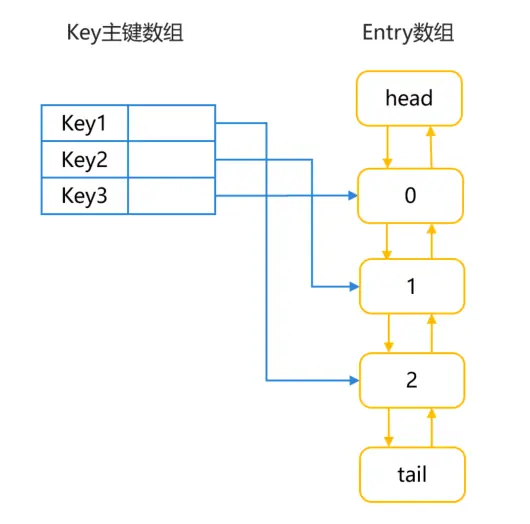
LruCache中将LinkedHashMap的顺序设置为LRU顺序,链表头部的对象为近期最少用到的对象。常用的方法及其说明如下所示:
- 调用get()方法:根据key查询对应,如果没有查到则返回null。查询到对应对象后,将该对象移到链表的尾端,并返回查询的对象。
- 调用put()方法:将key-value对添加到缓存中,同时将新对象存储在链表尾端。当内存缓存达到最大值时,移除链表头部的对象。如果key已存在,则更新其对应的value。
- 调用remove()方法:删除key对应的缓存value,如果key对应的value不在,则返回为null,否则,返回已删除的key-value键值对。
- 调用updateCapacity()方法,设置缓存存储容量。如果新容量小于原容量,仅保留新容量大小的数据。
(以上官方原话)
可扩展性
在MemoryLruCache,我们可以看到实现了IMemoryCache,而且ImageKnife中也是
ts
private memoryCache: IMemoryCache = new MemoryLruCache(256, 128 * 1024 * 1024);所以是支持我们自定义扩展的,只需要我们实现IMemoryCache~
ts
/**
* 设置自定义的内存缓存
* @param newMemoryCache 自定义内存缓存
*/
initMemoryCache(newMemoryCache: IMemoryCache): void {
this.memoryCache = newMemoryCache
}五、磁盘缓存与文件管理
磁盘缓存就像是一个智能的文件柜系统:不仅要知道文件在哪里,还要知道哪些文件最常用,哪些可以清理。
很容易的,我们能观察到FileCache这个文件:
让我们看看FileCache的实现:
ts
export class FileCache {
private lruCache: util.LRUCache<string, number>
// 初始化缓存目录,扫描现有文件
public async initFileCache(path: string = FileCache.CACHE_FOLDER) {
// 遍历缓存目录下的文件,按照时间顺序加入缓存
let filenames: string[] = await FileUtils.getInstance().ListFile(this.path)
// 按照文件创建时间排序
let cachefiles: CacheFileInfo[] = []
for (let i = 0; i < filenames.length; i++) {
let stat: fs.Stat | undefined = await FileUtils.getInstance().Stat(this.path + filenames[i])
cachefiles.push({
file: filenames[i],
ctime: stat === undefined ? 0 : stat.ctime, // 文件创建时间
size: stat?.size ?? 0
})
}
// 按时间排序,确保LRU顺序
let sortedCachefiles: CacheFileInfo[] = cachefiles.sort((a, b) => a.ctime - b.ctime)
// 将文件信息加入LRU缓存
for (let i = 0; i < sortedCachefiles.length; i++) {
this.lruCache.put(sortedCachefiles[i].file, fileSize)
this.addMemorySize(fileSize)
}
}
}- 启动时扫描:应用启动时扫描缓存目录,重建LRU缓存状态
- 时间排序:按文件创建时间排序,确保LRU顺序正确
- 内存同步:LRU缓存记录文件大小,用于内存使用量统计
缓存写入策略
ts
// 添加缓存键值对,同时写文件
put(key: string, value: ArrayBuffer): void {
// LRU容量管理
if (this.lruCache.length == this.maxSize && !this.lruCache.contains(key)) {
this.remove(this.lruCache.keys()[0]) // 删除最旧的文件
}
let pre = this.lruCache.put(key, value.byteLength)
FileUtils.getInstance().writeDataSync(this.path + key, value) // 同步写入文件
if (pre !== undefined) {
this.addMemorySize(value) // 更新内存统计
}
this.trimToSize() // 确保不超限
}有两个小细节:LRU缓存在主线程管理,避免并发冲突,文件读写在子线程进行,不阻塞UI。
作为一个程序员,我们必须有拿来主义的精神,实际上不仅仅是图片,大家可以看到两个地方都有lruCache,而ImageKnfile给我们提供了内存和文件的Lru实现。我们完全可以用到我们的下载等框架里面使用~
不同缓存策略
ts
// 从内存或文件缓存中获取图片数据
getCacheImage(loadSrc: string, cacheType: CacheStrategy = CacheStrategy.Default, signature?: string): Promise<ImageKnifeData | undefined> {
return new Promise((resolve, reject) => {
if (cacheType == CacheStrategy.Memory) {
// 只从内存缓存获取
resolve(this.readMemoryCache(loadSrc, option, engineKeyImpl))
} else if (cacheType == CacheStrategy.File) {
// 只从文件缓存获取
this.readFileCache(loadSrc, engineKeyImpl, resolve)
} else {
// 默认策略:先查内存,再查磁盘
let data = this.readMemoryCache(loadSrc, option, engineKeyImpl)
data == undefined ? this.readFileCache(loadSrc, engineKeyImpl, resolve) : resolve(data)
}
})
}
// 预加载缓存,支持不同策略
putCacheImage(url: string, pixelMap: PixelMap, cacheType: CacheStrategy = CacheStrategy.Default, signature?: string) {
let memoryKey = this.getEngineKeyImpl().generateMemoryKey(url, ImageKnifeRequestSource.SRC, { loadSrc: url, signature: signature });
let fileKey = this.getEngineKeyImpl().generateFileKey(url, signature);
switch (cacheType) {
case CacheStrategy.Default:
// 同时存入内存和磁盘
this.saveMemoryCache(memoryKey, imageKnifeData);
this.saveFileCache(fileKey, this.pixelMapToArrayBuffer(pixelMap));
break;
case CacheStrategy.File:
// 只存入磁盘
this.saveFileCache(fileKey, this.pixelMapToArrayBuffer(pixelMap));
break;
case CacheStrategy.Memory:
// 只存入内存
this.saveMemoryCache(memoryKey, imageKnifeData);
break;
}
}可以看到ImageKnfile,支持三种不同的缓存策略,满足不同需求,可以在运行时动态选择缓存策略,无需重新初始化。
那在实际应用中,什么时候应该使用CacheStrategy.Memory,什么时候使用CacheStrategy.File?
-
Memory策略:适用于频繁访问的小图片,如用户头像、图标等
-
File策略:适用于大图片或不常用图片,如背景图、详情图等
-
Default策略:适用于大多数场景,在性能和容量之间取得平衡
六、缓存架构的整体设计
让我们综合看看ImageKnife类是如何协调各个缓存组件的:
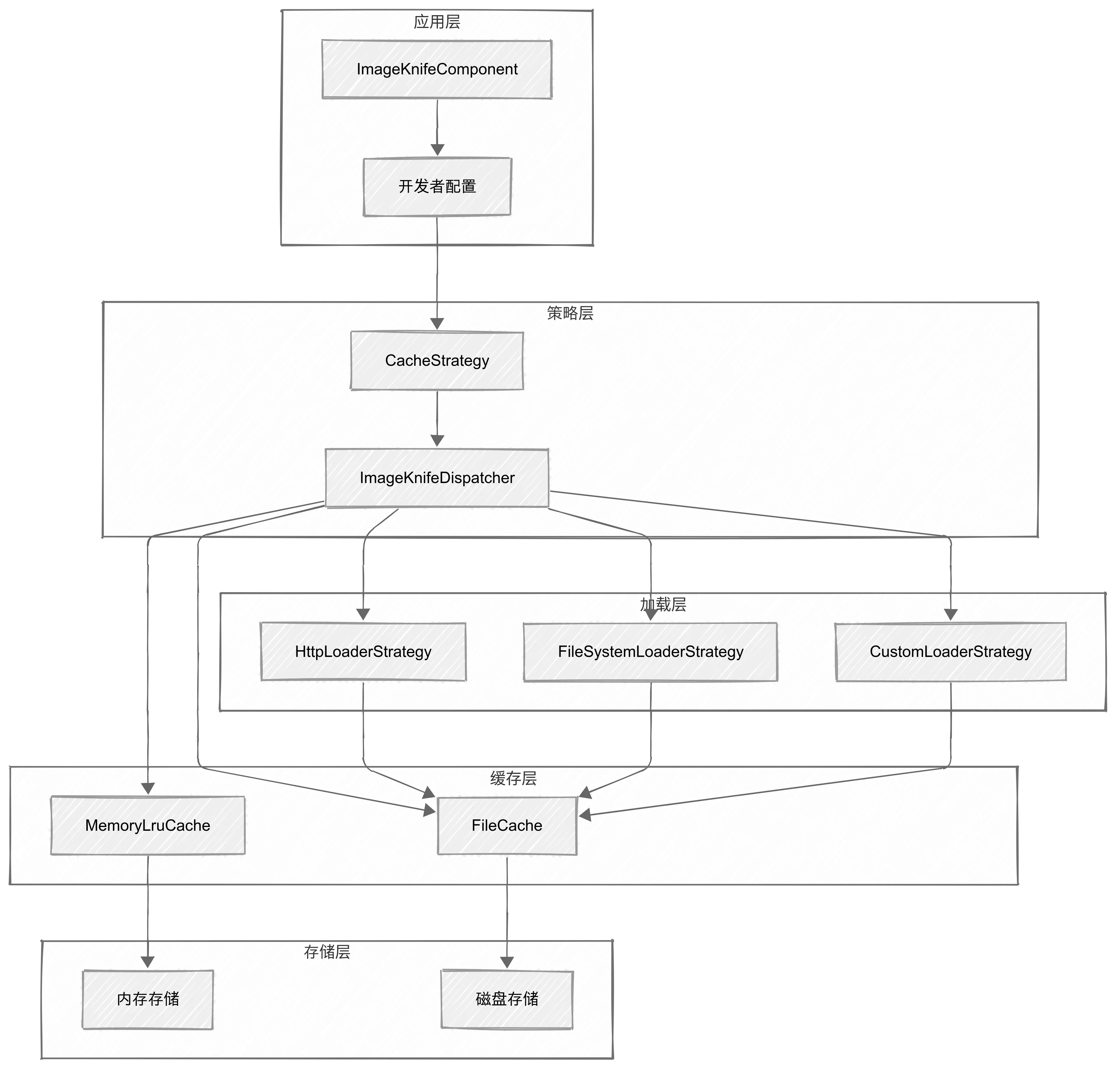
分层架构的层次关系
ImageKnife采用了经典的三层架构设计,每一层都有明确的职责边界:
-
应用层:负责用户交互和配置管理
-
策略层:负责缓存策略决策和任务分发
-
缓存层:负责数据存储和检索
-
加载层:负责从不同数据源获取图片
-
存储层:提供物理存储支持
这种分层设计让系统具有了高内聚、低耦合的特性。每一层都可以独立演进,不会因为其他层的变化而受到影响。
缓存策略的选择不是硬编码的,而是通过策略模式实现的。开发者可以通过CacheStrategy枚举选择不同的缓存行为:这种设计让ImageKnife能够适应不同的使用场景。
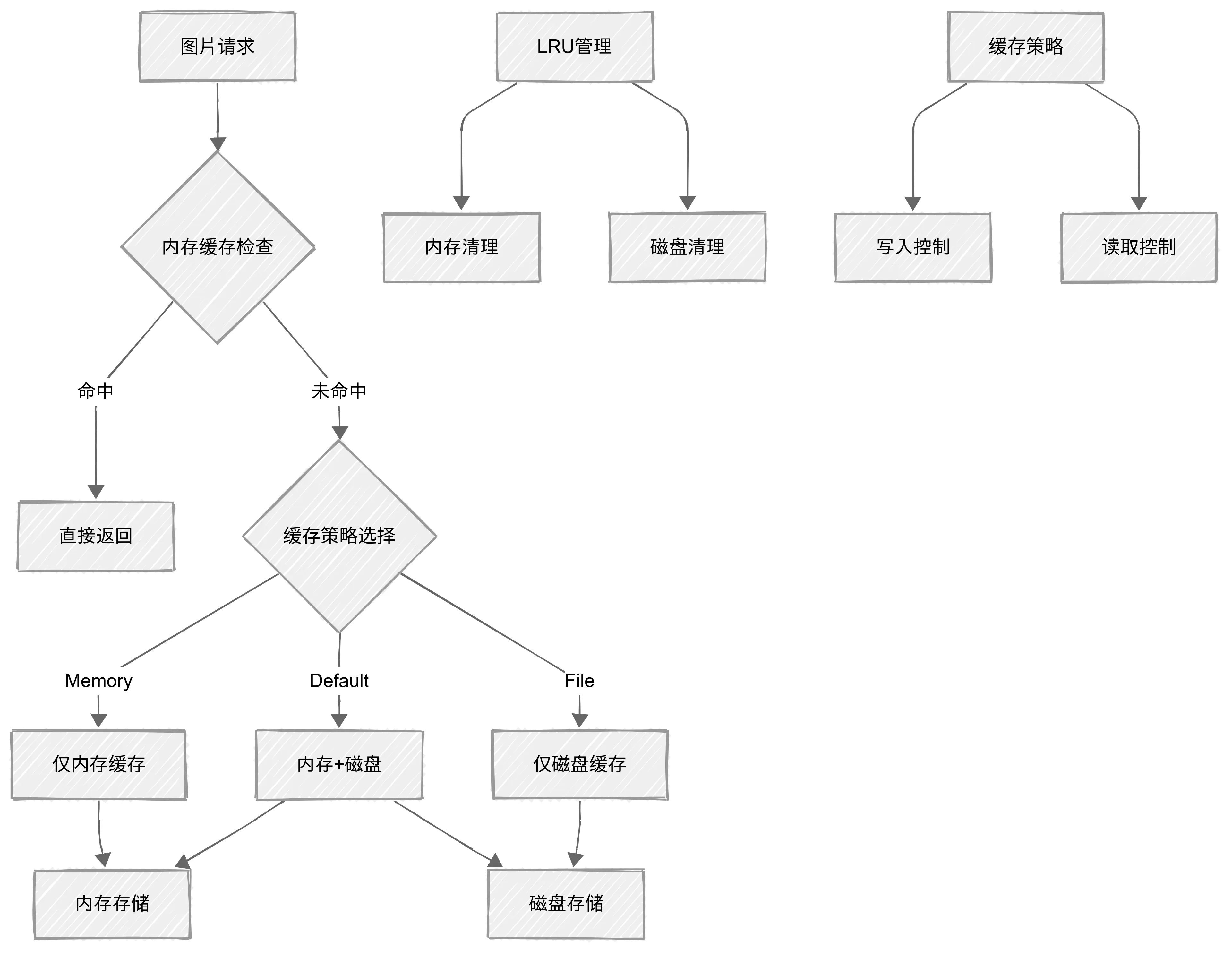
责任链模式的负载均衡
ImageKnifeDispatcher作为系统的"交通指挥中心",采用了责任链模式来管理图片加载请求:
ts
// 策略选择影响整个缓存流程
switch (cacheType) {
case CacheStrategy.Default: // 平衡策略
case CacheStrategy.Memory: // 速度优先
case CacheStrategy.File: // 容量优先
}这种设计确保了系统在高并发情况下的稳定性,就像高速公路的匝道控制,避免交通拥堵。
架构的扩展性设计
除了当前的场景,肯定要考虑可扩展性。
插件化的加载策略
ImageKnife通过工厂模式实现了加载策略的插件化:
ts
// 检查重复请求,避免重复下载
checkRepeatRequests(request: ImageKnifeRequest, imageSrc: string | ImageKnifeRequestSource): ImageKnifeCheckRequest | undefined {
// 如果并发请求数达到上限,加入排队队列
if (this.executingJobMap.length >= this.maxRequests && !this.executingJobMap.get(memoryKey)) {
this.jobQueue.add(request)
return
}
}这种设计让开发者可以轻松添加新的图片加载方式,比如从数据库加载、从加密存储加载等。
缓存接口的抽象化
通过IMemoryCache接口,ImageKnife为缓存实现提供了统一的抽象:
ts
export class ImageLoaderFactory {
static getLoaderStrategy(request: RequestJobRequest): IImageLoaderStrategy | null {
if (request.customGetImage !== undefined) {
return new CustomLoaderStrategy(); // 自定义加载
}
if (request.src.startsWith('http://')) {
return new HttpLoaderStrategy(); // HTTP加载
}
if (request.src.startsWith('file://')) {
return new FileSystemLoaderStrategy(); // 文件系统加载
}
// ... 其他策略
}
}这种抽象让系统可以轻松支持不同的缓存实现,比如Redis缓存、内存映射缓存等。
七、小结
通过深入分析ImageKnife的缓存策略源码,我们不仅看到了一个优秀的图片缓存系统,更看到了一个开源项目在可扩展性和设计理念上的卓越表现。
-
自定义缓存策略:实现自己的内存管理算法
-
替换核心组件:在不影响其他代码的情况下更换缓存实现
-
扩展功能:添加新的缓存特性,如缓存统计、性能监控等
不仅仅是图片。其实这样的设计,我们完全可以当做轮子,用于我们自己项目的文件管理,缓存管理等等等~拿来主义!
八、总结
没了
看这 -------------------->如果有想加入鸿蒙生态的大佬们,快来加入鸿蒙认证吧!初高级证书没获取的,点我!!!!!!!!,我真的很需要求求了!<--------------------看这