摘要 :未来预测对于大语言模型(LLM)智能体而言是一项复杂任务,它要求智能体具备高度的分析思维、信息收集、情境理解能力,以及在不确定性环境下进行决策的能力。智能体不仅要收集并解读海量动态信息,还需整合多样化数据源、权衡不确定性因素,并根据新兴趋势调整预测,这与人类专家在政治、经济和金融等领域的做法如出一辙。尽管未来预测至关重要,但目前尚无针对智能体未来预测能力的大规模基准测试,这主要归因于处理实时更新和获取及时准确答案所面临的挑战。为解决这一问题,我们推出了FutureX------一个专为执行未来预测任务的大语言模型智能体设计的动态实时评估基准测试。FutureX是当前规模最大、多样性最丰富的未来预测实时基准测试,支持每日实时更新,并通过自动化的问题收集和答案汇总流程避免数据污染。我们对25个大语言模型/智能体模型进行了评估,这些模型具备推理、搜索能力,并集成了外部工具,包括开源的深度研究智能体(Deep Research Agent)和闭源的深度研究模型(Deep Research models)。这一全面评估旨在检验智能体在动态环境中的适应性推理和性能表现。此外,我们还深入分析了智能体在未来导向任务中的失败模式和性能缺陷,包括其对虚假网页的脆弱性以及时间有效性问题。我们的目标是建立一种动态、无污染的评估标准,推动开发出能够在复杂推理和预测思维方面达到专业人类分析师水平的大语言模型智能体。Huggingface链接:Paper page,论文链接:2508.11987
研究背景和目的
研究背景:
随着大型语言模型(LLMs)的快速发展,其在自然语言处理(NLP)领域的应用日益广泛,尤其是在需要复杂分析和推理的任务中,如未来预测。未来预测作为LLMs的一个重要应用场景,要求模型具备高水平的信息收集、情境理解、分析和决策能力。然而,现有的基准测试方法在评估LLMs进行未来预测时面临诸多挑战,主要包括以下几个方面:
- 实时性要求:未来预测需要模型能够处理和整合实时更新的信息,而传统基准测试往往使用静态数据集,无法反映模型处理动态信息的能力。
- 数据污染问题:使用历史数据进行评估时,模型可能已经通过训练数据"见过"这些信息,导致评估结果不准确。
- 评估方法的局限性:传统基准测试主要关注模型的静态知识,而忽视了模型在动态环境中的规划、工具使用和适应能力。
为了应对这些挑战,研究者们提出了一系列新的基准测试方法,如AgentBench、WebArena和GAIA等,这些基准测试通过模拟环境或高保真网站来评估LLMs的推理、多模态、网络浏览和工具熟练度等能力。然而,这些基准测试仍然主要关注静态、定义明确的问题,无法全面评估模型在处理动态、实时信息并进行复杂分析的能力。
研究目的:
本研究旨在解决现有基准测试在评估LLMs进行未来预测时的不足,提出一个动态、实时的评估基准FutureX。具体目标包括:
- 构建大规模、多样化的实时基准:FutureX将从195个高质量网站上收集未来导向的问题,支持每日实时更新,确保评估的时效性和准确性。
- 消除数据污染:通过专注于未来事件,FutureX确保模型在预测时无法利用历史信息,从而避免数据污染问题。
- 全面评估LLMs的适应性和推理能力:FutureX将评估模型在动态环境中的信息收集、整合、分析和预测能力,为模型开发者提供详细的反馈和改进方向。
- 推动LLMs在专业领域的应用:通过建立一个无污染、动态的评估标准,FutureX旨在推动LLMs在复杂推理和预测性思维方面达到人类专业分析师的水平。
研究方法
1. 基准构建:
FutureX的构建过程包括四个主要阶段:事件数据库构建、未来事件每日整理、模型每日预测和答案每日获取。
- 事件数据库构建:从2008个网站中筛选出195个高质量网站,覆盖政治、经济、金融、科技、体育和娱乐等多个领域。这些网站将作为未来事件的问题来源。
- 未来事件每日整理:每日从128个网站上收集未来导向的问题,通过模板生成和随机化处理,生成约500个每日和每周的未来事件作为候选问题。同时,对事件进行过滤,去除简单、有害和主观的问题。
- 模型每日预测:在每个事件的开始日期,自动运行各种LLMs进行预测,并存储其预测结果。
- 答案每日获取:在事件的解决日期之后,自动从网络上抓取真实结果,并评分模型的预测。
2. 评估协议:
FutureX采用了一套详细的评估协议,包括评估延迟、缺失预测处理和评估指标。
- 评估延迟:由于未来预测的答案在预测时未知,FutureX采用一周的预测窗口,以平衡事件覆盖范围和评估及时性。
- 缺失预测处理:对于模型未能提供预测的情况,FutureX通过增加总测试样本量来减少标准差的影响,确保评估的稳定性。
- 评估指标:根据问题类型,FutureX采用不同的评估指标,如0-1误差、F1分数、部分信用和相对波动性等。
3. 模型选择:
FutureX评估了25个不同的LLMs,包括基础LLMs、具备搜索和推理能力的LLMs、开源深度研究代理和闭源深度研究代理。这些模型代表了不同层次的能力,从基本预测到复杂分析和推理。
研究结果
1. 整体性能:
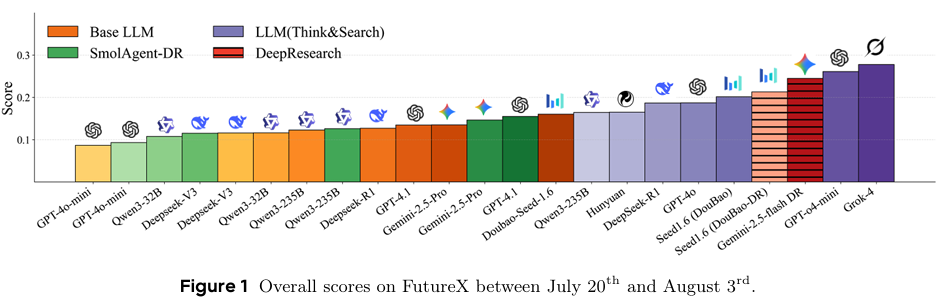
在25个评估模型中,Grok-4在整体性能上表现最佳,其次是Gemini-2.5-flash Deep Research和GPT-o4-mini(Think&Search)。基础LLMs在简单任务上表现良好,但在复杂任务上表现较差。具备搜索和推理能力的模型在复杂任务上表现显著优于基础LLMs,突显了工具增强推理的重要性。
2. 难度层级分析:
FutureX将问题分为四个难度层级:基础、广泛搜索、深度搜索和超级代理。实验结果表明,随着难度增加,模型性能显著下降。基础层级的问题主要涉及简单的事实回忆和基本推理,大多数模型都能取得较高准确率。广泛搜索层级的问题要求模型提供所有正确选项,性能下降主要源于遗漏正确答案或包含错误答案。深度搜索和超级代理层级的问题涉及开放式的排名和数值预测,要求模型进行多步搜索和推理,性能下降更为显著。
3. 领域特定表现:
不同模型在不同领域表现出不同的优势。例如,GPT模型在加密货币和技术领域表现优异,而DouBao-Seed1.6-Thinking在金融经济和商业公司领域表现突出。搜索增强的推理在信息驱动的领域(如文化和媒体、技术)中显著提高了性能。
4. 人类与模型对比:
通过与40名行业专家进行对比,研究发现人类专家在基础、深度搜索和超级代理层级的问题上显著优于LLMs。尽管LLMs在某些任务上已经展现出接近人类的表现,但在整体复杂推理和预测能力上仍有较大差距。
研究局限
尽管FutureX在评估LLMs进行未来预测方面展现出了显著优势,但本研究仍存在一些局限性:
- 数据覆盖的有限性:尽管FutureX覆盖了195个高质量网站,但仍可能无法涵盖所有未来可能发生的事件和领域。未来研究需要进一步扩展数据源,提高基准的全面性。
- 评估延迟的权衡:FutureX采用一周的预测窗口以平衡事件覆盖范围和评估及时性,但这可能引入一定的延迟。未来研究可以探索更短的预测窗口,以提高评估的实时性。
- 模型规模的局限性:本研究的实验主要在中型规模的模型上进行,未来研究需要在大规模模型上验证FutureX框架的有效性和可扩展性。
- 对抗性攻击的考虑:本研究未充分考虑对抗性攻击对模型预测的影响。未来研究需要探索模型在面对对抗性攻击时的鲁棒性,确保评估结果的可靠性。
未来研究方向
针对上述研究局限,未来的研究可以从以下几个方面展开:
- 扩展数据覆盖范围:进一步扩展FutureX的数据源,增加更多领域和类型的事件,提高基准的全面性和多样性。同时,探索多语言和多模态内容的融入,提高框架的适用性和灵活性。
- 优化评估延迟:研究更短的预测窗口对评估结果的影响,探索实时评估的可行性和准确性。同时,开发更高效的自动化评估流程,减少人工干预,提高评估效率。
- 在大规模模型上验证框架有效性:在大规模模型上验证FutureX框架的有效性和可扩展性,探索其在处理更复杂未来预测任务时的表现。同时,研究不同规模模型在未来预测能力上的差异,为模型优化和部署提供指导。
- 增强模型鲁棒性:研究模型在面对对抗性攻击时的鲁棒性,开发有效的防御机制,确保模型在未来预测任务中的可靠性和安全性。同时,探索模型在处理不确定性和模糊性信息时的能力,提高其在实际应用中的适应性。
- 结合其他评估方法:将FutureX框架与其他评估方法(如人类评估、对抗性测试等)相结合,提供更全面、更准确的模型评估结果。同时,探索将诊断反馈用于指导模型微调,提高模型的性能和可靠性。
- 跨领域和跨任务泛化:研究FutureX框架在跨领域和跨任务场景中的泛化能力,探索其在医疗、法律等其他高风险领域的应用潜力。通过迁移学习和元学习技术,使模型能够快速适应新领域和新任务,减少对大量标注数据的依赖。