论文题目:MBQ: Modality-Balanced Quantization for Large Vision-Language Models(MBQ:大型视觉语言模型的模态平衡量化)
会议:CVPR2025
摘要:视觉语言模型(vlm)支持各种现实世界的应用程序。vlms的大参数带来了巨大的内存和计算开销,这给部署带来了巨大的挑战。训练后量化(PTQ)是一种减少内存和计算开销的有效方法。现有的PTQ方法主要集中在大型语言模型(大型语言模型)上,而没有考虑到其他模式之间的差异。在本文中,我们发现在大型VLMs中,语言标记和视觉标记在灵敏度上存在显著差异。因此,像现有的PTQ方法一样,平等地对待来自不同模态的令牌,可能会过度强调不敏感的模态,导致显著的准确性损失。为了解决上述问题,我们提出了一种简单而有效的方法,即模态平衡量化(MBQ)。具体来说,MBQ在校准过程中结合了不同模态的不同灵敏度,以最大限度地减少重建损失,从而获得更好的量化参数。大量实验表明,与SOTA基线相比,在W3A16和W4A8量化下,MBQ可以显著提高7B至70B VLMs的任务精度,分别提高4.4%和11.6%。此外,我们实现了一个融合了去量化和gemv运算符的W3A16 GPU内核,在RTX 4090的LLaVAonevision-7B上实现了1.4→加速。
源码链接:https://github.com/thu-nics/MBQ
MBQ方法的具体实现
第一步:发现问题 - 如何测量"重要性"?
🔬 实验设计
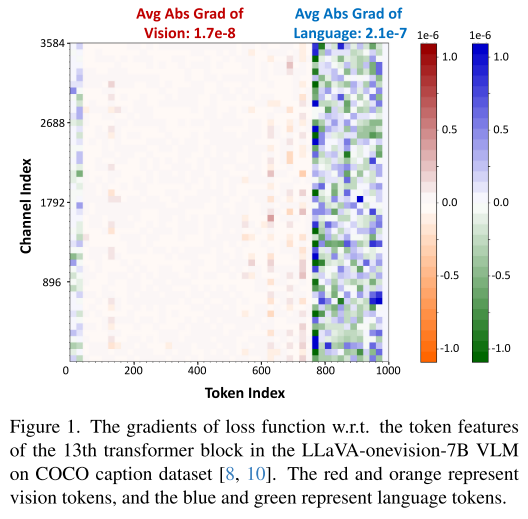
研究者们设计了一个巧妙的实验来测量图片和文字信息的重要性:
实验过程:
- 输入数据:给AI模型一张图片 + 对应的文字描述
- 计算梯度:看当我们稍微改变图片信息或文字信息时,最终输出会受到多大影响
- 量化差异:用数学方法计算这种影响的大小
关键发现:
文字信息的平均梯度值:2.1e-7
图片信息的平均梯度值:1.7e-8
差异:文字信息的影响力是图片信息的 12倍!🧠 为什么梯度能表示重要性?
想象你在调音台上:
- 如果轻轻调节某个按钮,音乐就发生很大变化 → 这个按钮很重要(高梯度)
- 如果用力调节另一个按钮,音乐几乎没变化 → 这个按钮不重要(低梯度)
第二步:验证想法 - 简单的"加权"实验
在开发完整方法之前,研究者先做了一个验证实验:
🧪 Oracle实验
# 传统方法(把图片和文字同等对待)
传统损失 = 图片重建误差 + 文字重建误差
# 改进方法(给图片信息更小的权重)
改进损失 = 0.1 × 图片重建误差 + 1.0 × 文字重建误差结果: 仅仅这个简单改动就让模型准确率提升了1.55%到3.66%!
这证明了想法的正确性,但0.1这个权重是人为设定的,不够科学。
第三步:数学建模 - 自动计算最优权重
📊 核心数学原理
研究者用泰勒展开来建立数学模型:
原始公式:L(Y + Δ) ≈ L(Y) + g^T · Δ翻译成人话:
- L(Y):原始的损失(错误程度)
- Δ:我们对数据的改动
- g:梯度(敏感性指标)
- 这个公式告诉我们:改动造成的影响 = 敏感性 × 改动大小
🎯 具体分解
将这个公式分别应用到图片和文字:
总影响 = |g_vision| × ||图片改动|| + |g_language| × ||文字改动||其中:
|g_vision|:图片信息的平均敏感性|g_language|:文字信息的平均敏感性||改动||:改动的大小
第四步:算法实现 - 两种量化策略
🔧 策略一:权重+激活量化(加速预填充阶段)
目标函数:
最小化 [|g_v| × ||原始图片输出 - 量化后图片输出|| +
|g_l| × ||原始文字输出 - 量化后文字输出||]应用场景: 当AI一次性处理很多信息时(比如分析一张复杂图片)
🔧 策略二:仅权重量化(加速解码阶段)
目标函数:
最小化 [|g_v| × ||W×X_v - Q(W×E)(E^(-1)×X_v)|| +
|g_l| × ||W×X_l - Q(W×E)(E^(-1)×X_l)||]应用场景: 当AI逐字生成回答时
第五步:具体实现步骤
📋 完整算法流程
# 伪代码展示MBQ算法
def MBQ_quantization(model, calibration_data):
# 步骤1:计算敏感性权重
for each_layer in model:
for each_sample in calibration_data:
# 前向传播
vision_output, language_output = layer.forward(sample)
# 计算损失
loss = compute_SFT_loss(vision_output, language_output)
# 反向传播计算梯度
vision_grad = compute_gradient(loss, vision_output)
language_grad = compute_gradient(loss, language_output)
# 计算平均梯度(敏感性指标)
avg_vision_sensitivity = mean(abs(vision_grad))
avg_language_sensitivity = mean(abs(language_grad))
# 步骤2:搜索最优量化参数
for each_layer in model:
# 定义目标函数
def objective_function(E): # E是通道均衡因子
vision_error = avg_vision_sensitivity * reconstruction_error_vision(E)
language_error = avg_language_sensitivity * reconstruction_error_language(E)
return vision_error + language_error
# 优化求解
optimal_E = optimize(objective_function)
# 应用量化
layer.apply_quantization(optimal_E)
return quantized_model🎛️ 关键技术细节
-
梯度计算
# 计算每个token对最终损失的敏感性 gradients = torch.autograd.grad(loss, token_features, retain_graph=True) sensitivity = torch.mean(torch.abs(gradients)) -
通道均衡
# 搜索最优的缩放因子 def channel_equalization(W, X, sensitivity_weights): # W: 权重矩阵, X: 输入激活, sensitivity_weights: 敏感性权重 best_E = None min_loss = float('inf') for E in search_space: quantized_output = quantize(W * E) @ (X / E) weighted_error = sensitivity_weights * reconstruction_error(quantized_output) if weighted_error < min_loss: min_loss = weighted_error best_E = E return best_E
第六步:硬件加速实现
⚡ 自定义GPU核心
研究者还开发了专门的GPU计算核心:
W3A16核心的工作原理:
-
数据打包:把8个3位权重打包成3个字节
-
融合操作:将解量化和矩阵运算合并成一个操作
-
内存优化:直接加载3位权重而不是16位,减少内存访问
// GPU核心伪代码
global void fused_w3_gemv_kernel(
uint8_t* packed_weights, // 打包的3位权重
float* input, // 输入向量
float* output, // 输出向量
float* scales // 缩放因子
) {
// 步骤1:解包3位权重
float unpacked_weight = unpack_3bit(packed_weights[idx]);// 步骤2:解量化 float dequantized_weight = unpacked_weight * scales[channel]; // 步骤3:计算 output[row] += dequantized_weight * input[col];}
第七步:完整的部署策略
🎯 分阶段优化策略
视觉编码器(ViT):
- 使用W4A8量化(4位权重,8位激活)
- 主要处理图片,计算密集型
语言模型(VLM):
- 预填充阶段:W4A8量化,处理长输入序列
- 解码阶段:W3A16量化,逐词生成,内存访问密集型
📈 性能优化结果
单个操作性能:
矩阵尺寸 3584×18944:FP16用时14.4ms → W3A16用时2.9ms(5倍加速)
矩阵尺寸 18944×3584:FP16用时14.6ms → W3A16用时3.1ms(4.7倍加速)端到端性能:
ViT编码器:11.2ms → 9.7ms(1.15倍加速)
VLM解码:29.6ms → 21.1ms(1.4倍加速)