xwiki livedata
前文中我们自定义页面,让livedata去加载自动定义页面,实现实时数据展示。发现有一个问题 ,筛选的时候没有正确显示数据
1、f12 查看接口请求
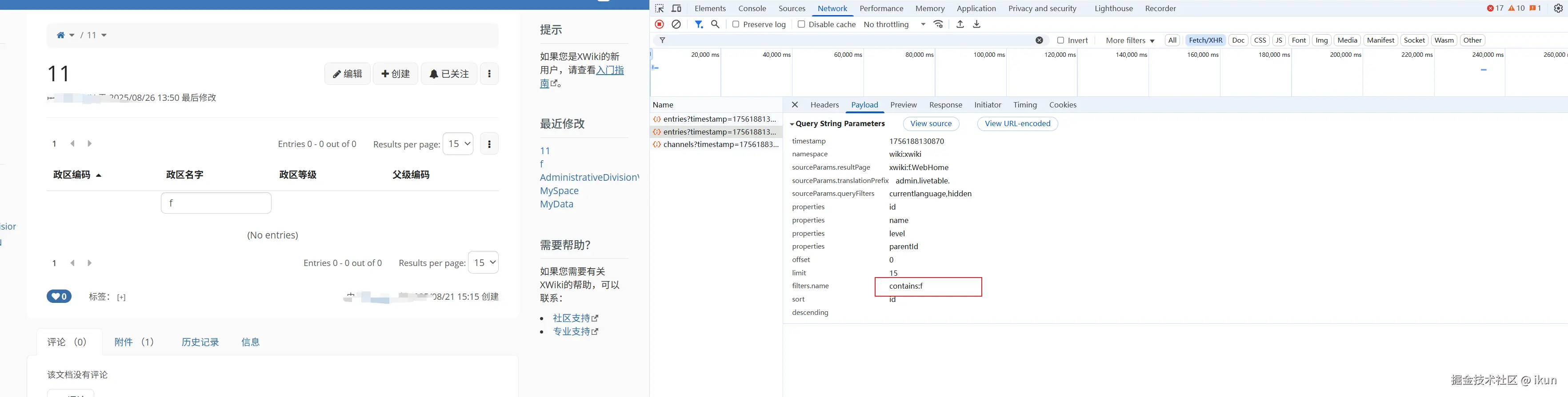
使用url解码
2.修改之前的自定义页面
java
{{groovy}}
import groovy.json.JsonOutput
import org.slf4j.Logger
import java.net.URLDecoder
// 获取 SLF4J 日志器
def logger = services.logging.getLogger("LiveTableScript")
// 设置 JSON 内容类型
if (request?.getParameter("xpage") == "plain") {
response.setContentType("application/json")
}
// 模拟数据库数据(根据之前的输出包含 8 条记录)
def all = [
[id: "620000000000000", name: "甘肃省", level: 1, parentId: "0"],
[id: "621000000000000", name: "甘肃省1", level: 1, parentId: "0"],
[id: "630000000000000", name: "青海省", level: 1, parentId: "0"],
[id: "631000000000000", name: "青海省2", level: 1, parentId: "0"],
[id: "640000000000000", name: "宁夏回族自治区", level: 1, parentId: "0"],
[id: "641000000000000", name: "宁夏回族自治区3", level: 1, parentId: "0"],
[id: "650000000000000", name: "新疆维吾尔自治区", level: 1, parentId: "0"],
[id: "651000000000000", name: "新疆维吾尔自治区4", level: 1, parentId: "0"]
]
// 处理参数
def offset = (request?.getParameter("offset") ?: "0") as int
def limit = (request?.getParameter("limit") ?: "15") as int
// 尝试多种可能的参数名并解码中文字符
def searchName = null
def rawSearch = request?.getParameter("filters.name") ?:
request?.getParameter("filter.name") ?:
request?.getParameter("name")
if (rawSearch) {
searchName = URLDecoder.decode(rawSearch.replaceFirst(/^contains:/, '').trim(), "UTF-8")
}
def sort = request?.getParameter("sort") ?: "id"
def dir = request?.getParameter("dir")?.toLowerCase() ?: "asc"
// 记录调试日志到 XWiki 日志
logger.debug("Request parameters: {}", request?.parameterMap)
logger.debug("Search value: {}", searchName)
// 过滤逻辑
def filtered = all
if (searchName) {
filtered = all.findAll { it.name.contains(searchName) }
logger.debug("Filtered results: {}", filtered)
}
// 排序逻辑
if (dir == "desc") {
filtered = filtered.sort { a, b -> -(a[sort] ?: 0) <=> (b[sort] ?: 0) }
} else {
filtered = filtered.sort { a, b -> (a[sort] ?: 0) <=> (b[sort] ?: 0) }
}
// 计算总数
def totalCount = filtered.size() ?: 0
def entries = filtered.drop(offset).take(limit)
// 构造 Live Table JSON
def result = [
totalrows: totalCount,
returnedrows: entries.size(),
offset: offset + 1,
reqNo: (request?.getParameter("reqNo") ?: "1") as int,
rows: entries.collect { entry ->
def row = [
id: entry.id,
name: entry.name,
level: entry.level,
parentId: entry.parentId,
doc_viewable: true
]
return row
}
]
// 输出 JSON
print JsonOutput.toJson(result)
{{/groovy}}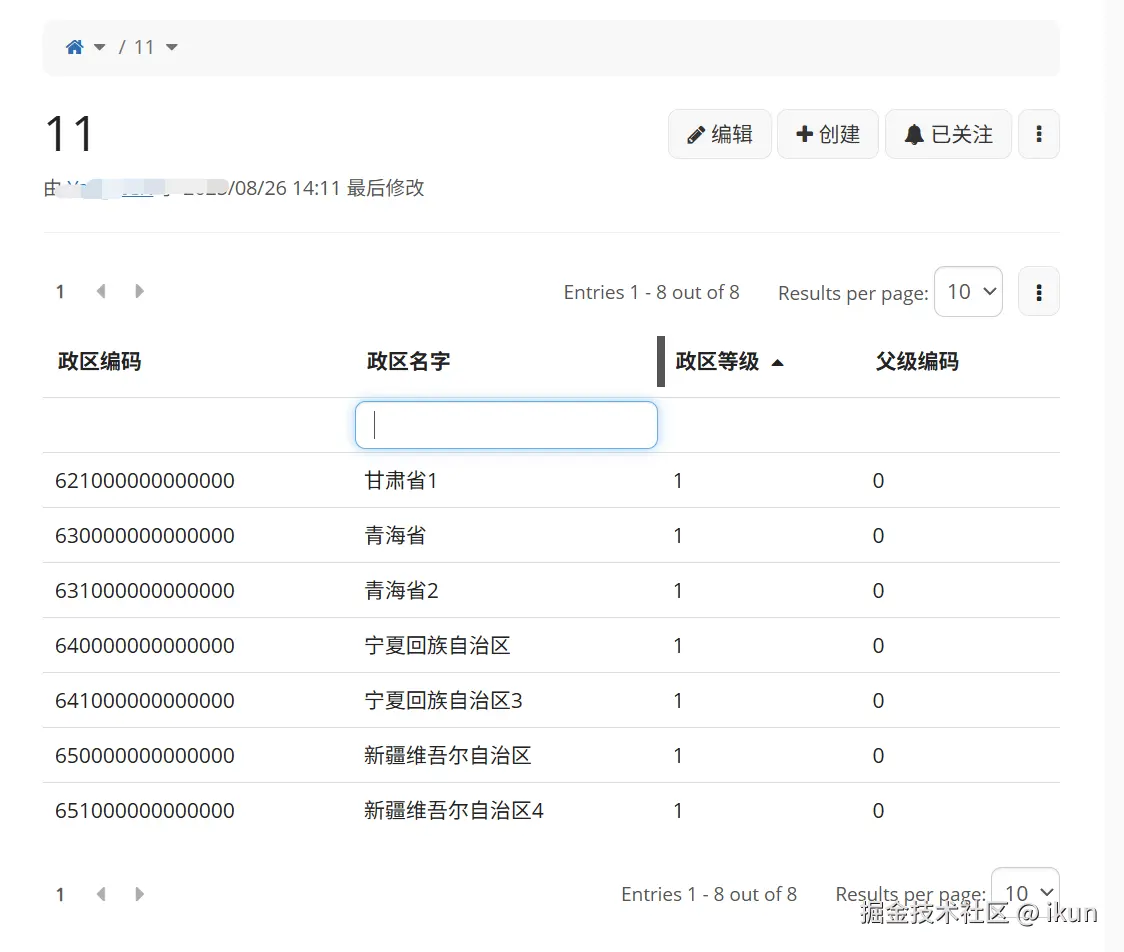
3.分页问题
这里反生了有意思问题,输入甘肃只显示其中一个。
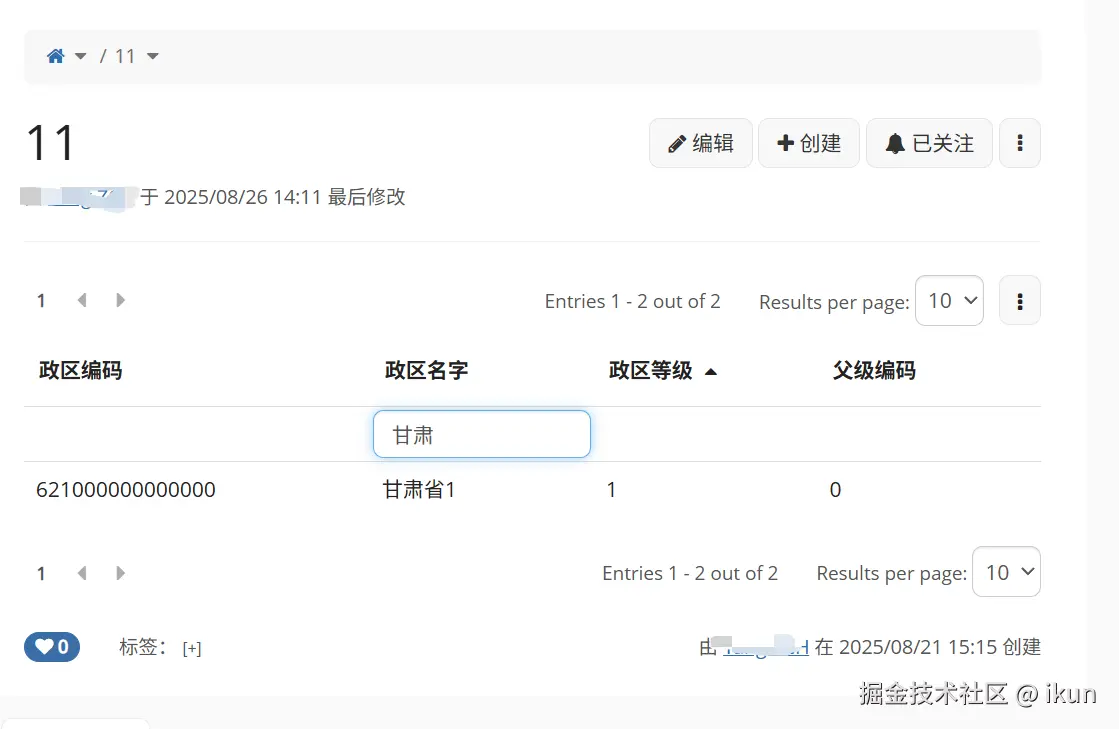
通过打印日志发现,请求的时候offset被设置为1,导致数据从1开始查询, XWiki LiveData offset 从 1 开始,这里要减 1 转换成 list 的 0 基准,修复语法
scss
{{groovy}}
import groovy.json.JsonOutput
import org.slf4j.Logger
import java.net.URLDecoder
def logger = services.logging.getLogger("LiveTableScript")
if (request?.getParameter("xpage") == "plain") {
response.setContentType("application/json; charset=UTF-8")
}
def all = [ [id: "620000000000000", name: "甘肃省", level: 1, parentId: "0"],
[id: "621000000000000", name: "甘肃省1", level: 1, parentId: "0"],
[id: "630000000000000", name: "青海省", level: 1, parentId: "0"],
[id: "631000000000000", name: "青海省2", level: 1, parentId: "0"],
[id: "640000000000000", name: "宁夏回族自治区", level: 1, parentId: "0"],
[id: "641000000000000", name: "宁夏回族自治区3", level: 1, parentId: "0"],
[id: "650000000000000", name: "新疆维吾尔自治区", level: 1, parentId: "0"],
[id: "651000000000000", name: "新疆维吾尔自治区4", level: 1, parentId: "0"]
]
// ==== 参数处理 ====
// XWiki LiveData offset 从 1 开始,这里要减 1 转换成 list 的 0 基准
def rawOffset = (request?.getParameter("offset") ?: "1") as int
def offset = rawOffset > 0 ? rawOffset - 1 : 0
def limit = (request?.getParameter("limit") ?: "15") as int
def sortField = request?.getParameter("sort") ?: "id"
def dir = request?.getParameter("descending") == "true" ? "desc" : "asc"
def rawSearch = request?.getParameter("filters.name") ?:
request?.getParameter("filter.name") ?:
request?.getParameter("name")
def searchName = rawSearch ? URLDecoder.decode(rawSearch.replaceFirst(/^contains:/, '').trim(), "UTF-8") : null
logger.debug("Request URL: {}", request?.requestURL)
logger.debug("Request parameters: {}", request?.parameterMap)
logger.debug("Raw offset parameter: {}", rawOffset)
logger.debug("Converted offset (0-based): {}", offset)
logger.debug("Limit: {}", limit)
logger.debug("Raw search parameter: {}", rawSearch)
logger.debug("Decoded search value: {}", searchName)
logger.debug("Sort field: {}", sortField)
logger.debug("Sort direction: {}", dir)
// ==== 过滤 ====
def filtered = all
if (searchName) {
filtered = all.findAll { record ->
def normalizedName = record.name.trim()
normalizedName.contains(searchName)
}
logger.debug("Filtered results: {}", filtered)
}
// ==== 排序 ====
if (filtered) {
filtered = filtered.sort { a, b ->
def valA = a[sortField] ?: (sortField == "name" ? "" : 0)
def valB = b[sortField] ?: (sortField == "name" ? "" : 0)
dir == "desc" ? -(valA <=> valB) : (valA <=> valB)
}
}
// ==== 分页 ====
def totalCount = filtered.size() ?: 0
def entries = filtered.drop(offset).take(limit)
logger.debug("Paginated entries: {}", entries)
// ==== 输出 ====
def result = [
totalrows : totalCount,
returnedrows: entries.size(),
offset : rawOffset,
reqNo : (request?.getParameter("reqNo") ?: "1") as int,
rows : entries.collect { entry ->
[ id : entry.id, name : entry.name, level : entry.level, parentId : entry.parentId, doc_viewable: true ]
}
]
print JsonOutput.toJson(result)
{{/groovy}}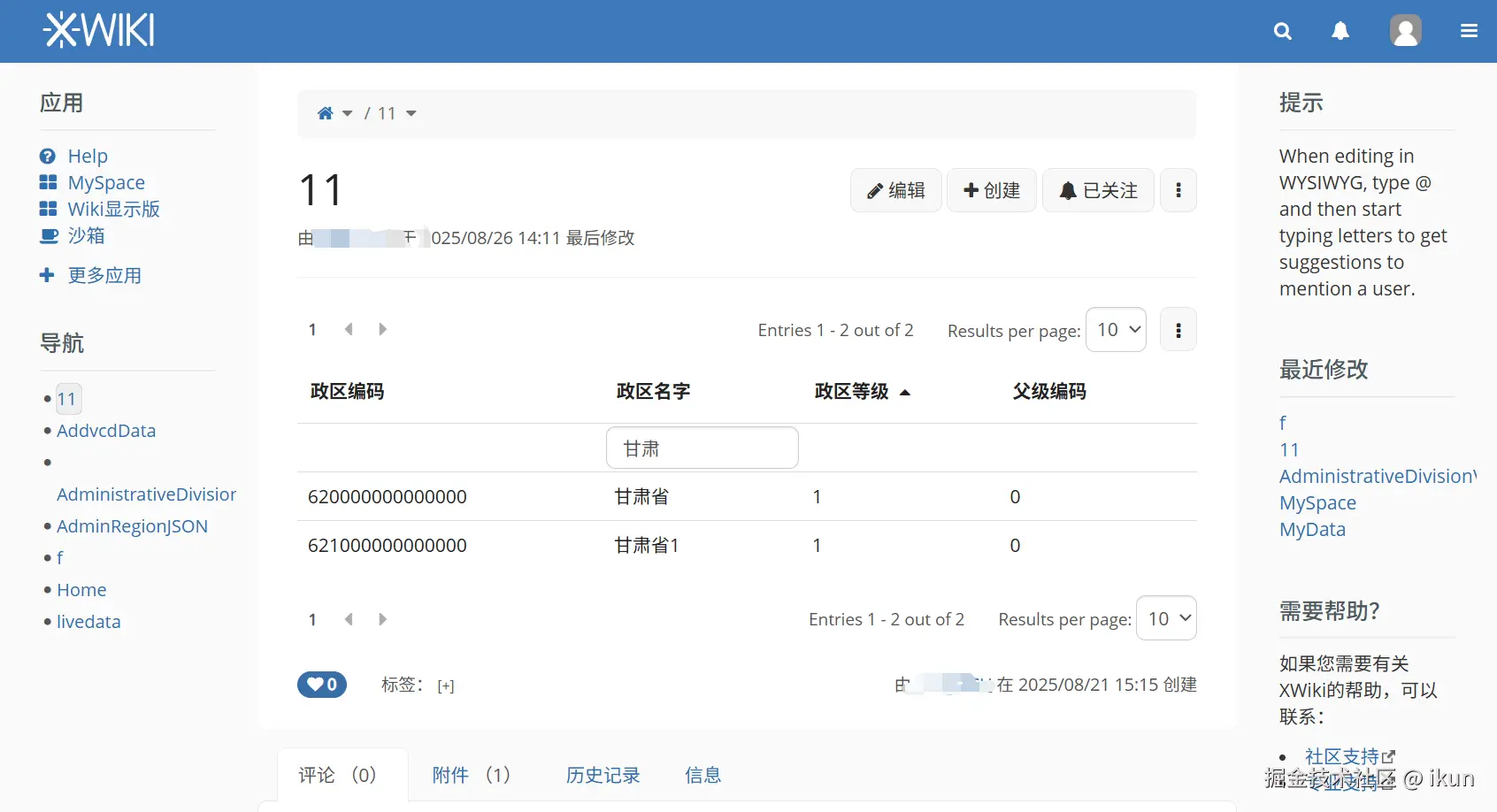
已经可以筛选和分页了,后边会接入实时数据。