frag里的数据哪来的
顶点阶段把想传下去的量(UV、法线、颜色、自定义 floatN...)写在带语义的输出上;
固定功能光栅器用重心坐标做透视正确插值,逐像素生成这些值,片元阶段按你声明的语义"接收"
顶点着色器唯一强制的输出 是带 SV_POSITION 的裁剪空间位置,供光栅器决定哪些像素被触发;它既可写在返回结构里,也可像示例那样用一个 out float4 ... : SV_POSITION 单独写出 。片元函数是否再"额外"要 VPOS/SV_Position 由你决定。Stack OverflowMicrosoft Learn
VPOS(像素坐标)属于系统值 ,需 Shader Model 3.0 才可用,所以 Unity 要 #pragma target 3.0;不同平台 它的底层类型不同 ,Unity 建议用 UNITY_VPOS_TYPE 做跨平台。
顶点着色器唯一强制的输出 是带 SV_POSITION 的裁剪空间位置,供光栅器决定哪些像素被触发;它既可写在返回结构里,也可像示例那样用一个 out float4 ... : SV_POSITION 单独写出。片元函数是否再"额外"要 VPOS/SV_Position 由你决定。
如下,,用out标注出来
vert()里的写法,在unity里是appdata的结构体直接引用,而这里是hlsl,但可以看到他们的相似点,核心逻辑是相同 的
cpp
v2f vert (
float4 vertex : POSITION, // vertex position input
float2 uv : TEXCOORD0, // texture coordinate input
out float4 outpos : SV_POSITION // clip space position output
)
{
v2f o;
o.uv = uv;
outpos = UnityObjectToClipPos(vertex);
return o;
}float4 v : POSITION
这表示把网格顶点位置 (输入布局里的 POSITION 属性)喂给此参数。HLSL/Unity 规定:顶点着色器的每个输入都必须带语义,否则无法从网格流里取到对应数据。Microsoft LearnUnity User Manual
struct v2f { float2 uv : TEXCOORD0; };(返回值里不含 SV_POSITION)
这就是给片元着色器的"插值数据包":把你想"插值传下去"的量(这里是 UV)标上 TEXCOORD 语义即可;光栅器会按三角形重心坐标做透视正确插值,然后片元阶段就能按同名语义接收它们。Microsoft Learn
cpp
fixed4 frag (v2f i, UNITY_VPOS_TYPE screenPos : VPOS) : SV_Target
{
screenPos.xy = floor(screenPos.xy * 0.25) * 0.5;
float checker = -frac(screenPos.r + screenPos.g);
// clip HLSL instruction stops rendering a pixel if value is negative
clip(checker);
// for pixels that were kept, read the texture and output it
fixed4 c = tex2D (_MainTex, i.uv);
return c;
}像素的屏幕坐标(VPOS)做一个"4×4 棋盘遮罩"------把一半的 4×4 像素块裁掉(clip),剩下的像素再按传入的 UV 采样主纹理输出。
screenPos.xy = floor(screenPos.xy * 0.25) * 0.5;
float checker = -frac(screenPos.r + screenPos.g);
VPOS 拿屏幕像素坐标 → 把坐标按 4×4 分箱 → 用 -frac(x+y) + clip 做出"隔块剔除"的棋盘遮罩
clip(x) 只有在 x < 0 时才会丢弃当前片元(fragment)。x == 0 或 x > 0 都不会被丢弃。等价于:if (x < 0) discard;
floor(screenPos.xy * 0.25)是像素统一的处理手段,4个像素frag时用的都是同一份的最终值
乘0.5是对整体的判断手段
之后相加必须为0,否则剔除,也就是r是0份,此时g也是0份
如果r是0.5的份,此时g是0.5份,相加也是0,可行
所以
看的出来,就是这样的交叉排布,是网格的做法而已
但这种网格的做法应该是比较常见的,因为这种跳格子的渲染状态,不会有多少变体,这种非常基础 的操作,就可以达成想要的目的----美术创造 力低了,,,,怎么提升
xxx
Face orientation: VFACE
z这个可以用来做一些效果,这是真的,对数来说,正面对着你就某种颜色,背面对着你就某种颜色
正面对着你就某种光照效果,反面则另一种,,开放性很大,,和前面那个得到具体的frag 的像素坐标值,两个的确都好像挺有扩展性的
A fragment shader can receive a variable that indicates whether the rendered surface is facing the camera, or facing away from the camera.
This feature also only exists from shader model 3.0 onwards, so the shader needs to have the #pragma target 3.0 compilation directive.
This is useful when rendering geometry that should be visible from both sides -- often used on leaves and similar thin objects. The VFACE semantic input variable will contain a positive value for front-facing triangles, and a negative value for back-facing ones.

cpp
Shader "Unlit/Face Orientation"
{
Properties
{
_ColorFront ("Front Color", Color) = (1,0.7,0.7,1)
_ColorBack ("Back Color", Color) = (0.7,1,0.7,1)
}
SubShader
{
Pass
{
Cull Off // turn off backface culling
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma target 3.0
float4 vert (float4 vertex : POSITION) : SV_POSITION
{
return UnityObjectToClipPos(vertex);
}
fixed4 _ColorFront;
fixed4 _ColorBack;
fixed4 frag (fixed facing : VFACE) : SV_Target
{
// VFACE input positive for frontbaces,
// negative for backfaces. Output one
// of the two colors depending on that.
return facing > 0 ? _ColorFront : _ColorBack;
}
ENDCG
}
}
}关于vert 的这里的写法
cpp
float4 vert (float4 vertex : POSITION) : SV_POSITION
{
return UnityObjectToClipPos(vertex);
}-
float4 vertex : POSITION输入参数:来自网格顶点缓冲的对象空间 位置属性(POSITION 语义)。 Unity User ManualMicrosoft Learn
-
: SV_POSITION(函数返回语义)告诉编译器:返回的是裁剪空间/同质坐标 中的最终顶点位置,供栅格化使用;类型必须是
float4。 Unity Documentation+1Microsoft Learn -
UnityObjectToClipPos(vertex)Unity 的内置函数,把对象空间位置变换到裁剪空间,本质等价于
mul(UNITY_MATRIX_MVP, float4(pos,1))。它既有float3也有float4的重载 ,所以把float4 vertex直接传进去没问题。 Unity Documentation+1GitHub
等价写法---
cpp
float4 vert (float4 v : POSITION) : SV_POSITION {
return UnityObjectToClipPos(v);
}
// 等价写法
struct V2F { float4 pos : SV_POSITION; };
V2F vert2 (float4 v : POSITION) {
V2F o; o.pos = UnityObjectToClipPos(v); return o;
}极简写法只输出位置 ,无法把 UV、法线等插值量传给片元阶段;若frag需要,你就必须用返回结构体并在上面标 TEXCOORDn/COLORn 等语义。Unity 文档明确建议用 TEXCOORDn 来承载自定义插值量以获得更好的跨平台兼容。
补充(URP/HDRP):在 SRP 下常用 TransformObjectToHClip(同样是"对象空间 → 齐次裁剪空间"),作用与 UnityObjectToClipPos 对应。
cpp
fixed4 frag (fixed facing : VFACE) : SV_Target
{
// VFACE input positive for frontbaces,
// negative for backfaces. Output one
// of the two colors depending on that.
return facing > 0 ? _ColorFront : _ColorBack;
}这一些节点就是为了优雅了,frame,和节点,,这些挺干扰的,一不留神就脱离现实了,做材质的图都来不及,管不上优雅,刚开始学不能优雅,粗暴一些,就是盯着某些效果想要具体实现,所以去做的
Vertex ID: SV_VertexID
A vertex shader can receivea variable thathas the "vertex number" as an unsigned integer . This is mostly useful when you want to fetch additional per-vertex data from textures or ComputeBuffers.
顶点着色器可以接收一个变量,该变量以无符号整数的形式表示"顶点编号"。这在您想要从纹理或ComputeBuffers中获取额外的每个顶点数据时非常有用。
This feature only exists from DX10 (shader model 4.0) and GLCore / OpenGL ES 3, so the shader needs to have the #pragma target 3.5 compilation directive.
此功能仅存在于DX10(着色器模型4.0)和GLCore/OpenGL ES 3中,因此着色器需要具有#pragma target 3.5编译指令。

比较有意思的点就是这个vert函数
还有经典的-1到1的映射x0.5+0.5
cpp
Shader "Unlit/VertexID"
{
SubShader
{
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma target 3.5
struct v2f {
fixed4 color : TEXCOORD0;
float4 pos : SV_POSITION;
};
v2f vert (
float4 vertex : POSITION, // vertex position input
uint vid : SV_VertexID // vertex ID, needs to be uint
)
{
v2f o;
o.pos = UnityObjectToClipPos(vertex);
// output funky colors based on vertex ID
float f = (float)vid;
o.color = half4(sin(f/10),sin(f/100),sin(f/1000),0) * 0.5 + 0.5;
return o;
}
fixed4 frag (v2f i) : SV_Target
{
return i.color;
}
ENDCG
}
}
}https://docs.unity3d.com/2021.3/Documentation/Manual/SL-ShaderSemantics.html
xxxx
https://docs.unity3d.com/2021.3/Documentation/Manual/SL-PlatformDifferences.html
The HLSL compiler is stricter than other compilers about various subtle Shader errors. For example, it doesn't accept function output values that aren't initialized properly.
Direct3D平台使用微软的HLSL着色器编译器。HLSL编译器在处理各种细微的着色器错误方面比其他编译器更为严格。例如,它不接受未正确初始化的函数输出值。
The most common situations that you might run into using this are:
使用此编译器时可能会遇到的最常见情况是:
111
A Surface Shader
vertex modifier that has an out parameter. In a surface shader, initialize the output like this:
222
Partially initialized values. For example, a function returns float4 but the code only sets the .xyz values of it. Set all values or change to float3 if you only need three values
部分初始化的值。例如,一个函数返回float4,但代码只设置了它的.xyz值 。设置所有值,或者如果只需要三个值,则更改为float3。
333
Using tex2D in the Vertex Shader. This is not valid, because UV derivatives don't exist in the vertex Shader. You need to sample an explicit mip level instead; for example, use tex2Dlod (tex, float4(uv,0,0)). You also need to add #pragma target 3.0 as tex2Dlod is a Shader model 3.0 feature.
在顶点着色器中使用tex2D。这是无效的,因为在顶点着色器中不存在UV导数。您需要采样一个显式的MIP级别;例如,使用tex2Dlod(tex,float4(uv,0,0))。您还需要添加#pragma target 3.0,因为tex2Dlod是着色器模型3.0的功能。
Some parts of the Surface Shader compilation pipeline do not understand DirectX 11-specific HLSL (Microsoft's shader language) syntax.
着色器编译管道中的某些部分不理解DirectX 11特定的HLSL(微软的着色器语言)语法。
If you're using HLSL features like StructuredBuffers, RWTextures and other non-DirectX 9 syntax, wrap them in a DirectX X11-only preprocessor macro as shown in the example below.
如果您正在使用HLSL功能,如StructuredBuffers、RWTextures和其他非DirectX 9语法,请将它们包裹在DirectX X11专用的预处理器宏中,如下例所示。
cpp
#ifdef SHADER_API_D3D11
// DirectX11-specific code, for example
StructuredBuffer<float4> myColors;
RWTexture2D<float4> myRandomWriteTexture;
#endif问题是,我怎么知道是不是非DirectX 9语法,,不是的话就用不了
"非 DirectX 9 语法"= DX10/11(Shader Model 4/5)才有的 HLSL 特性 。Surface Shader 的某些编译步骤沿用了老的 DX9 风格解析器,所以当你在 Surface Shader 里直接写 DX11 才有的类型/关键字,会报错;解决办法就是用平台宏把它们包起来。Unity 文档里举的例子正是这个意思。
看你是否用了下面这些典型 DX11/SM5 才有的东西(DX9 没有):
-
UAV/RW 对象 :
RWTexture2D/3D/*、RWStructuredBuffer、Append/ConsumeStructuredBuffer、ByteAddressBuffer、Interlocked*、AllMemoryBarrier*等。比如RWTexture2D明确要求 Shader Model 5.0+ 。Microsoft Learn -
DX10+ 的系统语义(SV_...) ,尤其是计算着色器相关:
SV_DispatchThreadID、SV_GroupID、SV_GroupThreadID等,这些只存在于 DX10/11 的模型里(DX9 没有 compute stage)。Microsoft Learn+1 -
需要提升 编译目标(#pragma target) 才能用的功能:几何/细分着色器会把目标提高到 4.x;很多基于 StructuredBuffer 的用法实际也意味着需要 4.5/5.0。Unity Documentation+1
实操判断法:看到
StructuredBuffer*/ 任何以RW*开头的资源 / 计算着色器的numthreads(...)和SV_*ThreadID,就把它们当成"非 DX9 语法"。
计算着色器会受"DX9 语法"影响吗?
**不会。**Compute Shader(.compute 文件)本身就是 DX11 风格 HLSL ,DX9 压根不支持 compute,所以不存在"兼容 DX9"的问题。Unity 文档写得很清楚:Compute Shader 用 DX11 风格 HLSL,通常需要 SM5.0 级别的硬件/后端。Unity Documentation+1dev.rbcafe.com
需要注意的是,不同后端的可用特性不同 (比如部分移动 GLES3.1 设备不支持 RWTexture3D),这属于平台能力差异,而不是 DX9 兼容性问题。Unity Forums
普通 vert/frag 或 Surface Shader
- 用到了
StructuredBuffer/RWTexture*/ 原子操作 → 加#pragma target 4.5/5.0,并在 Surface Shader 里对这些声明加#ifdef SHADER_API_D3D11(或按需扩到 D3D12/GLCore/Metal/Vulkan)。Unity Documentation+1
Compute Shader
- 放到
.compute,写#pragma kernel,必要时#pragma target 5.0,按目标平台测试功能是否可用(如 GLES3.1 的 RW3D 支持)。Unity Documentationdev.rbcafe.comUnity Forums
Provide fragment color as input
Some GPUs (most notably PowerVR-based ones on iOS) allow you to do a form of programmable blending by providing current fragment color as input to the Fragment Shader (refer to EXT_shader_framebuffer_fetch on khronos.org). This process is sometimes called framebuffer fetch.
片元着色器在运行时 读取当前帧缓冲里这个像素已有的颜色**,自己做"可编程混合(programmable blending)"。这在部分移动 GPU(尤其 iOS 上的 PowerVR、以及部分 GLES/Metal 设备)可用。
有啥用?
-
自定义混合 :不再受固定功能 Blend 的 src/dst 因子限制,你可以读到"当前颜色"再与本次输出任意计算(做 Overlay/SoftLight 之类自定义合成、特殊粒子叠加、逐像素累积等)。ImgTec DocsMedium
-
比 GrabPass 更省带宽 :传统做法是先把屏幕拷贝成纹理再采样;而 framebuffer fetch 直接从片上 tile 内存 读取当前像素,减少拷贝与显存带宽,特别利于TBDR 移动架构。URP 新文档也把这种"从帧缓冲读"的路径称作 framebuffer fetch(基于 input attachment 的等价机制)。Unity DocumentationUnity User Manual
怎么写?
核心就是把片元函数的颜色参数写成 inout,Unity 会把它绑定到当前帧缓冲颜色:
cpp
// 仅为支持 framebuffer fetch 的后端编译(GLES/GLES3/Metal)
#pragma only_renderers framebufferfetch
half4 frag(v2f i, inout half4 ocol : SV_Target)
{
// 读取:ocol = 当前帧缓冲里这个像素的颜色
// 计算:把本次想画的颜色 src 和 ocol 任意运算
half4 src = ...;
ocol = lerp(ocol, src, 0.5); // 举例:做个自定义"半混合"
return ocol; // 写回仍走正常输出
}小贴士:你仍可设置常规 Blend 状态,但读到的 ocol 是"混合前"的旧值 ;最终写回后是否再参与固定功能混合,要看你设的 Blend。通常++为避免重复混合++ ,会把 Blend 设成覆盖式(按需测试)。说明性背景见扩展规范。ImgTec Docs
能在哪些平台用 / 有啥坑?
-
可用 :iOS(Metal/PowerVR 传统上支持)、部分 Android GLES 设备(需扩展如
EXT_shader_framebuffer_fetch/ARM_shader_framebuffer_fetch)。Unity 提供#pragma only_renderers framebufferfetch来只在支持平台编译 。Unity User Manual -
不可用或不推荐:
-
Vulkan :Unity 目前没有直接启用"framebuffer fetch"语义;官方建议用 RenderPass/Input Attachment 路线实现等价能力。Unity Discussions
-
桌面 GL :没有通用的桌面等价扩展;通常要走"渲染到纹理再采样"的路径。Stack Overflow
-
-
URP 的等价做法 :URP 新版提供基于 Render Graph 的 Input Attachment (也称 framebuffer fetch),把写入与读取合并在同一渲染通道、直接用片上内存,提升移动端效率。做自定义效果时,应优先用这条路线。Unity User ManualUnity Documentation
-
移动端差异 :不同 GPU/驱动对 MSAA、多个渲染目标(MRT)、与其它采样的组合支持度各异,需按目标机型验证;ARM 的技术文章对这些限制和替代(如 Pixel Local Storage)有详细讨论。Arm Community
这么多优点为什么只在这些看上去不主流的,移动平台上可以用
"它很香,为什么桌面不用?"------并非没人用,而是桌面用不同名字/路径 (ROV、Interlock、Input Attachment),因为历史管线与内存层次决定了直接 fetch 目的颜色既不通用也未必高效 。Microsoft LearnKhronos Registry
移动端 TBR 的片上 tile 内存让"读取当前像素颜色"天然高效,所以才广泛提供 framebuffer_fetch 这类接口。ImgTec DocsPowerVR Developer Community Forums
如果你要在 Unity 里做同类效果:
-
移动端(URP/Metal/GLES) :优先用 framebuffer fetch / input attachment 的路径。Arm Community
-
桌面(DX11/12/Vulkan) :优先考虑 ROV/Interlock 或 Subpass ;没有时再退到多通道/计算着色器方案。Microsoft LearnKhronos RegistryGPUOpen
为什么移动端常见、桌面端少见?
-
移动 GPU 多为 TBR/TBDR(按瓦片渲染)
屏幕被切成小瓦片,颜色/深度都在片上tile 内存 里完成读写。这样片元着色器要读"当前像素已写入的颜色"(framebuffer fetch)既近且便宜 ,因此 ES/Metal 提供了
EXT_shader_framebuffer_fetch/MSL 的inout [[color(n)]]等能力来做"可编程混合"。ImgTec Docs+1PowerVR Graphics -
桌面 GPU 传统是 IMR(即时渲染)+ 固定功能 ROP 混合
片元着色器之后还有固定功能的混合/ROP 阶段;目标颜色常驻显存或专用缓存,片元阶段直接读"目的颜色"并不被暴露 (顺序/一致性难保证,带宽也贵)。所以历史上桌面 API 很少直接给"fetch 当前帧缓冲"的开口,而是让你用固定混合或其它机制。arXiv
-
移动端给了"直读"能力,桌面端给了"等价能力"但形式不同
桌面要做"可编程混合",通常走三条路:
-
ROV / Fragment Interlock :在像素/样本处加原子顺序保证 ,用读改写算法实现可编程混合(D3D11.3/12 的 ROV;Vulkan 的
VK_EXT_fragment_shader_interlock)。支持并不全,但这是桌面的正统做法之一。Microsoft LearnIntelKhronos Registry -
Vulkan Subpass Input Attachments :把前一子通道的颜色作为输入附件 给后一子通道读(同一 render pass 的同一像素),在瓦片内 可高效;在 IMR 上驱动可用但未必省带宽 。GPUOpenThe Khronos GroupSascha Willems
-
多通道/计算着色器方案 :把目标当纹理/图像读写,配合原子或链表等 OIT 技术;可移植但需要额外带宽/同步。Stack OverflowGitHub
-
-
平台策略差异
Apple/PowerVR 系列长期支持"framebuffer fetch"(Metal/iOS 全面可用),而很多桌面栈更推"ROV/Interlock 或 Subpass" ,不是做不到,而是用别的、更匹配桌面架构的机制 来达成同类目标。Stack OverflowChromium Issues
桌面 GPU 为啥不直接让片元着色器读"当前目标颜色"
- 在 D3D/GL 的经典桌面流水线里,片元着色器(Pixel/Fragment Shader)之后还有一个固定功能的"输出合并/混合"阶段 (微软叫 Output-Merger ,硬件里常称 ROP)。++深度/模板测试与固定功能混合都在这一步完成,不是着色器里做的++ 。也就是说,"++目标颜色"(render target 的现值)++ 通常是在固定功能阶段 里被读取与更新的,并不会作为常规输入暴露给frag着色器 。Microsoft Learn+1NVIDIA
另一层原因是一致性与顺序 :同一个像素可能同时有多个片元在并行执行。如果在片元着色器里去读"正在被更新的目标颜色",就会产生读写竞态/顺序未定义 的问题;传统 API 直接把这种"读写同一图像"的行为判为未定义/错误 (即所谓 feedback loop )。Stack Overflow
历史与架构上,桌面栈更倾向于"固定功能混合 +不暴露目标色读取",因此没有像移动端那样的"直接 framebuffer fetch"常规入口。需要可编程混合时,用专门机制来保障顺序与一致性。
桌面怎么实现"等价的可编程混合"?
桌面并非做不到,只是用不同机制来达成目标,主要有三条路:
-
ROV / Fragment Interlock(保证片元顺序的临界区)
-
ROV(Rasterizer Ordered Views) :在 D3D11.3/12 允许对 UAV 写入按像素顺序串行化,常用于可编程混合、OIT 等。Microsoft Learn+1
-
Vulkan
VK_EXT_fragment_shader_interlock:提供像素/采样级互斥与顺序保证,片元着色器可在"受保护"的临界区内读-改-写,实现自定义混合逻辑。Khronos Registry
-
-
Vulkan Subpass Input Attachments(子通道输入附件)
在同一 Render Pass 内,把前一个子通道写入的颜色作为输入附件 喂给下一个子通道的片元着色器(按同一像素坐标读取),等价于"读回上一阶段的帧缓冲内容",在瓦片内 可以很高效。Khronos Registry
-
多通道/计算着色器方案(更通用但带宽更高)
把目标当纹理/图像读写,配合原子/链表实现排序或可编程混合(OIT 等)。这种方式可移植 ,但要自己处理同步,显存带宽开销 也更大。Intel
OpenGL ES 侧,典型扩展是 EXT_shader_framebuffer_fetch 与 ARM_shader_framebuffer_fetch ,明确允许把"当前帧缓冲颜色"作为 inout 变量在片元着色器里读写,并规定了内存可见性/屏障等细节。Khronos Registry+1
xxxx
Direct3D 还有更早的 6/7/8 等版本,但现代开发主要关注 9 / 10 / 11 / 12 ,以及 11.x/12.x 的增量更新和"特性级别(Feature Level)"。微软在 D3D11 起用特性级别把不同硬件能力统一在同一 API 下(例如 9_1...12_2)
简明时间线(你需要知道的)
-
D3D9(2002) :引入 HLSL、Shader Model 2.0;9.0c(2004)带来 SM3.0。Wikipedia+1
-
D3D10(2006/2007 随 Vista) :SM4.0;取消"cap-bits",改为统一的最低硬件标准;DX10 SDK 2007 年 2 月提供。Wikipedia
-
D3D11(2009,随 Windows 7) :加入Compute Shader 、细分、改进多线程;并正式用Feature Levels 统一 9/10/11 代硬件。WikipediaMicrosoft Learn
-
D3D12(2015,随 Windows 10) :低开销、显式 API(命令列表/描述符堆等)。Wikipedia
-
D3D12 Ultimate(2020) :在 PC 与 Xbox 上统一的新"金标准",涵盖 DXR 1.1、VRS、Mesh Shader、Sampler Feedback 等。Microsoft for DevelopersWikipedia
现在该面向哪一代?(以 Steam PC 玩家作为"游戏设备市场"的代理)
-
具有 DX12 功能的 GPU 占比 ~92% ;
DX11 GPU ~0.6%,DX10 GPU ~0.4%(2025 年 7 月 Steam 硬件调查)。Steam Store
-
操作系统 :Steam 玩家中 Windows 11 ~59.9%,Windows 10 ~35.2%(两者都支持 D3D12)。Steam Store
注:Steam 调查是"PC 游戏玩家"的样本,而不是全体 PC;但对游戏/实时图形的目标人群非常有参考价值。
开发取舍(给你的结论)
-
PC/Windows 基线 :以 D3D11(SM5.0) 为最低线,覆盖面极广;
可选 D3D12 路径获取更低 CPU 开销/新特性(DXR、Mesh 等)。Microsoft LearnWikipedia -
很少再要求 DX9 ;只有在明确要兼容极老旧机器时才考虑。Steam 数据显示 DX9/DX10/纯 DX11 GPU 占比已很小。Steam Store
Depth (Z) direction differs on different Shader platforms.
DirectX 11, DirectX 12, Metal: Reversed direction
-- The depth (Z) buffer is 1.0 at the near plane, decreasing to 0.0 at the far plane.
--Clip space range is near,0(meaning the near plane distance at the near plane, decreasing to 0.0 at the far plane).
Other platforms: Traditional direction
深度(Z)缓冲区值在近平面处为0.0,在远平面处为1.0。
裁剪空间取决于具体平台:
在Direct3D-like平台上,范围是**0,远**(意味着在近平面处为0.0,在远平面处增加到远平面距离)。
在类似OpenGL的平台,范围是**-near,far**(意味着在近平面处减去近平面距离,增加到远平面处的远平面距离)。
Note that reversed direction depth (Z), combined with a floating point depth buffer, significantly improves depth buffer precision against the traditional direction. The advantages of this are less conflict for Z coordinates and better shadows, especially when using small near planes and large far planes.
这种方法的优点是Z坐标冲突更少,阴影效果更好,尤其是在使用小近平面和大远平面时。
然而,以下宏和函数会自动处理深度(Z方向)上的任何差异:
-
Linear01Depth(float z)Linear01Depth(float z) -
LinearEyeDepth(float z)LinearEyeDepth(float z) -
UNITY_CALC_FOG_FACTOR(coord)
如果您手动获取深度(Z)缓冲区值,您可能需要检查缓冲区方向。以下是一个示例:
float z = tex2D(_CameraDepthTexture, uv);
#if defined(UNITY_REVERSED_Z)
z = 1.0f - z;
#endif
深度写入 Z-Buffer 的值 ,是在顶点经过**投影矩阵 → 裁剪空间(clip) → 透视除法(NDC)**之后 得到的 Z。
不同图形 API 的 clip/NDC Z 范围不同:
-
++D3D/Metal/主机:Z ∈ 0,1 (近=0,远=1;且 Unity 在这些平台多数采用反转 Z++ ,见下)。Unity Documentation+1
-
O++penGL/ES:Z ∈ -1,1(近=-1,远=+1)++ 。Unity Documentation
Unity 文档因此会在"写不同 API 的 Shader"里专门强调 clip-space 差异,并提供宏来屏蔽平台差别。Unity Documentation
反转 Z(reversed-Z) :把"近处的深度值大、远处小"的映射灌进投影矩阵/深度测试(例如近=1、远=0),通常配合浮点深度缓冲使用。这样做有两大好处:
-
深度精度更合理 :浮点数在靠近 0 处的可表示值更密集。把"远处"映射到 0 ,整体可用精度分布会更好,减少 Z-fighting,尤其在"大远裁面 + 小近裁面"的场景。NVIDIA 的技术笔记与 Emil Persson 的文章都证明了 reversed-Z 的优势。Computergraphics and Virtual RealityNVIDIA DeveloperHumus
-
对阴影的连带好处 :阴影贴图本质也是"从光源相机渲"的深度比较 。深度精度更好→shadow acne 、抖动与"Peter-panning"需要的偏移更小、更稳定(仍需合理 bias,但更不容易出问题)。注意:**方向光(正交投影)**深度天然是线性的,reversed-Z 的改进幅度相对小;**聚光灯/点光(透视投影)**收益更明显。Unity DocumentationOgre Forums
小结:clip space 的映射决定了写入 Z-Buffer 的分布 ;反转 Z + 浮点深度 改善了分布,从而让常规渲染与阴影比较都更稳。
-
用 Unity 的宏与函数做深度方向与线性化:
-
UNITY_REVERSED_Z:平台是否使用反转 Z。Unity Documentation -
Linear01Depth(...)、LinearEyeDepth(...):把采样到的深度纹理值线性化到 0,1 或到眼空间距离;内部已考虑 D3D/GL 与反转 Z 的差异。Unity Documentation+1 -
_ZBufferParams:深度重建参数,在 Unity 5.5 起已适配反转 Z。Unity Documentation
-
-
采样相机深度图时,优先走官方 helper(内置管线:
UnityCG.cginc;URP/HDRP:各自的 ShaderLibrary)来避免方向弄反。Unity Documentation
你写入的值必须符合当前平台的深度方向:反转 Z 时,"越远越接近 0"。可以用 #if defined(UNITY_REVERSED_Z) 分支翻转。Unity Discussions
Unity 的阴影比较与 Bias 大多由引擎/管线处理,但手写 Shadow/屏幕空间阴影时:
-
正确线性化/解码深度(见 A),并按需设置 Bias / Normal Bias 来抑制 acne。Unity Documentation+1
-
方向光(正交投影)受 reversed-Z 的收益较小,更多依赖Cascaded Shadow Maps + 合理 bias 。聚光/点光的阴影更能从反转 Z 的精度里得益。Ogre Forums
如果你自己构建投影矩阵(例如无穷远平面、反转 Z),要确保与 Unity 的深度方向一致,或者同步调整深度测试/清屏值。(NVIDIA 的文章说明了 reversed-Z 与无穷远平面组合的优势与注意点。)NVIDIA Developer
-
自 Unity 5.5 起,在++多数 D3D11/12、Metal 和主机平台上,Unity 默认启用反转 Z(近=1、远=0)++ ,++配合浮点深度缓冲,以显著提升深度精度与阴影稳定性++ 。Unity Documentation+1
-
当平台使用反转 Z 时,Unity 在编译器里自动定义
UNITY_REVERSED_Z,并把_CameraDepthTexture的取值范围 设成"近=1,远=0";同时也给出Linear01Depth(...)、LinearEyeDepth(...)等函数,自动处理方向与非线性。Unity Documentation -
Unity 还会自动调整 ZTest/ZBias 的方向 以匹配反转 Z;只有你自己写原生插件时才需要手动反向 bias。Unity Documentation
Unity 能"干涉"API 的空间转换规则吗?
-
不能改变 API 的约定 (比如 D3D 的
[0,1]、OpenGL 的[-1,1]),这些是驱动/后端决定的。Unity能做的是:-
按平台生成合适的投影矩阵与深度测试方向(是否反转 Z);
-
在 Shader 端提供统一的宏与函数 ,让你不用关心各家后端差异。Unity Documentation
-
-
有的后端(如很多 GL/GLES/WebGL 目标)并不使用反转 Z ,Unity 就沿用传统方向;这类平台差异也体现在是否定义
UNITY_REVERSED_Z。Unity Discussions+1
不要硬编码"近=0/远=1"或手写反转;统一用:
-
UNITY_REVERSED_Z判断方向; -
Linear01Depth(z)/LinearEyeDepth(z)做线性化; -
_ZBufferParams做深度重建(URP/HDRP 也有对应 helper)。Unity Documentation+1
自定义投影矩阵是在 C#(脚本/渲染管线)里改,不是在 shader 里改。
剔除、深度、阴影等一系列流程都基于相机的投影矩阵进行,只有把矩阵设给相机/渲染命令,CPU 与 GPU 的视锥才一致;
单纯在 shader 里改只会影响该材质下的顶点变换,容易跟引擎侧剔除/深度不一致而出问题。
直接改相机(最常见)
-
设定:camera.projectionMatrix = yourMatrix
;这是"从++世界→裁剪空间"的 4×4 矩阵++ 。改了以后,FOV/near/far 就不再自动驱动相机投影了,++恢复默认要调用
ResetProjectionMatrix()++ 。Unity Documentation+1
-
平台适配(++Y-flip、反转 Z 等++ ):把你算好的投影矩阵再过一遍
++GL.GetGPUProjectionMatrix(yourMatrix, renderIntoTexture)++ ,它会转换成当前后端实际要用的 GPU 投影(和++shader 里的UNITY_MATRIX_P对齐++ )。Unity Documentation -
典型特例:做"斜切近裁剪面/水面裁剪"时,可用
Camera.CalculateObliqueMatrix(clipPlane)直接生成一个斜切投影矩阵 再赋给projectionMatrix。Unity Documentation+1
放在哪里改?把代码挂在相机上,在 OnPreCull 或更早阶段(确保剔除用的是你改后的矩阵)里设置;停用脚本或切回默认时调用
ResetProjectionMatrix()。StålhandskeUnity Documentation
(仅内置渲染管线)在 CommandBuffer 里临时设定
- 可在命令缓冲中调用
CommandBuffer.SetViewProjectionMatrices(view, proj),只对这段绘制生效;注意 官方写明该 API 与 URP/HDRP 不兼容。Unity Documentation
URP/HDRP(SRP)里的做法
- 不要用上面的 CommandBuffer 接口;若只是读取 "当前相机用于 GPU 的投影矩阵"(包含 y-flip、反转 Z、抖动等),URP 提供
CameraData.GetGPUProjectionMatrix()。若要真正改相机的投影 ,仍然走第 1 种方式改Camera.projectionMatrix(或实现自定义 Renderer/Pass,确保剔除和绘制一致)。Unity Documentation
反转 Z / 平台差异要点
-
Unity 在很多平台启用了反转 Z 并用宏和帮助函数屏蔽差异(
UNITY_REVERSED_Z、Linear01Depth等)。当你自己构建投影 时,先算"几何意义上的投影矩阵",再交给GL.GetGPUProjectionMatrix做平台转换即可;URP 里对应CameraData.GetGPUProjectionMatrix()。Unity Documentation+2Unity Documentation+2 -
反转 Z 配合浮点深度能显著优化深度精度;对阴影深度比较的稳定性也有帮助(bias 更容易收敛)。想做"无穷远平面 + 反转 Z"时,可参考 NVIDIA 的技术说明。NVIDIA Developer
什么时候不要在 shader 里改?
- 你当然可以把自定义投影矩阵作为
uniform传进 shader,然后用mul(P, mul(V, mul(M, v)))自己算SV_POSITION。但CPU 侧剔除、阴影、深度预通道 仍按相机默认投影执行,会出现"被剔除了但还在画 / 没剔除却不在画 / 深度冲突"等问题------除非你的效果就是刻意"欺骗投影"的屏幕后处理/特效。推荐仅在实验性/特定通道这样做。(Unity 也在文档强调:改变projectionMatrix后需要你自己负责对应参数一致性。)Unity Documentation
cpp
using UnityEngine;
[RequireComponent(typeof(Camera))]
public class CustomProjection : MonoBehaviour
{
public float fov = 60f, near = 0.1f, far = 1000f;
Camera cam;
void OnEnable() { cam = GetComponent<Camera>(); }
void OnPreCull()
{
// 1) 先按数学意义构建投影(可替换为自定义/斜切/无穷远等)
var P = Matrix4x4.Perspective(fov, cam.aspect, near, far);
// 2) 交给 Unity 适配到当前 GPU 后端(含 y-flip / 反转Z 等)
var gpuP = GL.GetGPUProjectionMatrix(P, cam.targetTexture != null);
// 3) 应用到相机
cam.projectionMatrix = gpuP;
}
void OnDisable() { if (cam) cam.ResetProjectionMatrix(); }
}-
Camera.projectionMatrix/ResetProjectionMatrix是官方通道; -
GL.GetGPUProjectionMatrix保证和 shader 里的UNITY_MATRIX_P一致。Unity Documentation
"谁规定每个阶段该做什么、该输出什么 "。答案很简单:
图形 API 规范(D3D/OpenGL/Vulkan)+ GPU 硬件管线规定了每个阶段的"契约"。Unity 只是把这些契约打包成统一接口,并把矩阵传给你的 shader。
GPU(图形处理器)硬件管线是指GPU处理图形数据和执行大规模并行计算的流水线化过程。
它包含多个专门的硬件单元,++按顺序执行渲染或计算任务的各个阶段,通过并行处理能力和专门的架构,能够高效地完成像素着色、纹理映射等图形相关任务++,以及深度学习和AI所需的计算密集型工作。
GPU 硬件管线的关键组成和流程:
- 几何处理阶段(Geometry Processing):
- 顶点处理(Vertex Processing)::将3D模型的数据(顶点坐标、颜色等)从模型空间转换到屏幕空间,进行缩放、旋转和位移等操作。
- 几何着色器(Geometry Shader)::处理和生成几何图元(如三角形、线条、点),有时用于动态增加或修改模型。
- 光栅化阶段(Rasterization):
- 将三维几何图形转换为二维屏幕上的像素网格。
- 三角形设置(Triangle Setup)::计算构成三角形的每个像素的属性。
- 像素填充(Pixel Filling)::根据三角形的边界填充内部的像素,确定每个像素的颜色。
- 像素处理阶段(Pixel Processing):
- 像素着色器(Pixel Shader/Fragment Shader)::为每个像素计算最终的颜色,执行复杂的颜色混合和纹理查找等操作。
- 深度测试和模板测试::根据深度缓冲和模板缓冲的信息,确定哪些像素是可见的,哪些被遮挡。
- 输出和混合阶段(Output and Blending):
- 将计算出的像素颜色写入帧缓冲区。
- 输出混合(Output Merging)::将新计算出的像素颜色与帧缓冲区中已有的像素颜色进行混合,处理透明度和Alpha 混合等问题。
为何使用硬件管线?
并行处理能力:
GPU拥有数千个内核,可以同时执行管线中多个阶段的相同任务,大大提高了处理效率。
专用硬件:
每个阶段都有专门的硬件单元,执行特定的任务,比通用的CPU更高效。
流水线优化:
将复杂的图形处理任务分解成一系列小的、相互独立的步骤,并允许它们在硬件中连续流动,减少等待时间。
总而言之,GPU硬件管线是一个高度优化的、并行化的计算流程,专为高效处理大量图形数据和计算密集型任务而设计。
阶段边界与必须/允许的输入输出由 API 规范决定 ;你写 shader 必须满足这些语义与数据格式(例如 VS 必须提供 SV_Position)。你当然能"怎么变换都行",但最后必须 把位置输出为 clip space 的 SV_POSITION,否则光栅器无法继续
光栅器 :做裁剪、插值、决定哪些像素要执行像素着色器;它是固定功能接口,连接 VS 和 PS。Microsoft GitHub
"空间转换"谁来定?我能改吗?
-
引擎(Unity/C#)决定 相机的投影矩阵/视图矩阵,并把它们作为常量传进 shader。你在 VS 里通常做
SV_POSITION = mul(UNITY_MATRIX_VP, mul(UNITY_MATRIX_M, v))。 -
你可以改:
-
局部(仅此材质/网格):在 VS 自己用自定义矩阵乘法(骨骼变形、顶点动画、屏幕扭曲等)。这只影响 GPU 顶点→像素的结果,不会改变 CPU 侧剔除与其他相机计算。
-
全局(整个相机都生效):在 C# 改
camera.projectionMatrix,并用GL.GetGPUProjectionMatrix适配到底层后端的 NDC/反转 Z 规则;这样 VS、光栅器、剔除、阴影都保持一致。Unity Documentation+2Unity Documentation+2
-
只在 shader 里"私自更改投影"的副作用:CPU 侧仍按原相机做剔除/阴影分配,可能出现"该画的不画/不该画的画了"的不一致。因此全局投影一定在 C# 相机层改 。Unity Documentation
为什么 Unity 老提"clip space / 反转 Z(reversed-Z)"?
-
因为不同 API 的 NDC Z 范围不同(GL -1,1,D3D/Vulkan 0,1),而 Unity 要跨平台统一。
-
Unity 在很多平台默认启用反转 Z (近=1 远=0,配合浮点深度),以显著提升深度精度与阴影稳定性;并提供宏/函数帮你不用关心方向:
-
UNITY_REVERSED_Z(是否反转) -
Linear01Depth/LinearEyeDepth(把采样的深度纹理正确线性化) -
_ZBufferParams(深度重建参数)这些都已按不同后端自动处理。Unity Documentation
-
你能控制(shader 里):
-
顶点如何从对象/世界空间变到 clip(可用自定义矩阵、皮肤、扭曲等),但必须 输出
SV_POSITION。Unity Documentation -
像素如何合成颜色,是否写
SV_Depth覆盖深度。Microsoft Learn
你不能控制(或不应在 shader 里改):
-
阶段职责与数据流(VS→Raster→PS→OM),这是 API/驱动规定的。Microsoft GitHub
-
NDC 深度范围、反转 Z 的平台策略(Unity 统一后在 shader 通过宏感知即可)。Unity Documentation
-
相机全局投影/剔除使用的矩阵------要在 C# 改,并用
GL.GetGPUProjectionMatrix取得与 shader 中UNITY_MATRIX_P一致的 GPU 投影矩阵。Unity Documentation
一张"责任分界速查"
-
API 规范 :定义每个阶段的契约 (VS 必须给
SV_POSITION、PS 输出SV_Target/SV_Depth;GL/VK/D3D 的 NDC Z 范围等)。Microsoft LearnMediumKDAB -
Unity 引擎 :选择是否反转 Z,构造投影/视图矩阵,提供跨平台宏/函数(
UNITY_REVERSED_Z/Linear01Depth/_ZBufferParams),并把矩阵以常量传给 shader。Unity Documentation -
你的 shader(VS/PS) :在这些契约内完成"位置变换与像素计算"。想改全局投影 → 去 C#;想做局部几何/屏幕扭曲 → 在 VS/PS 做即可(但接受剔除差异的后果)。Unity Documentation
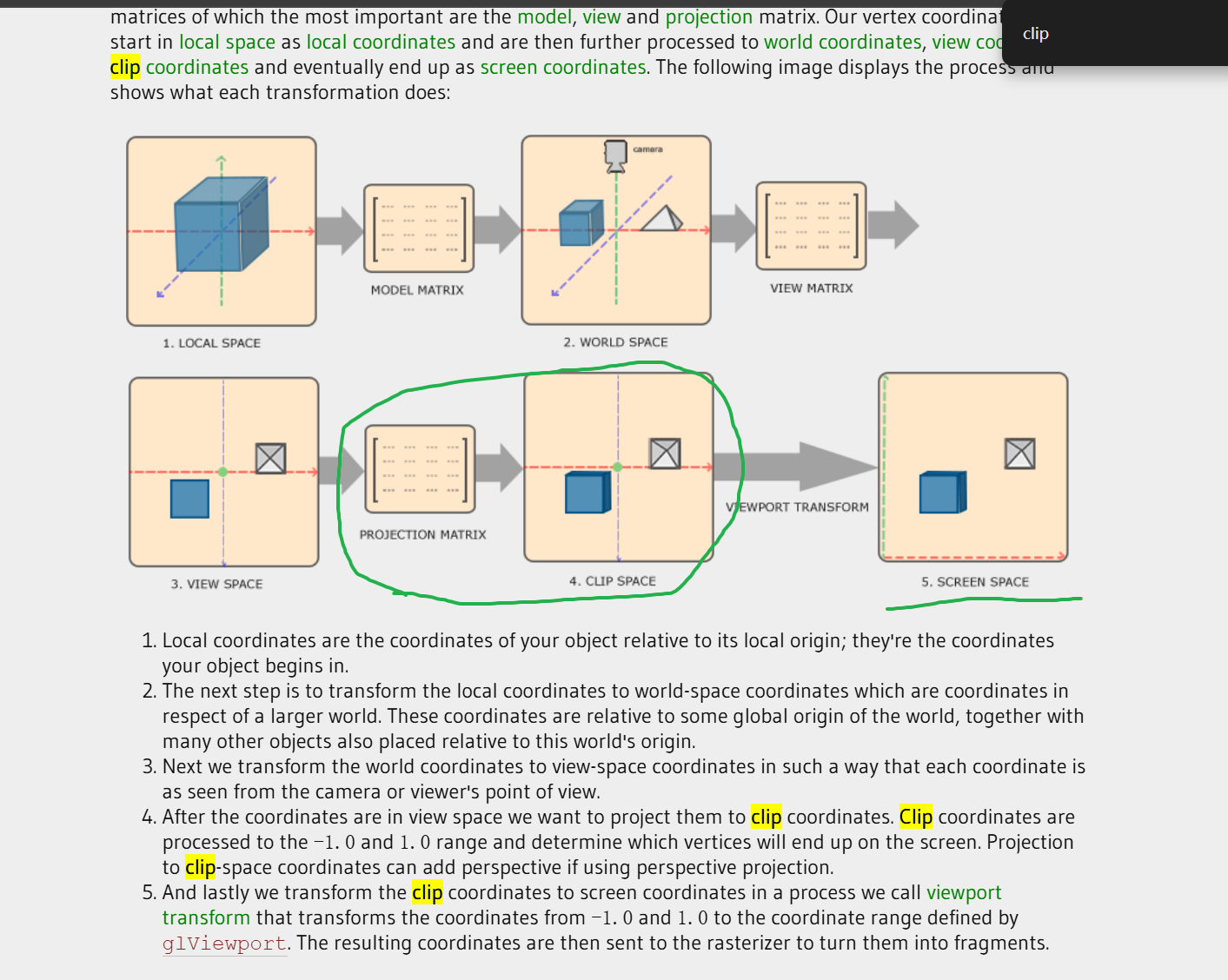
The reason we're transforming our vertices into all these different spaces is that some operations make more sense or are easier to use in certain coordinate systems.
For example, when modifying your object it makes most sense to do this in local space , whilecalculating certain operations on the object with respect to the position of other objects makes most sense in world coordinates and so on.
If we want, we could define one transformation matrix that goes from local space to clip space all in one go, but that leaves us with less flexibility.
At the end of each vertex shader run, OpenGL expects the coordinates to be within a specific range and any coordinate that falls outside this range is clipped. Coordinates that are clipped are discarded, so the remaining coordinates will end up as fragments visible on your screen.
This is also where clip space gets its name from.