3.1 算出去年每个销售的总销售额
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc(sales,orderDate,quantity,price,discount) |
| 2 | =A1.select(year(orderDate)==2024) |
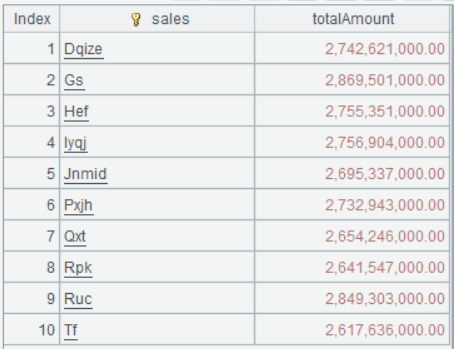
| 3 | =A2.groups(sales;sum(quantity*price*discount):totalAmount) |
A3 A2.groups(sales;sum(quantity*price*discount):totalAmount)表示将排列A2按sales分组统计聚合表达式sum(quantity*price*discount)的值,结果命名为totalAmount,函数返回由sales, totalAmount两个字段组成的序表。其功能类似于 SQL 的 "select sales, sum(quantity*price*discount) as totalAmount from A2 group by sales "。
前面章节介绍过的 sum、max、min、count、icount 等聚合函数,都可以在 groups 函数的聚合表达式中使用。
本例聚合表达式需要 sum(订单金额),订单金额由quantity*price*discount表达式算出,不需要先添加计算列,可以直接在 sum 函数中使用此表达式。
特别强调的是,分组字段和聚合表达式之间用分号来分隔,而聚合表达式和其列名之间用冒号分隔,这点和前面介绍的 derive 函数一致。
A3 的运行结果为:
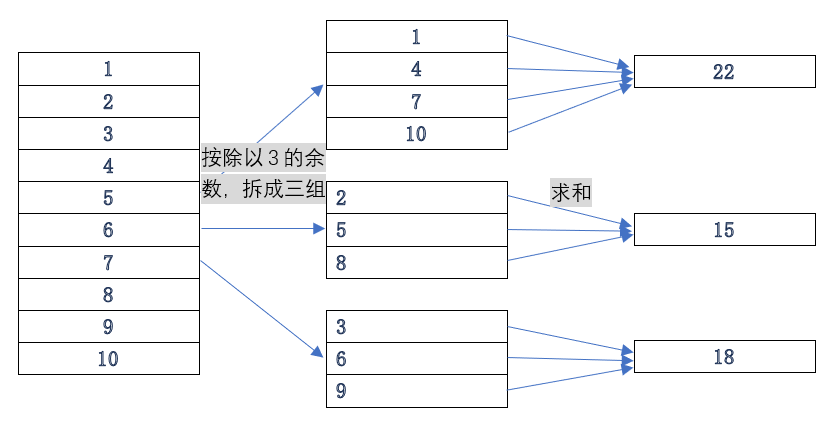
知识点:什么是分组运算?
分组运算就是把数据按某个规则分成一个个小组,再把这些小组的数据按聚合表达式进行聚合统计,如:
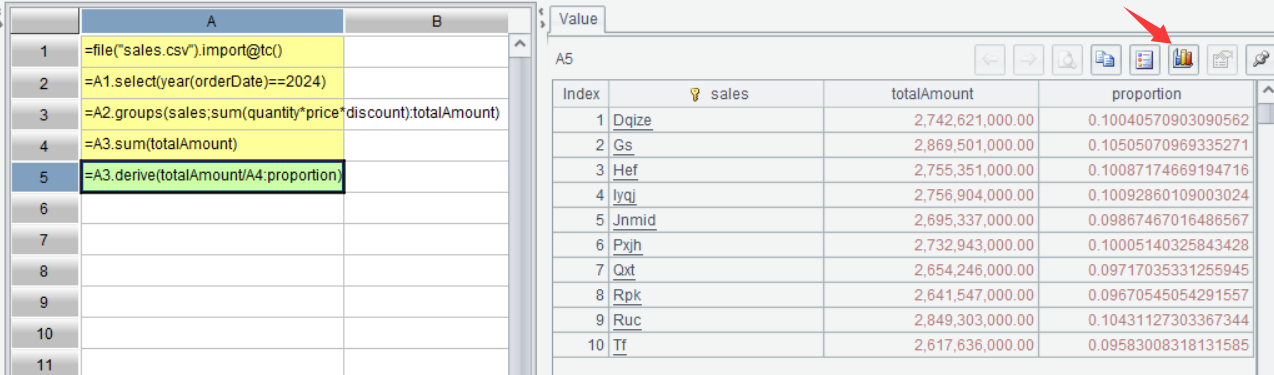
3.2 销售员贡献占比
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc(sales,orderDate,quantity,price,discount) |
| 2 | =A1.select(year(orderDate)==2024) |
| 3 | =A2.groups(sales;sum(quantity*price*discount):totalAmount) |
| 4 | =A3.sum(totalAmount) |
| 5 | =A3.derive(totalAmount/A4:proportion) |
A4 算出全年的总销售额。
A5 添加计算列,算出销售员的销售额占全年销售额的占比。
在界面上,选中 A5 单元格,在右侧的值显示栏中点 browse graphics 按钮:
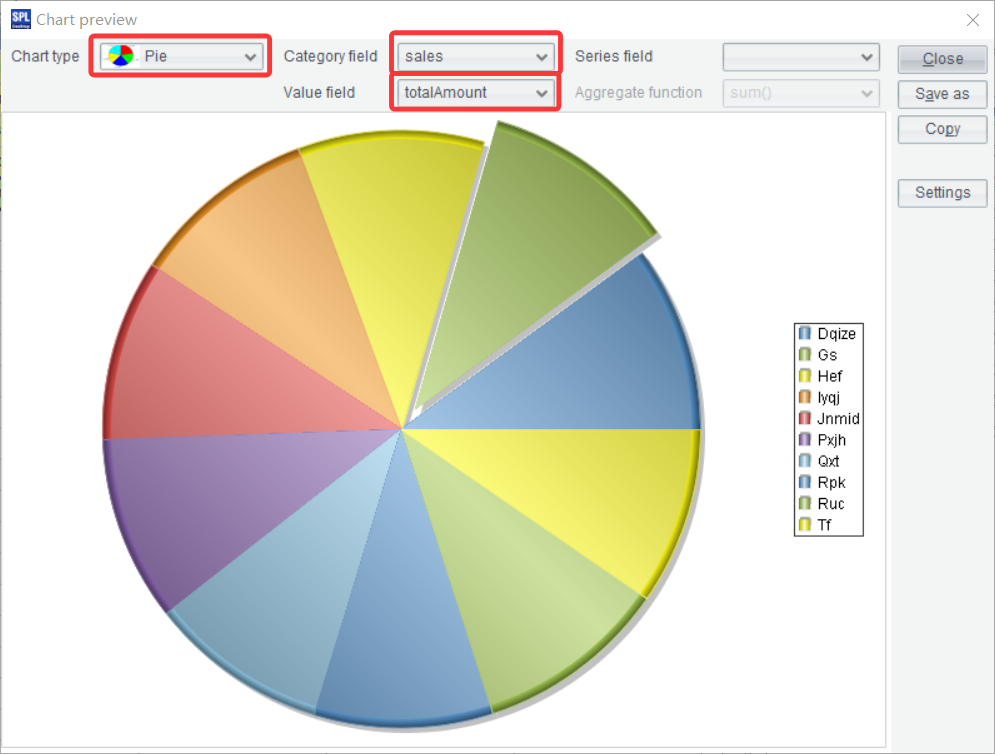
弹出界面中选择饼图,category field 选择 sales,value field 选择 totalAmount, 即可通过饼图直观显示销售员的贡献占比:
3.3 选出排名前三的销售
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc(sales,orderDate,quantity,price,discount) |
| 2 | =A1.select(year(orderDate)==2024) |
| 3 | =A2.groups(sales;sum(quantity*price*discount):totalAmount) |
| 4 | =A3.top@r(3,-totalAmount) |
A4 根据 A3 中的分组结果计算排名,返回排名前三的销售。
3.4 去年最畅销产品(按出现次数)
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc(orderDate,product) |
| 2 | =A1.select(year(orderDate)==2024) |
| 3 | =A2.groups(product;count(1):num) |
| 4 | =A3.top@r(1,-num) |
A3 按 product 分组统计销售次数。
A4 选出销售次数最多的所有产品,当只选出排名第一或倒数第一时,也可以用=A3.maxp@a(num)或minp@a,结果一样。
3.5 按年统计每个销售的总销售额、销售数量
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc(sales,orderDate,quantity,price,discount) |
| 2 | =A1.groups(year(orderDate):oYear,sales;sum(quantity):totalQuantity, sum(quantity*price*discount):totalAmount) |
A2 按多个字段分组汇总的表达式规则和单字段分组汇总差不多,多个之间用逗号分隔即可。这里需要强调的是,当分组不是按字段而是表达式时,可以直接用表达式分组,并不需要先用 derive 给序表添加计算列,如本例中的year(orderDate):oYear,表示按year(orderDate)分组,结果字段命名为oYear。
A2 的运行结果为:
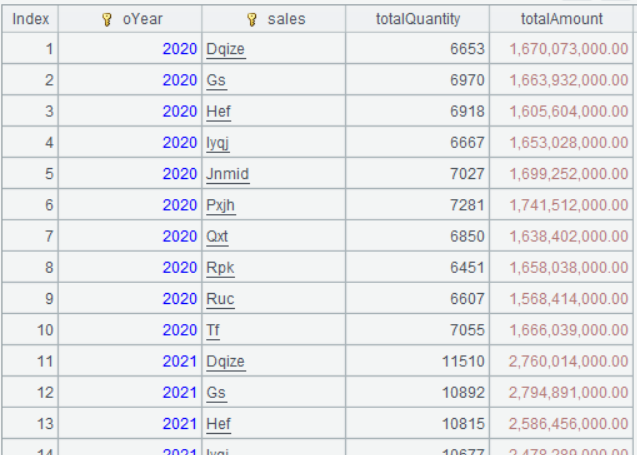
可以看出,groups 的运算结果是由分组表达式、聚合表达式组成的一个序表。
3.6 算出每一年排名前三的销售
本例的实现思路比较直观的是:先把数据按年分组,然后对着每一组的数据计算排名前三的销售。这就要求将数据分组后,能保留每一组的明细数据集合,然后才能对着这个数据集合计算排名前三。
如下图所示,红框里的就是每一组里的明细数据:
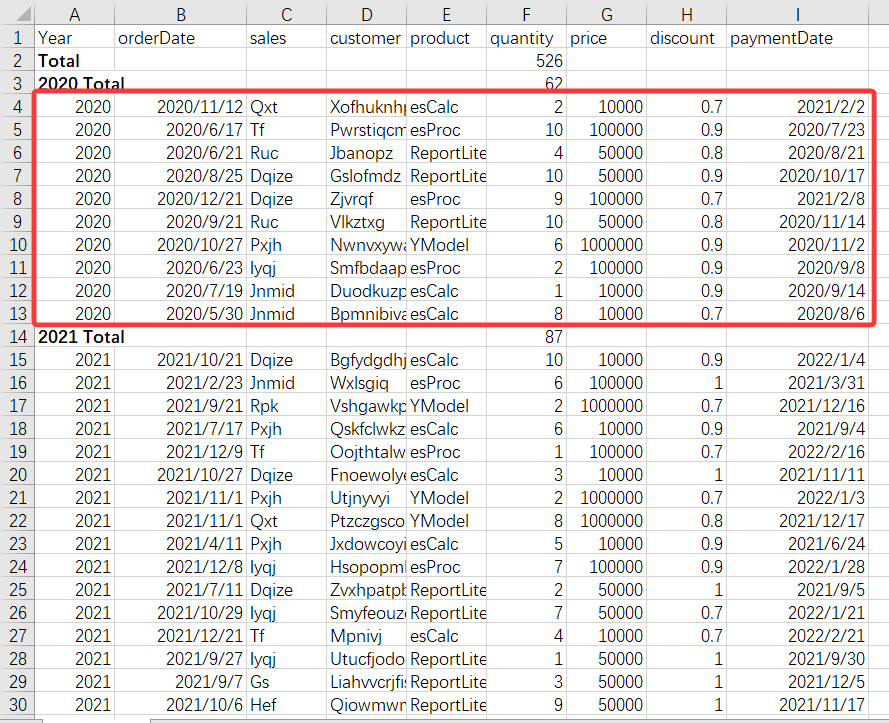
如果能够按组循环,对着每一组的明细数据做计算,那么就很容易算出每一年的排名前三。
SPL 提供了 group 函数,可以将数据分组后保留每一组的数据集合:
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc(sales,orderDate,quantity,price,discount) |
| 2 | =A1.groups(year(orderDate):oYear,sales;sum(quantity):totalQuantity, sum(quantity*price*discount):totalAmount) |
| 3 | =A2.group(oYear) |
A3 将 A2 按oYear字段分组,返回每一组的数据集合。
A2 的运行结果为:
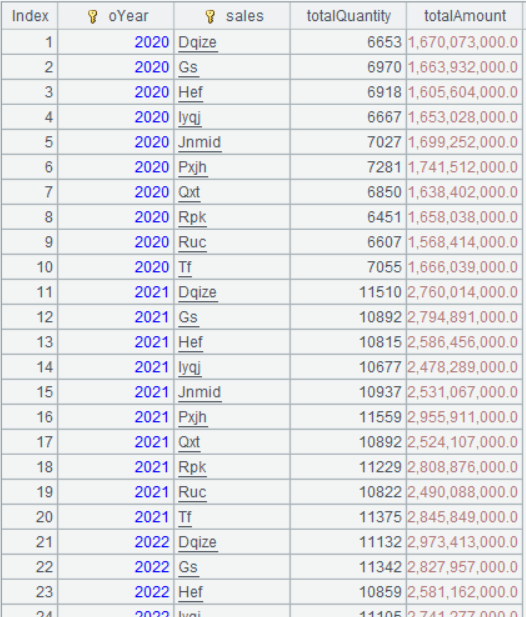
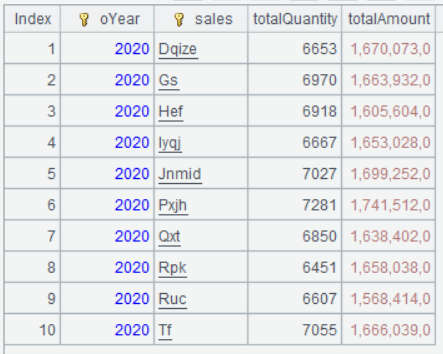
A3 的运行结果:
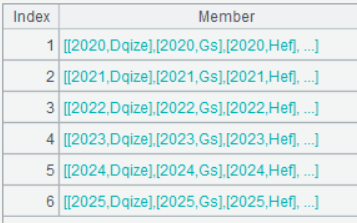
这是将数据按年分成了六组,双击任意一组,可以看到这一组的数据集合:
有了每一组的数据集合,就可以对其计算每一组的排名前三:
 |
A |
|---|---|
| 1 | =file("sales.csv").import@tc(sales,orderDate,quantity,price,discount) |
| 2 | =A1.groups(year(orderDate):oYear,sales;sum(quantity):totalQuantity,sum(quantity*price*discount):totalAmount) |
| 3 | =A2.group(oYear) |
| 4 | =A3.(~.top@r(3;-totalAmount)) |
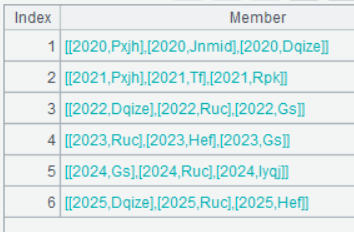
A4 A3.(~.top@r(3;-totalAmount))表示对 A3 循环计算,循环体内,~.top@r(3;-totalAmount)表示计算每一组销售额的排名前三。~ 表示 A3 当前的循环成员,因为 A3 是个组集组成的集合,因此 ~ 代表当前循环的组。
A4 的运行结果如下:
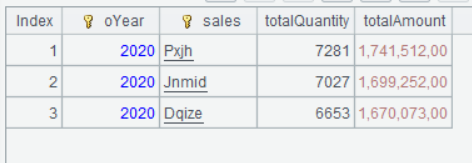
双击任意一行,可以看到该组数据的排名前三:
知识点:什么是 ~?
SPL 中,波浪号 ~ 用作当前成员引用符号。当对序列或表序列进行循环计算时,~ 表示当前正在处理的成员对象。在循环函数(如 sum() 、select() 、group() 等)中,~ 提供了对当前元素的直接引用,简化了集合运算的表达。
典型用法示例:
| A | |
|---|---|
| 1 | =1,2,3,4 |
| 2 | =A1.(~*~) |
| 3 | =file("sales.csv").import@tc() |
| 4 | =A3.select(~.quantity>5) |
| 5 | =A3.select(quantity>5) |
A2 计算 A1 序列中每个元素的平方。
A4 从 A3 中筛选出 quantity 大于 5 的记录,此写法和 A5 等同。
技术特性说明:
- 上下文绑定 :~ 的取值由当前执行的迭代上下文决定
- 动态引用 :在多层嵌套迭代中,~ 总是指向最内层循环的当前元素
- 类型多态 :~ 可以表示简单数据类型的值,也可以表示记录、序列等对象
- 表达式简写 :与字段名配合使用时可以省略,如
~.quantity可简写为quantity。之前例子都使用了这个简写形式,也就一直没有出现过 ~。
此符号的设计显著提升了 SPL 语言处理结构化数据时的简洁性和表达效率。
3.7 选出位于排名前三次数最多的销售
有了上一例的计算结果,如果想算出位于排名前三次数最多的销售,则只需要将结果合并成一个排列,再次按 sales 分组计数,返回计数值最大的记录即可:
第一步:先将每一年排名前三的数据合并成一个排列
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc(sales,orderDate,quantity,price,discount) |
| 2 | =A1.groups(year(orderDate):oYear,sales;sum(quantity):totalQuantity, sum(quantity*price*discount):totalAmount) |
| 3 | =A2.group(oYear) |
| 4 | =A3.(~.top@r(3;-totalAmount)) |
| 5 | =A4.conj() |
A5 A4.conj()表示将 A 中的组集合并成一个排列,从前面例子我们知道 A4 计算的结果是个集合的集合,那么 conj 函数将把这个二层的集合再拉平成一层的,计算结果如下:
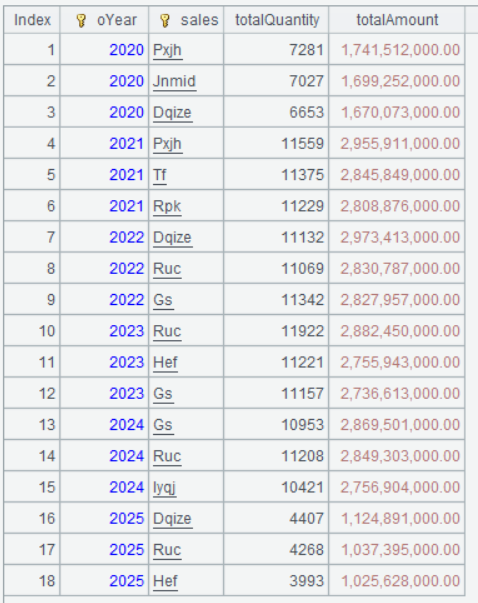
第二步:再将数据按 sales 分组计数,并选出计数值最大的记录
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc(sales,orderDate,quantity,price,discount) |
| 2 | =A1.groups(year(orderDate):oYear,sales;sum(quantity):totalQuantity, sum(quantity*price*discount):totalAmount) |
| 3 | =A2.group(oYear) |
| 4 | =A3.(~.top@r(3;-totalAmount)) |
| 5 | =A4.conj() |
| 6 | =A5.groups(sales;count(1):num) |
| 7 | =A6.maxp@a(num) |
此处 groups 和 maxp@a 的用法前面均有介绍,不再赘述。
3.8 连续三年排名前三的销售
本例比较直观的实现思路是:
将上例中每年排名前三的销售数据按销售、年份排序,然后进行计数累加,如果是同一个销售且年份递加 1,则累加值加 1,否则从 1 重新计数,最后从结果中选出累加值等于 3 的记录。
第一步:将数据按销售、年份排序:
 |
A |
|---|---|
| 1 | =file("sales.csv").import@tc(sales,orderDate,quantity,price,discount) |
| 2 | =A1.groups(year(orderDate):oYear,sales;sum(quantity):totalQuantity,sum(quantity*price*discount):totalAmount) |
| 3 | =A2.group(oYear) |
| 4 | =A3.(~.top@r(3;-totalAmount)) |
| 5 | =A4.conj() |
| 6 | =A5.sort(sales,oYear) |
第二步:添加计算列,从 1 开始计数,如果当前行的销售和上一行的销售相等且当年行的年份等于上一行的年份加 1,则计数值加 1,否则从 1 开始重新计数
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc(sales,orderDate,quantity,price,discount) |
| 2 | =A1.groups(year(orderDate):oYear,sales;sum(quantity):totalQuantity, sum(quantity*price*discount):totalAmount) |
| 3 | =A2.group(oYear) |
| 4 | =A3.(~.top@r(3;-totalAmount)) |
| 5 | =A4.conj() |
| 6 | =A5.sort(sales,oYear) |
| 7 | =A6.derive( if(sales==sales[-1] && oYear==oYear[-1]+1, cumnum=cumnum[-1]+1, cumnum=1):cumnum ) |
| 8 | =A7.select(cumnum==3) |
A7 sales[-1]表示上一行的 sales 字段值,反之若sales[1]则表示下一行的 sales 字段值。函数if(sales==sales[-1] && oYear==oYear[-1]+1, cumnum=cumnum[-1]+1, cumnum=1)表示当布尔表达式sales==sales[-1] && oYear==oYear[-1]+1为 true,则执行cumnum=cumnum[-1]+1,否则执行cumnum=1。这里 if 函数和 excel 的规则完全一致。
A8 选出 cumnum 为 3 的所有记录。
A7 的运行结果为:
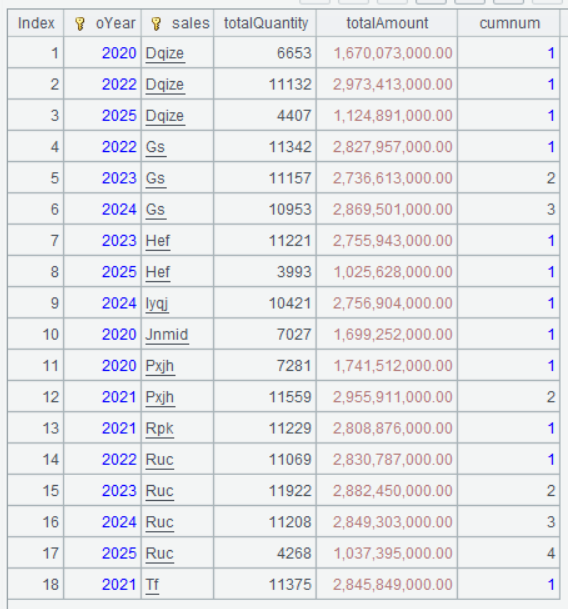
A8 的运行结果为:

这样就选出了曾经连续三年排名前三的销售
知识点:什么是 sales-1?
sales-1 表示引用当前记录的前一条记录中的 sales 字段值;相应地,sales1 表示引用当前记录的后一条记录中的 sales 字段值。这是 SPL 语言中特有的相对位置引用语法,常用于需要访问相邻记录数据的计算场景。
基本特性:
-
相对定位:基于当前记录的相对位置访问
-
动态计算:引用的具体值取决于当前处理的行位置
-
边界处理:当引用超出序列范围时 (如第一行的前一行,或最后一行的后一行),返回 null
典型应用场景
-
计算环比增长
-
查找相邻记录
-
实现滑动窗口计算
图示说明
- 示例数据表
| 月份 | sales |
|---|---|
| 1 月 | 100 |
| 2 月 | 120 |
| 3 月 | 150 |
| 4 月 | 130 |
- sales-1 和 sales1 运算过程
| 当前处理行 | sales-1 取值 | sales1 取值 | sales-1 计算逻辑 | sales1 计算逻辑 |
|---|---|---|---|---|
| 1 月记录 | null(无前一行) | 120 | 无前驱记录 | 取 2 月 sales 值 |
| 2 月记录 | 100 | 150 | 取 1 月 sales 值 | 取 3 月 sales 值 |
| 3 月记录 | 120 | 130 | 取 2 月 sales 值 | 取 4 月 sales 值 |
| 4 月记录 | 150 | null(无后一行) | 取 3 月 sales 值 | 无后驱记录 |
边界情况处理
- 首行记录:sales-1 返回 null
- 尾行记录:sales1 返回 null
- 跨组分引用:在分组计算中,相对引用不会跨组
- 多级偏移:也支持如 sales-2 (前两条记录)、sales3(后三条记录) 等写法
这种相对位置引用机制使得时间序列计算、滑动窗口分析等场景的表达式非常简洁直观。
3.9 2025 年排名前三的销售中,往前连续排前三年数最多的销售
有了上例的计算结果,只需要从 A7 中选出 2025 年中 cumnum 值最大的记录即可:
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc(sales,orderDate,quantity,price,discount) |
| 2 | =A1.groups(year(orderDate):oYear,sales;sum(quantity):totalQuantity, sum(quantity*price*discount):totalAmount) |
| 3 | =A2.group(oYear) |
| 4 | =A3.(~.top@r(3,-totalAmount,~)) |
| 5 | =A4.conj() |
| 6 | =A5.sort(sales,oYear) |
| 7 | =A6.derive(if(sales==sales-1 && oYear==oYear-1+1,cumnum=cumnum-1+1, cumnum=1):cumnum) |
| 8 | =A7.select(oYear==2025).maxp@a(cumnum) |
3.10 按订单金额分区统计
将订单金额分成大于等于 500 万,100-500 万之间,小于 100 万三类,分别统计 2024 年大中小三类订单的订单个数和总订单额
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc(sales,orderDate,quantity,price,discount) |
| 2 | =A1.select(year(orderDate)==2024).derive(quantity*price*discount:amount) |
| 3 | =A2.groups(if(amount>=5000000:"B",amount>=1000000:"M";"S"):type; count(1):oNum, sum(amount):oAmount) |
A3 将 A2 按订单金额区间分组统计。这里 if 函数的参数规则和前面介绍过的不太一致, if(amount>=5000000:"B",amount>=1000000:"M";"S")的含义是:当满足amount>=5000000时返回 "B",当满足amount>=1000000时,返回"M",否则返回"S"。相当于两层的嵌套:if(amount>=5000000,"B", if(amount>=1000000, "M","S"))。由于这种用法挺常见,所以 SPL 提供了简化的写法。
A3 计算结果为:
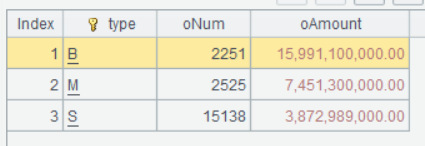
可以看出小额订单数最多,但是总销售额最小,大额订单和中额订单个数差不多,但是大额订单的总销售额远远超出中额订单。