背景
在边缘计算场景下,我们的服务器部署在客户环境中,需要对接客户自有的存储基础设施(往往是几百万购买的)。这些存储服务器通常只提供NFS挂载接口,而我们的对象存储方案基于MinIO实现,需要 同时支持裸磁盘部署和NFS挂载两种模式。
在裸磁盘部署场景下,MinIO运行稳定,性能表现良好。然而,当切换到NFS挂载模式时, 我们遇到了严重的性能瓶颈。
核心问题分析:MinIO的许多内置功能(如数据扫描、健康检查、元数据维护等)需要频 繁遍历文件系统。在本地磁盘上,这些操作的开销可以忽略不计;但在NFS环境下,每次 文件系统操作都涉及网络往返,大量操作需要对文件夹加锁,导致性能急剧下降,成为系统的性能灾难。
本文会包含下面这些内容:
- 通过Linux内核源码分析和eBPF追踪,定位MinIO在NFS环境下的锁竞争问题
- 直接使用NFS协议与服务器通信,避开VFS层的锁竞争,实现S3到NFS的协议转换
- 基于unfold+map+buffered组合,用简洁代码实现高效的文件预取机制
- 分片上传与异步合并、大目录遍历的状态复用和分页、List Objects流式的实现原理
- 支持多种存储后端抽象分层
- NFS 可视化监控的实现方式
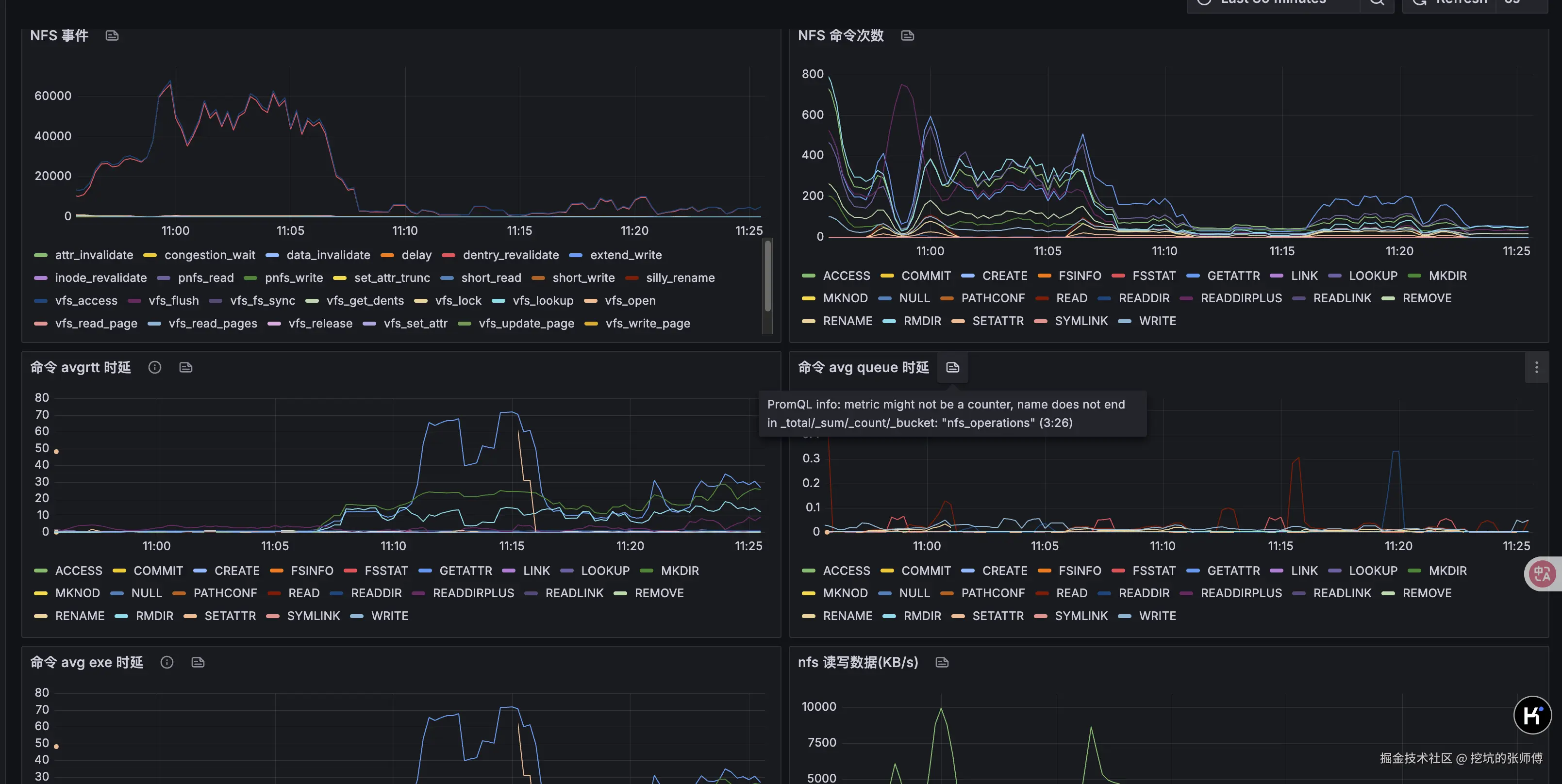
NFS 可视化监控
代码未写,监控先行。这部分的监控是缺失,我们基于 NFS 暴露的 stat 以及 EBPF 实现了一个比较完善的监控看板,可以看到 NFS 的事件、延迟、命令测试等,可以直观看到性能瓶颈时,NFS 的详细监控数据。
内核问题分析
这部分是内核源码分析,不感兴趣的同学可以跳过这一节。
当 minio 在扫描大目录时,此时一个简单的文件创建和写入都会卡住,内核堆栈如下
bash
PID: 21060 TASK: ffff8fad248a3fc0 CPU: 3 COMMAND: "file_rw_test"
#0 [ffffacbbcd747c38] __schedule at ffffffffa3a9600e
#1 [ffffacbbcd747c88] schedule at ffffffffa3a9649c
#2 [ffffacbbcd747c98] rwsem_down_write_slowpath at ffffffffa3150a29
#3 [ffffacbbcd747d40] path_openat at ffffffffa3398b49
#4 [ffffacbbcd747dd8] do_filp_open at ffffffffa339ada1
#5 [ffffacbbcd747ee8] do_sys_openat2 at ffffffffa3384d3d
#6 [ffffacbbcd747f20] do_sys_open at ffffffffa338616b
#7 [ffffacbbcd747f40] do_syscall_64 at ffffffffa3a88500其中 open 系统阻塞在 open_last_lookups 内核函数
c
static struct file *path_openat(struct nameidata *nd,
const struct open_flags *op, unsigned flags)
{
struct file *file;
int error;
file = alloc_empty_file(op->open_flag, current_cred());
if (IS_ERR(file))
return file;
if (unlikely(file->f_flags & __O_TMPFILE)) {
error = do_tmpfile(nd, flags, op, file);
} else if (unlikely(file->f_flags & O_PATH)) {
error = do_o_path(nd, flags, file);
} else {
const char *s = path_init(nd, flags);
// 阻塞在这里
while (!(error = link_path_walk(s, nd)) &&
(s = open_last_lookups(nd, file, op)) != NULL)
;
if (!error)
error = do_open(nd, file, op);
terminate_walk(nd);
}
}
static const char *open_last_lookups(struct nameidata *nd,
struct file *file, const struct open_flags *op)
{
struct dentry *dir = nd->path.dentry;
int open_flag = op->open_flag;
bool got_write = false;
unsigned seq;
struct inode *inode;
struct dentry *dentry;
const char *res;
nd->flags |= op->intent;
// 对目录 inode 加锁
if (open_flag & O_CREAT)
inode_lock(dir->d_inode); // 阻塞在这里
else
inode_lock_shared(dir->d_inode);
// 执行真正的 open 操作
dentry = lookup_open(nd, file, op, got_write);
if (!IS_ERR(dentry) && (file->f_mode & FMODE_CREATED))
fsnotify_create(dir->d_inode, dentry);
if (open_flag & O_CREAT)
inode_unlock(dir->d_inode);
else
inode_unlock_shared(dir->d_inode);
}
static inline void inode_lock(struct inode *inode)
{
down_write(&inode->i_rwsem); // 对信号量加写锁
}阻塞 rwsem_down_write_slowpath 函数上,源码如下:
arduino
/*
* Wait until we successfully acquire the write lock
*/
static struct rw_semaphore *
rwsem_down_write_slowpath(struct rw_semaphore *sem, int state)其中 rw_semaphore 是 linux 内核中的读写信号量,用来实现读写锁。
arduino
struct rw_semaphore {
atomic_long_t count;
/*
* Write owner or one of the read owners as well flags regarding
* the current state of the rwsem. Can be used as a speculative
* check to see if the write owner is running on the cpu.
*/
atomic_long_t owner;
}其中 owner 指向持有写锁的进程,我们来写一个 bpf 程序来打印
ini
SEC("kprobe/rwsem_down_write_slowpath")
int BPF_KPROBE(trace_rwsem_down_write_slowpath) {
char comm[16];
bpf_get_current_comm(&comm, sizeof(comm));
if ((strncmp(comm, "file_rw_test", 12) != 0) &&
(strncmp(comm, "minio", 5) != 0)) {
return 0;
}
struct rw_semaphore *rwsem = (struct rw_semaphore *) PT_REGS_PARM1(ctx);
s64 count = BPF_CORE_READ(rwsem, count.counter);
u64 owner = BPF_CORE_READ(rwsem, owner.counter);
// clear the lower 3 bits
owner &= ~((s64) 7);
struct task_struct *owner_task = (struct task_struct *) owner;
if (owner_task == NULL) {
return 0;
}
pid_t owner_pid = BPF_CORE_READ(owner_task, pid);
char owner_comm[16];
int len = bpf_probe_read_kernel_str(owner_comm, sizeof(owner_comm),
&owner_task->comm);
bpf_printk("[enter]write lock, owner_comm: %s, owner_pid: %d", owner_comm, owner_pid);
return 0;
}输出如下,可以看到这是一个 minio 线程。
yaml
bpf_trace_printk: [enter]write lock, owner_comm: minio, owner_pid: 12708通过 crash 工具,查看 12708 线程的堆栈
less
crash> bt 12708
PID: 12708 TASK: ffff8fa941a7aa80 CPU: 5 COMMAND: "minio"
#0 [ffffacbbc41ebab0] __schedule at ffffffffa3a9600e
#1 [ffffacbbc41ebb00] schedule at ffffffffa3a9649c
#2 [ffffacbbc41ebb10] io_schedule at ffffffffa3a96952
#3 [ffffacbbc41ebb20] __lock_page at ffffffffa328d0d9
#4 [ffffacbbc41ebbb0] invalidate_inode_pages2_range at ffffffffa32a742e
#5 [ffffacbbc41ebd30] nfs_readdir_filler at ffffffffc0aba60d [nfs]
#6 [ffffacbbc41ebd50] do_read_cache_page at ffffffffa3291e04
#7 [ffffacbbc41ebe00] nfs_readdir at ffffffffc0aba783 [nfs]
#8 [ffffacbbc41ebea0] iterate_dir at ffffffffa339e222
#9 [ffffacbbc41ebed8] __x64_sys_getdents64 at ffffffffa339f071
#10 [ffffacbbc41ebf40] do_syscall_64 at ffffffffa3a88500
#11 [ffffacbbc41ebf50] entry_SYSCALL_64_after_hwframe at ffffffffa3c00099
RIP: 000000000040720e RSP: 000000c202c2d8e8 RFLAGS: 00000206
RAX: ffffffffffffffda RBX: 0000000000000014 RCX: 000000000040720e
RDX: 0000000000100000 RSI: 000000c227916000 RDI: 0000000000000014
RBP: 000000c202c2d928 R8: 0000000000000000 R9: 0000000000000000
R10: 0000000000000000 R11: 0000000000000206 R12: 0000000000000000
R13: 000000c001100000 R14: 000000c0014d1a00 R15: 0000000000000106
ORIG_RAX: 00000000000000d9 CS: 0033 SS: 002biterate_dir 在非 shared 模式下会对 dir 目录加写锁,然后开始执行文件系统的 iterate(调用 nfs 的nfs_readdir)
ini
int iterate_dir(struct file *file, struct dir_context *ctx)
{
struct inode *inode = file_inode(file);
bool shared = false;
int res = -ENOTDIR;
if (file->f_op->iterate_shared)
shared = true;
else if (!file->f_op->iterate)
goto out;
res = security_file_permission(file, MAY_READ);
if (res)
goto out;
if (shared)
res = down_read_killable(&inode->i_rwsem);
else
res = down_write_killable(&inode->i_rwsem); // 对目录的 inode 加写锁
if (res)
goto out;
res = -ENOENT;
if (!IS_DEADDIR(inode)) {
ctx->pos = file->f_pos;
if (shared)
res = file->f_op->iterate_shared(file, ctx);
else
res = file->f_op->iterate(file, ctx);
file->f_pos = ctx->pos;
fsnotify_access(file);
file_accessed(file);
}
if (shared)
inode_unlock_shared(inode);
else
inode_unlock(inode);
out:
return res;
}因为目录遍历执行的特别快,我们程序抢不到锁,就会出现卡顿。当然除了遍历目录,还有很多地方会有锁的问题,比如 rename 文件等。
less
crash> bt 12733
PID: 12733 TASK: ffff8fa9821f2a80 CPU: 4 COMMAND: "minio"
#0 [ffffacbbc4263d38] __schedule at ffffffffa3a9600e
#1 [ffffacbbc4263d88] schedule at ffffffffa3a9649c
#2 [ffffacbbc4263d98] rwsem_down_write_slowpath at ffffffffa3150a29
#3 [ffffacbbc4263e48] lock_rename at ffffffffa33948a5
#4 [ffffacbbc4263e68] do_renameat2 at ffffffffa339b7b6
#5 [ffffacbbc4263f18] __x64_sys_renameat at ffffffffa339bbe5
#6 [ffffacbbc4263f40] do_syscall_64 at ffffffffa3a88500解决方案:绕过 vfs 和系统调用
技术方案如下图所示:
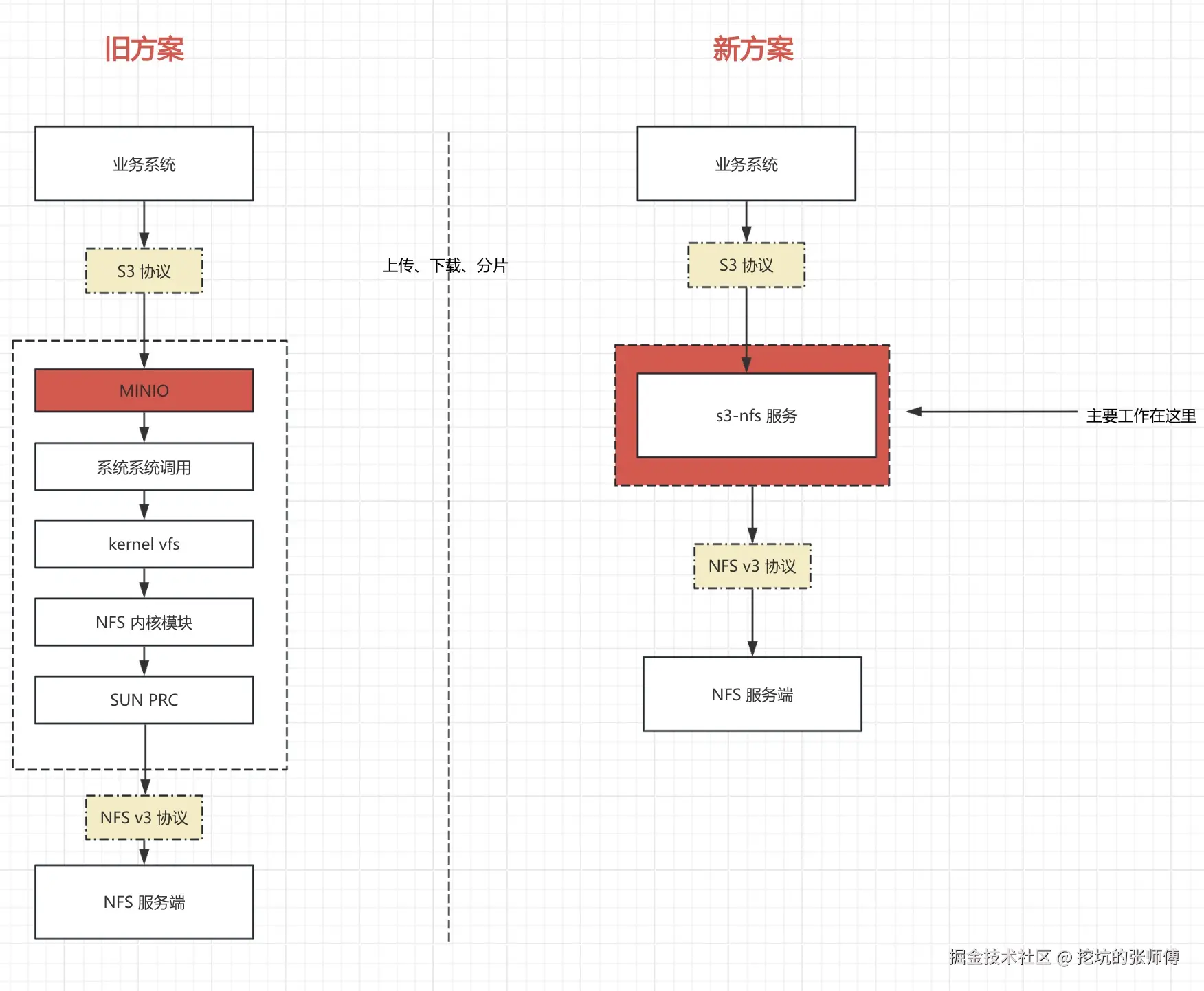
简单来说这个项目的设计如下:
- S3 API层:处理传入的S3协议请求(基于开源的 s3s,做了一些 fix)
- 协议转换:将 S3 操作转换为相应的 NFS 操作
- NFS协议实现:使用 NFS 协议直接与 NFS 服务器通信
一句话来说总结就是,把 S3 请求翻译为 NFS 的网络调用,就这么简单!下面是一些实现的细节。
MINIO 明确表示不处理任何与 NFS 挂载带来的问题(大家可以 github 搜 issue),可能也是 他们觉得 MINIO+NFS 不是一个好的组合吧。
关于接口抽象
ObjectLayer 是 maxio 项目中的核心存储抽象层,它定义了一个统一的接口来处理对象存储操作,支持不同的底层存储实现(如 NFS、本地文件系统等)。这个抽象层使得系统能够轻松切换存储后端,同时提供一致的 S3 兼容 API。
rust
#[async_trait::async_trait]
pub trait ObjectLayer: Send + Sync {
// 桶操作
async fn list_buckets(&self) -> anyhow::Result<Vec<BucketInfo>>;
async fn make_bucket(&self, bucket: &str, opt: Option<MakeBucketOptions>) -> MResult<()>;
async fn get_bucket_info(&self, bucket: &str) -> MResult<Arc<BucketInfo>>;
async fn delete_bucket(&self, bucket: &str) -> MResult<()>;
// 对象操作
async fn put_object(&self, bucket: &str, key: &str, stream: HashReaderStream, opts: ObjectOptions) -> MResult<ObjectInfo>;
async fn get_object(&self, bucket: &str, key: &str, range: Option<Range>) -> MResult<(GetObjectReader, u64, u64)>;
async fn delete_object(&self, bucket: &str, key: &str) -> MResult<()>;
async fn delete_objects(&self, bucket: &str, objects: Vec<ObjectToDelete>) -> anyhow::Result<(Vec<DeletedObject>, Vec<(String, MaxioError)>)>;
async fn list_objects(&self, bucket: &str, prefix: Option<String>, marker: Option<String>, delimiter: Option<String>, max_keys: Option<i32>) -> MResult<ListObjectsInfo>;
async fn get_object_info(&self, bucket: &str, key: &str) -> MResult<Option<ObjectInfo>>;
// 分片上传操作
async fn new_multipart_upload(&self, bucket: &str, key: &str) -> MResult<UploadId>;
async fn upload_part(&self, bucket: &str, key: &str, upload_id: UploadId, part_id: i32, stream: HashReaderStream, content_length: Option<i64>) -> MResult<PartInfo>;
async fn complete_multipart_upload(&self, bucket: &str, key: &str, upload_id: &str, parts: Vec<CompletePart>, opts: ObjectOptions) -> MResult<()>;
async fn abort_multipart_upload(&self, bucket: &str, key: &str, upload_id: &str) -> MResult<()>;
async fn list_multipart_uploads(&self, bucket: &str, prefix: &Option<String>, delimiter: &Option<String>, upload_id_marker: &Option<String>, key_marker: &Option<String>, encoding_type: &Option<String>, max_uploads: &Option<i32>) -> MResult<ListMultipartUploadsInfo>;
}除了对象存储层的抽象,还有一个非常重要的文件操作层的抽象 Fs trait,这样我们只需要实现不同的 fs 后端实现就可以支持不同的存储类型,比如 NFS、单机多磁盘、分布式多磁盘等。
核心抽象:Fs Trait
rust
#[async_trait::async_trait(Sync)]
pub trait Fs: Send + Sync {
// 目录操作
async fn create_dir(&self, path: &Path) -> MResult<()>;
async fn remove_dir(self: Arc<Self>, path: &Path, options: RemoveOptions) -> MResult<()>;
// 文件操作
async fn create_file(&self, path: &Path, options: CreateOptions) -> MResult<()>;
async fn remove_file(&self, path: &Path) -> MResult<()>;
async fn rename(&self, source: &Path, target: &Path, options: RenameOptions) -> MResult<()>;
async fn copy_file(&self, source: &Path, target: &Path, options: CopyOptions) -> MResult<()>;
// 读写操作
async fn read(&self, path: &Path, offset: u64, count: u64) -> MResult<Bytes>;
async fn read_to_bytes(&self, path: &Path) -> MResult<Bytes>;
async fn read_as_stream(self: Arc<Self>, path: &Path, offset: u64, count: u64) -> MResult<DataStream>;
async fn write_bytes(&self, path: &Path, content: Bytes, start_offset: u64) -> MResult<u64>;
async fn write_stream(&self, path: &Path, stream: &mut Pin<Box<dyn Stream<Item = Result<Bytes, Box<dyn std::error::Error + Send + Sync>>> + Send + Sync>>, start_offset: u64) -> MResult<u64>;
// 元数据操作
async fn metadata(&self, path: &Path) -> MResult<Option<Metadata>>;
async fn read_dir(self: Arc<Self>, path: &Path) -> MResult<ReaddirStream>;
async fn walk_file(&self, path: &Path, prefix: &str, recursive: bool) -> MResult<Pin<Box<dyn Stream<Item = MResult<FileEntry>> + Send + Sync>>>;
}分片上传与合并
关于分片上传的实现,我们参考了 minio 的实现细节,每当有新分片上传完成时,立即在后台异步合并连续的分片,然后在 complete 的时候等候所有分片合并完成。
1. 分片上传完成触发
当单个分片上传完成后,系统会触发后台增量合并:
rust
// 在 upload_part 方法中
self.spawn_incremental_merge(&bucket, &key, &upload_id);
fn spawn_incremental_merge(&self, bucket: &str, key: &str, upload_id: &str) {
let ttl = Duration::from_secs(self.config.merge_state_ttl_sec);
tokio::spawn(async move {
if let Err(e) = incremental_merge_parts(
nfs3_op, merge_states, &fs_uuid,
&bucket, &key, &upload_id, ttl
).await {
info!("Background merge failed: {:?}", e);
}
});
}2. 增量合并逻辑
增量合并只合并连续的分片,避免不必要的等待。只合并从 last_merged_part + 1 开始的连续分片,遇到分片间隙立即停止,等待缺失分片上传,保证合并文件的连续性和正确性。
rust
// 增量合并:只合并顺序连续的分片
let mut parts = Vec::new();
let mut expected_part = last_merged_part + 1;
for (part_number, etag, actual_size, file_name) in part_files {
if part_number == expected_part {
parts.push(MergePart { part_number, _etag: etag, size: actual_size, file_name });
expected_part += 1;
} else if part_number > expected_part {
// 发现间隙,停止增量合并
break;
}
}3. 完成时全量合并
用户调用完成上传时,执行全量合并确保所有分片都被处理,同步执行,确保完成前所有数据已合并
rust
async fn complete_merge_all_parts(&self, bucket: &str, key: &str, upload_id: &str) -> MResult<PathBuf> {
let ttl = std::time::Duration::from_secs(self.config.merge_state_ttl_sec);
let merge_file_path = merge_parts_with_ttl(
self.fs.clone(),
self.merge_states.clone(),
&self.fs_uuid,
bucket, key, upload_id,
true, // complete_all = true
ttl,
).await?;
}4. 核心合并操作
perform_merge_operation_with_state 是实际执行合并的核心函数:
rust
async fn perform_merge_operation_with_state(
fs: FsType,
merge_state: &mut MutexGuard<MergeState>,
fs_uuid: &str,
bucket: &str, key: &str, upload_id: &str,
complete_all: bool,
) -> anyhow::Result<Option<PathBuf>> {
// 1. 读取上传目录中的所有分片文件
let upload_dir = get_upload_id_dir(bucket, key, upload_id);
let entries = fs.clone().read_dir(&upload_dir).await?.try_collect::<Vec<_>>().await?;
// 2. 解析分片文件名,提取分片信息
for entry in entries {
if let Ok((part_number, etag, actual_size)) = decode_part_file(&entry.name) {
part_files.push((part_number as i32, etag, actual_size, entry.name));
}
}
part_files.sort_by_key(|&(part_number, _, _, _)| part_number);
// 3. 根据合并模式确定要合并的分片
let parts_to_merge = if complete_all {
// 全量合并:所有未合并的分片
part_files.into_iter()
.filter(|(part_number, _, _, _)| *part_number > last_merged_part)
.map(|(part_number, etag, actual_size, file_name)|
MergePart { part_number, _etag: etag, size: actual_size, file_name })
.collect()
} else {
// 增量合并:只合并连续分片
// ... (如前所述的连续性检查逻辑)
};
// 4. 执行实际的文件合并
let mut offset = merge_state.total_merged_size as u64;
for part in &parts_to_merge {
let part_path = path_join![upload_dir.as_str(), &part.file_name];
let mut stream = fs.clone().read_as_stream(&part_path, 0, part.size as u64).await?;
let n = fs.write_stream(&merge_file_path, &mut stream, offset).await?;
offset += n;
}
// 5. 更新合并状态(仅增量合并)
if !complete_all {
merge_state.merged_parts.extend(parts_to_merge);
merge_state.total_merged_size = offset as i64;
merge_state.last_merged_part = merge_state.merged_parts.last()
.map(|p| p.part_number).unwrap_or(0);
merge_state.merge_file_path = Some(merge_file_path.clone());
}
}这里我们还需要考虑,分片上传最终未完成的情况,避免脏文件。系统启动时会启动后台清理过期上传任务。
自动清理任务
rust
fn start_merge_state_cleanup(&self) {
let ttl = Duration::from_secs(self.config.merge_state_ttl_sec);
let cleanup_interval = Duration::from_secs(self.config.merge_state_cleanup_interval_sec);
tokio::spawn(async move {
let mut interval = tokio::time::interval(cleanup_interval);
loop {
interval.tick().await;
if let Err(e) = cleanup_expired_merge_states(merge_states, ttl, &fs, &fs_uuid).await {
error!("Failed to cleanup expired merge states: {:?}", e);
}
}
});
}清理流程
- 识别过期状态: 检查所有合并状态的创建时间
- 完整清理: 清理过期状态及其关联的所有文件系统资源
- 原子性删除: 先移动再删除,避免影响正在进行的操作
rust
pub async fn cleanup_expired_merge_states(
merge_states: MergeStateManager,
ttl: Duration,
fs: &FsType,
fs_uuid: &str
) -> MResult<()> {
let expired_uploads = merge_states.get_all_expired(ttl).await;
for expired in &expired_uploads {
// 完整的 multipart 清理
clean_multipart(fs, fs_uuid,
&expired.bucket, &expired.key, &expired.upload_id,
merge_states.clone()
).await?;
}
}list_objects 实现
list_objects 涉及到复杂的文件遍历,接口参数也比较多,delimiter、prefix 等,当然核心的问题是如何遍历文件。
传统的目录遍历在处理大目录时面临两个主要问题:
- 内存爆炸: 一次性加载所有文件信息,我们的超大目录,可能有上亿个文件
- 不可中断: 无法支持分页和断点续传
我们的实现也部分参考了 minio 的实现
核心架构
1. TreeWalkPool - 遍历状态池
rust
#[derive(Clone)]
pub struct TreeWalkPool {
pool: Arc<Mutex<HashMap<SharedListParams, VecDeque<TreeWalk>>>>,
fs_op: FsType,
timeout: Duration,
id_counter: Arc<AtomicU64>,
}核心特性:
- 状态复用: 相同参数的遍历任务可以复用之前的状态
- 超时管理: 自动清理过期的遍历状态
- 并发安全: 使用细粒度锁保证线程安全
2. TreeWalk - 遍历实例
rust
pub struct TreeWalk {
pub id: u64, // 唯一标识符
pub result_rx: mpsc::Receiver<TreeWalkResult>, // 结果接收通道
pub added: DateTime<Utc>, // 创建时间
pub end_timer_tx: Option<oneshot::Sender<()>>, // 超时控制信号
pub end_walk_tx: Option<oneshot::Sender<()>>, // 遍历结束信号
}3. ListParams - 遍历参数
rust
#[derive(Debug, Clone, Eq, PartialEq, Hash)]
pub struct ListParams {
pub bucket: String, // 桶名
pub recursive: bool, // 是否递归
pub marker: String, // 分页标记
pub prefix: String, // 前缀过滤
}实现原理详解
1. 对象列举流程 (list_objects)
rust
async fn list_objects(&self, bucket: &str, prefix: Option<String>, marker: Option<String>,
delimiter: Option<String>, max_keys: Option<i32>) -> MResult<ListObjectsInfo> {
// 1. 参数验证和标准化
let recursive = delimiter != SLASH_SEPARATOR;
let params = Arc::new(ListParams::new(bucket.to_string(), recursive,
marker.clone(), prefix.clone().unwrap_or_default()));
// 2. 尝试从池中获取现有的遍历状态
let mut tree_walk = match self.tree_walk_pool.release(params.clone()) {
Some(tree_walk) => {
info!("release tree walk from pool, params: {:?}", params);
tree_walk
}
None => {
// 3. 创建新的遍历任务
info!("start a new tree walk, params: {:?}", params);
self.tree_walk_pool.start_tree_walk(params.clone(), recursive, max_keys)?
}
};
// 4. 从通道接收遍历结果
let mut result = Vec::new();
let mut prefixes = Vec::new();
let mut eof = false;
for _ in 0..max_keys {
let item = match tree_walk.result_rx.recv().await {
Some(item) => item,
None => {
eof = true;
break;
}
};
// 5. 根据 delimiter 处理目录和文件
if item.is_dir && delimiter == SLASH_SEPARATOR {
prefixes.push(item.path());
} else {
result.push(ObjectInfo { /* ... */ });
}
}
// 6. 处理分页和状态保存
if !eof {
ret.is_truncated = true;
let param = ListParams::new(bucket.to_string(), recursive,
ret.next_marker.clone(), prefix.clone().unwrap_or_default());
// 将未完成的遍历状态返回到池中
self.tree_walk_pool.set(param, tree_walk);
}
}2. TreeWalk 生命周期管理
创建阶段 (start_tree_walk)
rust
pub fn start_tree_walk(&self, params: SharedListParams, recursive: bool, max_keys: u32) -> anyhow::Result<TreeWalk> {
// 1. 解析前缀参数
let (prefix_dir, entry_prefix_match) = if let Some(last_index) = prefix.rfind(SLASH_SEPARATOR) {
let (dir, p_match) = prefix.split_at(last_index + 1);
(dir.to_string(), p_match.to_string())
} else {
("".to_string(), prefix)
};
// 2. 创建通道
let (result_tx, result_rx) = mpsc::channel(max_keys as usize);
let (end_walk_tx, end_walk_rx) = oneshot::channel();
// 3. 启动后台遍历任务
tokio::spawn({
let fs_op = self.fs_op.clone();
async move {
Self::do_tree_walk(fs_op, recursive, bucket, prefix_dir,
entry_prefix_match, result_tx, end_walk_rx).await
}
});
// 4. 返回 TreeWalk 实例
Ok(TreeWalk {
id: self.alloc_id(),
result_rx,
added: Utc::now(),
end_walk_tx: Some(end_walk_tx),
end_timer_tx: None,
})
}后台遍历任务 (do_tree_walk)
rust
async fn do_tree_walk(
fs_op: FsType,
recursive: bool,
bucket: String,
prefix_dir: String,
entry_prefix_match: String,
result_tx: mpsc::Sender<TreeWalkResult>,
end_walk_rx: oneshot::Receiver<()>,
) -> MResult<()> {
let path = path_join!(&bucket, &prefix_dir);
let stream = fs_op.walk_file(&path, &prefix_dir, recursive).await?;
let mut end_walk_rx_fused = end_walk_rx.fuse();
let mut stream_fused = stream.fuse();
let mut pending_entry: Option<FileEntry> = None;
loop {
tokio::select! {
biased;
// 1. 响应取消信号
_ = &mut end_walk_rx_fused => {
trace!("received signal to end walk");
return Ok(());
}
// 2. 从文件系统流读取条目
entry_result = stream_fused.next(), if pending_entry.is_none() => {
match entry_result {
Some(Ok(entry)) => {
pending_entry = Some(entry);
}
Some(Err(e)) => return Err(e),
None => break, // 流结束
}
}
// 3. 获取发送许可并发送结果
permit = result_tx.reserve(), if pending_entry.is_some() => {
match permit {
Ok(permit) => {
let entry = pending_entry.take().unwrap();
if let Some(result) = Self::process_file_entry_non_blocking(
entry, &prefix_dir, &entry_prefix_match)? {
permit.send(result);
}
}
Err(e) => return Err(MaxioError::Other(format!("failed to reserve permit: {}", e))),
}
}
}
}
Ok(())
}3. 状态池管理机制
状态保存 (set)
rust
pub fn set(&self, params: ListParams, mut tree_walk: TreeWalk) {
let params = Arc::new(params);
let mut _guard = self.pool.lock().unwrap();
// 1. 容量控制 - 防止内存无限增长
if _guard.len() > TREE_WALK_ENTRY_LIMIT {
// 删除最旧的条目
let oldest_walk_dq = _guard.values_mut()
.min_by_key(|v| v.front().map(|w| w.added).unwrap_or(Utc::now()));
if let Some(dq) = oldest_walk_dq {
if let Some(mut oldest_walk) = dq.pop_front() {
// 发送结束信号
oldest_walk.end_timer_tx.take().map(|tx| tx.send(()));
oldest_walk.end_walk_tx.take().map(|tx| tx.send(()));
};
}
}
// 2. 设置超时管理
let (end_timer_tx, end_timer_rx) = oneshot::channel();
tree_walk.id = self.alloc_id();
tree_walk.added = Utc::now();
tree_walk.end_timer_tx = Some(end_timer_tx);
// 3. 添加到池中
let walks = _guard.entry(params.clone()).or_insert_with(VecDeque::new);
if walks.len() > TREE_WALK_SAME_ENTRY_LIMIT {
// 同样参数的遍历任务数量限制
if let Some(mut oldest_walk) = walks.pop_front() {
oldest_walk.end_timer_tx.take().map(|tx| tx.send(()));
};
}
walks.push_back(tree_walk);
// 4. 启动超时任务
tokio::spawn({
let pool = self.pool.clone();
let timeout = self.timeout;
async move {
tokio::select! {
_ = tokio::time::sleep(timeout) => {
// 超时清理
let mut _guard = pool.lock().unwrap();
// 清理逻辑...
}
_ = end_timer_rx => {
// 正常结束
}
}
}
});
}状态获取 (release)
rust
pub fn release(&self, params: SharedListParams) -> Option<TreeWalk> {
let mut _guard = self.pool.lock().unwrap();
let walks = _guard.get_mut(¶ms)?;
// 获取第一个遍历实例
let walk = walks.pop_front();
if walks.is_empty() {
_guard.remove(¶ms);
}
let Some(mut walk) = walk else {
return None;
};
// 取消超时定时器
walk.end_timer_tx.take().map(|tx| tx.send(()));
Some(walk)
}4. 前缀处理机制
系统支持复杂的前缀匹配逻辑:
rust
// 示例 1:
// prefix = "one/two/three/"
// marker = "one/two/three/four/five.txt"
// => prefix_dir = "one/two/three/"
// => entry_prefix_match = ""
// 示例 2:
// prefix = "one/two/th"
// marker = "one/two/three/four/five.txt"
// => prefix_dir = "one/two/"
// => entry_prefix_match = "th"
let (prefix_dir, entry_prefix_match) = if let Some(last_index) = prefix.rfind(SLASH_SEPARATOR) {
let (dir, p_match) = prefix.split_at(last_index + 1);
(dir.to_string(), p_match.to_string())
} else {
("".to_string(), prefix)
};5. 递归与非递归模式
系统根据 delimiter 参数决定遍历模式:
rust
let recursive = delimiter != SLASH_SEPARATOR;
// recursive = true: 深度遍历,返回所有文件
// recursive = false: 只遍历当前目录层级,目录作为前缀返回递归模式 (delimiter != "/"):
- 遍历所有子目录
- 返回所有文件对象
- 适用于完整列举场景
非递归模式 (delimiter == "/"):
- 只遍历当前层级
- 子目录作为
common_prefixes返回 - 适用于目录浏览场景
6. 内存控制与背压机制
Channel 容量控制
rust
let (result_tx, result_rx) = mpsc::channel(max_keys as usize);通道容量等于 max_keys,确保内存使用有界。
背压处理
rust
permit = result_tx.reserve(), if pending_entry.is_some() => {
match permit {
Ok(permit) => {
// 获得许可后才处理条目
let entry = pending_entry.take().unwrap();
if let Some(result) = Self::process_file_entry_non_blocking(...) {
permit.send(result);
}
}
Err(e) => return Err(...),
}
}使用 reserve() 方法实现背压控制,当接收端处理不及时时自动暂停生产。
file handle 的实现
我们都知道,linux 使用 inode 来关联具体的文件,在 NFS 中,文件句柄是 NFS File Handle ,它是服务器为每个文件和目录分配的唯一标识符。与传统文件系统中使用路径名不同,NFS使用文件句柄来标识和访问文件系统对象。
NFS File Handle 的特点:
- 唯一性: 每个文件/目录都有唯一的文件句柄
- 持久性: 文件句柄在文件生命周期内保持不变
- 不透明性: 对客户端来说是不透明的二进制数据
- 高效性: 直接定位文件,无需路径解析
典型的NFS操作流程:
- 路径解析: 客户端需要将路径 /a/b/c/file.txt 转换为文件句柄
- 逐级查找: 需要依次执行 LOOKUP 操作:
- LOOKUP(root_fh, "a") → a_fh
- LOOKUP(a_fh, "b") → b_fh
- LOOKUP(b_fh, "c") → c_fh
- LOOKUP(c_fh, "file.txt") → file_fh
- 文件操作: 使用最终的file_fh进行READ/WRITE等操作
没有缓存的情况下,每次文件访问都需要完整的路径解析,深层路径访问需要多次网络往返,严重影响性能
scss
// 访问 /deep/nested/directory/structure/file.txt 需要5次网络往返
LOOKUP(root, "deep") → deep_fh // 网络往返 1
LOOKUP(deep_fh, "nested") → nested_fh // 网络往返 2
LOOKUP(nested_fh, "directory") → dir_fh // 网络往返 3
LOOKUP(dir_fh, "structure") → struct_fh // 网络往返 4
LOOKUP(struct_fh, "file.txt") → file_fh // 网络往返 5项目中的 File Handle LRU 缓存设计
核心数据结构
FhCacheEntry - 缓存条目
rust
#[derive(Debug)]
pub struct FhCacheEntry {
pub fh: SharedFh3, // NFS3 文件句柄
pub is_dir: bool, // 是否为目录
}FhLruCache - LRU缓存容器
rust
pub struct FhLruCache {
path_cache: Mutex<LruCache<PathBuf, SharedFhCacheEntry>>,
}通过祖先路径查找最大化缓存命中:
rust
// 从最长路径到最短路径查找缓存
for ancestor in path.ancestors() {
if let Some(cached_fh) = self.path_cache.get(ancestor) {
existing_fh = Some(cached_fh.fh.clone());
cached_ancestor = Some(ancestor);
break; // 找到最长匹配的祖先路径
}
}文件 prefetch 实现
在完成这个项目的 demo 版本以后,实测文件下载速度比 minio 要慢,经过分析发现因为 minio 基于文件 fs,Linux系统采用预读(readahead)技术以加速顺序文件读取,会自动往后 readahead,对于 NFS 来说,就是提前发起了后续文件内容网络请求。于是 maxio 也实现了类似的 prefetch 特性。
1.1 核心设计理念
尽可能使用 rust 的 stream 或者 future 的高级特性,减少自定义 stream 或者 future 的实现,减少状态机的管理成本。于是基于 stream 的 fold、map 和 buffered 使用非常简短的代码就实现了这个特性。在这个之前我还写过一个比较复杂的基于状态机的版本,代码行数比这个多很多。
1.2 核心数据结构
rust
pub(crate) struct FileReadOp {
start_offset: u64, // 读取起始偏移
length: u64, // 总读取长度
file_fh: SharedFh3, // NFS 文件句柄
nfs_op: SharedFsInner, // NFS 操作实例
prefetch_chunk_size: u64, // 预取块大小 (默认 128KB)
prefetch_chunk_count: usize, // 并发预取块数量 (默认 4)
}设计要点:
prefetch_chunk_size: 单次预取的数据块大小,平衡网络效率和内存使用prefetch_chunk_count: 并发预取的块数量,控制网络并发度
1.3 配置参数
rust
// 默认配置常量
pub const DEFAULT_PREFETCH_CHUNK_COUNT: usize = 4; // 最大并发预取块数
pub const DEFAULT_PREFETCH_CHUNK_SIZE: u64 = 128 * 1024; // 128KB 块大小
pub const MAX_READ_PACKET_SIZE: u64 = 128 * 1024; // NFS 读取包最大尺寸
// 运行时配置
#[derive(Debug, Clone, Serialize, Deserialize)]
pub struct NfsConfig {
#[serde(default = "default_prefetch_chunk_size")]
pub prefetch_chunk_size: u64, // 可动态配置的块大小
#[serde(default = "default_prefetch_chunk_count")]
pub prefetch_chunk_count: usize, // 可动态配置的并发数
// ... 其他配置项
}二、Prefetch 实现原理详解
2.1 流式预取架构
rust
pub fn to_prefetch_stream(self) -> impl Stream<Item = Result<Bytes, Box<dyn std::error::Error + Send + Sync>>> {
let chunk_size = self.prefetch_chunk_size;
let init_start_offset = self.start_offset;
let stream_len = self.length;
// 1. 创建偏移量生成器
let offset_stream = unfold(init_start_offset, move |start| async move {
if start >= stream_len + init_start_offset {
return None; // 达到文件末尾
}
Some((start, start + chunk_size)) // 返回当前偏移量,更新下一个偏移量
});
// 2. 将偏移量转换为异步读取任务
offset_stream
.map(move |start_offset| {
let fs = self.nfs_op.clone();
let fh = self.file_fh.clone();
let n = min(stream_len + init_start_offset - start_offset, chunk_size);
// 返回一个 Future,表示一个异步 NFS 读取操作
async move {
fs.do_nfs_read(fh.clone(), start_offset, n).await
.map_err(|e| Box::new(e) as Box<dyn std::error::Error + Send + Sync>)
}
})
// 3. 并发执行读取任务,最大并发数为 prefetch_chunk_count
.buffered(self.prefetch_chunk_count)
}2.2 关键技术解析
A. 流式数据生成 (unfold)
rust
let offset_stream = unfold(init_start_offset, move |start| async move {
if start >= stream_len + init_start_offset {
return None; // 流结束
}
Some((start, start + chunk_size)) // (当前值, 下一个状态)
});原理:
unfold是一个状态驱动的流生成器- 每次产生一个偏移量,并计算下一个状态
- 当达到文件末尾时自动终止流
B. 异步任务映射 (map)
rust
.map(move |start_offset| {
let fs = self.nfs_op.clone();
let fh = self.file_fh.clone();
let n = min(stream_len + init_start_offset - start_offset, chunk_size);
async move { fs.do_nfs_read(fh.clone(), start_offset, n).await }
})原理:
- 将每个偏移量转换为一个异步读取任务
- 使用
Arc智能指针避免数据复制 - 动态计算读取长度,处理文件末尾情况
C. 并发缓冲执行 (buffered)
rust
.buffered(self.prefetch_chunk_count)核心优势:
- 同时维护最多
prefetch_chunk_count个并发请求 - 自动背压控制:当缓冲区满时,暂停新任务的启动
- 保持结果顺序:尽管请求可能乱序完成,但输出按偏移量顺序排列
2.3 内存管理策略
rust
impl FileReadOp {
pub fn new(fh: SharedFh3, start_offset: u64, length: u64, max_read_buffer_size: u64, nfs_op: SharedFsInner) -> Self {
Self {
file_fh: fh,
start_offset,
length,
// 关键:动态选择较小的块大小,避免内存过度使用
prefetch_chunk_size: min(nfs_op.nfs_config.prefetch_chunk_size, max_read_buffer_size),
prefetch_chunk_count: nfs_op.nfs_config.prefetch_chunk_count,
nfs_op: nfs_op.clone(),
}
}
}经过这个优化以后,文件的读取就比 NFS 原生的更快了,而且我们可以根据我们服务器的配置和 RTT 来做更好的参数配置预读的大小、预读的任务数。
测试与兼容
为了保证我们实现的正确性和与 minio 的兼容性,我们把 minio 的单元测试和接口测试几乎全部移植了过来,我们 2 行多行代码中大概有一万多行是测试代码,感谢 AI 编程吗喽(Cursor、Claude Code)
markdown
------------------------------------------------------
Language files blank comment code
------------------------------------------------------
Rust 145 4619 3949 22327
XML 6 0 0 790
TOML 14 28 23 438
Markdown 3 123 0 417
YAML 5 224 424 323
Text 1 21 0 184
JSON 5 0 0 107
Python 1 16 14 46
-------------------------------------------------
SUM: 180 5031 4410 24632
-------------------------------------------------扩展功能
我们在原有 minio 支持的功能上,还支持了文件类型白黑名单、文件防覆盖。以及后续会增加的文件生命周期管理、上传接口回调等。
性能对比
压测还在进行中,下面是一个简单的测试结果(测试工具:minio 的压测工具 warp github.com/minio/warp )
| 测试场景 | 系统 | 吞吐量 (MiB/s) | QPS (obj/s) | 说明 |
|---|---|---|---|---|
| 1KB 文件上传(锁竞争) | minio | 0.00 | 0 | 严重锁竞争 |
| maxio | 5.56 ▲ | 5834.53 ▲ | 高并发优势明显 | |
| 1KB 文件上传 | minio | 0.90 | 947.18 | |
| maxio | 5.44 ▲ | 5702.19 ▲ | QPS 高 6 倍 | |
| 10MB 文件不分片上传 | minio | 70.43 | 7.04 | |
| maxio | 103.70 ▲ | 10.36 ▲ | 吞吐量高 47% | |
| 10MB 文件分片上传 | minio | 39.88 | 3.99 | 分片降低性能 |
| maxio | 40.53 | 4.05 | 分片后性能接近 | |
| 100KB 文件下载 | minio | 106.45 ▲ | 996.17 | |
| maxio | 97.28 | 1090.01 ▲ | 读取性能数据相当 |
在有目录锁竞争时,minio 无响应,qps 降到 0,而 maxio 基于无影响。
更优竞争力的是 Rust 的内存占用,压测过程中,几乎很少有超过 100M 的内存占用,这和 minio 动辄 10 几个 G 的内存占用没法比。
关于 Rust
用 Rust 来写大型项目很有挑战,但带来的性能收益是很明显的,尤其是在边缘计算等资源受限的场景。
熟悉了,跟写 Go 和 Java 也没什么太大区别。