作者:来自 Elastic Jhon Guzmán
了解如何将 Vertex AI 与 Elasticsearch 集成来创建 RAG 应用。按照本教程配置一个 Gemini 模型并在 Kibana 的 Playground 中使用它。
更多阅读:
想要获得 Elastic 认证吗?看看下一期 Elasticsearch Engineer 培训什么时候开始!
Elasticsearch 拥有大量新功能,可以帮助你为你的用例构建最佳搜索解决方案。深入学习我们的示例 notebooks 以了解更多,开始免费的 cloud 试用,或者现在就在本地机器上尝试 Elastic。
从 Elasticsearch 版本 9.1.0 开始,你可以集成 Vertex AI 模型(包括 Gemini),并在 Elasticsearch 中使用它们。这个最新版本在现有的 embedding 和 reranking 功能上新增了 completion 和 chat_completion 能力,因此你可以通过 AI connector 在模型中配置它们。
Vertex AI 允许你使用像 Gemini 2.5 Pro 和 Flash 这样的模型,这些模型对 RAG 的推理和文本流很有用。此外,使用 Vertex AI 你还可以部署模型以进行更多自定义和微调。
我们选择 gemini-2.5-flash-lite,因为它在价格和性能之间有最佳平衡,同时在推理基准中得分很高。它被评为最快和最便宜的模型之一,是一个很好的入门选择。如果我们需要更强大性能,可以切换到 gemini-2.5-pro。Gemini 2.5-mini 非常适合低延迟、大数据量处理,比如我们要创建的这种 RAG 应用。

在这篇文章中,你将学习如何在 Elasticsearch 中配置一个基础的 Vertex AI 模型,以便在 Kibana 的 Playground 中使用它。我们将设置 GCP Service Account,并配置 gemini-2.5-flash-lite 来用 Playground 创建一个 RAG 应用。
下面是我们基础配置的示意图:
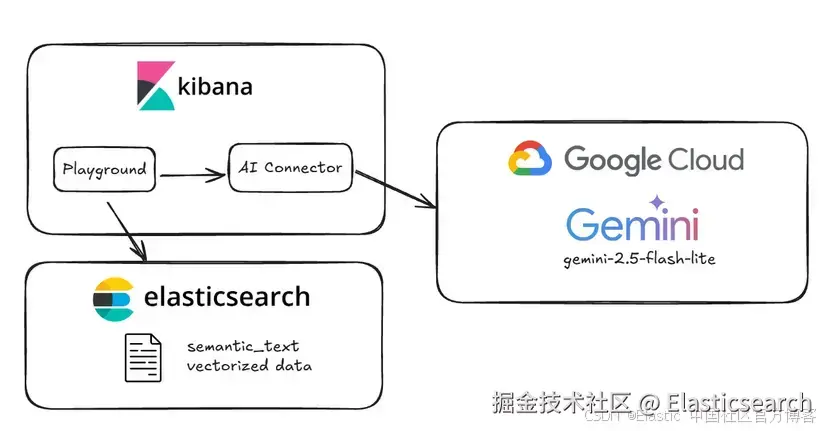
设置 AI Vertex Connector
第一步是在 GCP 中创建一个服务账号以使用 Vertex AI 平台。如果你已经有了,就跳过这一步,但要确保手头有认证用的 JSON 文件,并且该账号已分配 Vertex AI User 和 Service Account Token Creator 角色。
创建 GCP 服务账号
要创建 GCP 服务账号,你需要进入这个链接,选择将要创建账号的项目,然后点击 "+ Create service account"。
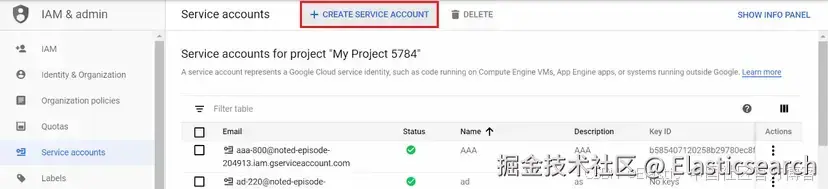
为服务账号选择一个名称并点击 "Create and continue"。在下一个菜单中,为其添加以下两个角色的权限:
-
Vertex AI User
-
Service Account Token Creator:该角色允许账号生成必要的访问令牌。
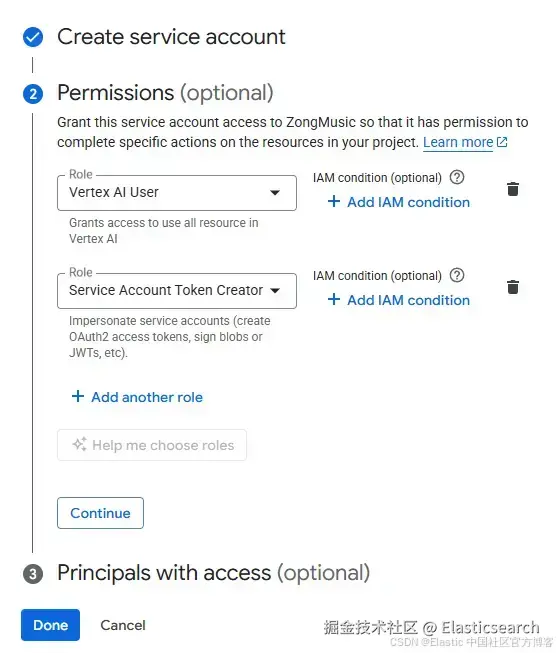
点击 "Done"。
创建服务账号后,你必须下载 JSON 访问密钥。在下一个链接中,选择你刚创建的账号。进入"Keys ",然后点击 "Add key ",再点击 "Create new key"。
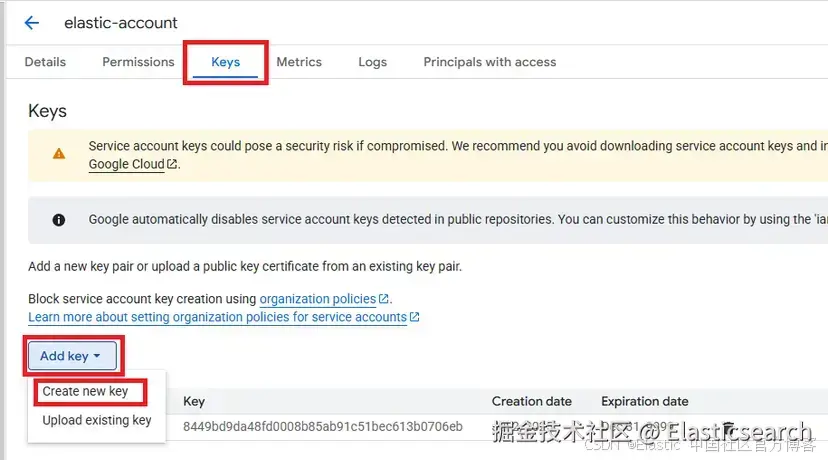
在弹出窗口中,确保将 JSON 标记为密钥类型,然后点击 "Create"。

这会下载一个 JSON 密钥,你将在接下来的步骤中用到它。
创建 Elasticsearch 集群
为了使用 Vertex 模型,我们将在这里注册并创建一个 Elastic Cloud Serverless 集群,但你可以选择适合你需求的部署类型。对于本教程,我们将选择 search 用例。
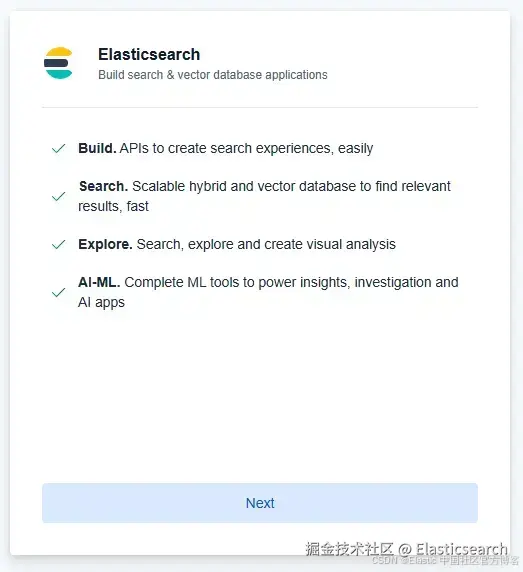
然后,表单会要求你选择一个 cloud provider 和区域。接着,你需要选择一个 "optimized for vectors" 的项目。这一步仅在 Serverless 部署中需要。
集群部署完成后,进入 Kibana 进行下一步操作。
创建 AI Connector
现在你的集群已经准备好,并且可以访问 Vertex AI,你就可以创建 connector 了。在 Kibana 中,进入 Connectors 菜单(Management > Stack Management > Alerts and Insights > Connectors)。然后,创建一个 connector 并选择 AI Connector。
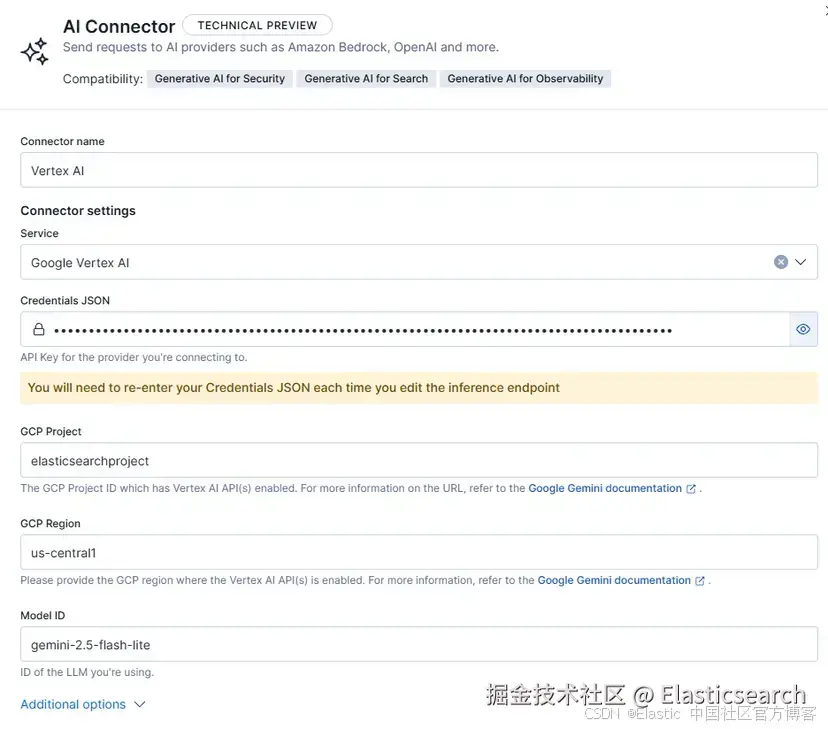
使用以下参数配置 connector:
-
Connector name:Vertex AI
-
Service:Google Vertex AI
-
JSON Credentials:在这里,你需要复制/粘贴前面步骤中创建的访问密钥的完整内容
-
GCP Project:服务账号和 Vertex AI 模型所在的项目 ID
-
GCP Region:模型所在的区域(us-central1 可访问大多数 Gemini 模型)
-
Model ID:gemini-2.5-flash-lite
-
Task Type:chat_completion
你的 connector 应该看起来像这样:
除了这个配置,你还有 "additional options",可以定义模型和通过 connector 可用的推断端点的关键属性。
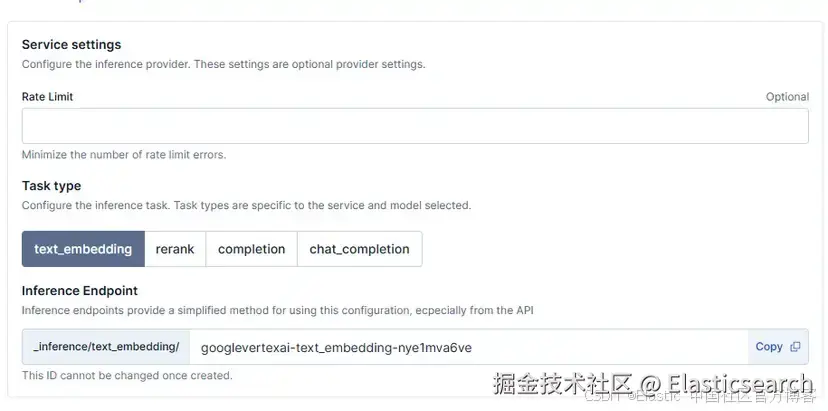
Rate limit :可选地定义每分钟发送请求的最大数量。
Task type:使用模型执行的任务。这个新版本增加了 completion 和 chat_completion:
-
Completion:模型接收一个 prompt 并生成最可能的延续。没有对话轮次、角色或任何对话结构。适用于简单任务,如补全代码、生成连续文本,或在没有上下文的情况下回答直接问题。
-
Chat Completion:此模式以基于角色的结构(system、user、assistant)训练模型,允许处理多轮交互。在内部,模型不仅预测下一个 token,还会基于对话意图进行预测。
-
Inference Endpoint:创建 connector 时,会生成一个推断端点以识别配置任务的模型。我们可以定义一个 ID 并在推断 API 和 Kibana 中使用它。
在 Kibana 的 Playground 中使用模型
上传数据
要测试模型,我们需要一些数据,并确认 _inference API 可用。从 8.17 版本开始,机器学习功能是动态的,这意味着要下载并使用 E5 dense multilingual vector,只需使用该模型即可。
bash
`
1. # find e5 model id
2. GET /_inference
4. # trigger the download by using it
5. POST /_inference/text_embedding/.multilingual-e5-small-elasticsearch
6. {
7. "input": "Warming up ML nodes!"
8. }
`AI写代码当你生成 embeddings 时,模型会被下载,推断端点会自动运行。
现在,让我们上传下面的文本作为 RAG 上下文:
vbnet
`
1. Casa Tinta Bistro is a small, family-run restaurant located in the Chapinero neighborhood of Bogotá, Colombia. It was founded in 2019 by siblings Mariana and Lucas Herrera, who combined their love for traditional Colombian flavors with a modern twist. The bistro is best known for its creamy coconut ajiaco, mango-infused arepas, and handcrafted guava lemonade.
3. The restaurant operates Tuesday through Sunday, from 12:00 PM to 9:30 PM, and closes on Mondays. They offer vegetarian and vegan options, and their menu changes slightly every season to incorporate fresh local ingredients. Casa Tinta also hosts monthly poetry nights, where local writers perform their work in front of a small crowd of regulars and newcomers alike.
5. Although it remains a hidden gem for most tourists, Casa Tinta has a loyal base of local customers and consistently ranks high on community food blogs and private reviews.
`AI写代码将文本保存为 .txt 文件,然后进入 Elasticsearch > Home > Upload a file
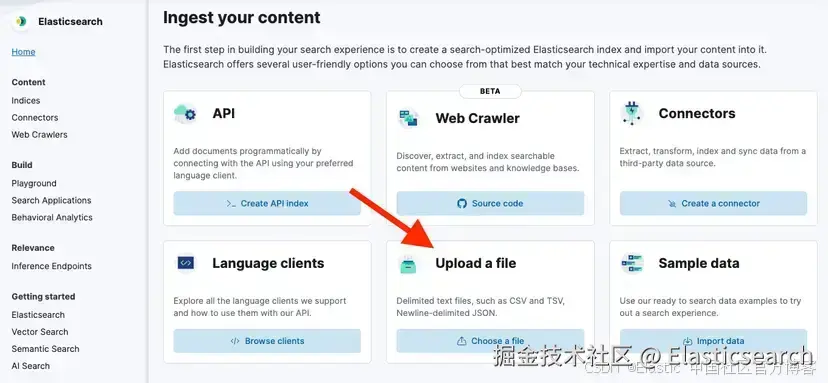
点击按钮或将文件拖放到 "Upload data " 框中。然后,点击 Import。

然后,选择 "Advanced " 标签,并将索引命名为 "bistro_restaurant1"。
接着,点击 "Add additional field ",选择 "Add semantic text field "。将推断端点改为 ".multilingual-e5-small-elasticsearch"。配置应如下所示:
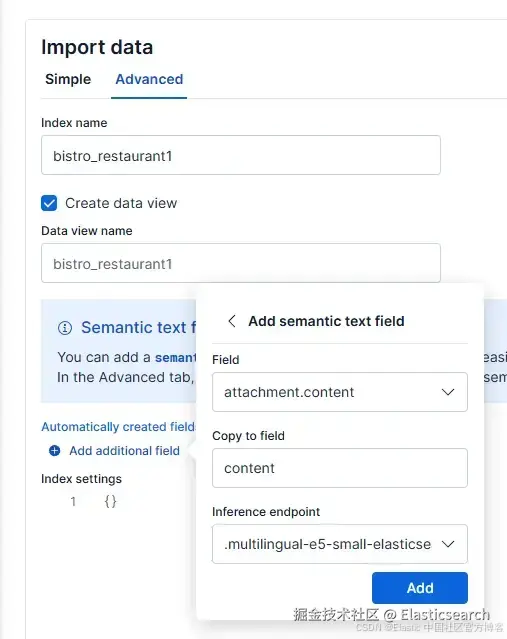
最后,点击 "Add ",然后点击 "Import"。
上传完成后,我们可以在 Playground 中使用这些数据。
在 Playground 中测试 RAG
进入 Kibana 的 Elasticsearch > Playground。
在 Playground 页面,你应该看到一个绿色对勾和消息 "LLM Connected",表示我们刚创建的 Vertex connector 已存在。你可以查看这个链接获取更深入的 Playground 指南。
点击蓝色按钮 "Add data sources",选择我们刚创建的 bistro_restaurant 索引。
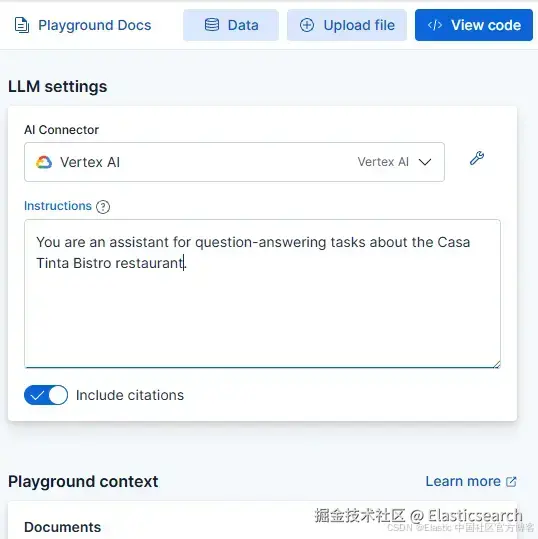
在 Playground 中,我们将模型的 prompt 定义为 "You are an assistant for question-answering tasks about the Casa Tinta Bistro restaurant。" 其余配置保持默认。
现在,我们可以向模型提出关于该餐厅的任何问题,它会查询索引以提供合适的答案。
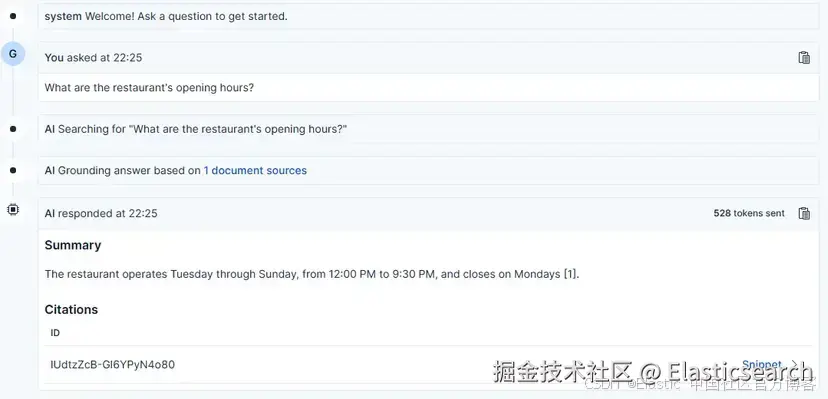
例如,我们可以询问营业时间,模型会给出答案的 "sources",这些指的是信息所在文档的 ID。
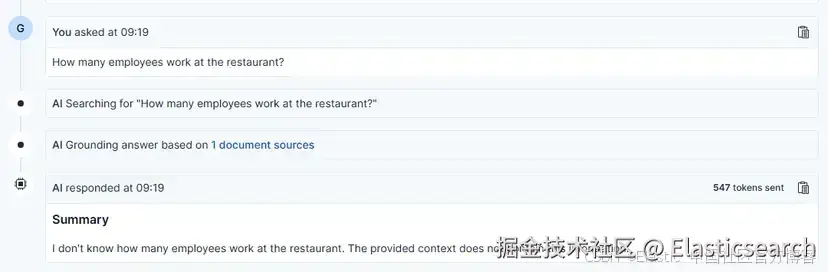
当你提出与 RAG 上下文无关的问题时,模型会回复 "The provided context does not contain this information",因为答案是基于数据的。
结论
通过新的 Vertex AI 集成,你可以轻松使用像 Gemini 这样的模型,在 Playground 中创建基于索引数据提供答案的 RAG 应用。现在,迈出下一步,决定要索引哪些其他来源,选择另一个 Vertex AI 模型,或者部署你自己的模型,让 RAG 为你的特定用例工作。
原文:Exploring Vertex AI with Elasticsearch - Elasticsearch Labs